IndustryNav:动态工业导航中具身智能体空间推理的探索
IndustryNav 动态工业导航基准,基于 Unity 构建 12 个含动态物体 / 人员的高保真仓库场景;设计零样本导航管线与碰撞率 / 警告率安全指标,评测 9 款 VLLM 发现:闭源模型表现更优,但所有模型在路径规划、避障、主动探索上均存在显著缺陷。
摘要:本文提出 IndustryNav 动态工业导航基准,基于 Unity 构建 12 个含动态物体 / 人员的高保真仓库场景;设计零样本导航管线与碰撞率 / 警告率安全指标,评测 9 款 VLLM 发现:闭源模型表现更优,但所有模型在路径规划、避障、主动探索上均存在显著缺陷。
一、引言
人类具备视觉 - 空间智能,能够感知、处理并在脑海中表征物体间的空间关系,进而在复杂环境中完成导航。近年视觉大语言模型(VLLMs)作为具身智能体,在感知、操作、导航等任务中展现出显著效果,但空间推理(如距离 / 方向测量、空间关系理解)仍是其核心且尚未解决的挑战。
现有具身智能基准存在两大关键局限:一是聚焦静态家居环境的被动空间感知,缺乏动态物体、人员移动等真实场景的动力学特征;二是仅评估孤立的推理能力(如目标定位),而非整合感知、规划、动作的整体视觉 - 空间智能。
由密歇根州立大学&北卡罗来纳大学教堂山分校&俄亥俄州立大学&加州大学圣巴巴拉分校&亚利桑那州立大学&独立研究员团队联合研究的IndustryNav《IndustryNav: Exploring Spatial Reasoning of Embodied Agents in Dynamic Industrial Navigation》:这是首个面向主动空间推理的动态工业导航基准(图 1)。该基准基于 Unity 构建 12 个人工设计的高保真仓库场景,包含动态物体和人员移动;设计结合第一视角视觉与全局里程计的 PointGoal 导航管线,评估智能体的全局 - 局部规划能力;创新性引入 “碰撞率” 和 “警告率” 指标,衡量安全行为与距离估计能力。对 9 款主流 VLLM(含 GPT-5-mini、Claude-4.5、Gemini-2.5)的全面评测表明:闭源模型持续占优,但所有智能体在鲁棒路径规划、避障、主动探索上均存在显著不足,凸显具身智能研究需从被动感知转向动态真实环境下的稳定规划、主动探索与安全行为。
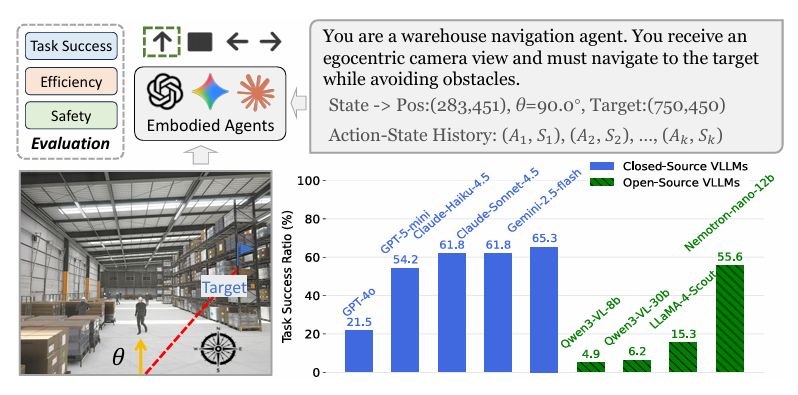
图 1 IndustryNav 基准示意图:零样本导航场景下,具身智能体基于第一视角图像、全局里程计和动作 - 状态历史到达目标并规避动态障碍;9 款 VLLM 的任务成功率显示,动态环境空间推理仍具挑战,闭源模型优于开源模型,仅 Nemotron 接近闭源模型性能。
二、相关工作
2.1 VLLMs 的空间推理
现有提升 VLLMs 空间推理的策略可分为三类:
-
显式几何预训练:从大规模 3D 数据、标注场景数据中学习空间知识,理解几何关系与空间概念;
-
深度感知增强:添加深度图、点云、多模态特征投影等几何线索,强化 2D 视觉对空间信息的理解;
-
结构化关系推理:构建符号 / 图结构表征(如场景图、拓扑地图),实现可解释的空间推理。
2.2 空间推理基准
空间推理评测已从简单几何推理发展到复杂具身交互,但现有基准存在明显局限:
-
被动感知基准:基于静态视角评估视觉接地、空间关系推理,无环境交互过程;
-
主动探索基准:加入多步导航,但动力学场景简化,缺乏工业场景所需的安全量化指标;
-
行业专用基准:聚焦户外导航、城市空间理解,但未覆盖动态工业环境的核心需求(如动态障碍、安全避障)。
IndustryNav 填补了这一空白,覆盖碰撞感知、动态障碍处理、全局 - 局部规划、主动交互,且引入工业场景必需的量化安全指标。
2.3 智能体导航
智能体导航研究可分为三类核心方向:
-
指令跟随推理:聚焦语言接地、动作对齐、语义建图,实现指令驱动的导航;
-
探索式推理:优化信息增益、搜索策略,适配探索策略提升任务完成效率;
-
结构化推理:采用分层规划、拓扑推理、语义图,支持可解释的空间推理。
本文将智能体导航研究拓展至动态工业环境的空间推理,强调主动交互与可靠的安全导航。
三、IndustryNav 基准设计
3.1 工业场景构建
3.1.1 仿真环境
基于 Unity 引擎构建工业场景,选择 Unity 的核心原因:
-
提供大规模高保真仓库资产,社区生态完善,可快速搭建真实场景;
-
跨平台兼容(Mac/Linux/Windows),支持无界面执行,硬件优化优异;
-
集成 MLAgents 工具包,便于具身智能体的强化学习 / 模仿学习训练。
3.1.2 仓库场景设计
由 5 名专家手动构建 12 个动态仓库场景,涵盖静态 / 动态两类场景(区分是否含物体 / 人员动画),场景设计遵循 OSHA 安全规范,包含多样化工业资产:
-
建筑类:墙体、地面标识、楼梯、支撑梁;
-
存储系统:货架、工业桶、集装箱、传送带、周转箱;
-
搬运设备:叉车、手推车、地面货运机器人;
-
人员与设施:作业工人、安全标识、灭火器等。
动态场景中,手动设计叉车、机器人、工人的运动轨迹,模拟真实工业环境的时空变化;为所有物体分配碰撞体几何形状,确保 Unity 物理引擎可精准检测智能体与障碍物的碰撞。
3.1.3 传感器配置
采用多传感器跟踪方案(图 3),兼顾局部感知与全局定位:
-
第一视角相机:分辨率 1024×1024,捕捉智能体周边环境细节;
-
全局状态跟踪:实时记录智能体的坐标 (x,y) 和朝向角 θ(0°-360°);
-
俯视监控相机:分辨率 1024×512,通过智能体顶部的红色锥体实时追踪其全局位置,便于轨迹可视化与定量分析。
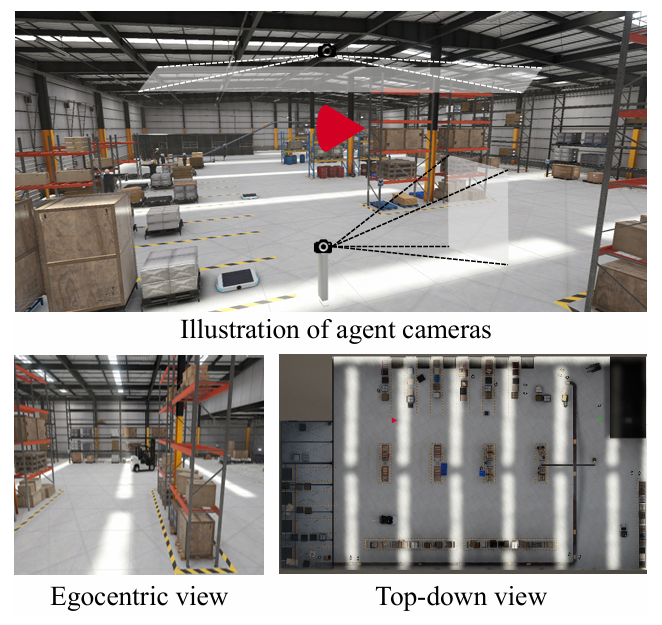
图 3 IndustryNav 智能体相机配置:第一视角相机捕捉周边环境,俯视相机通过红色锥体追踪智能体全局位置,底部面板展示对应的第一视角和俯视视角,支撑导航监控与轨迹分析。
3.2 零样本导航管线
设计零样本导航管线(图 2),评估具身智能体的全局 - 局部规划能力:
-
输入信息:第一视角图像(感知周边障碍)、全局里程计(智能体位置 / 朝向 / 目标距离)、动作 - 状态历史(避免动作循环);
-
方向映射:明确朝向角与真实坐标系的对应关系(θ=0°→西、90°→北、180°→东、270°→南),辅助智能体空间推理;
-
动作空间:离散动作集(前进、左转、右转、停止),左转 / 右转固定旋转 90°,到达目标附近时输出 “停止”;
-
推理输出:要求智能体同时输出动作和推理过程,便于分析决策逻辑的合理性。
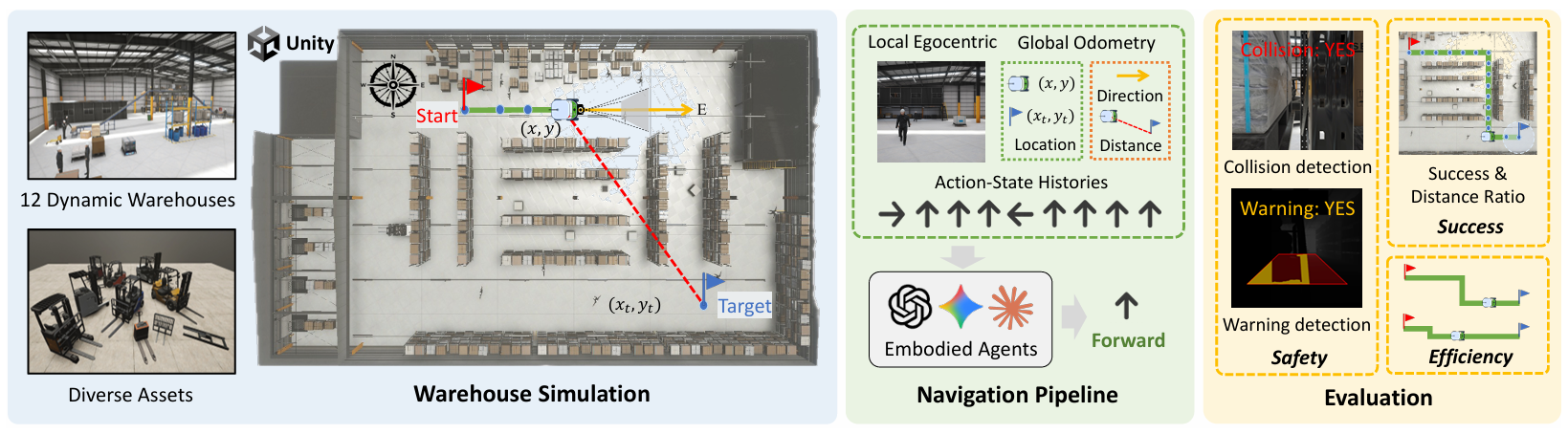
图 2 IndustryNav 基准整体框架:基于 Unity 构建 12 个动态仓库环境,导航管线融合第一视角观测与全局里程计,从任务成功率、轨迹效率、安全行为三个维度(5 项指标)全面评估导航性能。
3.3 评估指标
设计 5 项核心指标,从任务成功、轨迹效率、安全行为三个维度全面评测智能体性能:
3.3.1 任务成功维度
-
成功率(SR):衡量智能体到达目标的比例,距离阈值设为 20,值越高表示导航稳定性越强;
-
距离比(DR):量化智能体相对目标的进度(即使未到达目标),值越高表示导航的有效进度提升越显著。
3.3.2 轨迹效率维度
-
平均步数(AS):衡量每轮导航的平均步数,值越低表示路径规划越高效。
3.3.3 安全行为维度
-
碰撞率(CR):衡量每轮导航中碰撞次数占前进动作的比例,值越低表示避障能力越强;通过 Unity 碰撞体检测智能体前进后的位置变化,精准识别碰撞事件;
-
警告率(WR):基于深度图评估近碰撞风险,定义智能体前进路径的感兴趣区域(ROI),若 ROI 内像素深度小于 1 米阈值则标记为警告,值越低表示空间感知和风险规避能力越强(图 4)。

图 4 警告检测示意图:当感兴趣区域(ROI)内的最小深度值低于预设阈值时触发警告,可有效反映智能体的近碰撞风险。
四、实验验证
4.1 具身智能体对比实验
4.1.1 实验设置
-
评测模型:9 款主流 VLLM(5 款闭源:GPT-4o、GPT-5-mini、Gemini-2.5-flash、Claude-Haiku-4.5、Claude-Sonnet-4.5;4 款开源:Nemotron-nano-12B-v2-VL、Llama-4-Scout、Qwen3-VL-30B-a3B-Instruct、Qwen3-VL-8B-Instruct);
-
实验配置:每个场景随机采样 4 组难度不同的起点 - 目标对,每轮导航 70 步,输入第一视角图像和全局里程计,输出 JSON 格式的动作和推理过程;
-
核心参数:成功率阈值 δ=20,警告深度阈值 1 米,动作 - 状态历史长度固定为 10。
4.1.2 结果分析
核心发现(表 2):
-
无 VLLM 能可靠完成导航:所有模型的任务成功率均低于 70%,动态工业环境的空间推理和长时程导航仍是核心挑战;
-
闭源模型显著优于开源模型:闭源模型在任务成功率、轨迹效率上表现更优,开源模型(如 Qwen3-VL、LLaMA-4)在高风险动态导航中竞争力不足;
-
Nemotron 是最优开源基线:成功率达 55.56%,接近闭源模型,效率和安全指标表现相对合理;
-
安全是核心短板:所有模型的碰撞率、警告率均偏高,动态环境中的危险感知、避障能力远未达到实际部署要求。
表 2 ,9 款 VLLM 在 IndustryNav 基准的空间推理性能对比
| 具身智能体 | 任务成功 | 效率 平均步数↓ |
安全 | ||
|---|---|---|---|---|---|
|
成功率↑(%) |
距离比↑(%) |
碰撞率↓(%) |
警告率↓(%) |
||
|
闭源 VLLMs |
|||||
|
GPT-4o |
21.53 |
49.41 |
66.76 |
7.86 |
13.45 |
|
GPT-5-mini |
54.17 |
81.90 |
49.91 |
16.89 |
24.13 |
|
Claude-Haiku-4.5 |
61.81 |
82.87 |
46.80 |
32.18 |
31.57 |
|
Claude-Sonnet-4.5 |
61.81 |
86.26 |
47.33 |
27.68 |
31.52 |
|
Gemini-2.5-flash |
65.28 |
84.49 |
45.95 |
32.14 |
37.16 |
|
开源 VLLMs |
|||||
|
Qwen3-VL-8b-Instruct |
4.86 |
27.05 |
67.22 |
27.82 |
25.70 |
|
Qwen3-VL-30b-A3B-Instruct |
6.25 |
26.20 |
66.70 |
18.97 |
26.28 |
|
LLaMA-4-Scout |
15.28 |
50.69 |
80.48 |
56.40 |
61.53 |
|
Nemotron-nano-12b-v2-VL |
55.56 |
70.00 |
56.40 |
31.73 |
35.06 |
4.2 案例分析
以 GPT-5-mini 为例分析决策逻辑(图 5):
-
正确决策:识别路径被工人和叉车阻挡,结合目标位置(东南方向)选择左转规避风险,体现基础的全局 - 局部规划能力;
-
错误决策 1(全局规划失效):识别目标在东侧,但未察觉货架阻挡直线路径,陷入 “左转 - 右转” 动作循环,缺乏路径重规划和主动探索能力;
-
错误决策 2(距离估计偏差):误判中路无障碍物,执行前进动作导致与货架碰撞,反映距离感知精度不足的核心问题。
核心结论:当前 VLLMs 在动态场景的全局路径规划、主动探索、精准距离估计上仍存在显著缺陷。
4.3 消融实验
4.3.1 动作 - 状态历史的有效性
移除动作 - 状态历史后,智能体的成功率下降、警告率上升,原因是缺乏历史上下文导致短视决策、重复无效动作,验证了历史信息对导航稳定性的关键作用。
4.3.2 俯视图的必要性
添加俯视图后,除 GPT-5-mini 成功率小幅提升外,其余模型性能无改善甚至下降,原因是 VLLMs 难以有效解读俯视图信息,且引入额外视觉噪声,因此仅依赖全局里程计即可提供足够的全局定位信息。
五、结论
本文提出首个基于 Unity 的动态工业导航基准 IndustryNav,包含 12 个高保真仓库场景、零样本导航管线和 5 项多维度评估指标。对 9 款 VLLM 的评测表明:动态工业环境的空间推理仍具核心挑战,闭源模型表现优于开源模型,但所有模型在安全导航、全局规划上存在显著不足;案例分析揭示了全局路径规划、主动探索、距离估计的核心短板;消融实验验证了动作 - 状态历史的必要性,以及俯视图的非必需性。
本文为具身 AI 社区提供了新的基准和关键洞察,推动具身智能研究从被动感知转向动态真实环境下的稳定规划、主动探索与安全行为。
六、局限性与未来工作
6.1 局限性
-
帧率挑战:场景资产密集、光影复杂,导致运行帧率受限,影响异步执行效果;
-
视觉保真度:受 GPU 资源限制未启用光线追踪,视觉效果有提升空间;
-
执行模式:MLAgent 仅支持顺序执行,无法模拟真实环境的连续动态;
-
动画范围:缺乏工人受伤、工具切换等长尾场景动画;
-
场景覆盖:未包含户外多仓库集群、货运等工业场景。
6.2 未来工作
-
帧率优化:通过 LOD 技术、条件渲染等手段提升运行帧率;
-
主动具身智能体:采用强化学习训练长时程规划策略,提升主动探索能力;
-
安全感知智能体:引入深度图 / 3D 点云,构建安全导向的学习框架;
-
高效具身智能体:设计轻量化架构,适配嵌入式机器人的部署需求。
END

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)