End-to-End Autonomous Driving without Costly Modularization and 3D Manual Annotation
当前的E2EAD模型仍然模仿典型驾驶堆栈中的模块化架构,即精心设计了监督感知和预测子任务,为定向规划提供环境信息。场景下规划的鲁棒性。这个策略能够从不同的增强视角来学习预测轨迹的一致性。)来减弱对3D标注数据的需要。该前置模型通过预测角度方向的。引入的角度查询将两个模块链接为一个整体任务来感知驾驶场景。空间中每个扇区区域的物体/客观性/对象性(?最优角度解码器可以看作是一个增强世界模型,能够。角度
现象:
current E2EAD models still mimic the modular architecture in typical driving stacks, with carefully designed supervised perception and prediction subtasks to provide environment information for oriented planning.
当前的E2EAD模型仍然模仿典型驾驶堆栈中的模块化架构,即精心设计了监督感知和预测子任务,为定向规划提供环境信息
问题:
preceding subtasks require massive high-quality 3D annotations as supervision, posing a significant impediment to scaling the training data;
要求大量且高质量的标注来作为监督数据,这对扩展训练数据构成了重大障碍each submodule entails substantial computation overhead in both training and inference.
计算开销太大
解决:
本文提出了UAD Unsupervised pretext task for end-to-end Autonomous Driving来有效的模拟环境。
一般都需要进行perception, prediction, and planning,然后Angular Perception Pretext解决的是perception, prediction,来**models the driving environment。the Direction-Aware Planning解决的是planning,来train the planning module**。
-
models the driving environmenta novel Angular Perception Pretext to eliminate the annotation requirement. The pretext models the driving scene by predicting the angular-wise spatial objectness and temporal dynamics, without manual annotation.
设计了一个角度感知预案(Angular Perception Pretext)来减弱对3D标注数据的需要。该前置模型通过预测角度方向的空间物体性和时间动态来对驾驶场景进行建模-
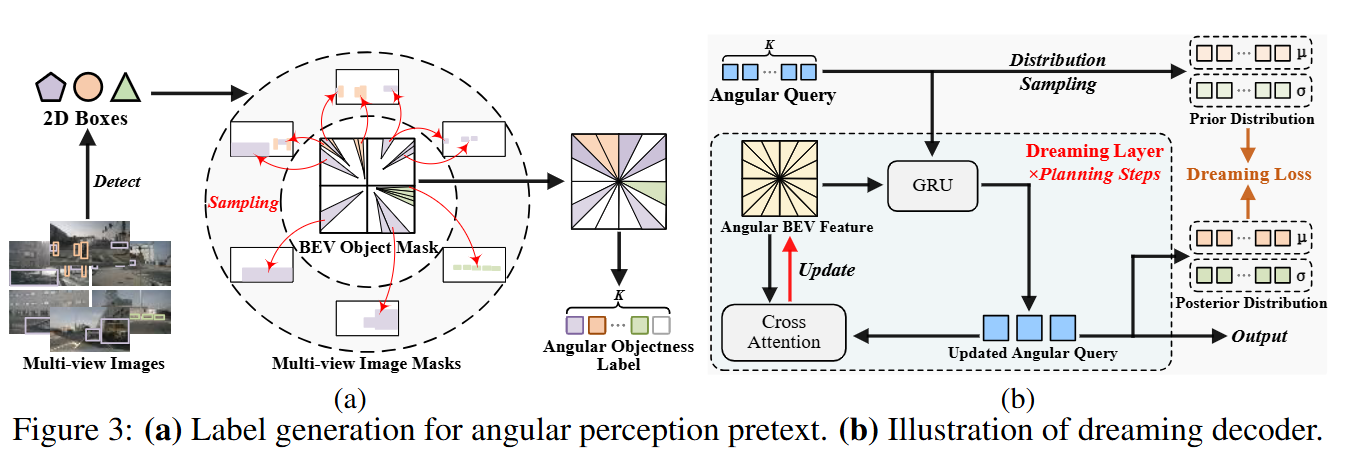
The pretext task consists of an angular-wise perception module to learn spatial information by predicting the objectness of each sector region in BEV space
角度感知模块,通过预测BEV空间中每个扇区区域的物体/客观性/对象性(?)来学习空间信息- 监督标签的来源:
by projecting the 2D regions of interests (ROIs) to the BEV space, which are predicted with an available open-set detector GroundingDINO
通过将现成的开放集检测器的2D感兴趣区域(ROI)投影到BEV空间,可以获得学习空间物体性的监督。在利用公开可用的开放集2D检测器(该检测器已通过来自其他域的手动标注进行预训练)的同时,本文避免了在作者的范式和目标域内使用任何额外的3D标注的需要,从而创建了一个实用的无监督设定。(2D的标注数据来代替3D的标注数据)
- 监督标签的来源:
-
an angular-wise dreaming decoder to absorb temporal knowledge by predicting inaccessible future states.
角度解码器,通过预测无法访问的未来状态来吸收时间知识。The dreaming decoder can be viewed as an augmented world model capable of auto-regressively predicting the future states.
最优角度解码器可以看作是一个增强世界模型,能够自动回归预测未来状态。 -
The introduced angular queries link the two modules as a whole pretext task to perceive the driving scene
引入的角度查询将两个模块链接为一个整体任务来感知驾驶场景
-
-
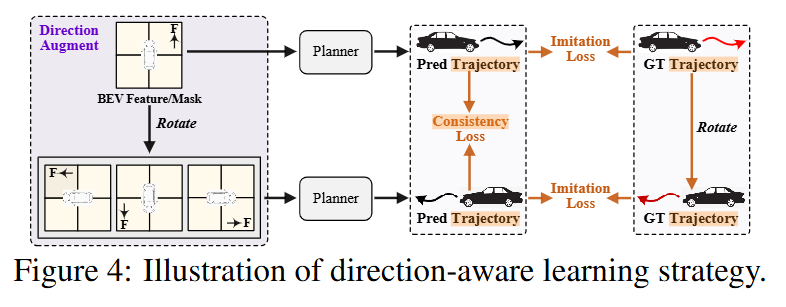
train the planning modulea self-supervised training strategy, which learns the consistency of the predicted trajectories under different augment views, is proposed to enhance the planning robustness in steering scenarios
提出了一个自监督的学习策略来增强在steering场景下规划的鲁棒性。这个策略能够从不同的增强视角来学习预测轨迹的一致性。The learning strategy can also be regarded as a novel data augmentation technique customized for end-to-end autonomous driving, which enhances the diversity of trajectory distribution.
补充:
BEV空间:
鸟瞰视角(Bird’s Eye View,简称BEV)是一种从上方观看对象或场景的视角,就像鸟在空中俯视地面一样。在自动驾驶和机器人领域,通过传感器获取的数据通常会被转换成BEV表示,以便更好地进行物体检测、路径规划等任务。BEV能够将复杂的三维环境简化为二维图像,这对于在实时系统中进行高效的计算尤其重要。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)