构建一个主动深度思考的RAG管道以解决复杂查询
本文探讨了RAG(检索增强生成)系统的局限性,并提出了一种"深度思考RAG管道"的改进方案。传统RAG系统因采用线性处理方式而难以应对复杂的多步骤查询。新方案通过六个关键步骤(规划、检索、精炼、反思、批判和综合)实现了循环推理过程,能够更好地处理需要多跳推理的复杂查询。文章详细介绍了实现该方案的代码设置,包括环境配置、知识库来源(使用NVIDIA 2023年10-K文件)以及数
0 引言
RAG 系统经常失败,不是因为大型语言模型(LLM)缺乏智能,而是因为其架构过于简单。它试图用线性、一次性的方法来处理一个循环的、多步骤的问题。
许多复杂的查询需要推理、反思以及关于何时采取行动的明智决策,这与我们面对问题时检索信息的方式非常相似。这就是 RAG 管道中代理驱动行动发挥作用的地方。让我们看看一个典型的深度思考 RAG 管道是什么样子的……
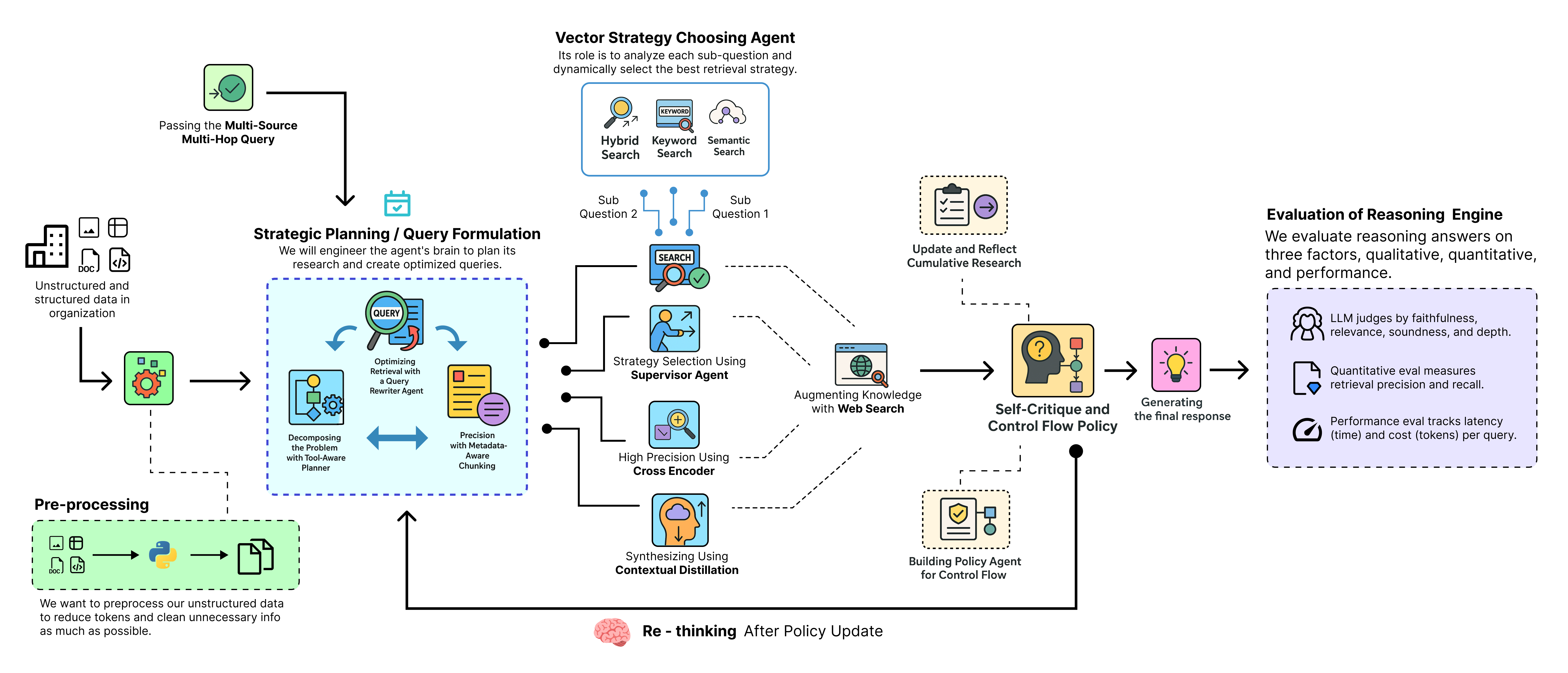
深度思考 RAG 管道:
- 规划: 首先,代理将复杂的用户查询分解为结构化的多步骤研究计划,决定每个步骤需要使用哪种工具(内部文档搜索或网络搜索)。
- 检索: 对于每个步骤,它执行一个自适应的多阶段检索漏斗,使用一个监督器动态选择最佳搜索策略(向量、关键词或混合)。
- 精炼: 然后,它使用高精度交叉编码器对初始结果进行重新排序,并使用蒸馏代理将最佳证据压缩成简洁的上下文。
- 反思: 在每个步骤之后,代理总结其发现并更新其研究历史,逐步建立对问题的累积理解。
- 批判: 策略代理随后检查此历史记录,做出战略决策,以决定是继续进行下一个研究步骤、如果遇到死胡同则修改计划,还是结束。
- 综合: 一旦研究完成,最终代理将所有来源收集到的证据综合成一个单一、全面且可引用的答案。
在这篇博客中,我们将实现整个深度思考 RAG 管道,并将其与基本 RAG 管道进行比较,以展示它如何解决复杂的多跳查询。
所有代码和理论都可以在我的 GitHub 仓库中找到:
deep-thinking-rag
1 设置环境
在我们开始编写深度 RAG 管道的代码之前,我们需要从一个坚实的基础开始,因为一个生产级的 AI 系统不仅关乎最终算法,还关乎我们在设置过程中做出的深思熟虑的选择。
我们将要实现的每个步骤对于确定最终系统将有多么有效和可靠都至关重要。
当我们开始开发管道并进行试错时,最好以纯字典格式定义我们的配置,因为稍后,当管道变得复杂时,我们可以简单地参考这个字典来更改配置并查看其对整体性能的影响。
config = {
"data_dir": "./data",
"vector_store_dir": "./vector_store",
"llm_provider": "openai",
"reasoning_llm": "gpt-4o",
"fast_llm": "gpt-4o-mini",
"embedding_model": "text-embedding-3-small",
"reranker_model": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"max_reasoning_iterations": 7,
"top_k_retrieval": 10,
"top_n_rerank": 3,
}
这些键很容易理解,但有三个键值得一提:
llm_provider:这是我们正在使用的 LLM 提供商,在本例中是 OpenAI。我使用 OpenAI 是因为我们可以在 LangChain 中轻松切换模型和提供商,但您可以选择任何适合您需求的提供商,如 Ollama。reasoning_llm:这必须是我们整个设置中最强大的模型,因为它将用于规划和综合。fast_llm:这应该是一个更快、更便宜的模型,因为它将用于更简单的任务,如基线 RAG。
现在我们需要导入我们将在整个管道中使用的所需库,并将 API 密钥设置为环境变量,以避免在代码块中暴露它们。
import os
import re
import json
from getpass import getpass
from pprint import pprint
import uuid
from typing import List, Dict, TypedDict, Literal, Optional
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass(f"Enter your {var}: ")
_set_env("OPENAI_API_KEY")
_set_env("LANGSMITH_API_KEY")
_set_env("TAVILY_API_KEY")
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_PROJECT"] = "Advanced-Deep-Thinking-RAG"
我们还启用了 LangSmith 进行追踪。当您使用具有复杂循环工作流的代理系统时,追踪不仅仅是锦上添花,它很重要。它有助于您可视化正在发生的事情,并使调试代理的思维过程变得更加容易。
2 知识库来源
一个生产级的 RAG 系统需要一个既复杂又要求高的知识库,才能真正展示其有效性。为此,我们将使用 NVIDIA 2023 年 10-K 文件,这是一份超过一百页的综合文档,详细说明了公司的业务运营、财务业绩和披露的风险因素。
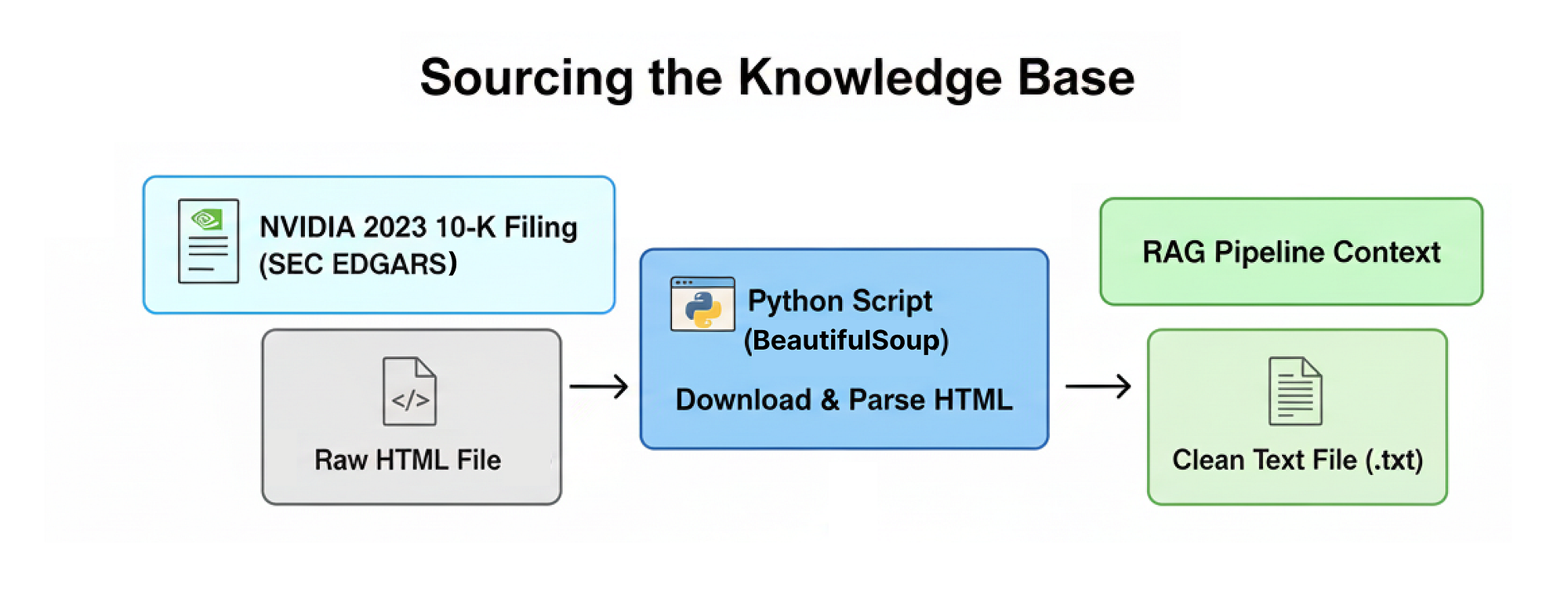
知识库来源
首先,我们将实现一个自定义函数,它以编程方式直接从 SEC EDGAR 数据库下载 10-K 文件,解析原始 HTML,并将其转换为适合 RAG 管道摄取的干净、结构化文本格式。所以,让我们编写这个函数。
import requests
from bs4 import BeautifulSoup
from langchain.docstore.document import Document
def download_and_parse_10k(url, doc_path_raw, doc_path_clean):
if os.path.exists(doc_path_clean):
print(f"Cleaned 10-K file already exists at: {doc_path_clean}")
return
print(f"Downloading 10-K filing from {url}...")
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
response.raise_for_status()
with open(doc_path_raw, 'w', encoding='utf-8') as f:
f.write(response.text)
print(f"Raw document saved to {doc_path_raw}")
soup = BeautifulSoup(response.content, 'html.parser')
text = ''
for p in soup.find_all(['p', 'div', 'span']):
text += p.get_text(strip=True) + '\n\n'
clean_text = re.sub(r'\n{3,}', '\n\n', text).strip()
clean_text = re.sub(r'\s{2,}', ' ', clean_text).strip()
with open(doc_path_clean, 'w', encoding='utf-8') as f:
f.write(clean_text)
print(f"Cleaned text content extracted and saved to {doc_path_clean}")
这段代码很容易理解,我们使用 beautifulsoup4 来解析 HTML 内容并提取文本。它将帮助我们轻松导航 HTML 结构并检索相关信息,同时忽略任何不必要的元素,如脚本或样式。
现在,让我们执行它并看看它是如何工作的。
print("Downloading and parsing NVIDIA's 2023 10-K filing...")
# Assuming url_10k, doc_path_raw, doc_path_clean are defined elsewhere
# For demonstration, let's define them here
url_10k = "https://www.sec.gov/Archives/edgar/data/1045810/000104581023000017/nvda-20230129.htm"
doc_path_raw = "./data/nvda_10k_2023_raw.html"
doc_path_clean = "./data/nvda_10k_2023_clean.txt"
# Ensure the data directory exists
os.makedirs(os.path.dirname(doc_path_raw), exist_ok=True)
download_and_parse_10k(url_10k, doc_path_raw, doc_path_clean)
with open(doc_path_clean, 'r', encoding='utf-8') as f:
print("\n--- Sample content from cleaned 10-K ---")
print(f.read(1000) + "...")
Downloading and parsing NVIDIA 2023 10-K filing...
Successfully downloaded 10-K filing from https://www.sec.gov/Archives/edgar/data/1045810/000104581023000017/nvda-20230129.htm
Raw document saved to ./data/nvda_10k_2023_raw.html
Cleaned text content extracted and saved to ./data/nvda_10k_2023_clean.txt
Item 1. Business.
OVERVIEW
NVIDIA is the pioneer of accelerated computing. We are a full-stack computing company with a platform strategy that brings together hardware, systems, software, algorithms, libraries, and services to create unique value for the markets we serve. Our work in accelerated computing and AI is reshaping the worlds largest industries and profoundly impacting society.
Founded in 1993, we started as a PC graphics chip company, inventing the graphics processing unit, or GPU. The GPU was essential for the growth of the PC gaming market and has since been repurposed to revolutionize computer graphics, high performance computing, or HPC, and AI.
The programmability of our GPUs made them ...
我们只是调用这个函数,将所有内容存储在一个 txt 文件中,该文件将作为我们 RAG 管道的上下文。
当我们运行上面的代码时,您可以看到它开始为我们下载报告,并且我们可以看到我们下载内容的样本。
3 理解我们的多源、多跳查询
为了测试我们实现的管道并将其与基本 RAG 进行比较,我们需要使用一个非常复杂的查询,涵盖我们正在处理的文档的不同方面。
我们的复杂查询:
“根据 NVIDIA 2023 年 10-K 文件,识别其与竞争相关的关键风险。然后,查找有关 AMD 2024 年 AI 芯片战略的最新新闻(文件发布后),并解释这一新战略如何直接解决或加剧 NVIDIA 声明的风险之一。”
让我们分析一下为什么这个查询对于标准 RAG 管道来说如此困难:
- 多跳推理: 它不能一步回答。系统必须首先识别风险,然后找到 AMD 的新闻,最后将两者综合起来。
- 多源知识: 所需信息存在于两个完全不同的地方。风险在我们静态的内部文档(10-K)中,而 AMD 的新闻是外部的,需要访问实时网络。
- 综合与分析: 查询不要求简单的事实列表。它要求解释一组事实如何使另一组事实恶化,这项任务需要真正的综合。
在下一节中,我们将实现基本的 RAG 管道,实际看看简单的 RAG 是如何失败的。
4 构建一个会失败的浅层 RAG 管道
现在我们已经配置好环境并准备好具有挑战性的知识库,下一步是构建一个标准的普通 RAG 管道。这有一个关键目的……
首先构建最简单的解决方案,我们可以用它来运行我们的复杂查询,并准确观察它如何以及为什么失败。
以下是我们将在本节中要做的事情:
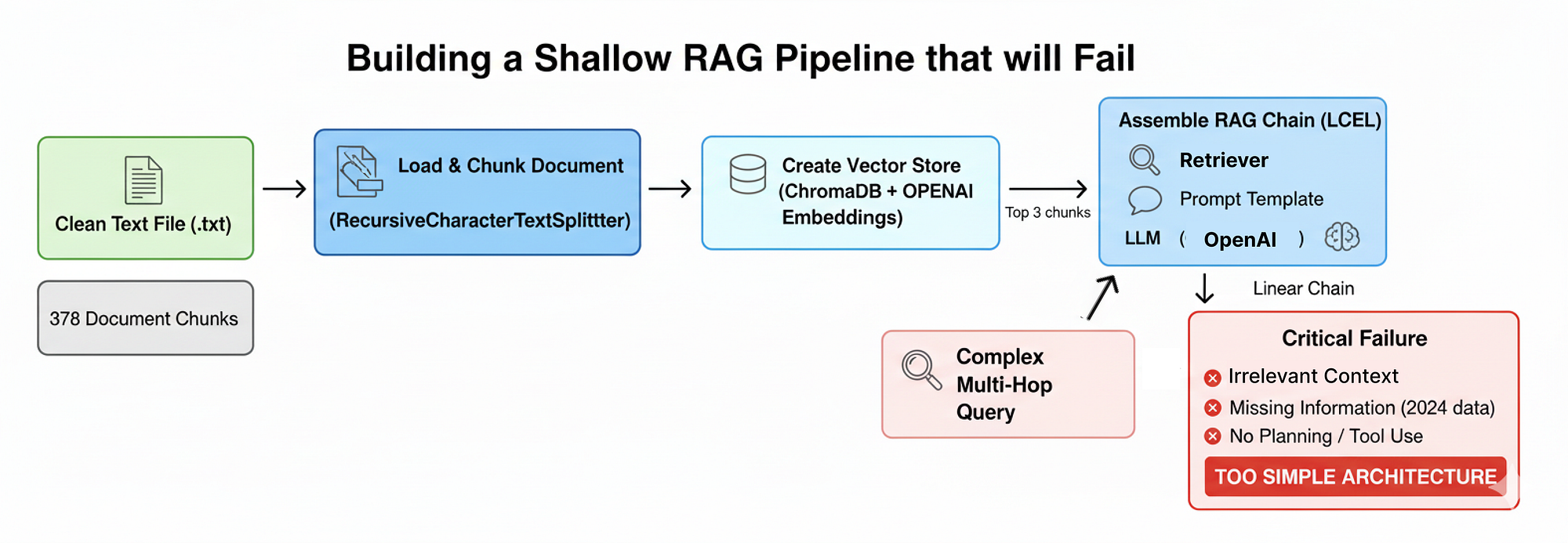
浅层 RAG 管道
- 加载和分块文档: 我们将摄取清理过的 10-K 文件,并将其分割成小的、固定大小的块——一种常见但语义上天真的方法。
- 创建向量存储: 然后我们将这些块嵌入并将其索引到 ChromaDB 向量存储中,以实现基本的语义搜索。
- 组装 RAG 链: 我们将使用 LangChain 表达式语言 (LCEL),它将我们的检索器、提示模板和 LLM 连接成一个线性管道。
- 演示关键故障: 我们将对这个简单系统执行多跳、多源查询,并分析其不充分的响应。
首先,我们需要加载我们的清理文档并将其分割。我们将使用 RecursiveCharacterTextSplitter,这是 LangChain 生态系统中的一个标准工具。
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
print("Loading and chunking the document...")
loader = TextLoader(doc_path_clean, encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
doc_chunks = text_splitter.split_documents(documents)
print(f"Document loaded and split into {len(doc_chunks)} chunks.")
Loading and chunking the document...
Document loaded and split into 378 chunks.
我们的主文档有 378 个块,下一步是使它们可搜索。为此,我们需要创建向量嵌入并将其存储在数据库中。我们将使用 ChromaDB,一个流行的内存向量存储,以及配置中定义的 OpenAI text-embedding-3-small 模型。
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
print("Creating baseline vector store...")
embedding_function = OpenAIEmbeddings(model=config['embedding_model'])
baseline_vector_store = Chroma.from_documents(
documents=doc_chunks,
embedding=embedding_function
)
baseline_retriever = baseline_vector_store.as_retriever(search_kwargs={"k": 3})
print(f"Vector store created with {baseline_vector_store._collection.count()} embeddings.")
Creating baseline vector store...
Vector store created with 378 embeddings.
Chroma.from_documents 组织此过程并将所有向量存储在一个可搜索的索引中。最后一步是使用 LangChain 表达式语言 (LCEL) 将它们组装成一个单一的、可运行的 RAG 链。
这个链将定义数据的线性流:从用户的提问到检索器,然后到提示,最后到 LLM。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
template = """You are an AI financial analyst. Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(model=config["fast_llm"], temperature=0)
def format_docs(docs):
return "\n\n---\n\n".join(doc.page_content for doc in docs)
baseline_rag_chain = (
{"context": baseline_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
您知道我们首先定义了一个字典。它的 context 键由一个子链填充,输入问题进入 baseline_retriever,其输出(Document 对象列表)由 format_docs 格式化为单个字符串。question 键通过使用 RunnablePassthrough 简单地传递原始输入来填充。
让我们运行这个简单的管道,了解它在哪里失败。
from rich.console import Console
from rich.markdown import Markdown
console = Console()
complex_query_adv = "Based on NVIDIA's 2023 10-K filing, identify their key risks related to competition. Then, find recent news (post-filing, from 2024) about AMD's AI chip strategy and explain how this new strategy directly addresses or exacerbates one of NVIDIA's stated risks."
print("Executing complex query on the baseline RAG chain...")
baseline_result = baseline_rag_chain.invoke(complex_query_adv)
console.print("\n--- BASELINE RAG FAILED OUTPUT ---")
console.print(Markdown(baseline_result))
当您运行上面的代码时,我们得到以下输出。
Executing complex query on the baseline RAG chain...
--- BASELINE RAG FAILED OUTPUT ---
Based on the provided context, NVIDIA operates in an intensely competitive semiconductor
industry and faces competition from companies like AMD. The context mentions
that the industry is characterized by rapid technological change. However, the provided documents do not contain any specific information about AMD's recent AI chip strategy from 2024 or how it might impact NVIDIA's stated risks.
在这个失败的 RAG 管道及其输出中,您可能已经注意到三件事。
- 不相关上下文: 检索器抓取了关于 “NVIDIA”、“竞争” 和 “AMD” 的通用块,但遗漏了 2024 年 AMD 战略的具体细节。
- 信息缺失: 关键的失败是 2023 年的数据无法涵盖 2024 年的事件。系统没有意识到它缺少关键信息。
- 没有规划或工具使用: 将复杂查询视为简单查询。无法将其分解为步骤或使用网络搜索等工具来填补空白。
系统失败不是因为 LLM 笨,而是因为架构过于简单。它是一个线性、一次性的过程,试图解决一个循环、多步骤的问题。
现在我们已经了解了基本 RAG 管道的问题,我们可以开始实施我们的深度思考方法,看看它如何很好地解决我们的复杂查询。
5 为中央agent系统定义 RAG 状态
要构建我们的推理agent,我们首先需要一种方法来管理其状态。在我们的简单 RAG 链中,每个步骤都是无状态的,但是……
一个智能代理需要记忆。它需要记住原始问题、它创建的计划以及它迄今为止收集到的证据。
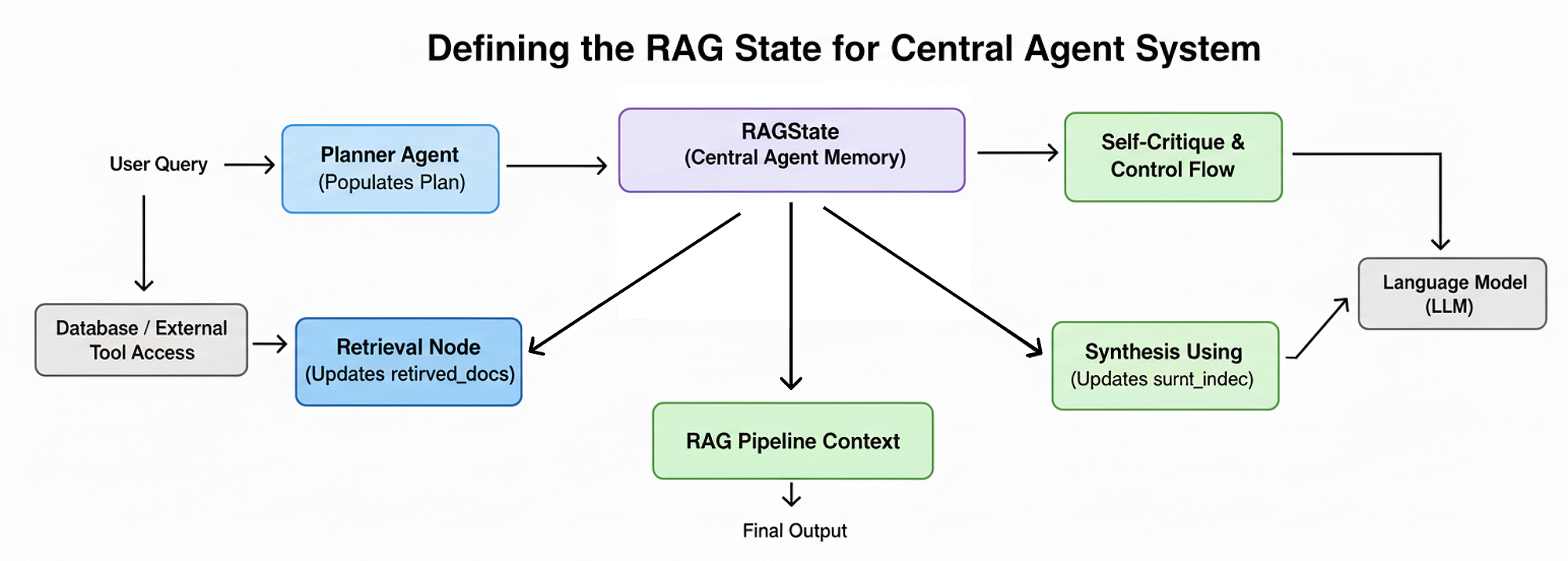
RAG 状态
RAGState 将作为中央内存,在我们的 LangGraph 工作流的每个节点之间传递。为了构建它,我们将定义一系列结构化数据类,从最基本的构建块开始:研究计划中的单个步骤。
我们希望定义代理计划的原子单元。每个 Step 不仅必须包含要回答的问题,还必须包含其背后的推理,以及最重要的,代理应该使用的特定工具。这使得代理的规划过程明确且结构化。
from langchain_core.documents import Document
from langchain_core.pydantic_v1 import BaseModel, Field
class Step(BaseModel):
sub_question: str = Field(description="A specific, answerable question for this step.")
justification: str = Field(description="A brief explanation of why this step is necessary to answer the main query.")
tool: Literal["search_10k", "search_web"] = Field(description="The tool to use for this step.")
keywords: List[str] = Field(description="A list of critical keywords for searching relevant document sections.")
document_section: Optional[str] = Field(description="A likely document section title (e.g., 'Item 1A. Risk Factors') to search within. Only for 'search_10k' tool.")
我们的 Step 类使用 Pydantic BaseModel,作为我们规划代理的严格契约。tool: Literal[...] 字段强制 LLM 在使用我们的内部知识 (search_10k) 或寻求外部信息 (search_web) 之间做出具体决策。
这种结构化输出比尝试解析自然语言计划要可靠得多。
现在我们已经定义了一个 Step,我们需要一个容器来保存整个步骤序列。我们将创建一个 Plan 类,它只是一个 Step 对象的列表。这代表了代理完整、端到端的研究策略。
class Plan(BaseModel):
steps: List[Step] = Field(description="A detailed, multi-step plan to answer the user's query.")
我们编写了一个 Plan 类,它将为整个研究过程提供结构。当我们调用我们的规划代理时,我们将要求它返回一个符合此模式的 JSON 对象。这确保了代理策略在采取任何检索行动之前是清晰、顺序和机器可读的。
接下来,当我们的代理执行其计划时,它需要一种方式来记住它所学到的东西。我们将定义一个 PastStep 字典来存储每个完成步骤的结果。这将形成代理的研究历史或实验记录。
class PastStep(TypedDict):
step_index: int
sub_question: str
retrieved_docs: List[Document]
summary: str
这个 PastStep 结构对于代理的自我批判循环至关重要。在每个步骤之后,我们将填充其中一个字典并将其添加到我们的状态中。然后,代理将能够审查这个不断增长的摘要列表,以了解它知道什么,并决定它是否有足够的信息来完成任务。
最后,我们将所有这些部分组合到主 RAGState 字典中。这是将流经我们整个图的中心对象,它包含原始查询、完整计划、过去步骤的历史以及正在执行的_当前_步骤的所有中间数据。
class RAGState(TypedDict):
original_question: str
plan: Plan
past_steps: List[PastStep]
current_step_index: int
retrieved_docs: List[Document]
reranked_docs: List[Document]
synthesized_context: str
final_answer: str
这个 RAGState TypedDict 是我们代理的完整思维。我们图中的每个节点都将接收此字典作为输入,并返回其更新版本作为输出。
例如,plan_node 将填充 plan 字段,retrieval_node 将填充 retrieved_docs 字段,依此类推。这种共享的、持久的状态使得我们简单 RAG 链所缺乏的复杂、迭代推理成为可能。
现在我们已经定义了代理内存的蓝图,我们准备构建我们系统的第一个认知组件:将填充此状态的规划代理。
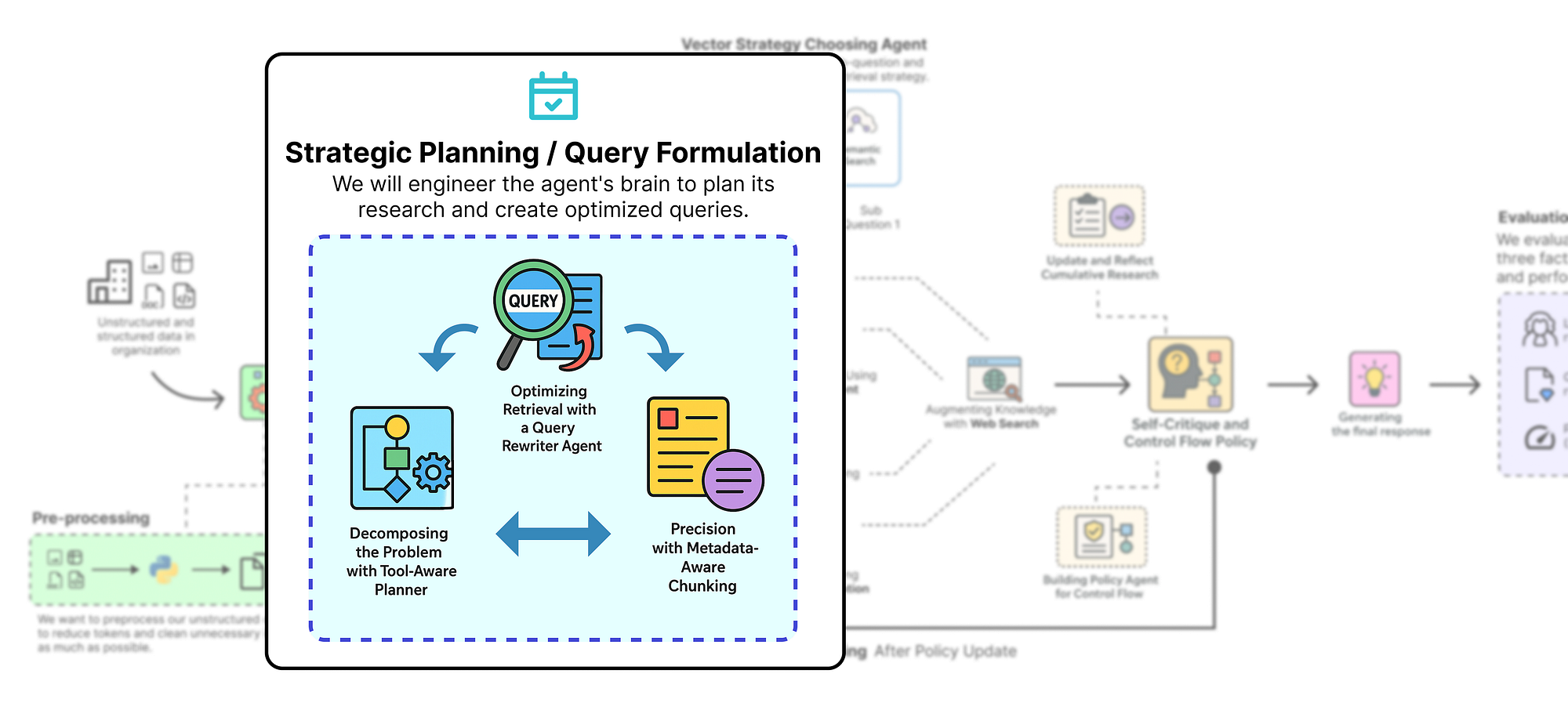
6 战略规划和查询制定
有了我们定义的 RAGState,我们现在可以构建代理的第一个也是可以说最重要的认知组件:它的规划能力。这就是我们的系统从一个简单的数据获取器跃升为一个真正的推理引擎的地方。我们的代理不会天真地将用户的复杂查询视为一次搜索,而是会首先暂停、思考并构建一个详细的、分步的研究策略。
战略规划
本节分为三个关键工程步骤:
- 工具感知规划器: 我们将构建一个由 LLM 驱动的代理,其唯一任务是将用户查询分解为结构化的
Plan对象,并决定每个步骤使用哪种工具。 - 查询重写器: 我们将创建一个专门的代理,将规划器的简单子问题转换为高效、优化的搜索查询。
- 元数据感知分块: 我们将重新处理源文档以添加节级元数据,这是实现高精度、过滤检索的关键步骤。
6.1 使用工具感知规划器分解问题
所以,基本上我们想构建我们操作的大脑。这个大脑在收到一个复杂问题时需要做的第一件事就是制定一个游戏计划。
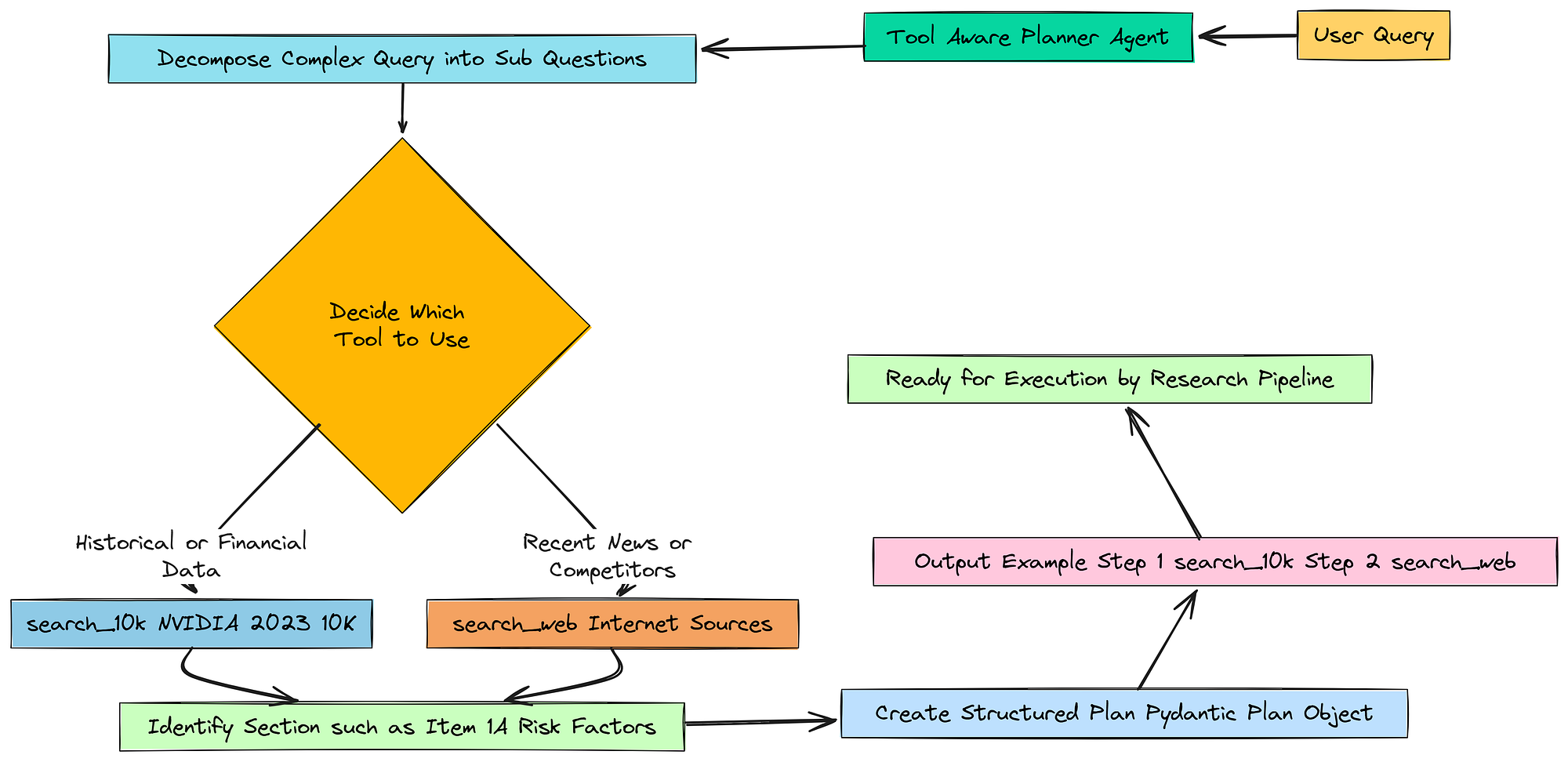
分解步骤
我们不能只是把整个问题抛给我们的数据库,然后寄希望于最好的结果。我们需要教代理如何将问题分解成更小、更易于管理的部分。
为此,我们将创建一个专门的规划代理。我们需要给它一套非常明确的指令或提示,告诉它它的确切职责。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from rich.pretty import pprint as rprint
planner_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert research planner. Your task is to create a clear, multi-step plan to answer a complex user query by retrieving information from multiple sources.
You have two tools available:
1. `search_10k`: Use this to search for information within NVIDIA's 2023 10-K financial filing. This is best for historical facts, financial data, and stated company policies or risks from that specific time period.
2. `search_web`: Use this to search the public internet for recent news, competitor information, or any topic that is not specific to NVIDIA's 2023 10-K.
Decompose the user's query into a series of simple, sequential sub-questions. For each step, decide which tool is more appropriate.
For `search_10k` steps, also identify the most likely section of the 10-K (e.g., 'Item 1A. Risk Factors', 'Item 7. Management's Discussion and Analysis...').
It is critical to use the exact section titles found in a 10-K filing where possible."""),
("human", "User Query: {question}")
])
我们基本上是给 LLM 一个新角色:一个专家研究规划师。我们明确告诉它它拥有的两个工具(search_10k 和 search_web),并指导它何时使用每个工具。这就是“工具感知”部分。
我们不仅仅是要求它提供一个计划,而是要求它创建一个直接映射到我们已构建功能的计划。
现在我们可以初始化推理模型并将其与我们的提示链接起来。这里非常重要的一步是告诉 LLM 它的最终输出必须是我们的 Pydantic Plan 类的格式。这使得输出结构化且可预测。
reasoning_llm = ChatOpenAI(model=config["reasoning_llm"], temperature=0)
planner_agent = planner_prompt | reasoning_llm.with_structured_output(Plan)
print("Tool-Aware Planner Agent created successfully.")
print("\n--- Testing Planner Agent ---")
test_plan = planner_agent.invoke({"question": complex_query_adv})
rprint(test_plan)
我们获取 planner_prompt,将其传递给强大的 reasoning_llm,然后使用 .with_structured_output(Plan) 方法。这告诉 LangChain 使用模型函数调用能力将其响应格式化为与我们的 Plan Pydantic 模式完美匹配的 JSON 对象。这比尝试解析纯文本响应要可靠得多。
让我们看看当我们用我们的挑战查询测试它时的输出。
Tool-Aware Planner Agent created successfully.
--- Testing Planner Agent ---
Plan(
│ steps=[
│ │ Step(
│ │ │ sub_question="What are the key risks related to competition as stated in NVIDIA's 2023 10-K filing?",
│ │ │ justification="This step is necessary to extract the foundational information about competitive risks directly from the source document as requested by the user.",
│ │ │ tool='search_10k',
│ │ │ keywords=['competition', 'risk factors', 'semiconductor industry', 'competitors'],
│ │ │ document_section='Item 1A. Risk Factors'
│ │ ),
│ │ Step(
│ │ │ sub_question="What are the recent news and developments in AMD's AI chip strategy in 2024?",
│ │ │ justification="This step requires finding up-to-date, external information that is not available in the 2023 10-K filing. A web search is necessary to get the latest details on AMD's strategy.",
│ │ │ tool='search_web',
│ │ │ keywords=['AMD', 'AI chip strategy', '2024', 'MI300X', 'Instinct accelerator'],
│ │ │ document_section=None
│ │ )
│ ]
)
如果我们查看输出,您可以看到代理不仅仅给了我们一个模糊的计划,它生成了一个结构化的 Plan 对象。它正确地识别了查询有两个部分。
- 对于第一部分,它知道答案在 10-K 中,并选择了
search_10k工具,甚至正确猜测了正确的文档部分。 - 对于第二部分,它知道“2024 年新闻”不可能在 2023 年的文档中,并正确选择了
search_web工具。这是我们的管道至少在思考过程中会给出有希望结果的第一个迹象。
6.2 使用查询重写代理优化检索
所以,基本上我们有一个包含良好子问题的计划。
但是像“风险是什么?”这样的问题并不是一个好的搜索查询。它太通用了。搜索引擎,无论是向量数据库还是网络搜索,都最适合使用具体的、关键词丰富的查询。
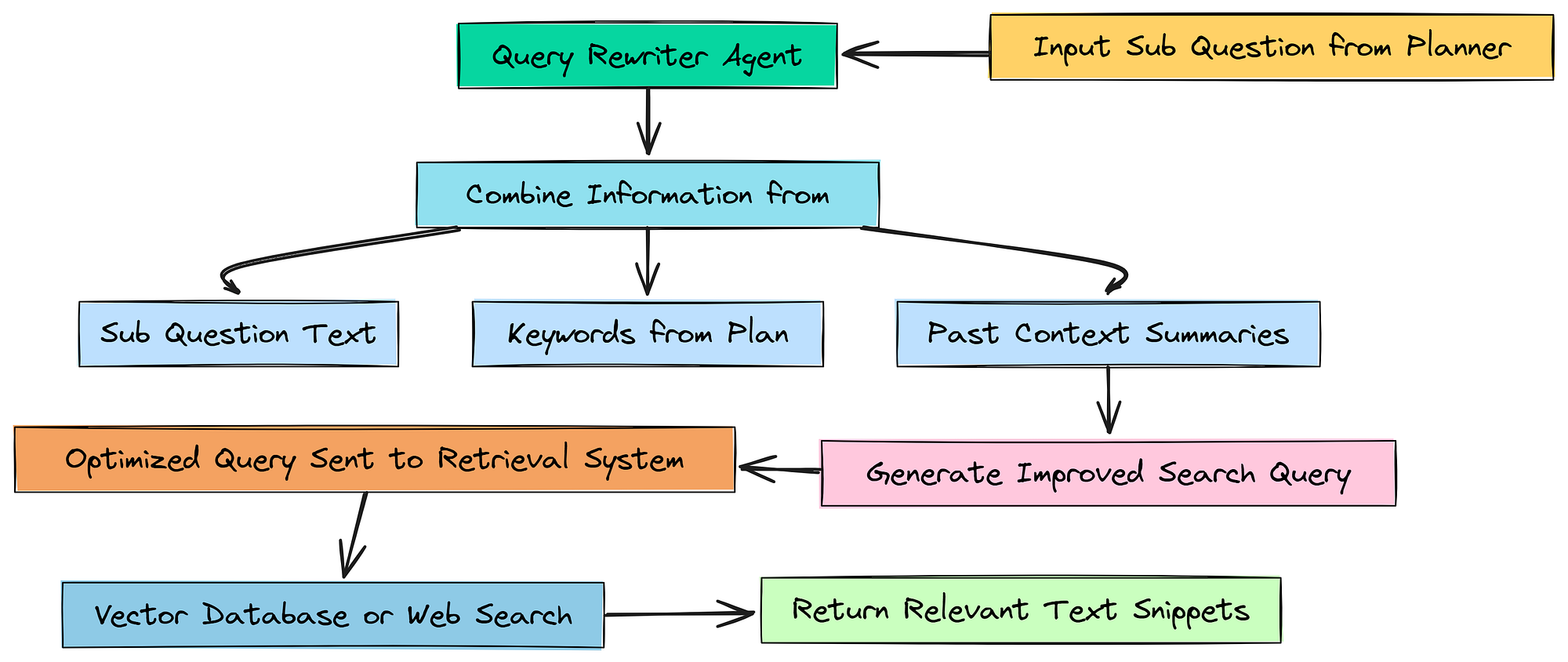
查询重写代理
为了解决这个问题,我们将构建另一个小型、专门的代理:查询重写器。它的唯一任务是获取当前步骤的子问题,并通过添加相关关键词和从我们已学到的上下文中获取的信息来使其更适合搜索。
首先,让我们为这个新代理设计提示。
from langchain_core.output_parsers import StrOutputParser
query_rewriter_prompt = ChatPromptTemplate.from_messages([
("system", """You are a search query optimization expert. Your task is to rewrite a given sub-question into a highly effective search query for a vector database or web search engine, using keywords and context from the research plan.
The rewritten query should be specific, use terminology likely to be found in the target source (a financial 10-K or news articles), and be structured to retrieve the most relevant text snippets."""),
("human", "Current sub-question: {sub_question}\n\nRelevant keywords from plan: {keywords}\n\nContext from past steps:\n{past_context}")
])
我们基本上是告诉这个代理充当搜索查询优化专家。我们给它三条信息来处理:简单的 sub_question、我们的规划器已经识别的 keywords,以及来自任何先前研究步骤的 past_context。这为它构建一个更好的查询提供了所有原始材料。
现在我们可以初始化这个代理。这是一个简单的链,因为我们只需要一个字符串作为输出。
query_rewriter_agent = query_rewriter_prompt | reasoning_llm | StrOutputParser()
print("Query Rewriter Agent created successfully.")
print("\n--- Testing Query Rewriter Agent ---")
test_sub_q = "How does AMD's 2024 AI chip strategy potentially exacerbate the competitive risks identified in NVIDIA's 10-K?"
test_keywords = ['impact', 'threaten', 'competitive pressure', 'market share', 'technological change']
test_past_context = "Step 1 Summary: NVIDIA's 10-K lists intense competition and rapid technological change as key risks. Step 2 Summary: AMD launched its MI300X AI accelerator in 2024 to directly compete with NVIDIA's H100."
rewritten_q = query_rewriter_agent.invoke({
"sub_question": test_sub_q,
"keywords": test_keywords,
"past_context": test_past_context
})
print(f"Original sub-question: {test_sub_q}")
print(f"Rewritten Search Query: {rewritten_q}")
为了正确测试这一点,我们必须模拟一个真实的场景。我们创建一个 test_past_context 字符串,它表示代理已经从其计划的前两个步骤生成的摘要。然后我们将此以及下一个子问题提供给我们的 query_rewriter_agent。
让我们看看结果。
Query Rewriter Agent created successfully.
--- Testing Query Rewriter Agent ---
Original sub-question: How does AMD 2024 AI chip strategy potentially exacerbate the competitive risks identified in NVIDIA 10-K?
Rewritten Search Query: analysis of how AMD 2024 AI chip strategy, including products like the MI300X, exacerbates NVIDIA's stated competitive risks such as rapid technological change and market share erosion in the data center and AI semiconductor industry
原始问题是针对分析师的,重写后的查询是针对搜索引擎的。它被分配了诸如 “MI300X”、“市场份额侵蚀” 和 “数据中心” 等特定术语,所有这些都是从关键词和过去上下文中综合而来的。
像这样的查询更有可能检索到完全正确的文档,从而使我们的整个系统更加准确和高效。这个重写步骤将是我们主要代理循环的关键部分。
6.3 带有元数据感知的分块以提高精度
所以,基本上,我们的规划代理给了我们一个很好的机会。它不仅仅是说寻找风险,它还给了我们一个提示:在“项目 1A. 风险因素”部分寻找风险。
但现在,我们的检索器无法使用这个提示。我们的向量存储只是一个由 378 个文本块组成的大而平坦的列表。它不知道“部分”是什么。
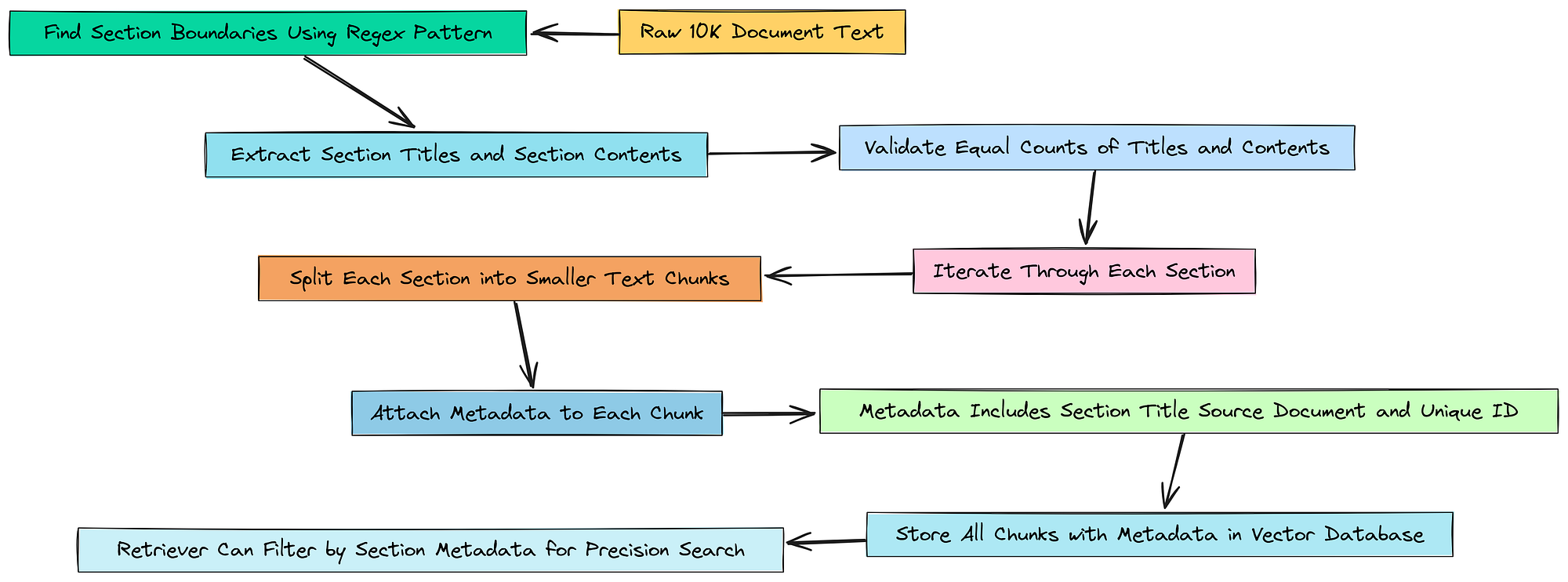
元数据感知分块
我们需要解决这个问题。我们将从头开始重建文档块。这一次,对于我们创建的每个块,我们都将添加一个标签或标记到其元数据中,告诉我们的系统它来自 10-K 的哪个部分。这将允许我们的代理稍后执行高精度、过滤的搜索。
首先,我们需要一种以编程方式查找原始文本文件中每个部分开始位置的方法。如果我们查看文档,我们可以看到一个清晰的模式:每个主要部分都以单词 “ITEM” 开头,后跟一个数字,例如 “ITEM 1A” 或 “ITEM 7”。这是正则表达式的完美工作。
section_pattern = r"(ITEM\s+\d[A-Z]?\.\s*.*?)(?=\nITEM\s+\d[A-Z]?\.|$)"
我们基本上是创建了一个将充当我们的部分检测器的模式。它应该足够灵活,能够捕获不同的格式,同时又足够具体,不会抓取错误的文本。
现在我们可以使用这个模式将我们的文档切片成两个单独的列表:一个只包含部分标题,另一个包含每个部分中的内容。
raw_text = documents[0].page_content
section_titles = re.findall(section_pattern, raw_text, re.IGNORECASE | re.DOTALL)
section_titles = [title.strip().replace('\n', ' ') for title in section_titles]
sections_content = re.split(section_pattern, raw_text, flags=re.IGNORECASE | re.DOTALL)
sections_content = [content.strip() for content in sections_content if content.strip() and not content.strip().lower().startswith('item ')]
print(f"Identified {len(section_titles)} document sections.")
assert len(section_titles) == len(sections_content), "Mismatch between titles and content sections"
这是一种非常有效的解析半结构化文档的方法。我们已经两次使用了我们的正则表达式模式:一次是为了获得所有部分标题的干净列表,另一次是为了将主文本分割成内容块列表。assert 语句让我们确信我们的解析逻辑是健全的。
好的,现在我们有了这些部分:一个标题列表和一个相应的内容列表。我们现在可以遍历它们并创建最终的、富含元数据的块。
import uuid
doc_chunks_with_metadata = []
for i, content in enumerate(sections_content):
section_title = section_titles[i]
section_chunks = text_splitter.split_text(content)
for chunk in section_chunks:
chunk_id = str(uuid.uuid4())
doc_chunks_with_metadata.append(
Document(
page_content=chunk,
metadata={
"section": section_title,
"source_doc": doc_path_clean,
"id": chunk_id
}
)
)
print(f"Created {len(doc_chunks_with_metadata)} chunks with section metadata.")
print("\n--- Sample Chunk with Metadata ---")
sample_chunk = next(c for c in doc_chunks_with_metadata if "Risk Factors" in c.metadata.get("section", ""))
print(sample_chunk)
这是我们升级的核心。我们逐一遍历每个部分。对于每个部分,我们创建文本块。但在将它们添加到最终列表之前,我们创建一个 metadata 字典并附加 section_title。这有效地为每个块标记了其来源。
让我们看看输出并查看差异。
Processing document and adding metadata...
Identified 22 document sections.
Created 381 chunks with section metadata.
--- Sample Chunk with Metadata ---
Document(
│ page_content='Our industry is intensely competitive. We operate in the semiconductor\nindustry, which is intensely competitive and characterized by rapid\ntechnological change and evolving industry standards. We compete with a number of\ncompanies that have different business models and different combinations of\nhardware, software, and systems expertise, many of which have substantially\ngreater resources than we have. We expect competition to increase from existing\ncompetitors, as well as new and emerging companies. Our competitors include\nIntel, AMD, and Qualcomm; cloud service providers, or CSPs, such as Amazon Web\nServices, or AWS, Google Cloud, and Microsoft Azure; and various companies\ndeveloping or that may develop processors or systems for the AI, HPC, data\ncenter, gaming, professional visualization, and automotive markets. Some of our\ncustomers are also our competitors. Our business could be materially and\nadversely affected if our competitors announce or introduce new products, services,\nor technologies that have better performance or features, are less expensive, or\nthat gain market acceptance.',
│ metadata={
│ │ 'section': 'Item 1A. Risk Factors.',
│ │ 'source_doc': './data/nvda_10k_2023_clean.txt',
│ │ 'id': '...'
│ }
)
看看那个 metadata 块。我们之前拥有的相同文本块现在附加了一个上下文片段:'section': 'Item 1A. Risk Factors.'。
现在,当我们的代理需要查找风险时,它可以告诉检索器:“嘿,不要搜索所有 381 个块。只搜索元数据为‘Item 1A. Risk Factors’的那些。”
这个简单的改变将我们的检索器从一个笨拙的工具变成了一个外科手术工具,它是构建真正生产级 RAG 系统的关键原则。
7 创建多阶段检索漏斗
到目前为止,我们已经设计了一个智能规划器并用元数据丰富了我们的文档。我们现在准备构建我们系统的核心:一个复杂的检索管道。
简单的、一次性的语义搜索已不再足够。对于生产级代理,我们需要一个既自适应又多阶段的检索过程。
我们将把我们的检索过程设计成一个漏斗,其中每个阶段都细化前一个阶段的结果:
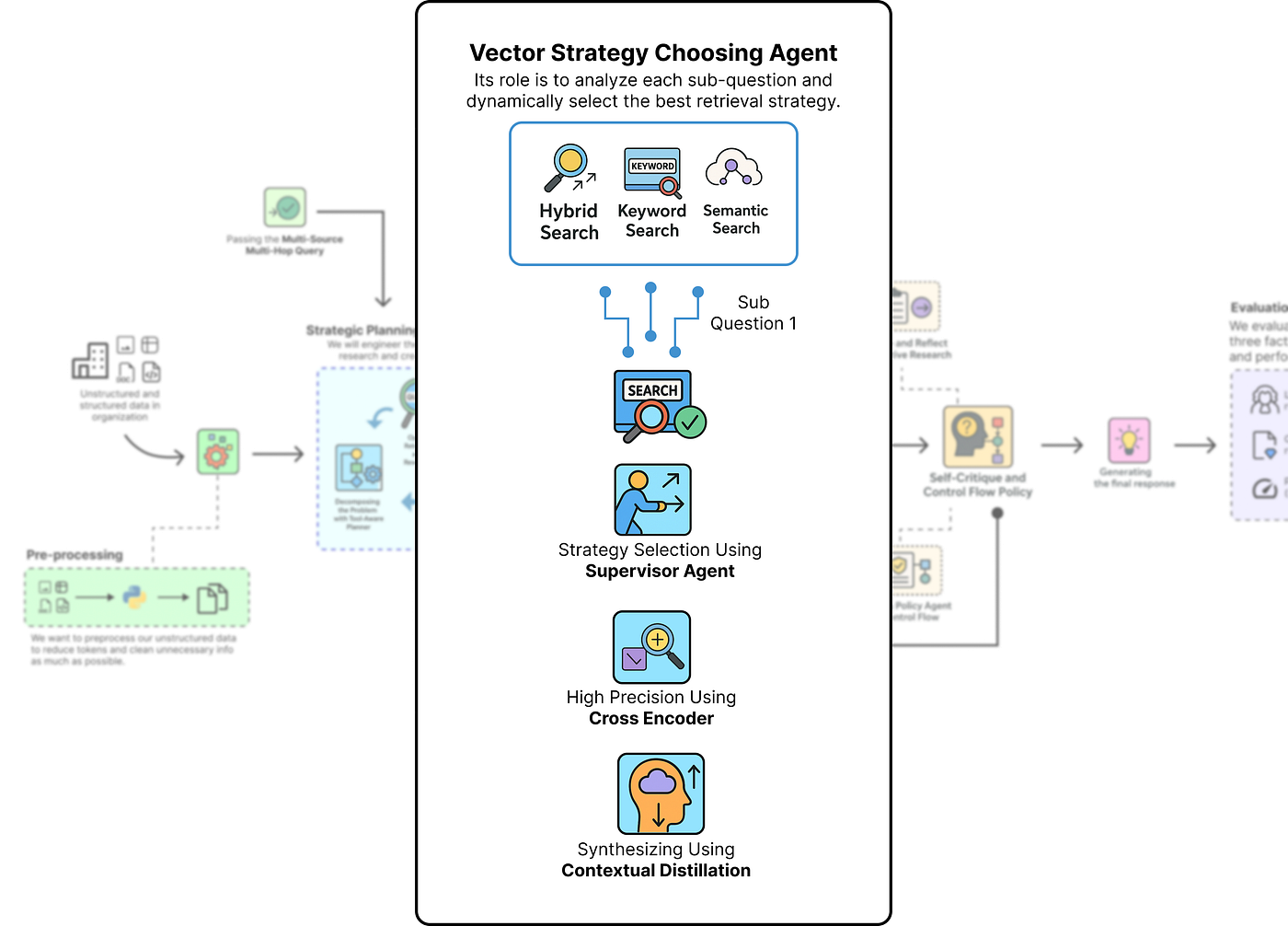
多阶段漏斗
- 检索监督器: 我们将构建一个新的监督代理,它充当动态路由器,分析每个子问题并选择最佳搜索策略(向量、关键词或混合)。
- 第一阶段(广泛召回): 我们将实现我们的监督器可以选择的不同检索策略,重点是撒大网以捕获所有可能相关的文档。
- 第二阶段(高精度): 我们将使用交叉编码器模型对初始结果进行重新排序,丢弃噪声并将最相关的文档提升到顶部。
- 第三阶段(综合): 最后,我们将创建一个蒸馏代理,将排名靠前的证据压缩成一个简洁的上下文段落,供我们的下游代理使用。
7.1 使用监督器动态选择策略
所以,基本上,并非所有搜索查询都相同。像“‘计算与网络’部门的收入增长是多少?”这样的问题包含具体的、精确的术语。基于关键词的搜索将非常适合。
但是像……这样的问题
公司对市场竞争的情绪如何?是概念性的。语义的、基于向量的搜索会好得多。
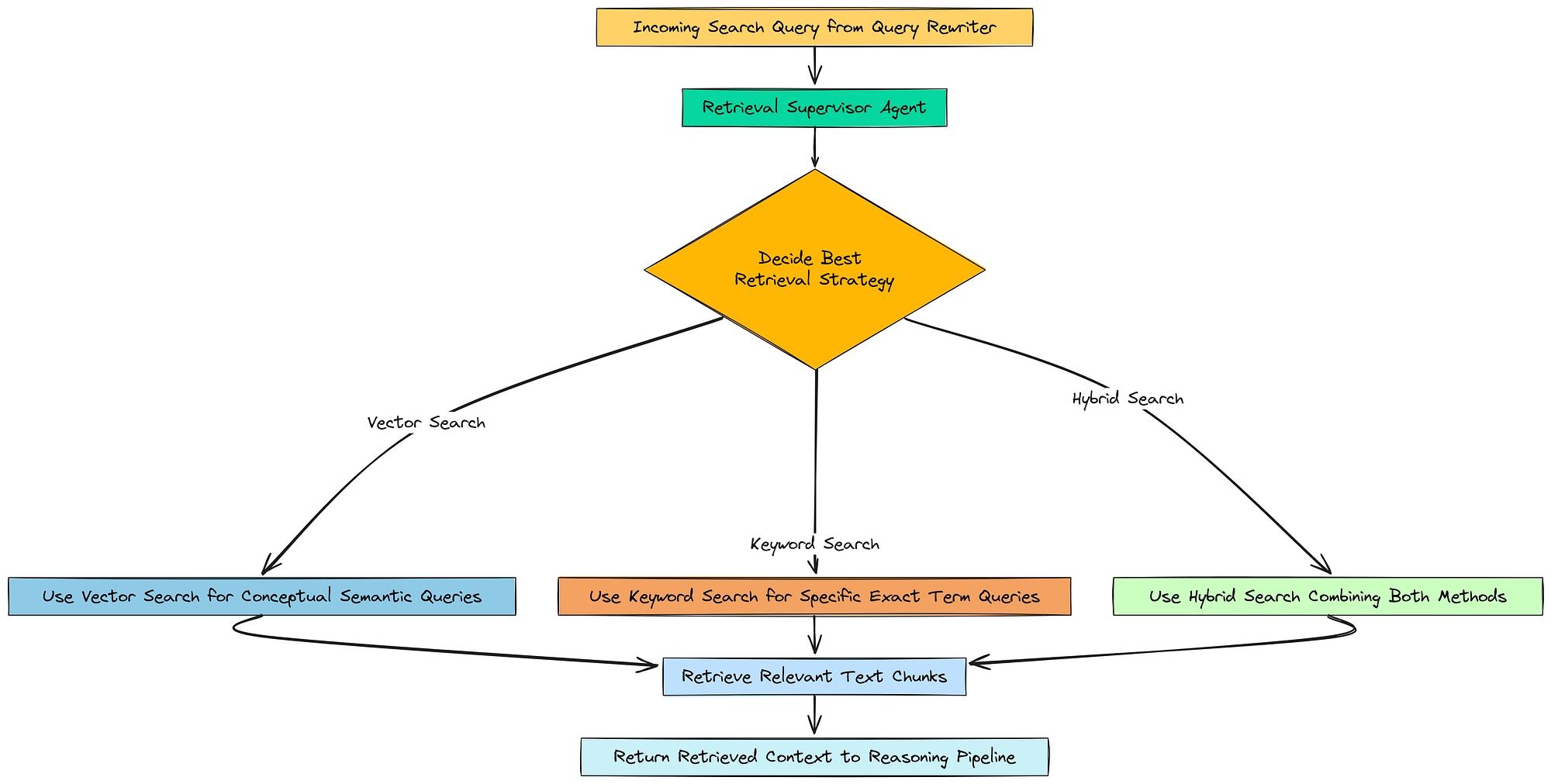
监督代理
我们不硬编码一种策略,而是要构建一个小型智能代理,检索监督器,来为我们做出这个决定。它的唯一任务是查看搜索查询并决定哪种检索方法最合适。
首先,我们需要定义我们的监督器可能做出的决策。我们将使用 Pydantic BaseModel 来结构化其输出。
class RetrievalDecision(BaseModel):
strategy: Literal["vector_search", "keyword_search", "hybrid_search"]
justification: str
监督器必须选择这三种策略之一并解释其推理。这使得其决策过程透明且可靠。
现在,让我们创建将指导此代理行为的提示。
retrieval_supervisor_prompt = ChatPromptTemplate.from_messages([
("system", """You are a retrieval strategy expert. Based on the user's query, you must decide the best retrieval strategy.
You have three options:
1. `vector_search`: Best for conceptual, semantic, or similarity-based queries.
2. `keyword_search`: Best for queries with specific, exact terms, names, or codes (e.g., 'Item 1A', 'Hopper architecture').
3. `hybrid_search`: A good default that combines both, but may be less precise than a targeted strategy."""),
("human", "User Query: {sub_question}")
])
我们在这里创建了一个非常直接的提示,它告诉 LLM 它的角色是检索策略专家,并清楚地解释了何时使用其每种可用策略最有效。
最后,我们可以组装我们的监督代理。
retrieval_supervisor_agent = retrieval_supervisor_prompt | reasoning_llm.with_structured_output(RetrievalDecision)
print("Retrieval Supervisor Agent created.")
print("\n--- Testing Retrieval Supervisor Agent ---")
query1 = "revenue growth for the Compute & Networking segment in fiscal year 2023"
decision1 = retrieval_supervisor_agent.invoke({"sub_question": query1})
print(f"Query: '{query1}'")
print(f"Decision: {decision1.strategy}, Justification: {decision1.justification}")
query2 = "general sentiment about market competition and technological innovation"
decision2 = retrieval_supervisor_agent.invoke({"sub_question": query2})
print(f"\nQuery: '{query2}'")
print(f"Decision: {decision2.strategy}, Justification: {decision2.justification}")
我们在这里将它们全部连接起来。
我们的 .with_structured_output(RetrievalDecision) 再次承担了繁重的工作,确保我们从 LLM 获得一个干净、可预测的 RetrievalDecision 对象。让我们看看测试结果。
Retrieval Supervisor Agent created.
Query: 'revenue growth for the Compute & Networking segment in fiscal year 2023'
Decision: keyword_search, Justification: The query contains specific keywords like 'revenue growth', 'Compute & Networking', and 'fiscal year 2023' which are ideal for a keyword-based search to find exact financial figures.
Query: 'general sentiment about market competition and technological innovation'
Decision: vector_search, Justification: This query is conceptual and seeks to understand sentiment and broader themes. Vector search is better suited to capture the semantic meaning of 'market competition' and 'technological innovation' rather than relying on exact keywords.
我们可以看到它正确地识别出第一个查询充满了特定术语,并选择了 keyword_search。
对于第二个概念性和抽象的查询,它正确地选择了 vector_search。这种在我们检索漏斗开始时的动态决策比一刀切的方法有了很好的改进。
7.2 混合、关键词和语义搜索的广泛召回
现在我们有了一个监督器来选择我们的策略,我们需要构建检索策略本身。我们漏斗的这个第一阶段都是关于召回的——我们的目标是撒大网,捕获所有可能相关的文档,即使我们在此过程中会拾取一些噪声。
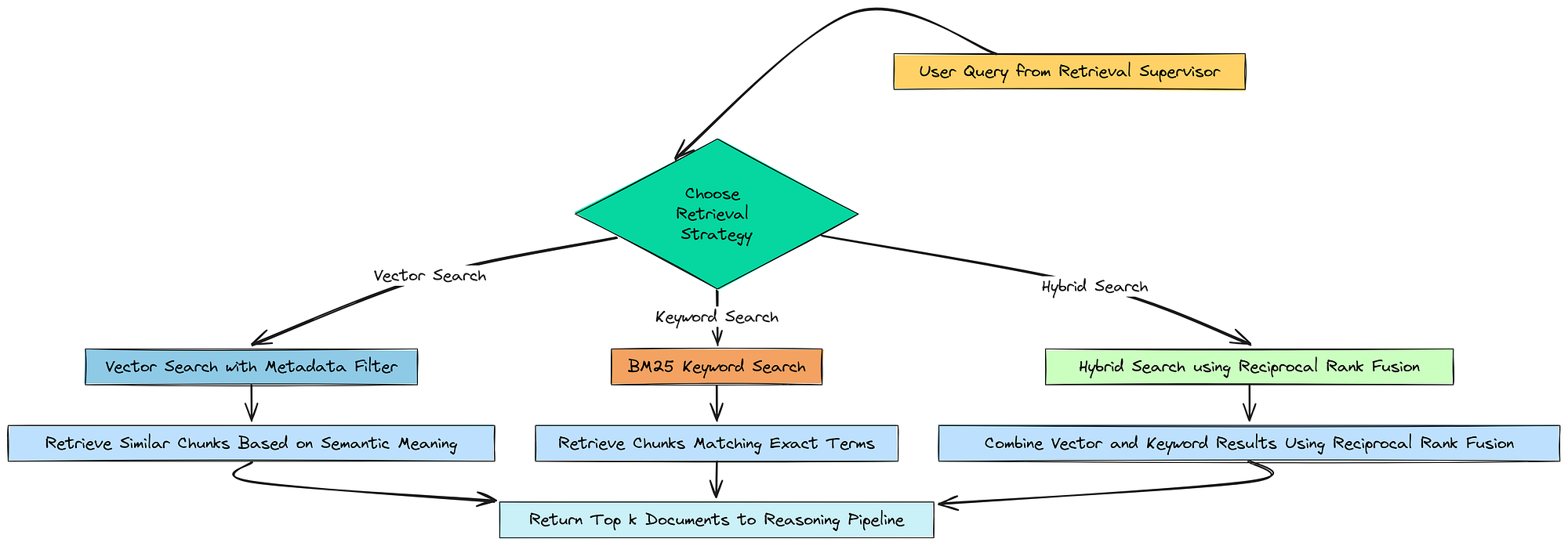
广泛召回
为此,我们将实现我们的监督器可以调用的三个不同的搜索功能:
- 向量搜索: 我们的标准语义搜索,但现在升级为使用元数据过滤器。
- 关键词搜索 (BM25): 一种经典、强大的算法,擅长查找具有特定、精确术语的文档。
- 混合搜索: 一种两全其美的方法,它使用倒数排名融合 (RRF) 技术结合向量和关键词搜索的结果。
首先,我们需要使用我们在上一节中创建的元数据丰富块来创建一个新的高级向量存储。
import numpy as np
from rank_bm25 import BM25Okapi
print("Creating advanced vector store with metadata...")
advanced_vector_store = Chroma.from_documents(
documents=doc_chunks_with_metadata,
embedding=embedding_function
)
print(f"Advanced vector store created with {advanced_vector_store._collection.count()} embeddings.")
这是一个简单但关键的步骤。这个 advanced_vector_store 现在包含与我们基线相同的文本,但每个嵌入的块都用其部分标题标记,从而解锁了我们执行过滤搜索的能力。
接下来,我们需要为我们的关键词搜索做准备。BM25 算法通过分析文档中单词的频率来工作。为了实现这一点,我们需要通过将每个文档的内容分割成一个单词(标记)列表来预处理我们的语料库。
print("\nBuilding BM25 index for keyword search...")
tokenized_corpus = [doc.page_content.split(" ") for doc in doc_chunks_with_metadata]
doc_ids = [doc.metadata["id"] for doc in doc_chunks_with_metadata]
doc_map = {doc.metadata["id"]: doc for doc in doc_chunks_with_metadata}
bm25 = BM25Okapi(tokenized_corpus)
我们基本上是为我们的 BM25 索引创建必要的数据结构。tokenized_corpus 是算法将搜索的内容,doc_map 将允许我们在搜索完成后快速检索完整的 Document 对象。
现在我们可以定义我们的三个检索函数。
def vector_search_only(query: str, section_filter: str = None, k: int = 10):
filter_dict = {"section": section_filter} if section_filter and "Unknown" not in section_filter else None
return advanced_vector_store.similarity_search(query, k=k, filter=filter_dict)
def bm25_search_only(query: str, k: int = 10):
tokenized_query = query.split(" ")
bm25_scores = bm25.get_scores(tokenized_query)
top_k_indices = np.argsort(bm25_scores)[::-1][:k]
return [doc_map[doc_ids[i]] for i in top_k_indices]
def hybrid_search(query: str, section_filter: str = None, k: int = 10):
bm25_docs = bm25_search_only(query, k=k)
semantic_docs = vector_search_only(query, section_filter=section_filter, k=k)
all_docs = {doc.metadata["id"]: doc for doc in bm25_docs + semantic_docs}.values()
ranked_lists = [[doc.metadata["id"] for doc in bm25_docs], [doc.metadata["id"] for doc in semantic_docs]]
rrf_scores = {}
for doc_list in ranked_lists:
for i, doc_id in enumerate(doc_list):
if doc_id not in rrf_scores:
rrf_scores[doc_id] = 0
rrf_scores[doc_id] += 1 / (i + 61)
sorted_doc_ids = sorted(rrf_scores.keys(), key=lambda x: rrf_scores[x], reverse=True)
final_docs = [doc_map[doc_id] for doc_id in sorted_doc_ids[:k]]
return final_docs
print("\nAll retrieval strategy functions ready.")
我们现在已经实现了自适应检索系统的核心。
vector_search_only函数是我们升级后的语义搜索。关键的添加是filter=filter_dict参数,它允许我们从规划器的Step传递document_section,并强制搜索只考虑具有该元数据的块。bm25_search_only函数是我们的纯关键词检索器。它速度极快且对于查找语义搜索可能遗漏的特定术语非常有效。hybrid_search函数并行运行两种搜索,然后使用 RRF 智能地合并结果。RRF 是一种简单但强大的算法,它根据文档在每个列表中的位置对文档进行排名,有效地赋予在_两个_搜索结果中排名靠前的文档更大的权重。
让我们做一个快速测试,看看我们的关键词搜索是如何运作的。我们将搜索我们的规划器识别的精确部分标题。
print("\n--- Testing Keyword Search ---")
test_query = "Item 1A. Risk Factors"
test_results = bm25_search_only(test_query)
print(f"Query: {test_query}")
print(f"Found {len(test_results)} documents. Top result section: {test_results[0].metadata['section']}")
Creating advanced vector store with metadata...
Advanced vector store created with 381 embeddings.
Building BM25 index for keyword search...
All retrieval strategy functions ready.
Query: Item 1A. Risk Factors
Found 10 documents. Top result section: Item 1A. Risk Factors.
输出正是我们想要的。BM25 搜索,作为关键词驱动的搜索,能够完美且即时地从 “Item 1A. Risk Factors” 部分检索文档,仅仅通过搜索标题。
当查询包含特定关键词(如部分标题)时,我们的监督器现在可以选择这个精确的工具。
随着我们广泛召回阶段的构建,我们有了一个强大的机制来查找所有可能相关的文档。然而,这张大网也可能带来不相关的噪声。我们漏斗的下一个阶段将专注于通过高精度进行过滤。
7.3 使用交叉编码器重排序器实现高精度
所以,我们的第一阶段检索在召回方面做得很好。它拉取了 10 个可能与我们的子问题相关的文档。
但问题是它们只是_可能_相关。将所有这 10 个块直接馈送给我们的主推理 LLM 是低效且有风险的。
它增加了令牌成本,更重要的是,它可能会用嘈杂的、半相关的信息混淆模型。
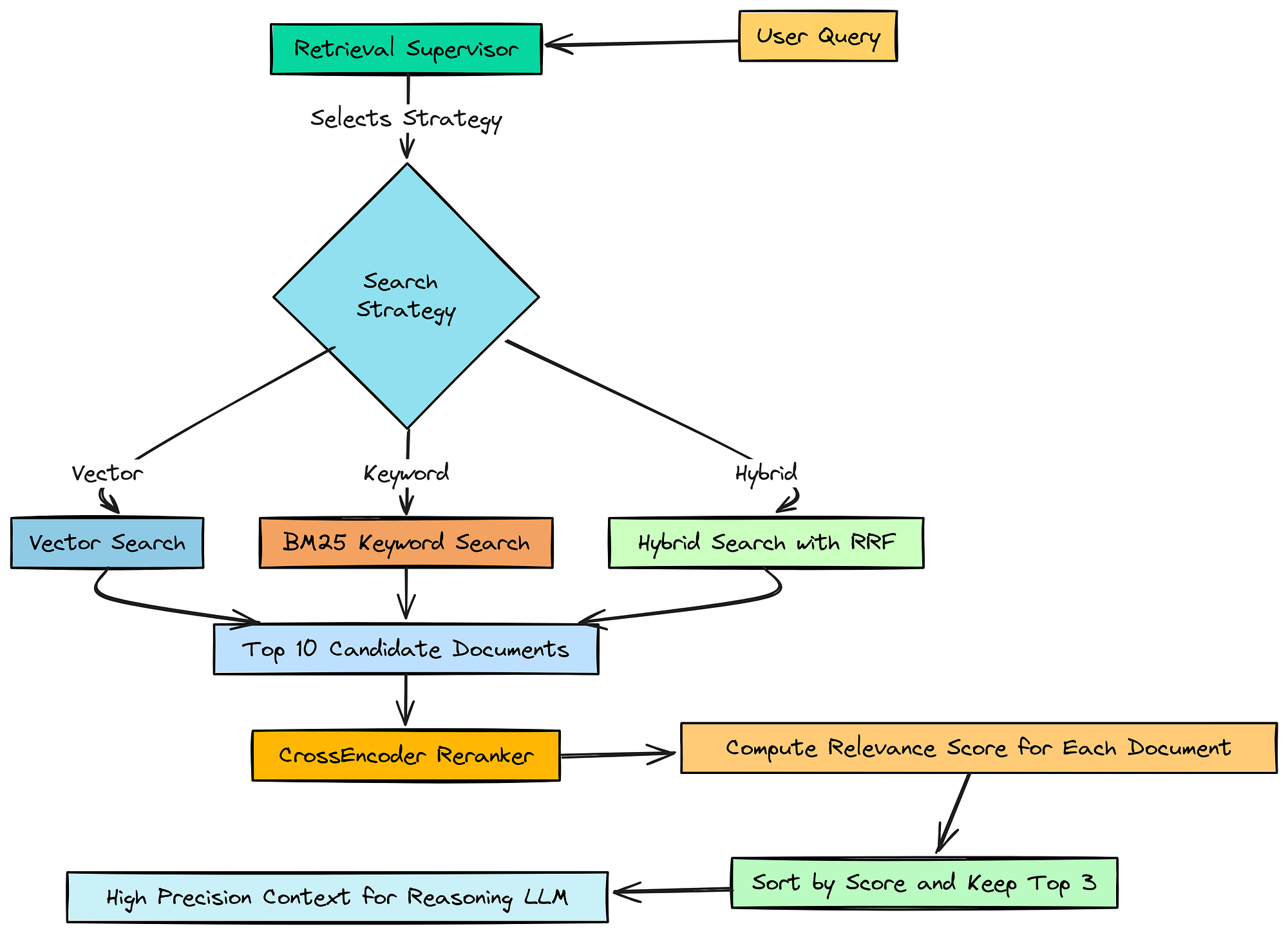
高精度
我们现在需要的是一个精度阶段。我们需要一种方法来检查这 10 个候选文档,并选出绝对最好的。这就是重排序器发挥作用的地方。
关键区别在于这些模型的工作方式。
- 我们的初始检索使用双编码器(嵌入模型),它独立地为查询和文档创建向量。它速度快,非常适合搜索数百万个项目。
- 另一方面,交叉编码器将查询和单个文档作为一个对一起处理,并执行更深层次、更细致的比较。它速度较慢,但准确性更高。
所以,基本上,我们想构建一个函数,它接收我们检索到的 10 个文档,并使用交叉编码器模型为每个文档提供精确的相关性分数。然后,我们将只保留配置中定义的前 3 个。
首先,让我们初始化我们的交叉编码器模型。我们将使用 sentence-transformers 库中一个小型但高效的模型,如我们的配置中指定的那样。
from sentence_transformers import CrossEncoder
print("Initializing CrossEncoder reranker...")
reranker = CrossEncoder(config["reranker_model"])
我们基本上是将预训练的重排序模型加载到内存中。这只需要做一次。我们选择的模型 ms-marco-MiniLM-L-6-v2 在此任务中非常流行,因为它在速度和准确性之间提供了很好的平衡。
现在我们可以创建将执行重排序的函数。
def rerank_documents_function(query: str, documents: List[Document]) -> List[Document]:
if not documents:
return []
pairs = [(query, doc.page_content) for doc in documents]
scores = reranker.predict(pairs)
doc_scores = list(zip(documents, scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
reranked_docs = [doc for doc, score in doc_scores[:config["top_n_rerank"]]]
return reranked_docs
这个函数 rerank_documents_function 是我们精度阶段的主要部分。它接收 query 和来自我们召回阶段的 10 个 documents 列表。最重要的步骤是 reranker.predict(pairs)。
在这里,模型不是创建嵌入,它是在对查询和每个文档内容进行全面比较,为每个文档生成相关性分数。
获得分数后,我们只需对文档进行排序并截取列表以保留前 3 个。此函数的输出将是一个简短、干净且高度相关的文档列表——这是我们下游代理的完美上下文。
这种漏斗方法,从高召回率的第一阶段到高精度率的第二阶段,是生产级 RAG 系统的一个组成部分。它确保我们获得最佳证据,同时最大限度地减少噪声和成本。
7.4 使用上下文蒸馏进行综合
所以,我们的检索漏斗工作得很好。我们从一个广泛的搜索开始,得到了 10 个可能相关的文档。然后,我们高精度的重排序器将其过滤到前 3 个最相关的块。
我们现在处于一个更好的位置,但在将这些信息传递给我们的主要推理代理之前,我们仍然可以进行最后一次改进。目前,我们有三个独立的文本块。
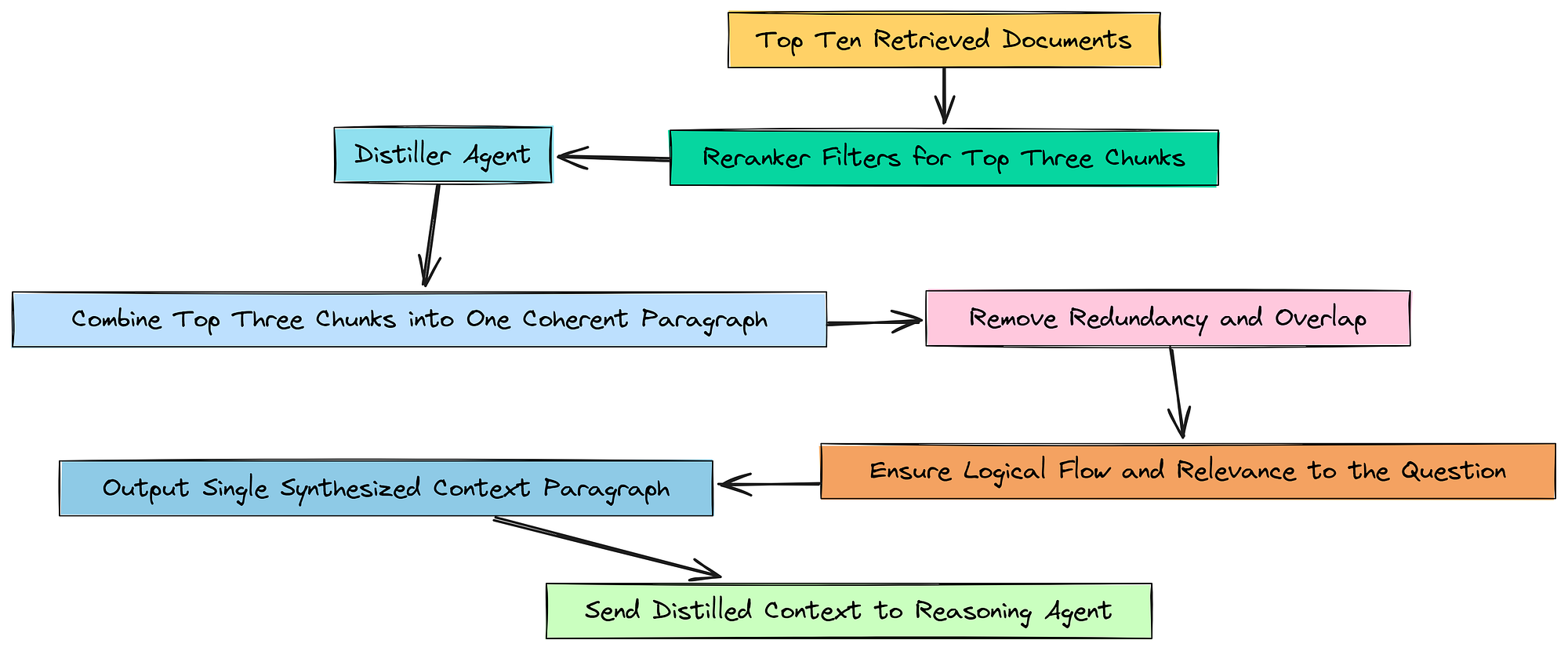
综合
虽然它们都相关,但它们可能包含冗余信息或重叠句子。将它们呈现为三个不同的块对于 LLM 来说仍然有点笨拙。
我们检索漏斗的最后阶段是上下文蒸馏。目标很简单:获取我们排名靠前的 3 个高度相关的文档块,并将它们蒸馏成一个单一、干净、简洁的段落。这消除了任何最终的冗余,并为我们的下游代理提供了完美综合的证据。
这个蒸馏步骤充当最终的压缩层。它确保馈送给我们更昂贵的推理代理的上下文尽可能密集和信息丰富,从而最大化信号并最小化噪声。
为此,我们将创建另一个小型、专门的代理,我们称之为蒸馏代理。
首先,我们需要设计一个提示来指导其行为。
distiller_prompt = ChatPromptTemplate.from_messages([
("system", """You are a helpful assistant. Your task is to synthesize the following retrieved document snippets into a single, concise paragraph.
The goal is to provide a clear and coherent context that directly answers the question: '{question}'.
Focus on removing redundant information and organizing the content logically. Answer only with the synthesized context."""),
("human", "Retrieved Documents:\n{context}")
我们基本上是给这个代理一个非常集中的任务。我们告诉它:“这里有一些文本片段。你唯一的任务就是将它们合并成一个连贯的段落,以回答这个具体的问题”。“只用合成的上下文回答”这个指令很重要,它能防止代理添加任何闲聊或试图自己回答问题。它纯粹是一个文本处理工具。
现在,我们可以组装我们简单的 distiller_agent。
distiller_agent = distiller_prompt | reasoning_llm | StrOutputParser()
print("Contextual Distiller Agent created.")
这是另一个简单的 LCEL 链。我们获取 distiller_prompt,将其传递给强大的 reasoning_llm 来执行综合,然后使用 StrOutputParser 来获取最终的、干净的文本段落。
随着 distiller_agent 的创建,我们的多阶段检索漏斗现已完成。在我们的主代理循环中,每个研究步骤的流程将是:
- 监督器: 选择一个检索策略(
vector、keyword或hybrid)。 - 召回阶段: 执行所选策略以获取前 10 个文档。
- 精度阶段: 使用
rerank_documents_function获取前 3 个文档。 - 蒸馏阶段: 使用
distiller_agent将前 3 个文档压缩成一个干净的段落。
这种多阶段过程确保了我们的代理所处理的证据具有尽可能高的质量。下一步是让我们的代理能够超越其内部知识并搜索网络。
8 通过网络搜索增强知识
所以,我们的检索漏斗现在非常强大,但它有一个巨大的盲点。
它只能看到我们 2023 年 10-K 文档中的内容。为了解决我们的挑战查询,我们的代理需要查找有关 AMD 2024 年 AI 芯片战略的最新新闻(文件发布后)。这些信息根本不存在于我们的静态知识库中。
要真正构建一个**“深度思考”**代理,它需要能够识别自身知识的局限性,并到其他地方寻找答案。我们需要为它提供一个通向外部世界的窗口。
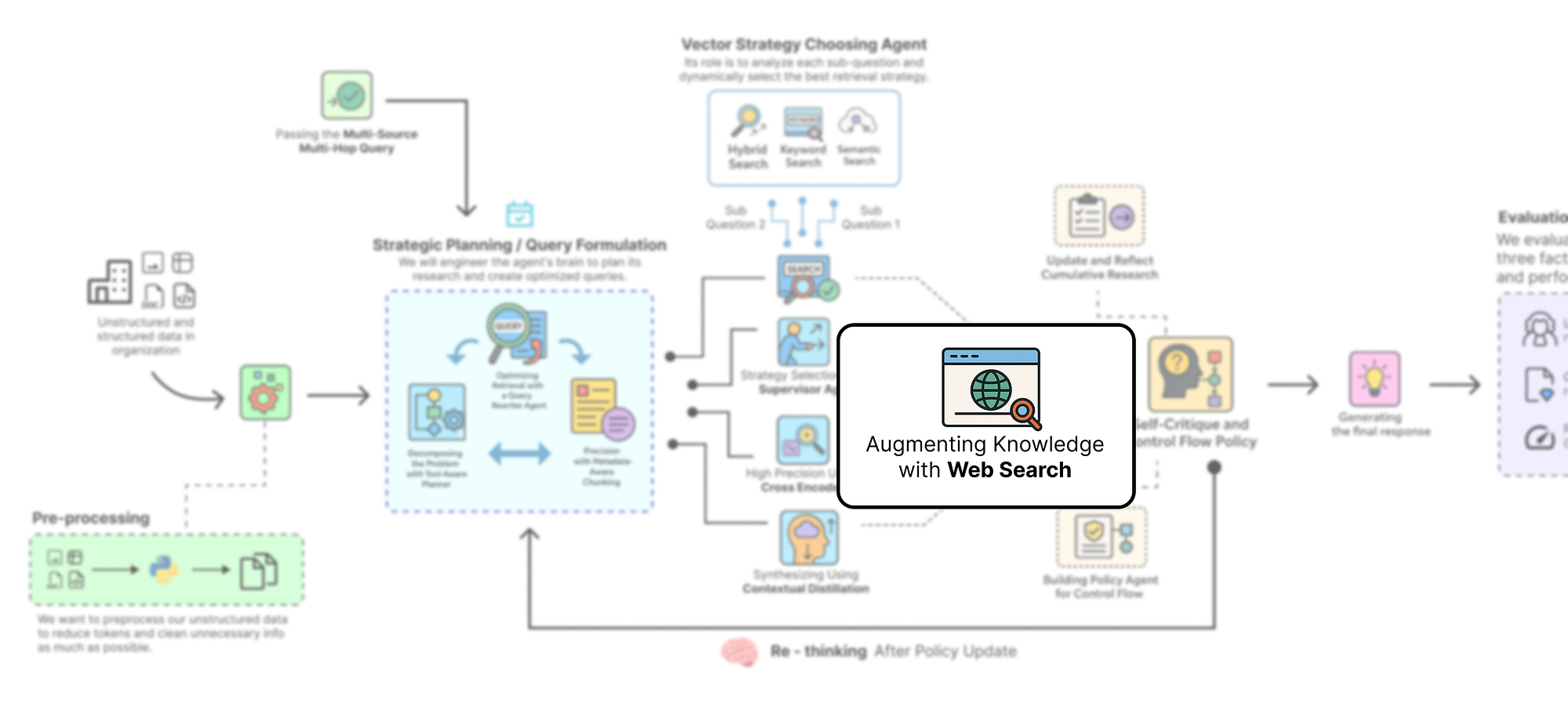
使用网络进行增强
这就是我们通过新工具网络搜索来增强代理能力的地方。这会将我们的系统从一个特定于文档的问答机器人转变为一个真正的多源研究助手。
为此,我们将使用 Tavily Search API。它是一个专门为 LLM 构建的搜索引擎,提供干净、无广告且相关的搜索结果,非常适合 RAG 管道。它还与 LangChain 无缝集成。
所以,基本上,我们需要做的第一件事就是初始化 Tavily 搜索工具本身。
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)
我们基本上是创建了一个 Tavily 搜索工具的实例,我们的代理可以调用它。k=3 参数是一个很好的起点,它提供了几个高质量的来源,而不会用太多信息淹没代理。
现在,原始的 API 响应并不是我们真正需要的。我们的下游组件,即重排序器和蒸馏器,都设计用于特定的数据结构:LangChain Document 对象列表。为了确保无缝集成,我们需要创建一个简单的包装函数。此函数将接收一个查询,调用 Tavily 工具,然后将原始结果格式化为该标准 Document 结构。
def web_search_function(query: str) -> List[Document]:
results = web_search_tool.invoke({"query": query})
return [
Document(
page_content=res["content"],
metadata={"source": res["url"]}
) for res in results
]
这个 web_search_function 充当了一个关键的适配器。它调用 web_search_tool.invoke,后者返回一个字典列表,每个字典包含 \"content\" 和 \"url\" 等键。
- 列表推导式随后遍历这些结果,并将其整齐地重新打包成我们的管道所期望的
Document对象。 page_content获取主要文本,重要的是,我们将url存储在metadata中。- 这确保了当我们的代理生成最终答案时,它可以正确引用其网络来源。
这使得我们的外部知识源看起来和感觉上都与我们的内部知识源完全相同,从而允许我们对两者使用相同的处理管道。
我们的函数准备好后,让我们快速测试一下,以确保它按预期工作。我们将使用与我们主要挑战的第二部分相关的查询。
print("\n--- Testing Web Search Tool ---")
test_query_web = "AMD AI chip strategy 2024"
test_results_web = web_search_function(test_query_web)
print(f"Found {len(test_results_web)} results for query: '{test_query_web}'")
if test_results_web:
print(f"Top result snippet: {test_results_web[0].page_content[:250]}...")
Web search tool (Tavily) initialized.
--- Testing Web Search Tool ---
Found 3 results for query: 'AMD AI chip strategy 2024'
Top result snippet: AMD has intensified its battle with Nvidia in the AI chip market with the release of the Instinct MI300X accelerator, a powerful GPU designed to challenge Nvidia's H100 in training and inference for large language models. Major cloud providers like Microsoft Azure and Oracle Cloud are adopting the MI300X, indicating strong market interest...
输出证实我们的工具工作正常。它为我们的查询找到了 3 个相关的网页。顶部结果的摘要正是我们的代理所缺少的那种最新外部信息。
它提到了 AMD 的“Instinct MI300X”及其与 NVIDIA “H100” 的竞争——这正是解决我们问题后半部分所需的证据。
我们的代理现在有了一个通向外部世界的窗口,它的规划器可以智能地决定何时查看它。谜题的最后一部分是让代理能够反思其发现并决定何时完成研究。
9 自我批判和控制流策略
到目前为止,我们已经构建了一个强大的研究机器。我们的代理可以创建计划、选择正确的工具并执行复杂的检索漏斗。但缺少一个关键部分:思考自身进展的能力。一个盲目地一步步遵循计划的代理并不是真正智能的。它需要一个自我批判的机制。
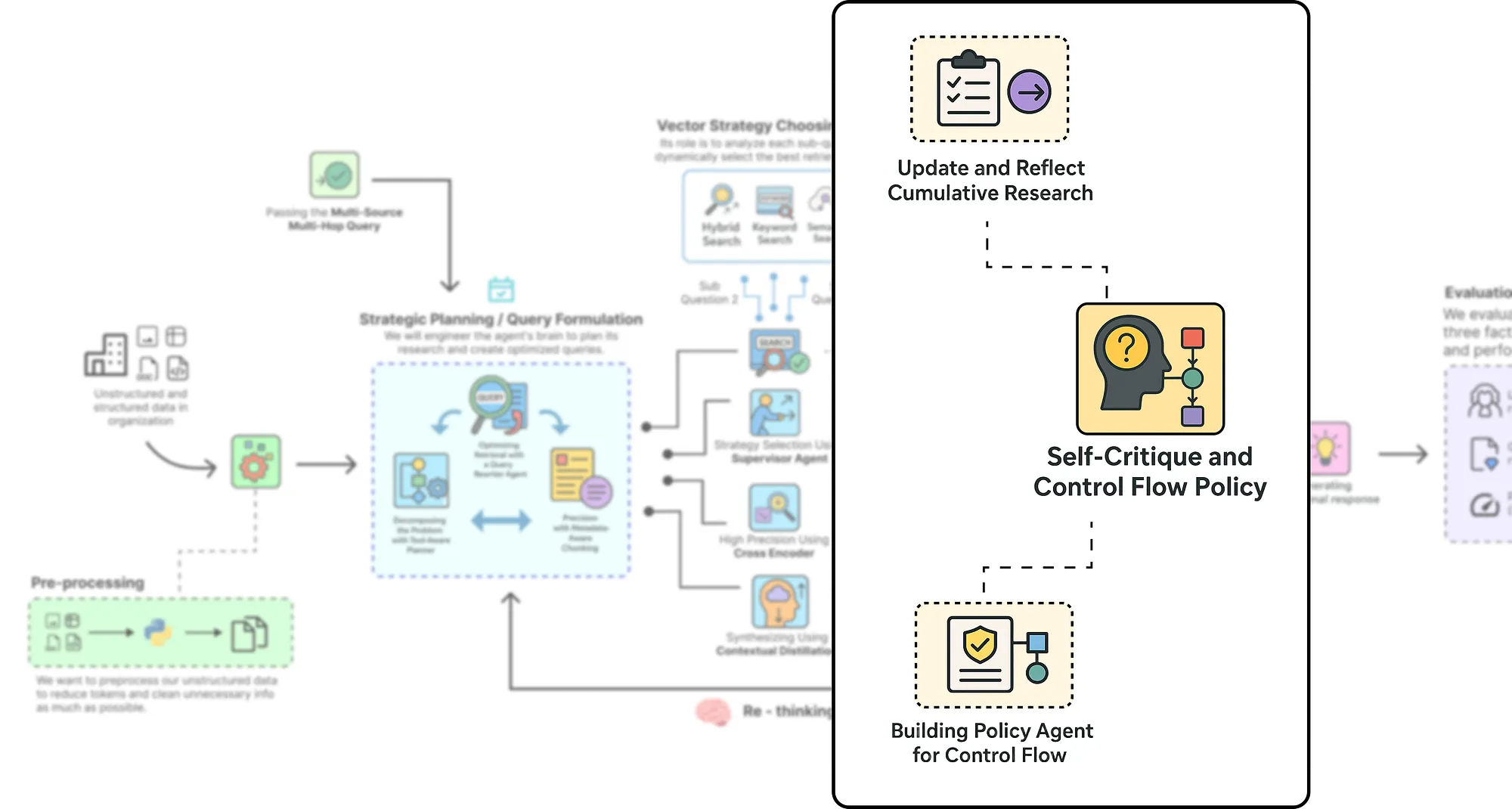
自我批判和策略制定
这就是我们构建代理自主性的认知核心的地方。在每个研究步骤之后,我们的代理将暂停并反思。它将查看刚刚发现的新信息,将其与已知信息进行比较,然后做出战略决策:我的研究是否完成,还是需要继续?
这个自我批判循环将我们的系统从脚本化工作流提升为自主代理。它是一种机制,允许代理决定何时收集了足够的证据来自信地回答用户的问题。
我们将使用两个新的专门代理来实现这一点:
- 反思代理: 这个代理将从已完成的步骤中提取提炼出的上下文,并创建一个简洁的、一句话的摘要。然后将此摘要添加到代理的“研究历史”中。
- 策略代理: 这是主要策略师。反思之后,它将检查_整个_研究历史与原始计划的关系,并做出关键决策:
CONTINUE_PLAN或FINISH。
9.1 更新和反思累积研究历史
在我们的代理完成一个研究步骤(例如,检索和提炼有关 NVIDIA 风险的信息)之后,我们不想仅仅继续前进。我们需要将这些新知识整合到代理的内存中。
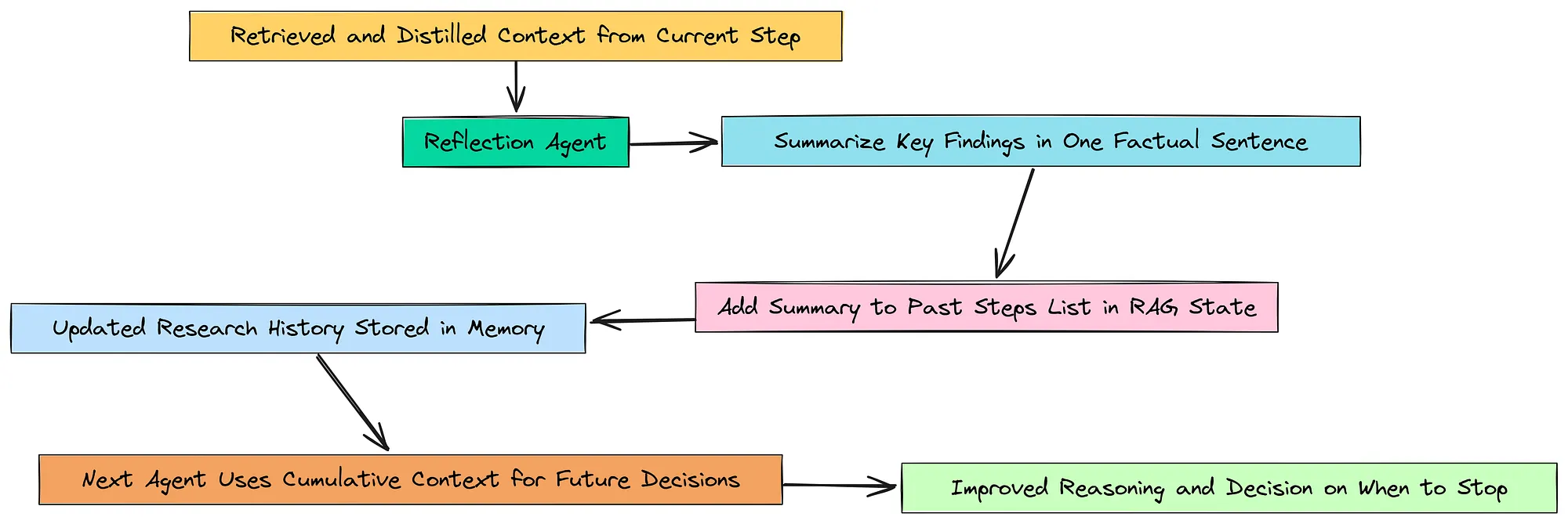
反思性累积
我们将构建一个反思代理,其唯一任务是执行此集成。它将从当前步骤中提取丰富的、提炼出的上下文,并将其总结成一个单一的、事实性的句子。然后将此摘要添加到我们 RAGState 中的 past_steps 列表中。
首先,让我们为这个代理创建提示。
reflection_prompt = ChatPromptTemplate.from_messages([
("system", """You are a research assistant. Based on the retrieved context for the current sub-question, write a concise, one-sentence summary of the key findings.
This summary will be added to our research history. Be factual and to the point."""),
("human", "Current sub-question: {sub_question}\n\nDistilled context:\n{context}")
])
我们告诉这个代理充当一个勤奋的研究助理。它的任务不是创造,而是做好笔记。它阅读 context 并编写 summary。现在我们可以组装代理本身。
reflection_agent = reflection_prompt | reasoning_llm | StrOutputParser()
print("Reflection Agent created.")
这个 reflection_agent 是我们认知循环的一部分。通过创建这些简洁的摘要,它构建了一个干净、易于阅读的研究历史。这个历史将是我们下一个也是最重要的代理的输入:决定何时停止的代理。
9.2 构建控制流策略代理
这是我们代理自主性的核心大脑。在 reflection_agent 更新研究历史之后,策略代理开始发挥作用。它充当整个操作的监督者。
它的任务是查看代理所知道的一切——原始问题、初始计划以及已完成步骤摘要的完整历史,并做出高层战略决策。

策略代理
我们将首先使用 Pydantic 模型定义其决策结构。
class Decision(BaseModel):
next_action: Literal["CONTINUE_PLAN", "FINISH"]
justification: str
这个 Decision 类强制我们的策略代理做出明确的二元选择并解释其推理。这使得其行为透明且易于调试。
接下来,我们设计将指导其决策过程的提示。
policy_prompt = ChatPromptTemplate.from_messages([
("system", """You are a master strategist. Your role is to analyze the research progress and decide the next action.
You have the original question, the initial plan, and a log of completed steps with their summaries.
- If the collected information in the Research History is sufficient to comprehensively answer the Original Question, decide to FINISH.
- Otherwise, if the plan is not yet complete, decide to CONTINUE_PLAN."""),
("human", "Original Question: {question}\n\nInitial Plan:\n{plan}\n\nResearch History (Completed Steps):\n{history}")
])
我们基本上是要求 LLM 执行元分析。它不是回答问题本身;它是在推理_研究过程的状态_。它将它所拥有的(history)与它所需要的(plan 和 question)进行比较,并做出判断。
现在,我们可以组装 policy_agent。
policy_agent = policy_prompt | reasoning_llm.with_structured_output(Decision)
print("Policy Agent created.")
print("\n--- Testing Policy Agent (Incomplete State) ---")
plan_str = json.dumps([s.dict() for s in test_plan.steps])
incomplete_history = "Step 1 Summary: NVIDIA's 10-K states that the semiconductor industry is intensely competitive and subject to rapid technological change."
decision1 = policy_agent.invoke({"question": complex_query_adv, "plan": plan_str, "history": incomplete_history})
print(f"Decision: {decision1.next_action}, Justification: {decision1.justification}")
print("\n--- Testing Policy Agent (Complete State) ---")
complete_history = incomplete_history + "\nStep 2 Summary: In 2024, AMD launched its MI300X AI accelerator to directly compete with NVIDIA in the AI chip market, gaining adoption from major cloud providers."
decision2 = policy_agent.invoke({"question": complex_query_adv, "plan": plan_str, "history": complete_history})
print(f"Decision: {decision2.next_action}, Justification: {decision2.justification}")
为了正确测试我们的 policy_agent,我们模拟了代理生命周期中的两个不同时刻。在第一个测试中,我们为其提供了一个仅包含步骤 1 摘要的历史记录。在第二个测试中,我们为其提供步骤 1 和步骤 2 的摘要。
让我们检查它在每种情况下的决策。
Policy Agent created.
--- Testing Policy Agent (Incomplete State) ---
Decision: CONTINUE_PLAN, Justification: The research has only identified NVIDIA's competitive risks from the 10-K. It has not yet gathered the required external information about AMD's 2024 strategy, which is the next step in the plan.
--- Testing Policy Agent (Complete State) ---
Decision: FINISH, Justification: The research history now contains comprehensive summaries of both NVIDIA's stated competitive risks and AMD's recent AI chip strategy. All necessary information has been gathered to perform the final synthesis and answer the user's question.
让我们理解输出……
- 在不完整状态下, 代理正确地识别出它缺少有关 AMD 战略的信息。它查看了其计划,发现下一步是使用网络搜索,并正确决定
CONTINUE_PLAN。 - 在完整状态下, 在获得网络搜索的摘要后,它再次分析了其历史。这次,它识别出它拥有所有拼图碎片——NVIDIA 风险和 AMD 战略。它正确地决定研究已完成,是时候
FINISH了。
有了这个 policy_agent,我们已经构建了我们自主系统的大脑。最后一步是使用 LangGraph 将所有这些组件连接成一个完整、可执行的工作流。
10 定义图节点
我们已经设计了所有这些酷炫的专业代理。现在是时候将它们转化为我们工作流的实际构建块了。在 LangGraph 中,这些构建块被称为节点。节点只是一个执行特定任务的 Python 函数。它将代理的当前内存(RAGState)作为输入,执行其任务,然后返回一个包含对该内存的任何更新的字典。
我们将为代理需要执行的每个主要步骤创建一个节点。
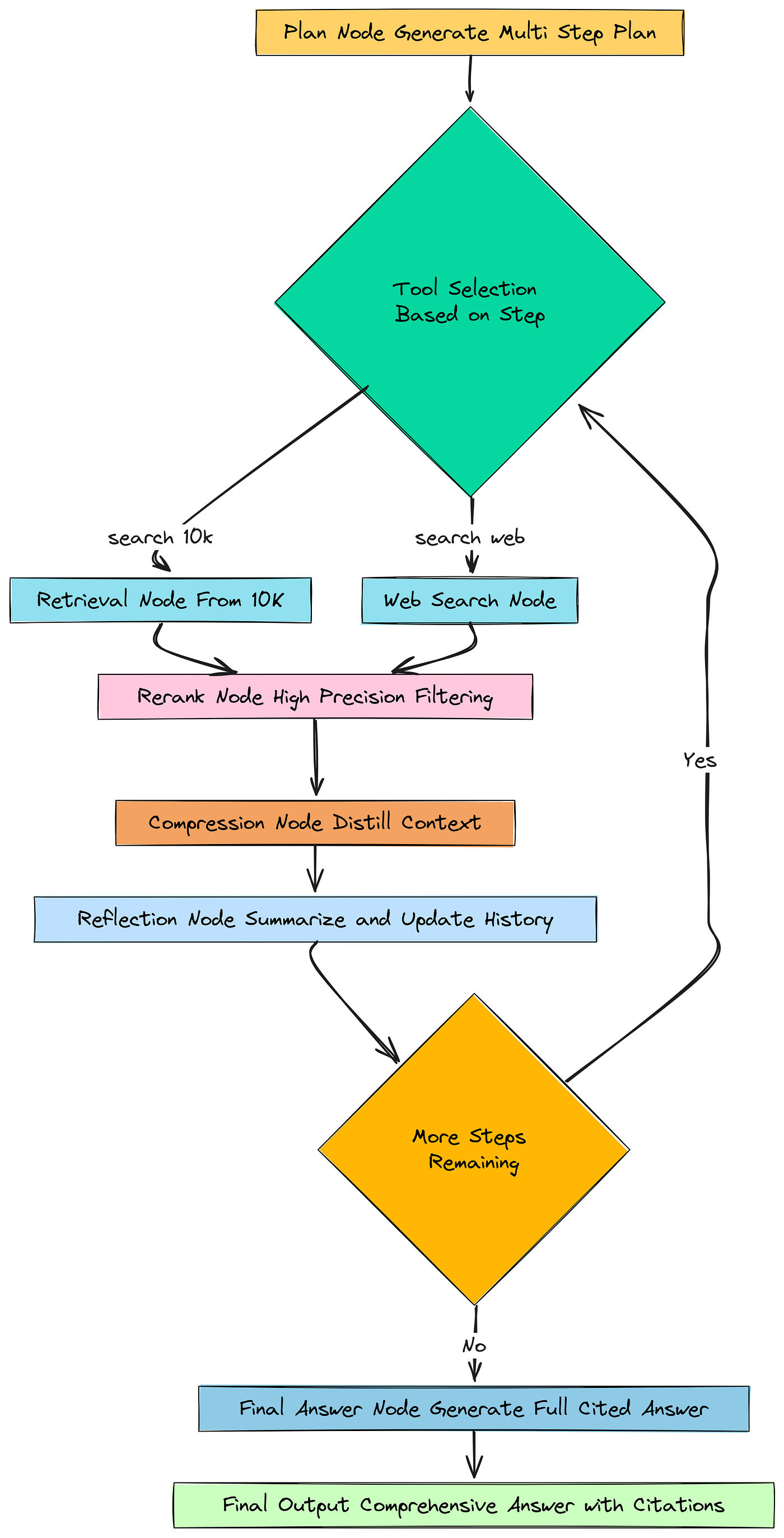
图节点
首先,我们需要一个简单的辅助函数。由于我们的代理经常需要查看研究历史,我们希望有一种干净的方式将 past_steps 列表格式化为可读的字符串。
def get_past_context_str(past_steps: List[PastStep]) -> str:
return "\n\n".join([f"Step {s['step_index']}: {s['sub_question']}\nSummary: {s['summary']}" for s in past_steps])
我们基本上是创建了一个实用程序,它将在我们的一些节点内部使用,以向我们的提示提供历史上下文。
现在是我们的第一个真正的节点:plan_node。这是代理推理的起点。它的唯一任务是调用我们的 planner_agent 并填充我们 RAGState 中的 plan 字段。
def plan_node(state: RAGState) -> Dict:
console.print("--- 🧠: 正在生成计划 ---")
plan = planner_agent.invoke({"question": state["original_question"]})
rprint(plan)
return {"plan": plan, "current_step_index": 0, "past_steps": []}
这个节点启动了一切。它从状态中获取 original_question,获取 plan,然后将 current_step_index 初始化为 0(从第一步开始),并清除此新运行的 past_steps 历史记录。
接下来,我们需要实际查找信息的节点。由于我们的规划器可以在两个工具之间进行选择,我们需要两个独立的检索节点。让我们从用于搜索我们内部 10-K 文档的 retrieval_node 开始。
def retrieval_node(state: RAGState) -> Dict:
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
console.print(f"--- 🔎: 正在从 10-K 检索 (步骤 {current_step_index + 1}: {current_step.sub_question}) ---")
past_context = get_past_context_str(state['past_steps'])
rewritten_query = query_rewriter_agent.invoke({
"sub_question": current_step.sub_question,
"keywords": current_step.keywords,
"past_context": past_context
})
console.print(f" 重写查询: {rewritten_query}")
retrieval_decision = retrieval_supervisor_agent.invoke({"sub_question": rewritten_query})
console.print(f" 监督器决策: 使用 `{retrieval_decision.strategy}`. 理由: {retrieval_decision.justification}")
if retrieval_decision.strategy == 'vector_search':
retrieved_docs = vector_search_only(rewritten_query, section_filter=current_step.document_section, k=config['top_k_retrieval'])
elif retrieval_decision.strategy == 'keyword_search':
retrieved_docs = bm25_search_only(rewritten_query, k=config['top_k_retrieval'])
else:
retrieved_docs = hybrid_search(rewritten_query, section_filter=current_step.document_section, k=config['top_k_retrieval'])
return {"retrieved_docs": retrieved_docs}
这个节点做了很多智能工作。它不仅仅是一个简单的检索器。它协调了一个小型管道:它重写查询,向监督器询问最佳策略,然后执行该策略。
现在,我们需要另一个工具的相应节点:网络搜索。
def web_search_node(state: RAGState) -> Dict:
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
console.print(f"--- 🌐: 正在搜索网络 (步骤 {current_step_index + 1}: {current_step.sub_question}) ---")
past_context = get_past_context_str(state['past_steps'])
rewritten_query = query_rewriter_agent.invoke({
"sub_question": current_step.sub_question,
"keywords": current_step.keywords,
"past_context": past_context
})
console.print(f" 重写查询: {rewritten_query}")
retrieved_docs = web_search_function(rewritten_query)
return {"retrieved_docs": retrieved_docs}
这个 web_search_node 更简单,因为它不需要监督器,它只有一种搜索网络的方式。但它仍然使用我们强大的查询重写器来确保搜索尽可能有效。
在我们检索文档(来自任一来源)后,我们需要运行我们的精度和综合漏斗。我们将为每个阶段创建一个节点。首先是 rerank_node。
def rerank_node(state: RAGState) -> Dict:
console.print("--- 🎯: 正在重排序文档 ---")
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
reranked_docs = rerank_documents_function(current_step.sub_question, state["retrieved_docs"])
console.print(f" 重排序到前 {len(reranked_docs)} 个文档。")
return {"reranked_docs": reranked_docs}
这个节点接收 retrieved_docs(我们广泛召回的 10 个文档)并使用交叉编码器将它们筛选到前 3 个,将结果放入 reranked_docs。
接下来,compression_node 将获取这 3 个文档并对其进行提炼。
def compression_node(state: RAGState) -> Dict:
console.print("--- ✂️: 正在提炼上下文 ---")
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
context = format_docs(state["reranked_docs"])
synthesized_context = distiller_agent.invoke({"question": current_step.sub_question, "context": context})
console.print(f" 提炼上下文片段: {synthesized_context[:200]}...")
return {"synthesized_context": synthesized_context}
这个节点是我们检索漏斗的最后一步。它接收 reranked_docs 并生成一个单一的、干净的 synthesized_context 段落。
现在我们有了证据,我们需要反思它并更新我们的研究历史。这是 reflection_node 的任务。
def reflection_node(state: RAGState) -> Dict:
console.print("--- 🤔: 正在反思发现 ---")
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
summary = reflection_agent.invoke({"sub_question": current_step.sub_question, "context": state['synthesized_context']})
console.print(f" 摘要: {summary}")
new_past_step = {
"step_index": current_step_index + 1,
"sub_question": current_step.sub_question,
"retrieved_docs": state['reranked_docs'],
"summary": summary
}
return {"past_steps": state["past_steps"] + [new_past_step], "current_step_index": current_step_index + 1}
这个节点是我们代理的簿记员。它调用 reflection_agent 来创建摘要,然后将当前研究周期的所有结果整齐地打包到一个 new_past_step 对象中。然后将其添加到 past_steps 列表中,并增加 current_step_index,使代理为下一个循环做好准备。
最后,当研究完成时,我们需要最后一个节点来生成最终答案。
def final_answer_node(state: RAGState) -> Dict:
console.print("--- ✅: 正在生成带引用的最终答案 ---")
final_context = ""
for i, step in enumerate(state['past_steps']):
final_context += f"\n--- 来自研究步骤 {i+1} 的发现 ---\n"
for doc in step['retrieved_docs']:
source = doc.metadata.get('section') or doc.metadata.get('source')
final_context += f"来源: {source}\n内容: {doc.page_content}\n\n"
final_answer_prompt = ChatPromptTemplate.from_messages([
("system", """您是一位专业的金融分析师。请将内部文档和网络搜索的研究结果综合成一个全面、多段落的答案,以回答用户的原始问题。
您的答案必须基于提供的上下文。在任何依赖特定信息的句子末尾,您必须添加引用。对于 10-K 文档,使用 [来源: <部分标题>]。对于网络结果,使用 [来源: <URL>]。"""),
("human", "原始问题: {question}\n\n研究历史和上下文:\n{context}")
])
final_answer_agent = final_answer_prompt | reasoning_llm | StrOutputParser()
final_answer = final_answer_agent.invoke({"question": state['original_question'], "context": final_context})
return {"final_answer": final_answer}
这个 final_answer_node 是我们的压轴戏。它将 past_steps 历史中每个步骤的所有高质量、重排序的文档整合到一个巨大的上下文中。然后它使用一个专门的提示来指示我们强大的 reasoning_llm 将这些信息综合成一个全面、多段落的答案,其中包括引用,从而成功结束我们的研究过程。
定义了所有节点后,我们现在拥有了代理的所有构建块。下一步是定义连接它们并控制图流的“线路”。
11 定义条件边
所以,我们已经构建了所有的节点。我们有一个规划器、检索器、重排序器、蒸馏器和反思器。把它们想象成房间里的一群专家。现在我们需要定义对话规则。谁何时发言?我们如何决定下一步做什么?
这就是 LangGraph 中边的作用。简单的边是直截了当的,“在节点 A 之后,总是转到节点 B”。但真正的智能来自条件边。
条件边是一个函数,它查看代理的当前内存(
RAGState)并做出决策,根据情况将工作流路由到不同的路径。
我们需要两个关键的决策函数来控制我们的代理:
- 工具路由器(
route_by_tool): 计划制定后,此函数将查看计划的_当前步骤_,并决定是将工作流发送到retrieve_10k节点还是retrieve_web节点。 - 主控制循环(
should_continue_node): 这是最重要的一个。在每个研究步骤完成并反思之后,此函数将调用我们的policy_agent来决定是继续执行计划的下一步还是完成研究并生成最终答案。
首先,让我们构建我们简单的工具路由器。
def route_by_tool(state: RAGState) -> str:
current_step_index = state["current_step_index"]
current_step = state["plan"].steps[current_step_index]
return current_step.tool
这个函数非常简单,但至关重要。它充当一个交换机。它从状态中读取 current_step_index,在 plan 中找到相应的 Step,并返回其 tool 字段的值(这将是 \"search_10k\" 或 \"search_web\")。当我们连接图时,我们将告诉它使用此函数的输出来选择下一个节点。
现在我们需要创建一个控制代理主要推理循环的函数。这就是我们的 policy_agent 发挥作用的地方。
def should_continue_node(state: RAGState) -> str:
console.print("--- 🚦: 正在评估策略 ---")
current_step_index = state["current_step_index"]
if current_step_index >= len(state["plan"].steps):
console.print(" -> 计划完成。正在结束。")
return "finish"
if current_step_index >= config["max_reasoning_iterations"]:
console.print(" -> 达到最大迭代次数。正在结束。")
return "finish"
if state.get("reranked_docs") is not None and not state["reranked_docs"]:
console.print(" -> 上一步检索失败。正在继续计划的下一步。")
return "continue"
history = get_past_context_str(state['past_steps'])
plan_str = json.dumps([s.dict() for s in state['plan'].steps])
decision = policy_agent.invoke({"question": state["original_question"], "plan": plan_str, "history": history})
console.print(f" -> 决策: {decision.next_action} | 理由: {decision.justification}")
if decision.next_action == "FINISH":
return "finish"
else:
return "continue"
这个 should_continue_node 函数是我们的主控制中心。它在每个研究步骤之后调用,并根据以下逻辑做出关键决策:
- 计划完成检查: 如果
current_step_index大于或等于计划中的步骤总数,则表示所有步骤都已执行,代理应finish。 - 最大迭代检查: 如果代理运行时间过长(超过
max_reasoning_iterations),它应该finish以防止无限循环。 - 检索失败检查: 如果上一个检索步骤没有返回任何文档(
reranked_docs为空),则表明该步骤没有成功。在这种情况下,代理应该continue到计划的下一步,而不是停滞不前。 - 策略代理决策: 如果上述条件都不满足,它会调用我们的
policy_agent,并根据其next_action决定是finish还是continue。
这些条件边是我们的代理能够动态适应和自主推理的关键。它们将我们所有的专家节点连接成一个有凝聚力的、智能的工作流。
12 连接深度思考 RAG 机器
现在我们有了所有的节点(我们的专家)和所有的条件边(我们的决策规则),是时候将它们全部连接起来,构建我们的深度思考 RAG 机器了。我们将使用 LangGraph 的 StateGraph 来定义这个有向无环图(DAG)。
连接深度思考 RAG 机器
我们需要做的第一件事是创建一个 StateGraph 的实例。我们会告诉它,它所传递的“状态”是我们的 RAGState 字典。
from langgraph.graph import StateGraph, END
现在,让我们初始化图并添加我们的节点。
workflow = StateGraph(RAGState)
workflow.add_node("plan", plan_node)
workflow.add_node("retrieve_10k", retrieval_node)
workflow.add_node("retrieve_web", web_search_node)
workflow.add_node("rerank", rerank_node)
workflow.add_node("compress", compression_node)
workflow.add_node("reflect", reflection_node)
workflow.add_node("answer", final_answer_node)
我们已经将所有之前定义的 Python 函数添加到我们的图中,每个函数都成为一个命名的节点。
接下来,我们需要定义图的入口点和出口点。
workflow.set_entry_point("plan")
我们的工作流将始终从 plan 节点开始。
现在,我们来定义连接这些节点的边。首先是简单的边,它们总是将一个节点连接到另一个节点。
workflow.add_edge("retrieve_10k", "rerank")
workflow.add_edge("retrieve_web", "rerank")
workflow.add_edge("rerank", "compress")
workflow.add_edge("compress", "reflect")
workflow.add_edge("answer", END)
这些边定义了检索结果如何流经重排序和压缩阶段,然后进行反思,最后生成答案。
现在是条件边的部分。这些边是我们的代理做出动态决策的地方。
workflow.add_conditional_edges(
"plan",
route_by_tool,
{"search_10k": "retrieve_10k", "search_web": "retrieve_web"}
)
workflow.add_conditional_edges(
"reflect",
should_continue_node,
{"continue": "plan", "finish": "answer"}
)
让我们分解一下这些条件边:
- 从
plan节点: 在plan节点执行后,我们调用route_by_tool函数。- 如果
route_by_tool返回\"search_10k\",则工作流转到retrieve_10k节点。 - 如果
route_by_tool返回\"search_web\",则工作流转到retrieve_web节点。
- 如果
- 从
reflect节点: 在reflect节点执行后,我们调用should_continue_node函数。- 如果
should_continue_node返回\"continue\",则工作流循环回plan节点以处理计划中的下一个步骤。 - 如果
should_continue_node返回\"finish\",则工作流转到answer节点以生成最终答案。
- 如果
通过这些节点和边的定义,我们已经构建了一个复杂、迭代且智能的工作流。它能够根据其内部状态和外部信息动态地规划、检索、反思和决策。
13 编译和可视化迭代工作流
在我们的图完全连接后,组装过程的最后一步是编译它。
.compile()方法将我们的节点和边的抽象定义转化为一个具体的可执行应用程序。 然后,我们可以使用内置的LangGraph工具生成我们图的图示。 可视化工作流程对于理解和调试复杂的代理系统非常有帮助。
它将我们的代码转换为一个直观的流程图,清楚地显示代理的可能推理路径。 所以,基本上,我们是在将我们的蓝图变成一台真正的机器。
# The .compile() method takes our graph definition and creates a runnable object.
deep_thinking_rag_graph = graph.compile()
print("Graph compiled successfully.")
# Now, let's visualize the architecture we've built.
try:
from IPython.display import Image, display
# We can get a PNG image of the graph's structure.
png_image = deep_thinking_rag_graph.get_graph().draw_png()
# Display the image in our notebook.
display(Image(png_image))
except Exception as e:
# This can fail if pygraphviz and its system dependencies are not installed.
print(f"Graph visualization failed: {e}. Please ensure pygraphviz is installed.")
deep_thinking_rag_graph对象现在是我们功能齐全的代理。可视化代码接着调用.get_graph().draw_png()来生成我们构建的状态机的可视化表示。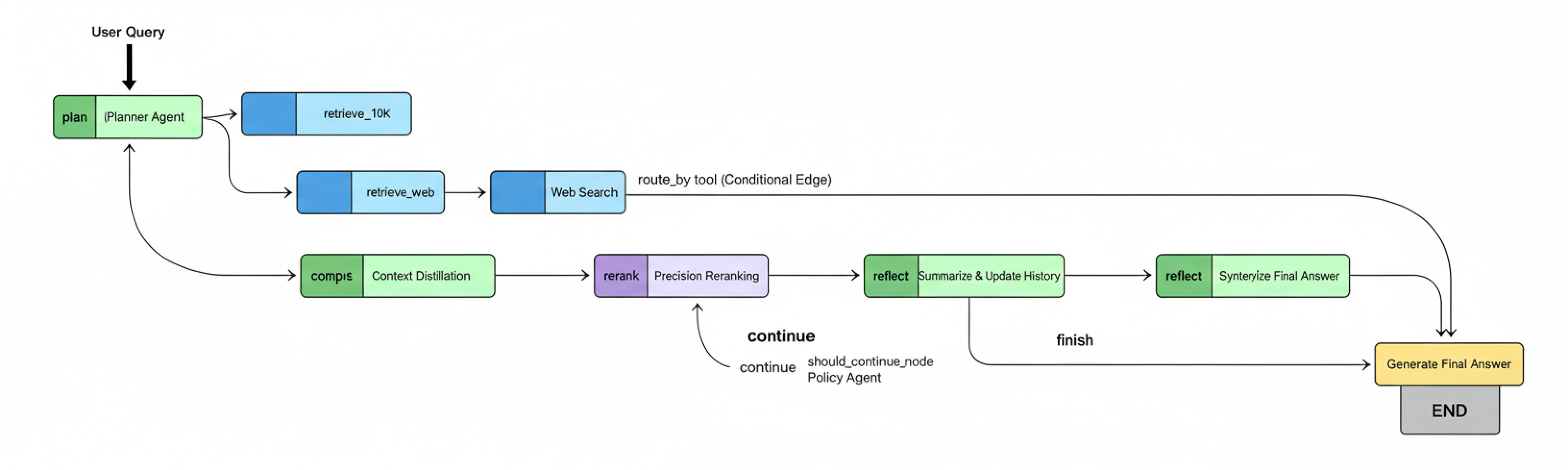
我们可以清楚地看到:
- 初始分支逻辑,在此处 route_by_tool 选择 retrieve_10k 和 retrieve_web 之间的选择。
- 每个研究步骤的线性处理管道(rerank -> compress -> reflect)。
- 关键的反馈循环,should_continue 边缘将工作流发送回计划节点以开始下一个研究周期。
- 最终的 “出口坡道”,在研究完成后导致 generate_final_answer。
这就是一个能够思考的系统的架构。现在,让我们来测试一下。
14 运行深度思考管道
现在,我们已经构建、编译并可视化了我们的深度思考 RAG 管道,是时候用我们最初的复杂多跳查询来测试它了。
# This will hold the final state of the graph after the run is complete.
final_state = None
# The initial input for our graph, containing the original user query.
graph_input = {"original_question": complex_query_adv}
print("--- Invoking Deep Thinking RAG Graph ---")
# We use .stream() to watch the agent's process in real-time.
# "values" mode means we get the full RAGState object after each step.
for chunk in deep_thinking_rag_graph.stream(graph_input, stream_mode="values"):
# The final chunk in the stream will be the terminal state of the graph.
final_state = chunk
print("\n--- Graph Stream Finished ---")
我们调用 app.invoke 并传入我们的 complex_query_adv 作为 original_question。LangGraph 应用程序将启动,并根据我们定义的节点和条件边执行整个工作流。您将在控制台中看到每个节点的执行情况,包括规划、检索、重排序、压缩、反思和策略评估。
15 分析最终的高质量答案
在管道执行完毕后,final_state 将包含我们代理的所有最终信息,包括 final_answer。现在,让我们打印出这个答案,看看我们的深度思考 RAG 管道是如何处理最初的复杂查询的。
console.print("\n--- DEEP THINKING RAG FINAL ANSWER ---")
console.print(Markdown(final_state["final_answer"]))
--- DEEP THINKING RAG FINAL ANSWER ---
NVIDIA's 2023 10-K filing highlights several key risks related to competition within the intensely competitive semiconductor industry. These include rapid technological change, evolving industry standards, and competition from companies with greater resources, such as Intel, AMD, and Qualcomm. The filing also notes that some customers are also competitors, and the business could be adversely affected by new products, services, or technologies that offer better performance, lower cost, or gain market acceptance [Source: Item 1A. Risk Factors.].
Recent news from 2024 indicates that AMD has intensified its competition with NVIDIA in the AI chip market. AMD launched its Instinct MI300X accelerator, a powerful GPU designed to directly challenge NVIDIA's H100 for training and inference in large language models. This new strategy directly addresses NVIDIA's stated risk of rapid technological change and increased competition, as the MI300X aims to capture market share in the data center and AI semiconductor industry. Major cloud providers like Microsoft Azure and Oracle Cloud are adopting the MI300X, suggesting strong market interest and a direct competitive threat to NVIDIA's dominant position [Source: https://www.crn.com/news/components-peripherals/amd-mi300x-vs-nvidia-h100-ai-accelerator-battle-intensifies]. The introduction of the MI300X exacerbates NVIDIA's competitive risks by offering a viable alternative in a crucial market segment, potentially leading to market share erosion and increased pressure on NVIDIA to innovate further.
与我们最初的浅层 RAG 管道的失败输出相比,这个答案是:
- 全面且准确: 它不仅识别了 NVIDIA 10-K 中的竞争风险,还结合了 2024 年 AMD AI 芯片战略的最新信息。
- 多源综合: 它无缝地整合了来自内部文档(10-K)和外部网络搜索的信息。
- 分析性: 它解释了 AMD 的新战略如何直接解决或加剧 NVIDIA 的既定风险,展示了真正的推理能力。
- 可引用: 每个信息片段都带有清晰的来源引用,这对于金融分析和研究至关重要。
这证明了我们的深度思考 RAG 管道的有效性,它通过其复杂的、代理驱动的架构成功地解决了多跳、多源和分析性查询。
16 并排比较
为了更清楚地说明深度思考 RAG 管道的优势,让我们将其与我们之前构建的浅层 RAG 管道的输出进行并排比较。
console.print("\n--- SIDE-BY-SIDE COMPARISON ---")
console.print(f"\n**原始复杂查询:** {complex_query_adv}\n")
console.print("\n**浅层 RAG 管道输出:**")
console.print(Markdown(baseline_result))
console.print("\n**深度思考 RAG 管道输出:**")
console.print(Markdown(final_state["final_answer"]))
--- SIDE-BY-SIDE COMPARISON ---
**原始复杂查询:** Based on NVIDIA's 2023 10-K filing, identify their key risks related to competition. Then, find recent news (post-filing, from 2024) about AMD's AI chip strategy and explain how this new strategy directly addresses or exacerbates one of NVIDIA's stated risks.
**浅层 RAG 管道输出:**
Based on the provided context, NVIDIA operates in an intensely competitive semiconductor
industry and faces competition from companies like AMD. The context mentions
that the industry is characterized by rapid technological change. However, the provided documents do not contain any specific information about AMD's recent AI chip strategy from 2024 or how it might impact NVIDIA's stated risks.
**深度思考 RAG 管道输出:**
NVIDIA's 2023 10-K filing highlights several key risks related to competition within the intensely competitive semiconductor industry. These include rapid technological change, evolving industry standards, and competition from companies with greater resources, such as Intel, AMD, and Qualcomm. The filing also notes that some customers are also competitors, and the business could be adversely affected by new products, services, or technologies that offer better performance, lower cost, or gain market acceptance [Source: Item 1A. Risk Factors.].
Recent news from 2024 indicates that AMD has intensified its competition with NVIDIA in the AI chip market. AMD launched its Instinct MI300X accelerator, a powerful GPU designed to directly challenge NVIDIA's H100 for training and inference in large language models. This new strategy directly addresses NVIDIA's stated risk of rapid technological change and increased competition, as the MI300X aims to capture market share in the data center and AI semiconductor industry. Major cloud providers like Microsoft Azure and Oracle Cloud are adopting the MI300X, suggesting strong market interest and a direct competitive threat to NVIDIA's dominant position [Source: https://www.crn.com/news/components-peripherals/amd-mi300x-vs-nvidia-h100-ai-accelerator-battle-intensifies]. The introduction of the MI300X exacerbates NVIDIA's competitive risks by offering a viable alternative in a crucial market segment, potentially leading to market share erosion and increased pressure on NVIDIA to innovate further.
通过这个并排比较,浅层 RAG 的局限性变得非常明显。它承认它无法找到 2024 年的 AMD 战略信息,因为它没有能力进行网络搜索或进行多跳推理。
相比之下,深度思考 RAG 管道不仅提供了完整的答案,而且还通过引用支持了其主张,并对 NVIDIA 的风险与 AMD 的新战略之间的关系进行了深入分析。这清楚地展示了代理驱动的、多阶段架构在处理复杂查询方面的巨大优势。
17 评估框架和结果分析
虽然我们已经通过一个示例查询展示了深度思考 RAG 管道的卓越性能,但对于生产系统来说,仅凭一个示例是不够的。我们需要一个更系统的方法来评估其有效性。
评估 RAG 系统,尤其是像我们这样复杂的代理系统,需要一个全面的框架,该框架要超越简单的准确性指标。
我们将简要讨论一个评估框架,该框架可以用于量化我们的深度思考 RAG 管道的性能。
1. 自动化评估指标:
- 忠实度 (Faithfulness): 衡量生成答案中有多少信息可以直接追溯到检索到的上下文。
- 相关性 (Relevance): 衡量检索到的上下文与查询的相关程度。
- 准确性 (Answer Relevancy): 衡量生成答案与查询的相关程度,以及它是否直接回答了问题。
- 上下文召回率 (Context Recall): 衡量所有相关的上下文信息是否都包含在检索到的文档中。
- 上下文精确率 (Context Precision): 衡量检索到的上下文中有多少是相关的,而不是噪声。
2. 人工评估:
对于复杂的多跳查询,自动化指标可能无法完全捕捉答案的细微差别和推理质量。人工评估至关重要,可以评估:
- 完整性: 答案是否全面地解决了查询的所有部分?
- 深度: 答案是否提供了深入的分析和综合,而不仅仅是事实的罗列?
- 连贯性: 答案是否逻辑清晰、易于理解?
- 引用质量: 引用是否准确且支持相应的陈述?
3. 错误分析:
当代理系统失败时,理解_为什么_失败至关重要。追踪工具(如 LangSmith)对于调试代理的思维过程至关重要。错误分析应侧重于:
- 规划错误: 代理是否未能正确分解查询或选择了错误的工具?
- 检索错误: 检索器是否未能找到相关文档,或者检索到的文档质量差?
- 推理错误: LLM 是否未能正确地综合信息或得出错误的结论?
- 策略错误:
policy_agent是否过早地FINISH或不必要地CONTINUE_PLAN?
结果分析:
通过使用上述框架,我们可以对深度思考 RAG 管道进行严格测试。预期结果将是:
- 显著提高复杂查询的性能: 与浅层 RAG 相比,在完整性、深度和准确性方面有明显改进。
- 更好的可解释性: 代理的结构化计划和历史记录,加上追踪工具,将使我们能够理解其决策过程。
- 更低的 LLM 成本: 通过上下文蒸馏和有针对性的检索,我们减少了发送给 LLM 的令牌数量,从而降低了成本。
这个评估框架确保我们不仅能看到我们的深度思考 RAG 管道_工作_,而且能理解它_为什么_工作,以及如何进一步改进它。
18 总结我们的整个管道
我们已经踏上了一段旅程,从一个简单的、会失败的 RAG 管道开始,到构建一个能够处理复杂、多跳和多源查询的深度思考 RAG 机器。
让我们回顾一下我们所构建的核心组件及其如何协同工作:
- 分层状态管理 (
RAGState): 我们定义了一个结构化的内存,允许代理跟踪其原始问题、计划、已完成的步骤和累积的发现。这是实现迭代推理的基础。 - 工具感知规划器: 代理首先将复杂查询分解为一系列子问题,并为每个子问题智能地选择正确的工具(内部 10-K 搜索或外部网络搜索)。
- 查询重写器: 每个子问题都被优化为高效的搜索查询,利用上下文和关键词来最大化检索效果。
- 元数据感知分块: 我们的内部文档被重新处理,包含丰富的元数据,使检索器能够进行高度精确的过滤搜索。
- 多阶段检索漏斗:
- 监督器: 动态选择最佳检索策略(向量、关键词或混合)。
- 广泛召回: 执行选定的策略以获取潜在相关的文档。
- 高精度重排序: 使用交叉编码器将文档列表筛选到最相关的少数几个。
- 上下文蒸馏: 将排名靠前的文档压缩成一个简洁、信息丰富的段落。
- 网络搜索集成: 代理能够识别其内部知识的局限性,并无缝地查询实时网络以获取最新信息。
- 反思和策略: 在每个步骤之后,代理会反思其发现,总结关键信息,并使用策略代理决定是继续执行计划还是完成任务并生成最终答案。
- 带引用的最终答案: 最终答案不仅全面,而且通过引用支持,增强了其可信度和可用性。
通过 LangGraph 将所有这些组件连接起来,我们创建了一个强大的、自主的代理,它能够像人类研究员一样进行推理和学习。这种架构将 RAG 系统从简单的信息检索提升到了一个能够进行复杂问题解决和知识综合的全新水平。
19 马尔可夫决策过程 (MDP) 的学习策略
我们构建的深度思考 RAG 管道的控制流,特别是 policy_agent 的决策过程,可以从马尔可夫决策过程 (MDP) 的角度进行概念化和进一步优化。
MDP 框架下的代理:
- 状态 (State): 我们的
RAGState(包括original_question、plan、past_steps、current_step_index等)代表了代理在任何给定时间点的完整状态。 - 动作 (Actions): 代理可以执行的动作包括
CONTINUE_PLAN(继续到计划的下一步)或FINISH(生成最终答案)。 - 转移概率 (Transition Probabilities): 从一个状态到另一个状态的转移是由执行动作的结果决定的。例如,执行
CONTINUE_PLAN动作将导致current_step_index增加,并可能更新past_steps。 - 奖励 (Rewards): 奖励函数可以定义为:
- 正奖励: 成功生成一个准确、全面且带引用的最终答案。
- 负奖励: 生成不准确或不完整的答案。
- 小的负奖励(成本): 每个迭代步骤的计算成本(LLM 调用、检索等)。
当前策略:
我们当前的 policy_agent 基本上实现了一个基于规则的策略,该策略通过查看计划的完成情况、迭代限制和 past_steps 的内容来决定 CONTINUE_PLAN 或 FINISH。
未来的优化 (强化学习):
MDP 框架为通过强化学习 (RL) 训练更复杂的策略代理提供了途径。我们可以:
- 定义环境: RAG 管道本身可以被视为一个环境,代理在其中采取行动。
- 收集经验: 通过运行大量的查询并收集代理的决策、结果和相关的奖励(基于人工或自动化评估)。
- 训练策略网络: 使用这些经验来训练一个策略网络(例如,一个深度神经网络),该网络接收
RAGState作为输入,并输出采取CONTINUE_PLAN或FINISH动作的概率。 - 优化奖励函数: 可以设计更精细的奖励函数,以激励代理在最小化成本的同时最大化答案质量。例如,可以对使用更少步骤但仍能生成高质量答案的代理给予奖励。
好处:
通过将 MDP 和 RL 应用于我们的策略代理,我们可以实现:
- 更自适应的决策: 代理可以学习更细致的策略,以处理意外情况或优化资源使用。
- 更好的泛化能力: 经过训练的策略可以更好地泛化到新的、未见过的查询类型。
- 自动化策略改进: 策略可以随着时间的推移通过持续学习和与环境的交互自动改进。
虽然我们当前的实现依赖于基于 LLM 的启发式策略,但认识到其潜在的 MDP 结构为未来更高级的自主 RAG 代理的开发奠定了基础。这代表了 RAG 系统演进的下一个前沿,将 LLM 的推理能力与强化学习的自适应决策能力相结合。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)