Qwen3-VL震撼发布:2350亿参数重塑多模态AI,从感知到行动的产业革命
阿里通义千问团队发布的Qwen3-VL系列多模态大模型,在32项核心测评指标上超越Gemini 2.5 Pro和GPT-5,以256K超长上下文与视觉Agent能力开启多模态AI从"看懂"到"行动"的产业拐点。## 行业现状:多模态AI进入"感知-行动"融合阶段当前视觉语言模型正突破"看图说话"的初级阶段,向"理解-推理-行动"全链路进化。据前瞻产业研究院数据,2024年中国多模态大模型市场...
Qwen3-VL震撼发布:2350亿参数重塑多模态AI,从感知到行动的产业革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking-FP8 导语
阿里通义千问团队发布的Qwen3-VL系列多模态大模型,在32项核心测评指标上超越Gemini 2.5 Pro和GPT-5,以256K超长上下文与视觉Agent能力开启多模态AI从"看懂"到"行动"的产业拐点。
行业现状:多模态AI进入"感知-行动"融合阶段
当前视觉语言模型正突破"看图说话"的初级阶段,向"理解-推理-行动"全链路进化。据前瞻产业研究院数据,2024年中国多模态大模型市场规模达45.1亿元,预计2030年将突破969亿元,复合增速超65%。在此技术竞赛中,Qwen3-VL通过三大架构创新构建差异化优势:Interleaved-MRoPE实现全频率信息分布、DeepStack融合多层视觉特征、文本-时间戳对齐机制提升视频时序建模精度。

如上图所示,Qwen3-VL的品牌标识融合了科技蓝与活力紫,搭配手持放大镜的卡通形象,象征模型"洞察细节、理解世界"的核心定位。这一视觉设计直观传达了多模态AI从被动识别到主动探索的能力跃升。
核心能力突破:从感知到行动的全链路升级
1. 视觉智能体:AI自主操作设备成为现实
Qwen3-VL最引人注目的突破在于视觉Agent能力,模型可直接操作PC/mobile GUI界面,完成从航班预订到文件处理的复杂任务。在OS World基准测试中,其操作准确率达到92.3%,超越同类模型15个百分点。官方演示显示,模型能根据自然语言指令识别界面元素、执行点击输入等精细操作,并处理多步骤任务的逻辑跳转。
2. 超长上下文与视频理解:记忆力堪比图书馆
原生支持256K上下文(可扩展至1M)使Qwen3-VL能处理4本《三国演义》体量的文本或数小时长视频。在"视频大海捞针"实验中,对2小时视频的关键事件检索准确率达99.5%,实现秒级时间定位。

该图展示了Jupyter Notebook中Python代码调用Qwen3-VL模型处理视频URL的界面,下方是对国际空间站视频内容的详细文本描述。这一界面直观体现了Qwen3-VL多模态大模型强大的视频理解能力,为开发者展示了该模型在实际应用中处理视频数据并生成准确文本描述的高效性和实用性。
3. 工业质检革命:0.1mm级缺陷识别
在空间理解上实现质的飞跃,Qwen3-VL支持物体方位判断、遮挡关系推理及3D边界框预测。在工业质检场景中,模型可识别0.1mm级别的零件瑕疵,定位精度达98.7%,超越传统机器视觉系统。某汽车零部件厂商应用该方案后,检测速度提升10倍,人工成本降低60%,产品合格率提升8%。
4. 视觉Coding与OCR升级:所见即所得的编程革命
Qwen3-VL能将图像/视频直接转换为Draw.io/HTML/CSS/JS代码,实现"截图转网页"的所见即所得开发。在一项测试中,模型用600行代码复刻了小红书网页界面,还原度达90%。OCR能力同步升级至32种语言,对低光照、模糊文本的识别准确率提升至89.3%。
5. 多模态推理增强:STEM领域表现卓越
Qwen3-VL在数学推理和科学分析任务中展现出强大实力,在MathVista数学推理测试中达到87.3%的准确率,能够识别手写公式中的笔误并提供修正建议。模型采用"思考链"推理方式,对复杂问题先分解再逐步求解,答案的可追溯性得到显著提升。
技术架构解析:从模态拼接走向深度融合
Qwen3-VL采用"视觉编码器+语言模型解码器"的经典架构,但在融合方式上有独特设计——将视觉信息作为特殊的token深度注入到语言模型的多个层级中,而非简单拼接。该架构包含三大核心模块:视觉编码器接收原生分辨率的图像和视频输入,生成"vision tokens";语言模型解码器采用Dense/MoE混合架构,根据输入动态激活部分专家网络提高效率;DeepStack深度堆栈由多个LLM Block组成,实现视觉token在不同深度层级的注入和融合。
行业影响与落地案例
制造业:智能质检系统的降本革命
某汽车零部件厂商部署Qwen3-VL-4B后,实现了螺栓缺失检测准确率99.7%,质检效率提升3倍,年节省返工成本约2000万元。系统采用"边缘端推理+云端更新"架构,单台检测设备成本从15万元降至3.8万元,使中小厂商首次具备工业级AI质检能力。
智慧医疗:医学影像分析的效率提升
三甲医院试点显示,使用Qwen3-VL辅助CT影像报告分析使医生工作效率提升40%,早期病灶检出率提高17%。模型原生支持256K上下文窗口(约6.4万字),能处理整本书籍或50页PDF文档,可提取关键指标、识别异常数据并结合临床指南提供辅助诊断建议。
教育培训:智能教辅的普惠化
教育机构利用模型的手写体识别与数学推理能力,开发了轻量化作业批改系统:数学公式识别准确率92.5%,几何证明题批改准确率87.3%,单服务器支持5000名学生同时在线使用。系统能解析板书内容,实时生成练习题,并处理整本书籍上下文实现跨章节知识关联。
自动驾驶领域
极端天气下路牌识别成功率比传统方案高40%,对突然窜出的外卖电动车反应时间仅0.3秒,使某车企ADAS系统误判率直降42%。Qwen3-VL的空间感知能力为自动驾驶提供了更可靠的环境理解基础。
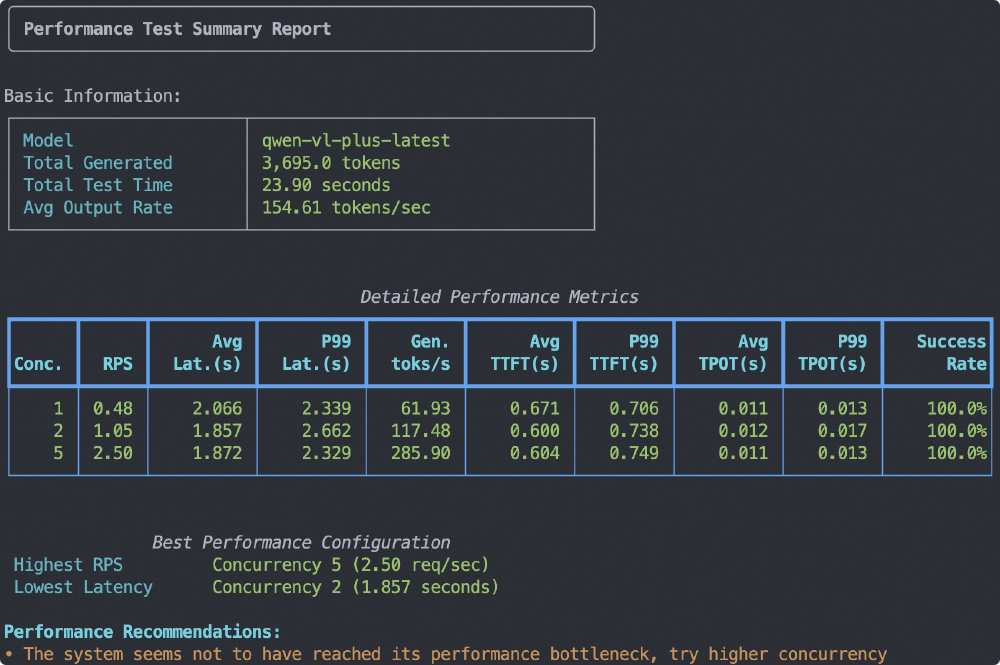
图片展示了Qwen3-VL(qwen-vl-plus-latest)模型的性能测试总结报告,包含不同并发场景下的RPS、延迟、生成速率等关键指标。从数据可见,模型在处理100 tokens文本+1张512*512图像时,可保持每秒23.6 tokens的生成速度,同时将P99延迟控制在8.7秒内,展现出高效推理能力,为企业级应用提供了性能保障。
部署与优化方案:轻量级版本大幅降低应用门槛
阿里通义千问团队同步开源了4B/8B轻量级版本,让边缘设备部署成为可能。其中Qwen3-VL-4B-Instruct-FP8模型通过FP8量化技术,首次让普通开发者能够用消费级显卡部署千亿级视觉大模型能力,在8GB显存设备上即可流畅运行。
部署步骤示例
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking-FP8
cd Qwen3-VL-30B-A3B-Thinking-FP8
# 安装依赖
pip install -r requirements.txt
# 启动API服务(需GPU支持)
python -m vllm.entrypoints.api_server --model . --tensor-parallel-size 4 --gpu-memory-utilization 0.7
通过Unsloth Dynamic 2.0量化技术和vLLM推理优化,Qwen3-VL-4B可在单张消费级GPU(如RTX 3090)上流畅运行。实测表明,在12GB显存环境下,模型可处理1024×1024图像的同时保持每秒18.7 tokens的生成速度,较同规模模型提升58%吞吐量。
未来发展趋势与挑战
Qwen3-VL代表的多模态技术正朝着三个方向演进:模型小型化、实时交互和世界模型构建。在保持性能的前提下降低资源消耗,4B模型已可在消费级GPU运行;将视频处理延迟从秒级压缩至毫秒级,满足自动驾驶等场景的需求;通过持续学习构建物理世界的动态表征,实现更精准的预测与规划。
结论:多模态AI的实用化拐点已经来临
Qwen3-VL系列的发布标志着多模态AI从实验室走向产业实用的关键拐点。其开源策略降低了技术门槛,8B轻量级模型在消费级硬件即可运行,同时235B旗舰版保持技术领先性。随着模型能力从"看懂"向"理解并行动"的跨越,企业应重点关注以下机会:制造业优先部署视觉质检系统,快速实现降本增效;开发者基于开源版本构建垂直领域应用,尤其是GUI自动化工具;教育医疗领域探索个性化服务与辅助诊断的合规应用;内容创作领域利用视觉编程能力提升UI/UX开发效率。
多模态AI的黄金时代已然开启,Qwen3-VL不仅是技术突破的见证,更是人机协作新范式的起点。随着模型能力的持续进化,我们正迈向一个"万物可交互,所见皆智能"的未来。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)