大模型必会基础知识2-大模型是怎么学习到知识的?
大模型学习可以理解为训练一个猴子,行业内人士称训练的过程是炼丹,这也有一定的道理,因为大模型学会哪些知识都是不可控的,需要多次尝试,需要一定的运气成分在里面。大模型学习知识的本质,其实就是把文本转换成的数字,写入大模型的词汇表里,词汇表是个大型的空间矩阵,空间矩阵每个维度(列),就是代表了某个词的一个含义,比如:苹果有水果和手机等多种含义。大模型学习过程就是通过训练,把现实世界的词汇含义,映射到此
大模型必会基础知识2-大模型是怎么学习到知识的?
1. 大模型学习路径
大模型学习可以理解为训练一个猴子,行业内人士称训练的过程是炼丹,这也有一定的道理,因为大模型学会哪些知识都是不可控的,需要多次尝试,需要一定的运气成分在里面。
大模型学习知识的本质,其实就是把文本转换成的数字,写入大模型的词汇表里,词汇表是个大型的空间矩阵,空间矩阵每个维度(列),就是代表了某个词的一个含义,比如:苹果有水果和手机等多种含义。大模型学习过程就是通过训练,把现实世界的词汇含义,映射到此表空间内。

大模型的维度非常多,像chatGPT达到了12500个维度,词空间矩阵是非常庞大的。再看下图,这是大模型的学习过程,目前主流是预训练-SFT训练和强化学习三个阶段。

预训练阶段:这个阶段完成后,模型可实现类似完形填空的效果。
大量的文本数据:预训练模型通常是在海量的文本数据上进行训练,这些数据涵盖了不同的领域、风格和表达方式。通过这些数据,模型能够接触到丰富的语法结构、句法规则和上下文关联等语言信息。例如,模型可以学习到“猫”和“狗”是常见的动物,甚至能理解它们通常出现在相似的上下文中(如:“猫喜欢吃鱼”与“狗喜欢吃肉”),从而掌握这些动物的基本语义。
SFT训练:这个阶段是可以实现基本的问答效果
指令微调的目标就是让模型在面对特定任务时,能够通过给定的指令进行有效的理解和处理。通过“指令微调”,模型不仅能更好地完成像问答、摘要生成、机器翻译等常见任务,还能提高在对话式AI、个性化推荐等应用中的表现。简而言之,SFT是为了让模型在面对具体任务时,能按预期提供更加精准和符合需求的结果。
强化学习与人类反馈(RLHF):这个阶段是为了实现回答符合人类偏好
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)是一种将强化学习与人类反馈结合的方法,旨在优化模型的行为和输出,使其更加符合人类的期望。通过引入人类反馈,RLHF帮助模型更好地理解和满足人类的偏好,生成更自然、更符合人类意图的输出。
在强化学习与人类反馈(RLHF)的训练框架中,我们可以用一个类比来帮助理解:它就像是一个高中生备战高考的全过程。首先,这个高中生通过三年的日常学习积累了大量的基础知识(类似于模型的预训练),为接下来的高考专项训练奠定了基础。然后,他通过模拟考试(类似于有监督微调SFT)来针对性地提高应试能力。而在强化学习阶段,学生需要根据模拟考试的反馈进行调整,优化答题策略,这就像是模型在RLHF中根据人类反馈不断优化自身行为。奖励模型就像是老师根据学生表现给出的评分,帮助学生找到改进的方向,最终通过这种反馈机制使模型更符合人类的期望,表现更好。
现在各家的训练过程大同小异,都有自己的诀窍在里面,目前训练最难的不是算法,而是数据,高精度数据会显著提升训练效果,数据已经成为大模型的核心竞争力!
2、学习过程原理
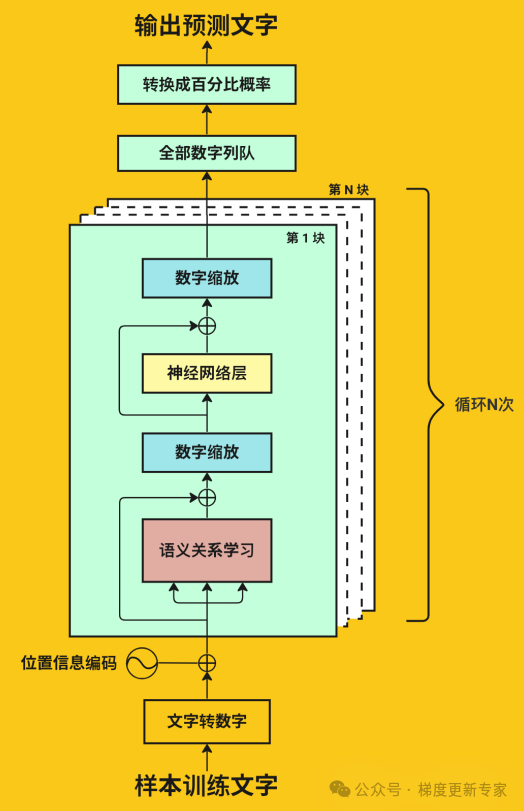
a. 数据输入与预处理
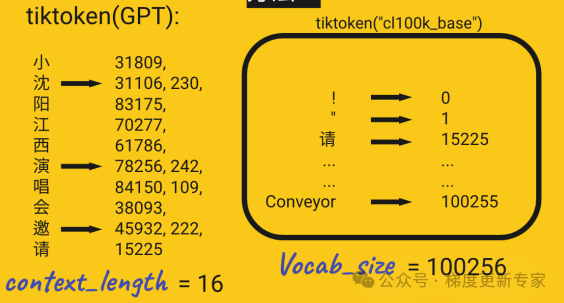
首先要对数据进行预处理,主要是将海量文本拆分为固定长度的短句,再通过分词器和词嵌入技术,将文本转为向量,
类似:苹果->[0.2,0.4,0.1,0.7]
数据集
-
模型通常在海量的文本数据(如网页、书籍、对话等)上进行训练,数据涵盖多种语言、领域和风格。
-
分词
文本被分解为词、子词或字符(通过如BPE或WordPiece的分词算法),并转换为数字表示(词嵌入,Embedding)。
-
上下文窗口
Transformer以固定长度的序列(Context Window)处理输入,序列中的每个词都有对应的嵌入向量。
b. 自注意力机制计算:详见大模型必会基础知识
-
捕捉关系
自注意力机制计算序列中每个词与其他词的相关性,生成加权表示。这使模型能理解词与词之间的上下文关系,如“苹果”在不同句子中是水果还是公司。
-
多头机制
通过多个注意力头并行处理,模型能同时关注不同的语义关系(如语法、语义、逻辑等),从而提取更丰富的特征。
c. 前馈网络与层堆叠
-
特征转换
每一层的全连接前馈网络对注意力机制的输出进行非线性变换,进一步提取和整合特征。
-
多层堆叠
Transformer通常包含数十到数百层,每层处理的信息逐渐抽象,从词级别到句子、段落级别的语义。
d. 反向更新:根据前向和反向传播计算结果,由损失函数计算出差值,反向更新模型参数,使词向量数值逼近现实世界词汇含义。
** **
Transformer模型通过反向传播算法更新参数,从而“学习”知识。这是深度学习的核心机制,具体步骤如下:
-
前向传播
-
- 输入数据(例如分词后的文本序列)经过Transformer的各层(自注意力、前馈网络等),生成输出(如预测下一个词的概率分布)。
- 输出与真实标签(Ground Truth)比较,计算损失函数(如交叉熵损失)。
-
反向传播
损失函数对模型参数(如权重矩阵、偏置)的梯度通过链式法则计算。
-
- 从输出层逐层向输入层反向传播,计算每一层参数的梯度。
- 例如,自注意力机制的权重、词嵌入矩阵等都会根据梯度更新。
-
参数更新
使用优化算法(如Adam)根据梯度更新模型参数,目标是最小化损失函数。
-
- 更新公式:参数 = 参数 - 学习率 * 梯度。
- 这一过程反复迭代,使模型逐步逼近数据分布,学习到语言模式和知识。
举例说明
输入句子:“今天是星期_”,模型预测“五”。
-
如果预测错误(真实答案是“二”),损失函数计算误差。
-
反向传播计算每一层(自注意力、前馈网络等)的梯度,更新权重。
-
经过多次迭代,模型学会正确预测“星期二”。
4.知识的“存储”:模型参数
大模型知识主要存储在safetensor文件内,文件大小随模型大小增大。
参数组成:
Transformer模型包含数十亿到千亿个参数,主要包括:
-
词嵌入矩阵
将词或子词映射到高维向量,编码词的语义和语法信息。
-
自注意力层的权重
包括查询(Query)、键(Key)、值(Value)矩阵,用于捕获词之间的上下文关系。
-
前馈神经网络权重
处理每一层的特征转换,提取更抽象的模式。
-
偏置和层归一化参数
用于稳定和调整模型输出
以上就是大模型学习知识的过程,这也是简化的描述,实际过程还更复杂一些,喜欢的朋友可以点赞、转发、收藏!
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)