【GitHub项目推荐--Company Research Agent:多智能体公司研究工具】
简介
Company Research Agent 是一个基于LangGraph和Tavily的多智能体公司研究工具,专门用于进行深度公司尽职调查。它采用多智能体框架,后端使用Google Gemini 2.5 Flash和OpenAI GPT-4.1进行推理,提供全面的公司研究报告生成能力。
🔗 GitHub地址:
https://github.com/guy-hartstein/company-research-agent
🏢 核心价值:
公司研究 · 尽职调查 · 多智能体 · AI驱动 · 开源免费
项目背景:
-
研究需求:公司尽职调查需求增长
-
效率挑战:传统研究效率低下
-
数据分散:研究数据来源分散
-
AI技术:AI技术研究应用
-
开源缺失:开源研究工具缺失
项目特色:
-
🤖 多智能体:多智能体协作框架
-
🔍 深度研究:深度公司尽职调查
-
⚡ 高效处理:高效数据处理能力
-
📊 全面报告:全面研究报告生成
-
🌐 多源数据:多数据源集成
技术亮点:
-
LangGraph:智能体编排框架
-
Tavily集成:研究API集成
-
双模型架构:Gemini+GPT双模型
-
实时流式:实时进度流式传输
-
模块化设计:模块化架构设计
主要功能
1. 核心功能体系
Company Research Agent提供了一套完整的公司研究解决方案,涵盖多源研究、智能体协作、数据处理、报告生成、实时通信、内容筛选、模型推理、进度监控、结果分析、配置管理、部署支持、扩展集成等多个方面。
研究智能体功能:
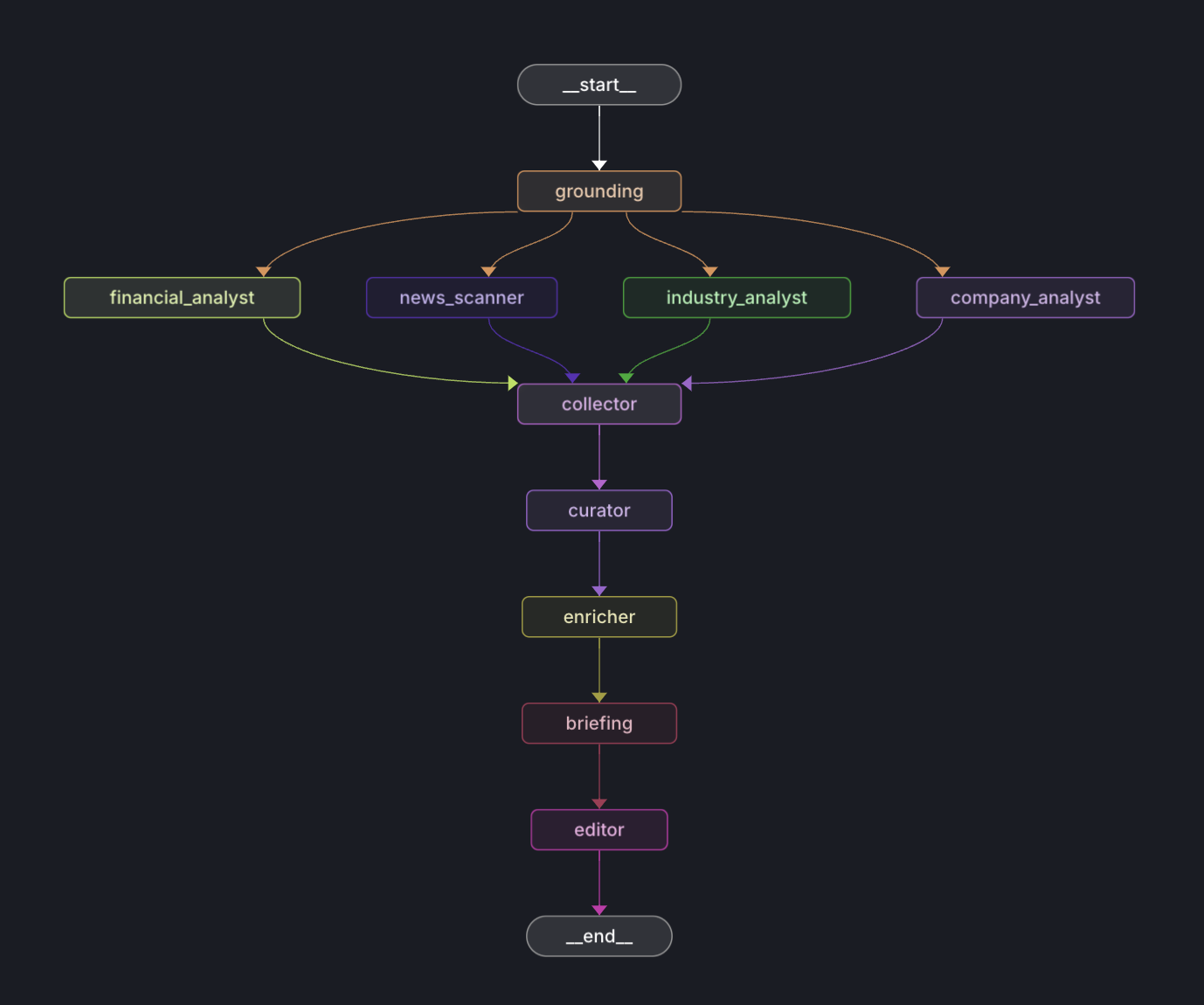
智能体体系:
- CompanyAnalyzer: 公司基础分析智能体
- IndustryAnalyzer: 行业分析智能体
- FinancialAnalyst: 财务分析智能体
- NewsScanner: 新闻扫描智能体
- 协作机制: 多智能体协作机制
分析能力:
- 业务分析: 核心业务分析
- 市场分析: 市场地位分析
- 财务分析: 财务状况分析
- 新闻分析: 新闻事件分析
- 竞争分析: 竞争环境分析
研究深度:
- 基础信息: 公司基本信息
- 深度洞察: 深度业务洞察
- 趋势分析: 行业趋势分析
- 风险识别: 风险因素识别
- 机会发现: 发展机会发现多源研究功能:
数据来源:
- 公司网站: 官方网站信息
- 新闻媒体: 新闻媒体报道
- 财务报告: 财务报告数据
- 行业分析: 行业分析报告
- 公开数据: 公开数据源
采集能力:
- 自动采集: 自动数据采集
- 多源整合: 多源数据整合
- 实时更新: 实时数据更新
- 质量验证: 数据质量验证
- 去重处理: 数据去重处理
研究范围:
- 基本信息: 公司基础信息
- 业务模式: 业务模式分析
- 财务状况: 财务健康状况
- 市场地位: 市场竞争地位
- 发展前景: 未来发展前景内容处理功能:
处理能力:
- 内容筛选: 智能内容筛选
- 相关性评分: 内容相关性评分
- 质量评估: 内容质量评估
- 去重处理: 内容去重处理
- 标准化: 内容标准化处理
筛选机制:
- 评分阈值: 相关性评分阈值
- 质量阈值: 质量评估阈值
- 自动过滤: 自动过滤低质内容
- 手动调整: 手动调整筛选条件
- 优先级: 内容优先级排序
处理流程:
- 原始采集: 原始数据采集
- 初步筛选: 初步内容筛选
- 深度处理: 深度内容处理
- 质量验证: 最终质量验证
- 结果输出: 处理结果输出2. 高级功能
双模型推理功能:
模型架构:
- Gemini 2.5 Flash: 研究推理模型
- GPT-4.1: 报告生成模型
- 分工协作: 模型分工协作
- 优势互补: 优势互补设计
- 性能优化: 性能优化配置
Gemini角色:
- 研究合成: 研究内容合成
- 深度分析: 深度分析推理
- 上下文处理: 长上下文处理
- 多文档分析: 多文档分析
- 洞察生成: 深度洞察生成
GPT角色:
- 报告生成: 最终报告生成
- 格式优化: 报告格式优化
- 一致性维护: 内容一致性
- 语言优化: 语言表达优化
- 结构调整: 报告结构调整
协作流程:
- 研究阶段: Gemini处理研究
- 生成阶段: GPT生成报告
- 质量保证: 双模型质量保证
- 效率优化: 分工效率优化
- 效果提升: 最终效果提升实时流式功能:
流式能力:
- 实时进度: 实时进度更新
- 状态推送: 状态实时推送
- 结果流式: 结果流式输出
- 错误实时: 错误实时报告
- 性能监控: 性能实时监控
通信机制:
- WebSocket: WebSocket通信
- 持久连接: 持久连接维护
- 状态管理: 连接状态管理
- 错误处理: 通信错误处理
- 重连机制: 自动重连机制
消息类型:
- 进度更新: 研究进度更新
- 结果片段: 结果片段推送
- 状态变更: 状态变更通知
- 错误报告: 错误报告通知
- 完成通知: 任务完成通知
前端集成:
- 实时显示: 前端实时显示
- 进度条: 进度条显示
- 状态指示: 状态指示器
- 结果预览: 结果实时预览
- 用户体验: 良好用户体验报告生成功能:
生成能力:
- 自动生成: 自动报告生成
- 结构化: 结构化报告
- 多章节: 多章节组织
- 可视化: 数据可视化
- 导出功能: 多种格式导出
报告内容:
- 执行摘要: 报告执行摘要
- 公司概述: 公司基本概述
- 业务分析: 业务模式分析
- 财务分析: 财务状况分析
- 市场分析: 市场竞争分析
- 风险分析: 风险因素分析
- 机会分析: 发展机会分析
- 结论建议: 结论与建议
格式支持:
- Markdown: Markdown格式
- HTML: HTML网页格式
- PDF: PDF文档格式
- Word: Word文档格式
- 自定义: 自定义格式
质量特性:
- 一致性: 内容一致性
- 准确性: 信息准确性
- 完整性: 内容完整性
- 可读性: 良好可读性
- 专业性: 专业报告质量安装与配置
1. 环境准备
系统要求:
最低要求:
- 操作系统: Linux/macOS/Windows
- Python版本: Python 3.10+
- Node.js版本: Node.js 16+
- 内存: 8GB RAM
- 存储: 10GB可用空间
推荐要求:
- 操作系统: Ubuntu 20.04+
- Python版本: Python 3.11+
- Node.js版本: Node.js 18+
- 内存: 16GB+ RAM
- 存储: 20GB+ SSD空间
理想环境:
- 专用服务器: 研究专用服务器
- 高性能CPU: 多核高性能CPU
- 大内存: 32GB+ RAM
- 高速存储: NVMe SSD存储
- 高速网络: 高速网络连接
软件依赖:
- Python环境: 完整Python环境
- Node.js环境: Node.js运行环境
- 数据库: MongoDB(可选)
- 缓存系统: Redis(可选)
- 消息队列: RabbitMQ(可选)API密钥要求:
必需API密钥:
- Tavily API: Tavily研究API密钥
- Gemini API: Google Gemini API密钥
- OpenAI API: OpenAI API密钥
- Google Maps: Google Maps API密钥
可选API密钥:
- MongoDB: MongoDB连接字符串
- 其他数据源: 额外数据源API密钥
- 云服务: 云服务提供商密钥
- 监控服务: 监控服务密钥
密钥管理:
- 环境变量: 环境变量管理
- 安全存储: 安全密钥存储
- 权限控制: 密钥权限控制
- 轮换策略: 密钥轮换策略
- 监控告警: 密钥使用监控2. 安装步骤
快速安装:
# 1. 克隆仓库
git clone https://github.com/guy-hartstein/company-research-agent.git
cd company-research-agent
# 2. 运行安装脚本
chmod +x setup.sh
./setup.sh
# 3. 配置环境变量
# 编辑后端.env文件
cp .env.example .env
# 编辑前端环境变量
cp ui/.env.development.example ui/.env
# 4. 启动服务
# 后端启动
python -m application.py
# 或
uvicorn application:app --reload --port 8000
# 前端启动
cd ui
npm run devDocker安装:
# 1. 克隆仓库
git clone https://github.com/guy-hartstein/company-research-agent.git
cd company-research-agent
# 2. 配置环境变量
cp .env.example .env
cp ui/.env.development.example ui/.env
# 3. 构建和启动
docker-compose up --build
# 4. 访问服务
# 后端: http://localhost:8000
# 前端: http://localhost:5173手动安装:
# 1. 克隆仓库
git clone https://github.com/guy-hartstein/company-research-agent.git
cd company-research-agent
# 2. 安装后端依赖
# 使用uv(推荐)
uv venv .venv
source .venv/bin/activate
uv pip install -r requirements.txt
# 或使用pip
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
# 3. 安装前端依赖
cd ui
npm install
# 4. 环境配置
# 后端配置
cp .env.example .env
# 编辑.env文件添加API密钥
# 前端配置
cp .env.development.example .env
# 编辑.env文件配置前端设置
# 5. 启动服务
# 后端启动
python -m application.py
# 前端启动(新终端)
npm run dev验证安装:
# 检查Python环境
python --version
pip list
# 检查Node.js环境
node --version
npm --version
# 检查后端服务
curl http://localhost:8000/health
# 检查前端服务
curl http://localhost:5173
# 检查API密钥
python -c "
import os
print('Tavily API:', 'OK' if os.getenv('TAVILY_API_KEY') else 'Missing')
print('Gemini API:', 'OK' if os.getenv('GEMINI_API_KEY') else 'Missing')
print('OpenAI API:', 'OK' if os.getenv('OPENAI_API_KEY') else 'Missing')
"3. 配置说明
后端配置:
# 后端环境配置
BACKEND_CONFIG = {
"api": {
"host": "0.0.0.0",
"port": 8000,
"debug": False,
"workers": 4,
"timeout": 300,
},
"database": {
"mongodb_uri": "mongodb://localhost:27017",
"database_name": "company_research",
"collection_prefix": "research_",
},
"processing": {
"max_workers": 8,
"timeout": 600,
"retry_attempts": 3,
"batch_size": 100,
},
"security": {
"cors_origins": ["http://localhost:5173"],
"rate_limit": "100/minute",
"api_key_required": True,
}
}模型配置:
# AI模型配置
MODEL_CONFIG = {
"gemini": {
"model_name": "gemini-2.0-flash",
"api_key": os.getenv("GEMINI_API_KEY"),
"temperature": 0.7,
"max_tokens": 8192,
"timeout": 120,
},
"openai": {
"model_name": "gpt-4.1-mini",
"api_key": os.getenv("OPENAI_API_KEY"),
"temperature": 0.3,
"max_tokens": 4096,
"timeout": 90,
},
"tavily": {
"api_key": os.getenv("TAVILY_API_KEY"),
"search_depth": "advanced",
"timeout": 60,
"max_results": 50,
}
}研究配置:
# 研究任务配置
RESEARCH_CONFIG = {
"defaults": {
"depth": "comprehensive",
"sources": ["web", "news", "financial"],
"timeframe": "5years",
"max_documents": 100,
"min_relevance": 0.4,
},
"categories": {
"company_analysis": {
"enabled": True,
"priority": "high",
"sources": ["web", "news"],
},
"industry_analysis": {
"enabled": True,
"priority": "medium",
"sources": ["web", "reports"],
},
"financial_analysis": {
"enabled": True,
"priority": "high",
"sources": ["financial", "reports"],
},
"news_analysis": {
"enabled": True,
"priority": "medium",
"sources": ["news", "social"],
}
}
}前端配置:
// 前端环境配置
const FRONTEND_CONFIG = {
api: {
baseURL: import.meta.env.VITE_API_URL || 'http://localhost:8000',
wsURL: import.meta.env.VITE_WS_URL || 'ws://localhost:8000',
timeout: 30000,
},
features: {
realTimeUpdates: true,
progressTracking: true,
reportExport: true,
multiCompany: true,
history: true,
},
ui: {
theme: 'dark',
language: 'en',
pageSize: 10,
autoSave: true,
}
};使用指南
1. 基本工作流
使用Company Research Agent的基本流程包括:环境准备 → 安装配置 → 启动服务 → 创建研究 → 监控进度 → 查看结果 → 导出报告 → 分析应用 → 保存分享 → 清理维护。
2. 基本使用
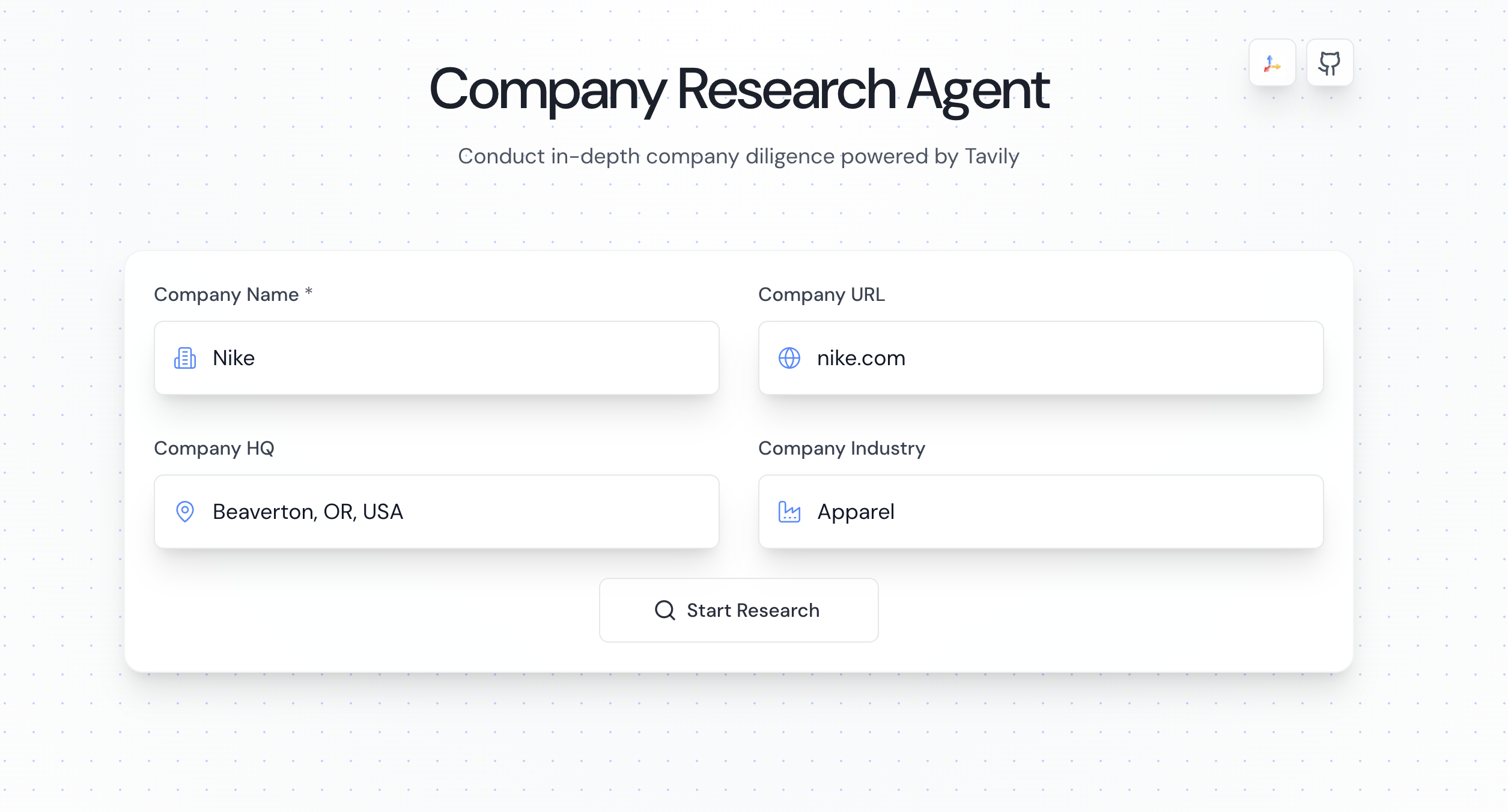
Web界面使用:
使用步骤:
1. 访问界面: 打开Web界面
2. 输入公司: 输入要研究的公司名称
3. 配置选项: 配置研究选项(可选)
4. 开始研究: 点击开始研究按钮
5. 监控进度: 实时监控研究进度
6. 查看结果: 查看生成的研究报告
7. 导出报告: 导出报告到各种格式
8. 保存分享: 保存或分享研究报告
界面功能:
- 公司输入: 公司名称输入框
- 配置面板: 研究配置选项
- 进度显示: 实时进度显示
- 结果展示: 研究报告展示
- 导出选项: 报告导出选项
- 历史记录: 研究历史记录
实时特性:
- 进度条: 研究进度条
- 状态更新: 实时状态更新
- 结果流式: 结果流式显示
- 错误提示: 实时错误提示
- 完成通知: 任务完成通知API接口使用:
API端点:
- POST /research: 创建研究任务
- GET /research/{job_id}: 获取研究状态
- GET /research/{job_id}/report: 获取研究报告
- GET /research/history: 获取研究历史
- DELETE /research/{job_id}: 删除研究任务
请求示例:
# 创建研究任务
curl -X POST "http://localhost:8000/research" \
-H "Content-Type: application/json" \
-d '{"company": "Apple Inc.", "depth": "comprehensive"}'
# 获取研究状态
curl "http://localhost:8000/research/{job_id}"
# 获取研究报告
curl "http://localhost:8000/research/{job_id}/report"
WebSocket连接:
# WebSocket连接研究进度
const ws = new WebSocket('ws://localhost:8000/research/ws/{job_id}')
响应格式:
{
"status": "completed",
"progress": 100,
"result": {
"report": "研究报告内容",
"metadata": {...}
}
}命令行使用:
命令行工具:
# 安装CLI工具
pip install company-research-cli
# 基本使用
company-research "Apple Inc."
# 带选项使用
company-research "Apple Inc." --depth comprehensive --output report.md
# 批量处理
company-research-batch companies.txt --output-dir ./reports
# 配置管理
company-research-config set api_key YOUR_API_KEY
company-research-config show
命令选项:
--depth: 研究深度(quick/standard/comprehensive)
--output: 输出文件路径
--format: 输出格式(markdown/html/pdf)
--sources: 数据源限制
--timeframe: 时间范围
输出格式:
- Markdown: Markdown格式报告
- HTML: HTML网页格式
- PDF: PDF文档格式
- JSON: 原始JSON数据
- CSV: CSV数据格式3. 高级用法
批量研究使用:
批量场景:
- 投资组合: 投资组合公司研究
- 竞争分析: 竞争对手批量分析
- 行业研究: 行业公司研究
- 监控列表: 监控列表公司研究
- 定期更新: 定期批量更新研究
批量配置:
- 输入文件: 公司列表文件
- 输出目录: 结果输出目录
- 并发控制: 并发任务数量
- 错误处理: 批量错误处理
- 进度跟踪: 批量进度跟踪
管理功能:
- 任务队列: 批量任务队列
- 优先级管理: 任务优先级
- 资源控制: 资源使用控制
- 结果聚合: 结果聚合分析
- 报告生成: 批量报告生成
优化策略:
- 并行处理: 多任务并行处理
- 缓存利用: 研究缓存利用
- 去重优化: 重复内容去重
- 资源优化: 资源使用优化
- 性能监控: 性能监控调整自定义研究使用:
自定义能力:
- 研究模板: 自定义研究模板
- 数据源配置: 自定义数据源
- 分析维度: 自定义分析维度
- 报告格式: 自定义报告格式
- 工作流定制: 自定义工作流
配置选项:
- 深度定制: 研究深度定制
- 源选择: 数据源选择
- 时间范围: 时间范围设置
- 过滤条件: 内容过滤条件
- 输出格式: 输出格式定制
扩展功能:
- 插件系统: 插件扩展系统
- API扩展: API功能扩展
- 数据源扩展: 自定义数据源
- 分析扩展: 自定义分析模块
- 输出扩展: 自定义输出格式
开发支持:
- SDK开发: 开发SDK支持
- 文档支持: 开发文档
- 示例代码: 示例代码库
- 测试工具: 测试工具支持
- 调试支持: 调试工具支持集成开发使用:
集成方式:
- API集成: REST API集成
- WebSocket集成: 实时集成
- SDK集成: SDK库集成
- 插件集成: 插件系统集成
- 数据集成: 数据流集成
开发接口:
- 研究接口: 研究任务接口
- 数据接口: 研究数据接口
- 报告接口: 报告生成接口
- 管理接口: 系统管理接口
- 监控接口: 监控统计接口
应用场景:
- 投资平台: 投资研究平台集成
- 风控系统: 风险控制系统集成
- 商业智能: 商业智能平台集成
- 学术研究: 学术研究工具集成
- 新闻媒体: 媒体研究平台集成
最佳实践:
- 错误处理: 健全错误处理
- 性能优化: 集成性能优化
- 安全考虑: 安全集成考虑
- 监控告警: 集成监控告警
- 文档维护: 集成文档维护应用场景实例
案例1:投资尽职调查
场景:投资前公司尽职调查
解决方案:使用Company Research Agent进行投资尽职调查。
实施方法:
-
目标公司:输入目标公司名称
-
深度研究:选择深度研究模式
-
全面分析:进行全面分析研究
-
风险评估:识别投资风险
-
机会评估:评估投资机会
-
报告生成:生成尽职调查报告
-
投资决策:支持投资决策
投资价值:
-
效率提升:大幅提升研究效率
-
全面性:研究全面性保证
-
客观性:客观分析评估
-
风险识别:风险因素识别
-
决策支持:投资决策支持
案例2:竞争情报分析
场景:市场竞争情报分析
解决方案:使用Company Research Agent进行竞争分析。
实施方法:
-
竞争对手:输入竞争对手列表
-
批量研究:批量研究竞争对手
-
对比分析:进行对比分析
-
优势分析:分析竞争优势
-
策略建议:生成策略建议
-
监控设置:设置持续监控
-
报告分享:分享分析报告
竞争价值:
-
情报收集:高效情报收集
-
分析深度:深度分析能力
-
实时更新:情报实时更新
-
策略支持:竞争策略支持
-
优势保持:竞争优势保持
案例3:供应商评估
场景:供应商风险评估
解决方案:使用Company Research Agent评估供应商。
实施方法:
-
供应商列表:输入供应商名单
-
风险评估:进行风险评估
-
财务健康:评估财务健康
-
业务稳定:评估业务稳定性
-
合规检查:合规性检查
-
评级分类:供应商评级分类
-
管理报告:生成管理报告
供应链价值:
-
风险降低:供应链风险降低
-
效率提升:评估效率提升
-
标准化:评估标准统一
-
合规保证:合规性保证
-
关系优化:供应商关系优化
案例4:市场进入研究
场景:新市场进入研究
解决方案:使用Company Research Agent研究新市场。
实施方法:
-
目标市场:定义目标市场
-
公司研究:研究市场内公司
-
竞争格局:分析竞争格局
-
市场趋势:研究市场趋势
-
机会识别:识别市场机会
-
进入策略:制定进入策略
-
可行性报告:生成可行性报告
市场价值:
-
决策支持:市场进入决策支持
-
风险控制:进入风险控制
-
机会把握:市场机会把握
-
资源优化:资源优化配置
-
成功概率:提高成功概率
案例5:学术研究支持
场景:学术公司研究
解决方案:使用Company Research Agent支持学术研究。
实施方法:
-
研究主题:确定研究主题
-
公司样本:选择研究样本
-
数据收集:自动数据收集
-
分析处理:数据分析处理
-
研究发现:生成研究发现
-
论文支持:支持论文写作
-
数据引用:规范数据引用
学术价值:
-
研究效率:研究效率提升
-
数据质量:研究数据质量
-
方法规范:研究方法规范
-
可重复性:研究可重复性
-
学术贡献:学术贡献价值
总结
Company Research Agent作为一个强大的多智能体公司研究工具,通过其先进的技术架构和智能的研究能力,为各种公司研究需求提供了完整的解决方案。
核心优势:
-
🤖 多智能体:多智能体协作研究
-
🔍 深度研究:深度公司尽职调查
-
⚡ 高效处理:高效数据处理能力
-
📊 全面报告:专业研究报告生成
-
🌐 多源集成:多数据源集成能力
适用场景:
-
投资尽职调查
-
竞争情报分析
-
供应商评估
-
市场进入研究
-
学术研究支持
立即开始使用:
# 快速安装使用
git clone https://github.com/guy-hartstein/company-research-agent.git
cd company-research-agent
./setup.sh
# 或Docker部署
docker-compose up --build资源链接:
-
🌐 项目地址:GitHub仓库
-
📖 文档:详细使用文档
-
🎮 演示:在线演示地址
-
💬 社区:开发者社区
-
🔧 支持:技术支持渠道
通过Company Research Agent,您可以:
-
效率提升:大幅提升研究效率
-
质量保证:研究质量保证
-
深度洞察:获得深度洞察
-
决策支持:支持重要决策
-
成本降低:降低研究成本
特别提示:
-
🔑 API密钥:需要多个API密钥
-
💻 硬件要求:需要一定硬件资源
-
📚 学习使用:需要学习使用
-
🔒 数据安全:注意数据安全
-
📋 合规使用:合规使用数据
通过Company Research Agent,提升您的研究能力!
未来发展:
-
🚀 更多功能:持续功能增强
-
🤖 更智能:更智能的研究
-
🌐 更多数据源:更多数据源集成
-
🔧 更易用:更友好的用户体验
-
📊 更强分析:更强的分析能力
加入社区:
参与方式:
- GitHub: 提交问题和PR
- 社区讨论: 参与社区讨论
- 文档贡献: 贡献文档改进
- 功能测试: 参与功能测试
- 案例分享: 分享使用案例
社区价值:
- 技术支持帮助
- 问题解答支持
- 经验分享交流
- 功能需求反馈
- 项目发展推动通过Company Research Agent,共同推动智能研究发展!
许可证:Apache-2.0许可证
致谢:感谢所有贡献者和开源项目
免责声明:注意数据合规和隐私保护
通过Company Research Agent,负责任地进行公司研究!
成功案例:
用户群体:
- 投资机构: 风险投资和私募股权
- 企业战略: 企业战略部门
- 咨询公司: 管理咨询公司
- 学术机构: 大学和研究机构
- 政府部门: 政府监管机构
使用效果:
- 效率提升: 研究效率大幅提升
- 质量改善: 研究质量显著改善
- 成本降低: 研究成本显著降低
- 深度增加: 研究深度明显增加
- 满意度高: 用户满意度高最佳实践:
使用建议:
1. 从简单开始: 从简单研究开始
2. 逐步深入: 逐步使用高级功能
3. 验证结果: 重要结果验证
4. 合规使用: 注意合规使用
5. 社区学习: 向社区学习经验
避免问题:
- 数据合规: 注意数据合规性
- 隐私保护: 保护隐私信息
- 过度依赖: 避免过度依赖
- 结果验证: 重要结果验证
- 资源管理: 合理资源管理通过Company Research Agent,实现高效的公司研究!
资源扩展:
学习资源:
- 公司研究方法论
- 尽职调查知识
- 数据分析技能
- 行业分析知识
- 投资评估方法通过Company Research Agent,构建您的研究分析未来!
未来展望:
技术发展:
- 更好性能
- 更多功能
- 更强智能
- 更易使用
- 更集成化
应用发展:
- 更多场景
- 更好体验
- 更广应用
- 更深影响
- 更大价值
社区发展:
- 更多用户
- 更多贡献
- 更好文档
- 更多案例
- 更大影响通过Company Research Agent,迎接智能研究的未来!
结束语:
Company Research Agent作为一个创新的多智能体研究工具,正在改变人们进行公司研究的方式。通过合理利用这一工具,用户可以享受多智能体协作、深度研究和高效分析带来的好处。
记住,工具是扩展能力的手段,结合清晰的研究需求与合理的技术选择,共同成就研究卓越。
Happy researching with Company Research Agent! 🔍🚀📊
附录:常见问题解答
Q: 需要哪些API密钥?
A: 必需API密钥:
-
Tavily API: 研究数据API密钥
-
Gemini API: Google Gemini模型密钥
-
OpenAI API: OpenAI模型密钥
-
Google Maps API: 地图服务密钥(可选)
Q: 研究一个公司需要多长时间?
A: 研究时间因素:
-
研究深度: Quick(1-2分钟)/Standard(3-5分钟)/Comprehensive(5-10分钟)
-
公司规模: 大公司需要更长时间
-
数据可用性: 数据可获得性影响
-
网络速度: 网络连接速度
-
系统性能: 硬件性能影响
Q: 是否支持批量处理?
A: 批量处理支持:
-
公司列表: 支持批量公司列表
-
并发控制: 可控制并发数量
-
进度跟踪: 批量进度跟踪
-
结果聚合: 批量结果聚合
-
报告生成: 批量报告生成
Q: 数据来源有哪些?
A: 主要数据来源:
-
公司网站: 官方网站信息
-
新闻媒体: 新闻媒体报道
-
财务报告: 公开财务报告
-
行业报告: 行业分析报告
-
公开数据: 各种公开数据源
Q: 如何保证研究质量?
A: 质量保证措施:
-
多源验证: 多数据源交叉验证
-
智能筛选: AI智能内容筛选
-
质量评分: 内容质量评分系统
-
人工审核: 重要结果人工审核
-
持续改进: 质量持续改进机制
Q: 是否支持自定义研究模板?
A: 模板定制支持:
-
研究维度: 自定义研究维度
-
报告格式: 自定义报告格式
-
数据源: 自定义数据源
-
分析模型: 自定义分析模型
-
输出格式: 自定义输出格式
Q: 如何集成到现有系统?
A: 集成方式:
-
API集成: REST API集成
-
WebSocket: 实时数据流集成
-
SDK: 开发SDK集成
-
数据导出: 数据导出集成
-
插件系统: 插件架构集成
Q: 是否支持本地部署?
A: 部署支持:
-
本地部署: 完全本地部署支持
-
私有化: 支持私有化部署
-
数据隔离: 数据完全隔离
-
自定义: 高度自定义配置
-
安全增强: 安全增强配置
通过合理使用Company Research Agent,您可以高效地进行公司研究,享受智能研究工具带来的便利和深度洞察。无论是投资决策、竞争分析还是学术研究,这个工具都能为您提供强大的支持。
开始您的智能研究之旅吧! 🎯✨

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 11
11 0
0- 0



 已为社区贡献246条内容
已为社区贡献246条内容

所有评论(0)