无需训练的LLM对齐方法综述
调整模型参数以符合人类价值观,但这种方法存在致命短板——它需要海量标注数据、消耗巨大算力,且会覆盖模型原有的知识("知识退化"),更无法适配闭源商业模型(如GPT-4)。三大阶段动态引导模型行为。(URIAL):在问题前添加3个安全回答示例+系统指令(如"你是一个无害助手"),即可让原始模型达到接近微调的安全水平。(CoSA):引入"安全配置器",动态生成文化适配的提示(如对欧美用户强调隐私,对亚
大型语言模型(LLMs)如GPT-4、Claude等已深刻改变人机交互方式,但其在医疗、教育等关键领域的应用引发了双重担忧:一方面,模型可能生成有害内容或泄露隐私;另一方面,用户期望模型更专业、更个性化。传统解决方案是通过微调(Fine-Tuning, FT) 调整模型参数以符合人类价值观,但这种方法存在致命短板——它需要海量标注数据、消耗巨大算力,且会覆盖模型原有的知识("知识退化"),更无法适配闭源商业模型(如GPT-4)。

-
论文:A Survey on Training-free Alignment of Large Language Models
-
链接:https://arxiv.org/pdf/2508.09016
为此,免训练对齐(Training-Free Alignment, TF Alignment) 应运而生。它像一位"无需动手术的调理师",在不修改模型内部结构的前提下,通过输入提示设计、生成过程干预或输出结果修正三大阶段动态引导模型行为。本文是首个系统综述TF对齐技术的论文,提出了创新的三阶段分类框架,并指出其如何突破资源与权限限制,为开源和闭源模型提供普惠、灵活的安全对齐方案。
为什么需要免训练对齐?
传统微调方法面临三重困境:
-
知识退化:调整参数时会"遗忘"预训练学到的通用知识,如同要求专家改行导致技能流失。
-
资源黑洞:标注高质量对齐数据需人类专家,训练需数百GPU小时,成本高昂且不环保。
-
闭源屏障:商业模型(如GPT-4)不开放参数,微调无从下手。
TF对齐的破局优势在于:
-
零训练开销:仅需调整输入或解码策略,省去90%+算力消耗。
-
即插即用:如提示工程可实时切换对齐目标(例如从"医疗严谨"切至"儿童友好")。
-
黑盒兼容:不触碰模型参数,开源(Llama)闭源(GPT-4)通吃。
-
知识保鲜:避免参数改动,保留模型原有能力。
免训练对齐的三阶段框架
(1)解码前干预:给模型"打预防针"
核心是在输入前添加提示或检测恶意内容。例如:
-
基础提示(URIAL):在问题前添加3个安全回答示例+系统指令(如"你是一个无害助手"),即可让原始模型达到接近微调的安全水平。
-
增强提示(CoSA):引入"安全配置器",动态生成文化适配的提示(如对欧美用户强调隐私,对亚洲用户强调集体责任)。
-
防御检测(VLMGuard):用无标注数据训练恶意输入检测器,过滤带毒图片或文本。
局限:依赖人工设计提示,对抗新型攻击泛化性弱。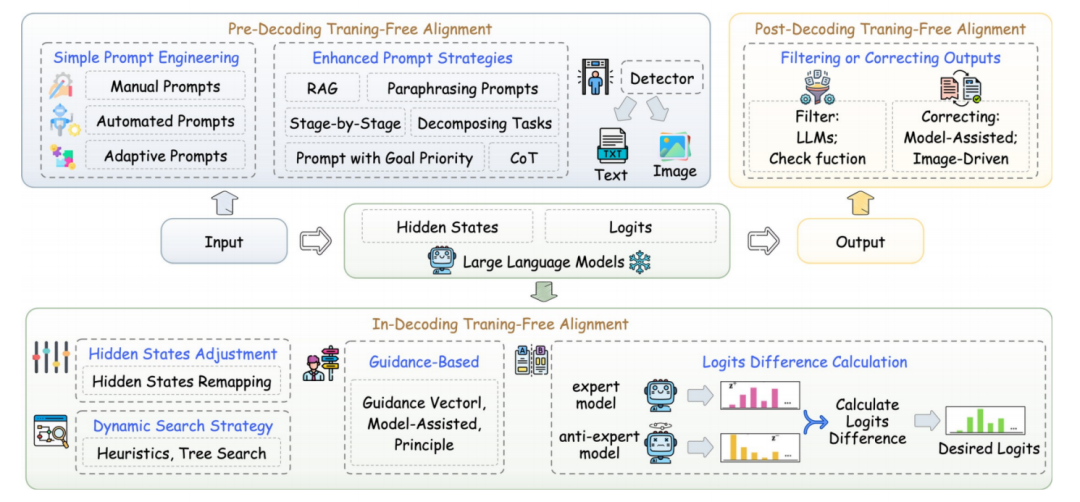
(2)解码中调整:实时操控生成方向
在模型逐词生成时干预内部计算,关键技术包括:
-
隐藏状态手术:多模态模型(VLMs)的图文模块常存在"表征割裂"。CMRM方法将视觉隐藏状态拉回语言模型优化过的空间(如图文安全对齐修复):其中, 是视觉特征, 是语言特征,λ控制校正强度。
-
Logits修正:δ-UNLEARNING用小模型学习"有害logits偏移量",应用于大模型:δ由小模型在有害/无害数据上的logits差异计算得出,相当于给原始输出概率"去毒"。
-
引导解码(GenARM):用奖励模型预测每个token的收益,引导生成:R(token)是奖励评分(如安全分),越高则token概率被放大。
-
动态搜索(RAIN):让模型自评生成内容,若不安全则回退重写,模拟人类"三思而后言"。
局限:多数方法需访问模型内部状态(白盒),不适用闭源模型。
(3)解码后修正:结果安检员
对生成文本进行过滤或改写:
-
自检过滤(RALLM):随机屏蔽部分输入重试,若输出不一致则判定原结果不可信。
-
多模态修正(ETA):用CLIP模型评估图文匹配度,若图片隐含暴力,则触发文本重写。
-
安全改写器(Aligner):训练小型校正模型,将有害输出转成无害表达(如将仇恨言论改为中立观点)。
优势:完全模型无关,通用性强。
局限:额外处理步骤增加延迟(如ETA需多次生成比较)。
实验验证与核心发现
论文在Llama2-7b-chat上对比TF与FT方法:
-
数据集:
-
-
AdvBench(456条恶意问题)
-
SafeEdit(500条对抗攻击)
-
TruthfulQA(753条良性问题)
-
-
指标:
-
-
防御成功率(↑越高越安全)
-
良性拒绝率(↓越低越有用,避免误伤正常问题)
-
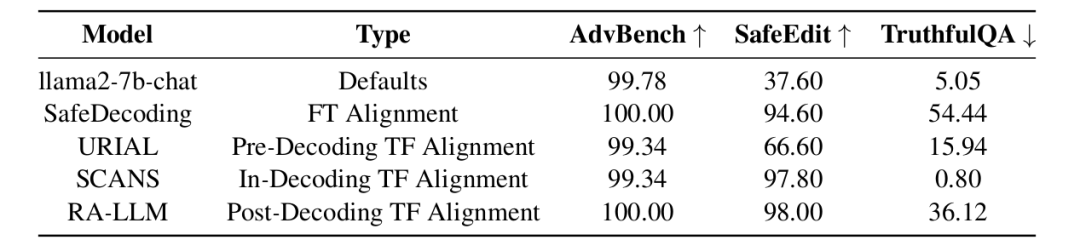
关键结果:
-
TF方法SCANS(解码中)在SafeEdit上防御率达97.8%,超越FT方法SafeDecoding(94.6%)。
-
所有TF方法在TruthfulQA的良性拒绝率均显著低于FT方法(如SCANS仅0.8% vs. SafeDecoding 54.44%),证明更保留有用性。
-
URIAL(解码前)在复杂对抗攻击(SafeEdit)上表现较差(66.6%),暴露提示工程的泛化瓶颈。
结论:TF方法在安全性和知识保留上可媲美甚至超越FT,且计算成本极低。
结论
本文三大里程碑式贡献:
-
首份TF对齐系统综述:填补了免训练模型伦理调控的研究空白。
-
创新三阶段框架(解码前/中/后):为纷繁复杂的技术提供清晰分类导航。
-
前沿研究路线图:指明轻量化、泛化性、多模态对齐等突破方向。
TF对齐的价值远超技术本身——它使资源有限者(如中小企业、发展中国家)也能部署安全模型,让闭源黑盒(如商业API)接受人类价值观约束,推动大模型真正普惠、负责任地赋能社会。未来需产学研协同攻坚泛化性与效率瓶颈,并建立跨文化对齐标准,让AI成为全球信任的"数字公民"。



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)