技术解码|特征提取(一):高频词vs关键词
摘要:特征提取是将文本数据转换为机器可处理的数值特征的关键步骤,包括词频统计、向量表示和语言结构分析等方法。其作用是降低维度、提取有效信息,使文本可计算。与分词不同,特征提取更注重数值转换。高频词提取和关键词提取(如TF-IDF、TextRank)是常见方法,工具如tatools提供可视化操作界面实现这些功能。特征提取直接影响模型性能,是文本分析的重要预处理环节。(148字)
特征提取(Feature Extraction)是指从非结构化的原始文本数据中提取有意义的、可量化的信息,也即“特征”,以便后续模型的理解和处理。
为什么要提取特征?
-
特征提取是完成预处理、开始文本分析的第一步。实施特征提取的主要原因有:
-
使机器理解文本:算法模型的输入必须是数值型数据。原始文本字符串无法直接用于数学计算,必须转换为数值特征,如词频、向量。
-
降低维度:文本是“高维”数据,会导致模型训练过程缓慢,而且容易过拟合。特征提取可以选择或构建出更有代表性、更低维度的特征,减少计算复杂度,提高模型性能。
-
提取有效信息: 文本中并非所有词语都很重要。比如,情感分析里,“开心”“失望”比“的”“是”“一个”这类停用词更重要。可以通过特征提取过滤出重点信息,去除噪声。
特征提取vs分词
分词是预处理阶段的准备工作,是所有文本分析的基础,目的是将文本“切碎”成有意义的基本单元。特征提取的重点在于转换,将文本转换成机器可以计算的数值。二者的的关系是分词是特征提取的前置步骤。
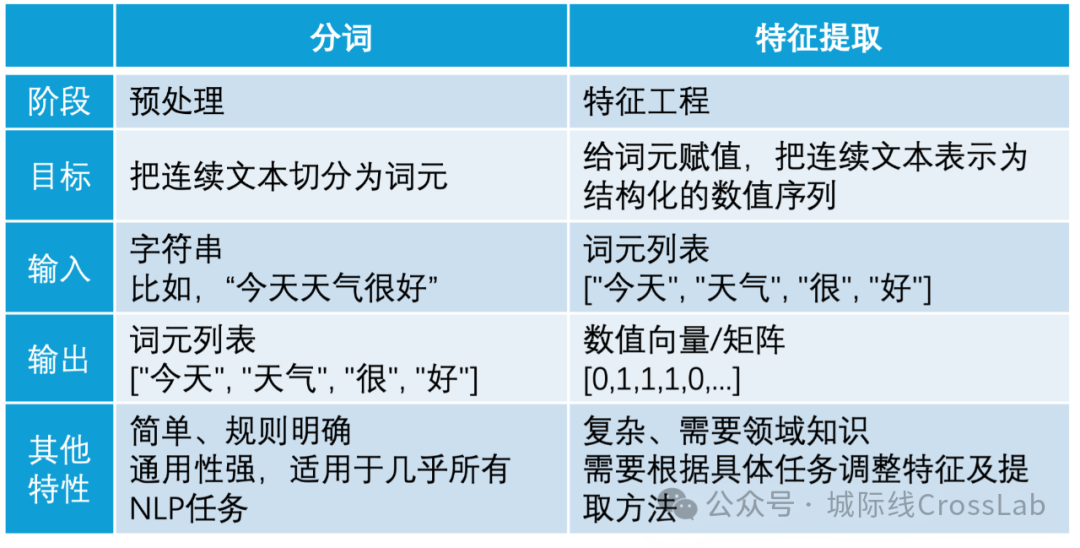
分词与特征提取的区别

分词与特征提取的示例
常见的特征提取思路
-
基于词频统计的特征提取。统计词在文本中的出现频率,频率越高,词越重要。适用于文本初步分析和主题识别。常用方法有高频词提取、关键词提取、词袋模型、N-gram模型等。
-
基于向量表示的特征提取。将文本映射到连续向量空间中,语义相近的词在向量空间中的距离相近。适用于语义相似度计算、文本分类、聚类分析。常用方法有Word2Vec、FastText、Doc2Vec等。
-
基于语言结构的特征提取。根据语法结构和规则分析词与词之间的语法依赖关系,据此提取特征。适用于关系识别,比如主体-对象关系识别、因果关系识别。常用方法有成分句法分析、依存句法分析、语义角色标注等。
特征提取的基本方法:高频词vs关键词
-
高频词提取的思路最简单,仅统计词的出现次数,取频率最高的词。该方法完全依赖词频,没有任何权重调整,所以,很容易提出高频但意义较小的词。
-
关键词提取的思路是在计算频率的基础上增加部分权重,提取出重要的词。常见的关键词提取算法有TF-IDF和TextRank。TF-IDF的提取思路是同时考虑词频(TF)和逆文档频率(IDF),降低常见词的权重。该方法擅长发现能够将当前文档与其他文档区分开来的标识词。TextRank则是将文本建模为词图,通过PageRank算法计算词的重要性。该方法的提取逻辑在于根据词关联度而不是词频率来判断一个词是否重要,所以,该方法无需依赖语料库,哪怕是单篇专业文本,也能有效发现其中的关键词。
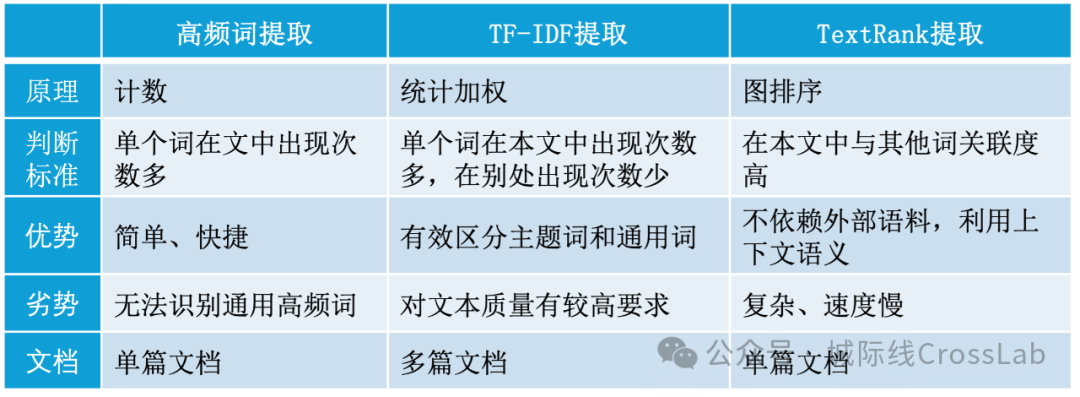
高频词提取与TF-IDF、TextRank提取的区别
- END -
在tatools中提取高频词/关键词:可视化操作指南
1. 在tatools中提取高频词
在标准文本处理模块中,选择高频词提取(high-frequency-words)。由于提取规则很简单,所以额外增加了5个可调节参数,以提高提取精度。
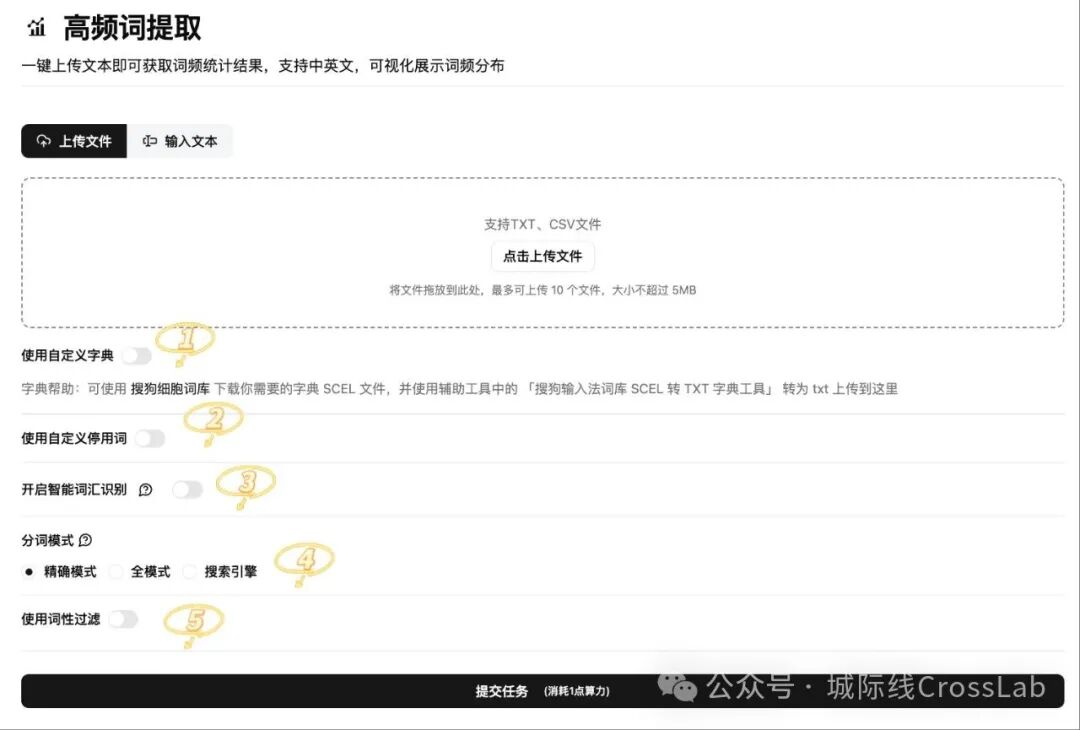
高频词提取的交互界面

高频词提取的结果
2. 在TAT中提取关键词
在标准文本处理模块中,选择关键词抽取(extract-keywords)。平台已经内置了TF-IDF和TextRank算法,所以无需再调节任何参数。直接上传待处理文档并点击提交任务,即可。
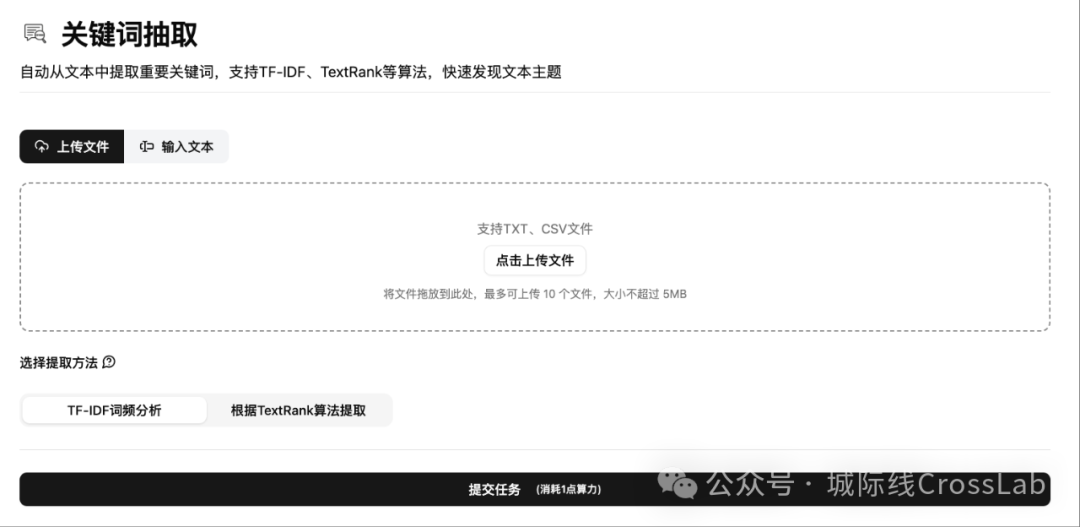
关键词提取的交互界面
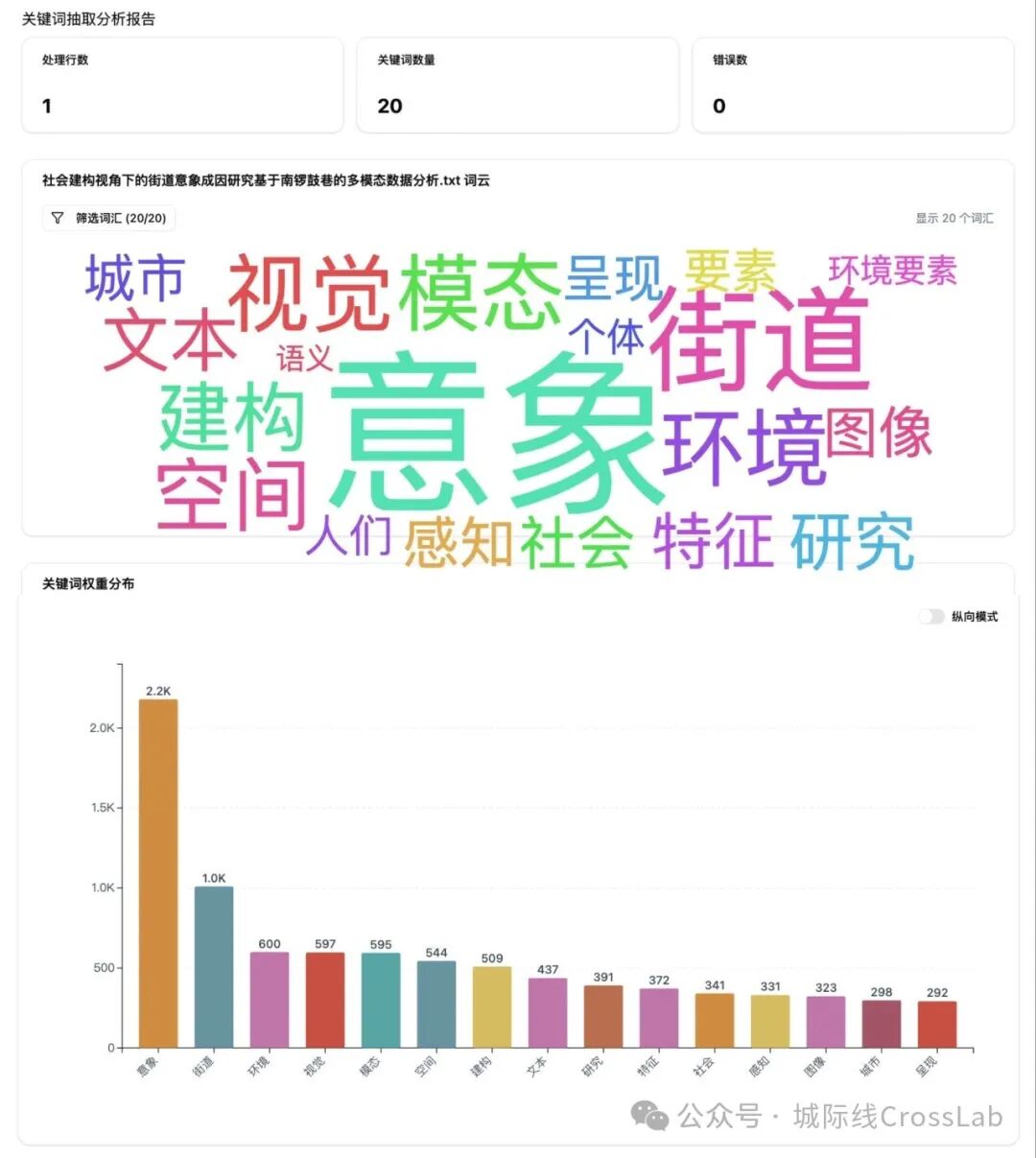
使用TF-IDF算法提取关键词的结果
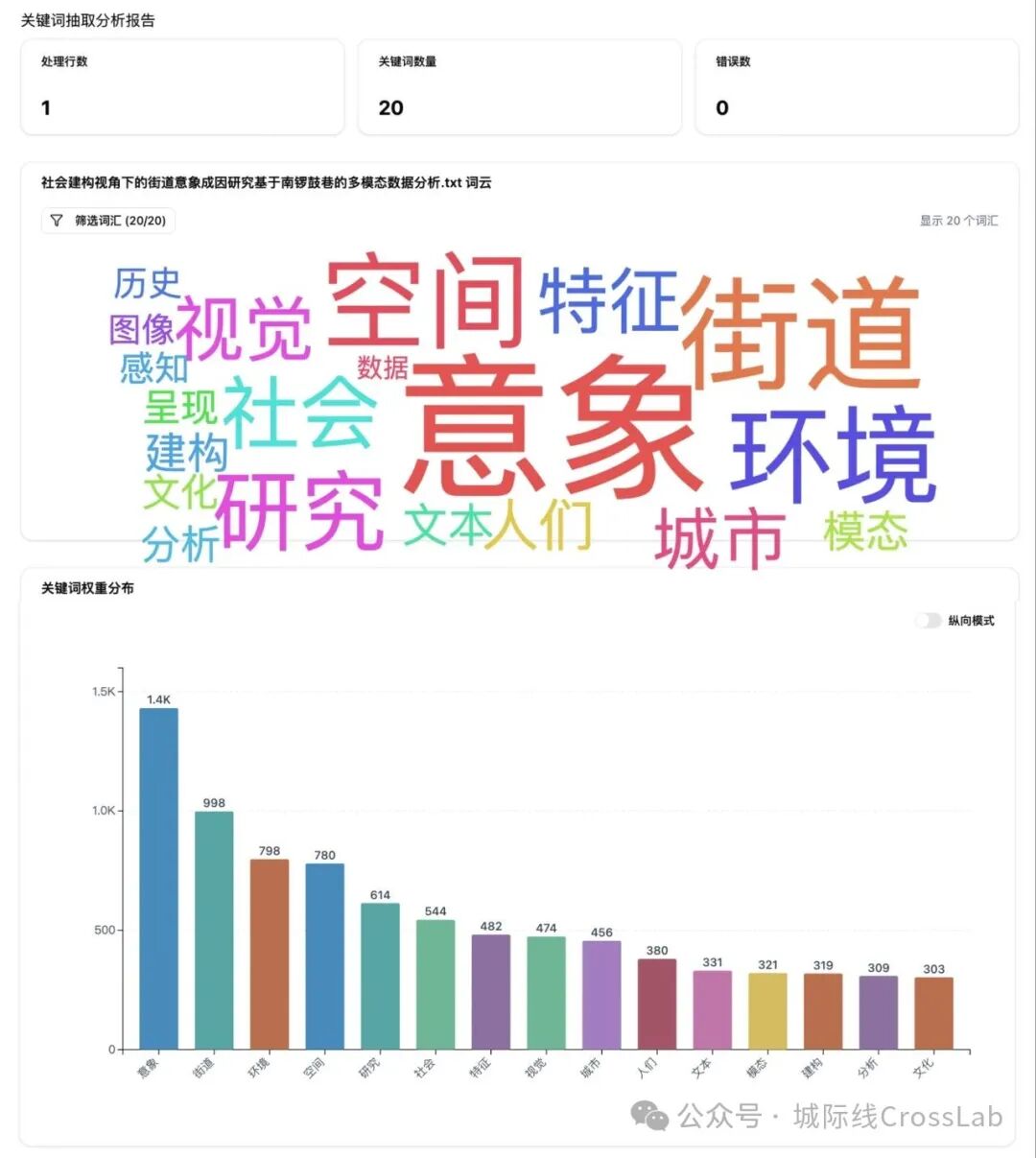
使用TextRank算法提取关键词的结果

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)