FlashCommunication V2登场!突破「任意比特」通信瓶颈,加速大模型分布式训练与部署
论文《FlashCommunicationV2》提出创新通信技术,解决大模型分布式训练中的带宽瓶颈问题。
内容源自计算机科研圈
在大语言模型(LLMs)向万亿参数级演进的过程中,分布式训练与部署中的通信瓶颈已成为制约效率的核心挑战。尤其是混合专家模型(MoE)的兴起 —— 如 DeepSeekV3(671B 参数)、Kimi K2(1T 参数)等 —— 对跨 GPU 通信的带宽、灵活性和效率提出了更高要求。
在此背景下,论文《FlashCommunication V2: Bit Splitting and Spike Reserving for Any Bit Communication》提出了一种创新的通信范式,通过比特分割(bit splitting)和尖峰保留(spike reserving)技术,实现了任意比特宽度下的高效跨 GPU 传输,为大模型分布式系统提供了关键优化方案。

论文标题:
FlashCommunication V2: Bit Splitting and Spike Reserving for Any Bit Communication
论文链接:
https://arxiv.org/abs/2508.03760
作者单位:
美团、英伟达

背景:大模型分布式通信的核心挑战
随着 LLMs 规模的爆炸式增长,分布式训练与部署依赖多种并行策略(如张量并行、专家并行),而通信操作(如 AllReduce、All2All)的开销逐渐成为性能瓶颈:
-
带宽压力:万亿参数模型的激活值、梯度等数据传输量巨大,即使采用高带宽的 NVLink 或 PCIe,也难以满足实时性需求。
-
量化困境:低比特量化(如 INT8、INT4)是减少通信量的有效手段,但存在两大问题:一是不规则比特宽度(如 INT5)难以适配硬件;二是数值异常值(尖峰)会导致低比特量化精度暴跌(如 INT2 量化时困惑度可能飙升至 1e3)。
-
硬件差异:不同架构(NVLink vs PCIe)的通信机制差异显著,通用优化方案难以兼顾。
现有方法(如 FlashCommunication V1、ZeRO++)虽在特定场景下有效,但无法支持任意比特宽度,且在极端低比特(如 INT2)下精度损失难以接受。FlashCommunication V2 正是针对这些痛点提出的革新方案。

核心创新:比特分割与尖峰保留技术
FlashCommunication V2 的突破在于两项核心技术,从“硬件兼容性”和“量化精度”两个维度解决了低比特通信的难题。
1. 比特分割(Bit Splitting):实现任意比特宽度的硬件适配
硬件通常仅支持规整比特宽度(如 INT4、INT8),而不规则比特(如 INT5、INT6)的传输效率极低。比特分割技术通过数据重组,将不规则比特宽度分解为 “规整单元 + 额外比特”,实现硬件友好的传输:

▲ 图3. 比特分割示意图
分解逻辑:以 INT5 为例,将每个数据拆分为 4 比特的 “规整部分” 和 1 比特的 “额外部分”;所有数据的规整部分打包传输,额外部分单独存储(如图 3 所示)。
效率保障:规整部分采用 FlashCommunication V1 的快速打包策略,额外部分通过紧凑存储最小化开销。例如,4096 个 BF16 数据(8192 字节)经 INT5 分割后,仅需 2048(4 比特部分)+128(额外比特)+512(尺度和零值)=2688 字节,通信量减少约 67%。
这一技术使任意比特宽度(如 INT5、INT6)均可高效传输,打破了硬件对量化精度的限制。
2. 尖峰保留(Spike Reserving):抑制低比特量化的精度损失
低比特量化(尤其是 INT2/INT3)的最大挑战是数值异常值(尖峰)—— 即数据中的极大值或极小值。这些尖峰会扩大动态范围,导致大部分数据量化误差激增。尖峰保留技术通过分离存储异常值,显著缩小量化范围:
核心逻辑:在每个量化组(如 32 个数据)中,识别并保留最大值和最小值(尖峰)为浮点数,仅对剩余数据在 “收缩后的动态范围” 内进行低比特量化(如图 5 所示)。
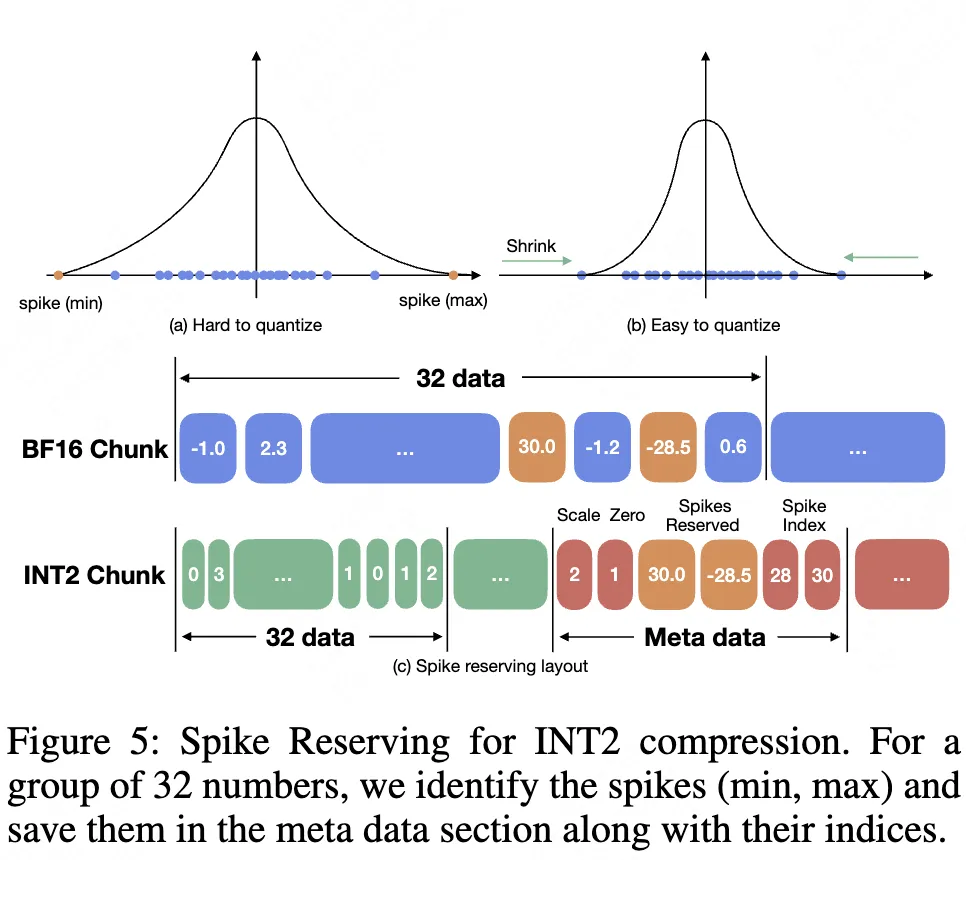
▲ 图5. 使用尖峰保留进行 INT2 压缩
细节优化:
尖峰的索引以 INT8 存储(替代 BF16),尺度参数通过整数化(scale_int = floor(log2(scale)*θ))进一步压缩元数据开销。
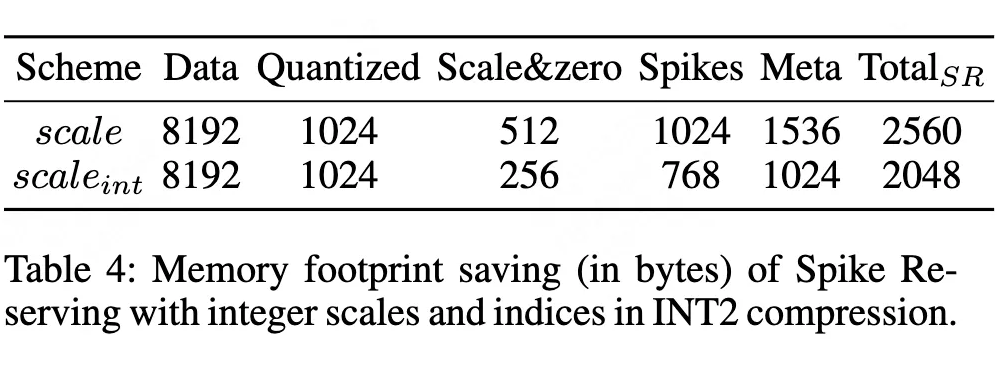
▲ 表4. 尖峰保留节省内存访问开销
整体存储量较纯低比特量化减少 20%(如表 4 所示)。
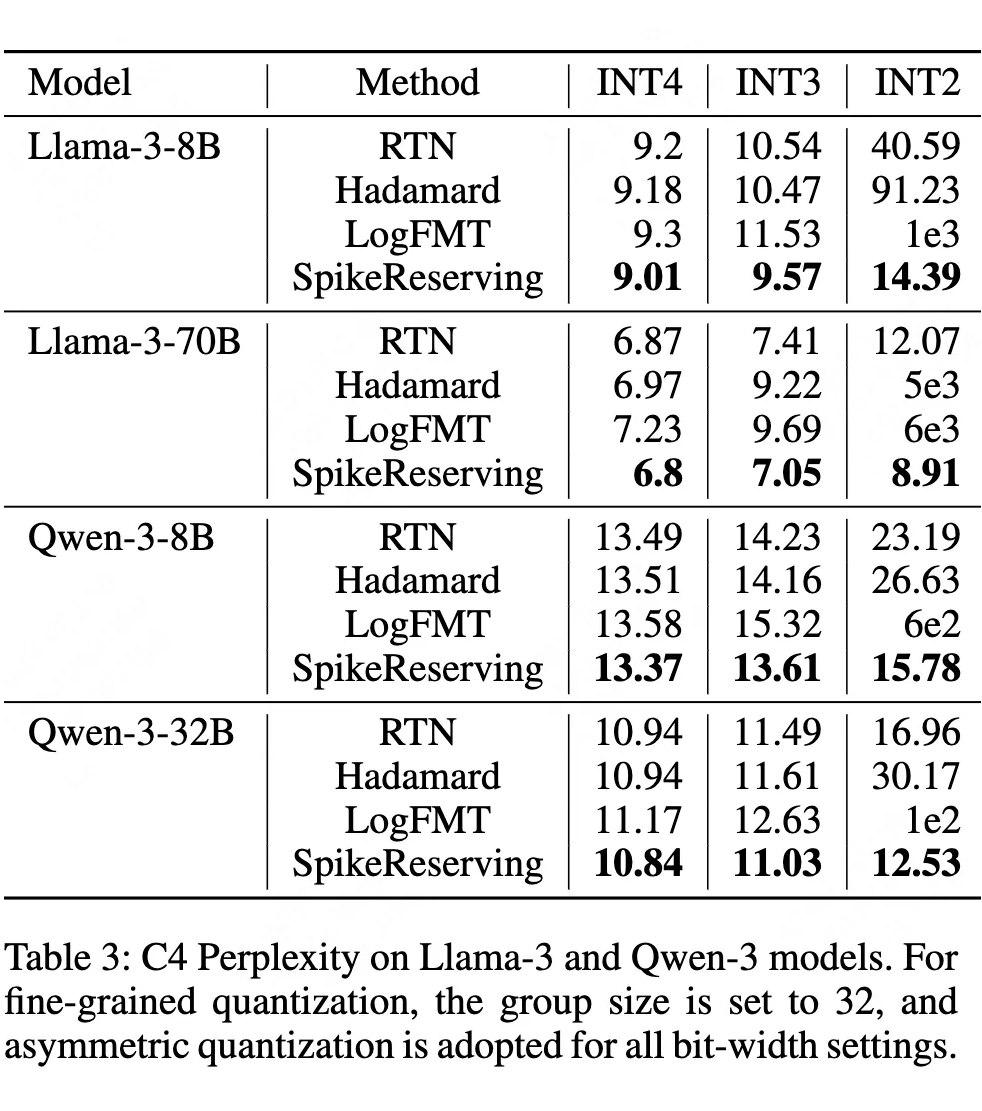
▲ 表3. C4 困惑度对比
实验验证(表 3)显示,尖峰保留可使 Llama-3-8B 在 INT2 量化时的困惑度从 40.59 降至 14.39,Llama-3-70B 的困惑度从 12.07 降至 8.91,精度损失控制在可接受范围。
扩展优化:层次化通信与流水线并行
针对低带宽场景(如 PCIe 架构的 L40 GPU),FlashCommunication V2 进一步提出层次化通信 + 流水线并行策略:
层次化通信:将 AllReduce 拆分为 “NUMA 组内部分 ReduceScatter → 跨 NUMA 桥归约 → NUMA 组内部分 AllGather” 三阶段,减少跨 NUMA 数据传输量(从 4M 降至 M,如表 5 所示)。

▲ 表5. 通信量对比
流水线并行:将通信任务拆分为微块,使不同阶段(如 ReduceScatter 与 AllGather)重叠执行,消除带宽空闲时间(如图 8 所示),最多可节省 20% 通信时间。
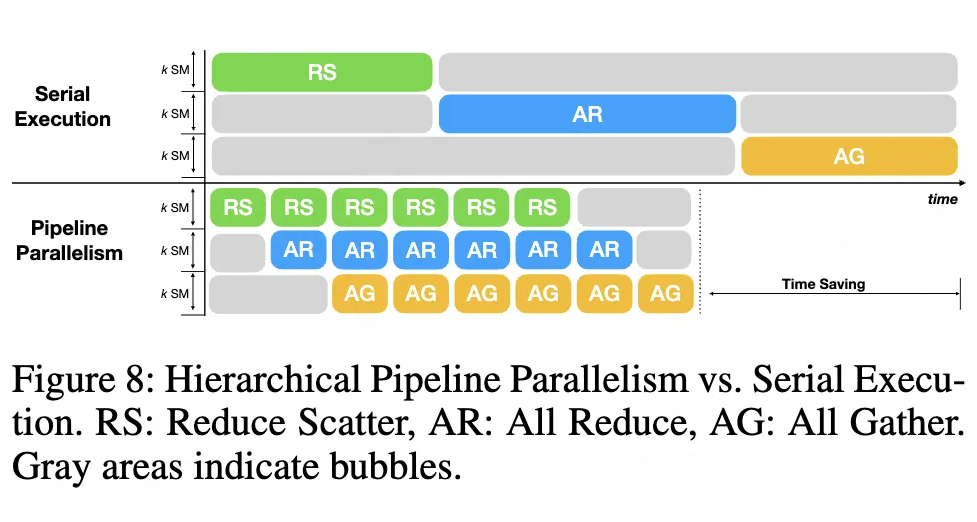
▲ 图8. 层次化的流水线并行

实验验证:性能与精度的双重突破
论文在 L40、A100、H800 等主流 GPU 上,对 dense 模型(Llama-3、Qwen-3)和 MoE 模型(Qwen3-30B-A3B)进行了全面测试,验证了技术的有效性。
1. 量化精度:尖峰保留显著改善低比特性能
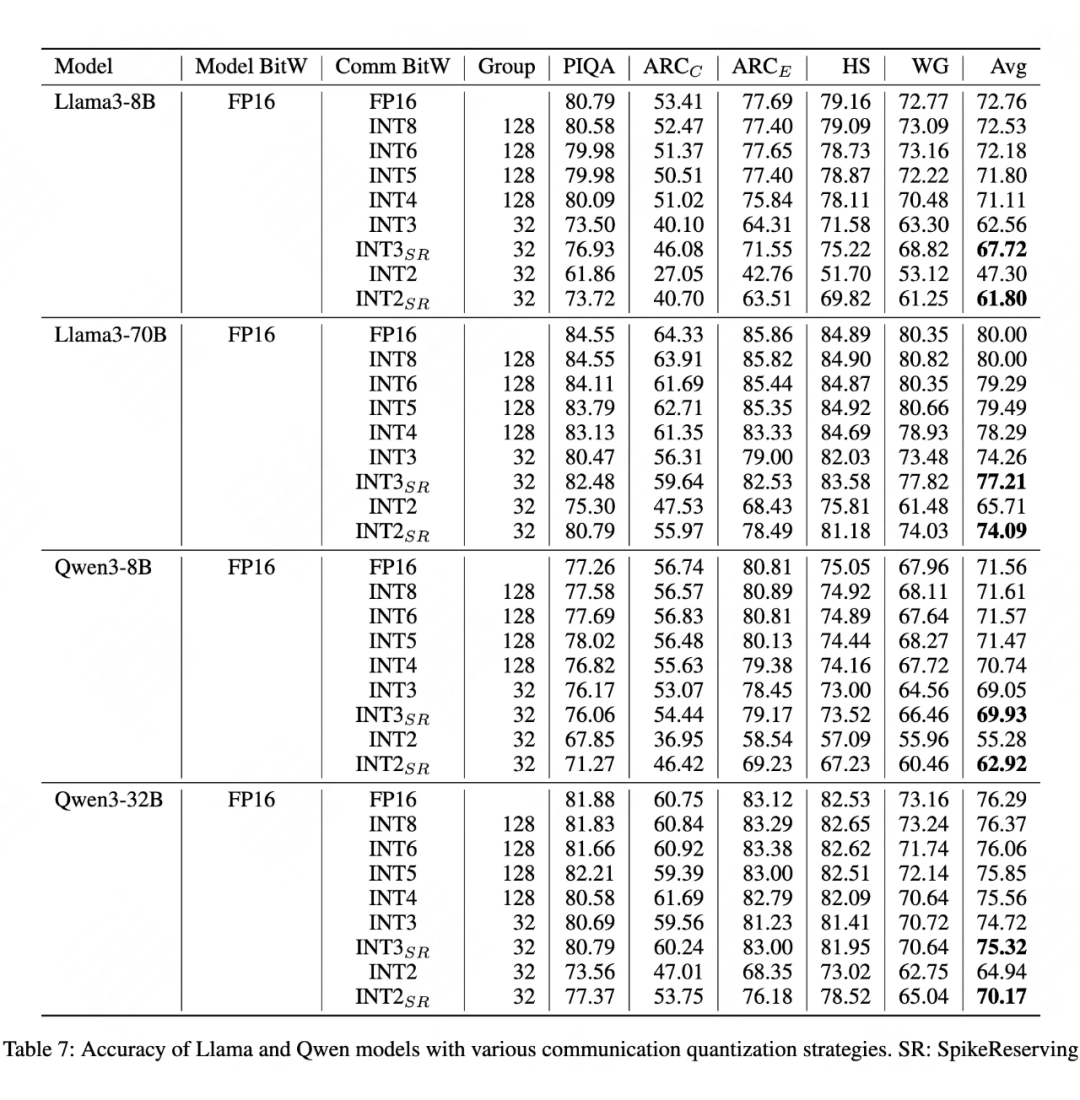
▲ 表7. LLaMA、Qwen 模型在不同量化位宽下的通信量化准确率
在 PIQA、ARC 等基准测试中(表 7),尖峰保留(SR)使 INT2 量化的平均精度提升显著:
-
Llama-3-8B 的 INT2 精度从 47.30 提升至 61.80(+14.5%);
-
Llama-3-70B 的 INT2 精度从 65.71 提升至 74.09(+8.38%)。
即使在极端低比特下,模型仍能保持实用性能。
2. 通信效率:加速比最高达 3.2 倍
AllReduce 通信:在 L40(PCIe 架构)上,INT2 + 尖峰保留 + 层次化通信的算法带宽达 29.6 GB/s,是 NCCL BF16(9.17 GB/s)的 3.2 倍;在 H800(NVLink 架构)上,INT4 量化实现 1.99 倍加速。
All2All 通信:在 A100 上,INT4 量化的算法带宽达 218.10 GB/s,是 BF16(165.41 GB/s)的 1.32 倍;在 H800 上,INT4 量化实现 2.01 倍加速(表 10)。

▲ 表10. All2All 算法带宽
3. 首 Token 时间(TTFT):优化用户体验
低比特量化结合比特分割后,Llama-3-8B 的 TTFT 显著降低:L40 上实现 2.28 倍加速,H800 上实现 1.3 倍加速(图 2),大幅提升实时交互体验。
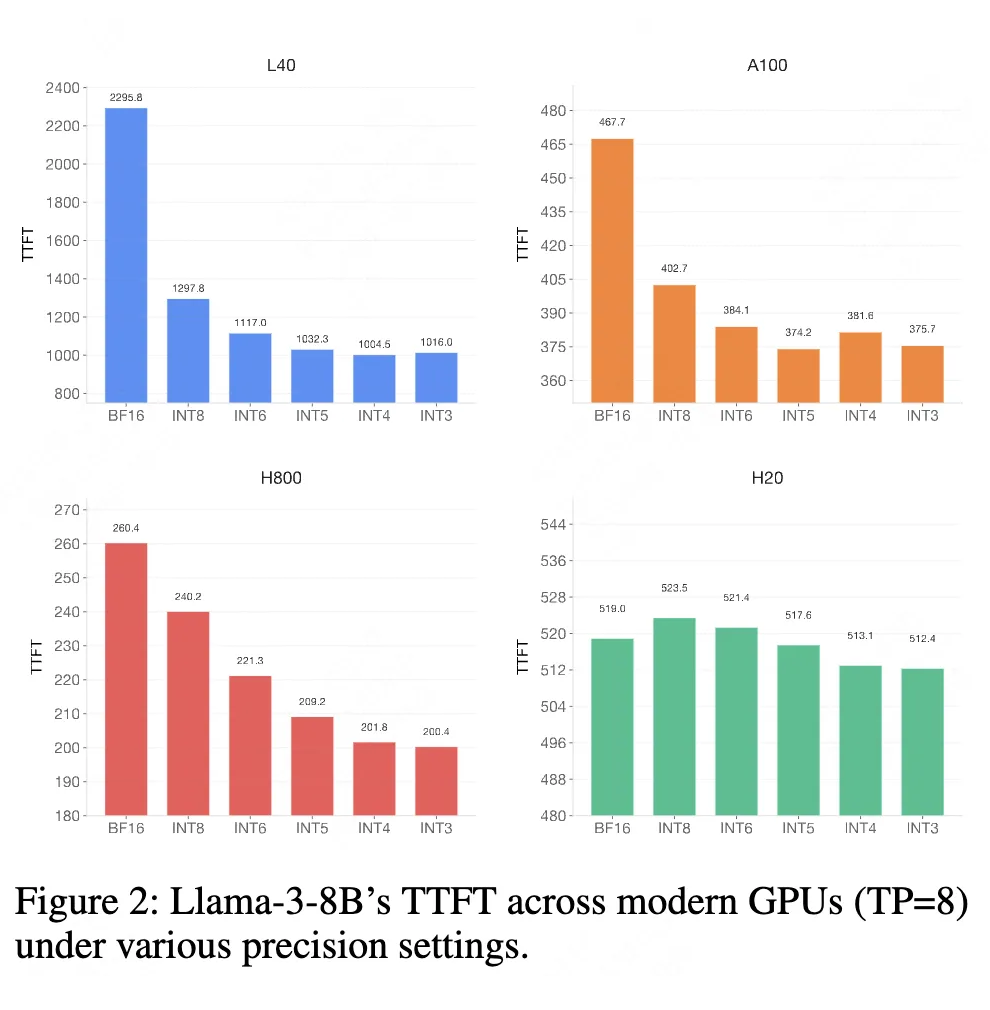
图2. 不同量化精度下 LLaMA-3-8B 的 TTFT 性能

意义与展望
FlashCommunication V2 的提出为大模型分布式系统带来了三大价值:
-
灵活性:支持任意比特宽度通信,使量化策略可根据模型特性(如对精度敏感的 MoE 专家通信)动态调整;
-
效率:在保持精度的前提下,将通信量减少 75% 以上,缓解带宽压力;
-
普适性:兼容 NVLink 和 PCIe 架构,适用于从低成本集群到高性能 GPU 服务器的各类场景。
未来方向包括:扩展至大规模 GPU 集群测试、探索硬件级支持(如集成尖峰保留专用单元)、结合动态量化策略进一步优化性能。

总结
FlashCommunication V2 通过比特分割与尖峰保留技术,突破了低比特通信的硬件限制和精度瓶颈,为万亿参数大模型的分布式训练与部署提供了高效解决方案。其核心价值在于平衡了“通信效率”与“模型精度”,使任意比特宽度的跨 GPU 传输从“不可能”变为“实用”,推动大模型向更高效、更经济的方向发展。
参考文献
1. FlashCommunication V1, https://arxiv.org/abs/2412.04964
2. ZeRO++, https://arxiv.org/abs/2306.10209
3. DeepSeekV3, https://arxiv.org/abs/2505.09343v1

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)