ELK日志分析(一):Elasticsearch、Logstash安装配置,连接方法,全流程讲解与实操
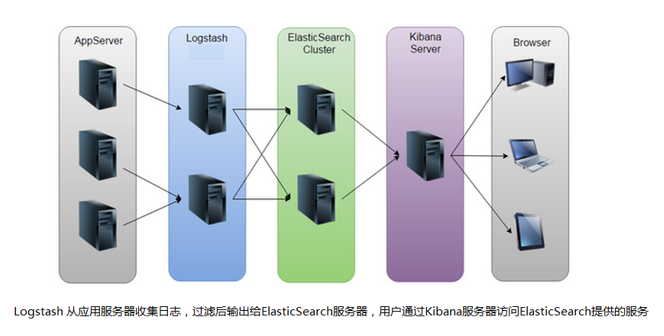
ELK(Elasticsearch+Logstash+Kibana)是一套开源的日志分析系统。Elasticsearch作为分布式搜索引擎和数据库,Logstash负责日志收集与过滤,Kibana提供图形化展示。部署ELK需要准备4台服务器,配置静态IP、关闭防火墙和SELinux、时间同步等基础环境。Elasticsearch集群部署需注意节点类型、分片设置和硬盘空间管理。Logstash通过输
目录
一、认识ELK
ELK是一套开源的日志分析系统,由elasticsearch+logstash+Kibana组成。
官网说明:https://www.elastic.co/cn/products
首先: 先一句话简单了解E,L,K这三个软件
elasticsearch: 分布式搜索引擎,也是数据库
logstash: 日志收集与过滤,输出给elasticsearch
Kibana: 图形化展示
elk下载地址:https://www.elastic.co/cn/downloads
1.1.ELK环境准备:
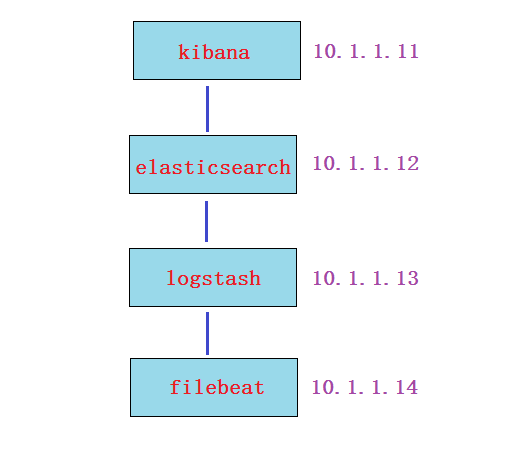
四台机器(内存建议大于1G,比如1.5G; filebeat服务器可为1G) :
1,静态IP(要求能上公网,最好用虚拟机的NAT网络类型上网)
2,主机名及主机名绑定

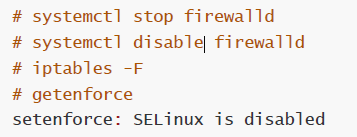
3, 关闭防火墙和selinux
# systemctl stop firewalld
# systemctl disable firewalld
# iptables -F
# getenforce
setenforce: SELinux is disabled
4, 时间同步
时间同步服务器设置
# vim /etc/ntp.conf
![]()
在最后添加内容
server 127.127.1.0
fudge 127.127.1.0 stratum 10
# systemctl restart ntpd

时间同步客户端设置
# ntpdate 192.168.136.10
![]()
二、elasticsearch部署
2.1.elasticsearch简介:
Elasticsearch(简称ES)是一个开源的分布式搜索引擎,Elasticsearch还是一个分布式文档数据库。所以它提供了大量数据的存储功能,快速的搜索与分析功能。
2.2.elasticsearch基础概念:
主要的基础概念有:Node, Index,Type,Document,Field,shard和replicas.
Node(节点):运行单个ES实例的服务器
Cluster(集群):一个或多个节点构成集群
Index(索引):索引是多个文档的集合
Type(类型):一个Index可以定义一种或多种类型,将Document逻辑分组
Document(文档):Index里每条记录称为Document,若干文档构建一个Index
Field(字段):ES存储的最小单元
Shards(分片):ES将Index分为若干份,每一份就是一个分片
Replicas(副本):Index的一份或多份副本
为了便于理解,我们和mysql这种关系型数据库做一个对比:
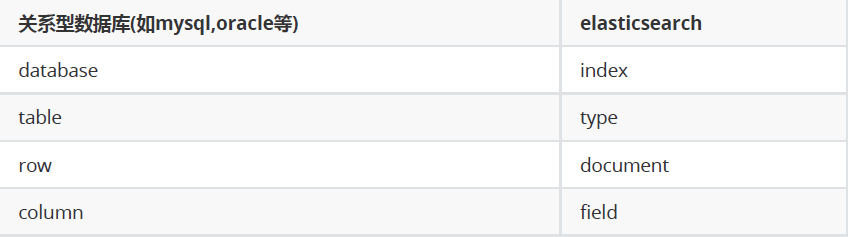
ES是分布式搜索引擎,每个索引有一个或多个分片(shard),索引的数据被分配到各个分片上。你可以看作是一份数据分成了多份给不同的节点。
当ES集群增加或删除节点时,shard会在多个节点中均衡分配。默认是5个primary shard(主分片)和1个replica shard(副本,用于容错)。
2.3.安装elasticsearch:
第1步: 在elasticsearch服务器上安装jdk(不要使用系统自带openjdk)
卸载旧版本jdk,安装高版本jdk
# rpm -ivh jdk-8u291-linux-x64.rpm
# java -version

第2步: es的安装,配置
# rpm -ivh elasticsearch-6.5.2.rpm
![]()
第3步: 单机es的配置与服务启动
# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: elk_cluster
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
![]()

# systemctl start elasticsearch
# systemctl enable elasticsearch

#启动需要1-2分钟
# netstat -anpt | grep java

9200则是数据传输端口
9300端口是集群通信端口
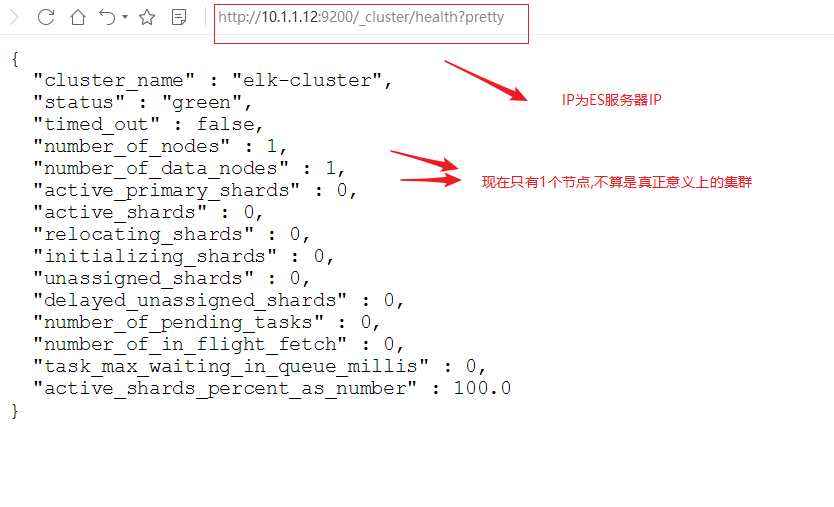
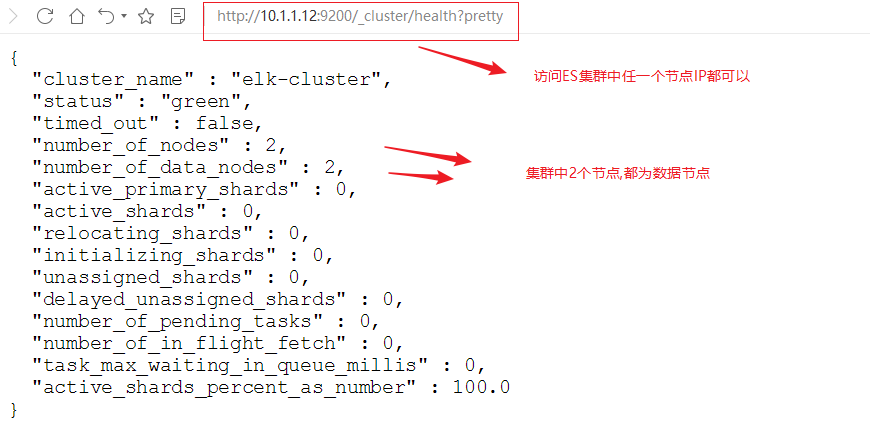
第4步: 查看状态
使用curl命令或浏览器访问http://10.1.1.12:9200/_cluster/health?pretty地址(IP为ES服务器IP)
curl http://10.1.1.12:9200/_cluster/health?pretty
![]()
2.4.elasticsearch集群部署:
集群部署主要注意以下几个方面
1. 集群配置参数:
discovery.zen.ping.unicast.hosts,Elasticsearch默认使用Zen Discovery来做节点发现机制,推荐使用unicast来做通信方式,在该配置项中列举出Master节点。
discovery.zen.minimum_master_nodes,该参数表示集群中Master节点可工作Master的最小票数,默认值是1。为了提高集群的可用性,避免脑裂现象。官方推荐设置为(N/2)+1,其中N是具有Master资格的节点的数量。
discovery.zen.ping_timeout,表示节点在发现过程中的等待时间,默认值是30秒,可以根据自身网络环境进行调整,一定程度上提供可用性。
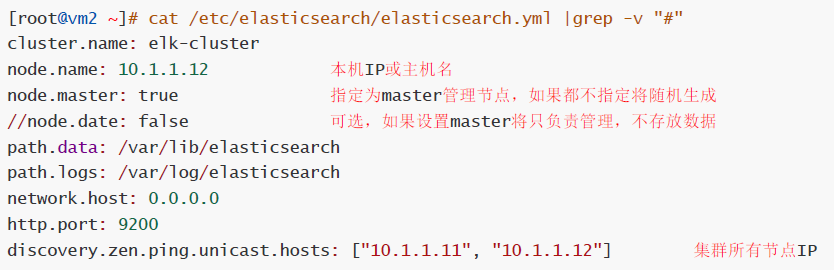
2. 集群节点:
节点类型主要包括Master节点和data节点。通过设置两个配置项node.master和node.data为true或false来决定将一个节点分配为什么类型的节点。
尽量将Master节点和Data节点分开,通常Data节点负载较重,需要考虑单独部署。
3. 硬盘空间:
Elasticsearch默认将数据存储在/var/lib/elasticsearch路径下,随着数据的增长,一定会出现硬盘空间不够用的情形,大环境建议把分布式存储挂载到/var/lib/elasticsearch目录下以方便扩容。
配置参考文档: https://www.elastic.co/guide/en/elasticsearch/reference/index.html
首先在ES集群所有节点都安装ES(步骤省略)
可以使用两台或两台以上ES做集群, 以下就是两台ES做集群的配置
# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#"
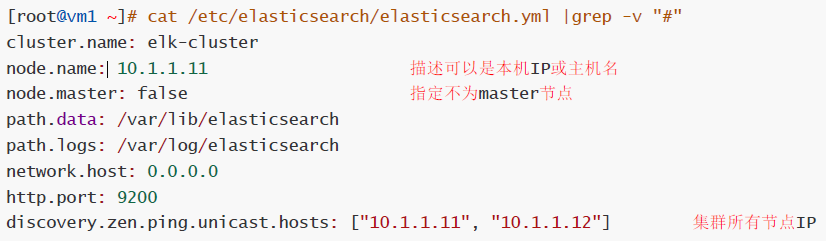
# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#"
启动或重启服务
# systemctl restart elasticsearch
# systemctl enable elasticsearch
# systemctl restart elasticsearch
查看状态
2.5..elaticsearch基础API操作:
前面我们通过http://10.1.1.12:9200/_cluster/health?pretty查看ES集群状态,其实就是它的一种API操作。
API(Application Programming Interface)应用程序编程接口,就是无需访问程序源码或理解内部工作机制就能实现一些相关功能的接口。
RestFul API 格式
curl -X<verb> ‘<protocol>://<host>:<port>/<path>?<query_string>’-d ‘<body>’ 
更多API参考:https://www.elastic.co/guide/en/elasticsearch/reference/6.2/index.html
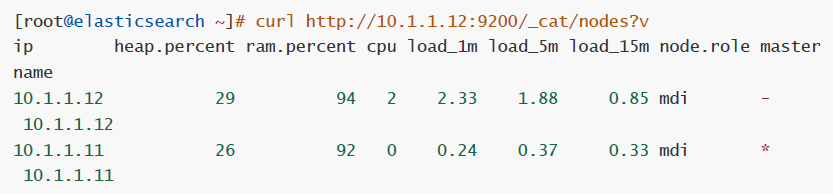
查看节点信息
通过curl或浏览器访问http://10.1.1.12:9200/_cat/nodes?v(ip为ES节点IP,如果有ES集群,则为ES任意节点IP),主要看master在哪(node.role master)
# curl http://10.1.1.12:9200/_cat/nodes?v

查看索引信息
通过curl或浏览器访问http://10.1.1.12:9200/_cat/indices?v
# curl http://10.1.1.12:9200/_cat/indices?v

新增索引
# curl -X PUT http://10.1.1.12:9200/nginx_access_log 
# curl http://10.1.1.12:9200/_cat/indices?v


green:所有的主分片和副本分片都已分配。你的集群是100%可用的。
yellow:所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把yellow 想象成一个需要及时调查的警告。
red:至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
删除索引
# curl -X DELETE http://10.1.1.12:9200/nginx_access_log

三、logstash
3.1.logstash简介:
logstash是一个开源的数据采集工具,通过数据源采集数据.然后进行过滤,并自定义格式输出到目的地。
数据分为:
1. 结构化数据 如:mysql数据库里的表等
2. 半结构化数据 如: xml,yaml,json等
3. 非结构化数据 如:文档,图片,音频,视频等
logstash可以采集任何格式的数据,当然我们这里主要是讨论采集系统日志,服务日志等日志类型数据。
官方产品介绍:https://www.elastic.co/cn/products/logstash
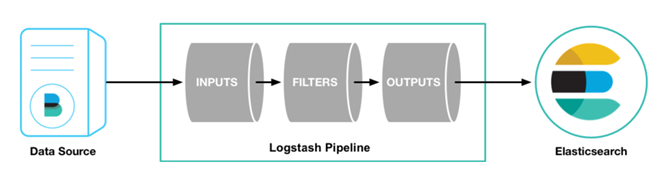
input插件: 用于导入日志源 (==配置必须==)
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
filter插件: 用于过滤(==不是配置必须的==)
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
output插件: 用于导出(==配置必须==)
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
3.2.logstash部署:
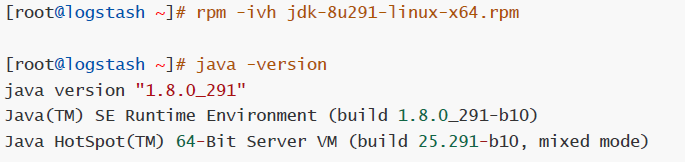
在logstash服务器上确认openjdk安装
卸载自带jdk,安装高版本jkd
# rpm -ivh jdk-8u291-linux-x64.rpm
# java -version
在logstash服务器上安装logstash
# rpm -ivh logstash-6.5.2.rpm
![]()
配置logstash主配置文件
# cat /etc/logstash/logstash.yml |grep -v '#' |grep -v '^$'

启动测试
# cd /usr/share/logstash/bin
![]()
使用下面的空输入和空输出启动测试一下
# ./logstash -e 'input {stdin {}} output {stdout {}}' ![]()
#-e:后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出)
#-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash
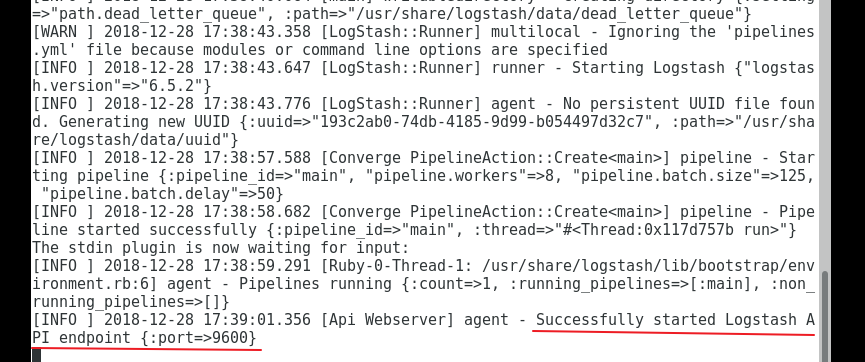
关闭启动,测试能启动成功后,ctrl+c取消,则关闭了
另一种验证方法:
上述测试还可以使用如下方法进行:
# vim /etc/logstash/conf.d/test.conf
input {
stdin {
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
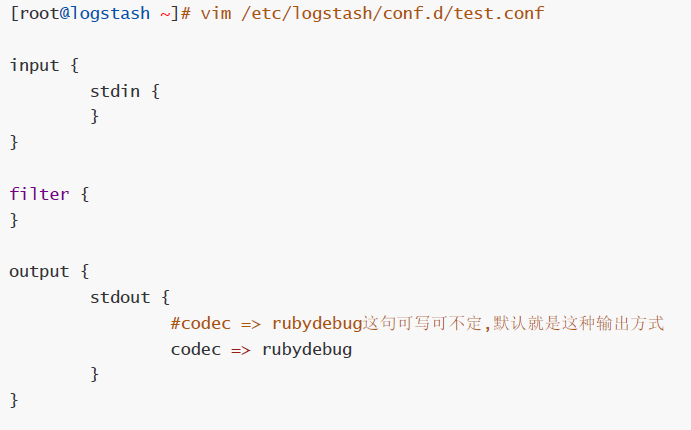
# ./logstash --path.settings /etc/logstash -f /etc/logstash/conf.d/test.conf

--path.settings 指定logstash主配置文件目录
-f 指定子配置文件
-t 测试配置文件是否正确
# ./logstash --path.settings /etc/logstash -f /etc/logstash/conf.d/test.conf
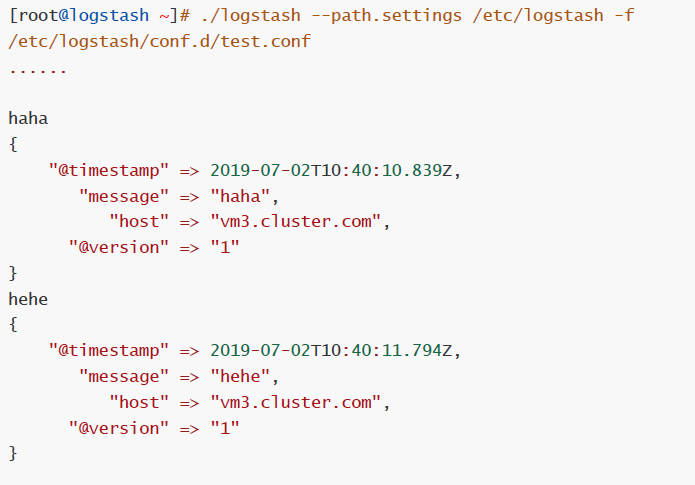
3.3.日志采集:
采集messages日志
这里以/var/log/messages为例,只定义input输入和output输出,不考虑过滤
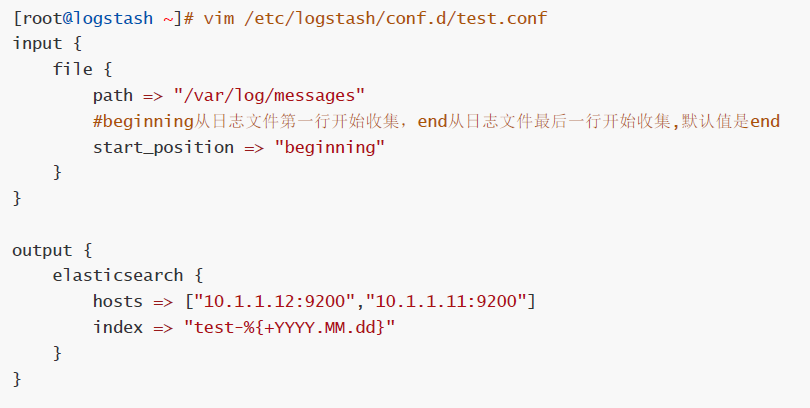
# vim /etc/logstash/conf.d/test.conf
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["10.1.1.12:9200","10.1.1.11:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
# ./logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/test.conf

验证
# curl http://192.168.136.20:9200/_cat/indices?v
![]()
3.4.采集多日志源:
# vim /etc/logstash/conf.d/test.conf
input {
file {
path => "/var/log/messages"
start_position => "beginning"
type => "messages"
}
file {
path => "/var/log/yum.log"
start_position => "beginning"
type => "yum"
}
}
filter {
}
output {
if [type] == "messages" {
elasticsearch {
hosts => ["10.1.1.12:9200","10.1.1.11:9200"]
index => "messages-%{+YYYY-MM-dd}"
}
}
if [type] == "yum" {
elasticsearch {
hosts => ["10.1.1.12:9200","10.1.1.11:9200"]
index => "yum-%{+YYYY-MM-dd}"
}
}
}

下文续作:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)