LongCat-Flash:美团出手,国产卡上跑出的「闪电级」大模型
最近,美团开源的 LongCat-Flash 彻底炸了 AI 圈。一方面,它用 国产算力 完成了一个 5600 亿参数的大模型训练;另一方面,它用一系列极具工程狠劲的设计,解决了很多 DeepSeek 一直头疼的系统级瓶颈。LongCat-Flash 可以说是一次真正懂大模型训练痛点的人干出来的技术工程奇迹。
最近,美团开源的 LongCat-Flash 彻底炸了 AI 圈。
一方面,它用 国产算力 完成了一个 5600 亿参数的大模型训练;另一方面,它用一系列极具工程狠劲的设计,解决了很多 DeepSeek 一直头疼的系统级瓶颈。LongCat-Flash 可以说是一次真正懂大模型训练痛点的人干出来的技术工程奇迹。
所有相关源码示例、流程图、面试八股、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!
一、LongCat-Flash 是什么?

LongCat-Flash 是一个 Mixture-of-Experts(MoE)混合专家大模型,总参数量高达 5600 亿,但每次推理只激活 18.6B–31.3B(平均 27B) 参数。
模型的核心目标很直接:“更快、更稳、更聪明,尤其是要能干 Agent 任务。”
在报告里,美团团队把它定位为兼具计算效率(Computational Efficiency)和智能行为能力(Agentic Capability)的双向突破。
二、核心创新
LongCat-Flash 的架构创新主要集中在两个点。
1. Zero-Computation Experts:计算预算动态分配
传统 MoE 的问题在于所有 token 都吃一样多的计算预算,浪费严重。LongCat-Flash 的做法很巧妙——引入 “零计算专家”。这些专家啥也不算(输入 = 输出),但在路由阶段参与决策,让模型能自己判断哪些 token 值得花更多算力。
核心逻辑就是“重要的 token 激活更多专家,不重要的 token 直接走零计算通道“。平均每个 token 激活 12 个专家,其中一部分是 “空转” 的。
这样做不仅大幅提高算力利用率,而且不浪费 GPU 通信时间(因为低权重 token 直接跳过)。
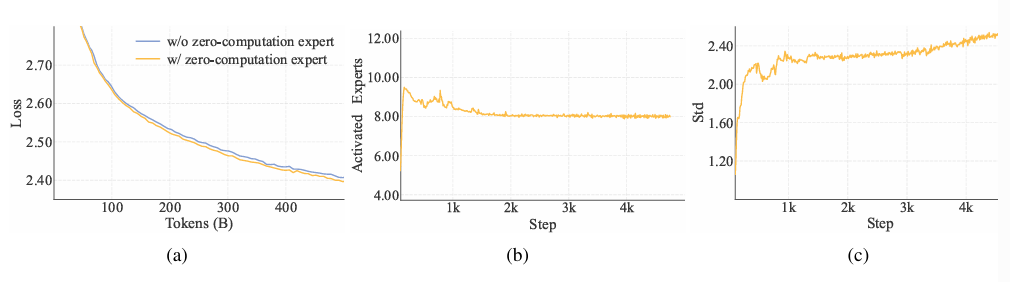
结果在报告里直接对比出来:在相同算力预算下,加入 Zero-Computation Expert 的模型 loss 曲线更低,训练收敛更快,推理更稳。
这一步,让 MoE 的“稀疏计算”真正变成了**“动态稀疏”**。
2. Shortcut-Connected MoE(ScMoE):通信与计算并行化
第二个创新,是让训练和推理都“跑得更顺”的关键。在大规模 MoE 模型里,通信延迟往往是最大瓶颈。每次路由都要先发数据再算,GPU 空跑。
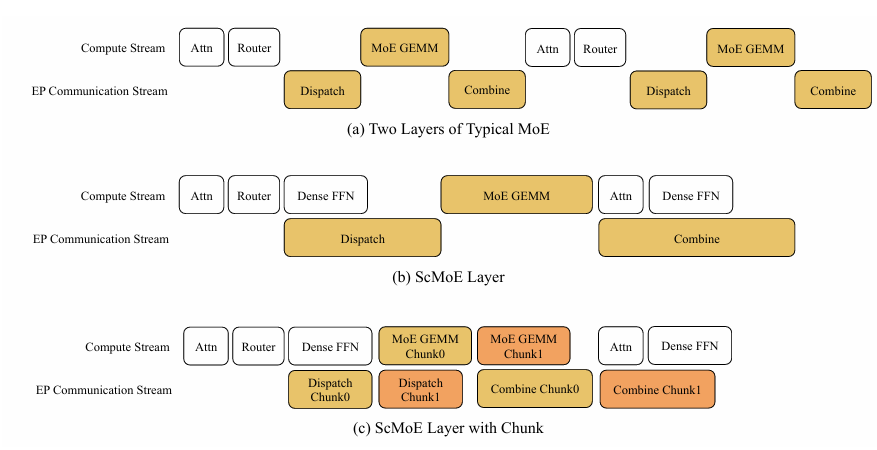
ScMoE 的想法是让上一层的 FFN 计算,与下一层的专家通信并行进行。这叫 Shortcut-Connected MoE。简单理解,就是在层间加了“捷径”,让前后两层的计算和通信互相交叠,从串行变并行。
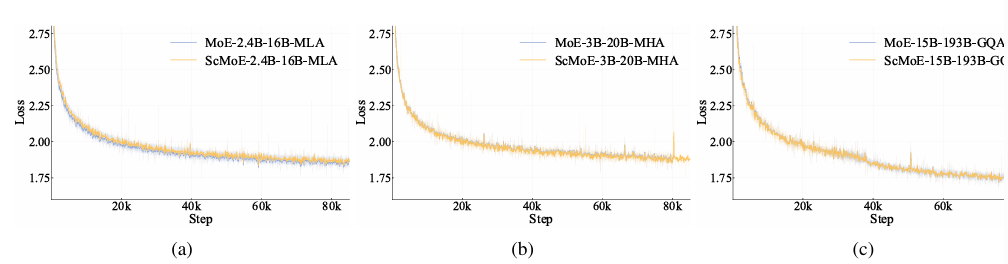
官方实验结果显示训练和推理都快了约 50%,Loss 曲线几乎重合(质量无损),并且TPOT(每 token 生成时间)比 DeepSeek-V3 降了一半。
这一步彻底解决了 MoE 系列“理论强但实践卡”的老问题。
三、可扩展性与稳定性
LongCat-Flash 不只是结构创新,它的工程系统也相当硬核。报告里专门有一节写Stability & Scaling Framework,包括:
1. 超稳的训练流程
- Hyperparameter Transfer:从小模型自动迁移超参。
- Model Growth Initialization:从半尺寸模型叠加成长,避免随机初始化带来的不稳定。
- Hidden z-Loss:用额外的小损失项抑制激活爆炸。
- Adam ε=1e-16:显式控制优化器稳定性。
2. Deterministic Computation(确定性计算)
“所有实验可复现,任何 Silent Data Corruption 都能被检测出来。” 这在千卡级训练里太重要了——
否则一个节点出错,整轮训练都得重来。
结果是超过 20T tokens 预训练数据,全流程仅用 30 天,98.48% 的时间可用性(几乎不用人工介入)。
四、训练数据
LongCat-Flash 的训练分成三阶段:
- 通用预训练阶段
- 20T token,保证语言通用能力。
- 数据源覆盖网页、书籍、代码等。
- 增强中文分词和数字处理。
- 推理与编程强化阶段
- 注重数学、逻辑、代码推理。
- 使用自研数据生成系统合成高难任务。
- 超长上下文扩展阶段
- 上下文长度扩展到 128K tokens。
- 用书籍和整库代码训练,提升长程记忆。
整个流程用到了复杂的过滤与去重机制,防止数据污染(decontamination)。
五、Agent 能力
LongCat-Flash 最大的亮点在于它在「Agent 能力」上的突破。它不是简单的语言模型,而是“能推理、能调用工具、能完成复杂任务的智能体。”
美团专门定义了三维复杂度来评估 Agent 任务:
- 信息处理复杂度
- 工具集复杂度
- 用户交互复杂度
他们还自建了一个超难的 benchmark —— VitaBench,完全基于真实业务场景,比如外卖调度、路线规划、客服应答等。在这个场景下,LongCat-Flash 甚至超过了 DeepSeek-V3.1 等同级模型。
LongCat-Flash 不是简单“复刻”国外架构,而是一步到位做到了体系化创新,架构上MoE 真正动态化、通信完全并行;系统上从超参迁移到容错训练全链打通;任务上Agent 能力实测领先;成本上单位算力效率拉满。
下一步要看它的生态能否跟上,毕竟,开源只是起点,真正的比拼在于谁能让它“跑在更多人的 GPU 上”。
关于深度学习和AI大模型相关的知识和前沿技术更新,请关注公众号 coting!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)