【论文笔记 CVPR 2025】Image Referenced Sketch Colorization Based on Animation Creation Workflow
原论文链接: https://arxiv.org/abs/2502.19937
感觉这篇文章挺不错,做的东西本身就很有意思(非常吸引二次元来看),然后对sketch colorization这个任务的介绍也很明了,不会让没做过相关方向的人阅读起来困难。然后方法部分的描述也很清晰,baseline也涉及了diffusion中非常经典的模型,很容易让读者理解。
Abstract
本论文以动画生成为例探讨线条照色问题
text-guided的方法不能准确提供颜色和风格的引导,hint-guided(提示引导)的方法依旧需要人工操作(比如说,依旧需要人手动画很简单的笔划来辅助),图像参考的方法,由于和sketches的空间不匹配,容易导致伪影。
作者设计了一种基于扩散模型的方法,将草图sketch作为空间引导,将一个RGB图像作为颜色reference图,并结合空间mask从reference图中分离前景和背景,然后通过模型来给sketch图上色。
模型具体设计了一种带有LoRA的分离交叉注意力机制,在前景和背景区域上分别训练,可以有效减少干扰和artifact.
在推理阶段,作者通过变换网络中激活的模块,设计了可切换的推理模式。
实验包括qualitative, quantitative结果,ablation study,还有user study.
Introduction
intro的第一段就是说明二次元日益增长的需求使得动画产业劳动力短缺,而动画创作本身就需要大量劳动力。
第二段,作者提及动画制作最耗力的就是画师给线条草图上色,一些机器学习方法已经应用于草图上色(有引用到Lvmin Zhang大佬的文章)来实现自动化上色。但是这些方法依然无法真正应用到业界,存在摘要中提及的问题(text-guided,例如ControlNet, user guided(hint guided)和图像参考的方法),其中第三类方法还有产生artifact和不期望的额外物体,称为空间混乱(spatial entanglement),如论文的图2所示。
第三段介绍了动画制作的流程,论文中的图3有详细说明(这里不放图了),首先,角色设计师会设计人物立绘图,作为reference,然后,高级动画师会绘制每一帧的sketches草图,接着,动画师为根据立绘reference图,为每一帧的草图着色,最后,动画师会对背景进行上色来完成着色帧。(感觉这一段就是废话没啥用)
作者根据观察,设计了一个基于diffusion的框架,来逐步模仿草图着色。该框架将sketch图作为spatial reference,将RGB图作为color reference。
语义信息的维护通过特征提取器的高维局部标记进行,多层编码器编码草图特征,用于精确控制背景嵌入的空间。
分离交叉注意力机制使得前景区域和背景区域的着色分开处理,使用到了spatial mask,LoRA在这里被用来挑战key和value的embedding.在推理阶段,作者实现了能够提供着色过程精准控制和无需更改模型权重即可实现各种场景推理模式的可切换LoRA机制。
整理作者提出的贡献:
- 提出了基于参考图像的草图着色框架,能够生存高质量的结果,并且没有artifact和空间紊乱。
- 设计了能够将背景和前进的着色在一次前向传递中分开进行的分离交叉注意力机制,并设计一个可切换的LoRA模块,实现推理阶段各种颜色模式的适应。
- 实验结果好(qualitative, quantitative, user study)
Related Work
第一部分是Diffusion Model的发展,作者用Stable Diffusion作为backbone,,然后用DPM++作为采样器(之前很多都用DDIM,可以看看DPM++是什么),采用CFG(classifier-free guidance).
第二部分是介绍把image作为提示的扩散模型,主要下游任务有image2image translation,风格迁移,着色,图像合成等。像草图上色任务,既需要参考图像的纹理颜色信息,又需要物体相关信息。将图像prompt输入扩散模型通常有2种方式,1种是训练一个adapter模块,另1种是利用attention层直接将特征插入。但是这两种方式对于草图上色任务表现得都不佳,由于spatial信息的不匹配,会带来artifact.
第三部分介绍了deep learning下草图着色任务的三种形式,基于文本提示,基于用户引导,基于图像参考。(优缺点分析基本同摘要和intro)
Method
下图呈现模型的整体架构(论文中的图4)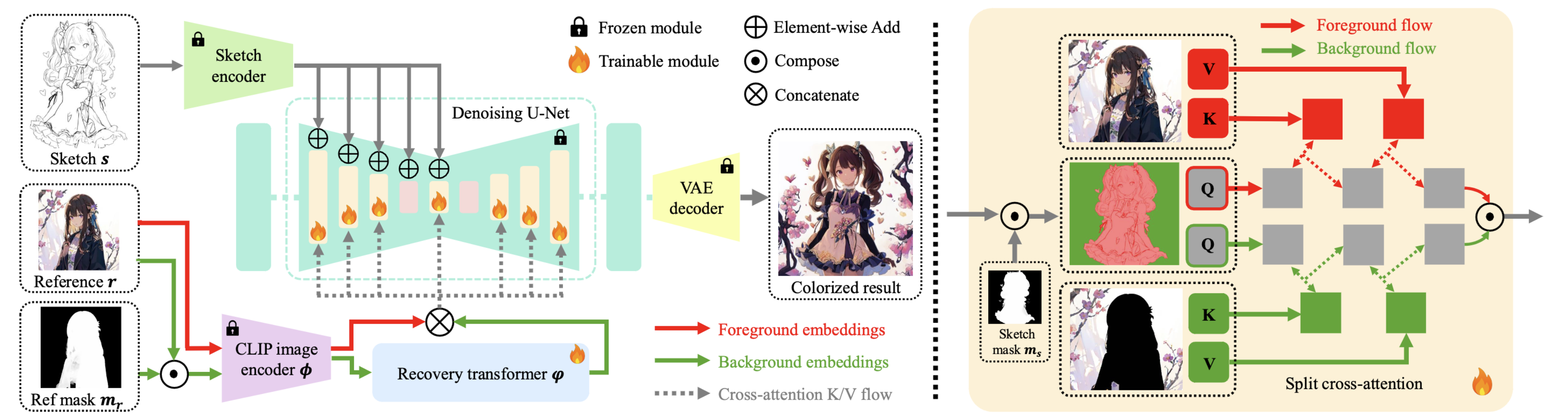
模型输入:
sketch image (草图,线稿): X s ∈ R w s × h s × 1 X_s \in \mathbb{R}^{w_s \times h_s \times 1} Xs∈Rws×hs×1
reference image (参考图像,想要绘制的风格): X r ∈ R w r × h r × c X_r \in \mathbb{R}^{w_r \times h_r \times c} Xr∈Rwr×hr×c
spatial mask (指示参考图的前景区域): X m ∈ R w s × h s × 1 X_m \in \mathbb{R}^{w_s \times h_s \times 1} Xm∈Rws×hs×1
(后面在方法里提及到,mask是通过SkyTNT/anime segmentation这个工具实现得到的)
模型输出着色结果: Y ∈ R w s × h s × c Y \in \mathbb{R}^{w_s \times h_s \times c } Y∈Rws×hs×c
颜色参考图会由ViT编码为embedding,并随后插入带有分离交叉注意力层的diffusion框架中,作为颜色参考信息。线稿草图将通过多层sketch encoder编码后加入diffusion框架中,作为空间引导。分离交叉注意力层可以将可训练的LoRA模块根据key和value划分为前景训练区域和背景训练区域,以模拟画师画画时,将前景和背景分开来画的习惯。最后,在模型的推理阶段使用了一个可切换的LoRA机制,用于具有不同颜色模式的应用场景。
补充材料里有模型的进一步细节,如下面图所示,原来的Unet部分的参数是冻结了,然后层间加入的带有split cross-attention的Transformer模块,从这个结构图可以看出,sketch草图像是模型的输入,而sketch mask以及颜色参考图的前后景embedding更像是注入的条件。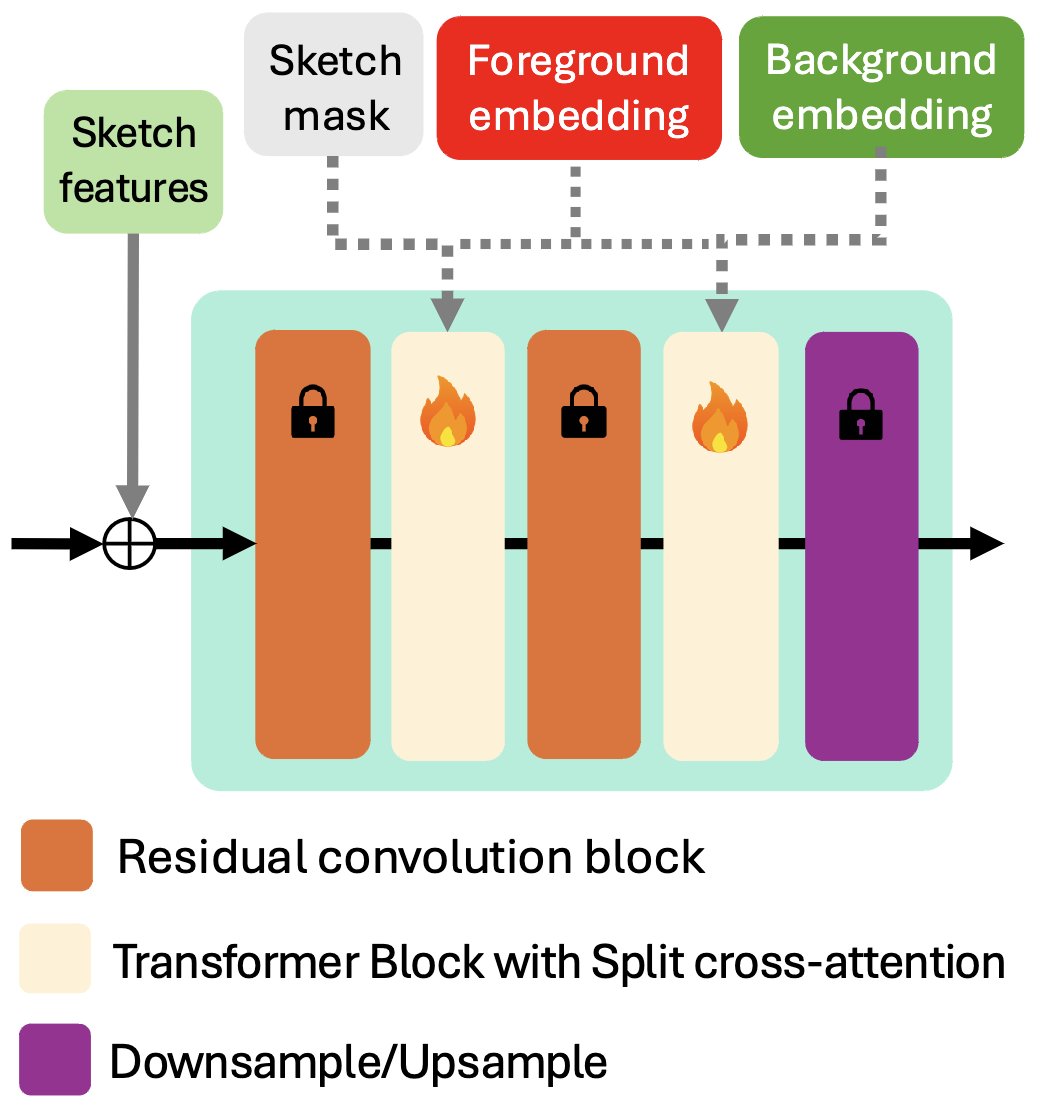
Backbone
模型组成:
VAE: 预训练,记为 E \mathcal{E} E
U-Net: diffusion去噪模块,记为 θ \theta θ, VAE和Unet都使用WaiduDiffusion中的模型进行初始化。
sketch encoder:预训练
ViT: 预训练,基于OpenCLIP-H,作为参考图的image encoder,记为 ϕ \phi ϕ
线稿草图,参考图,和实际真值分别记做 s , r s,r s,r和 y y y。
训练目标(预测 z t z_t zt中加入的噪声): L ( θ ) = E E ( y ) , ϵ , t , s , r [ ∥ ϵ − ϵ θ ( z t , t , s , ϕ ( r ) ) ∥ 2 2 ] \mathcal{L}(\theta)=\mathbb{E}_{\mathcal{E}(y),\epsilon,t,s,r}[\left\| \epsilon - \epsilon_{\theta}(z_t,t,s,\phi(r)) \right\|^{2}_2] L(θ)=EE(y),ϵ,t,s,r[∥ϵ−ϵθ(zt,t,s,ϕ(r))∥22].
模型训练时,参考图丢弃率会从80%到50%开始降低,防止出现分布偏移 (到底是reference的重要性越来越大还是越来越小?应该是越来越大) ,VAE,U-Net和sketch encoder是冻结的。
提取颜色参考
基于ViT的图像编码器会产生CLS(可优化的,全局的信息)embedding和局部embedding,在现有方法中,CLS embedding会投影到CLIP空间进行图像-文本对比学习,空间信息会被压缩,并与文本级别概念连接以用作颜色和风格的指导。而ColorizeDiffusion这篇论文认为local embedding也可以表示文本级语义,可以表征纹理,笔划,风格,颜色信息,本文模型也参照该思想,采用local token作为颜色参考输入。不过,由于图像中的空间信息过于丰富,而我们更想要颜色,风格信息,这些过度的信息可能导致artifacts,还有物体外不期望的区域出现着色,为了消除这一影响,在着色过程中将利用空间mask把图像显式了分成前景和背景两部分。
分离交叉注意力机制
分离交叉注意力机制替换了diffusion中的标准cross-attention层,用不同的参数分别处理前景区域和背景区域的着色。
一个分离交叉注意力层包括两组可训练LoRA权重 W f t W^{t}_f Wft和 W b t W^{t}_b Wbt,其分别含有query,key和value的权重参数矩阵,分别记做 W f q , W f k , W f v W^{q}_f,W^{k}_f,W^{v}_f Wfq,Wfk,Wfv和 W b q , W b k , W b v W^{q}_b,W^{k}_b,W^{v}_b Wbq,Wbk,Wbv。SkyTNT/anime segmentation被用来对草图和参考图分割前景区域的mask m s m_s ms和 m r m_r mr,可以通过调整相关阈值 t s s ts_s tss和 t s r ts_r tsr决定遮罩范围,大于被认为是前景区域,小于会被认为是背景区域。前景物体的LoRA矩阵秩设置为16,背景LoRA的秩设置为 r = 0.5 ∗ m i n ( D q , D k v ) r=0.5*min(D_q,D_{kv}) r=0.5∗min(Dq,Dkv).( D q , D k v D_q,D_{kv} Dq,Dkv是,query, key*value矩阵的维度)。
由于将不同颜色,纹理分布的背景和前景区域特征直接加入分离交叉注意力机制中会带来结构上的恶化,因此针对背景embedding,作者额外设计了一个恢复transformer φ \varphi φ,使得其能够和前景参考信息更好地聚合入diffusion中。
具体的注意力机制方面,将输入特征 z f , z b z_f,z_b zf,zb定义为query(线稿图的相关特征),将整体参考图的embedding e = ϕ ( r ) e=\phi(r) e=ϕ(r)作为key,将参考图背景区域的embedding e b = φ ( ϕ ( r b ) ) e_b=\varphi(\phi(r_b)) eb=φ(ϕ(rb))作为value.
记 y y y为split cross-attention的结果,其计算方式:
y = { softmax ( ( W ^ f q z f ) ⋅ ( W ^ f k e ) d ) ( W ^ f v e ) i f m s > t s s softmax ( ( W ^ b q z b ) ⋅ ( W ^ b k e b ) d ) ( W ^ b v e b ) i f m s ⩽ t s s y=\begin{cases} \text{softmax}(\frac{(\hat{W}^{q}_f z_f)\cdot (\hat{W}^{k}_f e)}{d})(\hat{W}^{v}_f e) \quad if \ \ m_s > ts_s \\ \text{softmax}(\frac{(\hat{W}^{q}_b z_b)\cdot (\hat{W}^{k}_b e_b)}{d})(\hat{W}^{v}_b e_b) \quad if \ \ m_s \leqslant ts_s \\ \end{cases} y=⎩
⎨
⎧softmax(d(W^fqzf)⋅(W^fke))(W^fve)if ms>tsssoftmax(d(W^bqzb)⋅(W^bkeb))(W^bveb)if ms⩽tss
其中, W ^ f t = W t + W f t \hat{W}^{t}_{f}=W^t + W^{t}_f W^ft=Wt+Wft, W t W^t Wt代表预训练的权重, W ^ b t \hat{W}^t_b W^bt的定义类似。
可切换推理模式
事实上简单地将着色划分为前景和背景区域可能在参考图像和线稿图语义大相径庭,或者背景特别复杂时,不能取得理想效果。因此,设计了三种推理模式:Vanilla, Bg2Fig, Fig2Fig。
Vanilla模式将仅依赖交叉注意力的预训练权重,恢复Transformer中的 W f t W^{t}_f Wft和 W b t W^{t}_b Wbt没有激活。不过当参考图仅含有人物时,他并不适用(就是说是风景画时,非常适合)。
Bg2Fig模式将仅激活前景相关的LoRA权重 W f t W^{t}_f Wft,在参考图像中有人物,并且背景非常复杂时比较适用。
Fig2Fig模式专为人物到人物的着色,即参考图是人物,且背景比较简单。在该模式下,前后景的LoRA权重 W f t W^{t}_f Wft和 W b t W^{t}_b Wbt都会被激活。该模式可以有效消除人物着色时的空间紊乱问题。
实验
实验细节
数据集: Danbooru2021, 其中选择480万个(sketch, color, mask)三元组作为训练集,5万个作为验证。sketch通过技术手段获取,使用4个H100 GPU进行训练。第一阶段训练时,对U-Net和sketch encoder进行了6轮训练,每轮8小时,然后冻结,之后对恢复transformer和可切换LoRA进行3轮训练,每轮9小时。
消融实验
关于分离交叉注意力:
设置1: baseline,没有分离交叉注意力,LoRA和恢复transformer
设置2: baseline + split cross-attention, 没有LoRA和恢复transformer
设置3: full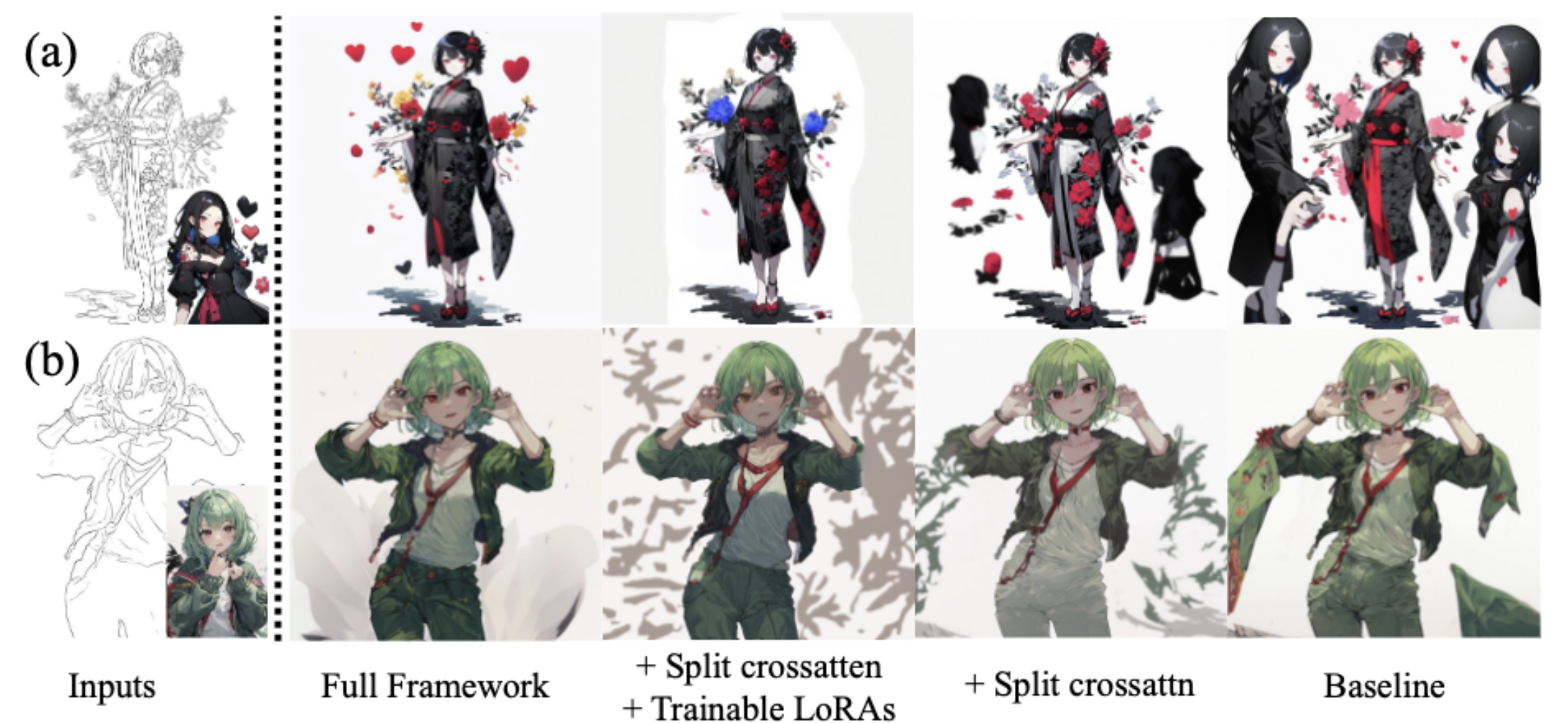
实验结果如上图显示,baseline的结果a多出了好几个类似参考图像的人物,b中人物的衣服不应该有额外拓展。加上分离交叉注意力后,紊乱得到缓解,但是依旧存在,并且颜色饱和度还下降了,加入LORA可以提升颜色质量,全模型的效果最佳。
关于推理模式:
针对不同的推理模式,作者设计了两个案例并进行了实验,下面给出实验结果。
a案例可以看出,Fig2Fig不容易生成紊乱的东西,但是对于人物部分的上色能力会稍差,b案例证明了Vanilla,Bg2Fig两种模式都可以很好地给背景上色。
对比实验
Qualitative result
选择对比的模型有的基于Stable Diffusion,有的基于ControlNet,有的基于IP-Adapter,还有T2I-Adapter等。下面就放上实验结果(论文的图8)。
这个具体的文字表述不再细说。上面的实验例子都是给出人物的sketch,参考图还是人物,还是有一定的语义联系,下面的实验结果,是关于sketch和reference没有任何语义联系的例子(论文的图9)。
(感觉就是IP-Adapter和T2I-Adapter图像的颜色就和reference不太一样了)
Quantitative result
FID计算:将生成图像和50000个验证集进行对比计算感知距离。
多尺度结构相似度指数度量(MS-SSIM),峰值信噪比(PSNR),CLIP Score等指标来衡量生成结果图像和ground truth的相似度。(FID不需要语义上对齐,但是剩下说到的这些指标要求对齐),以下呈现出相关结果(论文表1,其实总共也就一张表格,):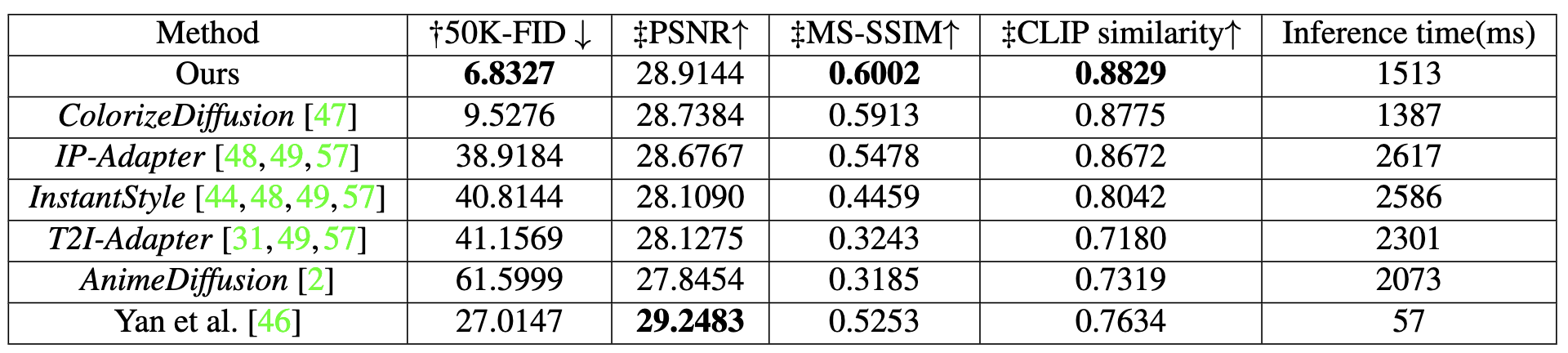
(有点不太确定这个CLIP score,感觉有点过高,因为自己读到的论文,CLIP这个指标很难超过0.4,有无大佬可以详细为我解释。)
User Study
(过去我一直以为这一部分主观性强不重要,但是其实user study是目前度量主观结果的最佳方式,如果怕不严谨,把实施的细节讲清楚,user study使用到的图片全部放入附录中,是可以接受,甚至对于生成任务来说是很重要的)
作者的user study邀请了40位参与者,针对总体上色质量和线稿图几何形状保留程度两个方面进行度量。具体地,准备了25个图像集,给每个参与者16个图像集做度量,每个图像集都包括6个现有方法生成的图像。实验结果呈现如下: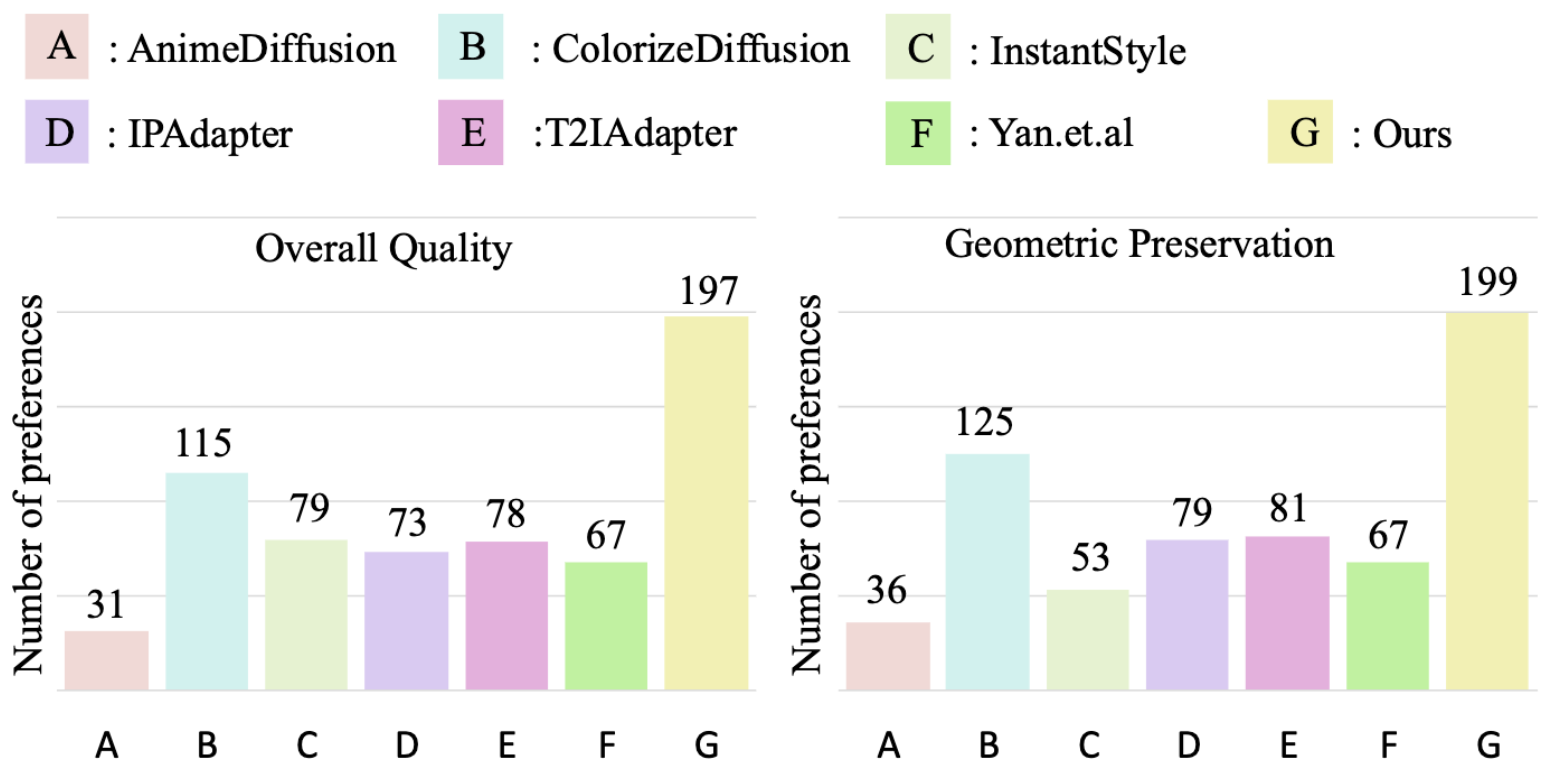

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)