2024 ESWC KGValidator: A Framework for Automatic Validation of Knowledge Graph Construction
论文基本信息
题目:KGValidator: A Framework for Automatic Validation of Knowledge Graph Construction
作者:Jack Boylan, Shashank Mangla, Dominic Thorn, Demian Gholipour Ghalandari, Parsa Ghaffari, Chris Hokamp
机构:Quantexa
发表地点与年份:3rd International Workshop on Knowledge Graph Generation from Text (TEXT2KG), 2024 ESWC
关键词:Text2KG, Knowledge Graph Evaluation, Knowledge Graph Completion, Large Language Models
摘要(详细复述)
背景:知识图谱(KG)的验证传统上依赖大规模人工标注,成本高昂且不可扩展。
方案概述:本文提出 KGValidator,一个利用大语言模型(LLM)自动验证知识图谱构建的框架,支持通过模型内部知识、用户提供的上下文或外部知识检索来验证图谱三元组。
主要结果/提升:在多个基准数据集(如 FB15K-237N、Wiki27K)上,结合外部上下文(如 Wikidata 或网络搜索)的 GPT-4 验证器达到最高准确率(FB15K-237N-150: 0.83, Wiki27K-150: 0.89)。
结论与意义:该框架为零样本三元组分类提供了可扩展的解决方案,显著降低了人工验证成本,并支持动态知识更新。
研究背景与动机
学术/应用场景与痛点:
- 知识图谱常存在不完整性,需通过知识图谱补全(KGC)预测缺失链接。
- 传统评估基于封闭世界假设(CWA),将未出现三元组视为错误,高估模型错误率;开放世界假设(OWA)更合理但需大量人工标注。
- 主流评估方法(如排名指标 MRR、Hits@K)无法有效区分错误与未知三元组。
主流路线与局限:
| 方法类别 | 代表工作 | 优点 | 不足 |
|---|---|---|---|
| 基于规则/模式 | TAC KBP [13] | 可解释性强 | 依赖手工规则,扩展性差 |
| 嵌入模型 | KG-BERT [22], Pretrain-KG [23] | 自动学习语义表示 | 受限于训练数据分布,无法处理未知事实 |
| LLM 生成式方法 | LLM2KB [30], GPT-4 [31] | 零样本能力强,支持灵活 schema | 输出结构难以约束,易产生幻觉 |
问题定义(形式化)
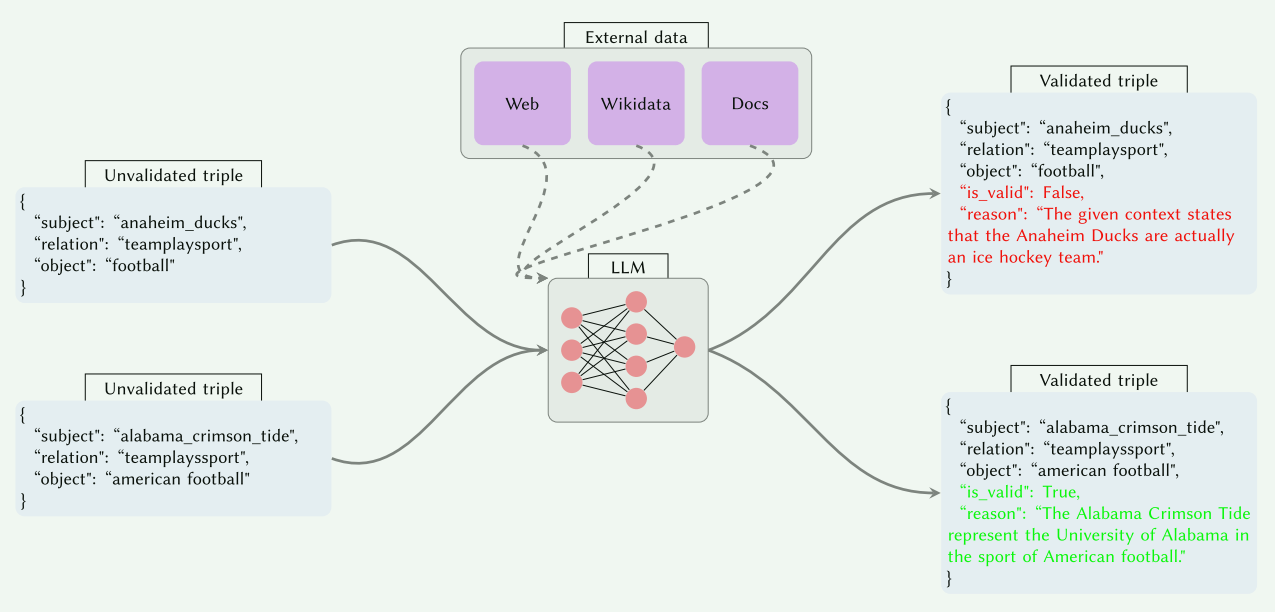
框架流程图
输入:候选三元组流 (h,r,t)(h, r, t)(h,r,t),其中 hhh 为头实体,rrr 为关系,ttt 为尾实体。
输出:验证结果 {is_valid∈{True,False,"Not enough information"},reason∈S}\{ \text{is\_valid} \in \{\text{True}, \text{False}, \text{"Not enough information"}\}, \text{reason} \in \mathbb{S} \}{is_valid∈{True,False,"Not enough information"},reason∈S}。
目标函数:最大化验证准确率,最小化外部知识检索成本。
评测目标:准确率(Acc)、精确率(P)、召回率(R)、F1 分数(F1)。
创新点
-
灵活上下文集成框架:支持三种上下文源(LLM 内部知识、用户文档、外部知识代理),无需黄金标注即可验证任意 KG。
- 实现方式:通过 Instructor 库和 Pydantic 类约束 LLM 输出结构,确保验证结果可解析。
- 有效性:外部上下文(如 Wikidata)显著提升准确率(如 CoDeX-S-150 从 0.54 到 0.91)。
-
零样本验证协议:无需训练即可适配不同 KG 和知识源,通过通用提示词实现跨数据集验证。
- 实现方式:固定提示词模板(附录图 6),避免过拟合。
- 有效性:在 5 个基准数据集上均取得竞争性结果。
-
结构化输出验证:利用 Pydantic 模型强制 LLM 输出标准化字段(is_valid, reason),支持自动化评估流水线。
- 实现方式:通过 Instructor 库修补 LLM API,请求结构化 JSON 响应。
- 有效性:确保输出可机器解析,降低后处理复杂度。
方法与核心思路
整体框架
步骤分解
- 三元组输入:从 KG 补全模型或数据集中流式读取候选三元组 (h,r,t)(h, r, t)(h,r,t)。
- 上下文选择:根据配置选择上下文源(无上下文、文本、Wikidata、网络搜索或混合)。
- 知识检索(若需要):
- 文本语料:将三元组字符串化为查询,通过向量索引(cosine 相似度)检索相关片段。
- Wikidata:以主题实体字符串查询 Wikidata API,过滤无关属性(如外部数据库标识符)。
- 网络搜索:通过 DuckDuckGo API 获取网页结果,解析为文本集合。
- LLM 验证:将三元组和检索到的上下文输入 LLM,请求结构化验证结果。
- 输出解析:通过 Pydantic 模型解析 LLM 响应,提取
is_valid和reason字段。
模块与交互
- 验证器核心:基于 Instructor 库封装 LLM API,支持 GPT 系列和开源模型(如 Llama-2)。
- 知识代理模块:负责与外部知识源(Wikidata API、搜索引擎)交互,返回文本化上下文。
- 索引管理模块:处理文本语料的分块、编码(Sentence-BERT 或 OpenAI embeddings)和向量检索。
- 输出规范化模块:使用 Pydantic 类
ValidatedTriple定义输出 schema,确保结构一致性。
公式与符号
- 三元组表示:t=(h,r,t)t = (h, r, t)t=(h,r,t),其中 h,t∈Eh, t \in \mathcal{E}h,t∈E(实体集),r∈Rr \in \mathcal{R}r∈R(关系集)。
- 向量检索相似度:sim(q,d)=cos(E(q),E(d))\text{sim}(q, d) = \cos(\mathbf{E}(q), \mathbf{E}(d))sim(q,d)=cos(E(q),E(d)),其中 E\mathbf{E}E 为嵌入模型,qqq 为查询字符串,ddd 为文档块。
- 验证函数:f(t,C)→{True,False,Unknown}f(t, C) \rightarrow \{\text{True}, \text{False}, \text{Unknown}\}f(t,C)→{True,False,Unknown},其中 CCC 为上下文集合。
伪代码
function validate_triple(triple, context_source):
if context_source == "text":
context = retrieve_from_text_index(triple)
elif context_source == "wikidata":
entity = query_wikidata(triple.subject)
context = filter_trivial_properties(entity)
elif context_source == "web":
results = duckduckgo_search(triple_to_query(triple))
context = parse_results(results)
else:
context = None
prompt = build_prompt(triple, context)
response = llm_completion(prompt, response_model=ValidatedTriple)
return response.is_valid, response.reason
伪代码描述:根据上下文源检索相关信息,构建提示词并调用 LLM 生成结构化验证结果。
复杂度分析
- 时间复杂度:单次验证耗时取决于 LLM 生成延迟(GPT-3.5: ~1-2s/条)和检索开销(向量检索: O(logN)O(\log N)O(logN),Wikidata API: ~100ms/次)。
- 空间复杂度:主要开销为向量索引(文本语料)和 LLM 显存(开源模型需 2×A100 GPU)。
- 资源开销:GPT-4 API 成本较高(实验用 150 条/数据集),开源模型需本地部署。
关键设计选择
- Pydantic 结构化输出:确保机器可解析性,避免自由文本后处理复杂度。
- 零样本提示设计:通用提示词避免数据集过拟合,增强框架泛化性。
- 混合上下文策略:优先使用结构化知识(Wikidata),失败时降级至内部知识或网络搜索。
实验设置
数据集:
- FB15K-237N-150、Wiki27K-150、WN18RR-150、UMLS-150、CoDeX-S-150(各 150 条样本)。
- 统计特征:FB15K-237N 源自 Freebase,Wiki27K 来自 Wikidata 含真实负例,UMLS 为医学本体,WN18RR 为词法关系。
对比基线:
- 内部知识(WorldKnowledge)、Wikidata、Web、WikidataWeb、WikipediaWikidata 五种上下文配置。
- LLM 骨干:GPT-3.5-turbo-0125 和 GPT-4-0125-preview(主实验),Llama-2-70B-chat(附录)。
评价指标:准确率(Acc)、精确率(P)、召回率(R)、F1 分数(F1)。
实现细节:
- 框架:Instructor + Pydantic,向量索引用 Sentence-BERT。
- 硬件:GPT 系列通过 API,Llama-2 用 2×A100 GPU。
- 超参数:temperature=0,max_retries=3,提示词固定(附录图 6)。
- 随机性:种子未说明。
实验结果与分析
主结果与消融实验
下表汇总主要实验结果(最佳值加粗):
| 模型 | FB15K-237N-150 (Acc/P/R/F1) | Wiki27K-150 (Acc/P/R/F1) | WN18RR-150 (Acc/P/R/F1) | UMLS-150 (Acc/P/R/F1) | CoDeX-S-150 (Acc/P/R/F1) |
|---|---|---|---|---|---|
| GPT-3.5 WorldKnowledge | 0.63/0.58/0.97/0.73 | 0.71/0.63/1.0/0.77 | 0.58/0.54/0.97/0.70 | 0.50/0.5/0.97/0.66 | 0.54/0.52/0.97/0.68 |
| GPT-3.5 Wikidata | 0.76/0.75/0.77/0.76 | 0.74/0.74/0.73/0.74 | 0.56/0.53/0.99/0.69 | 0.52/0.51/0.87/0.64 | 0.87/0.86/0.88/0.87 |
| GPT-3.5 WikidataWeb | 0.82/0.82/0.81/0.82 | 0.81/0.78/0.87/0.82 | 0.76/0.69/0.95/0.80 | 0.50/0.5/0.88/0.64 | 0.91/0.87/0.97/0.92 |
| GPT-4 WorldKnowledge | 0.81/0.87/0.72/0.79 | 0.86/0.95/0.76/0.84 | 0.95/0.99/0.92/0.95 | 0.59/0.57/0.77/0.66 | 0.85/0.87/0.81/0.84 |
| GPT-4 WikidataWeb | 0.83/0.92/0.72/0.81 | 0.89/1.0/0.77/0.87 | 0.94/1.0/0.88/0.94 | 0.57/0.56/0.64/0.60 | 0.89/0.93/0.85/0.89 |
关键发现:
- GPT-4 普遍优于 GPT-3.5,尤其在 WN18RR 上(Acc 0.95 vs 0.58)因语言理解更强。
- 外部上下文提升显著:CoDeX-S-150 上 GPT-3.5 WikidataWeb 比 WorldKnowledge 的 Acc 提升 0.37。
- UMLS 表现最差(所有模型 Acc<0.64),因医学知识需要专业上下文。
- 开源模型 Llama-2-70B 失败:总返回 is_valid=True(P≈0.5, R=1.0),缺乏推理能力(见附录图11-12)。
误差分析与失败案例
错误类别:
- 模糊三元组:如 UMLS 的
("age_group", "performs", "social_behavior")需本体知识,外部上下文无效。 - 领域特异性:医学三元组
("research_device", "causes", "anatomical_abnormality")缺乏专业来源。 - LLM 幻觉:Llama-2 在上下文明确时仍生成错误验证(如图11混淆 “film producer” 和 “record producer”)。
边界条件:
- 实体别名歧义(如 “Ricky Jay” 可能指多人)时检索错误上下文。
- 网络搜索结果包含矛盾信息时,LLM 可能无法权衡证据。
复现性清单
代码/数据:因 IP 限制未公开,但支持联系作者复现。
环境依赖:Instructor 库、Pydantic、OpenAI API 或 llama-cpp-python(开源模型)。
运行命令:未提供。
许可证:未说明。
结论与未来工作
可推广性:框架适用于任意 KG 和知识源,尤其适合通用领域(如 Wikidata 更新)。
后续方向:
- 支持更多开源模型(如 Mixtral、Gemma)。
- 融合图谱结构特征提升领域适配性。
- 探索微调方案专用于 KG 验证任务。
- 扩展至知识图谱构建流水线(从文本到 KG 的端到端验证)。
时间表:未明确。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 18
18 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)