大模型开发宝典:从RAG到Agent的实战指南,建议永久收藏
大模型开发宝典:从RAG到Agent的实战指南,建议永久收藏
2025 年更被视为 AI 技术爆发的奇点之年。如果你也和我一样,坚信 AI 将重塑现代产品的形态与未来,那么此刻正是我们共同踏上这辆时代快车的最佳时机。
然而面对层出不穷的 AI 技术浪潮,许多人与我有着相同的困惑:当 GPT、LLM、RAG、Agent 等术语如暴雨般袭来,我们该如何穿透概念的迷雾,真正理解这些技术的内在关联?又该如何构建系统化的认知框架,避免陷入“只见树木不见森林”的困境?
为此,我尝试梳理出一条“以应用为导向”的学习路径:
- 建立技术地图:理清生成式AI(AIGC)、大语言模型(LLM)、检索增强(RAG)等技术间的层级关系;
- 守卫认知边界:明确每个技术模块解决的问题边界,防止陷入无限延展的知识黑洞;
- 聚焦学以致用:始终以“解决实际问题”为锚点,让知识获取直接服务于场景化应用。
只有将碎片化的技术点串联成可落地的系统认知,我们才能在 AI 浪潮中保持清醒——既不做盲目追逐热点的“工具收藏家”,也不做纸上谈兵的“理论空想者”。让我们共同开启这场“从认知到实践”的 AI 进化之旅。
一、AI行业架构
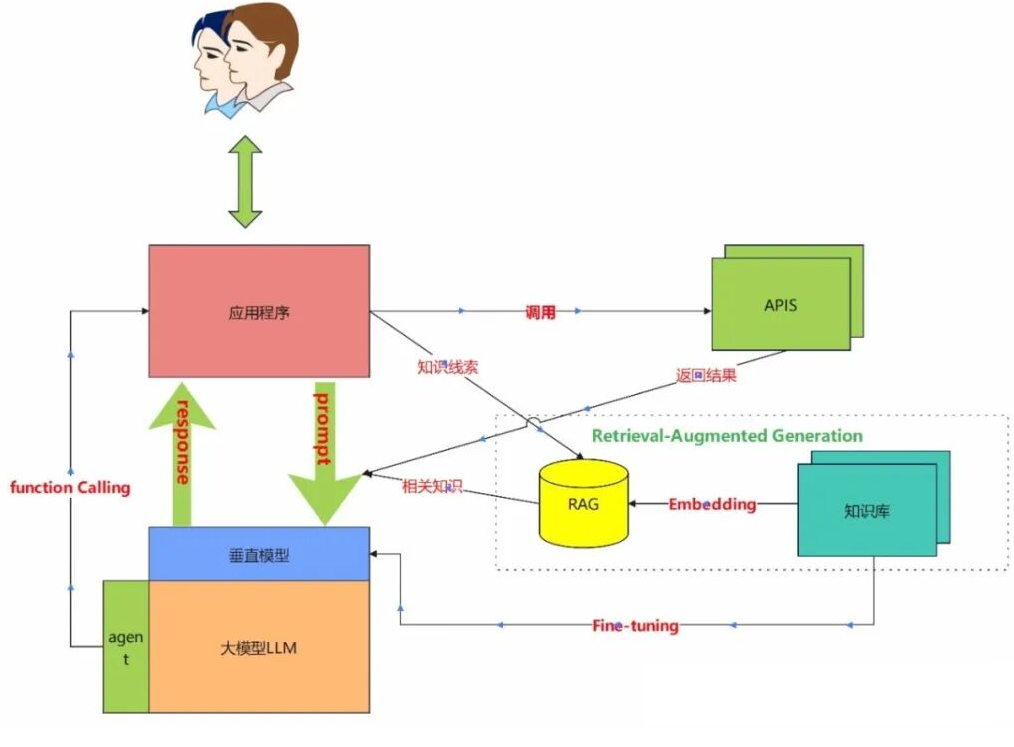
以上是一张几乎所有大模型应用系统搭建的标准架构图,需要图片的朋友可以私信我,下面我就图中涉及到的技术内容进行一一介绍。
1、 基础认知:训练阶段 vs 推理阶段
| 阶段 | 定义 | 技术特点 | 行业应用案例 |
| 训练阶段 | 模型通过海量数据学习规律的过程 | ▶ 基座模型(如GPT-4)预训练 ▶ 行业数据微调(Fine-tuning) ▶ 高算力消耗 | 金融风控模型训练 |
| 推理阶段 | 模型运用所学知识解决问题的过程 | ▶ 加载训练好的参数 ▶ 实时响应用户输入 ▶ 低延迟要求 | 智能客服对话场景 |
示例说明:
银行基于LLaMA基座模型,使用内部客户服务记录和金融法规数据进行微调,生成专属的「智能投顾模型」。当用户咨询理财建议时(推理阶段),模型会结合历史学习成果生成合规答复。
2、问题 1:模型幻觉(Hallucination)
定义:模型生成看似合理但实际错误或虚构的内容行业痛点:
-
医疗领域可能输出错误药品剂量
-
法律咨询可能编造不存在的法条
3、问题 2:语义理解偏差
1. 传统微调模式的局限
- 数据更新延迟:金融政策变化后需重新训练模型
- 冷启动困境:新业务线缺乏足够训练数据时效果差
2.RAG(检索增强生成)技术突破

技术优势对比
| 维度 | 传统微调 | RAG方案 |
| 知识更新时效 | 周/月级 | 分钟级 |
| 实施成本 | 需GPU集群重训练 | 仅需文本嵌入(Embedding) |
| 可解释性 | 黑箱操作 | 检索路径可追溯 |
| 典型场景 | 长期稳定的业务规则 | 政策频繁变更的税务咨询 |
4、最佳实践:混合架构解决方案
# 伪代码示例:金融客服系统工作流
def generate_answer(user_query):
# 第一步:RAG实时检索
rag_results = vector_db.search(user_query, top_k=3)
# 第二步:动态提示词构建
enhanced_prompt = f"""
你是一名资深银行顾问,请根据以下最新资料回答问题:
{rag_results}
用户问题:{user_query}
回答要求:使用简体中文,避免专业术语,标注数据来源
"""
# 第三步:大模型生成
final_answer = llm.generate(enhanced_prompt, temperature=0.3)
return add_disclaimer(final_answer) # 添加风险提示
5、 总结
- 动态知识管理:RAG将大模型从"静态知识库"转变为"实时信息中介"
- 成本平衡艺术:基座模型微调(沉淀核心能力)+ RAG(应对高频变化)的混合架构将成为行业标配
- 可信AI实践:通过检索溯源机制,使生成内容具备可验证性,符合金融/医疗等强监管领域要求
二、从单一问答到智能决策:Agent 技术演进
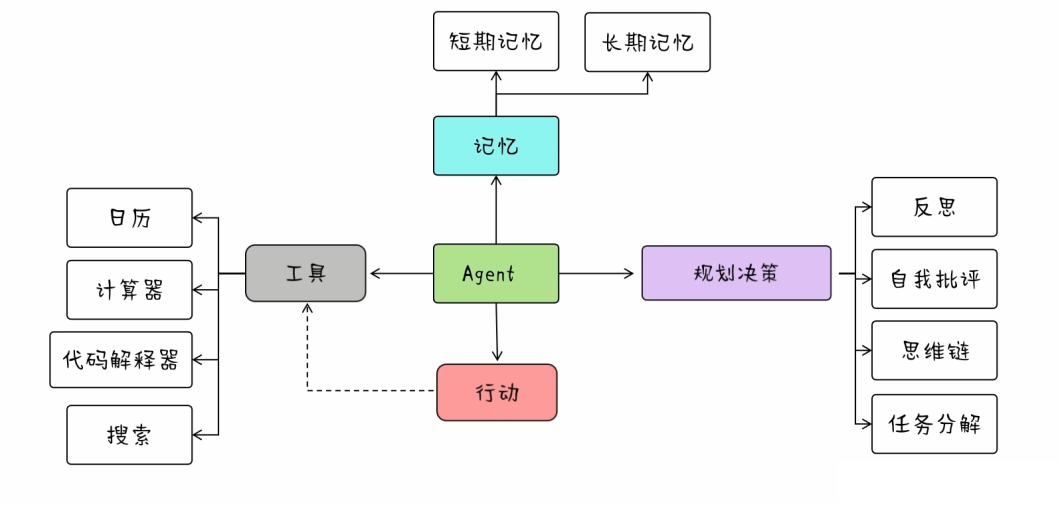
1、场景升级:从问答机器人到服务中枢
当企业需要提供跨系统的一站式服务(如同时处理天气查询、航班改签、酒店预订)时,传统问答流程面临两大瓶颈:
-
机械式流程缺陷:预设的线性Workflow无法应对用户意图的跳跃性变化
-
工具协同困境:多个功能模块间缺乏智能调度中枢
用户说:“帮我查明天北京飞上海的早班机,选靠窗座位,再预订外滩附近人均500元的餐厅” 传统Workflow:需要用户分步选择航班查询→座位选择→餐厅筛选 Agent方案:自动识别三个子任务,并行调用航司API、座位图数据库、美食平台接口
2、技术突破:Agent 核心能力解析
Agent vsWorkflow差异
| 维度 | Workflow | Agent |
| 决策模式 | 预设路径执行 | 动态推理生成 |
| 容错能力 | 依赖完整流程设计 | 支持异常状态自主修复 |
| 扩展成本 | 新增功能需重构流程 | 工具注册即插即用 |
| 交互体验 | 需用户明确指令 | 支持模糊语义意图揣摩 |
3、系统架构:多轮对话智能体设计
class ConversationAgent:
def __init__(self):
self.memory = VectorDatabase() # 对话历史向量存储
self.tools = ToolRegistry() # 注册工具集(航班/酒店/支付等API)
def process_query(self, user_input: str):
# 阶段1:上下文增强
context = self.memory.search(user_input, top_k=5)
augmented_input = f"历史对话:{context}\n当前问题:{user_input}"
# 阶段2:工具调用决策
tool_decision = llm.generate(f"""
请根据用户需求选择工具,输出JSON:
{{
"tool_name": "航班查询|酒店预订|...",
"parameters": {{"departure": "上海", "date": "2024-03-20"...}}
}}
""")
# 阶段3:执行并生成回复
api_result = self.tools.execute(tool_decision)
final_response = llm.generate(f"用口语化中文解释:{api_result}")
# 阶段4:记忆更新
self.memory.save(user_input, final_response)
return final_response
4、 延伸思考:上下文持久化挑战
当用户说"修改我刚订的酒店入住日期"时,Agent需要:
- 从对话历史中检索最近一次酒店订单ID
- 调用订单系统API验证可修改条件
- 联动日历工具检查新日期的房态
技术准备:
- 建立用户对话的向量化记忆库(如使用Redis+FAISS)
- 实现跨会话的状态保持机制(将在后续篇章详解)
三、Agent 与 Function Calling 技术解析
1、Agent:复杂场景的智能决策引擎
Agent通过动态语义理解与自主决策能力,将大模型转化为服务调度中枢,实现跨系统的智能协同。在用户需求涉及多步骤、多工具的场景中(如差旅规划、综合客服),Agent自动完成以下关键动作:
- 意图解构:解析复合型需求为原子任务(如"订机票+选座位+订酒店")
- 工具编排:根据上下文选择最佳执行路径(并行/串行调用API)
- 异常处理:当某服务不可用时,自动启用备用方案(如切换航司接口)
典型应用场景:
用户指令:“下周三杭州到北京的会议行程,要上午10点前到达,预算5000元内” Agent响应:
- 调用航班API筛选早班机(CA1704,08:15起飞)
- 联动地图API计算机场到会场的通勤时间
- 根据剩余预算推荐会场周边酒店
2、Function Calling:工具协同的神经网络
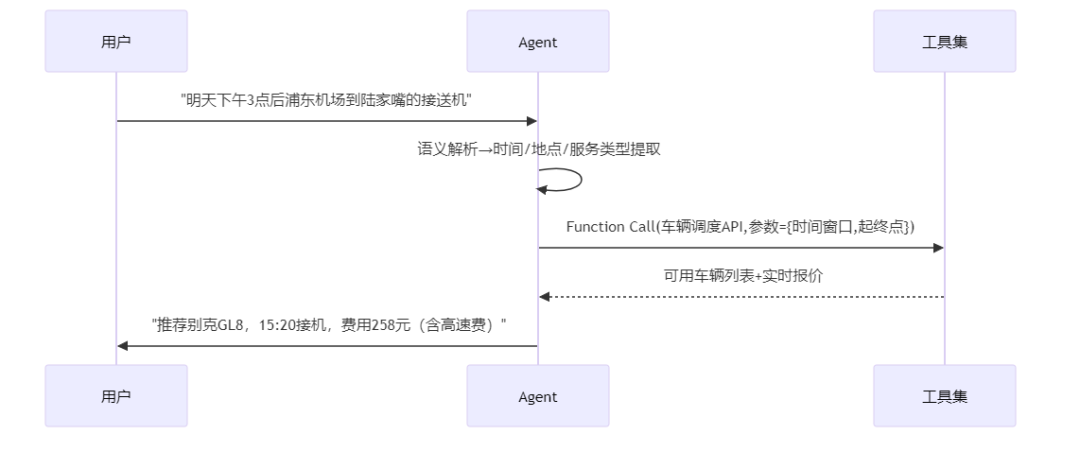
关键技术点:
- 标准化接口:通过JSON Schema定义工具输入输出规范
- 动态路由:基于语义相似度计算匹配最佳工具(如"订车"→车辆调度API)
- 异常熔断:当航班查询接口超时时,自动切换备用数据源
技术本质: 作为Agent与外部工具间的标准化协议层,Function Calling通过结构化接口定义,实现两大核心功能:
- 工具动态注册机制
{
"name": "hotel_booking",
"description": "根据位置、日期、预算筛选酒店",
"parameters": {
"location": {"type": "string", "desc": "行政区/地标名称"},
"check_in": {"type": "date", "desc": "入住日期"},
"max_price": {"type": "number", "desc": "最高单价(元)"}
}
}
- 即插即用:新增工具无需修改核心代码,注册Schema即可被Agent发现
- 语义对齐:工具描述(description)参与大模型的意图匹配计算
- 多模态数据路由
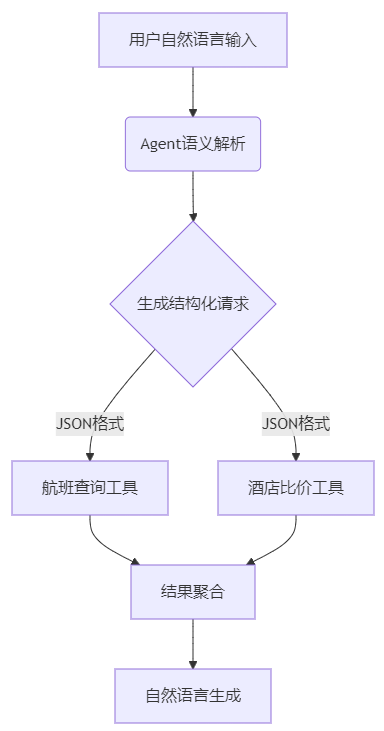
- 智能路由:基于向量相似度匹配工具功能与用户需求(如"找便宜机票"→低价航班接口)
- 异常隔离:单个工具故障不影响整体服务链(自动跳过或降级处理)
3、技术协同范式:从意图到执行
# 伪代码:会议安排Agent
def handle_user_request(query):
# Step1: 语义解析与工具匹配
tools = get_registered_tools() # 获取所有注册工具Schema
prompt = f"""
用户需求:{query}
可用工具:{json.dumps(tools)}
请输出需调用的工具名及参数(JSON格式)
"""
tool_call = llm.generate(prompt, response_format="json")
# Step2: 多工具协同执行
results = []
for tool in tool_call["tools"]:
api_result = call_api(tool["name"], tool["params"])
results.append(process_data(api_result))
# Step3: 结果整合与反馈
response_prompt = f"""
原始需求:{query}
执行结果:{results}
请生成用户友好的中文回复,突出关键信息
"""
return llm.generate(response_prompt)
4、技术演进意义
通过Agent与Function Calling的深度整合,企业服务系统实现三重跃迁:
- 从「被动应答」到「主动服务」:自动识别潜在需求(如查询航班后推荐目的地天气)
- 从「功能堆砌」到「智能融合」:有机整合离散工具,输出完整解决方案
- 从「刚性流程」到「弹性架构」:业务变更时仅需调整工具注册表,无需重构核心系统
四、开发者能力晋级路线
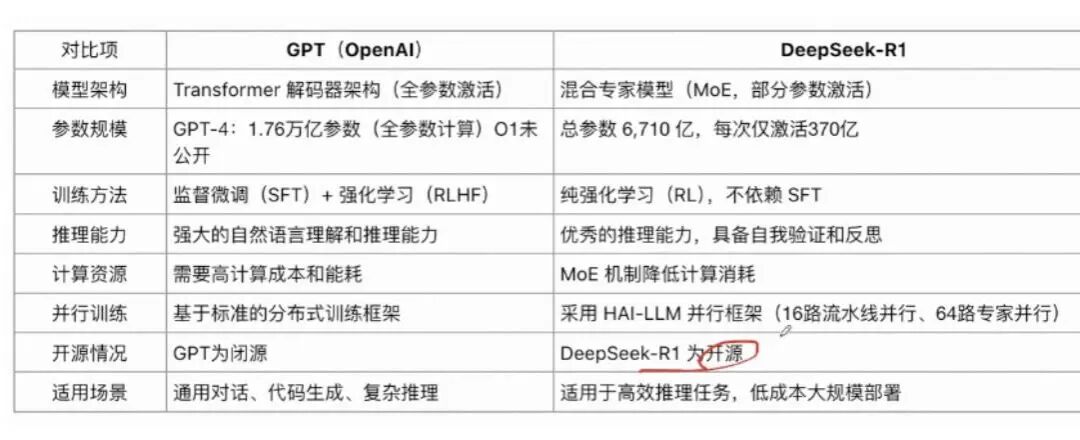
1、基座模型能力对比
2、LLM 差距的关键因素
- 技术创新与工程实现:无论是GPT的Transformer架构还是DeepSeek-R1的MoE架构,都需要在技术创新和工程实现上不断突破。例如,如何设计高效的并行训练框架、如何优化模型结构以减少计算量等,这些都是拉开差距的关键因素。
- 数据与算力资源:高质量的数据和强大的算力资源是训练大模型的基础。GPT和DeepSeek-R1在数据预处理、标注和清洗等方面都需要投入大量的人力和物力,而算力资源的充足与否直接影响到模型的训练速度和效果。
- 算法优化与调参技巧:训练大模型不仅仅是跑一遍代码那么简单,还需要在算法层面进行深入的优化和调参。例如,如何设计合适的损失函数、如何选择合适的超参数等,这些都需要丰富的经验和技巧。
- 应用场景与需求理解:不同的应用场景对模型的需求不同,因此需要针对具体场景进行定制化开发和优化。例如,对于需要高效推理的任务,DeepSeek-R1的MoE架构更具优势;而对于需要强大自然语言理解和生成能力的任务,GPT的表现更为出色。
总之,基座模型的训练是一个复杂且充满挑战的过程,需要在技术创新、工程实现、数据与算力资源、算法优化等多个方面不断努力,才能在激烈的竞争中脱颖而出。
3、AI 应用产品的潜力
AI应用开发就像在打造一个不断进化的智能生命体。开发者的核心突破口首先集中在两个关键领域——提示词工程和知识增强技术(RAG)。这相当于为AI系统安装「大脑操作系统」:通过精心设计的指令模板,我们教会AI理解业务场景中的潜台词(比如用户说"预算有限"时,自动触发成本优化算法);而RAG技术则像是给AI配备实时更新的「行业知识库」,让它能随时调取企业最新的产品手册、客户案例等专属信息,给出更精准可信的答案。
当这种能力沉淀到一定程度,就会汇聚成解决用户问题的「精准武器库」。这时候的AI不再只是机械应答,而是能根据具体场景自动组合最佳解决方案——就像经验丰富的客服专家,既能引用公司最新政策,又能结合用户历史行为给出个性化建议。这种能力不是靠单一技术实现的,而是提示词、知识库、业务规则等要素的有机融合。
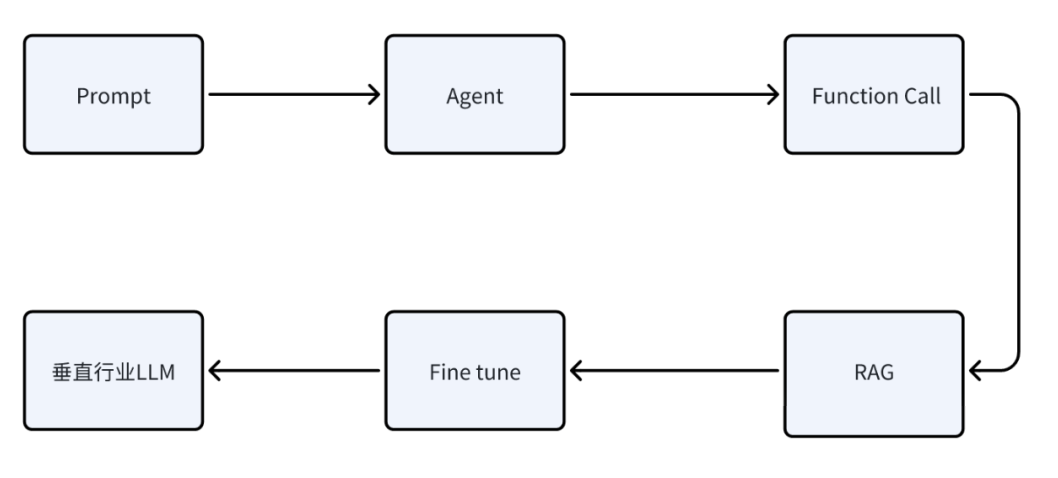
注意:深度理解原理+应用技术场景+项目实践
再往深处学习,就需要在功能调用(Function Calling) 和模型精调(Fine tune上下功夫。这相当于给AI进行"基因改造":Function Calling让AI学会使用企业的各种数字工具(比如自动调取ERP系统查库存),而模型精调则像是对AI进行专项特训,让它深度掌握行业术语和业务流程。这种升级不是简单的功能叠加,而是像游戏角色从1级升到50级——不仅是攻击力提升,而是移动速度、防御值、技能冷却等属性的全面提升,最终形成指数级的能力飞跃。
但这样的进化需要持续投入。就像培养顶尖运动员,既需要科学的训练方法(技术架构),也需要营养补给(数据喂养)和装备升级(算力支持)。当这些要素形成正向循环时,AI应用就会突破「好用」到「智慧」的临界点,真正成为推动企业增长的智能引擎。这或许就是AI时代的核心竞争力——不是拥有最强大的通用模型,而是打造出最懂自己业务的「专属智能体」。
4、最后
未来已来,在AI快速发展的时代,你我一定要做好时代的主人,是“时代的我们,还是我们的时代”完全取决你的思考能力和行动能力,未来我们每个人都会成为超级个体,首先应该从AI产品思维开始转变。
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
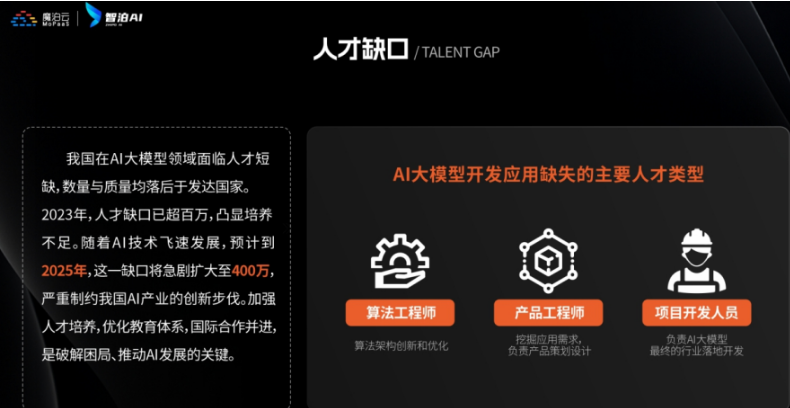
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献272条内容
已为社区贡献272条内容

所有评论(0)