新突破!阿里提出Lumos-1:自回归离散扩散视频生成模型
这样,同一空间位置的词元在所有帧中,要么同时可见,要么同时被遮蔽,从而有效切断了空间信息泄露的“捷径”,迫使模型依赖时序上下文进行预测。Lumos-1模型,核心目标是在尽可能保留LLM原生架构的基础上,构建一个不依赖外部文本编码器、并能实现高效训练推理的自回归视频生成器,从而为构建统一基础模型提供一个坚实且可行的技术路径。否则,生成的视频会出现明显的伪影和闪烁。这一操作确保了两种模态的位置编码处于
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料及应用!发论文/搞科研/涨薪,强烈推荐!

作者|袁杭杰,阿里巴巴达摩院算法工程师
引言

当大语言模型(LLM)在文本世界大放异彩时,我们不禁要问:能否用同样简洁、统一的自回归架构,来驾驭更加复杂的视频生成任务?现有的自回归视频生成方法,或多或少都面临着架构不统一、依赖笨重外部文本编码器、或生成速度过慢等挑战。为此,我们提出自回归离散扩散视频生成模型Lumos-1方法,一个在统一模型视角下构建的自回归视频生成器。
其核心理念是尽可能使用原生的LLM 架构,仅通过最小的改动,就让语言模型“学会”视频生成。我们主要解决了两大关键问题:
-
如何让模型更好理解时空?我们深入研究了旋转位置编码技术(RoPE),发现传统的 3D RoPE 存在频谱不均衡的问题。为此,我们提出了MM-RoPE,它为视觉数据设计了更均衡、更全面的时空位置编码,同时保留了模型原有的文本处理能力。
-
如何有效学习动态变化?为了解决视频帧间信息冗余导致的“学习捷径”问题,我们提出了自回归离散扩散强制(Autoregressive Discrete Diffusion Forcing, AR-DF)。该技术在训练时采用“时间管道掩码”(Temporal Tube Masking),迫使模型真正理解和预测动态变化;在推理时则采用配套策略,确保生成视频的质量和连贯性。
论文地址:https://arxiv.org/abs/2507.08801
代码地址:https://github.com/alibaba-damo-academy/Lumos
模型地址:https://huggingface.co/Alibaba-DAMO-Academy/Lumos-1

研究背景与现有方案的缺陷
自回归大语言模型(LLM)通过将广泛的自然语言任务统一到单一的生成式框架中,取得了显著的进展。它激发了学界与业界在自回归视觉生成领域的初步探索,其最终目标在于构建一个能够统一视觉理解与生成的单一模型(Unified Model),从而推动LLM向通用多模态智能体演进。然而,一个能与现有LLM架构完全兼容、并能实现高效训练推理的自回归视频生成范式,仍是一个未被充分探索的领域。当前的技术路径主要有以下的缺陷:
-
架构异构性:现有的部分自回归视频生成器在架构设计上与标准的LLM存在显著差异。这种架构上的不统一性阻碍了LLM向统一多模态模型的平滑扩展,增加了技术整合的复杂性与难度。
-
对外部文本编码器的依赖:许多主流方法依赖于庞大的、预训练的外部文本编码器来获取文本条件的语义信息。这种设计不仅增加了模型的参数量和系统的复杂度,也与构建一个端到端的统一模型的目标相悖。
-
推理延迟较大:传统的自回归模型采用逐词元的解码方式。当这一策略应用于高维、长序列的视频数据时,其串行生成的特性会导致极高的推理延迟,使得模型在实际应用中缺乏可行性。
为应对上述挑战,我们着手设计并实现了自回归离散扩散视频生成模型Lumos-1模型,核心目标是在尽可能保留LLM原生架构的基础上,构建一个不依赖外部文本编码器、并能实现高效训练推理的自回归视频生成器,从而为构建统一基础模型提供一个坚实且可行的技术路径。

生成理解统一模型视角下的视频生成模型
自回归离散扩散视频生成模型Lumos-1的设计扎根于视频数据的特性:时空关联性和时间因果性。由于视频数据时空关联性的存在,导致了原生大语言模型的简单位置编码不能充分有效地对时空进行建模;而时间因果性则导致了,当自回归模型使用基于掩码的方案进行训练时,很容易产生误入一个“学习捷径”,导致视频生成时序训练不佳。面对这两个挑战,我们提出了核心技术:MM-RoPE与AR-DF。
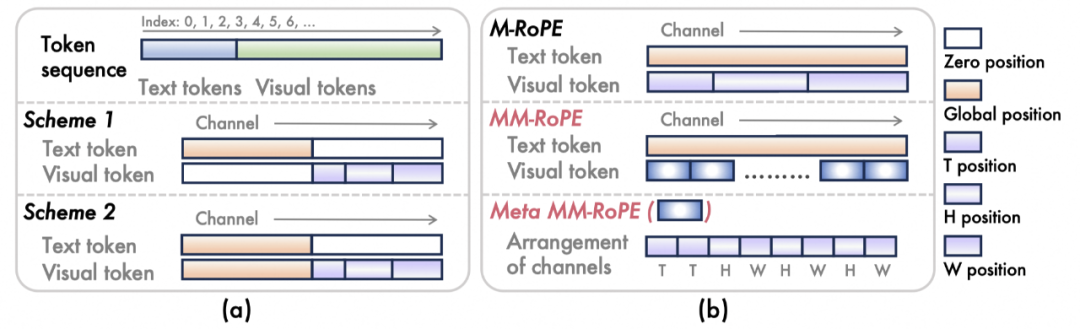
图1(a)3D RoPE诊断的基础方案。(b)MM-RoPE的具体细节
1.MM-RoPE: 面向多模态时空数据的旋转位置编码
原始方案的诊断:为了在LLM中有效注入时空相关性,我们对旋转位置编码(RoPE)进行了深入研究(如图1a、2a所示)。标准RoPE为一维文本序列设计,直接应用于视频数据时存在明显局限,简单的3D RoPE扩展方案存在频率谱分配不均衡的问题(图2b、2c)。具体而言,分配给时间维度的通道占据了过高频段,而空间维度则被分配到近零频段。这导致模型对时间变化过度敏感,而对空间细节的捕捉能力不足,从而限制了生成质量。
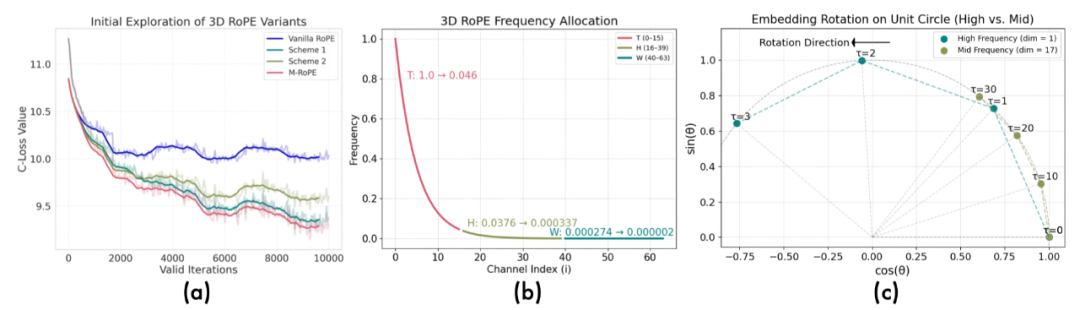
图2 (a)不同3D RoPE方案的验证损失曲线。(b)最原始3D RoPE方案的频率谱分布。(c)时间和高度维度的第一个通道的旋转速度对比。
技术方案:我们提出技术方案MM-RoPE, 该技术在保留原始文本RoPE的同时,为视觉部分提供了更优的时空先验,且无需修改Transformer核心模块,保持了架构的统一性。其核心改进在于:
-
分布式频谱分配:我们将整个通道维度划分为多个元组(meta MM-RoPE),在每个元组内按比例(如T:H:W = 2:3:3)分配给时、空维度,并对称地交错排布高、宽通道。这确保了每个维度都能在完整且均衡的频率谱上进行编码,从而实现对时空信息的精细化建模。通过实验证实,这种频谱分配的方案,比其他方案显著有效。
-
时空尺度缩放:为平衡文本和视觉两种模态在序列长度上的差异,我们根据视觉Tokenization的压缩比,对时空坐标进行尺度缩放。这一操作确保了两种模态的位置编码处于一个相对均衡的范围内,有利于模型进行跨模态对齐学习,从另一个角度来说,这样的做法也增加了坐标位置的分辨率。
2. AR-DF: 自回归离散扩散强制
为规避传统next-token预测的低效,我们采用基于离散扩散(基于掩码)的并行解码方式。然而,视频数据存在帧间信息冗余的问题,为自回归训练带来了帧间损失不平衡的问题。
问题诊断:在自回归设定下,模型可以通过注意力机制“窥视”前一帧的未遮蔽区域,来预测当前帧的被遮蔽词元,导致对后续帧的预测任务变得过于简单。这种“空间信息泄露”使得模型倾向于优化简单的复制任务,而非学习真正的时序动态。
技术方案:我们提出AR-DF (Autoregressive Discrete Diffusion Forcing),AR-DF通过一种新颖的掩码策略,强制模型学习时间维度的信息变化:
-
在训练阶段:我们提出使用时间管道掩码(Temporal Tube Masking)。对于一个视频样本,首先为其第一帧生成一个随机的2D掩码模式,然后将此模沿时间轴重复应用到所有后续帧。这样,同一空间位置的词元在所有帧中,要么同时可见,要么同时被遮蔽,从而有效切断了空间信息泄露的“捷径”,迫使模型依赖时序上下文进行预测。
-
在推理阶段:我们提出与训练对齐的掩码策略。在推理时,我们模拟训练过程中的部分历史观测条件。具体地,在生成下一帧前,对已生成的历史帧进行部分遮蔽再输入模型。这种训练-推理一致性的设计,有效避免了因分布偏移导致的生成质量下降问题。
通过AR-DF,自回归离散扩散视频生成模型Lumos-1能够在保持帧内双向依赖和帧间时序因果性的同时,实现高效且有效的自回归视频生成训练与推理。

实验结果与分析
1.基础任务对比(文生图、文生视频、图生视频)
定量对比:图3的结果展示了我们的模型在3个任务上的性能。
-
文生图能力:在GenEval评测基准上,自回归离散扩散视频生成模型Lumos-1展现了强大的图文对齐能力。与自回归模型对比,我们的3.6B模型性能与拥有8B参数的EMU3比肩。与扩散模型对比,性能优于同等规模的SD-XL,甚至不逊于参数量更大的FLUX模型。此外,其在物体位置关系和属性绑定等细分项上得分突出。这证明了我们提出的MM-RoPE等设计,使得模型即便没有经过文本预训练,也具备了对复杂语言描述的深刻理解能力。
-
文生视频能力:虽然没有专门针对这项任务进行训练,但其自回归特性能够天然支持图生视频。在VBench-I2V基准测试中,自回归离散扩散视频生成模型Lumos-1的表现与顶尖模型COSMOS-Video2World不相上下。COSMOS-Video2World使用了1亿视频数据进行训练,而我们仅使用了1000万,并且计算资源也远少于对方。
-
文生视频能力:在VBench-T2V基准上,其表现同样出色:即使没有依赖一个庞大且预训练好的文本编码器,性能依然能与OpenSoraPlan等依赖强大文本理解能力的先进扩散模型效果相当。由于我们的自回归生成范式保证了第一帧的质量,自回归离散扩散视频生成模型Lumos-1在物体类别和颜色等以物体为中心的指标上表现优异,视频内容的一致性更强。
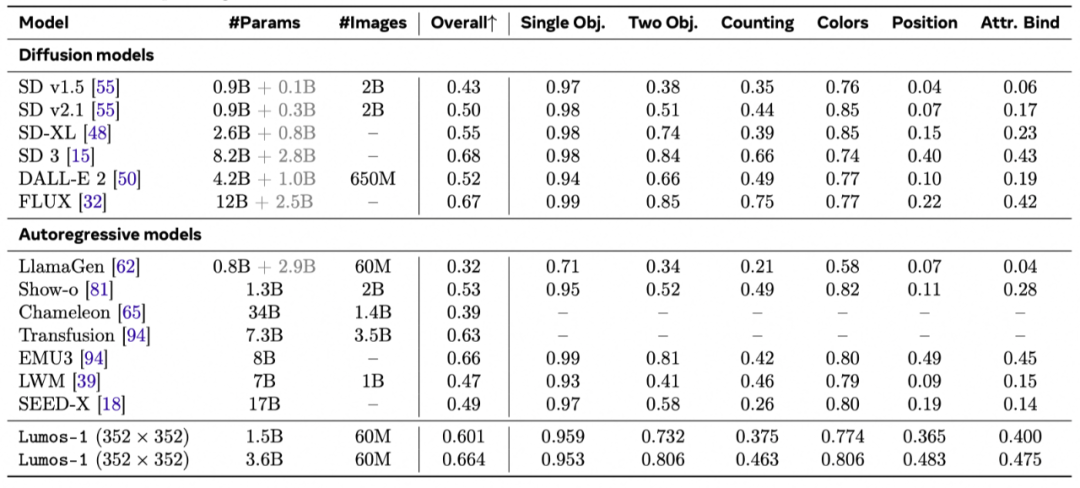
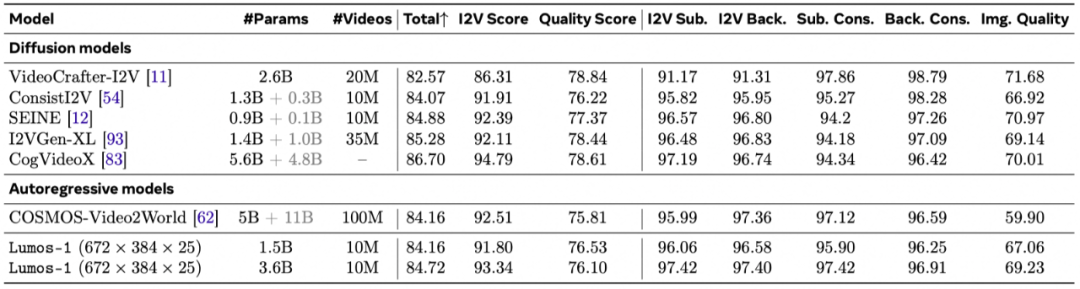
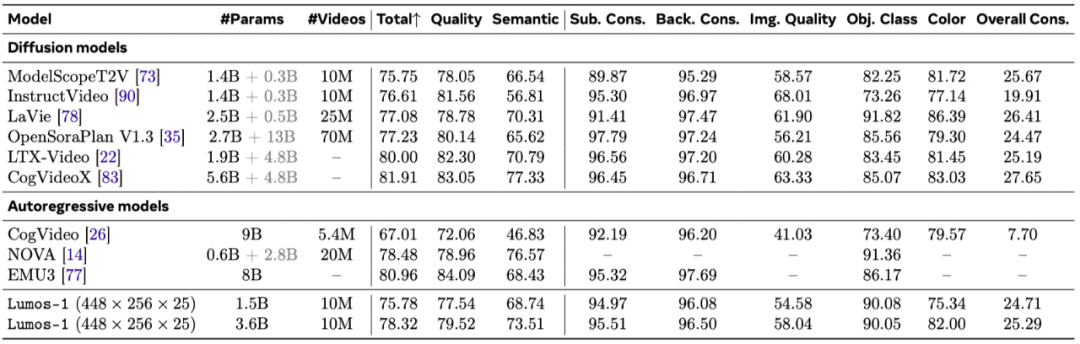
图3 文生图、文生视频、图生视频的定量性能对比。
定性展示:由于模型在训练的过程中使用了多分辨率的数据,并且token序列中编码了分辨率信息,因此,自回归离散扩散视频生成模型Lumos-1可以简单地进行多分辨率得生成,包括横屏和竖屏分辨率。

图4 3种任务的样例可视化。
2.核心技术消融实验
MM-RoPE:我们通过消融实验证明,相比传统的RoPE或M-RoPE,我们提出的MM-RoPE能够让模型:
-
收敛更快,最终的验证损失更低,证明了其在建模时空信息上的优越性(如图5(b)所示)。
-
几乎不增加额外的推理开销,实现了几乎零成本的性能增长(如图6所示)。
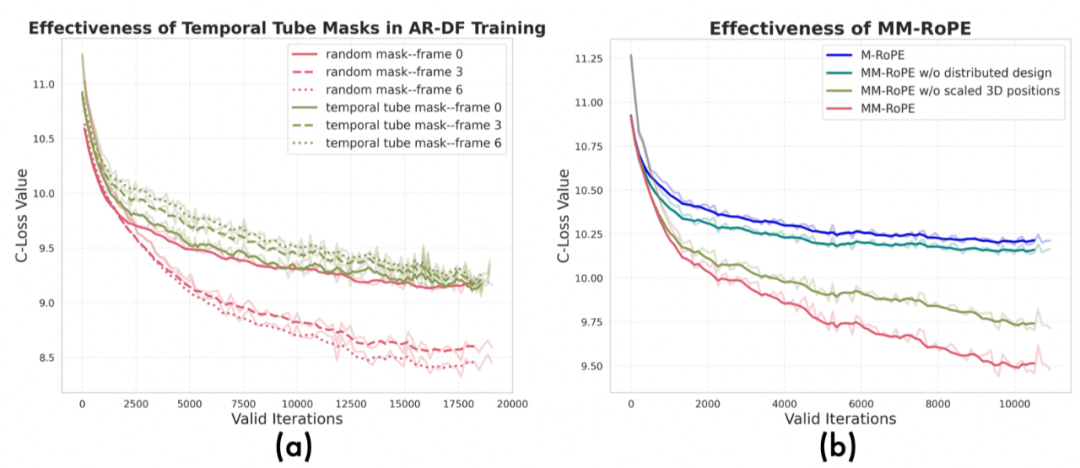
图5 (a) 时间管状掩码的使用对于验证集损失的影响; (b)MM-RoPE中两个关键设计的有效性。

图6 不同类型的RoPE对于推理速度的影响。
AR-DF:
-
训练阶段:实验证明,我们提出的“时间管状掩码”策略有效解决了信息泄露问题,不会造成验证集损失在不同帧之间差距过大,迫使模型学习真正的时间动态,而非简单地从相邻帧“抄作业” (如图5(a)所示)。
-
推理阶段:我们发现,推理时必须采用与训练时相匹配的掩码策略。否则,生成的视频会出现明显的伪影和闪烁。AR-DF推理策略保证了视频的连贯性和高质量,且几乎没有明显的额外开销(如图7所示)。

图7 (a) AR-DF推理阶段使用的掩码比例对于VBench指标的影响; (b) AR-DF推理阶段使用的掩码与否对于可视化结果的影响。
更详细的实验和可视化展示在论文中,欢迎阅读论文。

结论
自回归离散扩散视频生成模型Lumos-1 将LLM的简洁架构应用于自回归视频生成任务。通过MM-RoPE和AR-DF技术,它在保持架构统一性的同时,高效地解决了时空建模和训练不平衡两大难题。实验证明,其是构建下一代视觉-语言统一基础模型的一条极具潜力的技术路径,我们希望有更多基于自回归离散扩散视频生成模型Lumos-1的工作涌现。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ICCV 2025 论文和代码下载
在CVer公众号后台回复:ICCV2025,即可下载ICCV 2025论文和代码开源的论文合CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集
CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)