基于Hadoop的音乐推荐系统(源码+定制+开发)基于大数据的音乐推荐与用户行为分析系统 基于Hadoop和Spark的个性化音乐推荐系统开发 音乐推荐平台设计
【技术专家阿龙的多领域开发服务】博主阿龙是Java技术专家,拥有10W+粉丝,担任CSDN特邀作者、博客专家等职。擅长SpringBoot、Vue、Python等全栈技术,涵盖大数据、物联网等领域。提供毕业设计全流程服务:功能设计、论文辅导、代码实现、答辩指导等。采用B/S架构结合Python+MySQL技术栈,运用Django框架和协同过滤算法实现个性化推荐系统。展示爬虫代码实例,支持腾讯会议一
博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
目录:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!

2.1 Python语言
Python是一种高级编程语言,由Guido van Rossum于1989年创建。它的设计哲学强调代码的可读性和简洁性,使得Python成为了许多初学者和专业开发者的首选语言。Python支持多种编程范式,如面向对象编程、函数式编程和过程式编程。Python可以应用于各种领域[5],如Web开发、数据分析、人工智能、机器学习等。Python还具有良好的跨平台兼容性,可以在Windows、macOS和Linux系统上运行。总之,Python是一种功能强大、易于学习和使用的编程语言,适用于各种应用场景。
2.2 Django框架
协同过滤算法是一种广泛应用于推荐系统中的技术,通过分析用户行为数据或物品属性,挖掘用户偏好并实现个性化推荐。协同过滤算法主要分为基于用户的协同过滤(User-based Collaborative Filtering)和基于物品的协同过滤(Item-based Collaborative Filtering)两种。
基于用户的协同过滤通过计算用户之间的相似性,找到与目标用户兴趣相近的其他用户,根据这些用户的行为记录推荐可能感兴趣的内容。基于物品的协同过滤则关注物品之间的相似性,根据用户的历史行为,推荐与其喜爱物品类似的其他物品。
协同过滤算法无需依赖物品的具体内容,仅基于用户与物品的交互数据进行推荐,适用范围广泛。其应用领域包括电商平台的商品推荐、音乐和电影的个性化推荐等。然而,协同过滤算法在处理数据稀疏性、冷启动等问题时存在一定局限性,通常结合矩阵分解或深度学习技术进行优化。
协同过滤算法以其简单高效的特点,成为推荐系统的核心技术之一,在提升用户体验和平台粘性方面具有重要作用。
2.3 Mysql数据库
MySQL是Oracle公司旗下的一个开源的关系型数据库管理系统(Relational Database Management System, RDBMS)。 MySQL支持使用多线程,充分利用了CPU的计算资源,可以选择InnoDB, MyISAM和MEMORY等作为存储引擎[6],提供了丰富的数据库管理工具。在索引功能的加持下,其具有非常高的查询效率,并支持主从、多节点集群等高可用部署模式。MySQL凭借其低廉的成本、可靠的数据库服务和出色的性能,目前己经成为绝大多数企业在进行项目开发时的首选关系型数据库。
2.4 Mybatis技术简介
Mybatis是一种数据持久化的框架,内部封装了JDBC,能够对数据库基本的操作,能够对数据库中的数据进行查询操作。能够调用存储过程,从而进行在需要的时候进行调用,从而对其进行选择合适的调用获取所需要的信息,消除了参数的手工设置,Mybatis框架的重要作用是将大量SQL语句进行简化,能够在配置文件中进行配置,这样就可以把sql代码和程序分离开来。
2.5 协同过滤算法
协同过滤算法是一种常用于推荐系统的技术,通过分析用户行为数据,发现用户与用户之间或物品与物品之间的相似性,从而为用户推荐其可能感兴趣的内容[7]。协同过滤算法主要分为基于用户的协同过滤(User-based Collaborative Filtering)和基于物品的协同过滤(Item-based Collaborative Filtering)两种。
基于用户的协同过滤算法通过比较用户之间的行为相似度,找到与目标用户兴趣相近的其他用户,根据这些用户的行为记录向目标用户推荐内容。基于物品的协同过滤算法则关注物品之间的相似性,分析用户历史行为中出现的物品组合,向用户推荐与其历史行为中相关性高的物品。
协同过滤算法的核心优势在于无需了解物品的具体内容信息,而是仅依赖用户与物品的交互数据,这使其具备广泛的适用性。该算法在电商平台、音乐推荐、电影推荐等领域应用广泛,能够有效提升用户体验和平台活跃度[8]。然而,协同过滤算法也存在冷启动问题和数据稀疏性等挑战,需要结合其他方法(矩阵分解、深度学习)优化效果。
2.6 Vue.js技术简介
Vue是一种用于构建用户界面的渐进式JavaScript框架。它被设计为易于上手,灵活且轻量级,能够适应从小型项目到大型企业应用程序的需求。Vue的核心是一个响应式的数据绑定系统和一个组件系统。响应式数据绑定允许创建交互式的用户界面,而组件系统则使得代码组织和复用变得简单。Vue也提供了一套完整的前端开发工具,包括编译器、热重载、开发服务器等,以支持更高效的开发流程[9]。Vue的生态系统还包括Vuex(状态管理库)和Vue Router(路由管理器),这些工具可以帮助开发者构建复杂的单页应用程序。Vue是一个功能强大、易于使用且高效的前端框架,适用于各种规模的项目。
2.7 B/S架构
B/S架构(Browser/Server,浏览器/服务器)是一种广泛应用的系统架构模式,用户通过浏览器与服务器进行交互,实现操作与数据的传递和处理。该架构通过将客户端和服务器端分离,为现代互联网应用提供了更高的灵活性和易用性。相比传统的C/S架构(Client/Server),B/S架构具有显著的特点和优势。
B/S架构的客户端只需使用浏览器运行,无需安装额外的软件,具有良好的跨平台性,支持多种操作系统,如Windows、macOS、Linux、Android和iOS等,使用户可以通过多种设备访问系统,满足多样化的使用需求。此外,由于所有的业务逻辑和数据处理都集中在服务器端完成,客户端无需复杂安装和维护,这种集中式维护方式显著降低了系统维护成本,减少了因客户端问题导致的故障和管理压力。
安全性方面,B/S架构将数据统一存储在服务器端,避免了客户端数据分散可能引发的安全隐患。通过HTTPS协议、数据加密、用户身份验证和权限控制等机制,能够有效保障数据在传输和存储过程中的安全性。同时,集中化的管理模式使得管理员可以更加高效地实施安全策略和监控。
B/S架构的部署和更新十分简便,所有功能更新、版本迭代或问题修复均集中在服务器端完成,用户仅需刷新浏览器即可实时获取最新功能。这一优势显著提升了开发和维护效率,特别适合需要频繁迭代的系统。此外,B/S架构支持通过互联网进行远程访问,无论用户身处何地,只需具备网络连接,即可随时随地访问系统,极大提高了系统的灵活性,尤其在远程办公、在线教育和跨区域协作等场景中表现尤为突出。
B/S架构设计灵活,能够与现代技术如云计算、大数据、微服务架构等高效集成。系统可以通过负载均衡和集群部署的方式扩展性能,以应对高并发和大流量需求,同时支持多用户并发访问,适用于大规模应用场景。其应用范围涵盖企业管理系统(如ERP、CRM)、电子商务平台、在线教育平台、政府门户网站、医疗信息系统等领域,不仅优化了用户体验,还显著提升了开发和运营效率。
2.8 Hadoop技术介绍
Hadoop是一种开源的分布式数据存储和处理框架,由Apache基金会开发,用于处理大规模数据集(大数据)。Hadoop框架的核心组件包括HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算模型)。HDFS负责数据的分布式存储[10],提供高容错性和高吞吐量;MapReduce则通过分布式任务调度和并行计算,实现对海量数据的高效处理。
Hadoop还包括其他组件,如YARN(Yet Another Resource Negotiator),用于资源调度和任务管理,以及丰富的生态系统(Hive、HBase、Spark等),为用户提供多样化的大数据处理工具。Hadoop具有高扩展性和灵活性,支持在低成本硬件上部署,为企业大数据存储和分析提供了经济高效的解决方案。
凭借其可靠性、可扩展性和灵活性,Hadoop被广泛应用于各类大数据场景,包括日志分析、数据仓库、机器学习和推荐系统等领域,成为企业处理大数据的首选技术之一。
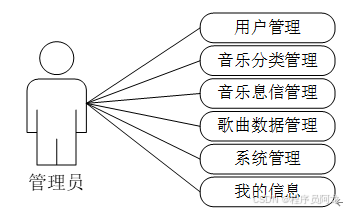
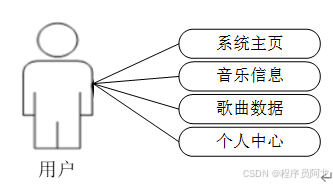
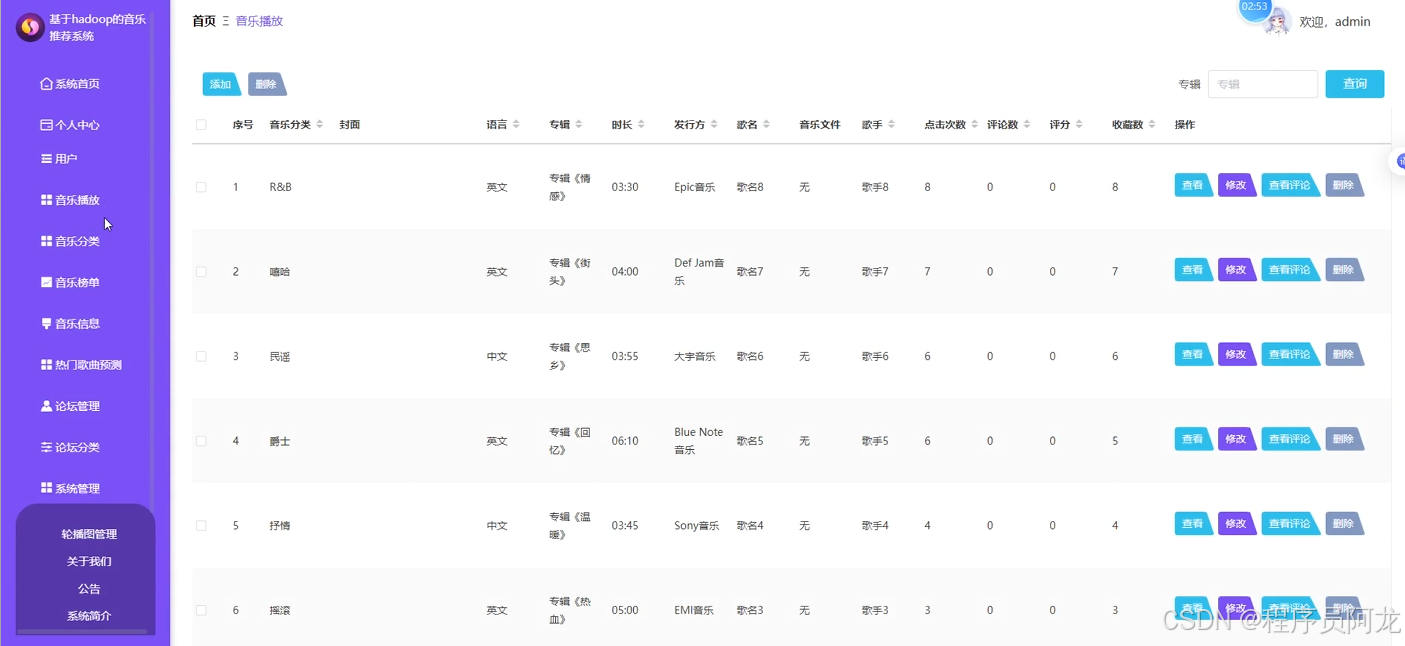
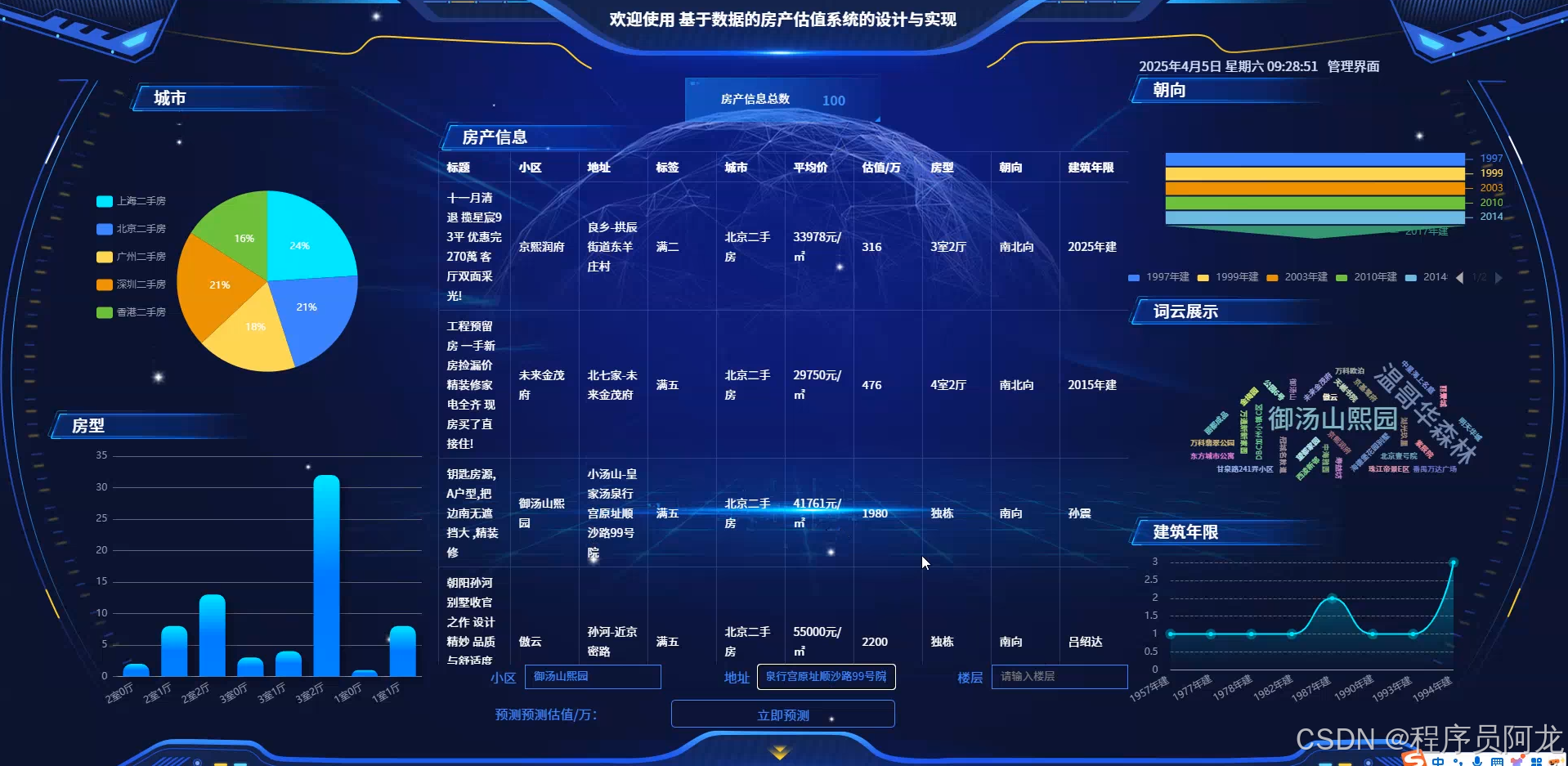
 系统实现界面展示:
系统实现界面展示:
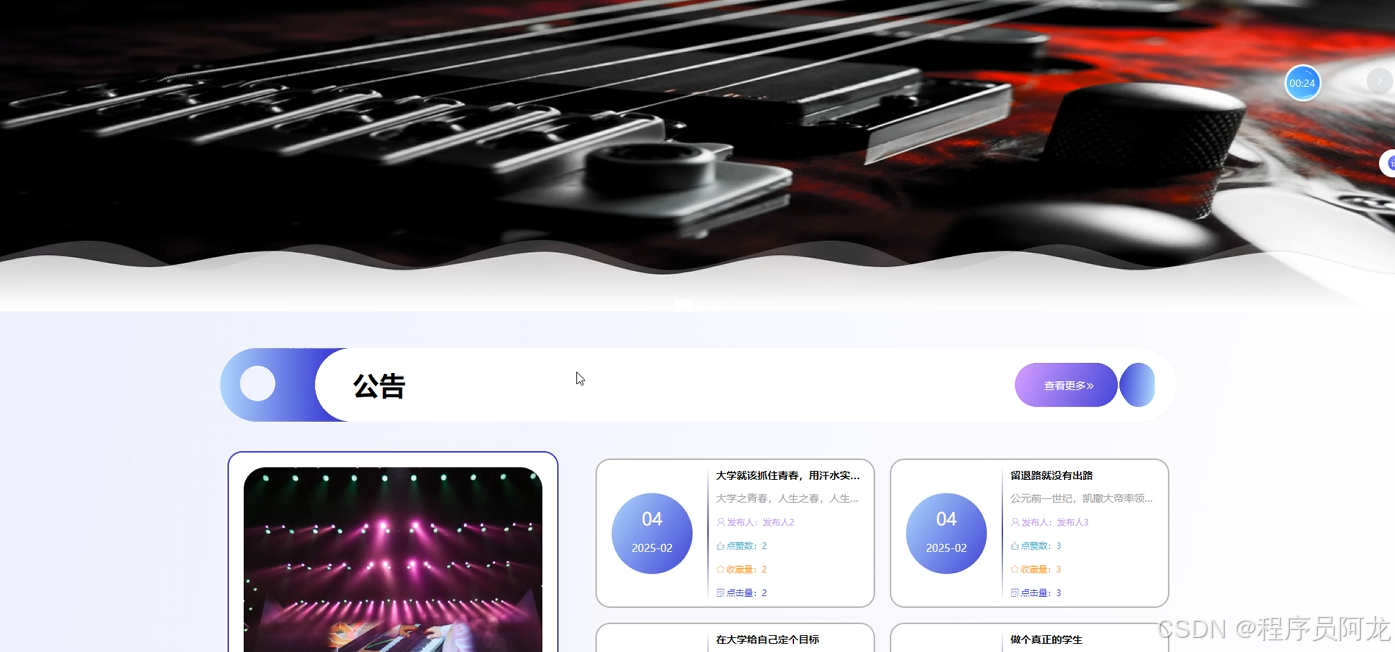
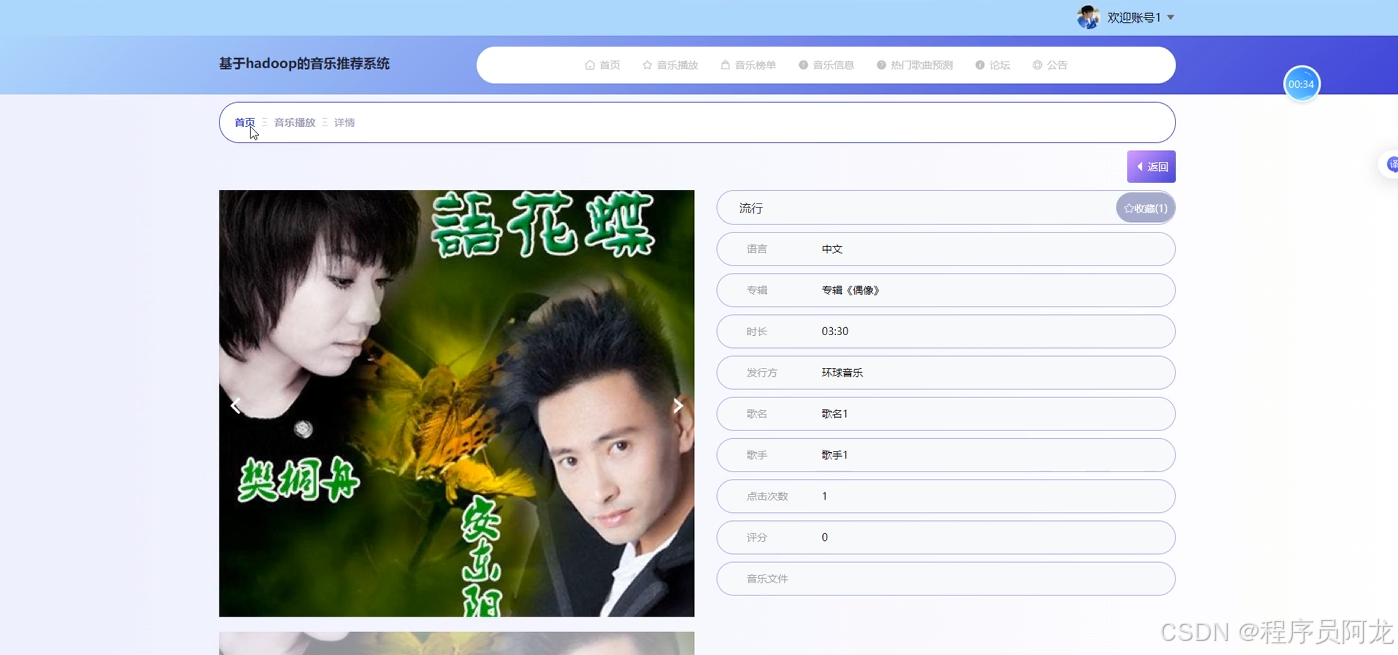

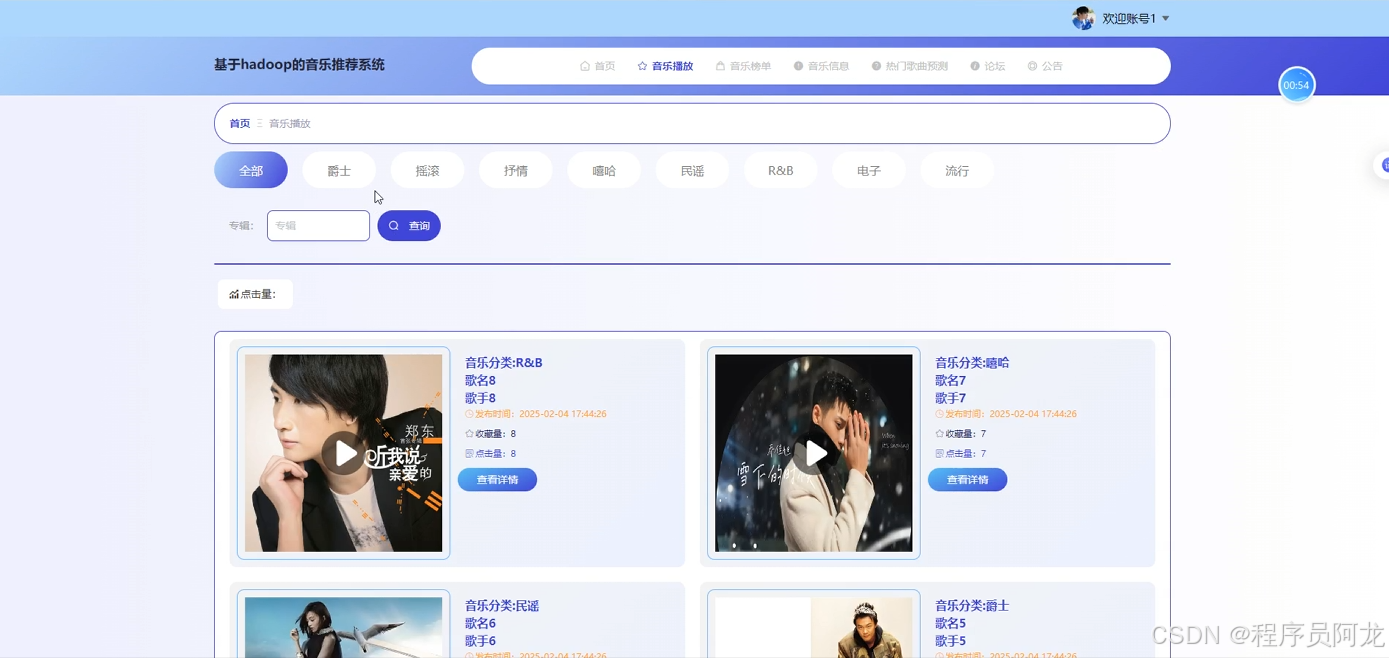
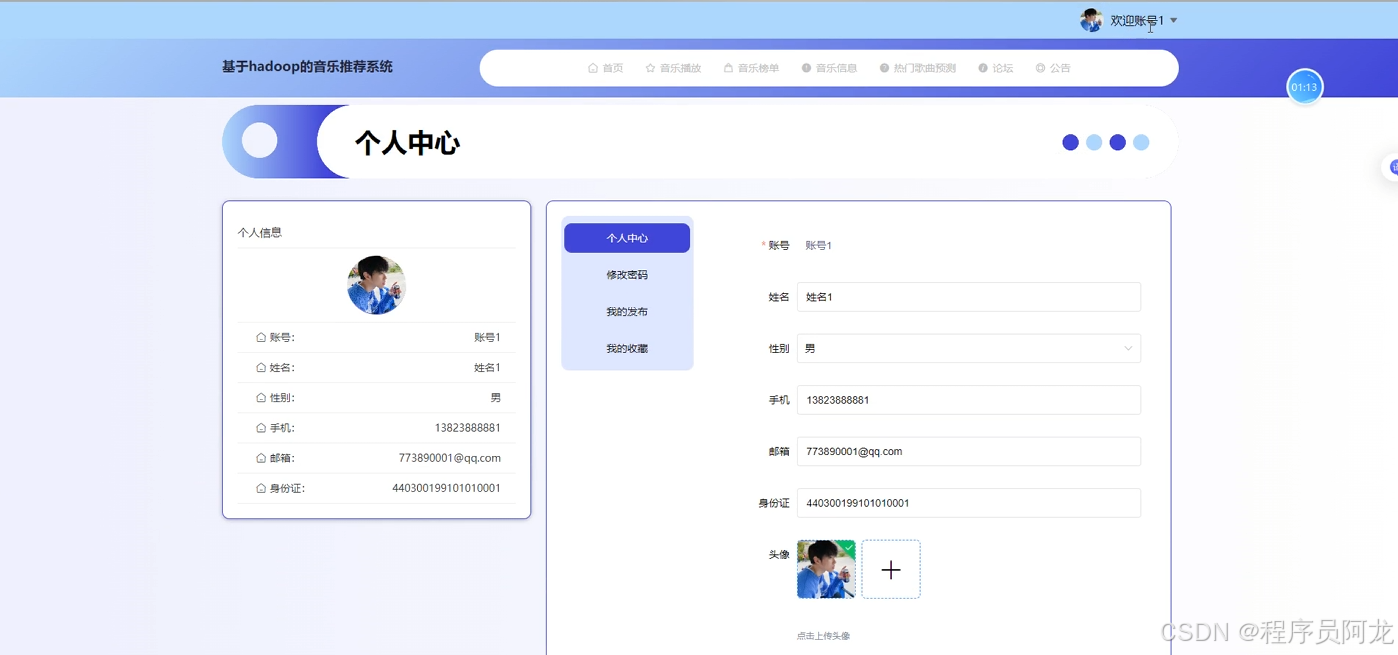
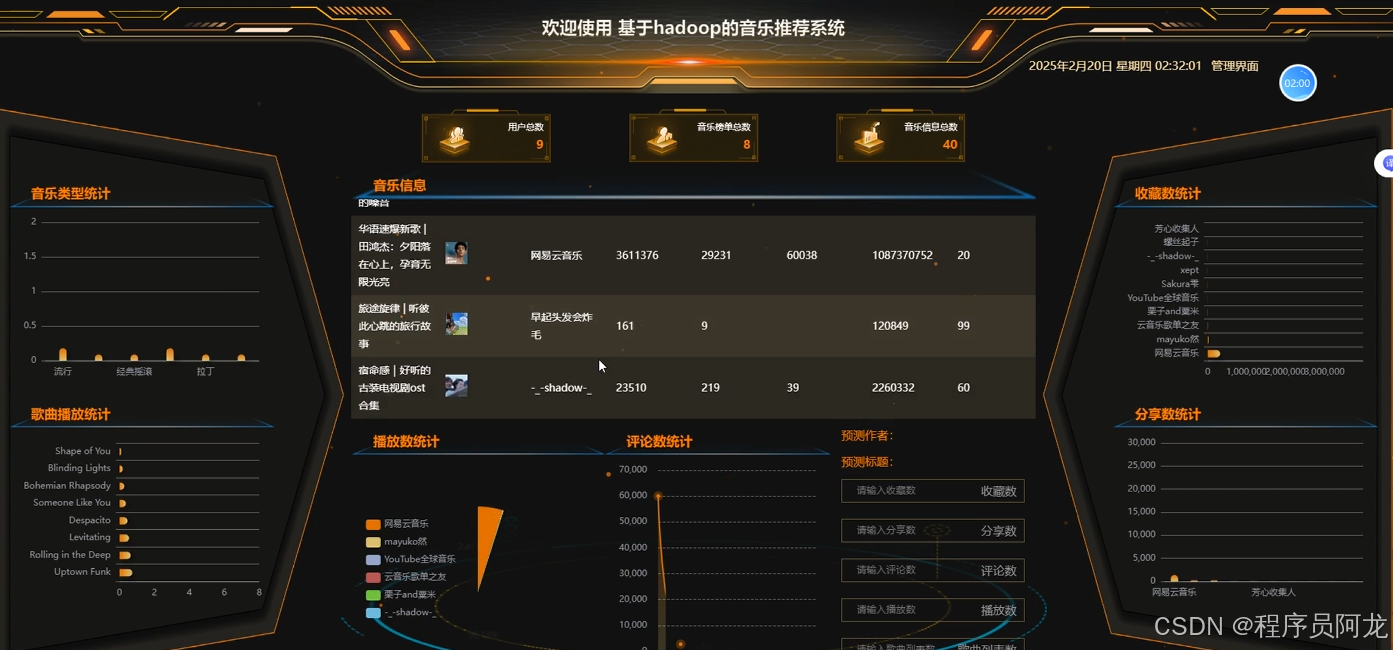
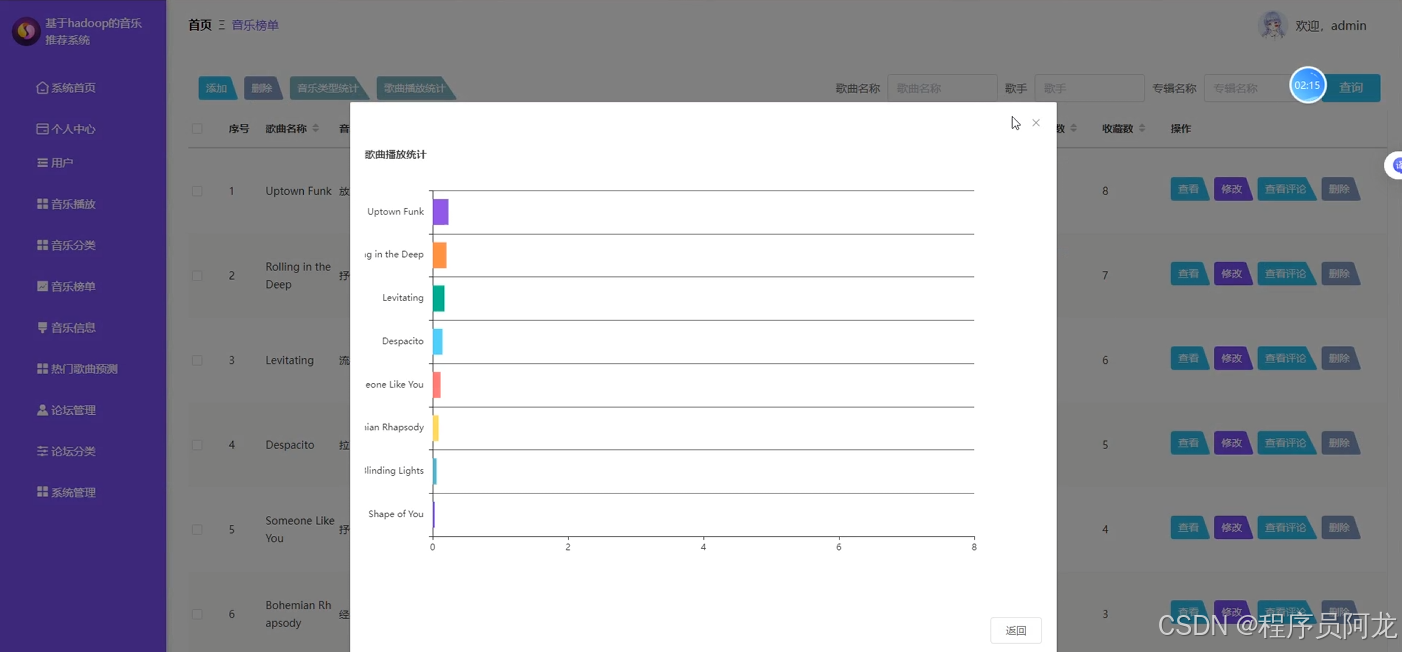
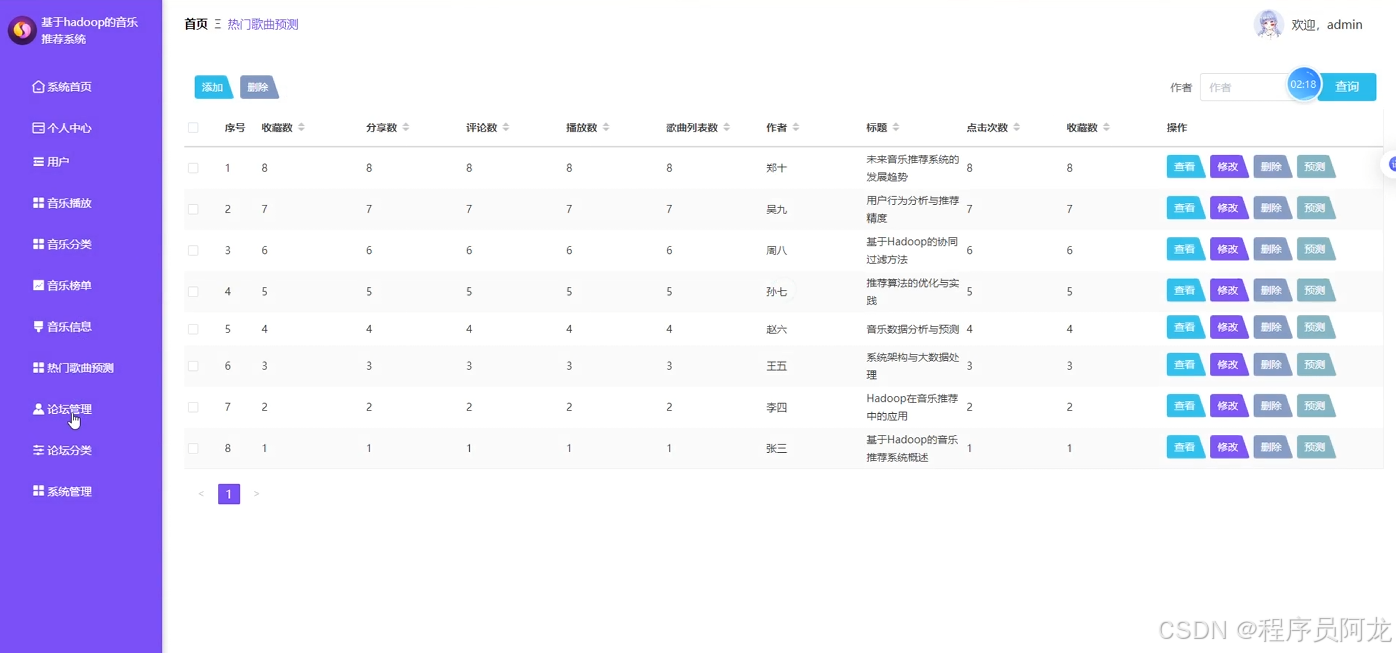

爬虫代码分析:
# 古典歌单
class ClassicalplaylistSpider(scrapy.Spider):
name = 'classicalplaylistSpider'
spiderUrl = 'https://music.163.com/discover/playlist/?order=hot&cat=%E5%8F%A4%E5%85%B8&limit=35&offset={}'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
headers = {
"cookie":"输入自己的cookie"
}
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'q90k0geu_classicalplaylist') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
headers=self.headers,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
headers=self.headers,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'q90k0geu_classicalplaylist') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('ul.m-cvrlst.f-cb li')
for item in list:
fields = ClassicalplaylistItem()
if '(.*?)' in '''p.dec a::text''':
try:
fields["msk"] = str( re.findall(r'''p.dec a::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["msk"] = str( self.remove_html(item.css('''p.dec a::text''').extract_first()))
except:
pass
if '(.*?)' in '''img.j-flag::attr(src)''':
try:
fields["cover"] = str( re.findall(r'''img.j-flag::attr(src)''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["cover"] = str( self.remove_html(item.css('''img.j-flag::attr(src)''').extract_first()))
except:
pass
if '(.*?)' in '''div.u-cover.u-cover-1 div.bottom span.nb::text''':
try:
fields["playcount"] = int( re.findall(r'''div.u-cover.u-cover-1 div.bottom span.nb::text''', item.extract(), re.DOTALL)[0].strip().replace("万","0000"))
except:
pass
else:
try:
fields["playcount"] = int( self.remove_html(item.css('div.u-cover.u-cover-1 div.bottom span.nb::text').extract_first()).replace("万","0000"))
except:
pass
if '(.*?)' in '''a.nm.nm-icn.f-thide.s-fc3::text''':
try:
fields["author"] = str( re.findall(r'''a.nm.nm-icn.f-thide.s-fc3::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["author"] = str( self.remove_html(item.css('''a.nm.nm-icn.f-thide.s-fc3::text''').extract_first()))
except:
pass
if '(.*?)' in '''div.u-cover.u-cover-1 a.msk::attr(href)''':
try:
fields["laiyuan"] = str("https://music.163.com"+ re.findall(r'''div.u-cover.u-cover-1 a.msk::attr(href)''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["laiyuan"] = str("https://music.163.com"+ self.remove_html(item.css('''div.u-cover.u-cover-1 a.msk::attr(href)''').extract_first()))
except:
pass
if fields["laiyuan"].startswith('//'):
fields["laiyuan"] = self.protocol + ':' + fields["laiyuan"]
elif fields["laiyuan"].startswith('/'):
fields["laiyuan"] = self.protocol + '://' + self.hostname + fields["laiyuan"]
elif fields["laiyuan"].startswith('http'):
pass
else:
fields["laiyuan"] = self.protocol + '://' + self.hostname + '/' + fields["laiyuan"]
detailUrlRule = item.css('div.u-cover.u-cover-1 a.msk::attr(href)').extract_first()
detailUrlRule ="https://music.163.com"+ detailUrlRule
if self.protocol in detailUrlRule or detailUrlRule.startswith('http'):
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
elif detailUrlRule.startswith('/'):
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + '/' + detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, headers=self.headers, callback=self.detail_parse, dont_filter=True)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''a.u-btni.u-btni-fav i::text''':
fields["collectioncount"] = int( re.findall(r'''a.u-btni.u-btni-fav i::text''', response.text, re.S)[0].strip().replace("(","").replace(")",""))
else:
if 'collectioncount' != 'xiangqing' and 'collectioncount' != 'detail' and 'collectioncount' != 'pinglun' and 'collectioncount' != 'zuofa':
fields["collectioncount"] = int( self.remove_html(response.css('''a.u-btni.u-btni-fav i::text''').extract_first()).replace("(","").replace(")",""))
else:
try:
fields["collectioncount"] = int( emoji.demojize(response.css('''a.u-btni.u-btni-fav i::text''').extract_first()).replace("(","").replace(")",""))
except:
pass
except:
pass
try:
if '(.*?)' in '''a.u-btni.u-btni-share i::text''':
fields["sharecount"] = int( re.findall(r'''a.u-btni.u-btni-share i::text''', response.text, re.S)[0].strip().replace("(","").replace(")",""))
else:
if 'sharecount' != 'xiangqing' and 'sharecount' != 'detail' and 'sharecount' != 'pinglun' and 'sharecount' != 'zuofa':
fields["sharecount"] = int( self.remove_html(response.css('''a.u-btni.u-btni-share i::text''').extract_first()).replace("(","").replace(")",""))
else:
try:
fields["sharecount"] = int( emoji.demojize(response.css('''a.u-btni.u-btni-share i::text''').extract_first()).replace("(","").replace(")",""))
except:
pass
except:
pass
try:
if '(.*?)' in '''a.u-btni.u-btni-cmmt span#cnt_comment_count::text''':
fields["commentcount"] = int( re.findall(r'''a.u-btni.u-btni-cmmt span#cnt_comment_count::text''', response.text, re.S)[0].strip())
else:
if 'commentcount' != 'xiangqing' and 'commentcount' != 'detail' and 'commentcount' != 'pinglun' and 'commentcount' != 'zuofa':
fields["commentcount"] = int( self.remove_html(response.css('''a.u-btni.u-btni-cmmt span#cnt_comment_count::text''').extract_first()))
else:
try:
fields["commentcount"] = int( emoji.demojize(response.css('''a.u-btni.u-btni-cmmt span#cnt_comment_count::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''span#playlist-track-count::text''':
fields["songcount"] = int( re.findall(r'''span#playlist-track-count::text''', response.text, re.S)[0].strip())
else:
if 'songcount' != 'xiangqing' and 'songcount' != 'detail' and 'songcount' != 'pinglun' and 'songcount' != 'zuofa':
fields["songcount"] = int( self.remove_html(response.css('''span#playlist-track-count::text''').extract_first()))
else:
try:
fields["songcount"] = int( emoji.demojize(response.css('''span#playlist-track-count::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''div#song-list-pre-cache ul.f-hide li a::text''':
fields["songname"] = str( re.findall(r'''div#song-list-pre-cache ul.f-hide li a::text''', response.text, re.S)[0].strip())
else:
fields["songname"] = ';'.join(response.css('''div#song-list-pre-cache ul.f-hide li a::text''').extract())
except:from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 粉丝信息
class FensixinxiSpider(scrapy.Spider):
name = 'fensixinxiSpider'
spiderUrl = 'https://music.163.com/#/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset={}'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'q90k0geu_fensixinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'q90k0geu_fensixinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('ul#m-pl-container > li')
for item in list:
fields = FensixinxiItem()
if '(.*?)' in '''a[class="tit f-thide s-fc0"]::text''':
try:
fields["name"] = str( re.findall(r'''a[class="tit f-thide s-fc0"]::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["name"] = str( self.remove_html(item.css('''a[class="tit f-thide s-fc0"]::text''').extract_first()))
except:
pass
detailUrlRule = item.css('a[class="tit f-thide s-fc0"]::attr(href)').extract_first()
detailUrlRule ='https://music.163.com'+ detailUrlRule
if self.protocol in detailUrlRule or detailUrlRule.startswith('http'):
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
elif detailUrlRule.startswith('/'):
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + '/' + detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse, dont_filter=True)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''a.f-tdn::attr(href)''':
fields["fsdz"] = str('https://music.163.com/#'+ re.findall(r'''a.f-tdn::attr(href)''', response.text, re.S)[0].strip())
else:
if 'fsdz' != 'xiangqing' and 'fsdz' != 'detail' and 'fsdz' != 'pinglun' and 'fsdz' != 'zuofa':
fields["fsdz"] = str('https://music.163.com/#'+ self.remove_html(response.css('''a.f-tdn::attr(href)''').extract_first()))
else:
try:
fields["fsdz"] = str('https://music.163.com/#'+ emoji.demojize(response.css('''a.f-tdn::attr(href)''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''a.f-tdn::attr(title)''':
fields["fsmc"] = str( re.findall(r'''a.f-tdn::attr(title)''', response.text, re.S)[0].strip())
else:
if 'fsmc' != 'xiangqing' and 'fsmc' != 'detail' and 'fsmc' != 'pinglun' and 'fsmc' != 'zuofa':
fields["fsmc"] = str( self.remove_ht
(1)用户登陆测试用例
表 6-1 用户登录用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
||||
|
功能模块名 |
用户登陆模块 |
用例编号 |
xxxx |
|||
|
功能特性 |
用户身份验证 |
|||||
|
测试目的 |
验证是否输入合法的信息,允许合法登陆,阻止非法登陆 |
|||||
|
测试数据 |
用户名=1密码=a1身份= 非认证用户 |
|||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
状态 |
|
|
1 |
输入用户名和密码 |
用户名= 1密码=1 |
显示进入后的页面。 |
同期望结果。 |
正常 |
|
|
2 |
输入用户名和密码 |
用户名= 1密码=aaa |
显示警告信息“不存在该用户名或密码错误!” |
同期望结果。 |
正常 |
|
|
3 |
输入用户名和密码 |
用户名= aaa密码=1 |
显示警告信息“不存在该用户名或密码错误” |
同期望结果。 |
正常 |
|
|
4 |
输入用户名和密码 |
用户名=“” 密码=“” |
显示警告信息“用户名密码不能为空!” |
同期望结果。 |
正常 |
|
(2)用户注册测试用例
表 6-2 用户注册用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
|||||
|
功能模块名 |
用户注册模块 |
用例编号 |
xxxx |
||||
|
功能特性 |
用户注册 |
||||||
|
测试目的 |
验证私注册是否成功,注册数据是否合法 |
||||||
|
测试数据 |
用户名=aaa 密码=aaa电子邮件=dwa@qq.com |
||||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
测试状态 |
||
|
1 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:注册成功!转入用户主页 |
同期望结果。 |
正常 |
||
|
2 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:用户名已注册 |
同期望结果。 |
正常 |
||
|
3 |
输入注册数据 |
用户名= aaa密码=”” 电子邮件=dwa@qq.com |
提示:密码不能为空 |
同期望结果。 |
正常 |
||
|
4 |
输入注册数据 |
密码=aaa 电子邮件=dwa@qq.com |
提示:用户名为空 |
同期望结果。 |
正常 |
||



 论文部分参考:
论文部分参考:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
我是程序员阿龙,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是CSDN特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。
已经为上百名同学获得优秀毕业生!
源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)