AI+微服务体系下的可观测性实践:从传统基石到智能未来的进化之路
本文系统阐述了AI与微服务架构融合下可观测性技术的演进与实践。传统微服务观测基于Metrics、Trace、Log三大支柱构建,字节跳动通过自研CloudWeGo技术栈实现高性能埋点采集。AI技术的引入形成了应用层(智能体)、服务层(中间件)和基础设施层(GPU集群)的三维观测挑战,需新增模型监控、智能体行为追踪等能力。全栈可观测体系需融合传统观测手段与AI专用监控工具,实现从底层算力到上层应用的
AI+微服务体系下的可观测性实践:从传统基石到智能未来的进化之路
引言
随着大语言模型、智能体等AI技术与微服务架构的深度融合,系统复杂性呈指数级增长,传统观测体系已难以应对“微服务调用链+AI算力+智能体行为”的三层叠加挑战。字节跳动基于亿级QPS的极端场景锤炼,通过融合OpenTelemetry、Prometheus等开源组件与企业级工具,构建了覆盖全生命周期的全栈可观测体系,为行业提供了极具价值的实践范本。本文将基于该分享内容,系统梳理传统微服务观测的技术基石、AI融合带来的全新挑战、全栈观测的实践路径及未来发展方向,深度解析可观测性在数智化时代的核心价值。
一、传统微服务观测:技术基石与成熟实践
在AI技术深度渗透前,微服务架构已通过多年发展形成了相对成熟的观测体系。字节跳动作为微服务实践的领军企业,自研的CloudWeGo技术栈为观测体系提供了坚实的底层支撑,而Metrics、Trace、Log“三大支柱”与精细化埋点设计则构成了观测能力的核心骨架。
1.1 字节自研微服务框架体系:高性能观测的技术底座
微服务框架是观测体系的起点,框架的设计理念直接决定了观测能力的上限。字节跳动围绕Go与Rust两大语言,构建了涵盖框架、网络库、编解码库的全栈自研体系——CloudWeGo,其核心特点是高性能、高扩展性与组件解耦,为观测埋点的植入与数据采集提供了天然优势。
核心框架:多场景适配的性能标杆
CloudWeGo包含三大核心框架,分别针对不同场景需求设计,共同支撑起字节内部庞大的微服务生态:
- Kitex:Golang语言的RPC框架,以高性能和强扩展性为核心优势。针对RPC场景的低延迟需求,Kitex采用了轻量级设计,同时提供灵活的扩展接口,可轻松融入企业自建的治理体系,成为对性能要求严苛的后端服务首选框架。
- Hertz:Golang语言的HTTP框架,在保持高性能的同时兼顾高易用性。其模块化设计允许开发者根据需求定制中间件与插件,观测埋点可通过中间件形式无缝集成,完美适配内部系统的个性化需求。
- Volo:基于Rust语言的轻量级RPC框架,充分利用Rust的内存安全特性与最新语言特性(如AFIT、RPITIT),在性能与安全性上实现突破,成为字节在高性能场景下的新兴选择。

基础组件:全链路性能优化的支撑体系
除核心框架外,CloudWeGo生态还包含一系列自研基础组件,从数据传输到序列化全环节保障系统性能,同时为观测提供精准的数据采集点:
- 网络库:以Netpoll为代表的高性能NIO网络库,专注于RPC场景的连接管理与数据传输,其内置的连接状态监控为观测提供了底层网络指标;
- 编解码与序列化库:Fastpb、Sonic、Pilota等库通过JIT编译、零拷贝等技术实现极致性能,同时支持对序列化耗时等关键指标的埋点采集;
- 辅助工具:Shmipc提供高性能进程间通信能力,Thriftgo支持可扩展的代码生成,这些工具均预留了观测接口,确保数据采集不影响核心性能。
这些组件的共同特点是“性能优先、观测友好”,既满足了字节亿级QPS场景的性能需求,又为后续的观测体系建设奠定了基础。
1.2 传统观测三大支柱:Metrics、Trace与Log的协同体系
传统微服务观测体系以Metrics(指标)、Trace(链路追踪)、Log(日志)为核心,三者各司其职又相互关联,共同构建起系统运行状态的全景视图。字节跳动基于开源工具与自研组件的融合,实现了三大支柱的无缝协同。
Metrics:系统运行状态的量化标尺
Metrics是观测体系的基础,通过对关键指标的持续采集与分析,实现对系统运行状态的实时监控。字节跳动主要基于Prometheus构建指标体系,核心覆盖三类指标:
- 基础运行指标:包括请求量(QPS)、处理耗时(P95/P99延迟)、错误率等黄金指标,直接反映服务可用性与性能;
- 运行时监控指标:涵盖CPU使用率、内存占用、网络带宽、磁盘IO等资源指标,用于识别资源瓶颈;
- 自定义业务指标:根据业务场景定制的指标,如订单转化率、支付成功率等,实现技术指标与业务价值的关联。
在实践中,字节通过monitor-prometheus项目将指标采集能力集成到微服务应用中,结合VMP(VictoriaMetrics)等监控组件实现指标的长期存储与聚合分析。以Kitex框架为例,开发者可通过kitex-contrib/monitor-prometheus插件快速接入,将服务端与客户端的关键指标暴露给Prometheus采集器,配置示例如下:
import "github.com/kitex-contrib/monitor-prometheus"
import "github.com/cloudwego/kitex/server"
func main() {
svr, err := note.NewServer(
new(NoteServiceImpl),
server.WithTracer(prometheus.NewServerTracer(addr: "9091", path: "/kitexserver")),
)
if err != nil {
log.Fatal(err)
}
if err := svr.Run(); err != nil {
log.Printf("server stopped with error: %v", err)
}
}
Trace:分布式调用链路的全景追踪
Trace通过追踪请求在分布式系统中的流转路径,解决了微服务架构下的“链路断层”问题。字节跳动基于OpenTelemetry标准构建链路追踪体系,核心通过obs-opentelemetry项目实现埋点注入与数据采集。
传统微服务的Trace覆盖从客户端发起调用到服务端处理完毕的全流程,关键埋点包括:
- 调用启动阶段:RPCStart(调用开始)、ClientConnStart(连接建立开始)等;
- 数据传输阶段:WriteStart(请求发送开始)、WaitReadStart(等待响应开始)等;
- 处理阶段:ServerHandleStart( handler处理开始)、ServerHandleFinish(handler处理完毕)等;
- 调用结束阶段:RPCFinish(调用结束)、ReadFinish(响应接收完毕)等。
这些埋点通过OpenTelemetry Collector汇总后,推送至应用观测平台,生成火焰图、拓扑图等可视化视图,帮助开发者快速定位链路中的性能瓶颈。例如,通过火焰图可直观识别某一RPC调用中序列化耗时过长的问题,通过拓扑图可清晰看到服务间的依赖关系与调用频率。
Log:系统行为的详细日志记录
Log作为事件级别的记录,为问题排查提供了细粒度的上下文信息。字节跳动将日志与Trace、Metrics进行关联,通过Trace ID实现“日志-链路-指标”的联动分析——开发者可通过指标告警定位异常服务,通过Trace ID追踪关联的调用链路,再通过日志查看具体的错误堆栈与业务上下文,大幅提升问题排查效率。
1.3 精细化埋点设计:可控性与性能的平衡艺术
埋点是观测数据的来源,但其采集过程必然消耗系统资源。字节跳动通过对埋点位置、粒度与控制方式的精细化设计,实现了观测需求与系统性能的平衡。
埋点位置与粒度分级
埋点位置覆盖微服务调用的全生命周期,从客户端连接建立到服务端处理完毕,关键节点均设置采集点。同时,为适应不同场景的性能需求,埋点粒度分为三级:
- LevelDisabled:禁用埋点,适用于极致性能场景;
- LevelBase:仅启用基本埋点(如RPCStart、RPCFinish),平衡性能与观测需求;
- LevelDetailed:启用基本埋点与细粒度埋点(如序列化耗时、连接建立耗时),适用于问题排查与性能优化场景。
埋点控制的实践实现
开发者可通过框架API灵活配置埋点级别,客户端与服务端均支持独立设置。以Kitex框架为例,客户端埋点配置如下:
import "github.com/cloudwego/kitex/client"
import "github.com/cloudwego/kitex/pkg/stats"
func main() {
baseStats := client.WithStatsLevel(stats.LevelBase)
client, err := echo.NewClient("echo", baseStats)
if err != nil {
log.Fatal(err)
}
}
服务端埋点配置如下:
import "github.com/cloudwego/kitex/server"
import "github.com/cloudwego/kitex/pkg/stats"
func main() {
baseStats := server.WithStatsLevel(stats.LevelBase)
svr, err := echo.NewServer(new(NoteServiceImpl), baseStats)
if err != nil {
log.Fatal(err)
}
if err := svr.Run(); err != nil {
log.Printf("server stopped with error: %v", err)
}
}
这种精细化的埋点设计,使得字节跳动的微服务在亿级QPS场景下,既能保障核心业务的性能稳定,又能提供足够的观测数据支撑问题排查。
二、AI+微服务:可观测性的全新挑战
当AI技术(尤其是大语言模型、智能体)与微服务架构深度融合后,系统从“服务调用网络”进化为“AI能力+服务集群”的复合体系,呈现出应用层、服务依赖层、基础设施层的三层叠加结构。这种结构带来了传统观测体系无法覆盖的全新挑战,主要集中在模型全生命周期监控、智能体行为分析与端到端全链路追踪三大维度。
2.1 AI+微服务的三层体系结构

AI与微服务的融合并非简单的技术叠加,而是形成了相互支撑的三层体系,每层均存在独特的观测需求:
- 应用层:以Multi-Agent(多智能体)为核心,融合大语言模型(LLM)、RAG(检索增强生成)等AI能力,同时包含Langchain、LlamaIndex、Eino等智能体框架,需关注智能体的会话行为、调用决策与输出质量;
- 服务依赖层:涵盖AI网关、MCP(模型控制平台)、推理引擎、向量数据库、知识库等中间组件,是AI能力与微服务的连接枢纽,需监控组件间的调用效率与数据流转;
- 基础设施层:以GPU集群为核心,配套高带宽低延迟网络(如InfiniBand、NVLink)与高速存储(如HBM),需保障AI计算所需的算力、带宽与存储资源稳定供给。
这种三层结构打破了传统微服务的“服务-数据库”二元依赖,引入了GPU、向量数据库、模型等全新观测对象,使得观测维度从“服务性能”扩展至“AI能力+服务性能+资源供给”的复合维度。
2.2 模型全生命周期的观测难题
模型是AI+微服务体系的核心资产,其从训练到推理的全生命周期均存在传统观测无法覆盖的监控需求,主要体现在训练过程的指标追踪、推理阶段的性能监控与资源消耗分析三个方面。
模型训练:指标复杂且关联性强
模型训练是AI能力生成的基础,其观测难点在于指标维度多、关联性强且需长期追踪。字节跳动在实践中发现,训练过程需重点监控两类指标:
- 算法指标:包括Loss(损失值)、Precision(精确率)、Recall(召回率)、Accuracy(准确率)等核心指标,反映模型的训练效果;
- 运行时指标:涵盖训练集群状态、任务调度进度、节点资源使用率(CPU、GPU、内存、网络)等,影响训练效率与稳定性。
此外,训练过程中的超参数(如学习率、批次大小)记录与指标横向对比也至关重要——不同训练实验的超参数差异可能导致算法指标的显著变化,需通过观测数据建立“超参数-算法指标-训练效率”的关联关系,为模型优化提供依据。
模型推理:性能指标与Token消耗并重
推理阶段是模型提供服务的核心环节,直接影响用户体验,其观测难点在于需同时关注性能指标与Token消耗:
- 性能指标:除传统的接口延时、请求速率、错误率外,新增首Token延时(从请求发起至首个Token输出的时间)与非首Token延时(后续Token的生成间隔),前者直接决定用户的等待感知,后者影响长文本生成效率;
- Token消耗指标:包括Token输入长度、输出长度、消耗速率等,既关系到模型服务的成本控制(Token用量直接关联计费),也反映请求的复杂度与模型的处理效率。
以字节自研的xLLM推理引擎与VLLM开源引擎为例,首Token延时通常在数百毫秒级别,非首Token延时需控制在几十毫秒级别,一旦超出阈值需快速定位是模型参数过大、GPU算力不足还是推理引擎优化不足导致。
基础设施:GPU资源监控难度大
GPU是模型训练与推理的核心算力来源,其监控难度远高于传统CPU资源。主要原因在于:
- 监控维度多:需同时监控GPU使用率、显存占用、NVLink带宽、温度等指标,且指标间存在耦合(如显存不足会导致GPU使用率骤降);
- 资源竞争激烈:一个GPU集群可能同时支撑多个训练任务与推理服务,需精确追踪每个任务/服务的GPU资源占用,避免资源争抢导致的性能下降;
- 故障影响范围广:单块GPU故障可能导致整个训练任务失败或推理服务不可用,需实现故障的快速定位与自动隔离。
2.3 智能体与全链路的观测复杂度
智能体的出现使得AI+微服务体系具备了自主决策能力,但也带来了行为可解释性差、会话追踪难等观测挑战,同时端到端全链路的范围扩展进一步提升了观测难度。
智能体:行为可解释性与用量统计难题
智能体通过调用工具、多轮对话实现复杂任务,但传统观测体系无法覆盖其核心行为:
- 行为可解释性:智能体的决策过程(如为何调用某一工具、为何选择某一模型)缺乏透明性,当输出结果异常时,难以通过传统Trace定位问题根源;
- 用量统计:智能体通常包含多轮会话,每轮会话可能调用多个模型与服务,需精确统计单个会话的Token总消耗、模型调用次数与工具调用频率,用于成本核算与性能优化;
- 框架适配:Langchain、LlamaIndex、Eino等智能体框架的埋点机制不同,传统观测工具无法实现统一的数据采集,导致智能体观测存在“框架孤岛”。
端到端全链路:范围扩展且节点复杂
AI+微服务的全链路已从传统的“客户端-API网关-服务-数据库”扩展至“用户终端-接入网关-AI网关-智能体-模型-微服务-基础设施”的超长链路,其观测难点在于:
- 节点类型多样:链路中包含终端设备(App、Web、小程序)、云服务(FaaS、容器化服务)、AI组件(模型、向量数据库)、基础设施(GPU、InfiniBand)等多种类型节点,需适配不同节点的数据采集方式;
- 数据格式异构:服务调用产生Trace/Metrics/Log数据,模型输出产生文本/图像/音频等多模态数据,基础设施产生资源监控数据,数据格式的异构性导致统一分析难度大;
- 告警关联困难:某一用户体验问题可能由多层问题导致(如智能体响应慢可能是GPU算力不足,也可能是模型推理效率低或服务调用超时),传统告警仅能定位单一环节,无法实现跨层关联分析。
三、全栈观测实践:字节跳动的解决方案
针对AI+微服务体系的观测挑战,字节跳动基于自身亿级QPS场景的实践经验,构建了“全链路覆盖+精细化监控+数据驱动优化”的全栈观测体系。该体系以OpenTelemetry为标准化采集入口,融合Prometheus等开源工具与自研平台,实现了从终端到基础设施、从服务到模型的全维度观测,核心包括端到端全链路观测、模型训练/推理监控、智能体观测与数据回流优化四大模块。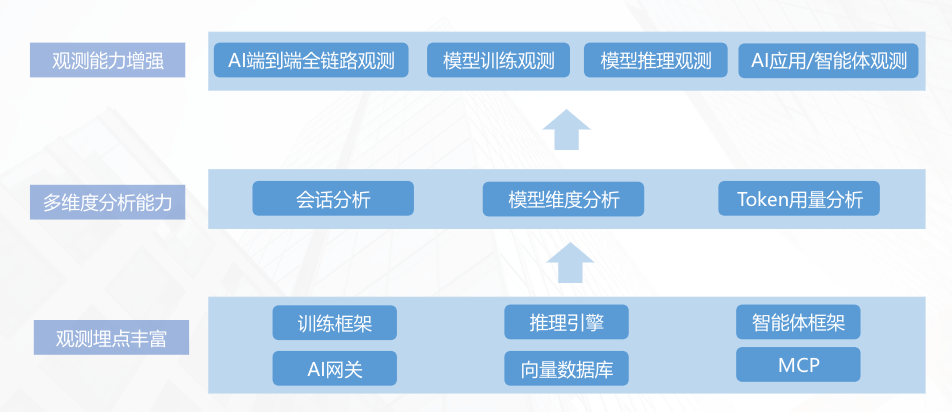
3.1 端到端全链路观测:从终端到AI引擎的全覆盖
端到端全链路观测是解决链路复杂问题的核心,其核心思路是“埋点全覆盖+数据统一存储+统一视图分析”,实现从用户终端到AI引擎的每一个节点均可观测、可追溯。
埋点覆盖:全链路无死角
字节跳动在实践中对全链路进行了“颗粒化埋点”,覆盖以下关键节点:
- 端侧:通过APM客户端监控采集App、Web、小程序的用户行为数据(如请求发起时间、页面加载耗时);
- 接入层:在ingress/nginx、API网关部署埋点,监控请求转发效率与错误率;
- 应用层:包含容器化服务、FaaS化服务、传统微服务,通过CloudWeGo框架埋点采集服务调用数据;
- AI层:在AI网关、智能体框架、MCP、推理引擎、向量数据库部署专属埋点,采集AI组件的调用数据;
- 基础设施层:通过Prometheus+Exporter采集GPU、CPU、内存、网络等资源指标。
这种全链路埋点确保了每一个数据流转环节均有观测数据支撑,为后续的链路追踪与问题定位奠定基础。
数据存储与分析:多引擎协同
全链路产生的Metrics、Trace、Log数据格式不同、查询需求各异,字节跳动采用“多引擎协同”的存储策略,实现数据的高效存储与快速查询:
- 时序数据引擎:存储Metrics数据,支持秒级聚合与长期归档,适配资源监控、性能指标等周期性数据的查询需求;
- Trace分析引擎:存储Trace数据,支持基于Trace ID的全链路检索与火焰图生成,适配链路性能分析;
- 日志存储引擎:存储全量Log数据,支持关键词检索与上下文关联,适配问题排查场景。
同时,字节跳动构建了统一可观测大盘,将三类数据进行关联分析,实现“告警统一关联-指标下钻-Trace追踪-日志排查”的闭环流程。例如,当用户反馈智能体响应慢时,可通过大盘定位到告警指标(如推理延时超标),下钻至具体Trace查看链路瓶颈(如GPU算力不足),再通过日志确认GPU节点的资源使用率异常,最终定位问题根源。
3.2 模型观测:训练与推理的精细化监控
针对模型全生命周期的观测需求,字节跳动构建了“训练实验监控+推理性能分析+资源监控”的三位一体解决方案,适配不同框架与引擎的监控需求。
训练实验观测:指标追踪与对比分析
为解决训练过程的指标监控难题,字节跳动开发了专属的训练实验观测平台,具备三大核心能力:
- 全指标采集:通过集成RAY、NVIDIA Dynamo等训练框架的监控接口,实时采集算法指标(Loss、Precision等)与运行时指标(集群状态、资源使用率等),并自动记录超参数信息;
- 多维度分析:支持同一模型不同实验的指标横向对比,通过折线图、柱状图等可视化方式展示超参数对训练效果的影响;
- 多媒体支持:针对图像生成等多模态模型,支持将训练过程中的生成结果与指标关联存储,直观展示模型效果的进化过程。
该平台使得算法工程师无需编写额外监控代码,即可实现训练过程的全程可视,大幅提升模型迭代效率。
推理性能监控:聚焦核心指标与引擎适配
推理阶段的监控核心是“性能指标+Token消耗”,字节跳动通过适配不同推理引擎,实现了精细化监控:
- 引擎适配:支持VLLM、NVIDIA Dynamo、自研xLLM等主流推理引擎,通过引擎原生接口采集首Token延时、非首Token延时、Token消耗速率等核心指标;
- 指标可视化:在统一大盘中展示单接口/单模型的性能趋势,支持按Token输入长度、输出长度进行维度拆分,识别不同请求类型的性能差异;
- 告警配置:针对首Token延时(如阈值200ms)、错误率(如阈值1%)等关键指标设置告警,确保推理服务质量稳定。
基础资源监控:GPU为核心的全维度覆盖
基础设施层的监控以GPU为核心,字节跳动通过自研监控插件与开源工具结合,实现了资源指标的全维度采集:
- GPU监控:采集使用率、显存占用、NVLink带宽、温度等指标,支持按模型/任务维度拆分资源占用;
- 网络监控:监控InfiniBand、NVLink的带宽利用率与延迟,确保模型数据传输效率;
- 存储监控:追踪HBM等高速存储的读写速率与容量使用率,避免存储成为性能瓶颈。
3.3 智能体观测:框架适配与多维度分析
智能体是AI+微服务体系的交互入口,其观测核心是“行为可追溯、性能可监控、用量可统计”。字节跳动通过适配主流智能体框架、设计专属埋点机制与构建多维度分析能力,实现了智能体的全生命周期观测。
框架适配:基于标准协议的统一采集
针对智能体框架碎片化问题,字节跳动以OpenTelemetry为标准协议,实现了对Langchain、LlamaIndex、Eino等主流框架的统一适配,核心通过“Callback机制”注入埋点。
以字节自研的Eino框架为例,其作为覆盖DevOps全流程的大模型应用开发框架,支持“横切面功能注入”与“中间状态透出”:开发者可注册Callback Handler,在智能体运行的关键时机(如节点启动、结束、报错)接收回调信息,实现埋点数据采集。Eino的Callback接口定义如下:
type Handler interface {
OnStart(ctx context.Context, info *RunInfo, input CallbackInput) context.Context
OnEnd(ctx context.Context, info *RunInfo, output CallbackOutput) context.Context
OnError(ctx context.Context, info *RunInfo, err error) context.Context
OnStartWithStreamInput(ctx context.Context, info *RunInfo, input *schema.StreamReader[CallbackInput]) context.Context
OnEndWithStreamOutput(ctx context.Context, info *RunInfo, output *schema.StreamReader[CallbackOutput]) context.Context
}
这种基于Callback的埋点机制,既适配了智能体的运行逻辑,又确保了观测数据符合OpenTelemetry标准,实现了不同框架的统一采集。
多维度分析:从性能到行为的全视角监控
智能体观测需覆盖性能、行为、用量三大维度,字节跳动在实践中构建了完善的分析能力:
- Metrics监控:包含三类核心指标——大模型指标(Token输入/输出长度、消耗速率)、黄金指标(响应延时、错误率、调用量)、运行时指标(智能体启动耗时、工具调用次数);
- Tracing分析:通过Trace列表、火焰图、拓扑图等视图,展示智能体内部节点的调用关系与耗时分布,定位如工具调用超时、模型响应慢等问题;
- 会话分析:通过配置会话ID与用户ID,将多轮对话与对应的调用链关联,展示会话整体的Token消耗、调用链总数、每轮对话的Input/Output等信息,实现“用户问题-智能体决策-服务调用”的全链路追溯。
以多轮会话分析为例,当用户与智能体进行多轮交互时,系统会为每个会话分配唯一ID,每轮对话对应一条调用链。通过会话ID筛选,开发者可查看该会话中智能体调用模型、工具的次数与耗时,当输出结果异常时,可快速定位是某轮调用的模型输出错误还是工具返回数据不准确。
3.4 数据回流:从观测到模型优化的闭环
观测数据的价值不仅在于问题排查,更在于驱动AI能力与系统性能的持续优化。字节跳动创新性地构建了“观测数据回流-模型微调-评测”的闭环机制,将Trace数据转化为模型优化的核心资产。
数据回流的核心流程
该闭环机制的核心是从Trace数据中提取有效信息,补充训练与评测数据集,具体流程如下:
- 数据采集:从Trace数据中提取智能体与模型的Input/Output信息,筛选高质量的对话样本与调用案例;
- 数据处理:对采集的样本进行清洗、标注(如标注优质回答、错误调用案例),分别构建训练数据集与评测数据集;
- 模型微调:将训练数据集用于模型SFT(有监督微调),优化模型对特定场景的理解与输出能力;
- 效果评测:利用评测数据集对微调后的模型、智能体或Prompt进行效果评估,验证优化效果。
例如,通过分析客服场景的Trace数据,发现智能体对“退款流程”的回答准确率较低,可提取相关对话样本构建训练集,对模型进行微调后,再用评测集验证回答准确率的提升效果。
这种机制使得观测不再是“被动监控”,而是成为“主动优化”的数据源,实现了“观测-分析-优化-再观测”的持续迭代,大幅提升了AI+微服务体系的核心竞争力。
四、未来展望:多模态、自治与标准化
随着AI与微服务的融合不断深化,可观测性将向“多模态融合、智能自治、开源标准化”三大方向演进,突破当前的技术局限,构建更智能、更全面、更易用的观测体系。钱世俊在分享中结合字节跳动的实践预判,未来三年将是可观测性技术实现跨越式发展的关键时期。
4.1 多模态观测:跨类型数据的融合分析
当前观测体系主要聚焦于文本类型数据(如日志、Trace)与时序数据(如Metrics),但AI+微服务体系已产生大量图像、音频、视频等多模态数据,这些数据与业务效果直接相关。未来的多模态观测将实现三大突破:
- 数据融合:打破单一数据类型的局限,实现文本、图像、音频、时序信号的统一存储与关联分析,例如将用户上传的图像(输入)、智能体生成的描述(输出)、模型推理耗时(时序数据)关联存储;
- 因果推理:结合AI技术构建因果推理模型,精准定位跨模态数据漂移问题,如图文生成场景中“输入图像与输出描述不匹配”的根源(可能是模型训练数据分布变化或推理引擎故障);
- 可解释性构建:通过多模态数据的关联分析,构建“输入-输出-业务效果”的全链路可解释性,例如展示某一广告图像的点击率下降与模型生成的文案质量、服务响应延时的关联关系。
4.2 AIOps智能体:自治闭环的运维进化
当前AIOps技术主要用于告警降噪与根因分析,未来将升级为“感知-分析-决策-行动”的自治闭环智能体,实现运维的自动化与智能化:
- 感知层:基于多模态观测数据,实时感知系统状态变化,包括服务性能波动、模型效果下降、资源瓶颈等;
- 分析层:通过机器学习算法预测系统风险,如基于GPU资源使用率趋势预测1小时后可能出现的算力不足,基于模型错误率变化预测数据漂移;
- 决策层:结合业务优先级与系统状态,生成最优处理策略,如对核心业务的推理服务优先分配GPU资源,对非核心服务进行限流;
- 行动层:联动策略引擎自动执行操作,包括扩缩容(增加GPU节点)、流量调度(将请求转发至空闲推理引擎)、热更新(部署优化后的模型)等。
这种自治闭环将大幅降低运维成本,使运维人员从“被动救火”转向“主动规划”,适应AI+微服务体系的动态变化需求。
4.3 开源生态的标准化:破解工具链碎片化
当前可观测性工具链存在严重的碎片化问题——不同框架、不同厂商的工具数据格式与协议不统一,导致集成成本高、数据孤岛严重。未来的开源标准化将聚焦两大方向:
- 数据格式统一:推动OpenTelemetry制定GenAI(生成式AI)场景的Semantic Conventions(语义规范),统一模型、智能体、向量数据库等AI组件的观测数据格式;
- 协议接口标准化:定义观测工具与AI组件的对接协议,使得不同厂商的监控工具可无缝接入各类AI框架与推理引擎,解决“一套工具适配一类组件”的现状。
字节跳动作为CloudWeGo开源社区的主导者,已在推动观测标准与开源工具的融合,未来将联合CPAOPS、开放运维联盟等机构,加速AI+微服务场景的观测标准化进程。
结语
从传统微服务的“三大支柱”到AI+微服务的“全栈观测”,可观测性的演进本质上是技术体系适应系统复杂性增长的必然结果。字节跳动基于自身亿级QPS场景的实践,证明了“开源组件+自研工具”的融合路径是解决AI+微服务观测难题的有效方案——通过精细化埋点实现数据全采集,通过多引擎存储实现数据全分析,通过数据回流实现能力全优化。
未来,随着多模态观测、AIOps智能体与开源标准化的落地,可观测性将从“系统监控工具”升级为“数智化体系的神经中枢”,不仅能保障系统稳定运行,更能驱动AI能力与业务价值的持续提升。对于企业而言,布局AI+微服务的可观测性实践,不仅是应对技术挑战的必需之举,更是在数智化时代构建核心竞争力的战略选择。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)