一张图搞定大模型技术全景:从Transformer到Agent的十大核心,构建你的系统知识体系!
文章系统地介绍了大语言模型(LLM)的十大核心知识板块,包括Transformer结构、主流大模型、预训练与后训练流程、模型压缩、专家模型、RAG与Agent技术、部署与加速策略、模型评估以及其他创新结构。文章强调理论学习需结合论文和源码,并提供了从零基础到进阶的完整学习路线,帮助读者系统掌握大模型技术,提升在AI时代的竞争优势。
LLM基础知识分成了十个部分:
-
Transformer结构
-
主流大模型
-
预训练Pre-train过程
-
后训练Post-train过程
-
模型压缩与量化
-
专家模型MoE
-
RAG&Agent
-
部署&分布式训练&推理加速
-
模型评估
-
其他结构
第一部分:Transformer结构
与LLM相关的面试都会问到transformer比如手撕多头注意力,自注意力缩放,参数计算等等
1.分词器tokenizer &Embedding层
BPE,BBPE,WordPiece等算法,了解一下各类模型的分词方法,感兴趣的同学可以看-下tokenizer在预训练过程具体如何处理
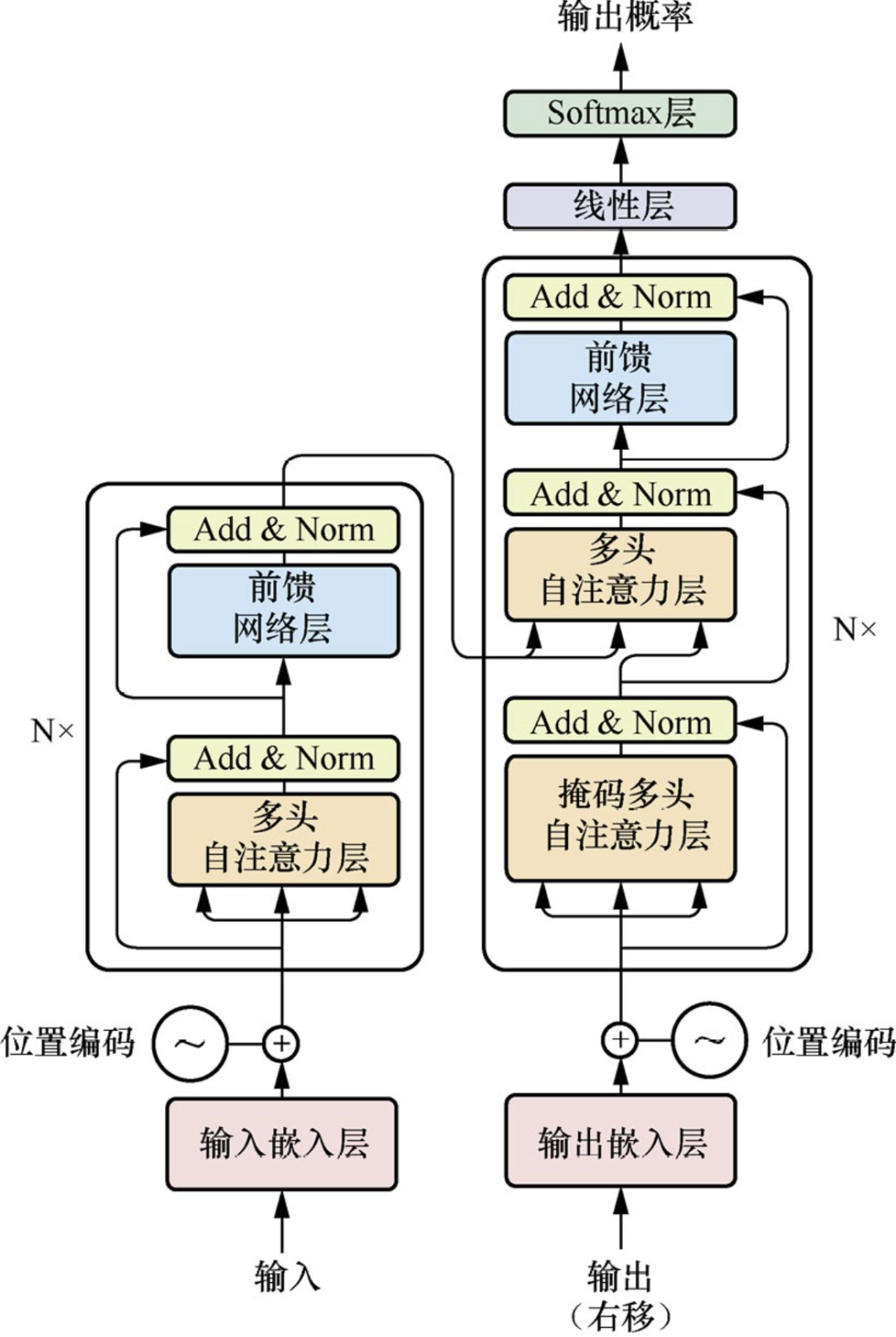
2.注意力模块
self-attention,cross-attention的原理MHA、MQA、GQA、MLA、DCA等多种注意力机制优化策略(可能会考手撕),线性注意力,稀疏注意力,kvcache等等,这部分推荐看苏神的科学空间,原理推导写的很清楚
3.前馈神经网络FFN&残差连接&归一化
这几个模块的作用是什么,LN和BN的区别,pre-norm和post-norm,SwiGLU等激活函数,RMSNorm等归一化
4.位置编码 PE
为什么需要位置编码,常见的位置编码有哪些,如正余弦、可学习、ROPE、ALiBi、YARN等,绝对位置编码和相对位置编码长度外推策略,了解各大模型长上下文处理方式
5.代表模型
encoder-only,decoder-only
encoder-decoder,prefix-decoder等结构及其代表模型,分别适用于哪些任务,为什么现在的大模型都是decoder-only结构
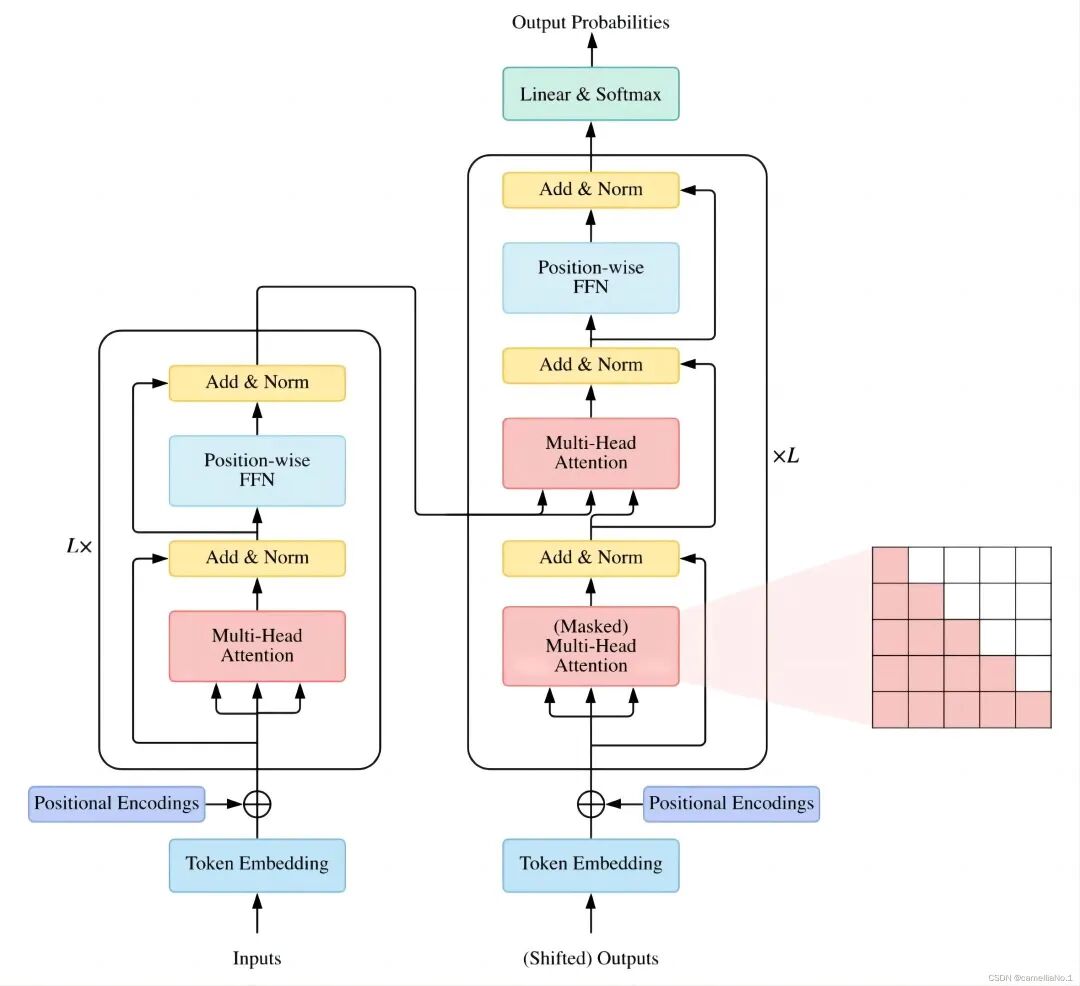
6.解码策略
top-k、top-p、temperature等参数含义greedy search、beam search等解码策略投机解码及其优化算法
第二部分:主流大模型
BERT系列、GPT、Llama、Qwen、GLM、Baichuan、DeepSeek等等,注意关注一下发展脉络,每一代做了哪些优化,不要只看最新版
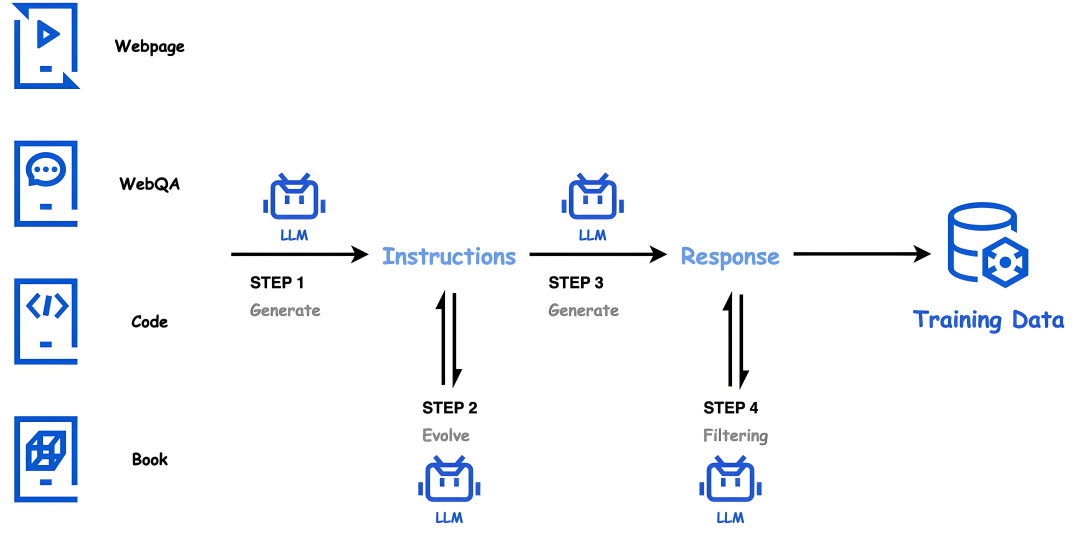
第三部分:预训练Pre-train过程
预训练任务有哪些,数据配比,数据筛选过滤方法,合成数据,这部分推荐阅读主流大模型开源的技术报告
第四部分:后训练Post-train 过程
这部分是面试过程中考察的第二个重点,般会联合实习项目一起深挖
1.SFT
微调数据构造,数据配比,全参微调,冻结微调,PEFT高效微调(prompt tuning、p-tuning v2、prefix-tuning、adapter-tuning、LoRA及其变体)
CoT,Reasoning等o1系列策略
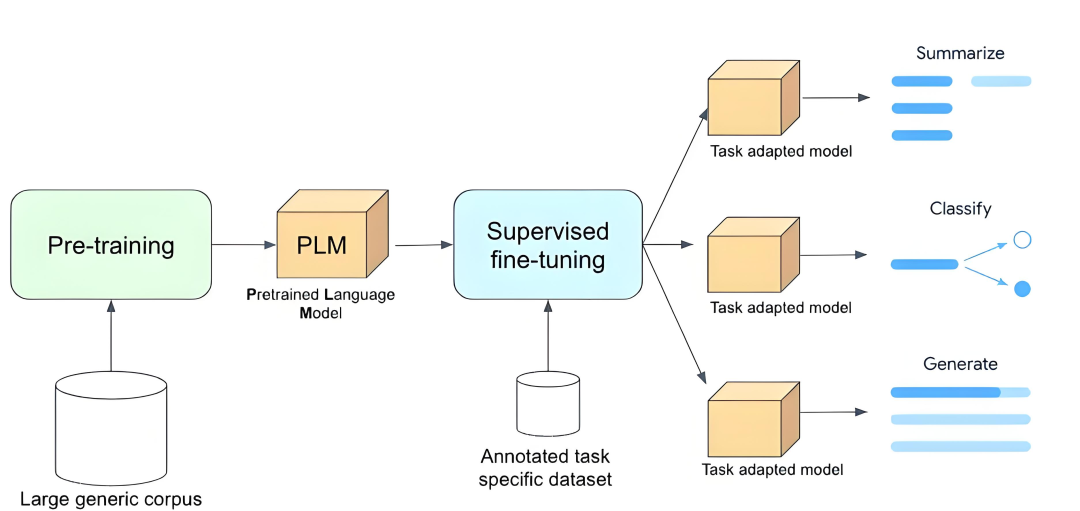
这部分建议做一个完整项目,加深对每一个步骤的理解
2.RLHF&Aligning
为什么有SFT还需要 RLHF,两者有何区别,RLAIF,ReFT,OpenAl做RLHF的过程,里面的几个模型分别是怎么运作的,DPO的原理和实现,PPO和DPO对比,DPO有哪些问题以及如何优化,SimPO,KTO,ORPO,GRPO等等
第五部分:模型压缩与量化
了解各种量化方式,GPTQ,AWQ等,各种量化精度,训练显存计算
第六部分:专家模型 MOE
了解MOE结构及其原理,训练思路,推荐看知乎上关于 MOE的万字长文介绍
第七部分:RAG&Agent
借助 LangChain框架学习RAG流程,了解文档分块,向量模型训练,多种检索策略等关键步骤
Agent的几个框架,如ReAct,Reflexion等了解基本思路
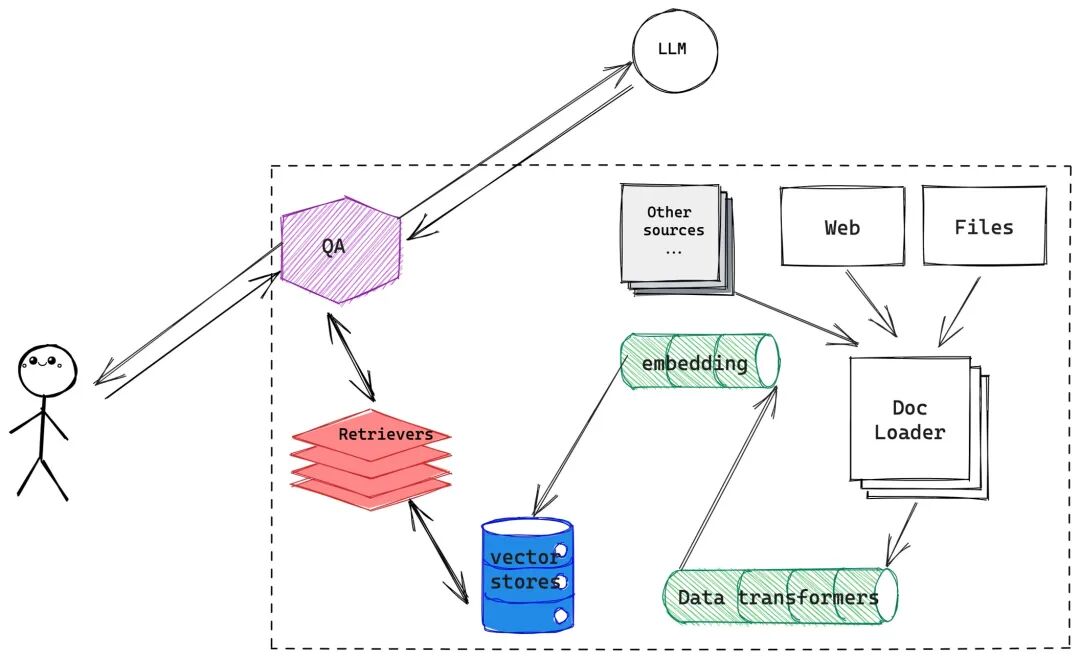
第八部分:部署&分布式训练&推理加速
windows、ios、Android多端部署框架flash attention,vllm,accelerate等推理加速框架
Deepspeed,Megatron等分布式训练框架
第九部分:模型评估
阅读理解、问答、代码生成、数学等多个维度评估 Benchmark
检测 LLM 真实性、流畅度、幻觉等如何利用LLM 对其他模型/任务做评估
第十部分:其他结构
Mamba,RWKV等
建议大家在学习基础知识的同时,配合相关paper和源码一起,进一步加深理解 LLM更新迭代非常快,平时可以多关注一些新的动态,闲着没事多刷刷三大会。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献154条内容
已为社区贡献154条内容

所有评论(0)