调用阿里接口实现TTS生成
然后运行测试python tts.py。此时合成的语音会直接通过当前电脑播放。
·
创建测试文件tts.py:
# DashScope SDK 版本不低于 1.24.6
# coding=utf-8
import os
import dashscope
import pyaudio
import time
import base64
import numpy as np
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1
dashscope.base_http_api_url = 'https://dashscope.aliyuncs.com/api/v1'
p = pyaudio.PyAudio()
# 创建音频流
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=24000,
output=True)
text = "我是一个台湾女孩,说话机车,声音好听,习惯简短表达,爱用网络梗。我的男朋友是一个程序员,梦想是开发出一个机器人,能够帮助人们解决生活中的各种问题。我是一个喜欢哈哈大笑的女孩,爱东说西说吹牛,不合逻辑的也照吹,就要逗别人开心。"
response = dashscope.MultiModalConversation.call(
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key = "sk-xxx"
api_key="sk-xxx",
model="qwen3-tts-flash",
text=text,
voice="Cherry",
language_type="Chinese", # 建议与文本语种一致,以获得正确的发音和自然的语调。
stream=True
)
for chunk in response:
if chunk.output is not None:
audio = chunk.output.audio
if audio.data is not None:
wav_bytes = base64.b64decode(audio.data)
audio_np = np.frombuffer(wav_bytes, dtype=np.int16)
# 直接播放音频数据
stream.write(audio_np.tobytes())
if chunk.output.finish_reason == "stop":
print("finish at: {} ", chunk.output.audio.expires_at)
time.sleep(0.8)
# 清理资源
stream.stop_stream()
stream.close()
p.terminate()安装依赖包:
pip install pyaudio
pip install dashscope
然后运行测试python tts.py
此时合成的语音会直接通过当前电脑播放。
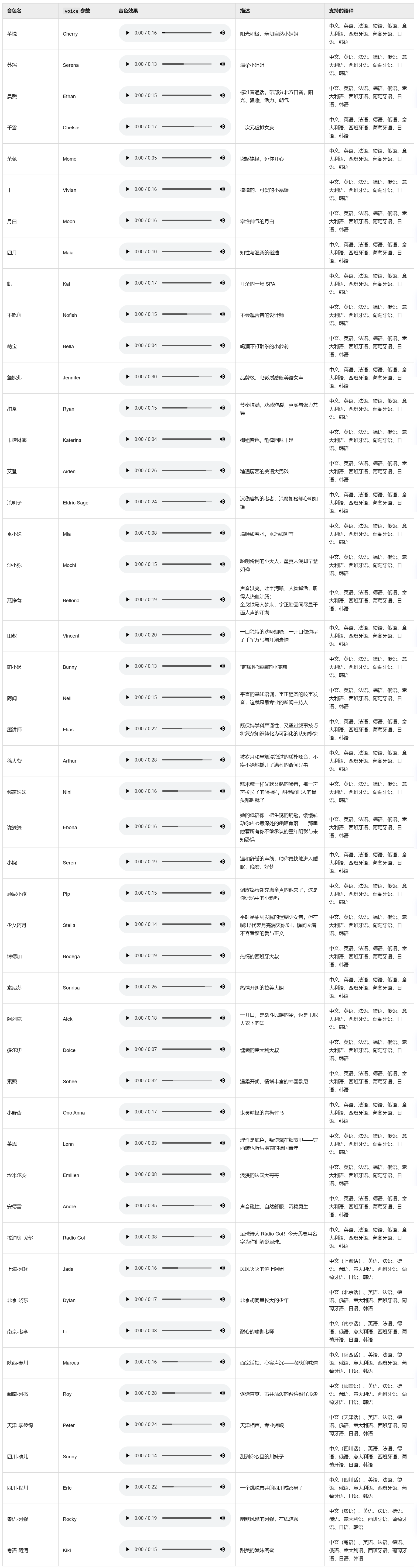
音色参数voice可以参考下图进行配置:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)