LLM已能自我更新权重,自适应、知识整合能力大幅提升,AI醒了?
自适应语言模型(SEAL)SEAL 框架可以让语言模型在遇到新数据时,通过生成自己的合成数据并优化参数(自编辑),进而实现自我提升。该模型的训练目标是:可以使用模型上下文中提供的数据,通过生成 token 来直接生成这些自编辑(SE)。
前言
前些天,OpenAI CEO、著名 𝕏 大 v 山姆・奥特曼在其博客《温和的奇点(The Gentle Singularity)》中更是畅想了一个 AI/智能机器人实现自我改进后的未来。他写道:「我们必须以传统的方式制造出第一批百万数量级的人形机器人,但之后它们能够操作整个供应链来制造更多机器人,而这些机器人又可以建造更多的芯片制造设施、数据中心等等。」
不久之后,就有 𝕏 用户 @VraserX 爆料称有 OpenAI 内部人士表示,该公司已经在内部运行能够递归式自我改进的 AI。这条推文引起了广泛的讨论 —— 有人表示这不足为奇,也有人质疑这个所谓的「OpenAI 内部人士」究竟是否真实。

https://x.com/VraserX/status/1932842095359737921
但不管怎样,AI 也确实正向实现自我进化这条路前进。
MIT 昨日发布的《Self-Adapting Language Models》就是最新的例证之一,其中提出了一种可让 LLM 更新自己的权重的方法:SEAL🦭,即 Self-Adapting LLMs。在该框架中,LLM 可以生成自己的训练数据(自编辑 /self-editing),并根据新输入对权重进行更新。而这个自编辑可通过强化学习学习实现,使用的奖励是更新后的模型的下游性能。

- 论文标题:Self-Adapting Language Models
- 论文地址:https://arxiv.org/pdf/2506.10943
- 项目页面:https://jyopari.github.io/posts/seal
- 代码地址:https://github.com/Continual-Intelligence/SEAL
这篇论文发布后引发了广泛热议。在 Hacker News 上,有用户评论说,这种自编辑方法非常巧妙,但还不能说就已经实现了能「持续自我改进的智能体」。

论文一作 Adam Zweiger 也在 𝕏 上给出了类似的解释:
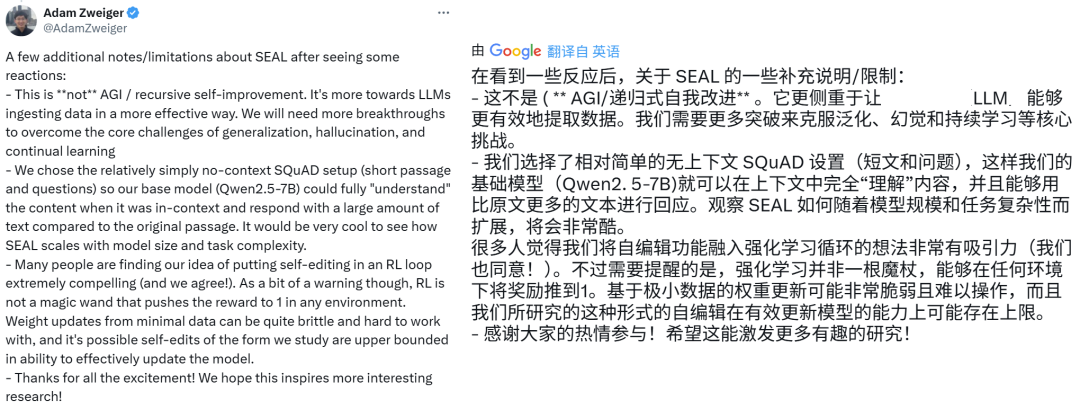
也有人表示,这表明我们正在接近所谓的事件视界(event horizon)—— 这个概念其实也出现在了山姆・奥特曼《温和的奇点》博客的第一句话,不过奥特曼更激进一点,他的说法是「我们已经越过了事件视界」。简单来说,event horizon(事件视界)指的是一个不可逆转的临界点,一旦越过,人类将不可避免地迈入某种深刻变革的阶段,比如通向超级智能的道路。
当然,也有人对自我提升式 AI 充满了警惕和担忧。

下面就来看看这篇热门研究论文究竟得到了什么成果。
自适应语言模型(SEAL)
SEAL 框架可以让语言模型在遇到新数据时,通过生成自己的合成数据并优化参数(自编辑),进而实现自我提升。
该模型的训练目标是:可以使用模型上下文中提供的数据,通过生成 token 来直接生成这些自编辑(SE)。
自编辑生成需要通过强化学习来学习实现,其中当模型生成的自编辑在应用后可以提升模型在目标任务上的性能时,就会给予模型奖励。
因此,可以将 SEAL 理解为一个包含两个嵌套循环的算法:一个外部 RL 循环,用于优化自编辑生成;以及一个内部更新循环,它使用生成的自编辑通过梯度下降更新模型。

该方法可被视为元学习的一个实例,即研究的是如何以元学习方式生成有效的自编辑。
通用框架
令 θ 表示语言模型 LM_θ 的参数。 SEAL 是在单个任务实例 (C, τ) 上运作,其中 C 是包含与任务相关信息的上下文,τ 定义了用于评估模型适应度(adaptation)的下游评估。
比如,在知识整合任务中,C 是旨在整合到模型内部知识中的段落,τ 是关于该段落的一组问题及其相关答案。而在少样本学习任务中,C 包含某个新任务的少样本演示,τ 是查询输入和 ground-truth 输出。
给定 C,模型会生成一个自编辑 SE(其形式因领域而异),并通过监督微调更新自己的参数:θ′ ← SFT (θ, SE)。
该团队使用了强化学习来优化自编辑的生成过程:模型执行一个动作(生成 SE),再根据 LM_θ′ 在 τ 上的表现获得奖励 r,并更新其策略以最大化预期奖励:
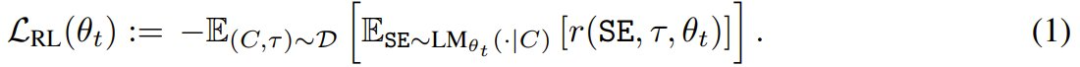
不过,与标准强化学习设置不同,在这里的设置中,分配给给定动作的奖励取决于执行动作时的模型参数 θ(因为 θ 会更新为 θ′,然后再被评估)。
如此一来,底层的强化学习状态必定会包含策略的参数,并由 (C, θ) 给出,即使策略的观测值仅限于 C(将 θ 直接置于上下文中是不可行的)。
这意味着,使用先前版本模型 θ_old 收集的 (state, action, reward) 三元组可能会过时,并且与当前模型 θ_current 不一致。因此,该团队采用一种基于策略的方法,其中会从当前模型中采样自编辑 SE,并且至关重要的是,奖励也会使用当前模型进行计算。
该团队尝试了各种在线策略方法,例如组相对策略优化 (GRPO) 和近端策略优化 (PPO) ,但发现训练不稳定。
最终,他们选择了来自 DeepMind 论文《Beyond human data: Scaling self-training for problem-solving with language models.》的 ReST^EM,这是一种基于已过滤行为克隆的更简单的方法 —— 也就是「拒绝采样 + SFT」。
ReST^EM 可以被视为一个期望最大化 (EM) 过程:E-step 是从当前模型策略采样候选输出,M-step 是通过监督微调仅强化那些获得正奖励的样本。这种方法可在以下二元奖励下优化目标 (1) 的近似:

更准确地说,在优化 (1) 时,必须计算梯度 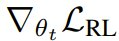 。然而,在这里的设置中,奖励项 r (SE, τ, θ_t) 取决于 θ_t,但不可微分。为了解决这个问题,该团队的做法是将奖励视为相对于 θ_t 固定。通过这种近似,对于包含 N 个上下文和每个上下文 M 个采样得到自编辑的小批量,其蒙特卡洛估计器变为:
。然而,在这里的设置中,奖励项 r (SE, τ, θ_t) 取决于 θ_t,但不可微分。为了解决这个问题,该团队的做法是将奖励视为相对于 θ_t 固定。通过这种近似,对于包含 N 个上下文和每个上下文 M 个采样得到自编辑的小批量,其蒙特卡洛估计器变为:
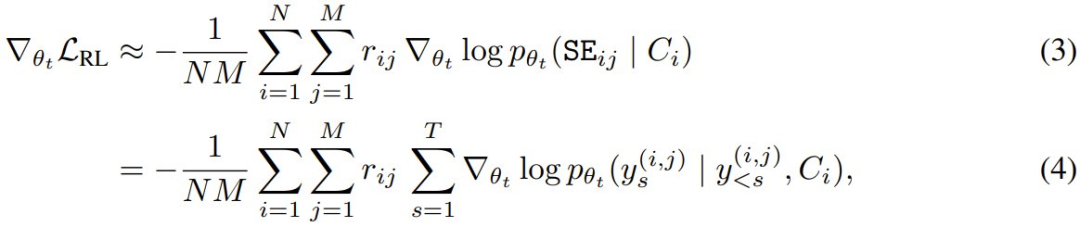
其中 p_θ_t 表示模型的自回归分布,y_s^(i,j) 是自编辑 SE_ij 的第 s 个 token,即上下文 C_i 的第 j 个样本。由于在 (4) 中可以忽略 r = 0 的序列,该团队研究表明:在二元奖励 (2) 下(对奖励项应用停止梯度),ReST^EM 只需使用简单的「在好的自编辑上进行 SFT」,就能优化 (1)。算法 1 给出了 SEAL 的训练循环。

最后,他们还注意到,虽然本文的实现是使用单个模型来生成自编辑并从这些自编辑中学习,但也可以将这些角色分离。在这样一种「教师-学生」形式中,学生模型将使用由另一个教师模型提出的编辑进行更新。然后,教师模型将通过强化学习进行训练,以生成能够最大程度提高学生学习效果的编辑。
针对具体领域实例化 SEAL
理论有了,该团队也打造了 SEAL 的实例。具体来说,他们选择了两个领域:知识整合和少样本学习。
其中,知识整合的目标是有效地将文章中提供的信息整合到模型的权重中。下图展示了相关设置。

而下图则给出了少样本学习的设置。
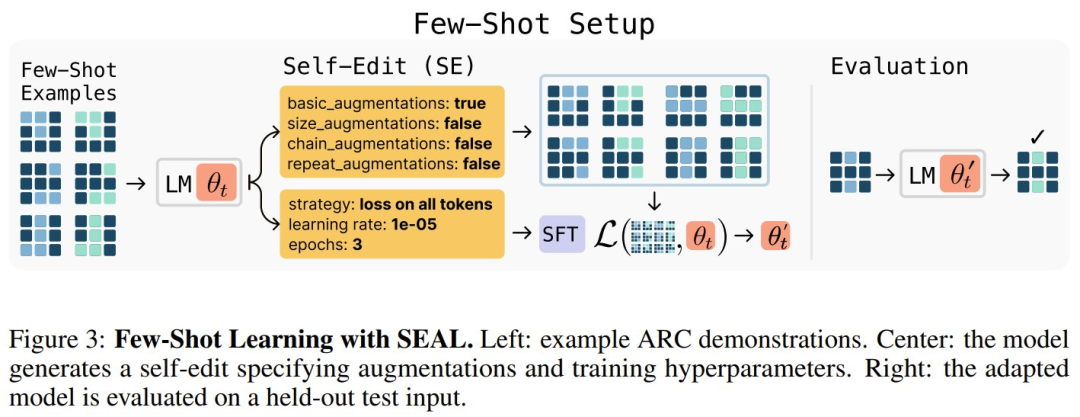
对这两种实例化的更详细描述请访问原论文,下面来看看 SEAL 的实际表现。
实验结果
少样本学习
实验所用的模型是 Llama-3.2-1B-Instruct,基准为 ARC。参与对比的方法包括 ICL(上下文学习)、TTT + 自编辑(无强化学习)、Oracle TTT。结果见下表。

可以看到,与基线相比,SEAL 显著提高了适应成功率:72.5% vs. 20%(使用基础模型的自编辑但未进行强化学习训练)和 0%(无适应),但性能仍低于 Oracle TTT,表明新方法仍有进一步改进的空间。
知识整合
知识整合则使用了更大一些的 Qwen2.5-7B,目标是整合 SQuAD 文章中的新事实内容。这里对比的方法包括基础模型、仅在文章上训练的模型、在文章 + 合成数据训练的模型、在文章 + GPT-4.1 合成数据上训练的模型。结果见下表。
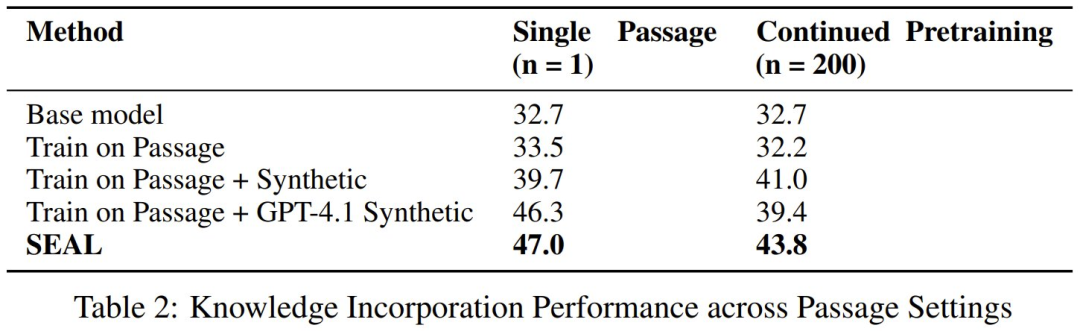
可以看到,在单篇文章(n = 1)和持续预训练(n = 200)这两种情况下,SEAL 方法的准确度表现都超过了基准。
首先使用基础 Qwen-2.5-7B 模型生成的合成数据训练后,模型的表现已经能获得明显提升,从 32.7% 分别提升到了 39.7% 和 41.0%,之后再进行强化学习,性能还能进一步提升(47.0% 和 43.8%)。
图 4 展现了每次外部强化学习迭代后的准确度。
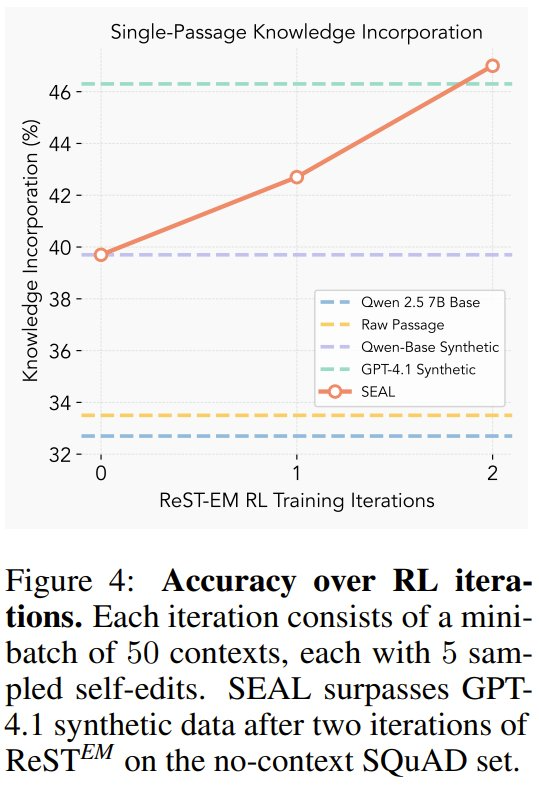
可以看到,两次迭代足以使 SEAL 超越使用 GPT-4.1 数据的设置;后续迭代的收益会下降,这表明该策略快速收敛到一种将段落蒸馏为易于学习的原子事实的编辑形式(参见图 5 中的定性示例)。

在这个例子中,可以看到强化学习如何导致生成更详细的自编辑,从而带来更佳的性能。虽然在这个例子中,进展很明显,但在其他例子中,迭代之间的差异有时会更为细微。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献381条内容
已为社区贡献381条内容

所有评论(0)