大模型长文本处理的秘密:检索头机制完全解析,收藏级干货!
本文揭示了大模型处理超长文本的核心机制——检索头(retrieval heads)。这些特殊的注意力头负责从长上下文中检索关键信息,具有普遍稀疏、固有存在、动态激活和因果性四大特点。研究通过"大海捞针"实验和检索分数量化检测方法,并基于此提出DeCoRe技术,通过对比解码减少模型幻觉。实验表明,DeCoRe能显著提升模型的上下文忠实度、事实召回能力和多步推理能力,为解决大模型幻觉问题提供了新思路。
一、论文信息

论文封面
北京大学(Peking University)、华盛顿大学(University of Washington)、麻省理工学院(MIT)、伊利诺伊大学厄巴纳 - 香槟分校(UIUC)、爱丁堡大学(University of Edinburgh)等众高校于2024年4月发布论文Retrieval Head Mechanistically Explains Long-Context Factuality,探讨了LLMs在处理超长文本时找到关键信息得潜在机制。
二、论文概述
论文试图解释,LLMs在处理超长文本时,怎么能从一大堆信息中快速找到关键点?作者用了大海捞针实验回答这个问题。所谓大海捞针指的是,给模型一段超长上下文(海),要求LLM从“海”中精确检索某一个短句(针)的信息。
论文通过对Llama、Qwen等4个模型家族、6种模型规模和3种微调类型的广泛实验,论文发现在模型的注意力层中,存在少量的检索头(retrieval heads),这些注意力头负责搜索被询问的信息,并将输入中的相关token重定向到输出。
论文基于已有研究提出一种假设:LLM内部存在一些特殊头负责信息检索,并实现条件复制粘贴算法。作者发现检索头具有几个重要特性:
- • 普遍且稀疏:对于任何模型家族(LLaMA、Yi、QWen和Mistral),任何规模(6B、14B、34B和8×7B),无论是基础模型还是聊天模型,无论是密集模型还是MoE,只要模型能够精确复述输入信息,它们都有一小组检索头。
- • 固有性:基础模型在预训练后已包含检索头。后续的衍生模型,如LLaMA2-7B-80K、Qwen-Chat,使用的仍然是与基础模型相同的检索头
- • 动态激活:最强的检索头无论所需信息是什么,始终会被激活;而较弱的检索头则根据所需信息的不同部分被激活。
- • 因果性:当在输入中放置一个“针”:“在旧金山最好的活动是在公园吃三明治”。如果完全屏蔽检索头,模型会产生幻觉(输出:最好的活动是参观金门大桥);如果部分屏蔽检索头,模型只能检索部分信息(例如记得三明治但忘了公园);如果屏蔽随机的非检索头,模型仍能完整找到“针”;如果未屏蔽检索头但模型仍产生幻觉,则说明检索头未被激活。
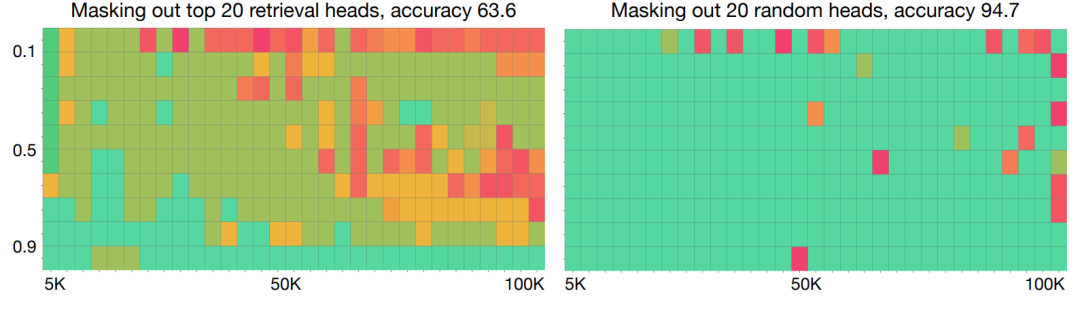
以上两幅热力图展示了在屏蔽不同注意力头时(屏蔽:把某个头的输出全部置0),LLaMA-2-7B-80K模型在“大海捞针”测试中的表现。深绿色表示高准确率,红黄色表示低准确率。横轴表示输入上下文的长度(从5K到100K),纵轴表示准确率。图分为左右两部分:左图屏蔽了前20个最高得分检索头,准确率下降到63.6%;右图屏蔽了20个随机非检索头,准确率保持在94.7%。初步证明了检索头是模型检索信息的核心;论文还注意到检索头只影响事实性,而不影响语言流畅性。
三、如何检测检索头
检索头是Transformer模型中注意力头的一种特殊子集,负责从长上下文中检索相关信息并将其复制粘贴到输出中。其中复制粘贴指的是检索头通过注意力机制从输入序列中直接提取特定的token,并将其原封不动地用于生成输出序列。
检索分数
论文引入了以下检索分数来衡量一个头的复制粘贴行为频率,并结合“大海捞针”测试检测检索头。
:某个注意力头的检索分数
:针,即需要检索的关键信息(例如“the best thing to do in San Francisco is to eat a sandwich”)
:由头 在解码过程中复制输入token并粘贴到输出的token集合
: 与 的交集大小,即头 正确复制到输出中的 的token数量。
:关键信息 的token总数,作为归一化因子。
检索分数本质上是一个token级别的召回,表示头 在生成答案时,成功从 中复制了多少比例的token。分数范围在 [0, 1] 之间,1 表示完全复制,0 表示完全未复制。当满足以下两个条件时,token算作“被复制”:
- • 前生成的token 属于关键信息 (),意思是输出的词需要来自关键信息。
- • ,其中 且 。
对于条件二, 是头 在当前解码步骤生成的对输入序列的注意力分布, 表示头 对输入 中第 个token的注意力分数;指输入序列中最受关注的token索引为 ;要求输入序列中第 个token()必须与当前生成的token 相同,即头 最关注的输入token恰好是输出 本身。

如上图所示,一段100K的上下文中含有“针”,一个注意力头在生成token eat时,注意力高度集中于输入中的“eat”,这意味着该头通过复制粘贴输入的eat,并“粘贴”到输出中,实现了对问题的回答。这种行为是检索头的主要功能。
大海捞针
作者使用“大海捞针”实验,模拟从长上下文中检索短句的场景。
针对某一次实验,作者先构造一个长上下文,长度从1K~50K 不等;再设计一个短句,插入到 的10个不同深度(均匀分布在 的起点到终点),每次测试调整位置;最后设计一个问题,要求LLM从 上下文 中检索 回答。
是和、 完全无关的文本,确保答案只能从 复制,而非依赖模型的内部知识。
如果一个头的平均检索分数 ≥ 0.1,说明它在10%以上的时间里执行了复制粘贴操作,判定为检索头。
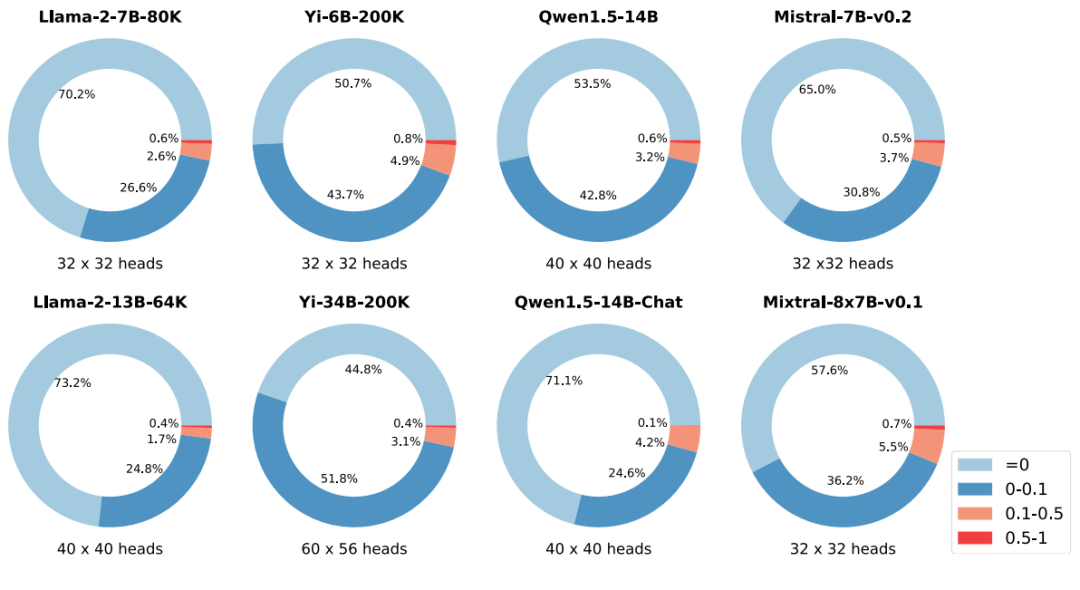
上图表明检索头在模型族和规模上是普遍且稀疏。对于论文考虑到的模型,当需要检索时,只有不到5%的注意力在50%以上的时间(检索分数>=0.5)被激活。
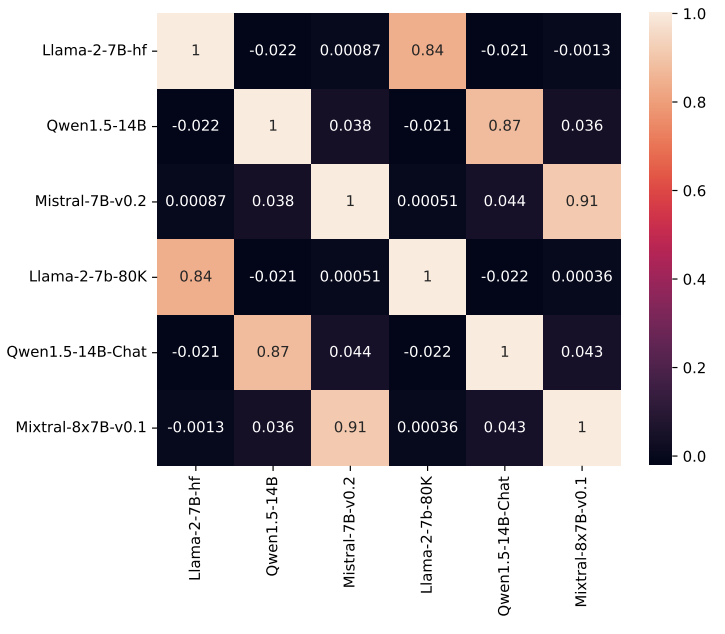
以上热力图展示了一系列语言模型及其变体之间的检索头相关性,每个单元格中的数字是两个模型之间Pearson相关系数,衡量了两个模型的检索头分数分布之间的线性相关性。上图表明同一家族内的检索头分数分布具有高相关性,不同家族间的相似度较低。
后续有研究利用检索头降低LLM的幻觉频率。DeCoRe: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations,简称DeCoRe(对比头解码)。

DeCoRe 作者在了解到屏蔽头之后,自然地提出一个假设:屏蔽检索头会削弱模型从上下文中提取相关信息的能力,从而诱发幻觉。DeCoRe利用对比解码放大原始输出和幻觉输出之间的差异,从而生成更准确的最终响应,并使用模型下一词分布的条件熵来控制对比解码机制。
DeCoRe通过先前的检索头论文介绍的方法,找出检索头并按照每个检索头的检索分数排序,选取排名前 的头作为检索头,记为 ,其中 是层索引, 是该层内的头索引。在 Transformer 架构中,第 层的多头注意力机制的输出为:
其中, 是注意力头的数量;、、 分别表示查询、键和值矩阵; 表示模型的隐藏维度, 是键的维度(其中 ; 表示输出投影层;每个头的计算方式为:
其中,、、 分别表示层 上的查询、键和值权重矩阵。为了屏蔽每个头(其中 ),我们定义一个掩码 如下:
然后,第 层的屏蔽多头注意力输出变为:
其中 表示标量乘法。屏蔽模型的标记对数概率由 给出,下一标记分布为:
下图展示了一个示例,显示屏蔽 10 个检索头后在 Llama3-8b-Instruct中诱发的幻觉。

DeCoRe使用以下公式实现对比解码:
- • : 基本模型的分布
- • : 屏蔽模型的分布
- • : 控制权重的标量因子
DeCoRe 还有基于条件熵动态选择超参数 的方法。对于给定的上下文 ,模型的下一个标记分布 的条件熵 定义为:
其中 表示模型的词汇表;较高的条件熵表明模型对其预测不确定(就是分布熵)。DeCoRe 建议将超参数 设置为 。
当基本模型的下一个标记分布的熵 增大时, 增加,公式中的 变大,放大了 的权重,与此同时 的负效应也变强,更多地压制了屏蔽模型的输出。最终效果是相对增强基本模型的可靠预测。
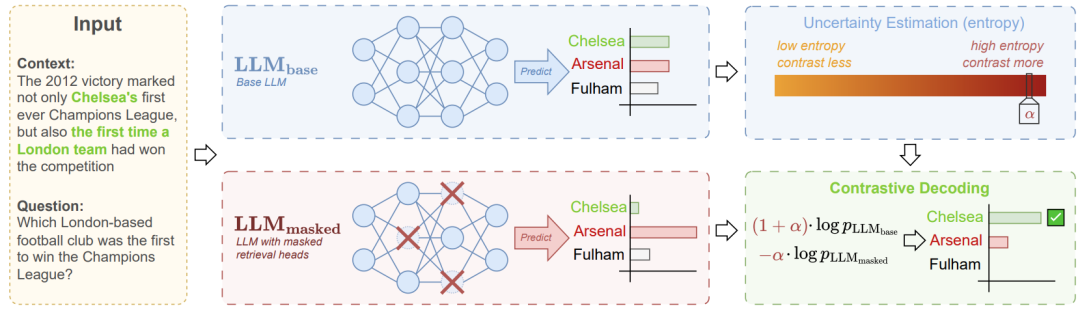
DeCoRe实验
实验围绕3个关键问题设计,旨在验证DeCoRe的效果:
-
- 能否提升模型的上下文忠实度(避免编造与给定信息矛盾的内容);
-
- 能否维持或增强模型的事实召回能力(准确回忆常识或事实);
-
- 与 CoT 结合时,能否提升模型的多步推理能力。
1. 数据集:覆盖3类核心任务
实验采用多类数据集,分别对应“忠实度”“事实性”“推理能力”的评估,具体如下:
| 任务类型 | 数据集名称 | 任务描述 |
|---|---|---|
| 忠实度评估 | XSum[1] | 抽象摘要任务,从BBC新闻中生成1句话摘要,验证摘要与原文的事实一致性 |
| MemoTrap[2] | 指令遵循任务,测试模型是否能避开自身参数限定、严格按给定指令输出 | |
| IFEval[3] | 指令遵循任务,评估模型对可验证指令的执行度 | |
| NQ-Open[4] | 开放域问答,提供1份支撑文档,验证回答与文档的匹配度 | |
| NQ-Swap[5] | 问答“陷阱”任务,替换原文中的答案实体,测试模型是否忠实于修改后的上下文 | |
| 事实性评估 | TruthfulQA | 事实准确性任务,包含多选(MC1/MC2/MC3)和生成任务,验证模型是否规避常见谬误 |
| TriviaQA | 常识问答任务,测试模型对 trivia 类事实的召回能力 | |
| PopQA | 长尾实体问答任务,测试模型对小众事实的记忆准确性 | |
| NQ-Open | 开放域问答,验证模型依赖内部知识的事实准确性 | |
| 推理评估 | MuSiQue | 多步推理问答任务,需整合多个分散信息才能回答,分闭卷/开卷、有无CoT设置 |
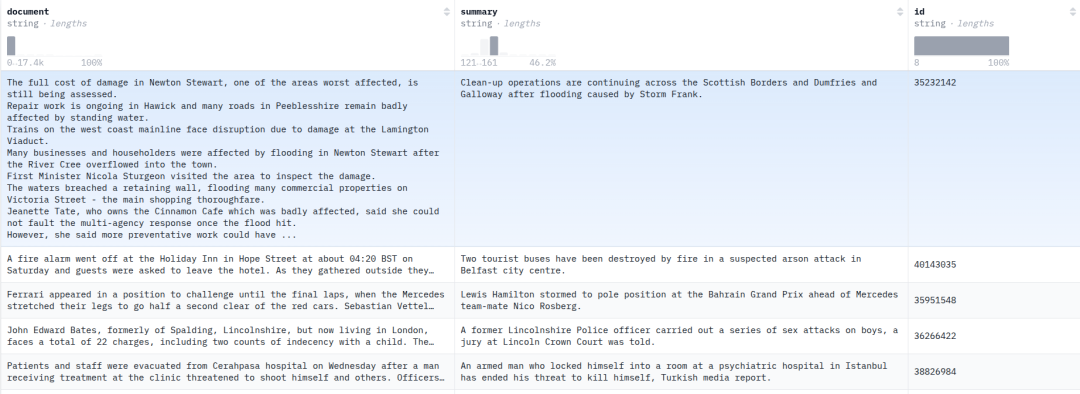
Xsum结构

MemoTrap
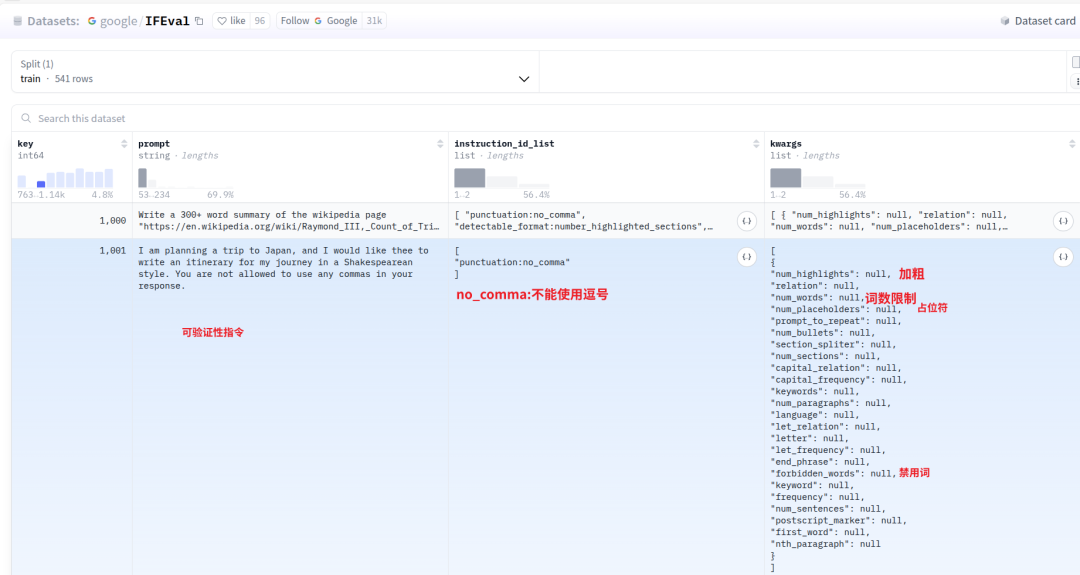
IFEval

NQ-Open
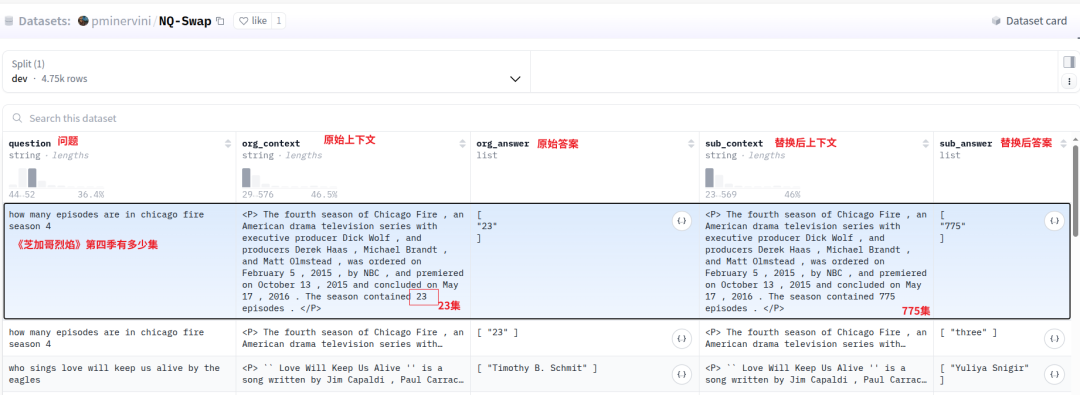
NQ-Swap
2. 评估指标:针对性衡量“准确性”与“忠实度”
不同任务采用对应的专业指标,核心分为3类:
| 指标类型 | 具体指标 | 适用任务/含义及原理 |
|---|---|---|
| 忠实度指标 | ROUGE-L | XSum任务,通过计算最长公共子序列的长度来评估摘要与原文的词级重叠,LCS越长说明忠实度越好。 |
| BERTScore-F1 | XSum任务,用BERT计算摘要与原文的语义相似度。 | |
| factKB | XSum任务,基于知识图谱对摘要中的事实性陈述进行验证,判断摘要是否准确反映原文中的实体关系和事实信息,减少事实错误。 | |
| Macro/Micro Accuracy | MemoTrap任务,计算每个类别准确率的平均值(平等对待所有类别),和总体样本的准确率,评估模型对复杂指令的遵循程度。 | |
| Prompt/Instruction Acc | IFEval任务,通过判断模型输出是否满足指令的全部/单个要求,计算符合要求的比例,评估指令理解与执行能力。 | |
| Exact Match(EM) | NQ-Open/NQ-Swap任务,直接对比预测结果与标准答案的文本一致性,评估答案的精确性。 | |
| 事实性指标 | MC1/MC2/MC3 | TruthfulQA多选任务,针对包含事实性问题的多选题,计算模型选择正确答案的比例,评估事实辨别能力。 |
| % Truth/% Info/% T∩I | TruthfulQA生成任务,评估回答的真实性、信息量及两者的交集。原理:% Truth衡量回答中真实内容的占比,% Info衡量回答包含的有效信息量,% T∩I衡量既真实又有信息量的内容占比,综合评估事实性与实用性。 | |
| EM | TriviaQA/PopQA/NQ-Open,对比模型生成的事实性答案与标准答案的文本一致性,评估模型在开放域事实问答中的精确性。 | |
| 推理指标 | EM | MuSiQue任务,针对需要多轮逻辑推理的问题,通过对比最终答案与标准答案的完全匹配度,评估模型在复杂推理链中的结论正确性。 |
实验模型
- • Qwen2-7B-Instruct
- • Mistral-7B-Instruct-v0.3
- • Llama3-8B-Instruct、Llama3-70B-Instruct
对比基线
将DeCoRe与现有减少幻觉的方法对比,涵盖不同技术思路:
| 基线方法 | 核心原理 |
|---|---|
| Greedy Decoding | 贪心解码 |
| Contrastive Decoding(CD) | 对比“专家模型”(大参数)与“业余模型”(小参数)的输出,放大准确内容 |
| Context-Aware Decoding(CAD) | 对比“给上下文的模型”与“不给上下文的模型”,增强上下文忠实度 |
| Decoding by Contrasting Layers(DoLa) | 对比模型“早期层”与“最终层”的输出,校准logits |
| Activation Decoding(AD) | 用中间层“上下文激活的尖锐度”校准下一个词的预测概率 |
| ITI | 训练线性分类器识别“事实性头/层”,推理时干预模型输出(需额外训练,非无训练方法) |
DeCoRe变体:验证动态调整的价值
- • DeCoRe_static:固定对比强度(α为静态值);
- • DeCoRe_entropy:用“条件熵”动态调整对比强度;
- • DeCoRe_entropy-lite:类似前者,但用更小的模型作为对比模型。
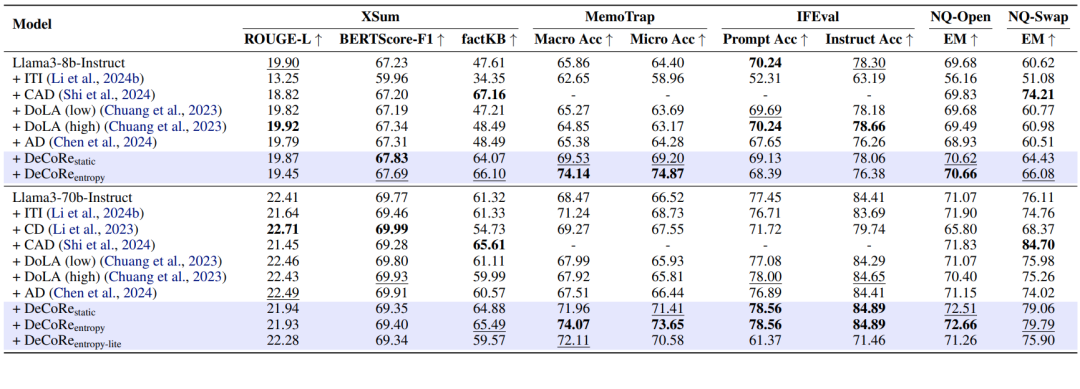
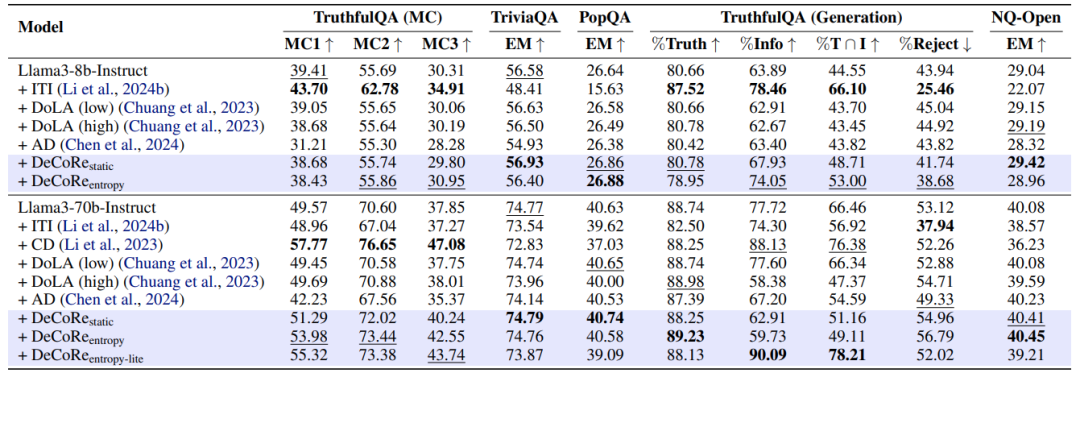
实验结果
最佳性能黑体加粗,次佳性能下划线表示
四、AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献361条内容
已为社区贡献361条内容

所有评论(0)