EgoMem: Lifelong Memory Agent for Full-duplex Omnimodal Models翻译
我们推出了 EgoMem,这是首个专为处理实时全模态流的全双工模型量身定制的终身记忆 Agent。EgoMem 使实时模型能够直接从原始视听流中识别多个用户,提供个性化响应,并长期保存从视听历史中提取的用户信息、偏好和社交关系。**EgoMem 通过三个异步进程运行**:(i)检索进程,通过面部和语音动态识别用户,并从长期记忆中收集相关上下文;(ii)全模态对话进程,基于检索到的上下文生成个性化音
摘要
我们推出了 EgoMem,这是首个专为处理实时全模态流的全双工模型量身定制的终身记忆 Agent。EgoMem 使实时模型能够直接从原始视听流中识别多个用户,提供个性化响应,并长期保存从视听历史中提取的用户信息、偏好和社交关系。EgoMem 通过三个异步进程运行:(i)检索进程,通过面部和语音动态识别用户,并从长期记忆中收集相关上下文;(ii)全模态对话进程,基于检索到的上下文生成个性化音频响应;以及(iii)记忆管理进程,自动从全模态流中检测对话边界,并提取必要信息以更新长期记忆。与现有的终身学习模型(LLM)记忆 Agent 不同,EgoMem 完全依赖于原始视听流,使其特别适用于终身、实时和具身化的场景。实验结果表明,EgoMem的检索和记忆管理模块在测试集上的准确率超过95%。当与经过微调的 RoboEgo 全模态聊天机器人集成时,该系统在实时个性化对话中实现了87%以上的事实一致性得分,为未来的研究奠定了坚实的基础。
1.Introduction
人工智能的广泛应用都涉及实时、终身的全模态信息流。一个显著的例子是部署在家庭和公共场所的机器人。在这种情况下,模型不仅需要快速执行指令,还需要识别用户、记住他们的历史记录、理解社交关系并提供个性化服务。从技术角度来看,满足这些要求的关键能力在 [53] 中进行了总结,包括全模态性、实时响应能力和类人认知能力。关于全模态性,随着基础模型的快速发展,人们在整合音频、视觉和动作信号以实现联合理解方面做出了大量努力。对于实时响应能力,已经有一些解决方案实现了全双工,这些方案基于时分复用或原生双工方案。然而,对于当前的全模态全双工系统而言,类人认知能力仍然是一个尚未充分开发的能力。本文将终身记忆能力的实现视为迈向类人认知的关键第一步,因为记忆系统是人类和通用人工智能的基础。我们重点关注实时个性化对话,以此作为验证终身全模态记忆设计的主要任务。
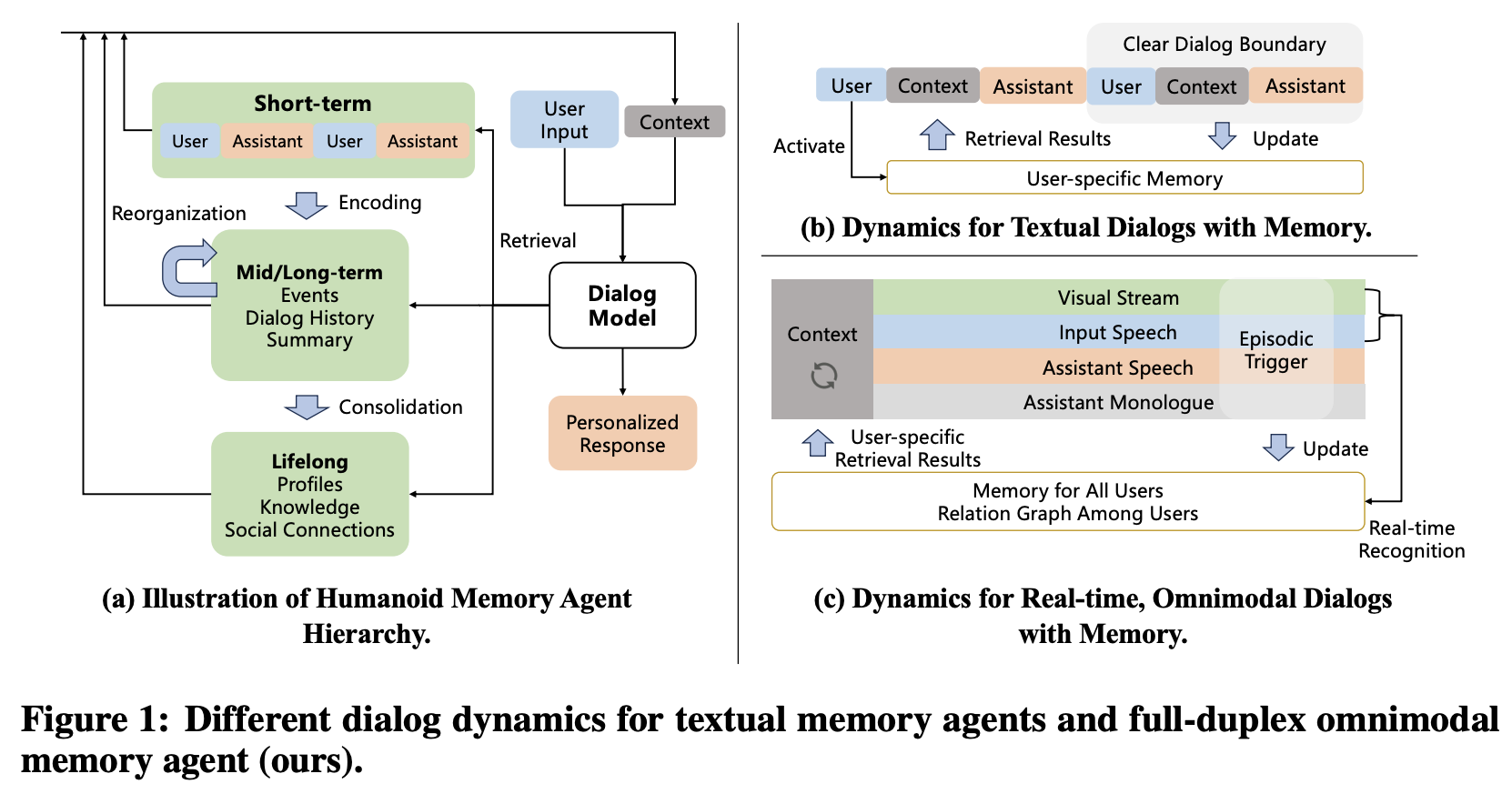
在文献中,为文本型大语言模型(LLM)配备长期记忆主要有两种方法:扩展上下文窗口和记忆 Agent。然而,这两种方法都难以很好地应用于终身全模态场景。一方面,扩展上下文窗口可以保留较长的特征表示序列,编码完整的全模态信息。然而,在终身环境中,音频和视频流的长度会无限增长,即使是百万级的上下文也不足以满足需求,最终会导致信息丢失(例如,用户身份)。另一方面,记忆 Agent 方法(图1(a))虽然非常适合终身运行,但通常依赖于几个强假设:用户身份明确已知、对话会话具有清晰的边界,以及所有输入均为文本(图1(b))。遗憾的是,这些假设在全双工全模态应用中并不成立。在这些应用中,用户身份信息隐式地编码在音视频流中,而全双工特性意味着对话轮次或用户会话之间没有明确的界限(图 1 ©)。此外,现有的记忆 Agent 通常忽略了多用户社交关系图,而这对于类人认知而言至关重要。
我们通过以下方式展示全模态终身记忆 Agent 在个性化对话中的作用。(1) 当用户Emily出现时,会进行轮询,直接从音视频流(例如,摄像头和麦克风输入)中检测用户身份是否为 Emily;(2) Emily的个人资料被编码并放入全模态聊天机器人的对话上下文中;(3) 当Emily询问“does any of my colleagues love tennis?”时,聊天机器人会生成一个关于 “colleague” 关系和关键词 “tennis” 的查询,从而激活对包含 Emily 社交关系图的知识库的文本检索,返回一条对话记录:“John, colleague, 2024-05-13, user discussed a tennis game he played 2 days ago”。该记录被进一步编码为对话上下文;(4) 聊天机器人根据可用的上下文回答 “Yes, Emily, your colleague John loves tennis”。 (5)一个独立的进程从最近对话的原始音视频流中提取用户事实:“Emily shows interest in tennis”和对话记录“2024-05-14, user asked if any of her colleagues loves tennis”,并将这些内容更新艾米丽的个人资料以供将来使用;(6)当艾米丽在另一天出现时,该模型能够问候道:“Hi Emily, did you talk to John about tennis?”
针对类似场景,我们提出了 EgoMem,这是首个专为全模态场景量身定制的终身记忆系统,旨在促进全双工个性化对话。EgoMem 通过三个异步进程运行。首先,检索进程负责实时轮询用户识别,并采用视听检索机制实现。它还包含一个内容驱动的文本检索模块,用于收集相关记忆。该进程有助于将用户特定信息和 RAG 式信息高效地集成到对话流程中。其次,全模态对话进程使用经过微调的对话模型,根据检索到的上下文实时提供全双工个性化响应。第三,记忆管理进程通过处理实时原始视听流来处理对话边界检测、信息提取和记忆更新。这使得系统能够以低成本持续收集有意义的信息,并长期保持记忆的最新状态。
尽管 EgoMem 方法可以应用于任何全模态骨干网络,但我们将其集成到 RoboEgo 中。RoboEgo 是一款原生全双工模型,与我们的目标场景最为契合,同时在通用实时对话任务上也能达到与最先进系统相当的对话性能。我们为 RoboEgo 集成了完整的 EgoMem Agent 套件,并训练了对话模型及其必要的子模块,使其能够为任意用户提供实时、持久且个性化的响应。我们对音频、文本和视觉检索模块、记忆管理模块以及系统的个性化能力进行了自动化评估,分别以单用户配置文件(一级)和多用户社交图谱(二级)作为参考上下文。评估结果表明,这些模块展现出较高的准确性和鲁棒性,并且 EgoMem 的集成增强了个性化功能,同时又不影响 RoboEgo 原有的对话能力。
我们的贡献如下:
- 框架——我们提出了 EgoMem,这是一个用于全双工、全模态交互的终身记忆 Agent,据我们所知,它是同类产品中的第一个。
- 实现——我们提供了基于 RoboEgo 主干网的 EgoMem 的具体实现,包括详细的模块设计、数据构建管道和训练配置。
- 评估——我们证明 EgoMem 在终身全模态场景的个性化任务中取得了稳健的性能,为未来的研究建立了一个坚实的基准。
2.Task Definition and Preliminaries
2.1 Task Description
EgoMem 旨在为长期部署的全模态模型提供全双工、个性化的聊天功能。作为第一步,我们首先关注每次只有一个活跃发言者的情况,将更复杂的鸡尾酒会问题留待未来研究。在此设置下,在每个时刻 ttt,主对话模型 FFF 接收音频 ata_tat、视频 vtv_tvt 以及可选的文本输入 ltl_tlt 作为输入(监听),同时接收用户个人资料 ptp_tpt 和参考信息 ctc_tct。它生成个性化回复rtr_trt:
rt=Fθ(at,vt,pt,ct).(1)r_t=F_{\theta}(a_t,v_t,p_t,c_t).\tag{1}rt=Fθ(at,vt,pt,ct).(1)
在此,ptp_tpt 和 ctc_tct 在现有文献中通常被称为上下文或短期记忆,它们通常作为输入序列和 Transformer KV 缓存的一部分传递给 FFF。
EgoMem 管理外部记忆单元 MMM,具有三个核心功能:检索、写入和更新。
检索。检索功能根据当前对话内容,在 MMM 中搜索相关信息,从而为对话模型提供 ptp_tpt 和 ctc_tct:
pt,ct=EgoMem.retr(at,vt,M).(2)p_t,c_t=EgoMem.retr(a_t,v_t,M).\tag{2}pt,ct=EgoMem.retr(at,vt,M).(2)
在传统的基于 RAG 的文本记忆系统中,对话会话开始前,用户身份 (ptp_tpt) 就已经确定,而对话边界 (ctc_tct) 的检索则在用户发出每个指令后、模型做出最终响应之前激活。检索过程可以由外部模块完成,也可以由经过微调以执行工具调用的 LLM 完成。在终身全模态场景中,一个关键区别在于用户身份和对话边界都是任意的。记忆 Agent 应该能够从原始音视频流中自行检测用户身份和会话边界。在第 3 节中,我们提供了一套基于不同形式的 ctc_tct 的 EgoMem 算法,用于实现此功能。
写入。写入功能从终身多模态数据流中提取重要事件,并将其存储在记忆单元 MMM 中:
Episode=EgoMem.extract(a0 t,v0 t,l0 t),(3)Episode=EgoMem.extract(a_{0~t},v_{0~t},l_{0~t}),\tag{3}Episode=EgoMem.extract(a0 t,v0 t,l0 t),(3)
M←EgoMem.write(M,Episode).(4)M\leftarrow EgoMem.write(M,Episode).\tag{4}M←EgoMem.write(M,Episode).(4)
在 EgoMem 中,记忆写入与主对话异步进行,通过独立进程执行。与传统记忆 Agent 不同,EgoMem 以对话历史记录中的原始多模态数据流片段(“情景记忆”)作为输入,并提取事件的文本描述、用户角色和其他有用信息。
更新。与传统记忆 Agent 类似,EgoMem 会定期执行在线或离线记忆巩固:它将现有记忆整合到新的、巩固的表征中,并解决潜在的冲突:
M←EgoMem.update(M).(5)M\leftarrow EgoMem.update(M).\tag{5}M←EgoMem.update(M).(5)
2.2 Preliminaries
本节介绍本文所用 EgoMem 实现的预备知识。尽管如此,EgoMem 的框架和方法论可以应用于任意全双工全模态对话模型 FFF,以及超出我们实现范围的 ata_tat、vtv_tvt 和 ltl_tlt 的不同流组织形式。
Model Choice。我们采用 RoboEgo 作为主要对话模型,因为它至少在音频模式下支持原生全双工方案。理论上,原生方案具有更低的响应延迟和更好的可扩展性。此外,在日常对话和一般指令执行任务中,RoboEgo 的响应质量和用户体验可与 Qwen-2.5-Omni 等最先进的实时聊天系统相媲美。
Omnimodal Stream Processing。对于音频信号,我们使用 Mimi tokenizer 以每秒12.5帧的速度提取特征。每个音频帧由一个语义 token 和七个声学 token 表示。音频输入和输出被分为两个通道:听音通道和说话通道,而文本独白 token 则放置在一个额外的文本通道中。因此,模型在每次前向传播中消耗17个 token,其中包括来自前一个时刻的1个文本 token 和16个音频 token。它们被加性地合并到输入嵌入中。然后,模型使用7B LLM骨干网络处理所有历史输入嵌入,以生成当前时刻的隐藏状态。遵循 RQ-Transformer 架构,一个轻量级深度Transformer(具有 100M 参数)首先基于顶层的当前隐藏状态生成一个文本独白 token,然后自回归地生成八个说话 token。在终身部署场景中,该过程实时持续运行,形成主对话流;同时,视觉信号 vtv_tvt 通过视觉 Transformer 进行编码,并以 2-4 秒的固定间隔,以时分复用 (TDM) 的方式添加到上下文中。有关详细的结构配置,请参阅相关文献。
3.EgoMem
EgoMem 的设计可分为两个层次:第一层级支持基于用户个人资料的多用户个性化设置,第二层级则支持基于社交网络及其他参考信息的个性化对话。与第一层级相比,第二层级尤其适用于用户间联系更为紧密的应用场景,例如家用机器人。对于每一层级,我们首先描述整体记忆系统设计,然后基于2.2节概述的主要对话流程,详细介绍各个子模块的实现细节。
3.1 Level-1: Profile-only
在 EgoMem Level-1 中,记忆系统会为每个已识别的用户维护详细的个人资料信息,但不会记录用户之间的社会关系图或其他参考资料。形式上,Level-1 EgoMem 在公式 1 和 2 中将 ctc_tct 设置为 None。
3.1.1 System Design
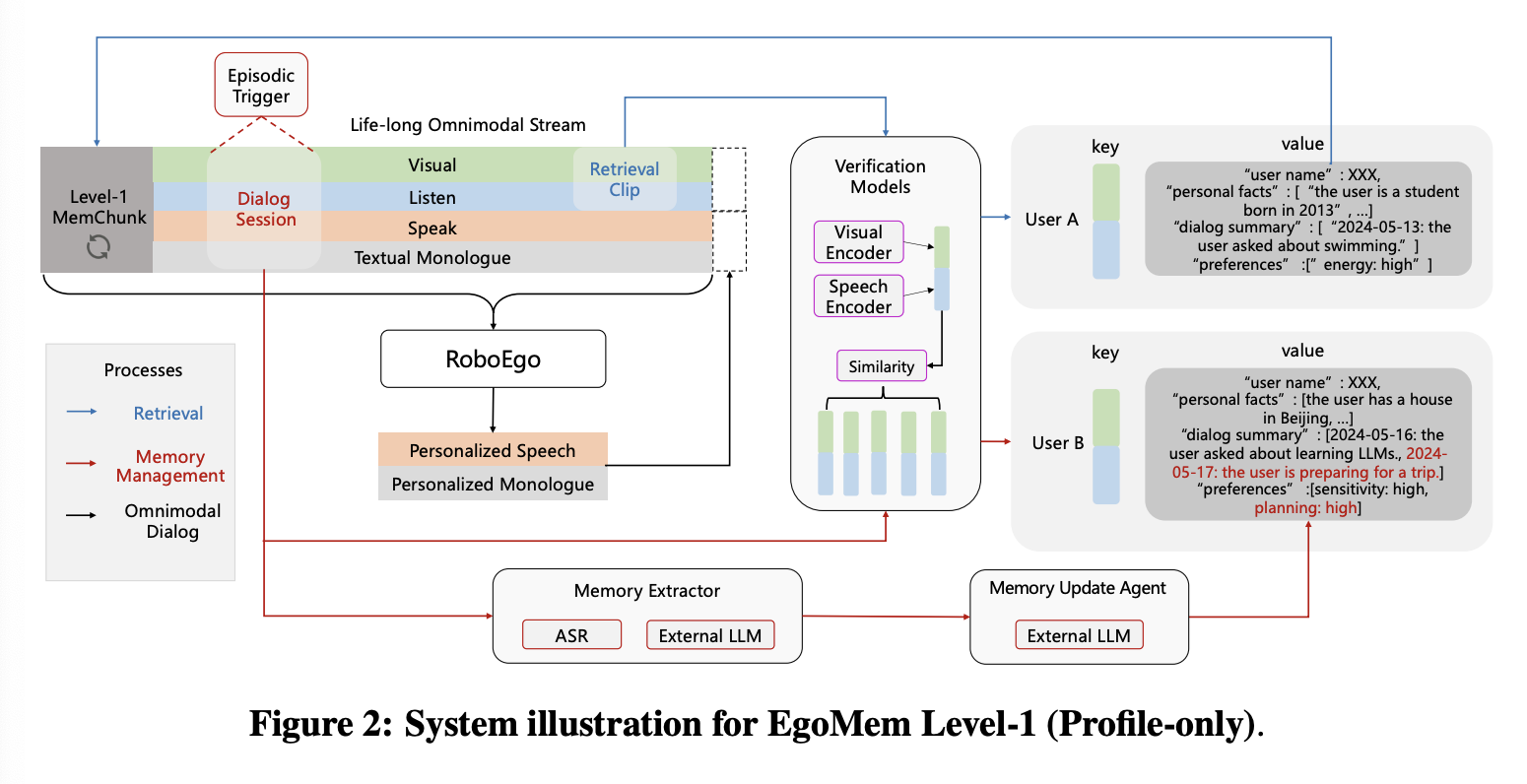
Level-1 EgoMem 的系统设计如图 2 所示。
Storage。EgoMem Level-1 将每个用户的个人资料存储在键值对中:键是双重的,一个视觉嵌入向量 vfuv^u_fvfu 用于人脸验证,一个音频嵌入向量 vsuv^u_svsu 用于说话人验证;值可以抽象为一个字典,其中存储用户的姓名、个人信息、先前对话的摘要和偏好。
Level-1 EgoMem 由以下三个异步运行的组件进程驱动:
Retrieval Process。与传统记忆 Agent 不同,我们的检索过程以固定的 2 秒间隔(“轮询”)持续运行,而不是由用户指令结束或主对话模型调用工具触发。这是一项关键设计,使得对话模型能够主动与用户对话(例如,“Greetings John!”)。每隔 2 秒,EgoMem.retr()EgoMem.retr()EgoMem.retr() 都会提取长度为 τττ 的音频和视频信号块,并提取查询向量:
vfq=visual_encoder(v(t−τ):t),(6)v^q_f=visual\_encoder(v_{(t-τ):t}),\tag{6}vfq=visual_encoder(v(t−τ):t),(6)
vsq=speech_encoder(a(t−τ):t).(7)v^q_s=speech\_encoder(a_{(t-τ):t}).\tag{7}vsq=speech_encoder(a(t−τ):t).(7)
vfqv^q_fvfq 和 vsqv^q_svsq 分别用于基于距离和阈值(3.1.2 节)对每个用户的 vfuv^u_fvfu 和 vsuv^u_svsu 进行人脸和说话人验证。如果找到有效用户,则使用文本分词器对其个人资料进行分词,并将其推送到主对话 token 流中特殊 Level-1 MemChunk 字段的文本通道。该特殊块最大长度为 512 个时间步,其 16 个音频 token 始终填充为 <empty>\text{<empty>}<empty>。主对话模型的每次前向传播都会处理该块(图 2)。请注意,Level-1 MemChunk 完全由检索过程管理:一旦当前识别的用户与之前的用户不同,其文本内容就会刷新。每次 Level-1 MemChunk 更新时,主对话进程都会收到一个信号,并运行一次前向传播,同时更新该块中所有文本词元的 KV 缓存。由于此前向传递仅由检测到的用户切换触发,因此它在推理中引入的开销可以忽略不计。
Omnimodal Dialog Process。这是运行 RoboEgo 聊天服务的主进程。Level-1 MemChunk 在每个步骤中都由 EgoMem 处理。如果检索过程未返回用户个人资料,则 Level-1 MemChunk 的文本通道将填充 <pad><pad><pad> 标记。我们使用相应的流数据格式(第 4 节)对 RoboEgo 进行微调,以根据用户的个人资料信息生成个性化的语音回复。
Memory Management Process。这是一个独立进程,它实例化了 EgoMem 的提取、写入和更新功能(公式 3-5),模拟人形机器人的记忆活动。在固定的时间间隔(例如 10 分钟)内,从主对话进程的 17 路 token 流中提取信息:记忆管理进程以一个 8192 步的流块作为输入,使用序列标记模型(即情景触发器)标记每个时间步,以确定 RoboEgo 与每个用户之间现有对话会话的边界,并收集每个对话会话对应的原始流。接下来,我们利用外部 LLM 作为记忆提取器,从剪辑后的原始流中提取事件、用户信息和用户偏好。之后,记忆管理进程调用人脸和说话人检索功能来识别此会话片段的用户。如果系统识别出用户为新用户,EgoMem 会创建一个新的用户配置文件,将人脸/语音嵌入向量存储为键,并根据提取的记忆内容初始化该用户配置文件。否则,系统会将用户身份和提取的记忆内容提供给记忆更新 Agent(Memory Update Agent),该 Agent 是一个外部 LLM,用于检测提取的记忆内容与用户现有 Profile 文件之间是否存在潜在冲突。用户的 Profile 文件将据此进行更新。
3.1.2 Sub-modules
图 2 显示了 Level-1 EgoMem Agent 中使用的所有子模块的实现。
Face Verification。我们利用 DeepFace 的开源流程从视频帧中提取人脸。具体来说,我们使用 Retinaface 作为人脸检测后端,Facenet512 作为视觉编码器,从而得到512维的人脸特征,分别用于 vfqv^q_fvfq 和 vfuv^u_fvfu。在检索过程中,我们首先通过最小余弦距离 d=1−cosine_similarity(vfq,vfu)d = 1−cosine\_similarity(v^q_f, v^u_f)d=1−cosine_similarity(vfq,vfu) 找到与查询向量 vfqv^q_fvfq 最接近的现有用户 uuu,然后使用预调阈值 δ=0.3δ = 0.3δ=0.3 进行验证:
current user={u,if d<δ,new user,else.(8)current~user=\begin{cases} u, & if~d<δ,\\ new~user, & else. \end{cases}\tag{8}current user={u,new user,if d<δ,else.(8)
Speaker Verification。我们利用专门针对说话人验证微调的 wavelm_large 模型作为语音特征提取器,生成256维的 vsqv^q_svsq 和 vsuv^u_svsu 向量。虽然说话人验证也依赖于余弦相似度,但普遍认为,对相似度得分应用自适应s范数可以显著提升性能。我们使用seed-tts-eval 数据集的中文子集作为冒名顶替者队列,其中包含 2000 个候选样本。我们基于等错误率(EER)调整验证阈值,并根据我们集成的EgoMem系统的案例研究对阈值进行微调。
Episodic Trigger。情景触发器用于确定用户身份一致的对话会话的边界。它不仅能检测对话会话的开始和结束,还能区分不同用户的会话。具体来说,情景触发器会预测音频流中每个时间步的标签(包括对齐的听和说通道):
Tag0∼t=episodic_trigger(a0∼t,r0∼t).(9)Tag_{0\sim t} = episodic\_trigger(a_{0\sim t}, r_{0\sim t}).\tag{9}Tag0∼t=episodic_trigger(a0∼t,r0∼t).(9)
具体来说,情景触发器是一个基于 RQ-Transformer 的模型,尽管参数量只有 100 M,但其输入流组织和模型结构拓扑与 RoboEgo(第 2.2 节)相同。它以 17 个 token 文本通道作为输入,最大时间步长为 8192。它不生成对话响应,而是为每个时间步长分配一个标签,标签范式如下:{0: no dialog; 1: start of a new user’s dialog session; 2: in-session step; 3: end of current user’s session}\text{\{0: no dialog; 1: start of a new user’s dialog session; 2: in-session step; 3: end of current user’s session\}}{0: no dialog; 1: start of a new user’s dialog session; 2: in-session step; 3: end of current user’s session}。由于序列标注过程是离线且分块进行的,我们将注意力掩码从类似 GPT 的因果掩码修改为类似 BERT 的全掩码。情景触发器的训练配置详见第 4 节。评估结果见第 5.2 节。
Memory Extractor。记忆提取器采用以下流水线实现:
- Episodic Trigger 会为每个时刻都会生成一个事件触发标签。根据这些标签,以标签“1”开头、以标签“3”结尾且正确填充为“2”的音频片段被视为某个用户对话会话的音频源。相应的音频波形会被截断。
- 监听通道中的截断波形经过自动语音识别(ASR)处理。原始ASR结果被送入记忆提取器。对话模型独白文本通道中的响应文本也作为参考。
- 我们利用 DeepSeek-V3 API 提取有意义的内容并存储在记忆中。具体来说,我们指示模型用简短精炼的句子概括对话内容,生成描述用户信息的句子,并为用户构建一个 90 维的个人轨迹。用户名(或“unknown_user”)存储在一个单独的字段中。
Memory Update Agent。这是 DeepSeek-V3 API,用于解决配置文件冲突并规范从记忆提取器提取的内容,确保它们适合更新结构化记忆存储。
Main Dialog Model。我们进一步微调 RoboEgo 模型,使其能够关注 Level-1 MemChunk 区域,并据此生成个性化的对话响应。微调配置详见第 4 节。与 Level-2 MemChunk(第 3.2 节)不同,该模型不会向 EgoMem 生成任何额外的控制信号或查询。
3.2 Level-2: Content-driven
在 Level-2 EgoMem 中,记忆不仅像 Level-1 那样存储每个已识别用户的个人资料,还维护用户之间的社交关系图以及其他可能有用的信息。形式上,Level-2 EgoMem 同时提供了公式 1 和公式 2 中的 ptp_tpt 和 ctc_tct。与 Level-1 的主要区别在于,我们设置了一个额外的 Level-2 MemChunk,其内容会根据主 RoboEgo 模型基于当前对话内容生成的查询动态刷新,而不是像 Level-1 MemChunk 那样由外部轮询过程驱动。在实时对话过程中,当前用户的个人资料缓存在 Level-1 MemChunk 中,而 Level-2 MemChunk 则缓存主模型主动检索数据库的结果,该数据库包含所有用户的完整社交关系图和事实信息,以及其他外部知识库。
3.2.1 System Design
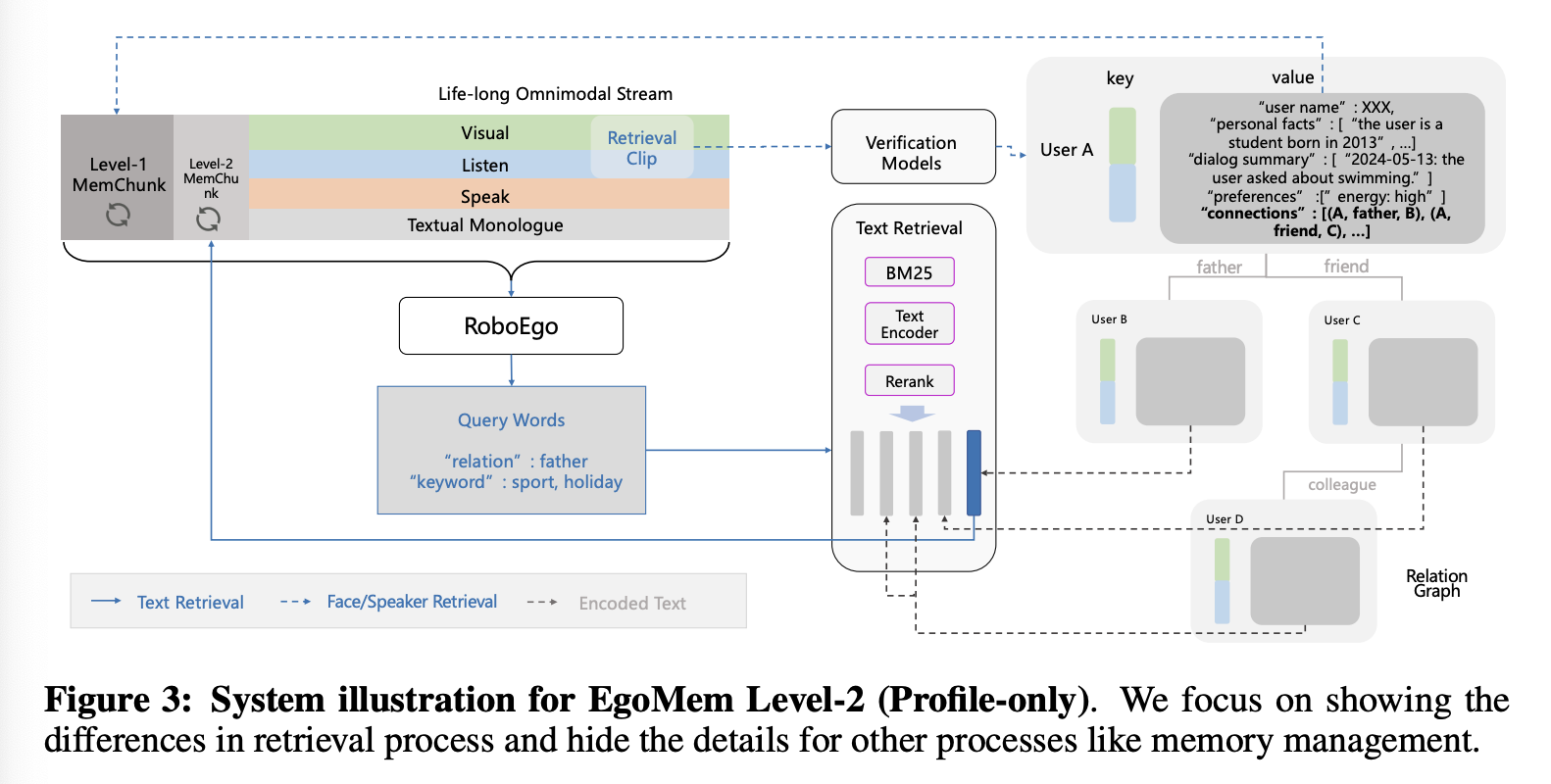
图 3 展示了 Level-2 EgoMem 的系统设计,重点展示了检索过程中的差异。
Storage。与 Level-1 版本相比,唯一的格式区别在于,对于每个用户,我们添加了一个字段,其中包含一个三元组列表,表示当前用户到完整社交关系图中其他用户的边。此外,还可以选择性地将任何其他有用的信息添加到存储中,以用于类似的 RAG 流程。
与 3.1.1 节相同的三个过程支持 Level-2 EgoMem。我们具体说明它们之间的区别如下:
Retrieval Process。Level-1 MemChunk 在系统中保持其功能,完全由外部轮询检索过程管理。此外,主模型的注意力上下文中添加了一个最大长度为 256 的 Level-2 MemChunk,该记忆块由主模型根据对话内容驱动。例如,在特定用户 A 与 RoboEgo 模型的对话会话中,Level-1 MemChunk 的内容保持不变,缓存用户 A 的个人资料。相反,在每次用户发出指令后,RoboEgo 可以激活一个独立的文本检索过程,从包含与 A 在社交关系图中关联的所有用户的姓名和个人信息以及其他有用信息的数据库中检索数据。RoboEgo 会根据当前对话在其独白通道上生成文本查询。该文本检索过程的结果会被分词并缓存到 Level-2 MemChunk 中。
Omnimodal Dialog Process。借助 Level-2 EgoMem,RoboEgo 模型能够基于 Level-1 MemChunk 和 Level-2 MemChunk 生成个性化响应。它还允许在独白通道上以任意时间步长生成文本查询词,这些查询词由特殊 token 标记,从而撤销上述文本检索过程。
Memory Management Process。记忆管理过程与 Level-1 基本相同,唯一的区别在于,记忆提取器会被提示从原始对话内容中提取新的关系事实(例如,用户 A 说他现在是用户 B 的男朋友),并且记忆更新 Agent 会被提示将用户与现有的已知用户进行相应的链接,从而更新现有社交图的边。
3.2.2 Sub-modules
在 Level-2 EgoMem 中,人脸验证、说话人验证和情景触发器与 Level-1 EgoMem 保持一致。记忆提取器和记忆更新 Agent 与 Level-1 自我记忆的区别仅在于 prompt。关键区别在于以下子模块:
Main Dialog Model。对于 Level-2 EgoMem,我们对 RoboEgo 对话模型进行了微调,使其能够生成用于主动文本检索过程的查询词。具体来说,我们允许两组查询词,格式为 <retr>:\n<group1>\n<group2><answer>\texttt{<retr>:\textbackslash n<group1>\textbackslash n<group2><answer>}<retr>:\n<group1>\n<group2><answer>,其中 group1 为“关系查询”,group2 为“关键词查询”。每组查询词都是以逗号分隔的序列。当生成最后一个 <answer>\texttt{<answer>}<answer> token 时,EgoMem 会激活文本检索过程以更新 Level-2 MemChunk。为了针对 Level-2 EgoMem 微调 RoboEgo,对于每个对话回合,我们同时使用(旧的 Level-2MemChunk、主标记流、真实查询词)三元组和(新的 Level-2 MemChunk、主标记流 + 检索词、真实响应)三元组作为训练样本。更多训练细节请参见第 4 节。
Textual Retrieval。文本检索系统根据 RoboEgo 生成的查询词收集前 K 个相关的文本信息,并更新 Level-2 MemChunk 的内容。具体来说,对于社交图中与当前用户 A 相连的每个用户 U,将 U 的名称及其与 A 的关系,与 U 的每个记忆项(事实、对话历史等)连接起来,形成一个待检索的候选文档。如果“关系查询”组不为空,我们首先仅使用关系查询,通过 BM25 算法匹配所有相关用户的文档;接下来,如果“关键词查询”组不为空,我们将所有关键词连接成一个字符串,并根据检索到的文档与该关键词字符串的向量距离重新排序。我们使用 BGE-small 模型作为文本编码器。前 K 个结果返回到 Level-2 MemChunk 的文本通道。
4.Training Details
接下来,我们将详细介绍如何微调 RoboEgo,使其能够利用 Level-1 和 Level-2 自我记忆生成个性化响应。我们还训练了情景触发器,用于标记对话边界,以便提取记忆。值得注意的是,这三个训练任务的数据收集可以通过监督掩码统一到一个框架中。
4.1 Data Collection
4.2 Training Configurations

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)