Milvus 一致性级别
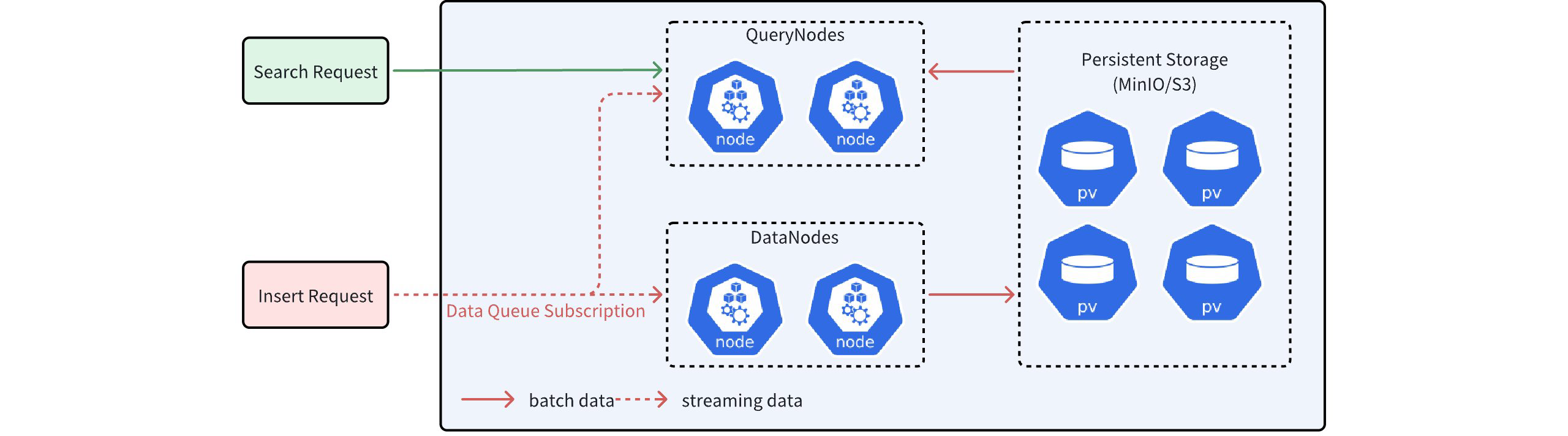
Milvus 是一个存储和计算分离的系统。在这个系统中,数据节点负责数据的持久性,并最终将其存储在 MinIO/S3 等分布式对象存储中。查询节点负责处理搜索等计算任务。这些任务涉及批量数据和流数据的处理。简单地说,批量数据可以理解为已经存储在对象存储中的数据,而流式数据指的是尚未存储在对象存储中的数据。由于网络延迟,查询节点通常无法保存最新的流数据。如果没有额外的保障措施,直接在流数据上执行搜索
作为一个分布式向量数据库,Milvus 提供了多种一致性级别,以确保每个节点或副本在读写操作期间都能访问相同的数据。目前,支持的一致性级别包括强、有界、最终和会话,其中有界是默认使用的一致性级别。
概述
Milvus 是一个存储和计算分离的系统。在这个系统中,数据节点负责数据的持久性,并最终将其存储在 MinIO/S3 等分布式对象存储中。查询节点负责处理搜索等计算任务。这些任务涉及批量数据和流数据的处理。简单地说,批量数据可以理解为已经存储在对象存储中的数据,而流式数据指的是尚未存储在对象存储中的数据。由于网络延迟,查询节点通常无法保存最新的流数据。如果没有额外的保障措施,直接在流数据上执行搜索可能会导致丢失许多未提交的数据点,从而影响搜索结果的准确性。
Milvus 商业版是一个将存储和计算分离的系统。在这个系统中,数据节点负责数据的持久化,并最终将数据存储在 MinIO/S3 等分布式对象存储中。查询节点负责处理搜索等计算任务。这些任务涉及批量数据和流数据的处理。简单地说,批量数据可以理解为已经存储在对象存储中的数据,而流式数据指的是尚未存储在对象存储中的数据。由于网络延迟,查询节点通常无法保存最新的流数据。如果没有额外的保护措施,直接在流数据上执行搜索可能会导致丢失许多未提交的数据点,从而影响搜索结果的准确性。
批数据和流数据
如上图所示,在收到搜索请求后,查询节点可以同时接收流数据和批处理数据。但是,由于网络延迟,查询节点获得的流数据可能不完整。
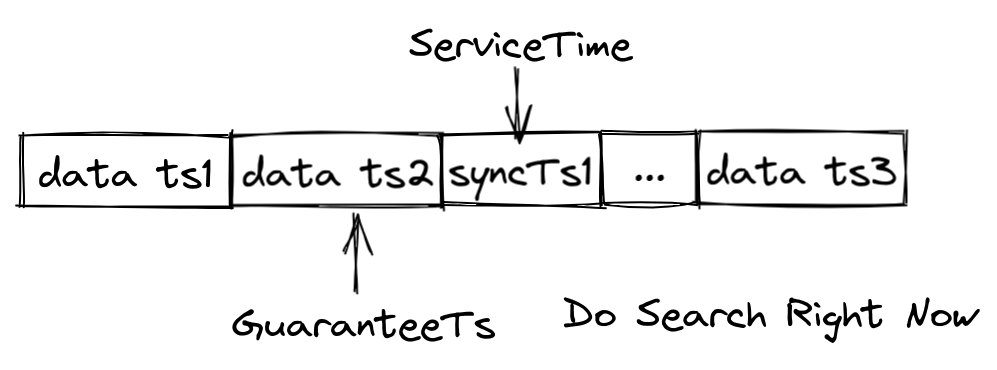
为了解决这个问题,Milvus 对数据队列中的每条记录都打上时间戳,并不断向数据队列中插入同步时间戳。每当收到同步时间戳(syncTs),QueryNodes 就会将其设置为服务时间,这意味着 QueryNodes 可以查看该服务时间之前的所有数据。基于 ServiceTime,Milvus 可以提供保证时间戳(GuaranteeTs),以满足用户对一致性和可用性的不同要求。用户可以通过在搜索请求中指定 GuaranteeTs,通知查询节点需要在搜索范围中包含指定时间点之前的数据。
服务时间和保证时间
如上图所示,如果 GuaranteeTs 小于 ServiceTime,则表示指定时间点之前的所有数据已全部写入磁盘,允许查询节点立即执行搜索操作。当 GuaranteeTs 大于 ServiceTime 时,查询节点必须等到 ServiceTime 超过 GuaranteeTs 后才能执行搜索操作。
用户需要在查询准确性和查询延迟之间做出权衡。如果用户对一致性要求较高,对查询延迟不敏感,可以将 GuaranteeTs 设置为尽可能大的值;如果用户希望快速获得搜索结果,对查询准确性的容忍度较高,则可以将 GuaranteeTs 设置为较小的值。
一致性级别图解
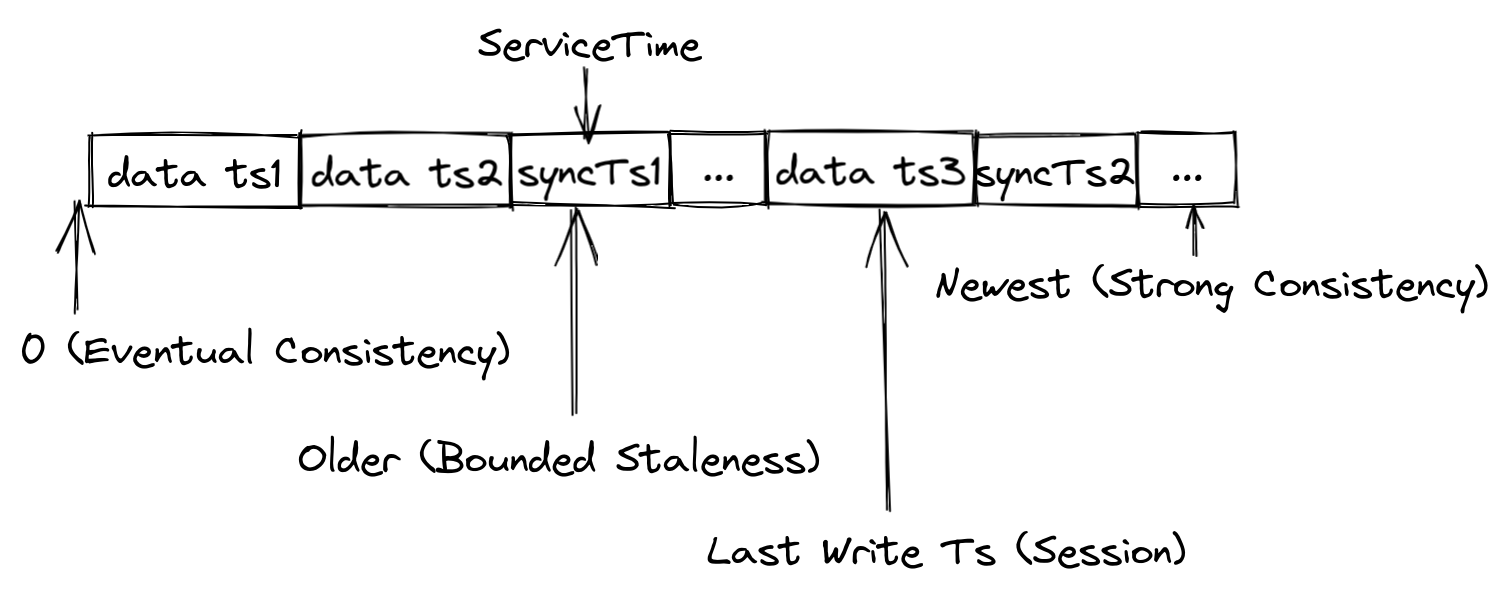
Milvus 提供四种不同 GuaranteeTs 的一致性级别。
-
强
使用最新的时间戳作为 GuaranteeTs,查询节点必须等到服务时间满足 GuaranteeTs 后才能执行搜索请求。
-
最终
GuaranteeTs 设置为极小值(如 1),以避免一致性检查,这样查询节点就可以立即对所有批次数据执行搜索请求。
-
有限制的停滞
GuranteeTs 设置为早于最新时间戳的时间点,以便查询节点在执行搜索时能容忍一定的数据丢失。
-
会话
客户端插入数据的最新时间点被用作 GuaranteeTs,这样查询节点就能对客户端插入的所有数据执行搜索。
Milvus 使用 "有界滞后 "作为默认的一致性级别。如果未指定保证时间,则使用最新的服务时间作为保证时间。
设置一致性级别
创建 Collections 以及执行搜索和查询时,可以设置不同的一致性级别。
创建 Collections 时设置一致性级别
创建 Collections 时,可以为集合内的搜索和查询设置一致性级别。以下代码示例将一致性级别设置为强。
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
// highlight-next
.consistencyLevel(ConsistencyLevel.STRONG)
.build();
client.createCollection(createCollectionReq);
consistency_level 参数的可能值是Strong,Bounded,Eventually, 和Session 。
在搜索中设置一致性级别
您可以随时更改特定搜索的一致性级别。下面的代码示例将一致性级别设置为 "有界"。该更改仅适用于当前搜索请求。
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(3)
.searchParams(params)
.consistencyLevel(ConsistencyLevel.BOUNDED)
.build();
SearchResp searchResp = client.search(searchReq);
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClBounded).
WithANNSField("vector"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
该参数也可用于混合搜索和搜索迭代器。consistency_level 参数的可能值是Strong,Bounded,Eventually, 和Session 。
在查询中设置一致性级别
您可以随时更改特定搜索的一致性级别。以下代码示例将一致性级别设置为最终。该设置仅适用于当前查询请求。
QueryReq queryReq = QueryReq.builder()
.collectionName("my_collection")
.filter("color like \"red%\"")
.outputFields(Arrays.asList("vector", "color"))
.limit(3)
.consistencyLevel(ConsistencyLevel.EVENTUALLY)
.build();
QueryResp getResp = client.query(queryReq);
该参数在查询迭代器中也可用。consistency_level 参数的可能值是Strong,Bounded,Eventually, 和Session 。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献173条内容
已为社区贡献173条内容

所有评论(0)