针对特定领域搜索的文本嵌入微调
然后,对于每个正样本对,我挑选出与负样本最不相似的JD(同时确保没有两行包含相同的负样本)。微调是指通过额外的训练,使预训练模型适应特定任务。本文介绍了如何将这一理念应用于文本嵌入模型,以提高其将(类似人类的)求职查询与职位描述进行匹配的准确性。在我的下一篇文章中,我将讨论如何使用类似的过程来使多模态嵌入适应特定的用例。,我将“清理后的”JDs 与 GPT-4o-mini 中的合成(类人)查询进行
文本嵌入模型的一个常见用途是检索增强生成 (RAG)。在这种情况下,给定一个基于 LLM 的系统输入(例如客户问题),系统会自动从知识库中检索相关上下文(例如常见问题解答),并将其传递给 LLM。
嵌入通过3 个步骤实现检索过程。
- 为知识库中的所有项目计算向量表示(即嵌入)
- 输入文本被转换成向量表示(使用与步骤 1 相同的嵌入模型)
- 计算输入文本向量与知识库中每一项之间的相似度,并返回最相似的项目
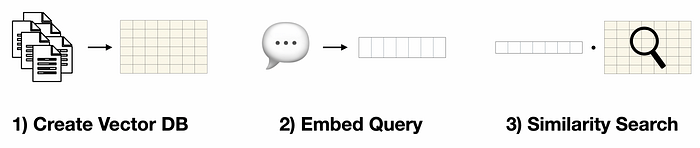
使用嵌入的三步搜索过程。图片由作者提供。
此过程(即语义搜索)提供了一种简单灵活的方法来搜索任意文本项。然而,存在一个问题。
相似性搜索问题
尽管语义搜索很流行,但它有一个核心问题。也就是说,仅仅因为查询和知识库项相似(即它们相关的嵌入向量之间的角度很小),并不一定意味着该项目有助于回答查询。
例如,考虑这个问题“我如何更新我的付款方式? ”
相似性搜索的最佳结果可能是:“要查看您的付款历史记录,请访问您帐户的“结算”部分。 ”
虽然它们在语义上相似,但结果并没有提供有用的信息来回答问题。
微调嵌入
解决这个问题的一种方法是通过微调。我们通过额外的训练来调整嵌入模型的行为。
例如,我们可能希望将客户问题与常见问题解答中的相应答案进行匹配。这不仅需要将一小段文本(问题)与一长段文本(答案)进行匹配,还可能涉及理解特定领域的术语。例如,在云计算领域,“扩展”和“实例”等术语具有非常具体的含义,通用模型可能无法恰当地表达这些含义。
在这种情况下,对嵌入模型进行微调需要使用问题对及其相应的答案进行训练。实现这一目标的关键方法是对比学习,它通过最小化相关对嵌入之间的距离,同时最大化不相关对嵌入之间的距离,教会模型区分有用和无用的结果。
我如何进行微调?
我们可以将微调过程分为5 个关键步骤。
- 收集正(和负)对
- 选择预先训练的模型
- 选择损失函数
- 微调模型
- 评估模型
我不会用抽象的术语来讨论每个步骤,而是用具体的例子来演示(和讨论)每个步骤。
示例:对 AI 招聘信息进行微调
在这里,我将逐步讲解如何微调嵌入模型,以便将求职者与职位描述进行匹配。正如我们将看到的,大多数步骤都由句子转换器库 (Sentence Converters Library)完成。示例脚本可在GitHub 仓库 (Sentence Converters Library)上免费获取。
1)收集正样本对
第一步是准备训练数据。这是整个过程中最重要(也是最耗时)的部分。
首先,我从这个Hugging Face 数据集中提取了各种关键职位(例如数据科学家、数据工程师、AI 工程师)的职位描述。
from datasets import load_dataset
# load data from HF hub
ds = load_dataset("datastax/linkedin_job_listings")接下来,我使用OpenAI 的 Batch API,通过 GPT-4o-mini 生成与每个关键词对应的类人搜索查询。Batch API 运行需要 24 小时,但比立即获取结果便宜 50%。整个工作花费了我 0.12 美元。(参见示例笔记)
然后,我删除了与职位资格无关的描述部分。这一步很重要,因为大多数文本嵌入模型无法处理超过 512 个标记。
为了生成正对,我将“清理后的”JDs 与 GPT-4o-mini 中的合成(类人)查询进行匹配。然后,删除所有重复的行,最终得到1012 个 JDs。

正对数据框的头部。图片由作者提供。
虽然我们可以就此打住,但我更进一步,为每个示例挑选出负样本对。我使用预先训练的嵌入模型来计算数据集中所有已清理的JD之间的相似度。然后,对于每个正样本对,我挑选出与负样本最不相似的JD(同时确保没有两行包含相同的负样本)。
from sentence_transformers import SentenceTransformer
import numpy as np
# Load an embedding model
model = SentenceTransformer("all-mpnet-base-v2")
# Encode all job descriptions
job_embeddings = model.encode(df['job_description_pos'].to_list())
# compute similarities
similarities = model.similarity(job_embeddings, job_embeddings)
# match least JDs least similar to positive match as the negative match
# get sorted indexes of simiarlities
similarities_argsorted = np.argsort(similarities.numpy(), axis=1)
# initialize list to store negative pairs
negative_pair_index_list = []
for i in range(len(similarities)):
# Start with the smallest similarity index for the current row
j = 0
index = int(similarities_argsorted[i][j])
# Ensure the index is unique
while index in negative_pair_index_list:
j += 1 # Move to the next smallest index
index = int(similarities_argsorted[i][j]) # Fetch next smallest index
negative_pair_index_list.append(index)
# add negative pairs to df
df['job_description_neg'] =
df['job_description_pos'].iloc[negative_pair_index_list].values最后,我将数据分成训练-验证-测试集,并将它们上传到 HuggingFace 中心,这样就可以通过这一行函数调用来访问它们。
# Shuffle the dataset
df = df.sample(frac=1, random_state=42).reset_index(drop=True)
# Split into train, validation, and test sets (e.g., 80% train, 10% validation, 10% test)
train_frac = 0.8
valid_frac = 0.1
test_frac = 0.1
# define train and validation size
train_size = int(train_frac * len(df))
valid_size = int(valid_frac * len(df))
# create train, validation, and test datasets
df_train = df[:train_size]
df_valid = df[train_size:train_size + valid_size]
df_test = df[train_size + valid_size:]
from datasets import DatasetDict, Dataset
# Convert the pandas DataFrames back to Hugging Face Datasets
train_ds = Dataset.from_pandas(df_train)
valid_ds = Dataset.from_pandas(df_valid)
test_ds = Dataset.from_pandas(df_test)
# Combine into a DatasetDict
dataset_dict = DatasetDict({
'train': train_ds,
'validation': valid_ds,
'test': test_ds
})
# push data to hub
dataset_dict.push_to_hub("shawhin/ai-job-embedding-finetuning")我们可以用一行代码导入结果数据集。
from datasets import load_dataset
# importing data
dataset = load_dataset("shawhin/ai-job-embedding-finetuning")2)选择一个预先训练的模型
有了(终于)拿到训练数据后,我们接下来选择一个预训练模型进行微调。我通过比较各种基础模型和语义搜索模型来做到这一点。
为此,我创建了一个评估器,它采用我们的示例(查询、正 JD、负 JD)三元组并计算准确率。以下是验证集的准确率示例。
from sentence_transformers import SentenceTransformer
from sentence_transformers.evaluation import TripletEvaluator
# import model
model_name = "sentence-transformers/all-distilroberta-v1"
model = SentenceTransformer(model_name)
# create evaluator
evaluator_valid = TripletEvaluator(
anchors=dataset["validation"]["query"],
positives=dataset["validation"]["job_description_pos"],
negatives=dataset["validation"]["job_description_neg"],
name="ai-job-validation",
)
evaluator_valid(model)
#>> {'ai-job-validation_cosine_accuracy': np.float64(0.8811881188118812)}比较了几个模型之后,我选择了“ all-distilroberta-v1 ”,因为它在验证集上具有最高的准确度(在任何微调之前)。
3)选择损失函数
接下来,我们需要选择一个损失函数。这取决于你的数据和后续任务[1]。句子转换器文档中有一个很好的汇总表,列出了适合各种损失函数的数据格式。
在这里,我使用了MultipleNegativesRankingLoss,因为它符合我们的(锚点、正值、负值)三元组格式。
from sentence_transformers.losses import MultipleNegativesRankingLoss
loss = MultipleNegativesRankingLoss(model)4)微调模型
数据、模型和损失函数准备就绪后,我们现在可以对模型进行微调。为此,我们首先定义各种训练参数。
关键点在于,对比学习受益于更大的批量大小和更长的训练时间 [2]。为了简单起见,我使用了此处示例中显示的许多超参数。
from sentence_transformers import SentenceTransformerTrainingArguments
num_epochs = 1
batch_size = 16
lr = 2e-5
finetuned_model_name = "distilroberta-ai-job-embeddings"
train_args = SentenceTransformerTrainingArguments(
output_dir=f"models/{finetuned_model_name}",
num_train_epochs=num_epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
learning_rate=lr,
warmup_ratio=0.1,
batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss benefits from no duplicate samples in a batch
eval_strategy="steps",
eval_steps=100,
logging_steps=100,
)接下来,我们训练模型。我们可以通过 SentenceTransformerTrainer 轻松完成此操作。
from sentence_transformers import SentenceTransformerTrainer
trainer = SentenceTransformerTrainer(
model=model,
args=train_args,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
loss=loss,
evaluator=evaluator_valid,
)
trainer.train()5)评估模型
最后,我们可以用类似于步骤 2 中评估预训练模型的方式来评估微调模型。结果显示验证集的准确率为 99%,测试集的准确率为 100%。
作为可选步骤,我们可以将模型推送到 Hugging Face Hub,以便轻松导入进行推理。
# push model to HF hub
model.push_to_hub(f"shawhin/{finetuned_model_name}")
# import model
model = SentenceTransformer("shawhin/distilroberta-ai-job-embeddings")
# new query
query = "data scientist 6 year experience, LLMs, credit risk, content marketing"
query_embedding = model.encode(query)
# encode JDs
jd_embeddings = model.encode(dataset["test"]["job_description_pos"])
# compute similarities
similarities = model.similarity(query_embedding, jd_embeddings)下一步是什么?
微调是指通过额外的训练,使预训练模型适应特定任务。本文介绍了如何将这一理念应用于文本嵌入模型,以提高其将(类似人类的)求职查询与职位描述进行匹配的准确性。
另一个微调应用是多模态嵌入模型,它在单个向量空间中表示多种模态(例如文本和图像)。在我的下一篇文章中,我将讨论如何使用类似的过程来使多模态嵌入适应特定的用例。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)