AI大模型微调教程4
Alpaca、AdaLoRA、QLoRA
·
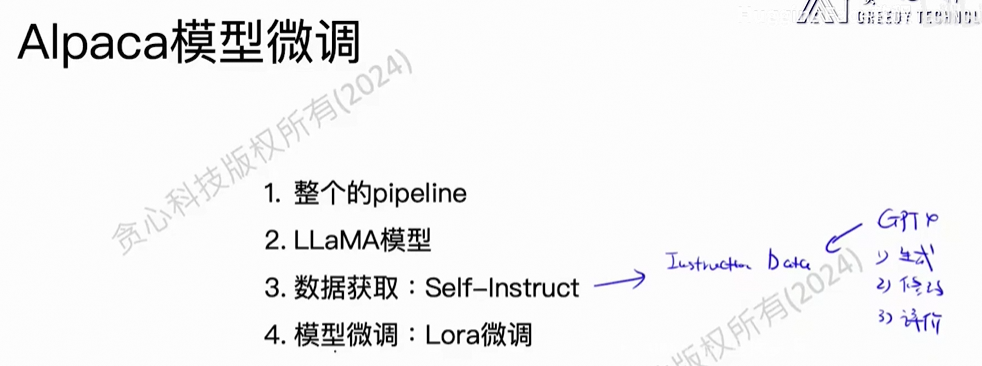
1、目录

2、Alpaca
(1)概述
Lora的变种。
训练:一次性,讲究效果。
推理:关注性能,关注量化技术。
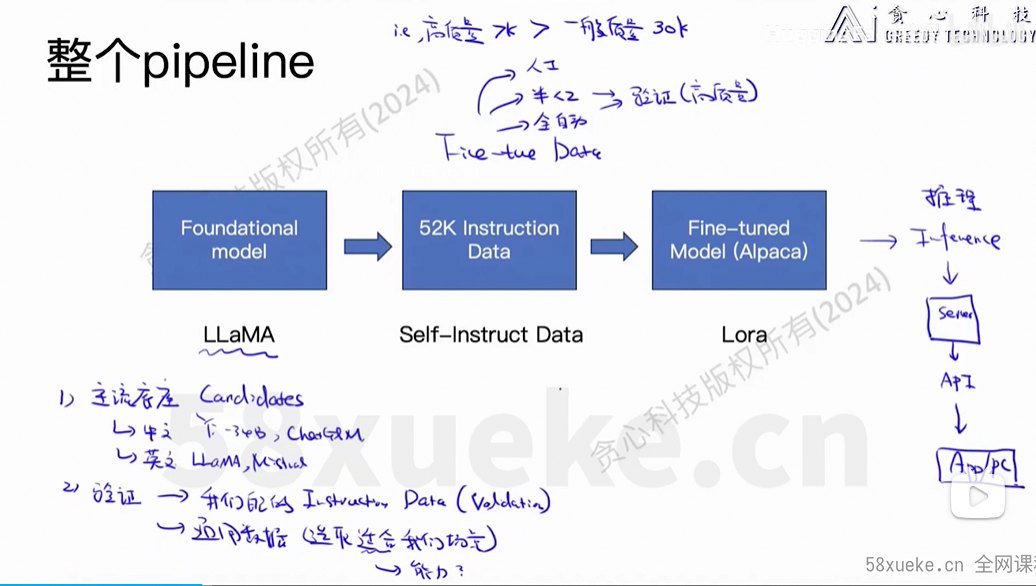


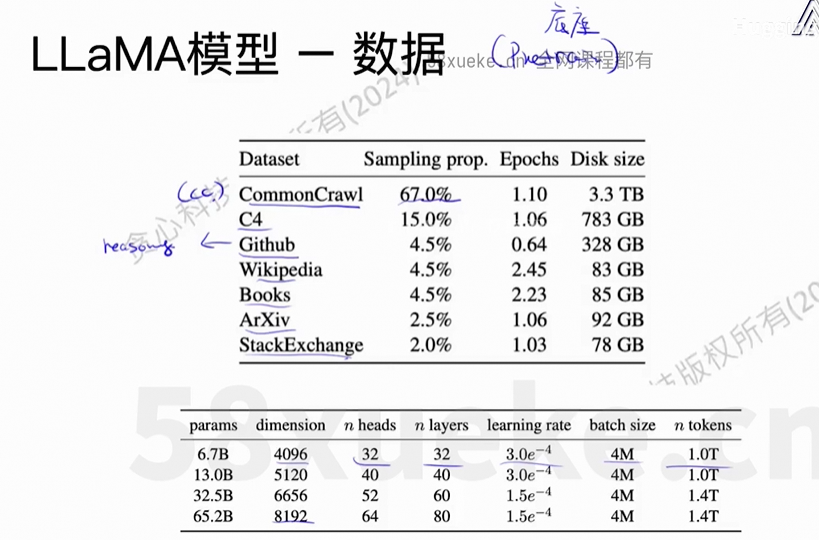

(2)数据
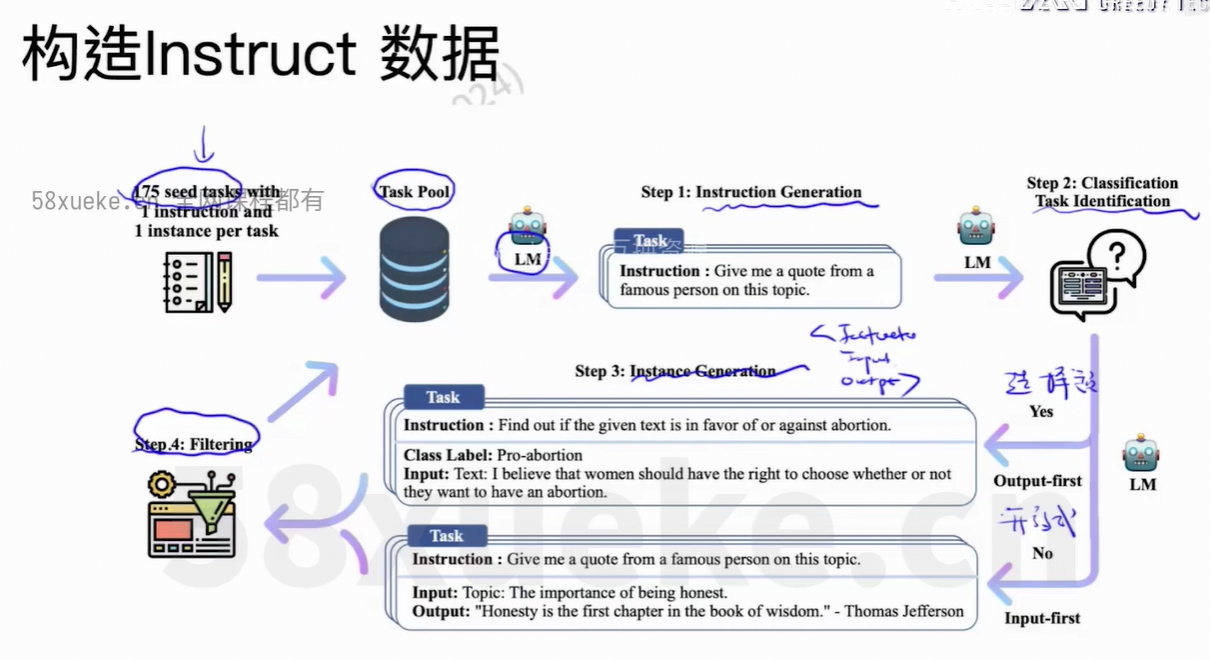

从8个example生成更多的example。

分类式/开放式的task。
上面过程只是生成instruction的数据,还没有生成input/output。



先生成label、output、再生成input,保证数据均匀。

Code:

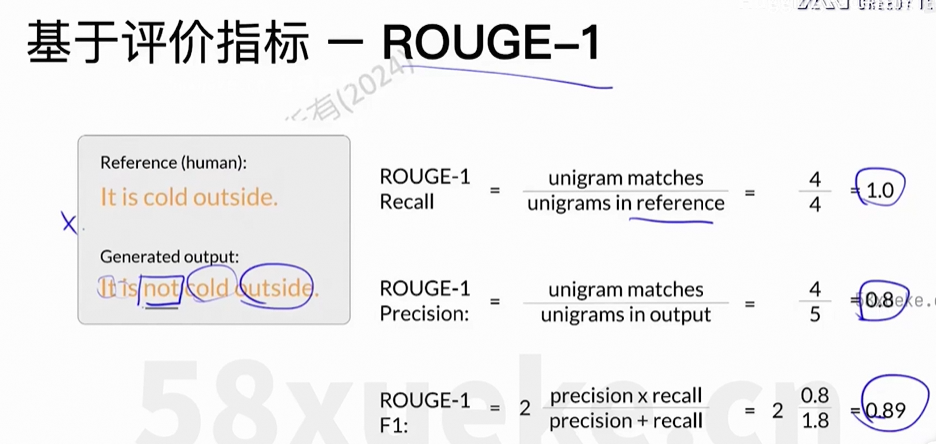
(3)评价



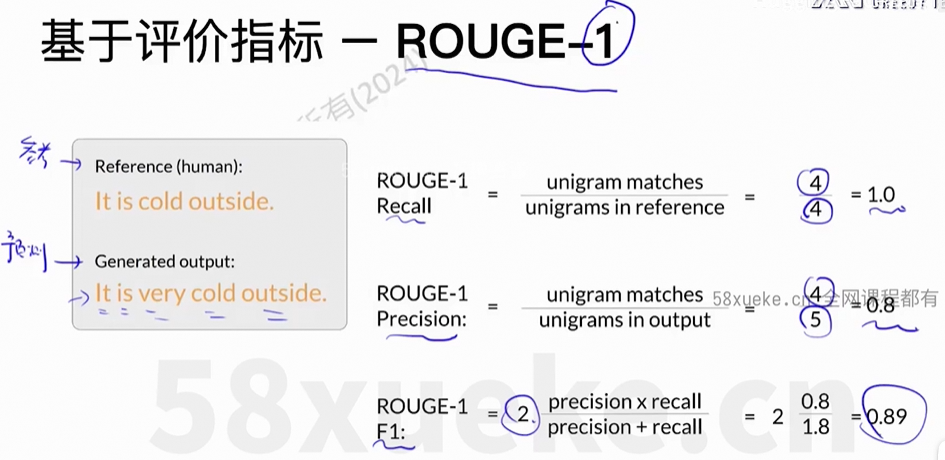
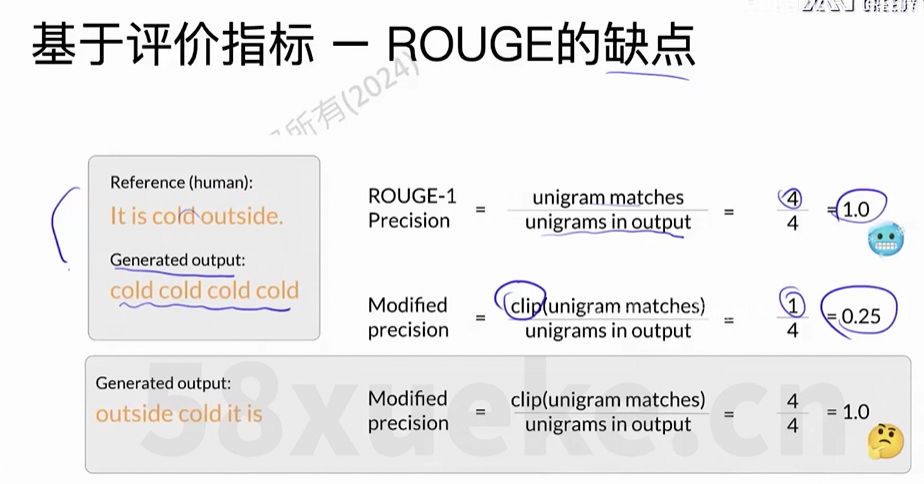
存在的问题:错误的答案,但是一样的得分
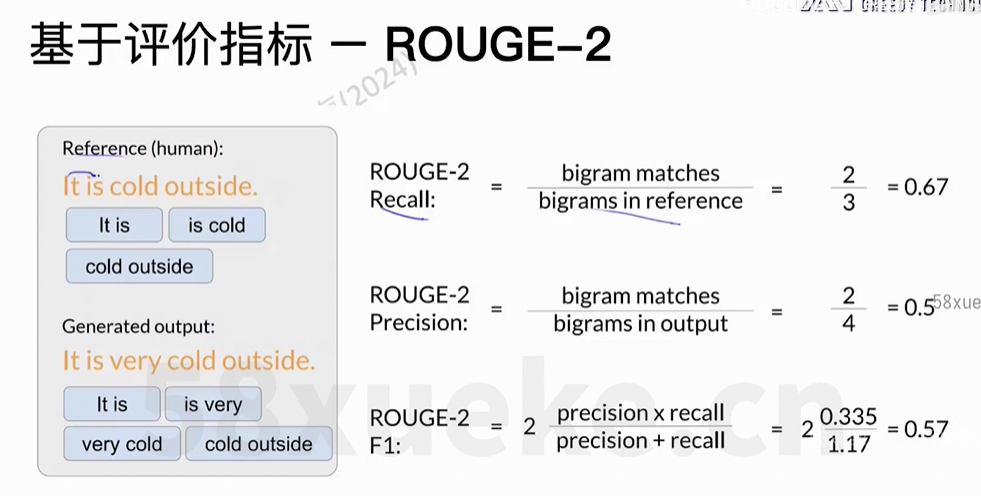

3、AdaLoRA



SVD矩阵,控制对角矩阵的rank从而动态分配rank的总量。





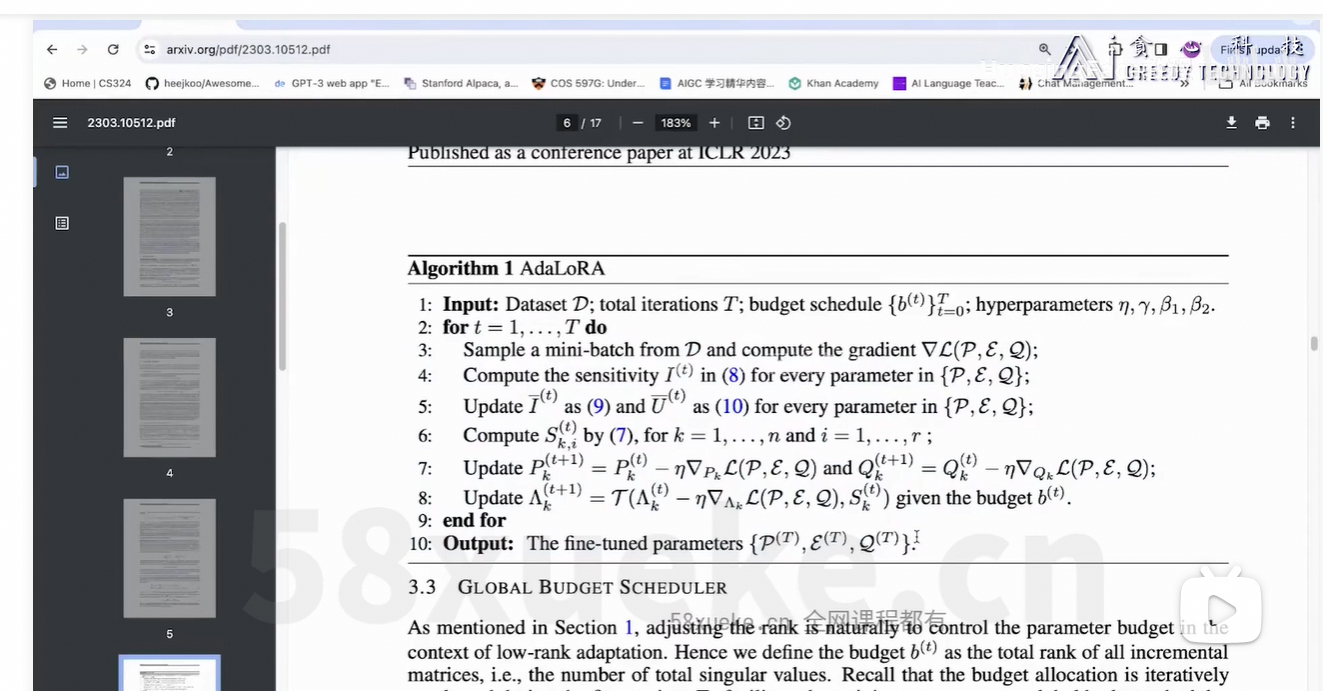
整体思路:在Lora的基础上,动态调整r的数量,重要的矩阵r的数量多一点,不重要的矩阵r的数量少一点。
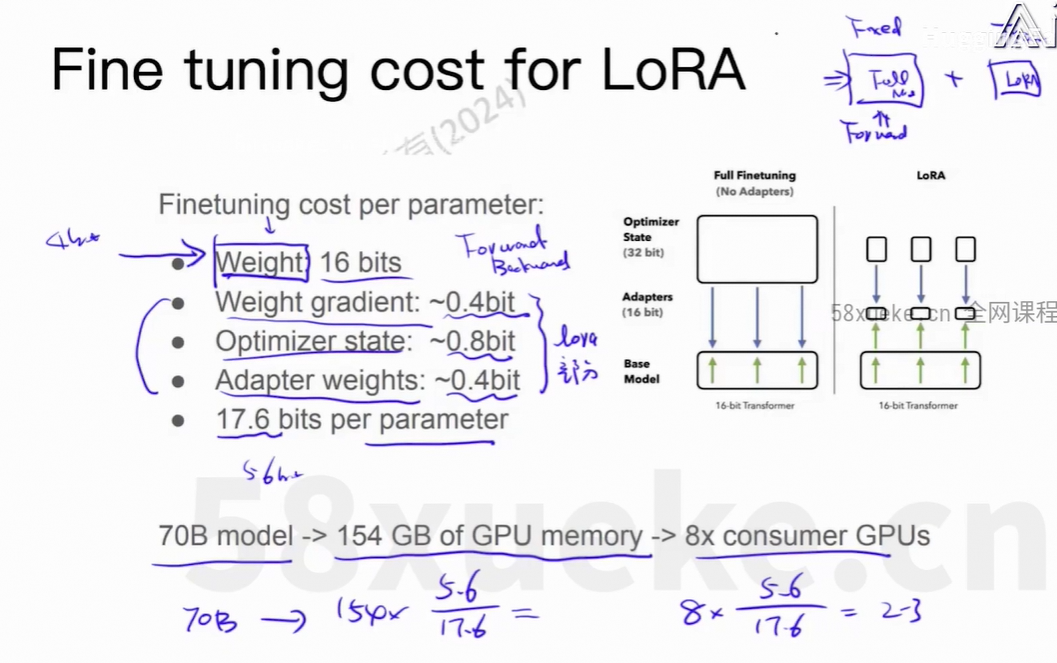
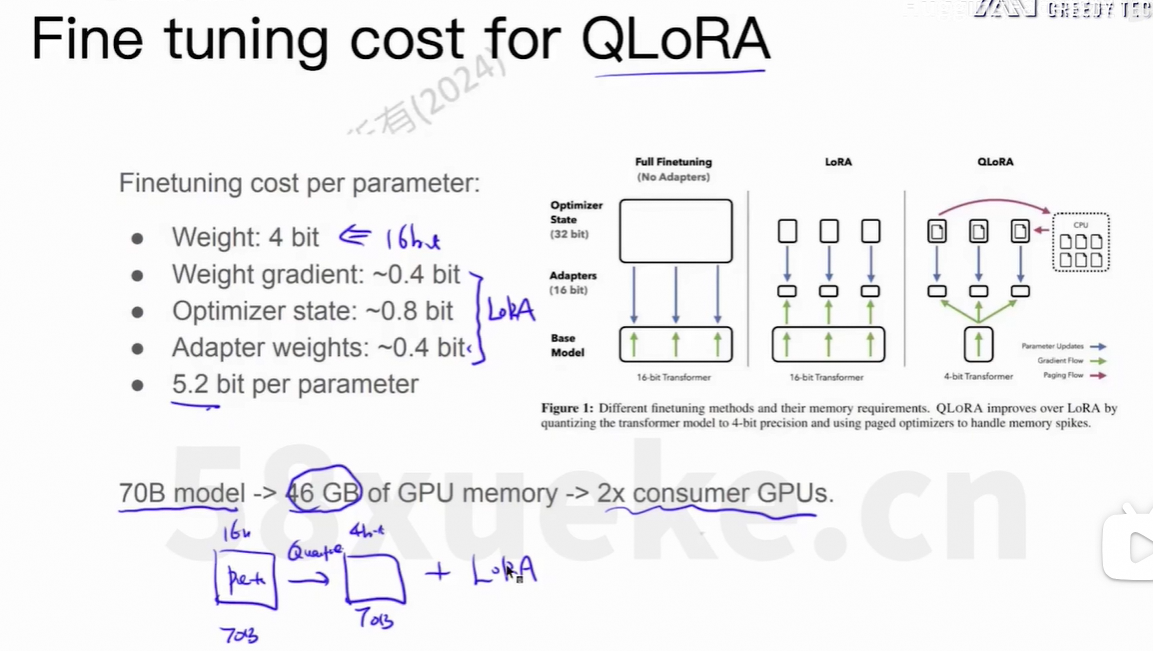
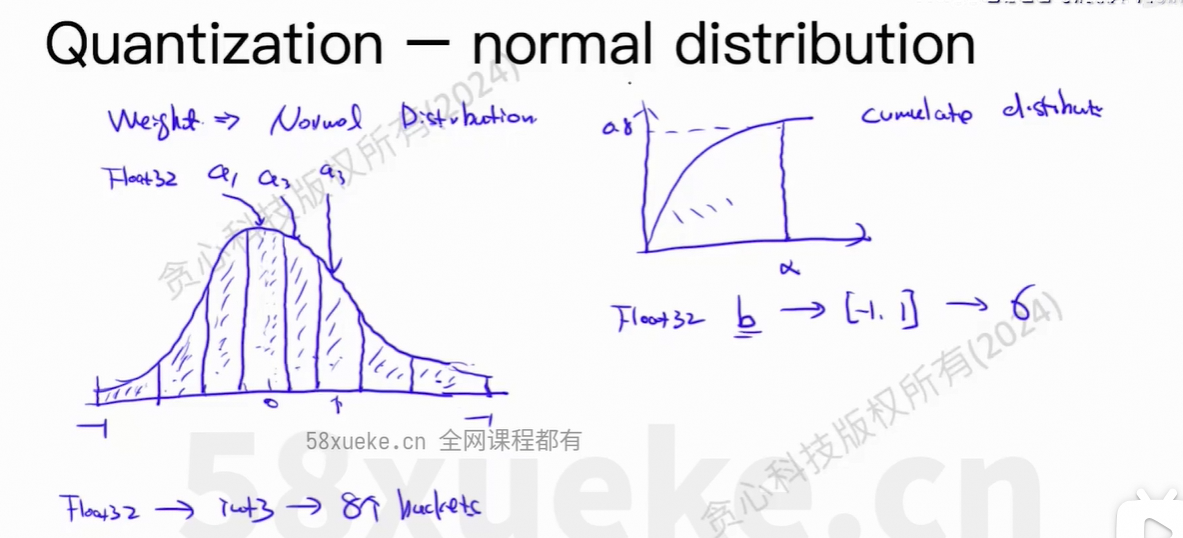
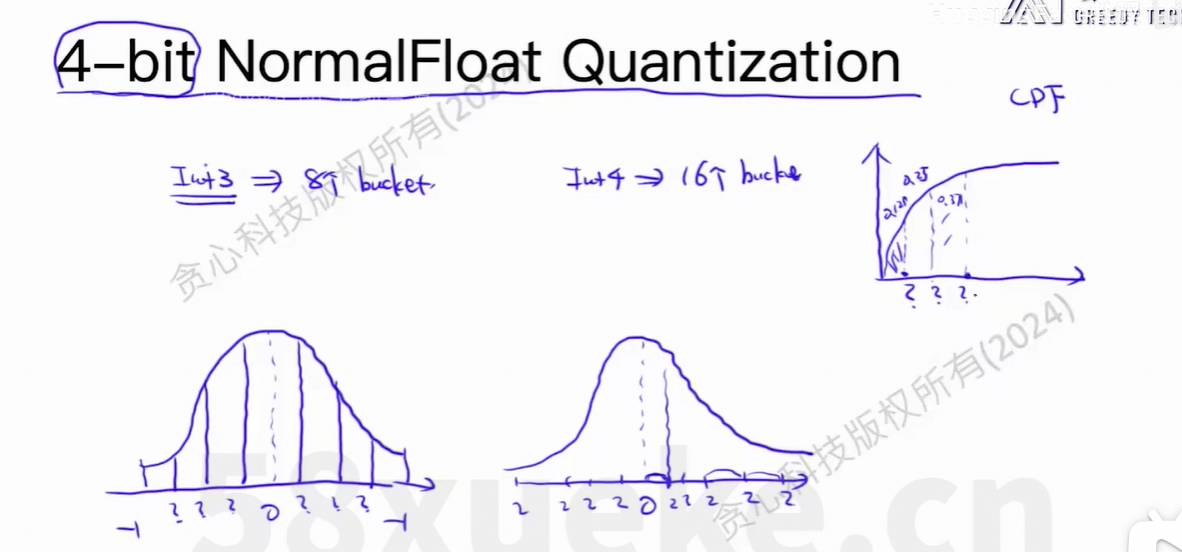
4、QLoRA
量化方法的LoRA。



上面描述了在训练神经网络模型时,每个参数在内存/显存中所占用的总资源量。逐项值的说明:
| 项目 | 精度 | 字节数 | 说明 |
|---|---|---|---|
| 模型权重(Weight) | 16-bit (FP16/BF16) | 2 bytes | 模型当前的参数值,通常用半精度存储 |
| 权重梯度(Weight Gradient) | 16-bit (FP16) | 2 bytes | 反向传播计算出的梯度,也常以半精度存储 |
| 优化器状态(Optimizer State) | 32-bit × 2 (例如 Adam) | 8 bytes | 这是最关键的部分,通常占用最多 |
为什么优化器状态是8bytes(即64-bit)?
最常见的优化器如Adam/AdamW,会为每个参数维护两个状态变量。
- 一阶动量(momentum / m):移动平均梯度 → 32-bit(4 bytes)
- 二阶动量(variance / v):移动平均平方梯度 → 32-bit(4 bytes)
上面的例子中,参数量是70亿,每个参数占用12bytes,显存需求约为 70亿*12bytes=840G。
这只是优化器状态 + 梯度 + 参数本身 的基本开销,实际中还有:
- 激活值(activations,反向传播需要)
- 临时缓存(CUDA kernel 临时空间)
- Batch processing 的开销
所以实际需求可能比840G更多。


outlier:异常值


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)