手把手-NER 命名实体识别
手把手,微调一个BERT的下游任务,即NER
概述:
6月做语音填单时,用领域数据微调的BERT模型,主要用于对用户输出文本进行实体识别(NER),从自然语言指令中抽取表单字段和对应的值;
后来使用纯前端推理,采用GGUF 方案,使用GPT模型,BERT就不能用了,重新记录下,别忘了。
环境
服务器
主要基于bert做增量微调,命名实体识别任务
|
基座模型 |
google-bert/bert-base-chinese |
|
硬件 |
TITAN Xp(12GB) * 1(12G) |
|
软件 |
PyTorch 2.5.1 Python 3.12(ubuntu22.04) CUDA 12.4 |
|
内存 |
15G |
|
备注 |
AutoDL上租一个就行,0.52/时 |
基座模型

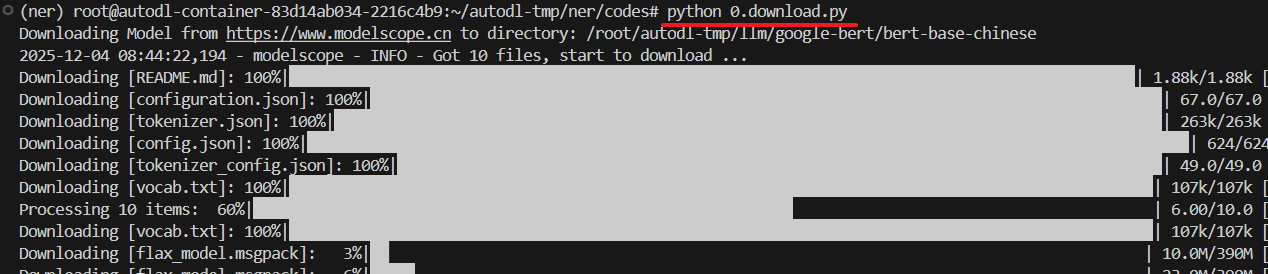
数据集:
BIO标注
|
标签 |
全称 |
含义 |
示例 |
|
B- |
Begin |
实体的起始位置 |
B-字段 表示"字段"实体的开始 |
|
I- |
Inside |
实体的内部位置 |
I-字段 表示"字段"实体的后续部分 |
|
O |
Outside |
不属于任何实体 |
普通词或标点符号 |
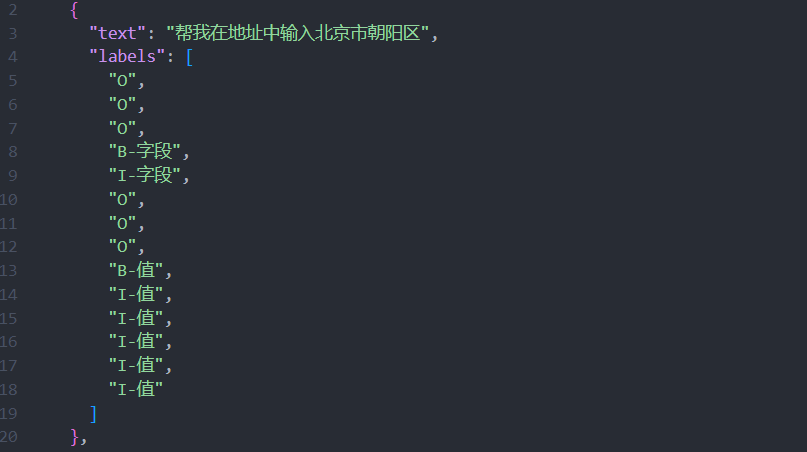
举例:
文本:帮我在地址中输入北京市朝阳区
提取:字段实体(地址)/值实体(北京市朝阳区)
|
原始文本 |
帮我在地址中输入北京市朝阳区 |
|
标注文本 |
O O O B-字 I-字 O O O B-值 I-值 I-值 I-值 I-值 I-值 |
|
说明 |
字符级标注(每个字对应一个标签):
|
数据格式
根据BIO标注数据,
上传至服务器
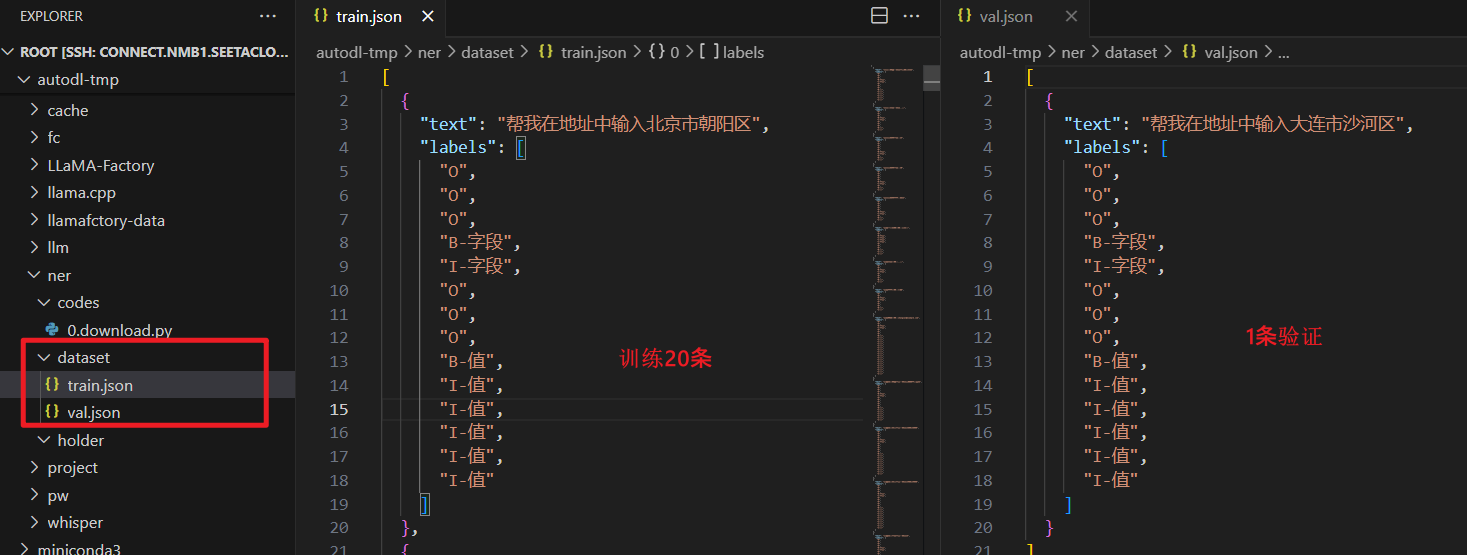
[
{
"text": "帮我在地址中输入北京市朝阳区",
"labels": [
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值"
]
},
{
"text": "帮我在姓名中输入李四",
"labels": [
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值"
]
},
{
"text": "请帮我填写年龄为25",
"labels": [
"O",
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"B-值",
"I-值"
]
},
{
"text": "请帮我填写年龄为30",
"labels": [
"O",
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"B-值",
"I-值"
]
},
{
"text": "请帮我填写学历为硕士",
"labels": [
"O",
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"B-值",
"I-值"
]
},
{
"text": "请将身份证号设置为示例值",
"labels": [
"O",
"O",
"B-字段",
"I-字段",
"I-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值"
]
},
{
"text": "请将姓名设置为李四",
"labels": [
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值"
]
},
{
"text": "请将学历设置为本科",
"labels": [
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值"
]
},
{
"text": "请将邮箱设置为zhangsan@example.com",
"labels": [
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值"
]
},
{
"text": "我需要在地址字段中填入上海市浦东新区",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值"
]
},
{
"text": "我需要在电话字段中填入13800138000",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值"
]
},
{
"text": "我需要在电话字段中填入13900139000",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值"
]
},
{
"text": "我需要在年龄字段中填入25",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值"
]
},
{
"text": "我需要在身份证号字段中填入示例值",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"I-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值"
]
},
{
"text": "我需要在姓名字段中填入张三",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值"
]
},
{
"text": "我需要在学历字段中填入硕士",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值"
]
},
{
"text": "我需要在职业字段中填入工程师",
"labels": [
"O",
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值"
]
},
{
"text": "我要在电话里填写13900139000",
"labels": [
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值"
]
},
{
"text": "我要在姓名里填写李四",
"labels": [
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值"
]
},
{
"text": "我要在邮箱里填写zhangsan@example.com",
"labels": [
"O",
"O",
"O",
"B-字段",
"I-字段",
"O",
"O",
"O",
"B-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值",
"I-值"
]
}
]数据集处理类
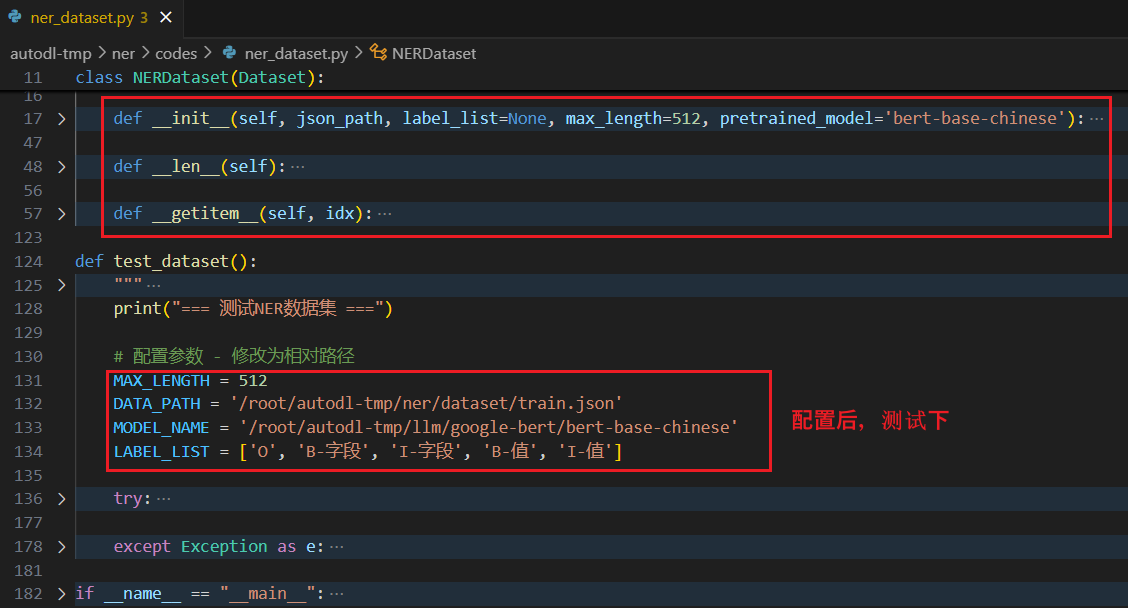
文件:ner_dataset.py
功能:用于加载和预处理命名实体识别任务的数据,实现基本方法 len、getitem
import json
import torch
from torch.utils.data import Dataset
from transformers import BertTokenizerFast
class NERDataset(Dataset):
def __init__(self, json_path, label_list=None, max_length=512, pretrained_model='bert-base-chinese'):
with open(json_path, 'r', encoding='utf-8') as f:
self.data = json.load(f)
self.tokenizer = BertTokenizerFast.from_pretrained(pretrained_model, local_files_only=True)
self.max_length = max_length
if label_list is None:
label_list = ['O', 'B-字段', 'I-字段', 'B-值', 'I-值']
self.label2id = {label: idx for idx, label in enumerate(label_list)}
self.id2label = {idx: label for label, idx in self.label2id.items()}
print(f"数据集加载完成,共{len(self.data)}个样本")
print(f"标签映射: {self.label2id}")
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
text = item['text']
labels = item['labels']
tokens = list(text)
encoding = self.tokenizer(
tokens,
is_split_into_words=True,
truncation=True,
padding='max_length',
max_length=self.max_length,
return_tensors='pt'
)
word_ids = encoding.word_ids()
label_ids = []
prev_word_id = None
for word_id in word_ids:
if word_id is None:
label_ids.append(-100)
elif word_id != prev_word_id:
label_ids.append(self.label2id[labels[word_id]])
else:
label_ids.append(self.label2id[labels[word_id]])
prev_word_id = word_id
label_ids = label_ids[:self.max_length]
if len(label_ids) < self.max_length:
label_ids += [-100] * (self.max_length - len(label_ids))
encoding['labels'] = torch.tensor(label_ids)
for key in ['input_ids', 'attention_mask']:
if key in encoding:
encoding[key] = encoding[key].squeeze(0)
if 'token_type_ids' in encoding:
encoding['token_type_ids'] = encoding['token_type_ids'].squeeze(0)
return encoding
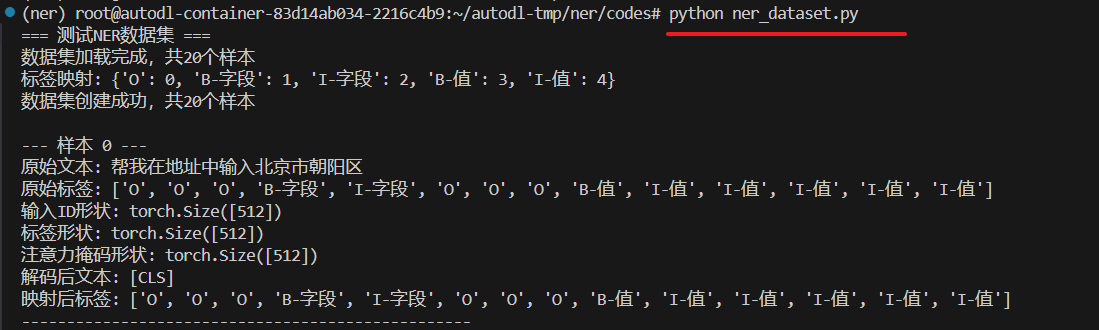
def test_dataset():
print("=== 测试NER数据集 ===")
MAX_LENGTH = 512
DATA_PATH = '/root/autodl-tmp/ner/dataset/train.json'
MODEL_NAME = '/root/autodl-tmp/llm/google-bert/bert-base-chinese'
LABEL_LIST = ['O', 'B-字段', 'I-字段', 'B-值', 'I-值']
try:
train_dataset = NERDataset(
DATA_PATH,
label_list=LABEL_LIST,
max_length=MAX_LENGTH,
pretrained_model=MODEL_NAME
)
print(f"数据集创建成功,共{len(train_dataset)}个样本")
for i in range(min(3, len(train_dataset))):
print(f"\n--- 样本 {i} ---")
original_text = train_dataset.data[i]['text']
original_labels = train_dataset.data[i]['labels']
processed_data = train_dataset[i]
print(f"原始文本: {original_text}")
print(f"原始标签: {original_labels}")
print(f"输入ID形状: {processed_data['input_ids'].shape}")
print(f"标签形状: {processed_data['labels'].shape}")
print(f"注意力掩码形状: {processed_data['attention_mask'].shape}")
decoded_text = train_dataset.tokenizer.decode(processed_data['input_ids'][0])
print(f"解码后文本: {decoded_text}")
label_ids = processed_data['labels'].tolist()
mapped_labels = [train_dataset.id2label.get(lid, 'PAD') for lid in label_ids if lid != -100]
print(f"映射后标签: {mapped_labels}")
print("-" * 50)
print("数据集测试完成!")
return True
except Exception as e:
print(f"数据集测试失败: {e}")
return False
if __name__ == "__main__":
test_dataset()
微调训练
配置文件
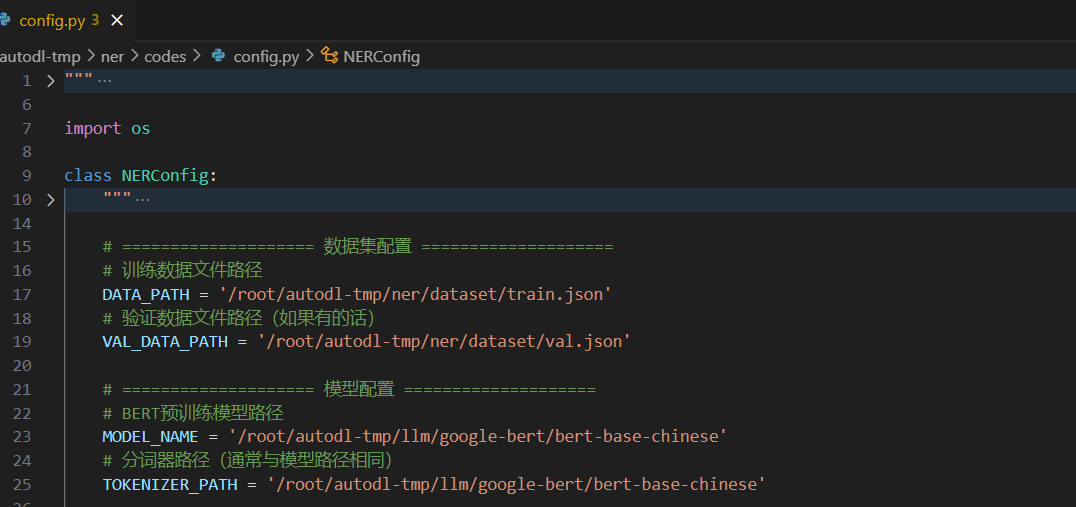
文件:config.py
功能:统一管理训练参数、模型路径、数据集路径等,学习率、轮次、设备、权重路径等都在这配置
import os
class NERConfig:
DATA_PATH = '/root/autodl-tmp/ner/dataset/train.json'
VAL_DATA_PATH = '/root/autodl-tmp/ner/dataset/val.json'
MODEL_NAME = '/root/autodl-tmp/llm/google-bert/bert-base-chinese'
TOKENIZER_PATH = '/root/autodl-tmp/llm/google-bert/bert-base-chinese'
LABEL_LIST = ['O', 'B-字段', 'I-字段', 'B-值', 'I-值']
EPOCH = 3000
BATCH_SIZE = 20
LEARNING_RATE = 2e-5
MAX_LENGTH = 512
DEVICE = 'cuda'
SAVE_DIR = 'params'
BEST_MODEL_PATH = 'params/best_model.pth'
EVAL_STEPS = 10
RANDOM_SEED = 42
USE_AMP = False
MAX_GRAD_NORM = 1.0
@classmethod
def create_save_dir(cls):
if not os.path.exists(cls.SAVE_DIR):
os.makedirs(cls.SAVE_DIR)
print(f"创建保存目录: {cls.SAVE_DIR}")
@classmethod
def get_device(cls):
import torch
device = torch.device(cls.DEVICE if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
if device.type == 'cuda':
print(f"GPU名称: {torch.cuda.get_device_name()}")
print(f"GPU显存: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f}GB")
return device
@classmethod
def set_random_seed(cls):
import torch
import numpy as np
import random
torch.manual_seed(cls.RANDOM_SEED)
torch.cuda.manual_seed(cls.RANDOM_SEED)
torch.cuda.manual_seed_all(cls.RANDOM_SEED)
np.random.seed(cls.RANDOM_SEED)
random.seed(cls.RANDOM_SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
print(f"随机种子设置为: {cls.RANDOM_SEED}")
@classmethod
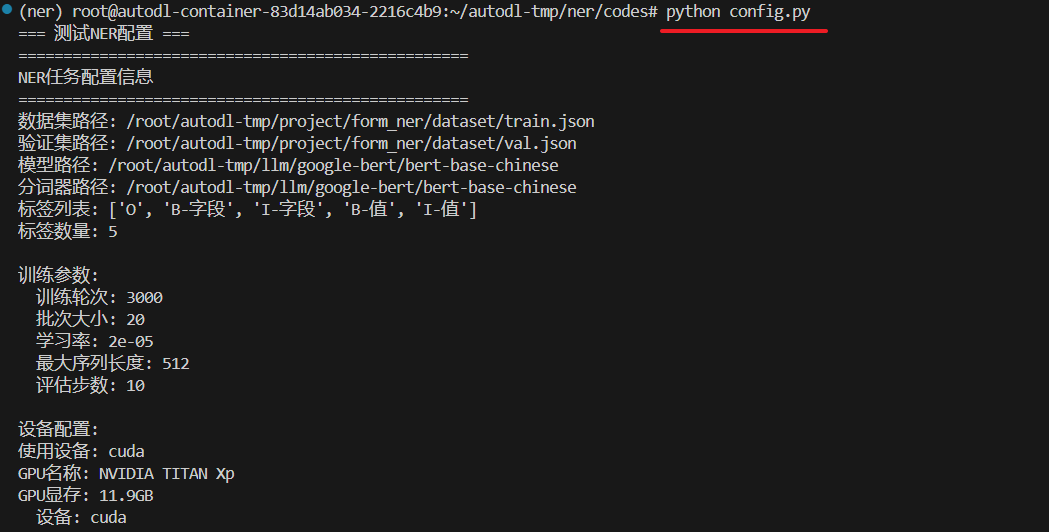
def print_config(cls):
print("=" * 50)
print("NER任务配置信息")
print("=" * 50)
print(f"数据集路径: {cls.DATA_PATH}")
print(f"验证集路径: {cls.VAL_DATA_PATH}")
print(f"模型路径: {cls.MODEL_NAME}")
print(f"分词器路径: {cls.TOKENIZER_PATH}")
print(f"标签列表: {cls.LABEL_LIST}")
print(f"标签数量: {len(cls.LABEL_LIST)}")
print(f"\n训练参数:")
print(f" 训练轮次: {cls.EPOCH}")
print(f" 批次大小: {cls.BATCH_SIZE}")
print(f" 学习率: {cls.LEARNING_RATE}")
print(f" 最大序列长度: {cls.MAX_LENGTH}")
print(f" 评估步数: {cls.EVAL_STEPS}")
print(f"\n设备配置:")
device = cls.get_device()
print(f" 设备: {device}")
print(f"\n保存配置:")
print(f" 保存目录: {cls.SAVE_DIR}")
print(f" 最佳模型路径: {cls.BEST_MODEL_PATH}")
print(f"\n其他配置:")
print(f" 随机种子: {cls.RANDOM_SEED}")
print(f" 混合精度训练: {cls.USE_AMP}")
print(f" 梯度裁剪阈值: {cls.MAX_GRAD_NORM}")
print("=" * 50)
@classmethod
def validate_config(cls):
errors = []
if not os.path.exists(cls.DATA_PATH):
errors.append(f"训练数据文件不存在: {cls.DATA_PATH}")
if not os.path.exists(cls.MODEL_NAME):
errors.append(f"模型路径不存在: {cls.MODEL_NAME}")
if cls.BATCH_SIZE <= 0:
errors.append(f"批次大小必须大于0: {cls.BATCH_SIZE}")
if cls.LEARNING_RATE <= 0:
errors.append(f"学习率必须大于0: {cls.LEARNING_RATE}")
if cls.MAX_LENGTH <= 0:
errors.append(f"最大序列长度必须大于0: {cls.MAX_LENGTH}")
if errors:
print("配置验证失败:")
for error in errors:
print(f" ❌ {error}")
return False
else:
print("✅ 配置验证通过")
return True
def test_config():
print("=== 测试NER配置 ===")
NERConfig.print_config()
is_valid = NERConfig.validate_config()
NERConfig.set_random_seed()
NERConfig.create_save_dir()
if is_valid:
print("配置测试完成!")
return True
else:
print("配置测试失败!")
return False
if __name__ == "__main__":
test_config()执行后会在当前路径新建文件夹params,用于保存权重
微调脚本
文件:ner_train.py
功能:NER模型训练脚本,用于训练命名实体识别模型,从自然语言指令中抽取表单字段和值
import os
import torch
from torch.utils.data import DataLoader
from transformers import BertTokenizer, BertForTokenClassification
from torch.optim import AdamW
from ner_dataset import NERDataset
import torch.nn as nn
import numpy as np
from config import NERConfig
import time
from datetime import datetime
def setup_environment():
print("=" * 60)
print("开始设置训练环境")
print("=" * 60)
device = NERConfig.get_device()
NERConfig.set_random_seed()
NERConfig.create_save_dir()
if not NERConfig.validate_config():
raise ValueError("配置验证失败,请检查配置文件")
print("环境设置完成!")
return device
def create_data_loader():
print("正在创建数据加载器...")
train_dataset = NERDataset(
NERConfig.DATA_PATH,
label_list=NERConfig.LABEL_LIST,
max_length=NERConfig.MAX_LENGTH,
pretrained_model=NERConfig.TOKENIZER_PATH
)
def collate_fn(data):
try:
if not data:
raise ValueError("数据列表为空")
batch = {}
for key in data[0].keys():
try:
batch[key] = torch.stack([item[key] for item in data])
except Exception as e:
print(f"处理键 '{key}' 时出现错误: {e}")
print(f"数据形状: {[item[key].shape for item in data]}")
raise
return batch
except Exception as e:
print(f"collate_fn 出现错误: {e}")
raise
train_loader = DataLoader(
dataset=train_dataset,
batch_size=NERConfig.BATCH_SIZE,
shuffle=True,
drop_last=True,
collate_fn=collate_fn
)
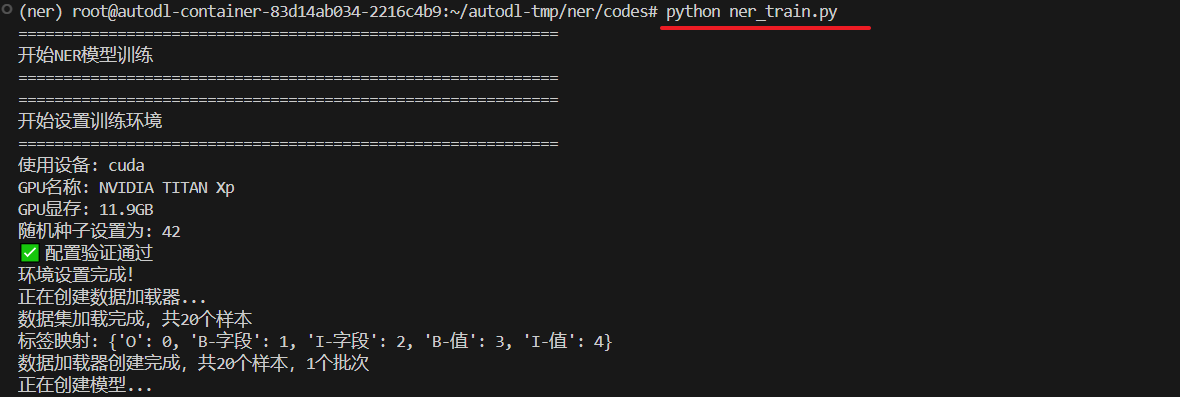
print(f"数据加载器创建完成,共{len(train_dataset)}个样本,{len(train_loader)}个批次")
return train_loader
def create_model(device):
print("正在创建模型...")
model = BertForTokenClassification.from_pretrained(
NERConfig.MODEL_NAME,
num_labels=len(NERConfig.LABEL_LIST)
)
model = model.to(device)
print(f"模型创建完成,标签数量: {len(NERConfig.LABEL_LIST)}")
return model
def create_optimizer(model):
optimizer = AdamW(model.parameters(), lr=NERConfig.LEARNING_RATE)
print(f"优化器创建完成,学习率: {NERConfig.LEARNING_RATE}")
return optimizer
def evaluate_model(model, data_loader, device):
model.eval()
total_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch in data_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch.get('token_type_ids', None)
if token_type_ids is not None:
token_type_ids = token_type_ids.to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
logits = outputs.logits
loss_fct = nn.CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(logits.view(-1, len(NERConfig.LABEL_LIST)), labels.view(-1))
total_loss += loss.item()
predictions = logits.argmax(dim=-1)
valid_mask = labels != -100
correct += (predictions[valid_mask] == labels[valid_mask]).sum().item()
total += valid_mask.sum().item()
avg_loss = total_loss / len(data_loader)
accuracy = correct / total if total > 0 else 0
return avg_loss, accuracy
def train_epoch(model, train_loader, optimizer, device, epoch):
try:
model.train()
total_loss = 0
total_correct = 0
total_valid = 0
start_time = time.time()
for batch_idx, batch in enumerate(train_loader):
try:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch.get('token_type_ids', None)
if token_type_ids is not None:
token_type_ids = token_type_ids.to(device)
labels = batch['labels'].to(device)
try:
if token_type_ids is not None:
outputs = model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
else:
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs.logits
except Exception as e:
print(f"前向传播错误: {e}")
print(f"input_ids shape: {input_ids.shape}")
print(f"attention_mask shape: {attention_mask.shape}")
print(f"token_type_ids: {token_type_ids}")
raise
loss_fct = nn.CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(logits.view(-1, len(NERConfig.LABEL_LIST)), labels.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
predictions = logits.argmax(dim=-1)
valid_mask = labels != -100
correct = 0
if valid_mask.sum() > 0:
correct = (predictions[valid_mask] == labels[valid_mask]).sum().item()
total_correct += correct
total_valid += valid_mask.sum().item()
if batch_idx % 5 == 0:
batch_acc = correct / valid_mask.sum().item() if valid_mask.sum() > 0 else 0
print(f"Epoch {epoch}, Batch {batch_idx}/{len(train_loader)}, "
f"Loss: {loss.item():.4f}, Acc: {batch_acc:.4f}")
except Exception as e:
print(f"批次 {batch_idx} 训练时出现错误: {e}")
continue
avg_loss = total_loss / len(train_loader) if len(train_loader) > 0 else 0
avg_acc = total_correct / total_valid if total_valid > 0 else 0
epoch_time = time.time() - start_time
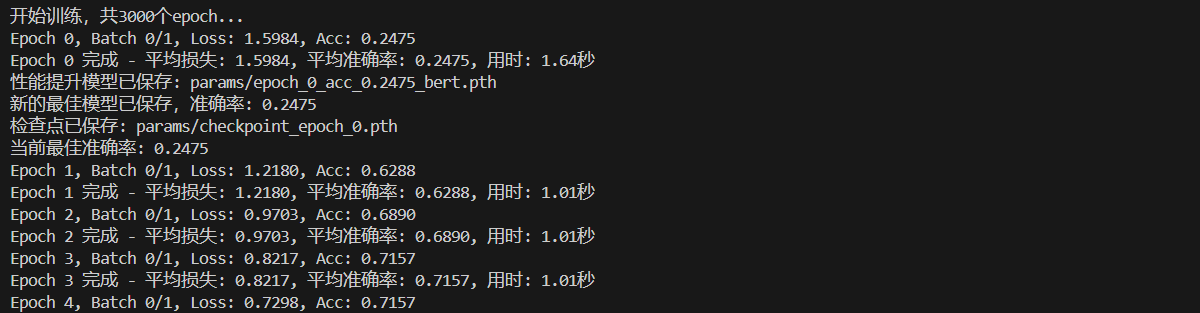
print(f"Epoch {epoch} 完成 - "
f"平均损失: {avg_loss:.4f}, "
f"平均准确率: {avg_acc:.4f}, "
f"用时: {epoch_time:.2f}秒")
return avg_loss, avg_acc
except Exception as e:
print(f"Epoch {epoch} 训练过程中出现错误: {e}")
import traceback
traceback.print_exc()
return 0.0, 0.0
def save_model(model, epoch, loss, accuracy):
model_path = f"{NERConfig.SAVE_DIR}/epoch_{epoch}_acc_{accuracy:.4f}_bert.pth"
torch.save(model.state_dict(), model_path)
info_path = f"{NERConfig.SAVE_DIR}/epoch_{epoch}_acc_{accuracy:.4f}_info.txt"
with open(info_path, 'w', encoding='utf-8') as f:
f.write(f"Epoch: {epoch}\n")
f.write(f"Loss: {loss:.4f}\n")
f.write(f"Accuracy: {accuracy:.4f}\n")
f.write(f"Save Time: {datetime.now()}\n")
f.write(f"Performance-based save: True\n")
print(f"性能提升模型已保存: {model_path}")
def train_model():
print("=" * 60)
print("开始NER模型训练")
print("=" * 60)
try:
device = setup_environment()
train_loader = create_data_loader()
model = create_model(device)
optimizer = create_optimizer(model)
print(f"\n开始训练,共{NERConfig.EPOCH}个epoch...")
best_accuracy = 0
training_history = []
for epoch in range(NERConfig.EPOCH):
loss, accuracy = train_epoch(model, train_loader, optimizer, device, epoch)
training_history.append({
'epoch': epoch,
'loss': loss,
'accuracy': accuracy
})
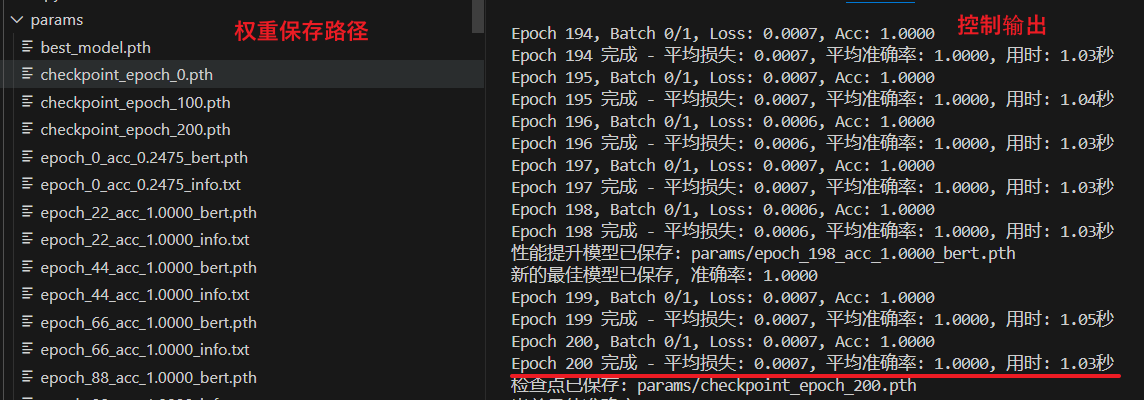
if epoch % 22 == 0:
save_model(model, epoch, loss, accuracy)
best_accuracy = accuracy
best_model_path = f"{NERConfig.SAVE_DIR}/best_model.pth"
torch.save(model.state_dict(), best_model_path)
print(f"新的最佳模型已保存,准确率: {best_accuracy:.4f}")
if epoch % 100 == 0:
checkpoint_path = f"{NERConfig.SAVE_DIR}/checkpoint_epoch_{epoch}.pth"
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
'accuracy': accuracy
}, checkpoint_path)
print(f"检查点已保存: {checkpoint_path}")
if epoch % NERConfig.EVAL_STEPS == 0:
print(f"当前最佳准确率: {best_accuracy:.4f}")
print("\n" + "=" * 60)
print("训练完成!")
print(f"最佳准确率: {best_accuracy:.4f}")
print(f"最佳模型路径: {NERConfig.SAVE_DIR}/best_model.pth")
print("=" * 60)
return True
except Exception as e:
print(f"训练过程中出现错误: {e}")
return False
if __name__ == '__main__':
success = train_model()
if success:
print("✅ 训练成功完成!")
else:
print("❌ 训练失败!")
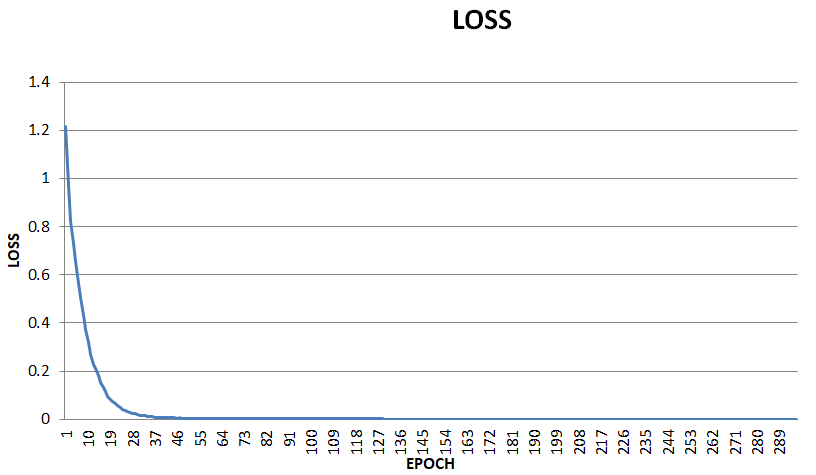
早停:训练数据集少,40个epoch就开始躺平了,在200个epoch的loss已经到0.0007了,手动停了吧。
推理评估
文件:ner_inference.py
功能:用于加载训练好的模型并进行预测,从自然语言指令中抽取表单字段和值

import torch
import json
from transformers import BertTokenizerFast, BertForTokenClassification
from ner_dataset import NERDataset
from config import NERConfig
class NERPredictor:
def __init__(self, model_path, tokenizer_path, label_list, device='cuda'):
self.device = torch.device(device if torch.cuda.is_available() else "cpu")
print(f"使用设备: {self.device}")
self.label_list = label_list
self.label2id = {label: idx for idx, label in enumerate(label_list)}
self.id2label = {idx: label for label, idx in self.label2id.items()}
print("正在加载分词器...")
self.tokenizer = BertTokenizerFast.from_pretrained(tokenizer_path)
print("正在加载模型...")
self.model = BertForTokenClassification.from_pretrained(
tokenizer_path,
num_labels=len(label_list)
)
self.model.load_state_dict(torch.load(model_path, map_location=self.device))
self.model.to(self.device)
self.model.eval()
print("模型加载完成!")
def predict(self, text, max_length=512):
print(f"正在预测文本: {text}")
tokens = list(text)
encoding = self.tokenizer(
tokens,
is_split_into_words=True,
truncation=True,
padding='max_length',
max_length=max_length,
return_tensors='pt'
)
input_ids = encoding['input_ids'].to(self.device)
attention_mask = encoding['attention_mask'].to(self.device)
token_type_ids = encoding.get('token_type_ids', None)
if token_type_ids is not None:
token_type_ids = token_type_ids.to(self.device)
with torch.no_grad():
outputs = self.model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
predictions = outputs.logits.argmax(dim=-1)
word_ids = encoding.word_ids()
predicted_labels = []
token_to_word = []
for i, word_id in enumerate(word_ids):
if word_id is not None:
predicted_label = self.id2label[predictions[0][i].item()]
predicted_labels.append(predicted_label)
token_to_word.append(word_id)
entities = self.extract_entities(text, predicted_labels, token_to_word)
return predicted_labels, entities
def extract_entities(self, text, labels, token_to_word):
entities = []
current_entity = None
current_start = None
current_end = None
for i, (label, word_id) in enumerate(zip(labels, token_to_word)):
if label.startswith('B-'):
if current_entity is not None:
entity_text = text[current_start:current_end + 1]
entities.append({
'type': current_entity,
'text': entity_text,
'start': current_start,
'end': current_end + 1
})
current_entity = label[2:]
current_start = word_id
current_end = word_id
elif label.startswith('I-') and current_entity is not None:
if label[2:] == current_entity:
current_end = word_id
else:
entity_text = text[current_start:current_end + 1]
entities.append({
'type': current_entity,
'text': entity_text,
'start': current_start,
'end': current_end + 1
})
current_entity = None
current_start = None
current_end = None
else:
if current_entity is not None:
entity_text = text[current_start:current_end + 1]
entities.append({
'type': current_entity,
'text': entity_text,
'start': current_start,
'end': current_end + 1
})
current_entity = None
current_start = None
current_end = None
if current_entity is not None:
entity_text = text[current_start:current_end + 1]
entities.append({
'type': current_entity,
'text': entity_text,
'start': current_start,
'end': current_end + 1
})
return entities
def extract_field_value_pairs(self, entities):
field_value_pairs = {}
fields = [e for e in entities if e['type'] == '字段']
values = [e for e in entities if e['type'] == '值']
for i, field in enumerate(fields):
if i < len(values):
field_value_pairs[field['text']] = values[i]['text']
return field_value_pairs
def test_model():
print("=" * 60)
print("开始测试NER模型")
print("=" * 60)
MODEL_PATH = "params/best_model.pth"
TOKENIZER_PATH = NERConfig.TOKENIZER_PATH
LABEL_LIST = NERConfig.LABEL_LIST
test_texts = [
"帮我在地址中输入北京市朝阳区",
"请帮我填写年龄为25",
"请将姓名设置为李四",
"我需要在电话字段中填入13800138000",
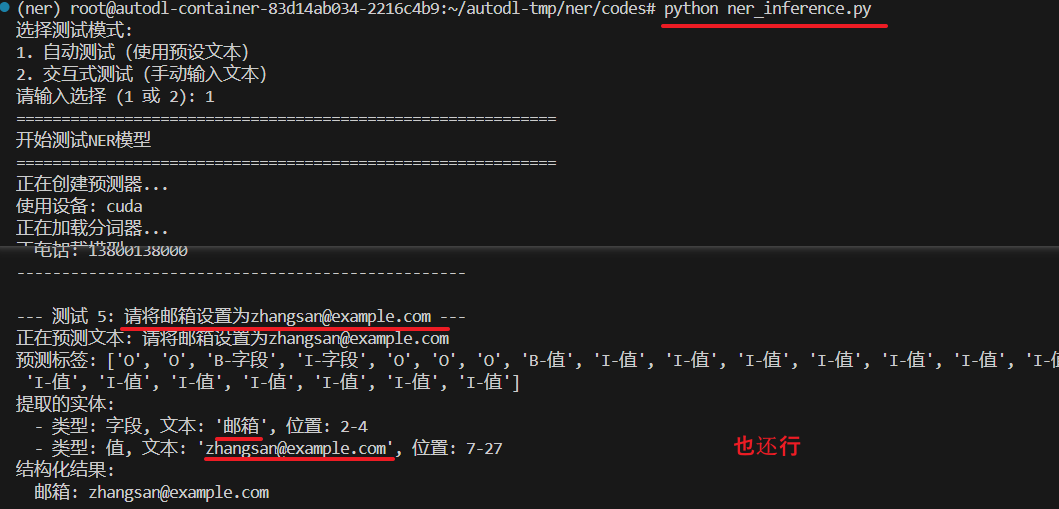
"请将邮箱设置为zhangsan@example.com",
"请帮我填写学历为硕士",
"我需要在身份证号字段中填入示例值"
]
try:
print("正在创建预测器...")
predictor = NERPredictor(MODEL_PATH, TOKENIZER_PATH, LABEL_LIST)
print("\n" + "=" * 60)
print("NER模型测试结果")
print("=" * 60)
for i, text in enumerate(test_texts, 1):
print(f"\n--- 测试 {i}: {text} ---")
predicted_labels, entities = predictor.predict(text)
print(f"预测标签: {predicted_labels}")
if entities:
print("提取的实体:")
for entity in entities:
print(f" - 类型: {entity['type']}, "
f"文本: '{entity['text']}', "
f"位置: {entity['start']}-{entity['end']}")
else:
print("未提取到实体")
field_value_pairs = predictor.extract_field_value_pairs(entities)
if field_value_pairs:
print("结构化结果:")
for field, value in field_value_pairs.items():
print(f" {field}: {value}")
else:
print("未提取到字段-值对")
print("-" * 50)
print("\n测试完成!")
return True
except FileNotFoundError:
print("❌ 模型文件未找到,请先训练模型")
print(f"期望的模型路径: {MODEL_PATH}")
return False
except Exception as e:
print(f"❌ 测试过程中出现错误: {e}")
return False
def interactive_test():
print("=" * 60)
print("交互式NER测试")
print("=" * 60)
MODEL_PATH = "params/best_model.pth"
TOKENIZER_PATH = NERConfig.TOKENIZER_PATH
LABEL_LIST = NERConfig.LABEL_LIST
try:
print("正在加载模型...")
predictor = NERPredictor(MODEL_PATH, TOKENIZER_PATH, LABEL_LIST)
print("\n模型加载完成!现在可以输入文本进行测试。")
print("输入 'quit' 或 'exit' 退出测试。")
print("-" * 50)
while True:
text = input("\n请输入要测试的文本: ").strip()
if text.lower() in ['quit', 'exit', '退出']:
print("退出测试。")
break
if not text:
print("请输入有效的文本。")
continue
try:
predicted_labels, entities = predictor.predict(text)
print(f"\n预测结果:")
print(f"输入文本: {text}")
print(f"预测标签: {predicted_labels}")
if entities:
print("提取的实体:")
for entity in entities:
print(f" - {entity['type']}: '{entity['text']}'")
field_value_pairs = predictor.extract_field_value_pairs(entities)
if field_value_pairs:
print("结构化结果:")
for field, value in field_value_pairs.items():
print(f" {field}: {value}")
else:
print("未提取到字段-值对")
else:
print("未提取到实体")
except Exception as e:
print(f"预测过程中出现错误: {e}")
except FileNotFoundError:
print("❌ 模型文件未找到,请先训练模型")
except Exception as e:
print(f"❌ 交互式测试出现错误: {e}")
if __name__ == "__main__":
print("选择测试模式:")
print("1. 自动测试(使用预设文本)")
print("2. 交互式测试(手动输入文本)")
choice = input("请输入选择 (1 或 2): ").strip()
if choice == "1":
success = test_model()
if success:
print("✅ 自动测试完成!")
else:
print("❌ 自动测试失败!")
elif choice == "2":
interactive_test()
else:
print("无效选择,运行自动测试...")
test_model()
合并导出
文件:model_merge.py
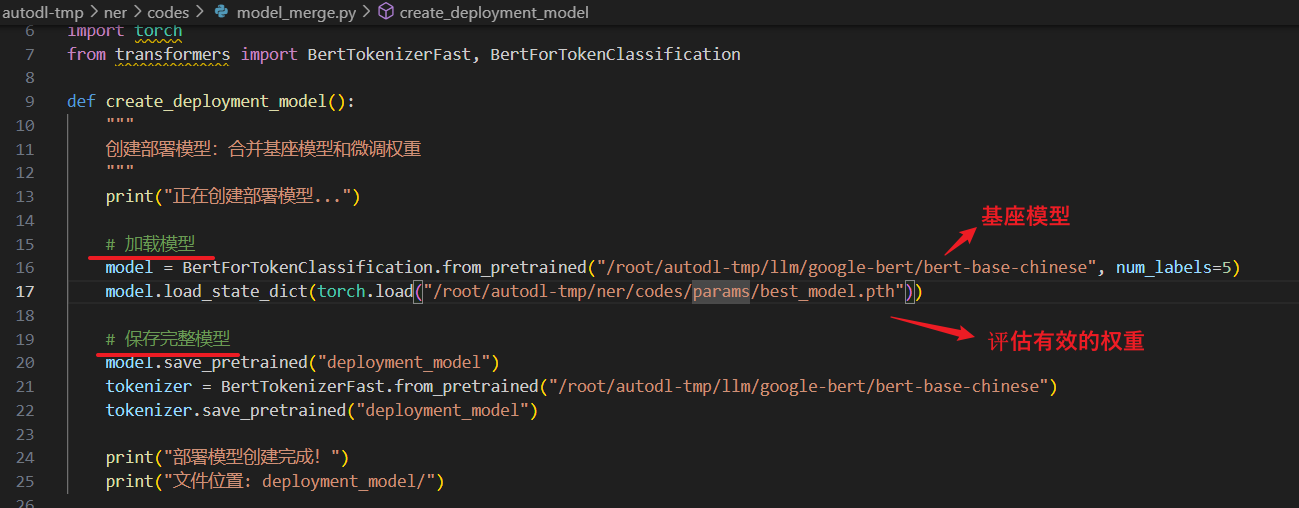
功能:将基座模型和微调权重合并为一个完整的模型


import torch
from transformers import BertTokenizerFast, BertForTokenClassification
def create_deployment_model():
print("正在创建部署模型...")
model = BertForTokenClassification.from_pretrained("/root/autodl-tmp/llm/google-bert/bert-base-chinese", num_labels=5)
model.load_state_dict(torch.load("/root/autodl-tmp/ner/codes/params/best_model.pth"))
model.save_pretrained("deployment_model")
tokenizer = BertTokenizerFast.from_pretrained("/root/autodl-tmp/llm/google-bert/bert-base-chinese")
tokenizer.save_pretrained("deployment_model")
print("部署模型创建完成!")
print("文件位置: deployment_model/")
def ner_predict_deployed(text, model_path="deployment_model"):
model = BertForTokenClassification.from_pretrained(model_path)
tokenizer = BertTokenizerFast.from_pretrained(model_path)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
model.eval()
label_list = ['O', 'B-字段', 'I-字段', 'B-值', 'I-值']
id2label = {idx: label for idx, label in enumerate(label_list)}
tokens = list(text)
encoding = tokenizer(
tokens,
is_split_into_words=True,
truncation=True,
padding='max_length',
max_length=512,
return_tensors='pt'
)
with torch.no_grad():
outputs = model(
encoding['input_ids'].to(device),
attention_mask=encoding['attention_mask'].to(device)
)
predictions = outputs.logits.argmax(dim=-1)
word_ids = encoding.word_ids()
predicted_labels = []
token_to_word = []
for i, word_id in enumerate(word_ids):
if word_id is not None:
predicted_label = id2label[predictions[0][i].item()]
predicted_labels.append(predicted_label)
token_to_word.append(word_id)
entities = extract_entities_simple(text, predicted_labels, token_to_word)
field_value_pairs = {}
fields = [e for e in entities if e['type'] == '字段']
values = [e for e in entities if e['type'] == '值']
for i, field in enumerate(fields):
if i < len(values):
field_value_pairs[field['text']] = values[i]['text']
return field_value_pairs
def extract_entities_simple(text, labels, token_to_word):
entities = []
current_entity = None
current_start = None
current_end = None
for i, (label, word_id) in enumerate(zip(labels, token_to_word)):
if label.startswith('B-'):
if current_entity is not None:
entity_text = text[current_start:current_end + 1]
entities.append({'type': current_entity, 'text': entity_text})
current_entity = label[2:]
current_start = word_id
current_end = word_id
elif label.startswith('I-') and current_entity is not None:
if label[2:] == current_entity:
current_end = word_id
else:
if current_entity is not None:
entity_text = text[current_start:current_end + 1]
entities.append({'type': current_entity, 'text': entity_text})
current_entity = None
if current_entity is not None:
entity_text = text[current_start:current_end + 1]
entities.append({'type': current_entity, 'text': entity_text})
return entities
if __name__ == "__main__":
create_deployment_model()
test_text = "帮我在姓名中输入李四"
result = ner_predict_deployed(test_text)
print(f"测试结果: {result}")
链接(源码):
https://github.com/zenmathink/2728/tree/main/ner
ROB
关于整段文本的抽取,结合本项目,考虑:多语言(中日英)、推理时延(非离线)、通用性(后期扩展)、成本等,可实施的方案如下:
1 Encoder-only
1.1 mBERT:
传统Bert
1.2 XLM-RoBERTa:
- 优点:
- 快
- 比mBert聪明
- 轻装上阵(无NSP)
- 字段不固定,可学习通用模式
- 缺点:
- 精度没UIE高
- 任务单一
2 Encoder-Decoder
2.1 mT5+UIE微调:
优点:
- Schema引导,准确率高、通类型字段有一定泛化性
缺点:
- 推理慢
- 抽取字段类型固定,没见过的字段抽取不准确(关键)
2.2 Flan-T5+指令微调:
-优点:
- 更强的0样本能力
- 微调后不丢失原有任务能力
- 短输出时Flan-T5略快(qwen),长输出时差异缩小
- 缺点:
- 英文支持好,其他语言弱,如日文
2.3 mT5+指令微调
- 优点:
- 多语言+指令灵活性,泛化能力强
- 能力一定情况下,模型较 Decoder-only小很多
- 缺点:推理慢
3 Decoder-only
- 优点:
- 通用
- 可以通过vLLM等加速推理
- 缺点:
- 大、费钱
- 备注:
- 微调了0.5B的单句话抽取(边缘推理),未验证多句话的推理
小节
针对本项目,大段文本的抽取,按架构可验证的方案,如下:
- Encoder:XLM-RoBERTa+通用标签
- Encoder-Decoder:mT5+指令微调(折中方案)
- Decoder-only:验证更大的模型

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)