技术动态 | 多模态GraphRAG的图谱构建及文档OCR多模态大模型可用合成数据集
基于IDEFICS3 架构,VIT采用siglip2-base-patch16-512(https://huggingface.co/google/siglip2-base-patch16-512)与 Granite 165M LLM,https://huggingface.co/ibm-granite/granite-docling-258M,https://docling-project.gi
转载公众号 | 老刘说NLP
继续看技术,一个是文档多模态小模型Granite Docling 258M及合成数据集,这是目前训练多模态文档解析模型可以用的数据。
另一个,再看多模态GraphRAG的思路,再温故知新下怎么基于文档解析的结果,组织构成为一个Graph形式。
多总结,多归纳,多从底层实现分析逻辑,会有收获。
一、文档多模态小模型Granite Docling 258M及合成数据集
来看文档多模态进展,Granite Docling 258M,基于IDEFICS3 架构,VIT采用siglip2-base-patch16-512(https://huggingface.co/google/siglip2-base-patch16-512)与 Granite 165M LLM,https://huggingface.co/ibm-granite/granite-docling-258M,https://docling-project.github.io/docling/#features,针对不同的ocr任务,采用不同的instruction:
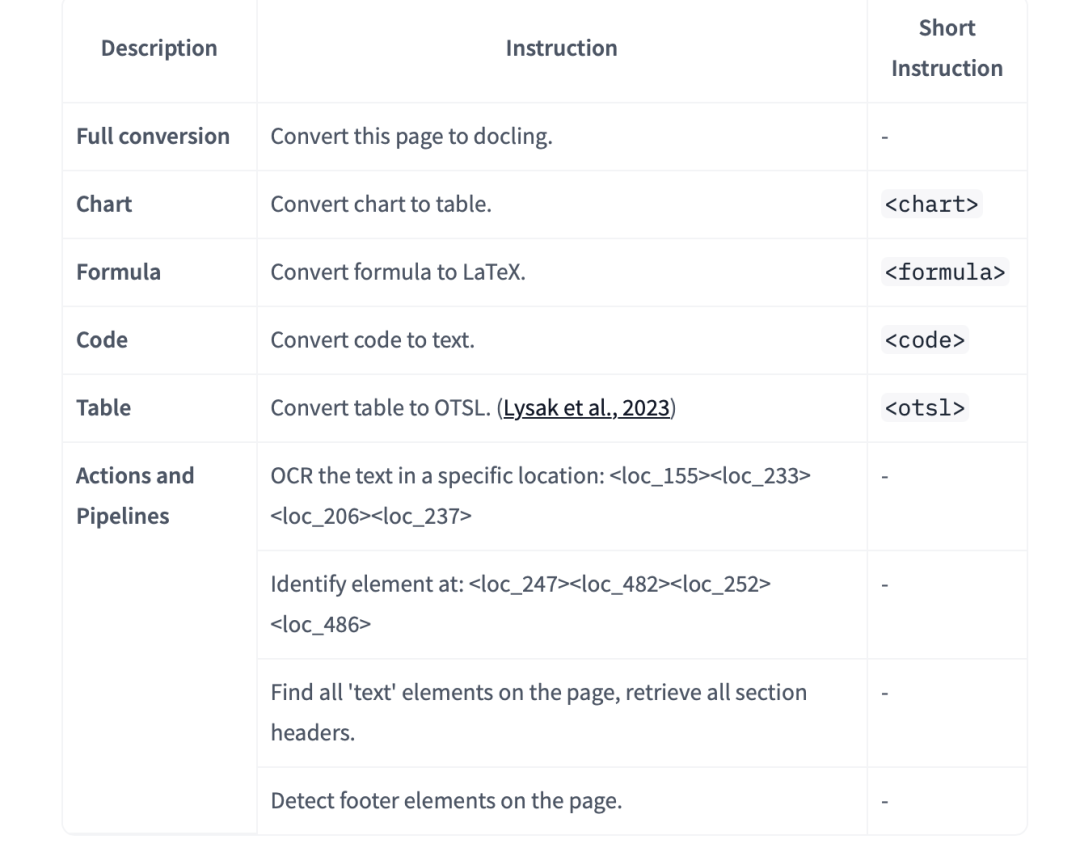
顺着它的项目,可以看看用了一些开源的合成数据项目。例如:
1、SynthCodeNet,https://huggingface.co/datasets/ds4sd/SynthCodeNet,【合成代码片段集合,涵盖超过50种编程语言];
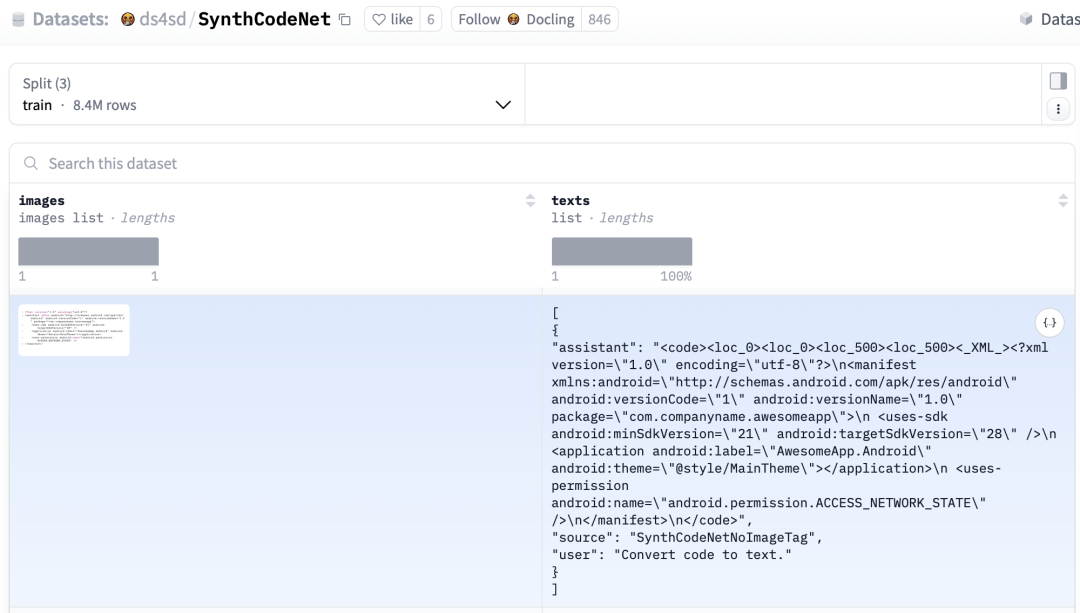
数据统计信息如下:
Total samples: 9,334,257;
Training set: 8,400,838;
Validation set: 466,703;
Test set: 466,716
2、SynthFormulaNet,https://huggingface.co/datasets/ds4sd/SynthFormulaNet,【包含合成数学表达式的数据集,每个表达式都配有真实的LaTeX表示】;
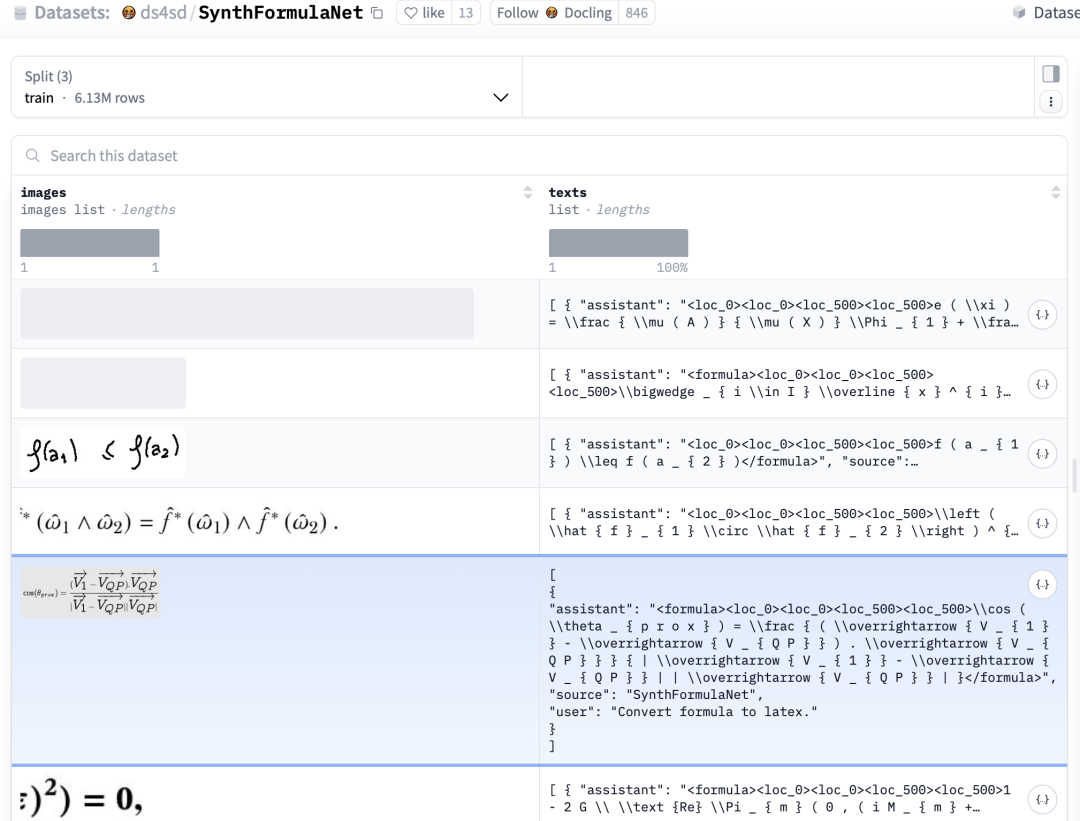
数据统计信息如下:
Total samples: 6,452,704;
Training set: 6,130,068;
Validation set: 161,317;
Test set: 161,319**
3、SynthChartNet,https://huggingface.co/datasets/ds4sd/SynthChartNet,【合成图表图像,标注有结构化的表格输出】;
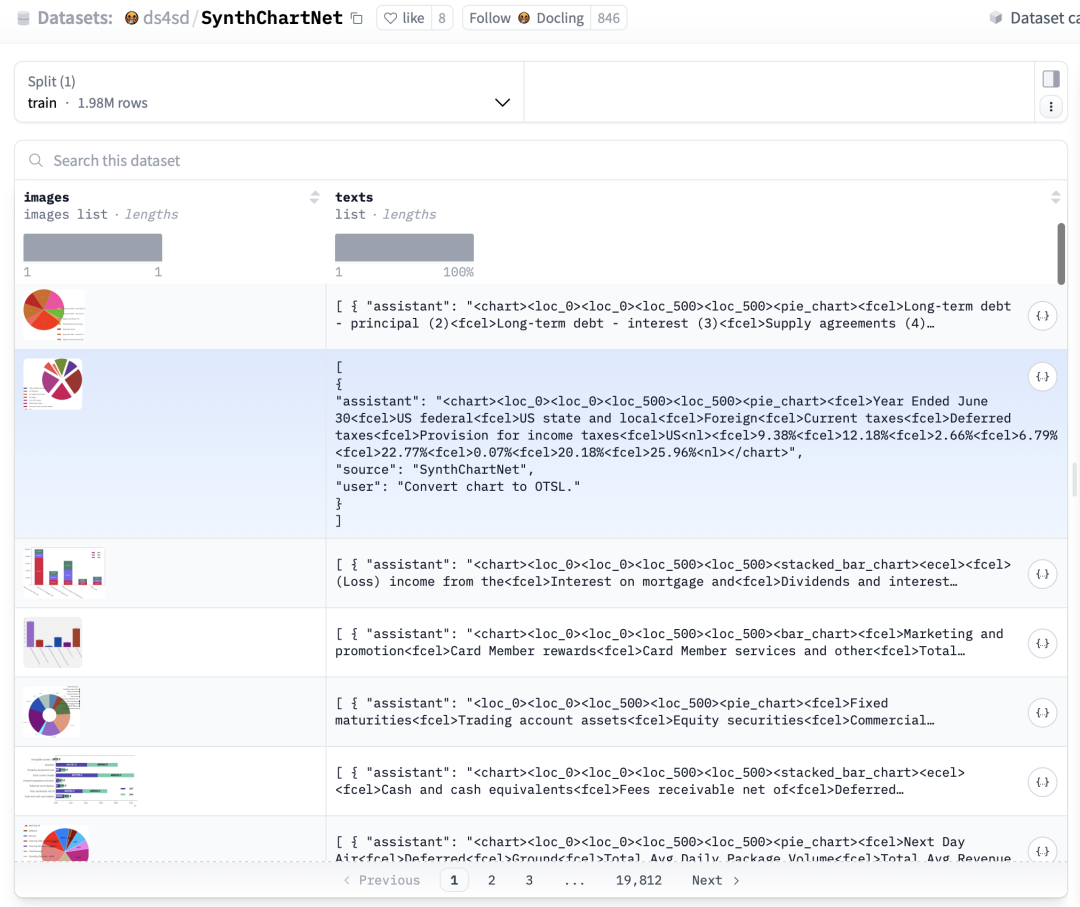
数据统计信息如下:
Total samples: 1,981,157;
Training set: 1,981,157;
Chart Types: Line, Bar, Pie, Stacked Bar;
Rendering Engines: Matplotlib, Seaborn, Pyecharts;
4、DoclingMatix,https://huggingface.co/datasets/HuggingFaceM4/DoclingMatix 【真实文档页面语料库,采样自多个不同领域】
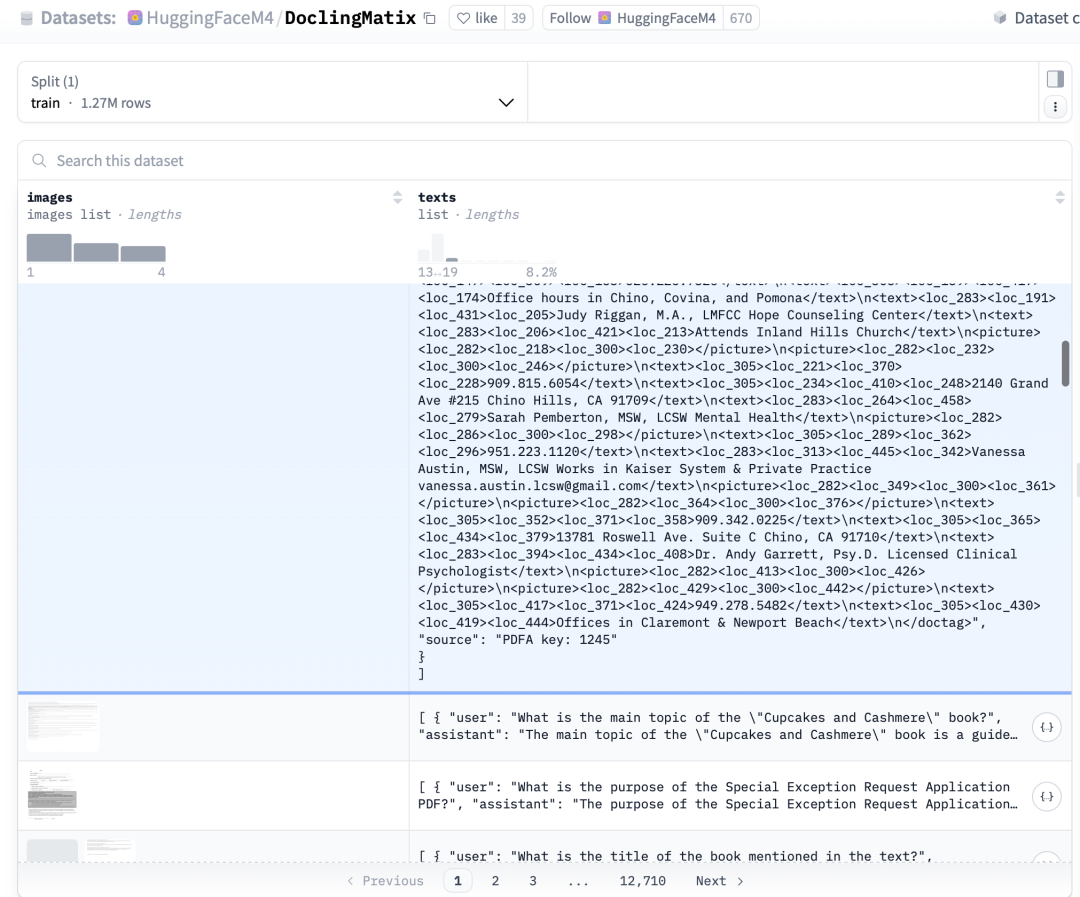
数据统计信息如下:
Total samples: 1,270,911
Training set: 1,270,911
二、再看多模态GraphRAG的图谱构建问题
《DSRAG: A Domain-Specific Retrieval Framework Based on Document-derived Multimodal Knowledge Graph》,https://arxiv.org/pdf/2509.10467,讲的还是在文档解析之后,整合文本、图像、表格等异构信息构建多模态知识图谱(DSKG),然后再做RAG检索生成。
借鉴的点,还是这张图怎么建,构建流程分为三阶段,形成从原始文档到多模态KG的完整pipeline。
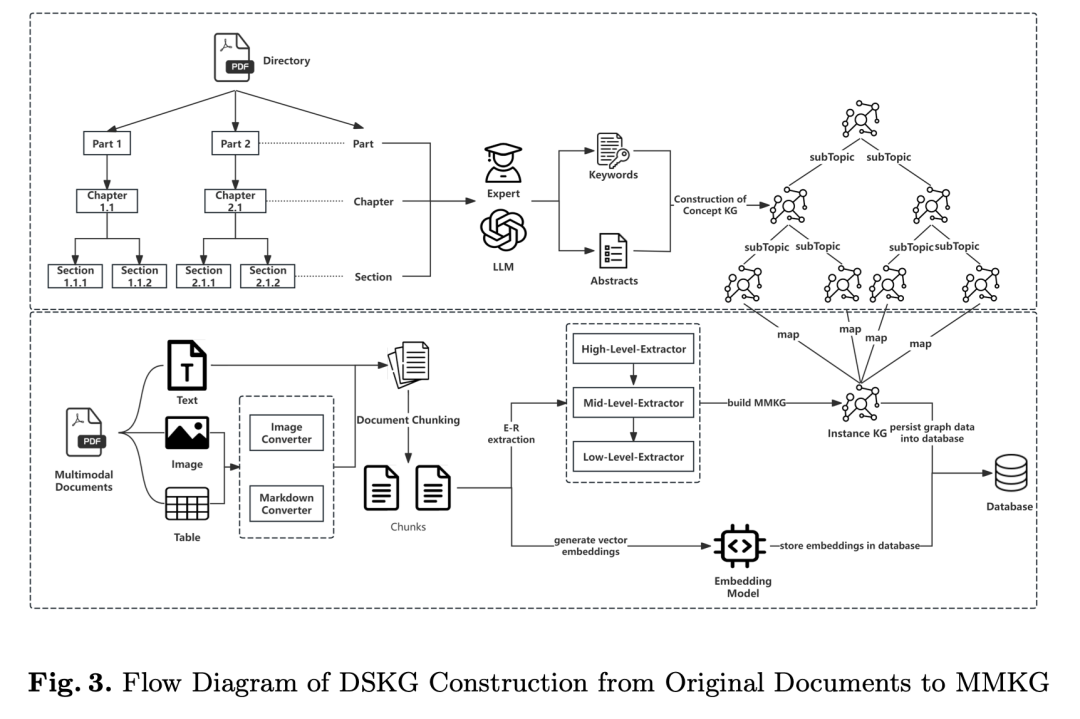
1、数据预处理,先用Mineru文档挖掘工具+混合OCR引擎解析原始PDF,实现像素级处理->文本去噪、表格结构检测(转Markdown)、图像特征提取(生成自然语言描述)->段落级文本分割(保留语义连续性),表格/图像作为独立知识块;
2、概念层KG(ConceptKG)构建,以文档目录(Part/Chapter/Section标题)为基础,结合LLM和专家标注生成章节摘要->提取关键概念关联,定义层级边关系(如subTopic、hasKeyword)->构建有向无环图(DAG)形式的多层子图;
3,实例层KG(InstanceKG)构建,采用结构化分块策略将文档分割为最小语义单元(标注章节结构与上下文),从多模态数据(文本、图像、表格)中提取细粒度实体与关系,补充属性。但是,这个核心的核心,还是依赖于文档解析,文档解析对于很长的文档,计算量和精度都有问题。
参考文献
1、https://arxiv.org/pdf/2509.10467
2、https://huggingface.co/ibm-granite/granite-docling-258M
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)