大模型参数高效微调:BitFit、Child-Tuning等选择方法实战指南
文章介绍大模型微调的参数选择方法,分为基于规则和基于学习两类。基于规则的方法如BitFit、层选择和PaFi,通过人工经验选择特定参数子集更新。基于学习的方法如Child-Tuning,引入梯度掩码矩阵自动选择参数子集,分为任务无关和任务驱动两种。这些方法显著减少微调参数,降低计算成本,适合资源受限环境。
文章介绍大模型微调的参数选择方法,分为基于规则和基于学习两类。基于规则的方法如BitFit、层选择和PaFi,通过人工经验选择特定参数子集更新。基于学习的方法如Child-Tuning,引入梯度掩码矩阵自动选择参数子集,分为任务无关和任务驱动两种。这些方法显著减少微调参数,降低计算成本,适合资源受限环境。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
参数选择方法(Parameter Selection Methods)
是在微调过程中,只对预训练模型中的部分参数子集进行更新。与参数附加方法不同,这类方法无需在模型中引入新的参数,从而避免了推理阶段额外的计算开销。根据实现方式的不同,参数选择方法通常可分为两类:基于规则的选择和基于学习的选择。

1 基于规则的方法
依赖人工经验或简单规则决定哪些参数需要更新,代表方法有:
- BitFit
- 仅优化网络各层的偏置项(Biases)和任务分类头。
- 参数占比极低(约 0.08%–0.09%)。
- 在 GLUE Benchmark 上性能接近甚至超过全量微调。
- 优点:允许更大学习率,训练稳定;极高的参数效率。
- 局限:目前主要在中小模型(BERT、RoBERTa)验证,大模型效果待研究。
- BERT/RoBERTa 方法
- 仅微调 BERT/RoBERTa 的最后 1/4 层参数,能达全量微调约 90% 性能。
- PaFi
- 选择绝对值最小的参数作为可训练部分,进一步减少计算。
基于规则的方法 通常依赖专家经验来决定哪些参数需要更新。其中最具代表性的是 BitFit。该方法仅优化神经网络各层的偏置项(Biases)以及任务相关的分类头,从而实现高效微调。由于偏置项在模型总参数中占比极小(约 0.08%–0.09%),BitFit 在保持极高参数效率的同时,依然能在 GLUE Benchmark 上取得与全量微调相当,甚至在部分任务上更优的性能。与全量微调相比,BitFit 还允许使用更大的学习率,使训练过程更加稳定。不过,该方法目前主要在中小规模模型上验证,能否在更大规模模型中保持同样的效果仍有待研究。
除 BitFit 外,学界还提出了一些其他基于规则的选择方法来提升参数效率。例如,仅对模型的最后四分之一层进行微调,即可达到全量微调约 90% 的性能。另一种方法 PaFi 则通过选择绝对值最小的模型参数作为可训练部分,进一步降低了微调的计算开销。
规则的方法实现思路
- 冻结所有参数
- 默认情况下,将预训练模型所有参数
requires_grad=False,即不参与反向传播更新。
- 选择需要更新的参数(基于规则)
- BitFit:只解冻 偏置项(bias) 和 任务分类头(classifier head)。
- 层选择方法(Layer-wise Tuning):只解冻最后几层(例如 BERT 的最后四分之一层)。
- PaFi:选取 权重值绝对值最小 的参数,作为可更新部分。
- 训练时仅更新解冻的参数
- 优化器只会看到
requires_grad=True的参数,从而减少训练规模。
from transformers import BertForSequenceClassification
2 基于学习的方法
通过训练自动选择参数子集,代表方法有:
Child-Tuning
- 思路:引入 梯度掩码矩阵,仅对子网络更新梯度,其余参数进行梯度屏蔽。
基于学习的方法 会在训练过程中自动决定哪些参数需要微调。其中,最具代表性的方法是 Child-Tuning。该方法通过引入梯度掩码矩阵,仅对被选中的子网络进行梯度更新,而对其余部分的梯度进行屏蔽,从而有效控制微调的参数规模,实现参数高效微调。
具体来说,设第 t 轮迭代的参数矩阵为 Wt,Child-Tuning 在此基础上引入一个与其维度相同的 0-1 掩码矩阵Mt,用于确定本轮训练中所更新的子网络 Ct。这样,只有掩码矩阵中被激活(取 1)的参数会参与更新,而其他参数保持冻结状态:
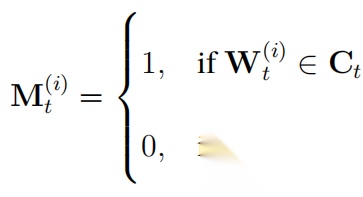
其中,M(t i) 和 Wt(i) 分别是矩阵 Mt 和 Wt 在第 t 轮迭代的第 i 个元素。此时,梯度更新公式为:
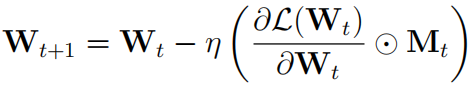
Child-tuning 提供了两种生成子网络掩码 M 的方式,由此产生两种变体模型:Child-tuningF 和 Child-tuningD。
Child-tuningF 是一种任务无关的变体,它在不依赖任何下游任务数据的情况下选择子网络。在每次迭代时,Child-tuningF 从伯努利分布中抽取 0-1 掩码,
生成梯度掩码 Mt :Mt ∼ Bernoulli(pF )
其中,pF 是伯努利分布的概率,表示子网络的比例。此外,Child-tuningF 通过引入噪声来对全梯度进行正则化,从而防止小数据集上的过拟合,并提高泛化能力。
Child-tuningD 是一种任务驱动的变体,它利用下游任务数据来选择与任务最相关的子网络。具体来说,Child-tuningD 使用费舍尔信息矩阵来估计特定任务相关参数的重要性。具体地,对于给定的任务训练数据 D,模型的第 i 个参数矩阵 W(i) 的费舍尔信息估计为:
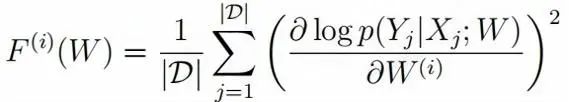
其中,Xi 和 Yi 分别表示第 i 个样本的输入和输出,log p(Yi|Xi; W) 是对数似然概率,通过计算损失函数对参数 W(i) 的梯度得到。通常,我们假设参数对目标任务越重要,它的费舍尔信息的值就越高。因此,可以根据费舍尔信息来选择子网络,子网络 C 由具有最高费舍尔信息的参数组成。选择子网络参数的步骤如下:
-
计算每个参数的费舍尔信息值;
-
对这些费舍尔信息值进行排序;
-
选择前 pD 比例的参数作为子网络 C 。
确定子网络后,生成相应的掩码矩阵完成模型训练。
Child-tuning 通过梯度屏蔽减少了计算负担,同时减少了模型的假设空间,降低了模型过拟合的风险。然而,子网络的选择需要额外的计算代价,特别是在任务驱动的变体中,费舍尔信息的计算十分耗时。但总体而言,Child-tuning 可以改善大语言模型在多种下游任务中的表现,尤其是在训练数据有限的情况下。此外,Child-tuning 可以很好地与其他 PEFT 方法的集成,进一步提升模型性能。
实现思路:
- 冻结参数:和规则法一样,起点是冻结大部分参数。
- 引入掩码(Mask)矩阵:
- 每个参数对应一个 0/1 标记,决定它是否更新。
- 掩码可以是固定的(预先生成),也可以在训练过程中动态调整。
- 学习掩码:
- 通过随机采样(Child-Tuning-F)
- 或者根据参数重要性(Child-Tuning-D,FishMask)
- 或者根据训练动态(LT-SFT、SAM)
来生成掩码。
- 更新时屏蔽梯度:
-
梯度更新公式:
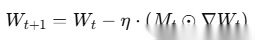
其中Mt是掩码矩阵,⊙表示逐元素乘法。掩码为 0 的位置,梯度被屏蔽(保持冻结)。
Child-Tuning-F(随机采样掩码)

import torch
Child-Tuning-D(任务驱动,基于Fisher信息)

from collections import defaultdict
基于选择的方法通过选择性地更新预训练模型的参数,在保持大部分参数不变的情况下对模型进行微调。基于选择的方法能够显著减少微调过程中所需要更新的参数,降低计算成本和内存需求。对于资源受限的环境或者需要快速适应新任务的场景尤其适用。然而,这些方法也面临挑战,比如,如何选择最佳参数子集,以及如何平衡参数更新的数量和模型性能之间的关系。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献235条内容
已为社区贡献235条内容

所有评论(0)