这思路太绝了!多模态LLM新成果拿下顶会SOTA!
【摘要】近期研究聚焦多模态大模型(LLM)的优化难题与医疗应用创新。针对数据标注依赖问题,NeurIPS等顶会提出无监督后训练、跨模态知识蒸馏等技术,如MM-UPT框架通过自奖励机制将数学推理准确率提升6.6%。在医疗领域,FT-ARM模型结合微调与自省机制,实现压力性损伤85%的分类准确率(较CNN提升4%),并生成可解释的临床推理。PairUni框架则通过理解-生成配对数据与Pair-GRPO
做多模态大模型研究的同学都懂这个痛点:传统模型想提升性能,离不开海量人工标注数据,成本高还难落地;碰到医疗、金融等数据敏感领域,标注数据更是稀缺,推理精度直接打折扣,成了落地的大障碍。
好在近期NeurIPS、CVPR等顶会给出了破局方案,无监督后训练、跨模态知识蒸馏等新技术,让多模态LLM实现自我进化,如今已成AI领域的核心热点。以上交大提出的MM-UPT框架为例,靠自奖励机制摆脱标注依赖,在数学推理任务上准确率从66.3%提至72.9%;金融风控场景中,融合多模态数据的模型违规识别准确率提升40%。
想发论文的同学,可重点关注无监督训练、跨模态推理、轻量化部署这些方向。我整理了相关顶会/顶刊核心论文,涵盖不同任务的实现方案,部分还附带复现代码打包免费送,感兴趣的同学工种号 沃的顶会 扫码回复 “多模态LLM” 领取。
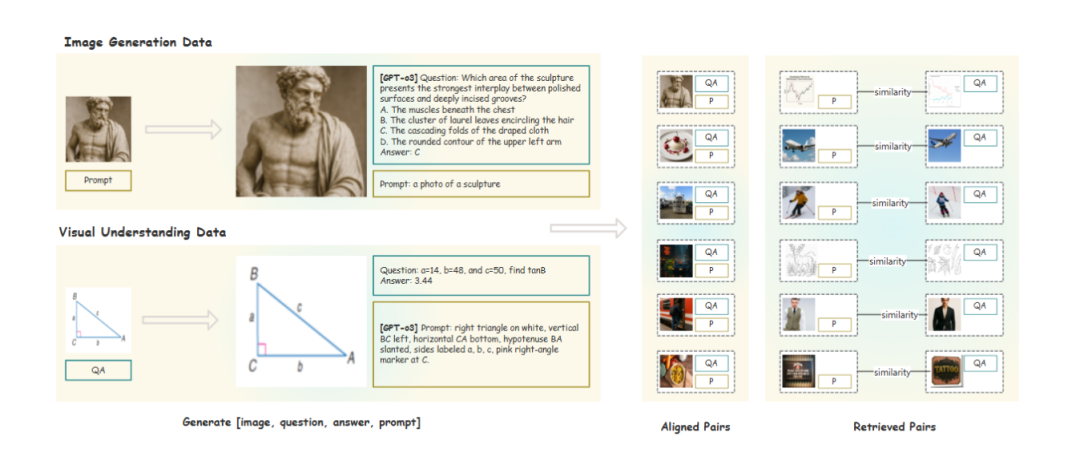
PairUni:Pairwise Training for Unified Multimodal Language Models
文章解析
Unified Vision-Language Models (UVLMs) 在理解和生成任务上面临优化冲突,尤其是在强化学习(RL)中因数据和监督信号异构导致任务干扰。本文提出PairUni框架,通过构建理解-生成(UG)配对数据(包括对齐配对和检索配对),并在优化过程中引入Pair-GRPO算法,利用配对相似性调节优势函数,提升跨任务语义一致性,减少干扰。实验表明该方法在多个UVLM上实现均衡性能提升,优于现有RL基线。
创新点
提出将理解与生成任务的数据组织为理解-生成(UG)配对结构,增强跨任务语义对齐。
利用GPT-o3自动生成缺失模态内容,构建高质量对齐的UG配对数据。
通过图像嵌入检索构建语义相关的生成-理解检索配对,扩展数据覆盖。
提出Pair-GRPO,一种配对感知的GRPO变体,根据配对相似性调节优势函数。
设计包含16K高质量UG配对的PairUG数据集用于RL微调。
研究方法
使用GPT-o3对单任务数据进行增强,补全理解样本的描述或生成样本的问答对,形成对齐配对。
基于图像嵌入相似性检索语义相关样本,构建生成任务与理解任务之间的检索配对。
采用聚类方法筛选高质量代表性样本作为训练数据。
在GRPO基础上引入配对相似性得分,动态调整不同配对的训练权重。
在Janus-Pro等先进UVLM上进行RL微调并评估理解与生成性能。
研究结论
数据层面的语义对齐能显著提升多模态模型在RL中的优化稳定性。
PairUni能有效缓解理解与生成任务间的梯度冲突和任务干扰。
Pair-GRPO通过相似性加权机制增强了高质量配对的学习贡献。
该方法在MMMU、MMStar和GenEval等基准上取得全面且平衡的性能提升。
配对训练范式为统一多模态语言模型的联合优化提供了新方向。
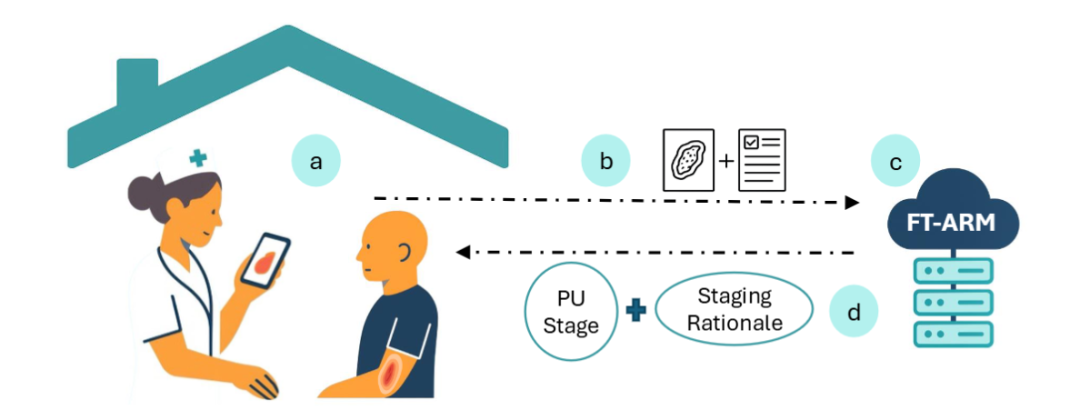
FT-ARM:Fine-Tuned Agentic Reflection Multimodal Language Model for Pressure Ulcer Severity Classification with Reasoning
文章解析
压力性损伤(PUs)的准确分期对治疗至关重要,但临床视觉评估存在主观性和变异性。现有基于CNN或Vision Transformer的方法虽有一定分类性能,但缺乏可解释性。本文提出FT-ARM,一种结合微调多模态大语言模型(MLLM)与智能体自省机制的新型方法,通过整合伤口图像与临床文本信息,实现更准确的压力性损伤分期,并生成具有临床合理性的自然语言解释。该模型在公开数据集PIID上达到85%的准确率,优于传统CNN模型(+4%),且在实时推理场景中验证,具备更强的临床部署潜力。
创新点
提出FT-ARM框架,首次将微调多模态大语言模型与智能体自省机制结合用于压力性损伤自动分期。
引入基于临床知识和视觉特征的迭代自省推理机制,模拟医生再评估过程以提升分类准确性。
模型不仅输出分类结果,还生成符合专家思维路径的自然语言解释,增强决策透明度与可信度。
在真实推理环境下进行评估,区别于以往仅报告离线性能的工作,更具临床实用性。
融合图像与临床文本等多模态输入,实现上下文化、个性化且可解释的医学图像分类。
研究方法
采用LLaMA 3.2 90B作为多模态大语言模型主干,对压力性损伤图像与临床笔记进行联合微调。
设计智能体自省模块,使模型能够基于初始预测进行多轮自我反思与修正。
利用自然语言理解编码临床知识,并与视觉特征协同推理,优化最终分类决策。
在公开Pressure Injury Image Dataset (PIID)上训练并评估模型性能。
在模拟实时推理环境中测试模型表现,确保其适用于实际临床流程。
研究结论
FT-ARM在压力性损伤四阶段分类任务中达到85%准确率,显著优于传统CNN方法。
结合微调与自省推理的策略有效提升了模型的分类一致性与鲁棒性。
生成的自然语言解释与临床专家判断逻辑一致,有助于建立医生对AI系统的信任。
该方法为自动化创面评估系统提供了更高水平的可靠性、透明性和临床可用性。
FT-ARM展示了多模态大语言模型在高风险医疗决策任务中兼具高性能与可解释性的潜力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)