一文详解!用强化学习优化医学大模型!Deep-DxSearch系统详解,值得收藏!
Deep-DxSearch是一种基于强化学习的端到端训练代理式RAG系统,专为提升医学诊断准确性而设计。它通过构建大规模医学检索语料库,将LLM作为核心代理,使用定制奖励机制优化检索和推理策略。实验证明,该系统在常见和罕见疾病诊断上显著超越GPT-4o等现有模型,为医学AI诊断提供了更可靠的解决方案。

摘要
由于固有的知识局限性和幻觉,准确诊断仍然是医学大型语言模型的中心挑战。虽然检索增强生成(RAG)和工具增强代理方法在缓解这些问题方面显示出潜力,但由于外部知识的次优利用以及反馈推理可追溯性的脱节,这些方法仍然面临主要限制,这源于监督不足。为了应对这些挑战,我们引入了Deep-DxSearch,这是一种使用强化学习(RL)端到端训练的代理式RAG系统,能够为医学诊断提供引导式的可追溯检索增强推理。在Deep-DxSearch中,我们首先构建了一个包含患者记录和可靠医学知识来源的大规模医学检索语料库,以支持跨诊断场景的检索感知推理。更为关键的是,我们将大型语言模型(LLM)作为核心代理,将检索语料库作为其环境,并使用针对格式、检索、推理结构和诊断准确性的定制奖励,从而通过RL从大规模数据中演化出代理式RAG策略。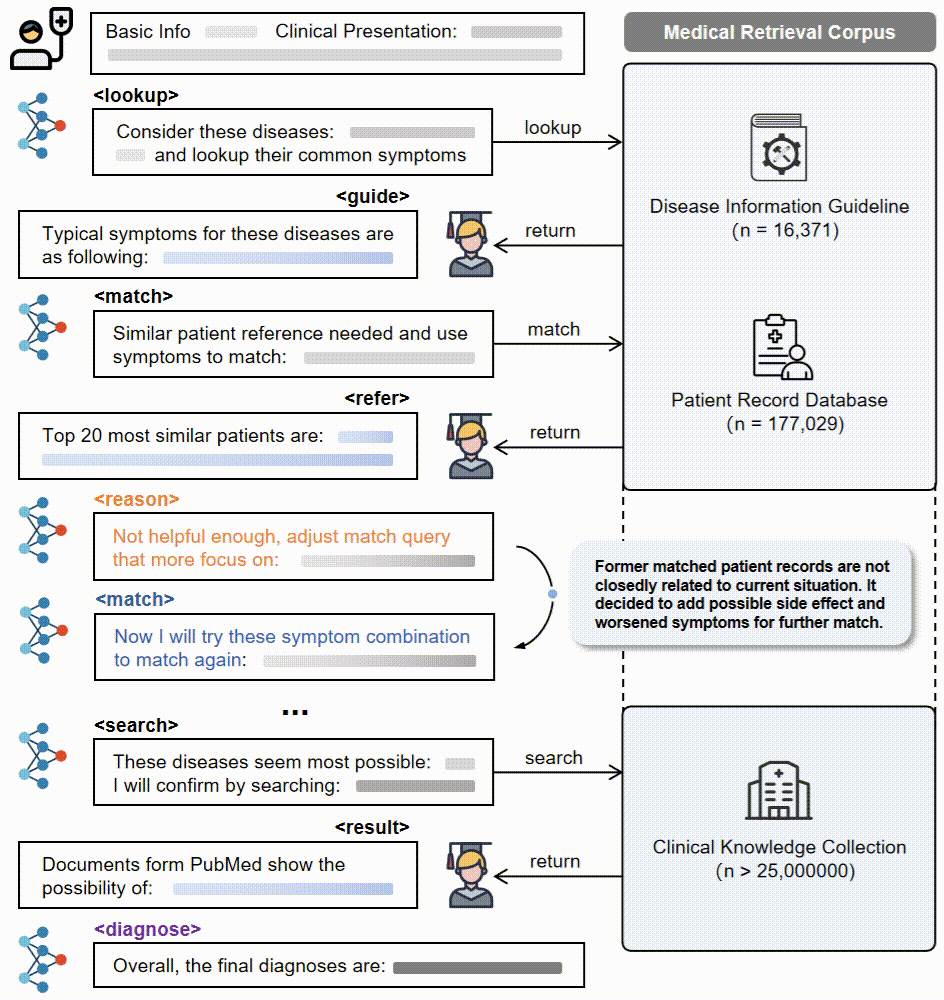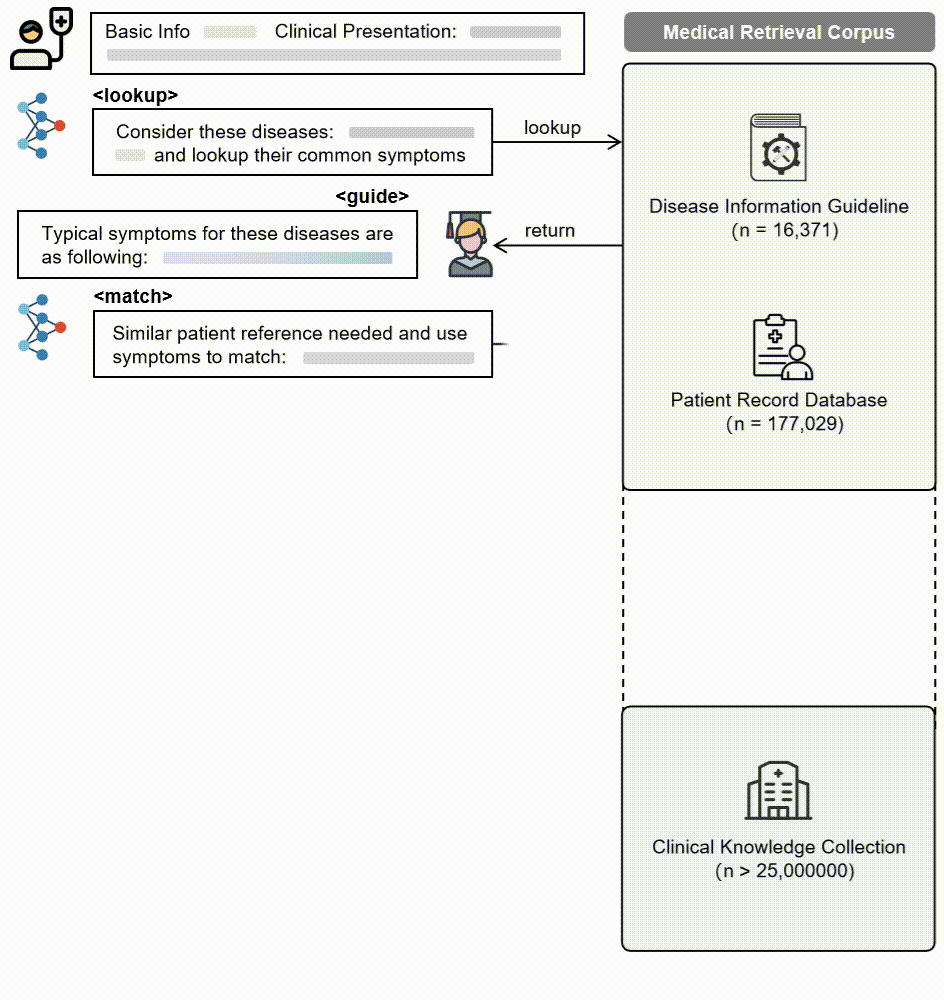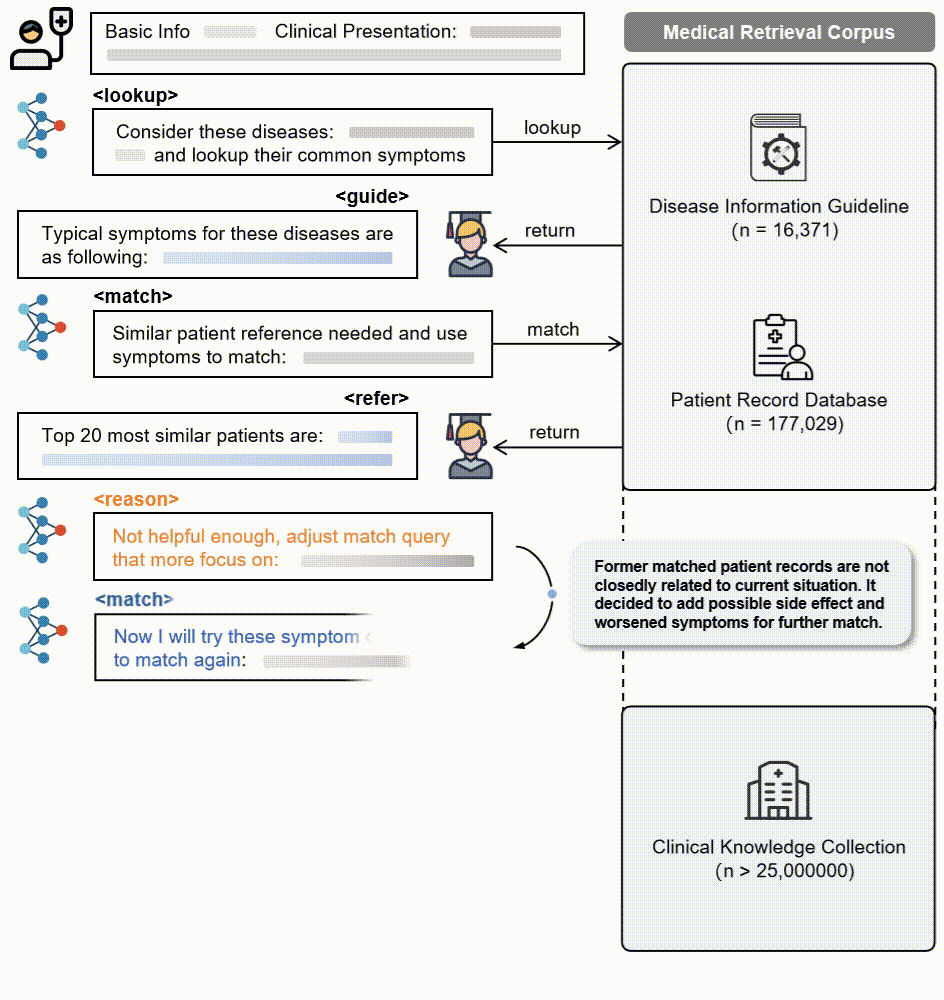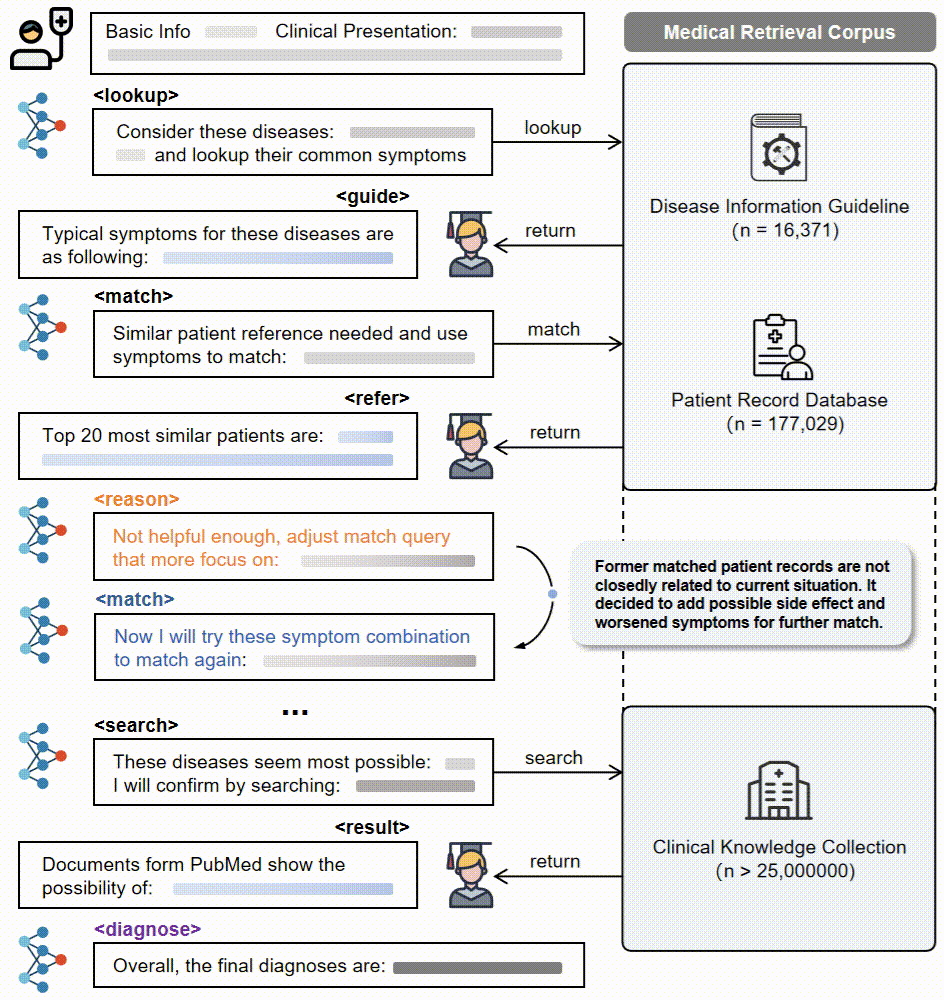
实验表明,我们的端到端代理强化学习训练框架在多个数据中心一致性地优于提示工程和免训练的RAG方法。经过训练后,Deep-DxSearch在诊断准确性方面取得了实质性提升,超越了强大的诊断基线,如GPT-4o、DeepSeek-R1以及其他针对常见和罕见疾病的专业医学框架,无论是在分布内(ID)还是分布外(OOD)环境下进行疾病诊断。此外,对奖励设计和检索语料库组件的消融研究确认了它们的关键作用,这突显了我们方法与传统实现相比的独特性和有效性。最后,案例研究和可解释性分析突显了Deep-DxSearch在诊断策略上的改进,为其性能提升提供了更深入的见解,并支持临床医生提供更可靠和精确的初步诊断。
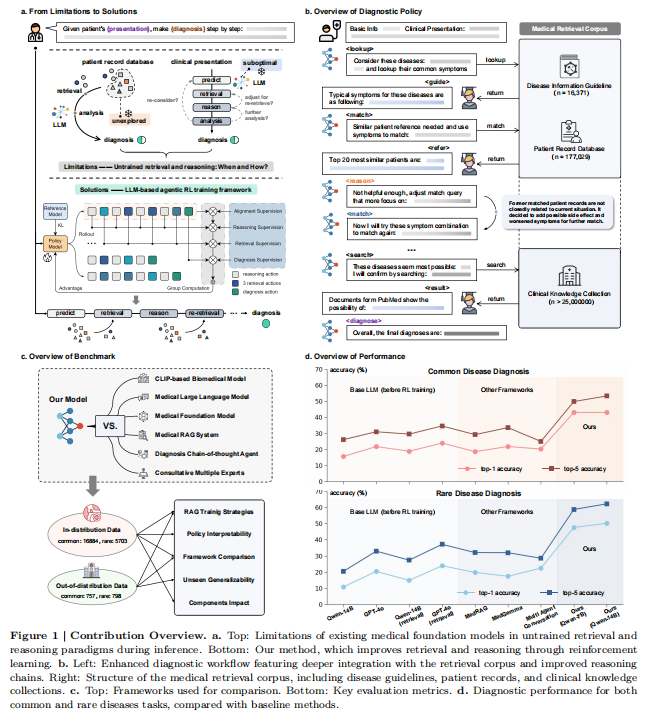
核心速览
研究背景
- 1.研究问题:这篇文章要解决的问题是医学大型语言模型在诊断过程中由于知识局限性和幻觉导致的准确性问题。尽管检索增强生成(RAG)和工具增强代理方法在缓解这些问题方面显示出潜力,但由于外部知识的利用不足和反馈推理的可追溯性脱节,这些方法仍然存在局限性。
- 2.研究难点:该问题的研究难点包括:推理与检索的交替工作流程过于僵硬;过度依赖手工制作的查询提示;以及有限的基于反馈的适应性。
- 3.相关工作:该问题的研究相关工作包括基于LLM的代理检索增强生成RAG系统,但这些系统通常是推理模型,没有端到端训练,导致在高风险的诊断环境中表现脆弱。
研究方法
这篇论文提出了Deep-DxSearch,一种用于医学诊断的代理RAG系统,通过强化学习(RL)进行端到端训练。
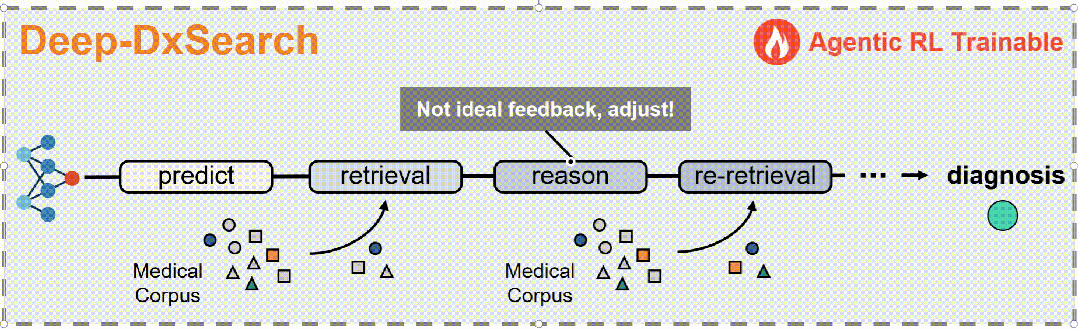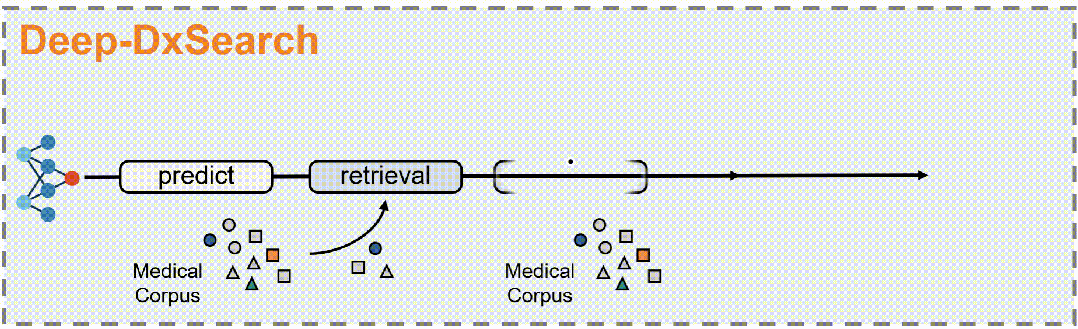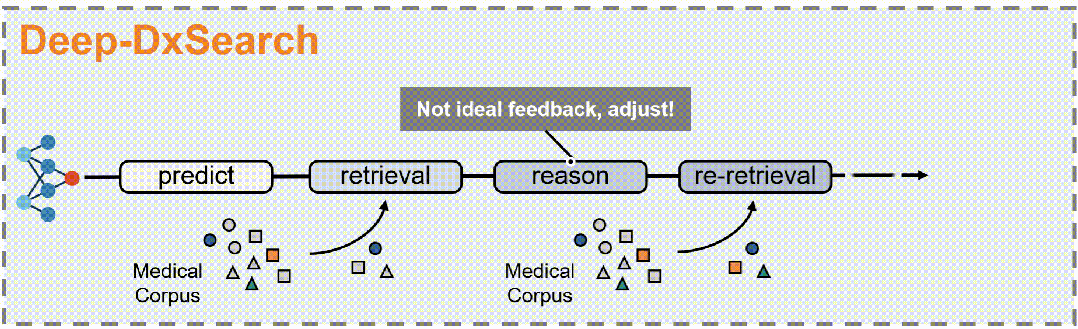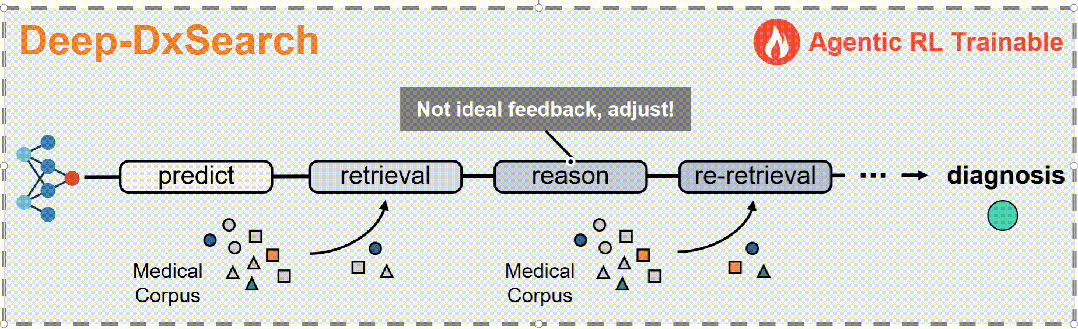
具体来说,
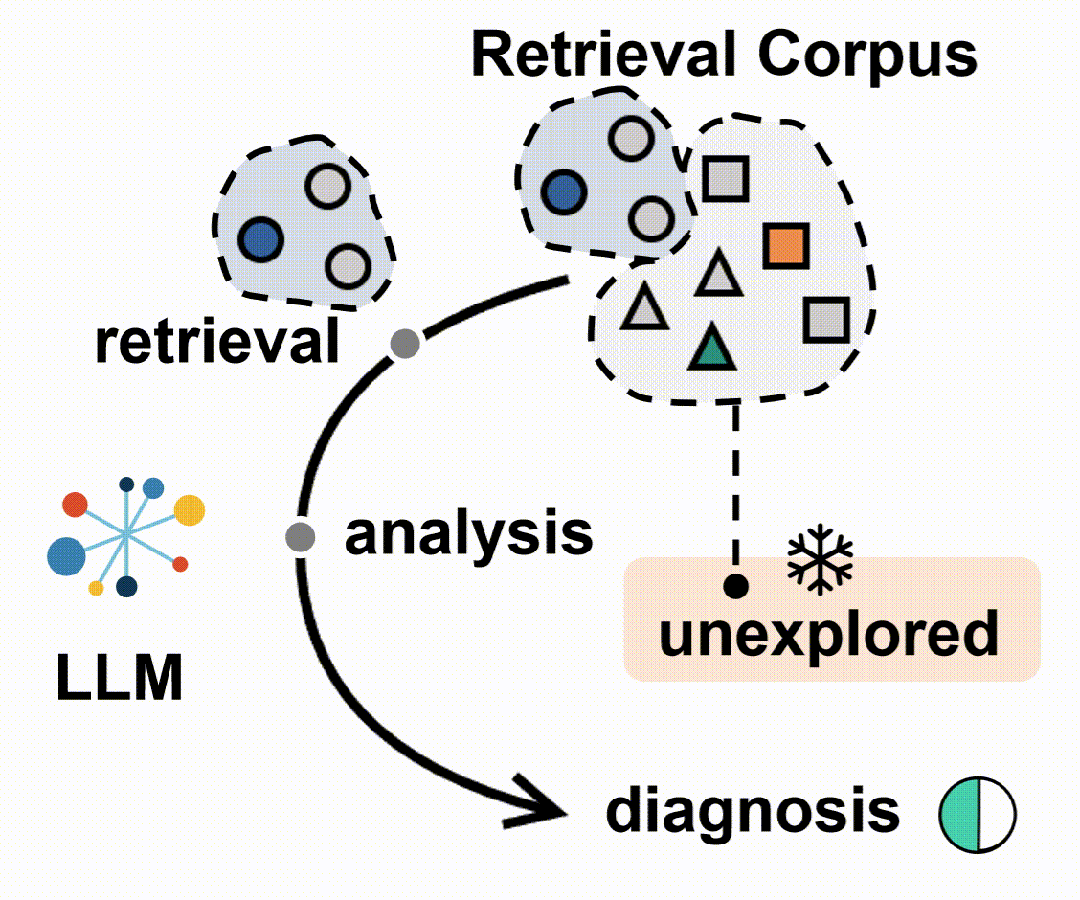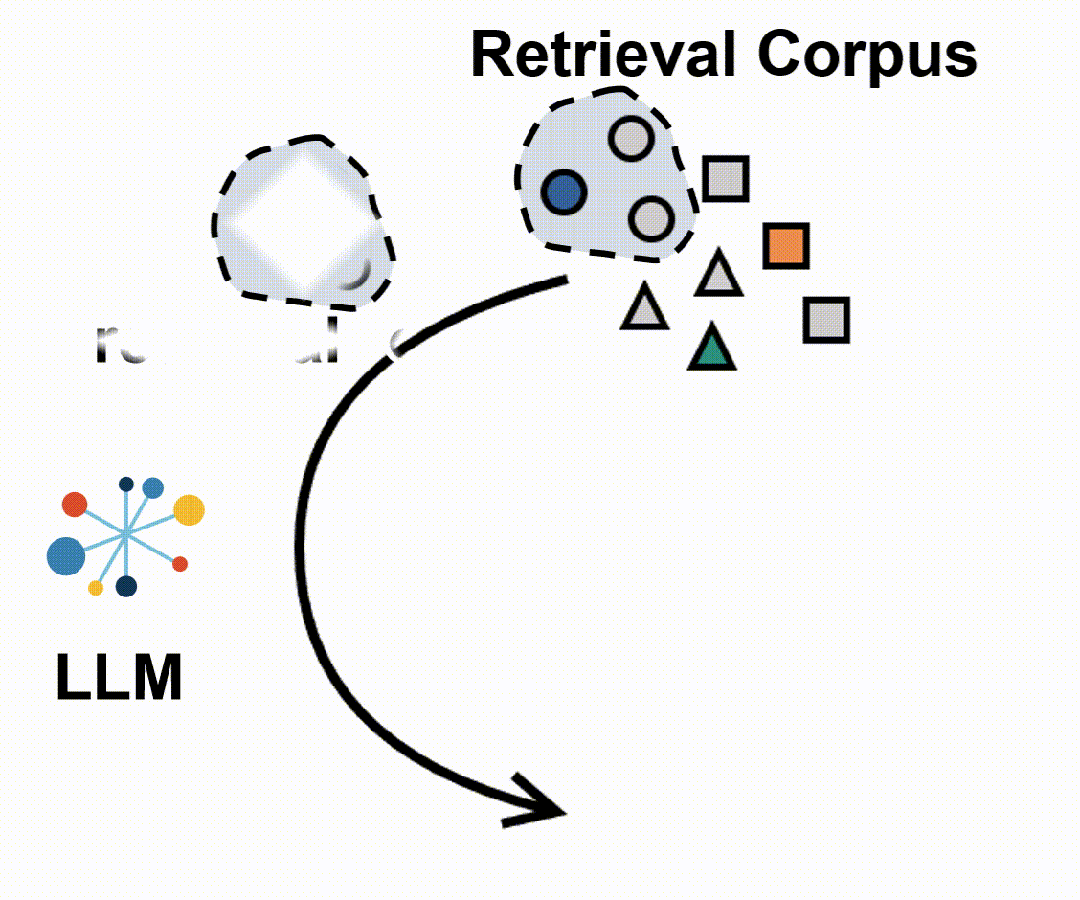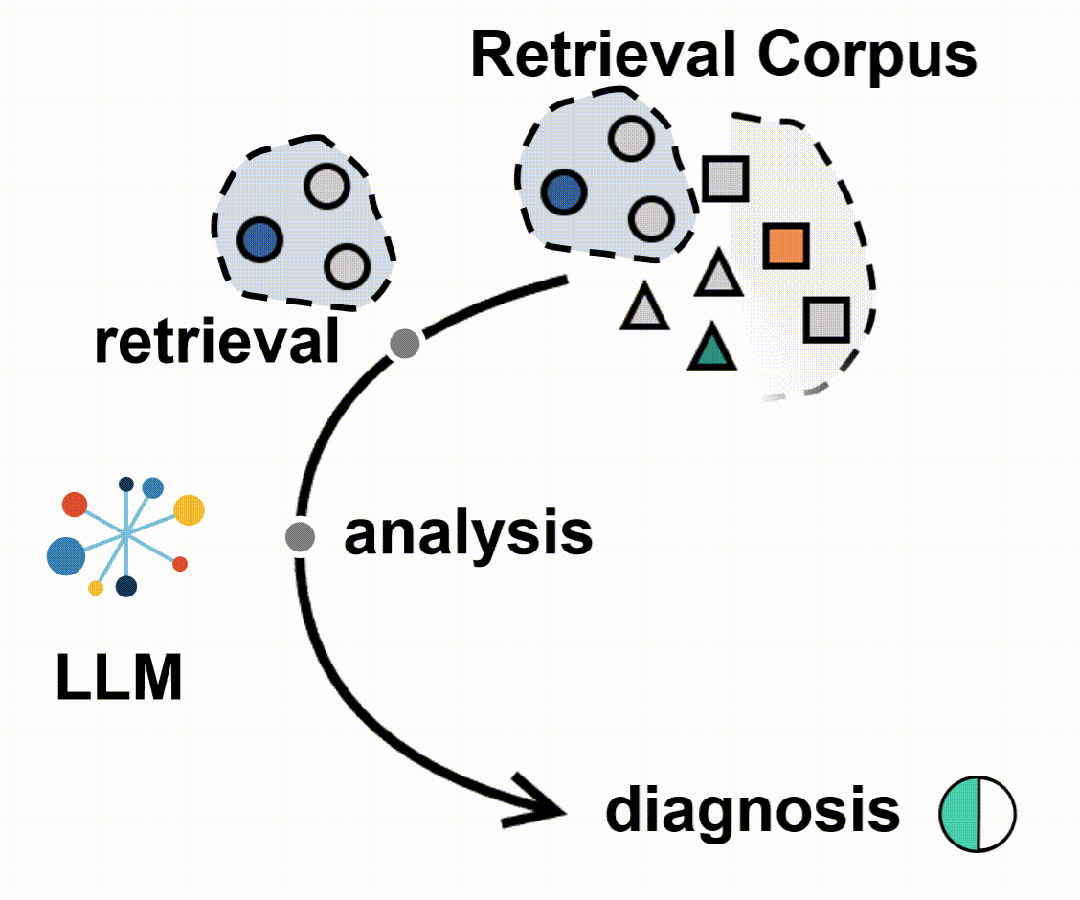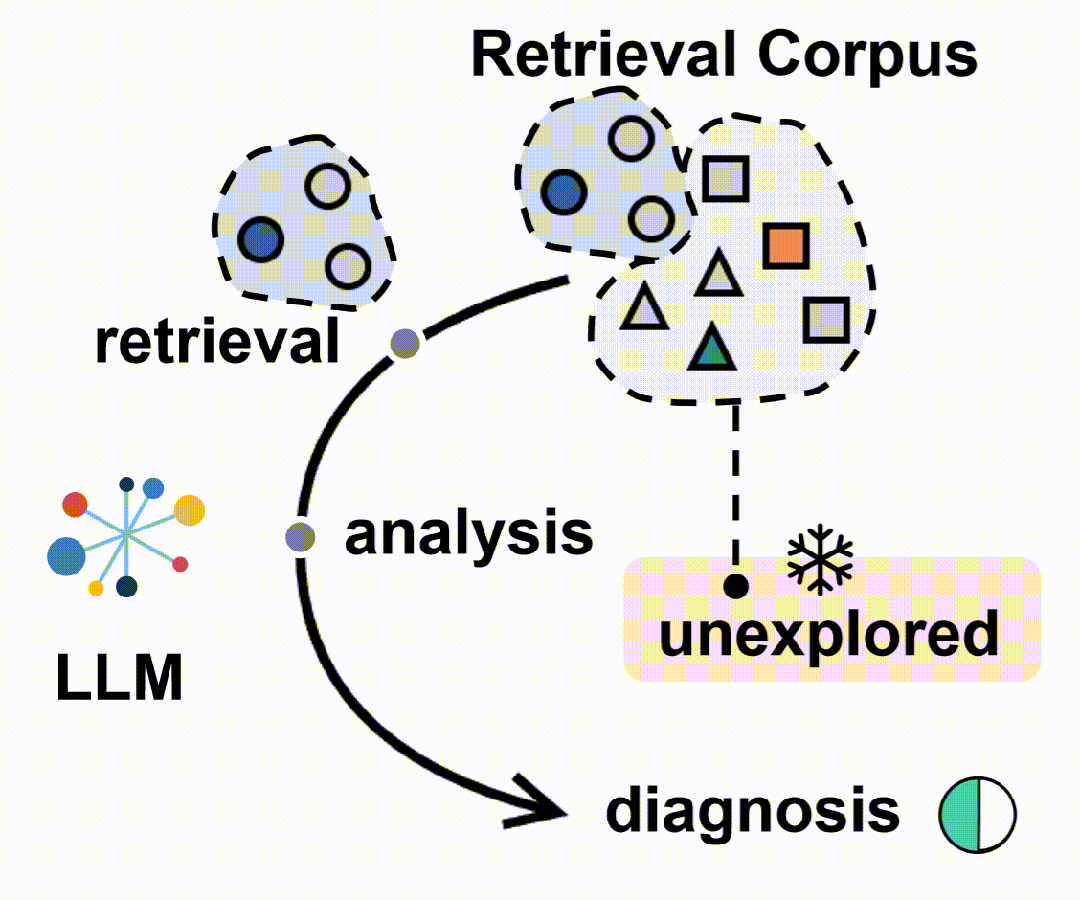
- 构建大规模医学检索语料库:首先,构建了一个包含患者记录和可靠医学知识来源的大规模医学检索语料库,以支持跨诊断场景的检索感知推理。
2. 代理RAG策略:将LLM作为核心代理,检索语料库作为其环境,使用格式、检索、推理结构和诊断准确性方面的定制奖励,从而通过RL从大规模数据中进化代理RAG策略。
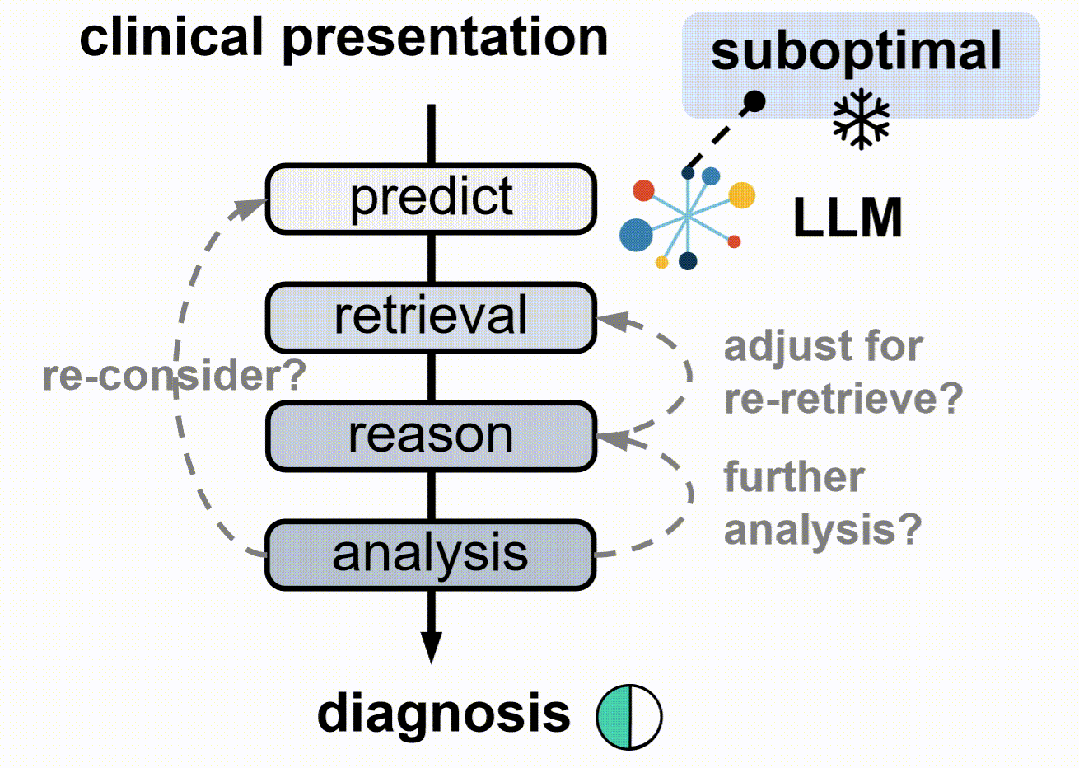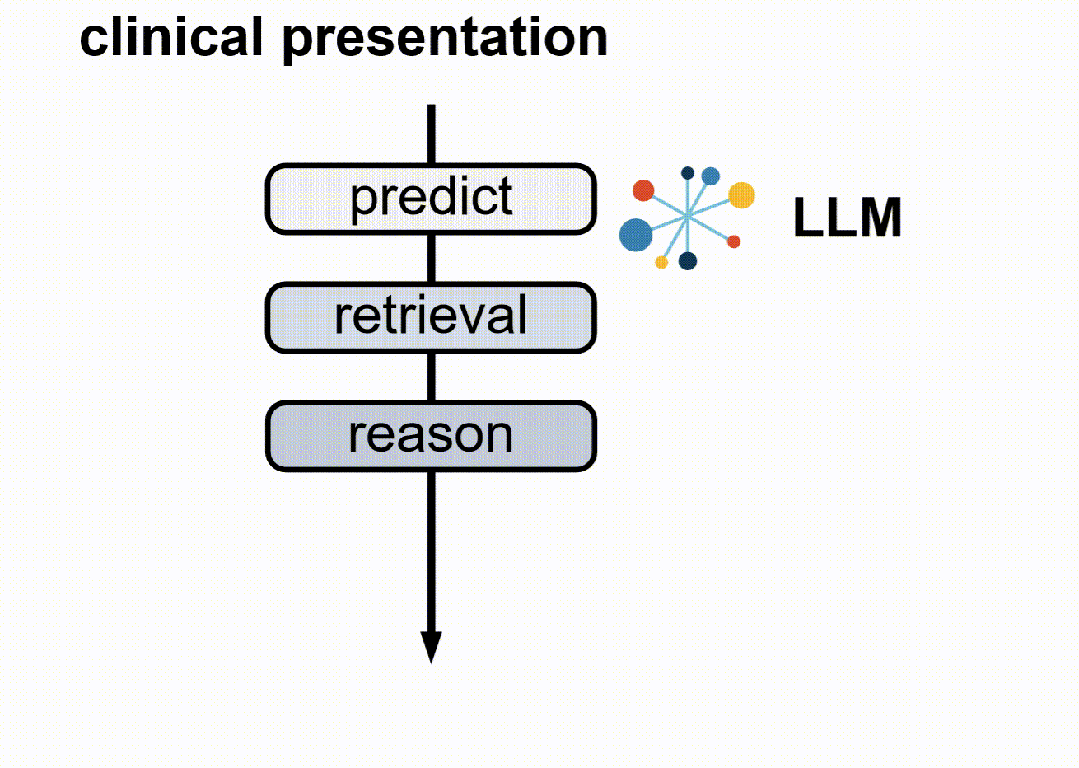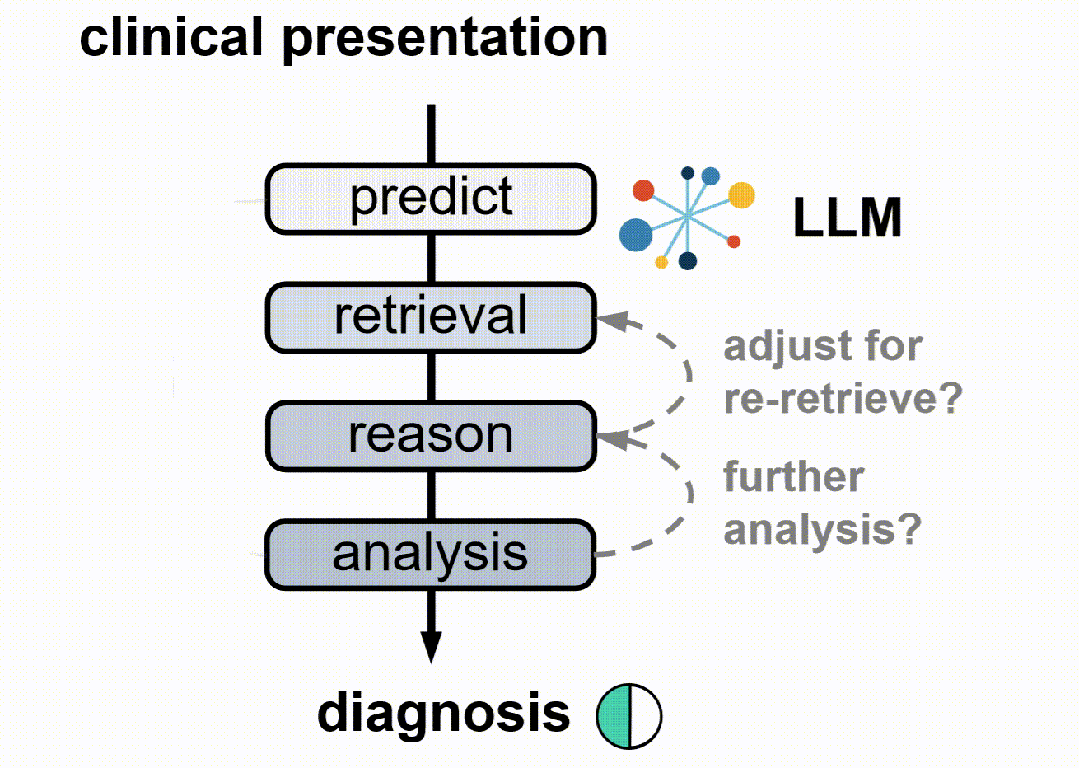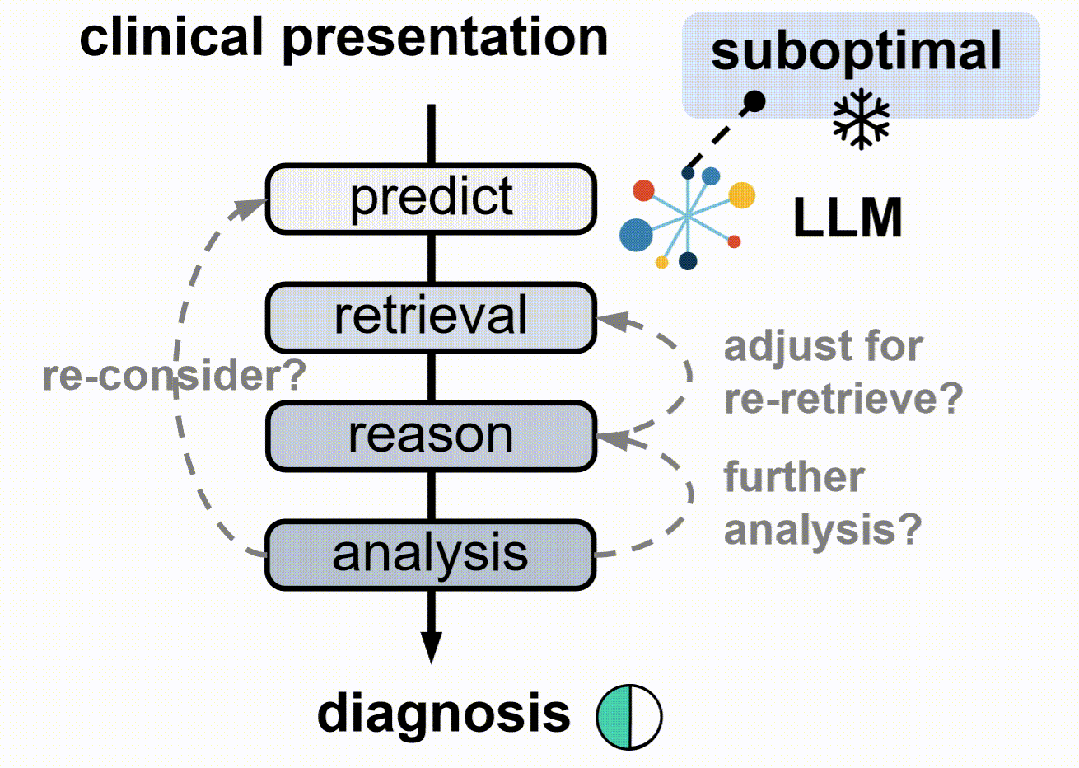
3. 动作模式:LLM基于代理的核心操作通过五个动作模式获取证据并逐步推理:推理、查找、匹配、搜索和诊断。
4. 奖励设计:设计了最终的奖励方案,涵盖输出格式、检索质量、分析组织和诊断准确性四个维度,以指导代理RAG系统。
5. 强化学习框架:将代理RAG系统构建在一个标准的强化学习(RL)框架内,包括一个基于LLM的代理和一个包含大规模临床语料库的外部环境。代理在每个步骤中选择一个动作类型,生成相应的文本规范,环境响应动作并返回检索反馈。代理执行一系列交替的动作,直到最终诊断动作。
实验设计
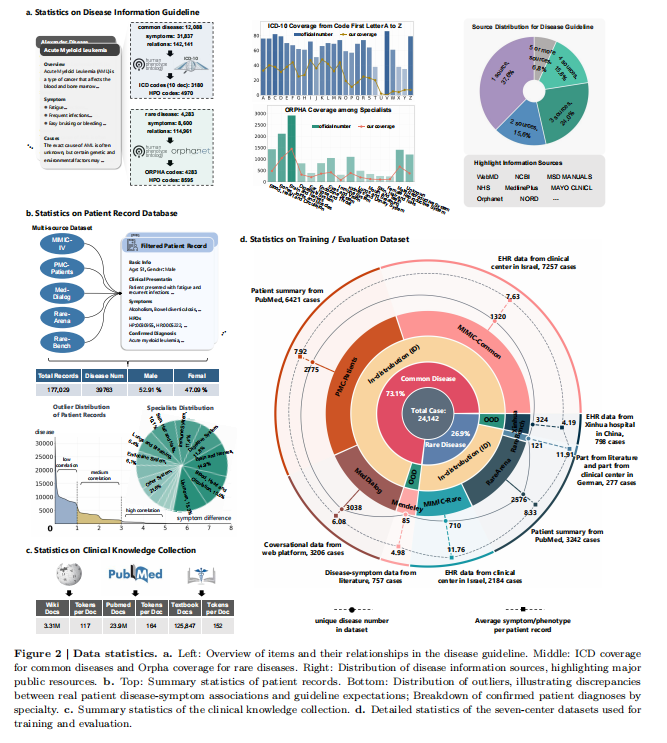
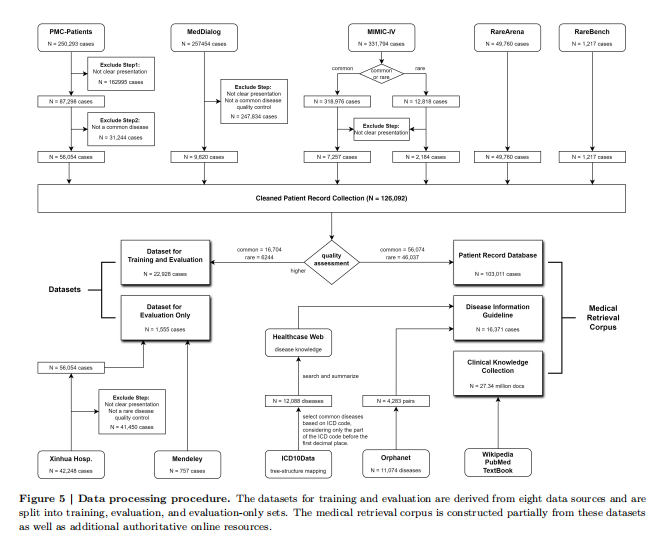
- 数据收集:构建了一个综合医学数据资源,包括医学检索语料库、患者记录数据库和临床知识集合。检索语料库整合了多样的医学知识,涵盖了常见和罕见疾病。
2. 数据集划分:从多个来源收集了24,142个临床病例,每个病例包含临床表现和确诊诊断。数据集按Orphanet编码系统分为常见疾病和罕见疾病两组。
3. 训练与评估数据集:将前五个ID数据集按3:1的比例划分为训练和评估数据集,剩余的两个数据集用于OOD评估。
4. 对比方法:将Deep-DxSearch与直接推理的vanilla模型、训练无RAG方法和目标仅RL训练进行对比,评估其在不同LLM骨干上的有效性。
结果与分析
-
ID评估:在ID评估中,Deep-DxSearch在常见疾病和罕见疾病的top-1准确率上分别提高了23.56%至30.94%和21.61%至52.41%。与vanilla Qwen2.5-14B相比,Deep-DxSearch在MedDialog和RareBench上的top-1准确率分别提高了24.12%和35.78%。
-
OOD评估:在OOD评估中,Deep-DxSearch在Mendeley和Xinhua医院的top-1准确率上分别提高了8.87%和15.12%。与RAG基线相比,Deep-DxSearch在Mendeley和Xinhua医院的top-1准确率分别提高了4.50%和7.51%。
-
对比其他诊断SOTA方法:Deep-DxSearch在常见疾病和罕见疾病的诊断任务上均优于其他SOTA方法,包括GPT-4o和DeepSeek-R1。在常见疾病数据集上,Deep-DxSearch的top-1准确率为43.04%,在罕见疾病数据集上为49.25%。
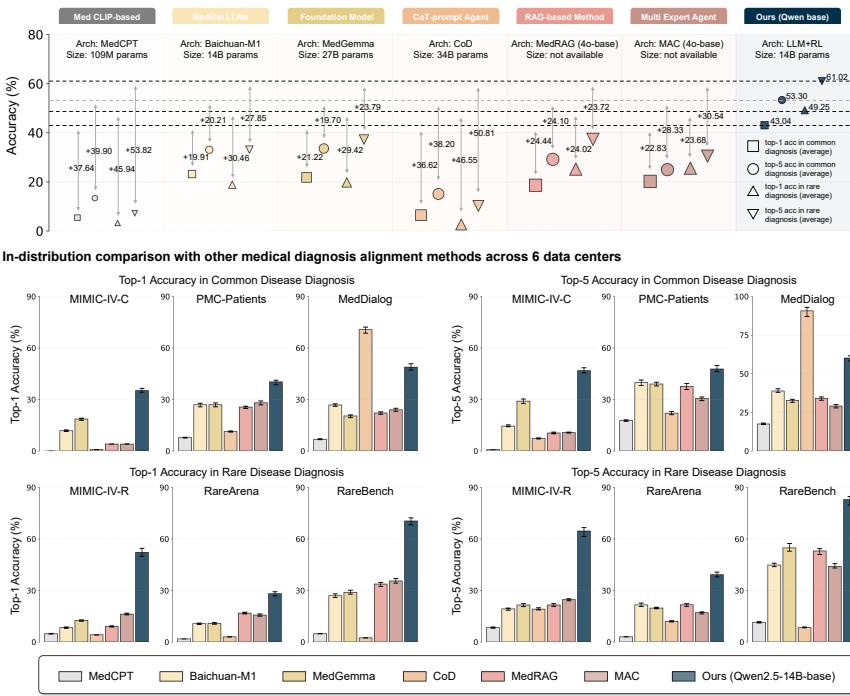
-
消融研究:奖励设计和检索语料库组件的消融研究表明,所有组件都对性能有显著贡献,其中患者记录检索最为关键。
-
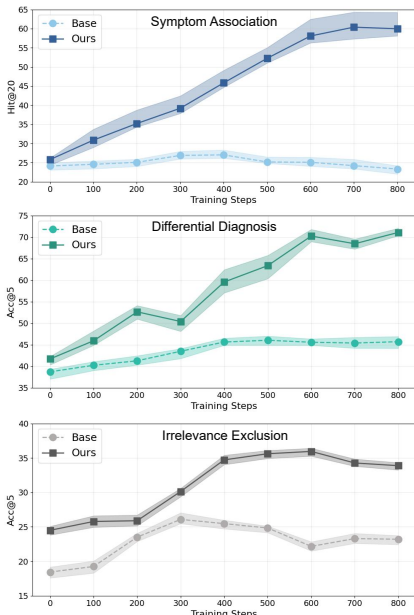
可解释性分析:通过可解释性量化分析,发现Deep-DxSearch在训练过程中逐渐改进了其诊断策略,增强了检索、推理和鲁棒性。
总体结论
这篇论文提出的Deep-DxSearch通过端到端RL训练,显著提高了医学诊断的准确性和可靠性。Deep-DxSearch不仅构建了大规模、异构的临床语料库,还通过软奖励RL框架联合优化了代理RAG策略和推理过程。实验结果表明,Deep-DxSearch在常见疾病和罕见疾病的诊断任务上均优于现有的SOTA方法,具有广泛的应用前景。未来的工作将重点评估Deep-DxSearch在实际临床诊断环境中的有效性及其在不同临床中心的适应性。
正如人工智能研究中著名的"苦涩教训"所强调的那样:虽然人类知识和手工设计的策略可能带来短期收益,但长期进步依赖于从大规模数据中挖掘统计规律。
我们认为,当前无需训练的代理人工智能设计正在经历这一"苦涩教训"的"代理版本"。作为可追溯诊断推理的一个具体步骤,我们的Deep-DxSearch展示了如何通过释放大规模医疗数据的力量来发展当前的代理系统。

论文评价
优点与创新
1.大规模医学检索语料库:构建了迄今为止最大的医学检索语料库,包括1500多种疾病的指南、170,000多个患者记录和数十亿条在线医学资源和科学文献的条目。
2.端到端训练:通过强化学习(RL)对代理RAG策略进行端到端训练,使系统能够在大规模数据中自我学习最优的检索和推理轨迹。
3.多动作模式:LLM核心操作通过五个动作模式(推理、查找、匹配、搜索、诊断)逐步获取证据并进行透明推理。
4.定制化奖励设计:设计了针对检索和推理策略联合优化的最终奖励方案,涵盖输出格式、检索质量、分析组织和诊断准确性四个维度。
5.显著性能提升:在多个数据中心的交叉验证中,端到端代理RL训练框架一致性地优于提示工程和免训练RAG方法,诊断准确性显著提升。
6.消融研究:对奖励设计和检索语料库组件进行了消融研究,确认了它们的关键作用,凸显了该方法与传统实现相比的独特性和有效性。
7.案例研究和可解释性分析:通过案例研究和可解释性分析,深入探讨了Deep-DxSearch诊断策略的改进,提供了对其性能提升的更深层次理解,并支持临床医生提供更可靠和精确的初步诊断。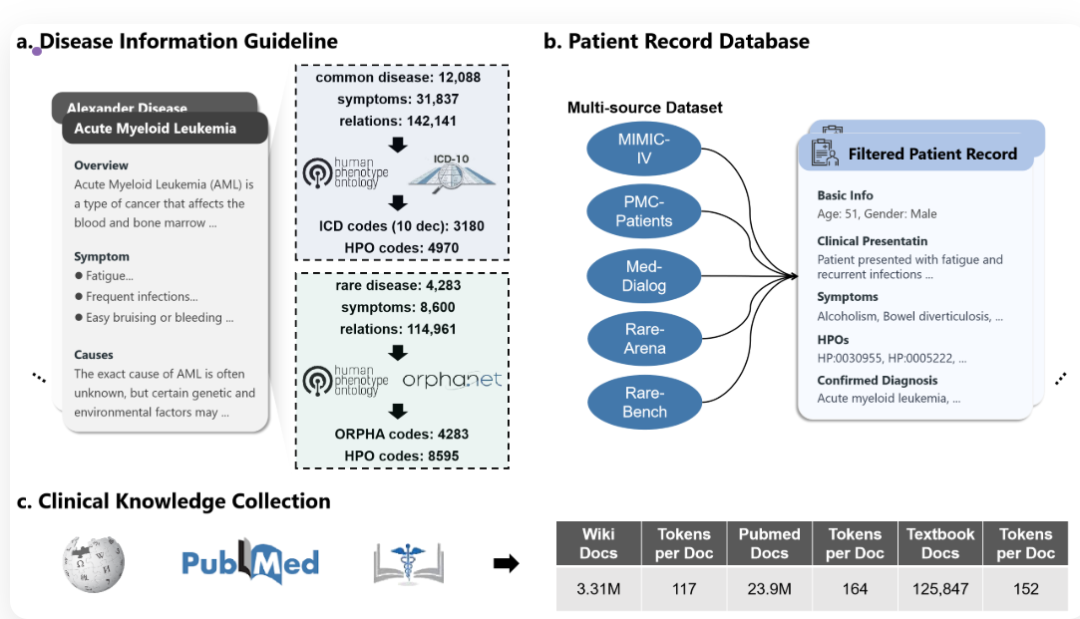
不足与反思
1.实时诊断设置的临床验证:尽管Deep-DxSearch在多个基准测试中表现出色,但尚未评估其在实际临床环境中的实时诊断支持能力。未来的工作将集中在临床验证上,以确定其在部署中的实际有效性和协作潜力。
2.特定临床中心的定制化限制:当前的检索语料库虽然全面,但对特定临床中心的定制化有限,这可能限制了框架全面捕捉当地临床上下文的能力。未来的努力将集中于促进更广泛的采用和对多样化临床环境的精确适应。
3.其他医疗领域的适用性:评估仅限于诊断任务;该方法在其他关键医疗领域(如治疗计划和患者随访)的适用性尚未测试。扩展框架以涵盖更广泛的医疗任务和开发补充工具(不仅仅是基于检索的推理)将是未来方向的重要部分。
关键问题及回答
问题1:Deep-DxSearch如何通过强化学习(RL)优化代理RAG策略?
Deep-DxSearch通过构建一个大规模医学检索语料库,并将其作为代理的环境,使用强化学习(RL)来优化代理的检索增强生成(RAG)策略。具体来说,LLM作为核心代理,通过五个动作模式(推理、查找、匹配、搜索和诊断)逐步获取证据并进行推理。为了指导代理的决策,设计了四个维度的定制奖励:输出格式、检索质量、分析组织和诊断准确性。这些奖励共同作用于代理的决策过程,使其能够在检索和推理过程中不断学习和优化,最终实现更准确的诊断结果。
问题2:Deep-DxSearch在实验中如何验证其有效性和鲁棒性?
Deep-DxSearch通过多种实验设置验证了其有效性和鲁棒性。首先,在分布(ID)评估中,Deep-DxSearch在常见疾病和罕见疾病的top-1准确率上分别提高了23.56%至30.94%和21.61%至52.41%,显著优于直接推理的vanilla模型和训练无RAG方法。其次,在零样本(OOD)评估中,Deep-DxSearch在Mendeley和Xinhua医院的top-1准确率上分别提高了8.87%和15.12%,进一步证明了其泛化能力。最后,通过与通用LLM(如GPT-4o)和其他医疗诊断SOTA方法(如DeepSeek-R1)的对比,Deep-DxSearch在常见疾病和罕见疾病的诊断任务上均表现出色,显示出其在实际应用中的鲁棒性和优越性。
问题3:Deep-DxSearch的检索语料库是如何构建的,它包含了哪些关键组件?
Deep-DxSearch的检索语料库是通过整合多种医学知识和数据源构建的,包含以下关键组件:
- 1.疾病信息指南:从ICD-10-CM、Orphanet和HPO等数据库中提取了超过15,000种疾病及其特征症状和表型,涵盖了常见和罕见疾病。
- 2.患者记录数据库:包含了来自MIMIC-IV、PMC-Patients、MedDialog等数据源的177,029条经过验证的患者记录,涉及14个主要人体系统。
- 3.临床知识集合:整合了来自Wikipedia、PubMed和18本标准医学教科书的3.31百万篇生物医学文档,提供了广泛的临床知识支持。
这些组件共同构成了一个多样化、多源的医疗检索语料库,为Deep-DxSearch提供了丰富的证据支持和诊断依据。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献341条内容
已为社区贡献341条内容

所有评论(0)