【NLP 入门必看】文本预处理全流程详解:从分词到词向量,一篇打通任督二脉!
本文系统介绍了NLP文本预处理的六大核心模块:1)文本处理基本方法(分词、命名实体识别、词性标注);2)文本张量表示(one-hot、Word2Vec、Word Embedding);3)文本数据分析(标签分布、句子长度、词云);4)文本特征处理(n-gram、长度规范);5)数据增强方法(回译);6)实战代码与可视化。重点讲解了中文分词工具jieba的使用、词向量训练方法对比(Word2Vec
【NLP 入门必看】文本预处理全流程详解:从分词到词向量,一篇打通任督二脉!
关键词:NLP、文本预处理、jieba分词、Word2Vec、Word Embedding、one-hot、数据增强
阅读建议:建议收藏+关注,适合 NLP 初学者、转行者、面试准备者系统学习!
前言:为什么文本预处理如此重要?
在自然语言处理(NLP)的世界里,“垃圾进,垃圾出”(Garbage in, Garbage out) 是铁律。
无论你用多么复杂的模型(BERT、Transformer),如果输入的文本“脏乱差”,模型也难以发挥真正实力。而文本预处理,正是让原始文本变得“干净、规整、可计算”的第一步。
一句话总结:文本预处理 = 把人类语言变成机器能吃的“数字饭”。
本文将带你从零开始,系统掌握 NLP 文本预处理的六大核心模块:
- 文本处理基本方法(分词、NER、词性标注)
- 文本张量表示(one-hot、Word2Vec、Word Embedding)
- 文本数据分析(标签分布、句子长度、词云)
- 文本特征处理(n-gram、长度规范)
- 数据增强方法(回译)
- 实战代码 + 可视化
Let’s go!
一、文本处理基本方法
1. 分词(Tokenization)—— 理解语言的最小单元
分词是将连续的字符序列切分成有意义的“词”序列的过程。
- 英文:天然以空格分隔,相对简单。
- 中文:无明显分隔符,必须依赖分词工具。
推荐工具:jieba(结巴分词)
import jieba
text = "故事的小黄花,从出生那天就飘着。"
# 精确模式(默认)
print(jieba.lcut(text))
# 全模式(所有可能组合)
print(jieba.lcut(text, cut_all=True))
# 搜索引擎模式(长词再切分)
print(list(jieba.cut_for_search(text)))
高级功能:
- 支持繁体中文
- 支持用户自定义词典(如:防止“小黄花”被切开)
jieba.load_userdict("../data/user_dict.txt") # 自定义词表
注意:分词质量直接影响后续任务,建议结合业务场景优化词典。
2. 命名实体识别(NER)—— 找出关键信息
NER(Named Entity Recognition)用于识别文本中的人名、地名、机构名等实体。
import jieba.posseg as pseg
text = "鲁迅是浙江绍兴人,五四新文化运动的重要参与者"
words = pseg.lcut(text)
for word, flag in words:
print(f"{word} -> {flag}")
# 鲁迅 -> nr, 浙江 -> ns, 绍兴 -> ns, 五四新文化运动 -> nz ...
常见实体类型:
nr:人名ns:地名nt:机构名t:时间m:数量mq:数量词
应用场景:知识图谱、信息抽取、智能客服。
3. 词性标注(POS)—— 理解语法结构
词性标注为每个词打上语法标签,帮助模型理解句子结构。
words = pseg.lcut("我爱自然语言处理")
# [('我', 'r'), ('爱', 'v'), ('自然语言', 'n'), ('处理', 'vn')]
常用词性:
v:动词n:名词r:代词a:形容词d:副词
提示:可结合词性过滤停用词或提取关键词(如只保留名词和形容词)。
二、文本张量表示方法(让文本变“数字”)
机器无法直接理解“爱”、“自然语言”这些词,必须将其转换为向量。
1. One-Hot 编码 —— 最基础但最“浪费”
将每个词表示为一个稀疏向量,词典大小为 V,则每个词是 V 维向量,仅一位为1。
["周杰伦", "陈奕迅", "王力宏"]
# 周杰伦 -> [1, 0, 0]
# 陈奕迅 -> [0, 1, 0]
# 王力宏 -> [0, 0, 1]
缺点:
- 向量维度巨大(词典越大越糟)
- 无法表达词义相似性(“猫”和“狗”距离 = “猫”和“石头”)
优点:简单直观,适合教学理解。
2. Word2Vec —— 让词有“语义”
Word2Vec 是 Google 提出的无监督词向量训练方法,核心思想:上下文相似的词,向量也相似。
两种训练模式:
| 模式 | 原理 | 适用场景 |
|---|---|---|
| CBOW | 用上下文预测当前词 | 训练快,适合高频词 |
| Skip-gram | 用当前词预测上下文 | 效果好,适合低频词 |
cbow: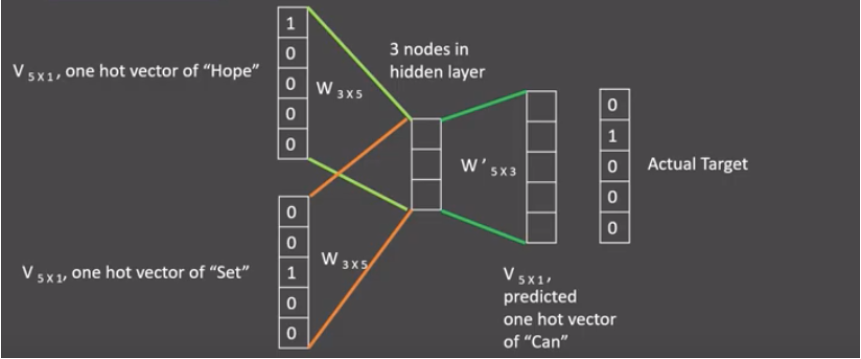
Skip-gram: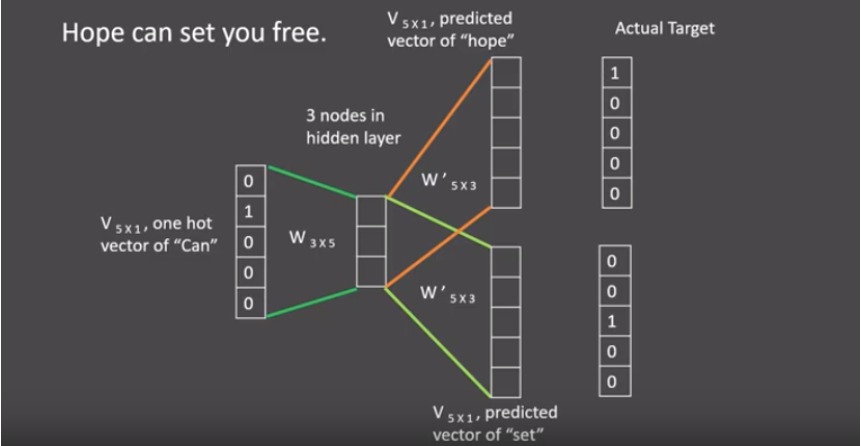
使用 fasttext 训练词向量:
import fasttext
# 训练模型
model = fasttext.train_unsupervised("../data/fil9", model='skipgram', dim=100)
# 获取词向量
vec = model.get_word_vector("人工智能")
print(vec.shape) # (100,)
优点:捕捉语义关系(如
king - man + woman ≈ queen)
3. Word Embedding —— 深度学习中的动态词向量
在神经网络中,nn.Embedding 层会自动学习词向量,且权重可更新。
import torch
import torch.nn as nn
embedding = nn.Embedding(num_embeddings=1000, embedding_dim=128)
input_ids = torch.tensor([1, 2, 3]) # 词ID
embeds = embedding(input_ids) # 输出 (3, 128)
与 Word2Vec 对比:
| 对比项 | Word2Vec | Word Embedding |
|---|---|---|
| 是否静态 | 是(训练完固定) | 否(随模型更新) |
| 是否需预训练 | 是 | 否(可随机初始化) |
| 是否易集成 | 需两步(查表+输入) | 一步嵌入网络 |
| 是否属于广义 Embedding | 是 | 是 |
总结:Word2Vec 是“预训练词向量”,Word Embedding 是“可训练的嵌入层”。
三、文本语料数据分析(EDA for NLP)
在建模前,必须对数据有充分了解。
1. 标签数量分布(检查数据均衡性)
import seaborn as sns
import matplotlib.pyplot as plt
train_df = pd.read_csv("train.tsv", sep='\t')
sns.countplot(data=train_df, x='label')
plt.title("Label Distribution")
plt.show()
若正负样本严重不均衡(如 9:1),需考虑过采样、欠采样或 focal loss。
2. 句子长度分布(决定 padding 长度)
train_df['sentence_length'] = train_df['sentence'].apply(len)
sns.histplot(train_df['sentence_length'], bins=50)
plt.title("Sentence Length Distribution")
plt.show()
建议:选择覆盖 95% 以上样本的长度作为
maxlen。
3. 关键词词云(可视化高频词)
from wordcloud import WordCloud
import jieba
# 提取形容词(情感分析常用)
def get_adj(text):
return [word for word, flag in pseg.lcut(text) if flag == 'a']
pos_words = ' '.join(train_df[train_df['label']==1]['sentence'].apply(get_adj))
wordcloud = WordCloud(font_path='SimHei.ttf', background_color='white').generate(pos_words)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
用途:检查数据噪声、发现领域关键词。
四、文本特征处理
1. 添加 n-gram 特征
n-gram 表示连续的 n 个词共现,能捕捉局部语义。
def get_ngram(tokens, n=2):
return list(zip(*[tokens[i:] for i in range(n)]))
tokens = ['我', '爱', '自然语言', '处理']
print(get_ngram(tokens, 2))
# [('我', '爱'), ('爱', '自然语言'), ('自然语言', '处理')]
应用:文本分类、情感分析中提升效果显著。
2. 文本长度规范(Padding & Truncating)
模型输入需固定长度,使用 Keras 工具:
from keras.preprocessing.sequence import pad_sequences
sequences = [[1, 2, 3], [1, 2]]
padded = pad_sequences(sequences, maxlen=5, padding='post', truncating='post')
# [[1, 2, 3, 0, 0], [1, 2, 0, 0, 0]]
post:在末尾填充/截断;pre:在开头。
五、数据增强方法:回译(Back Translation)
当数据少时,可用回译增强数据多样性。
原理:中文 → 英文 → 中文,语义不变,表达变化。
# 使用有道翻译API(需申请KEY)
import requests
def back_translate(text, from_lang='zh-CHS', to_lang='en'):
# 先翻译成英文
en_text = youdao_translate(text, from_lang, to_lang)
# 再翻译回中文
zh_text = youdao_translate(en_text, to_lang, from_lang)
return zh_text
# 示例
original = "烦恼即菩提,我暂且不提"
augmented = back_translate(original)
print(augmented) # "Trouble is Bodhi, I'll leave it for now"
# 回译后可能变为:"烦恼即是觉悟,我先放一放"
效果:提升模型泛化能力,防止过拟合。
总结:NLP 文本预处理全流程图
写在最后
文本预处理看似“简单”,实则是 NLP 项目的基石。一个优秀的 NLP 工程师,往往能在预处理阶段就拉开差距。
本文核心要点回顾:
- 分词是基础,
jieba是中文首选- Word2Vec 学语义,Embedding 可更新
- 数据分析决定模型上限
- n-gram 和回译是提分利器
参考资料 & 工具推荐
如果你觉得这篇博客对你有帮助,欢迎点赞、收藏、关注!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)