LLM学习笔记--2.1Transformer 架构-注意力机制
NLP任务中需要处理的文本往往以序列的形式出现,在注意力机制提出之前,专用于处理序列、时许数据的RNN常用来处理NLP任务。举例解释,若Q是“查找2024年奥运会举办地”,K是新闻全文的每个词,V是对应词的语义向量,注意力机制会计算Q与每个K的相关性,权重高的V被重点关注,最终输出“巴黎”的语义表示。以字典为例,假设查询值 Query 为“fruit”,所查询的文本内容为字典形式,字典中的键对应注
一、使用注意力机制的一些原因
作为NLP核心结构的文本表示方法逐渐从统计学习向深度学习方向迈进,通过神经网络学习文本表示。常用的神经网络方法核心架构有三种:
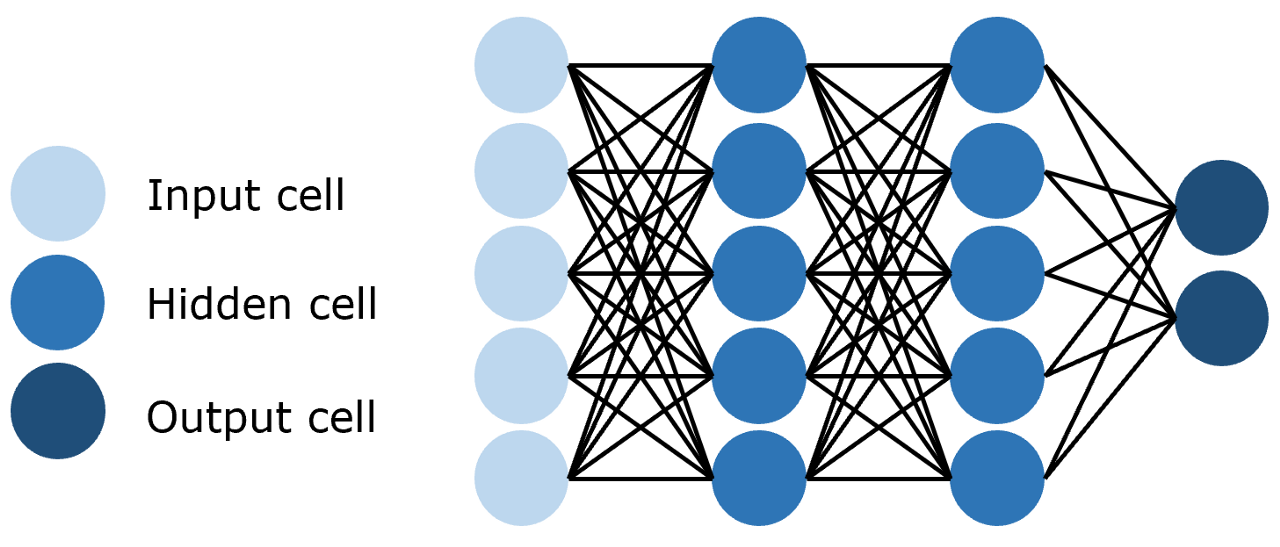
- 前馈神经网络(Feedforward Neural Network,FNN),层与层之间的神经元完全连接,其结构如下图所示:
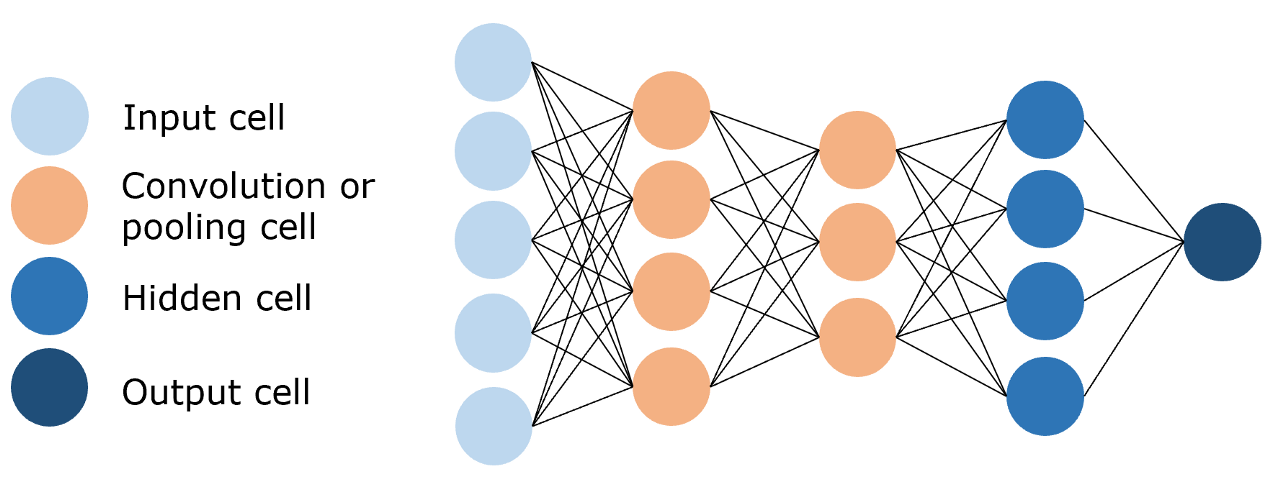
- 卷积神经网络(Convolutional Neural Network,CNN),利用训练参数远小于前馈神经网络的卷积层来进行特征提取和学习,其结构如下图所示:
- 循环神经网络(Recurrent Neural Network,RNN),利用历史信息作为输入,包含环和自重复网络,其结构如下图所示:
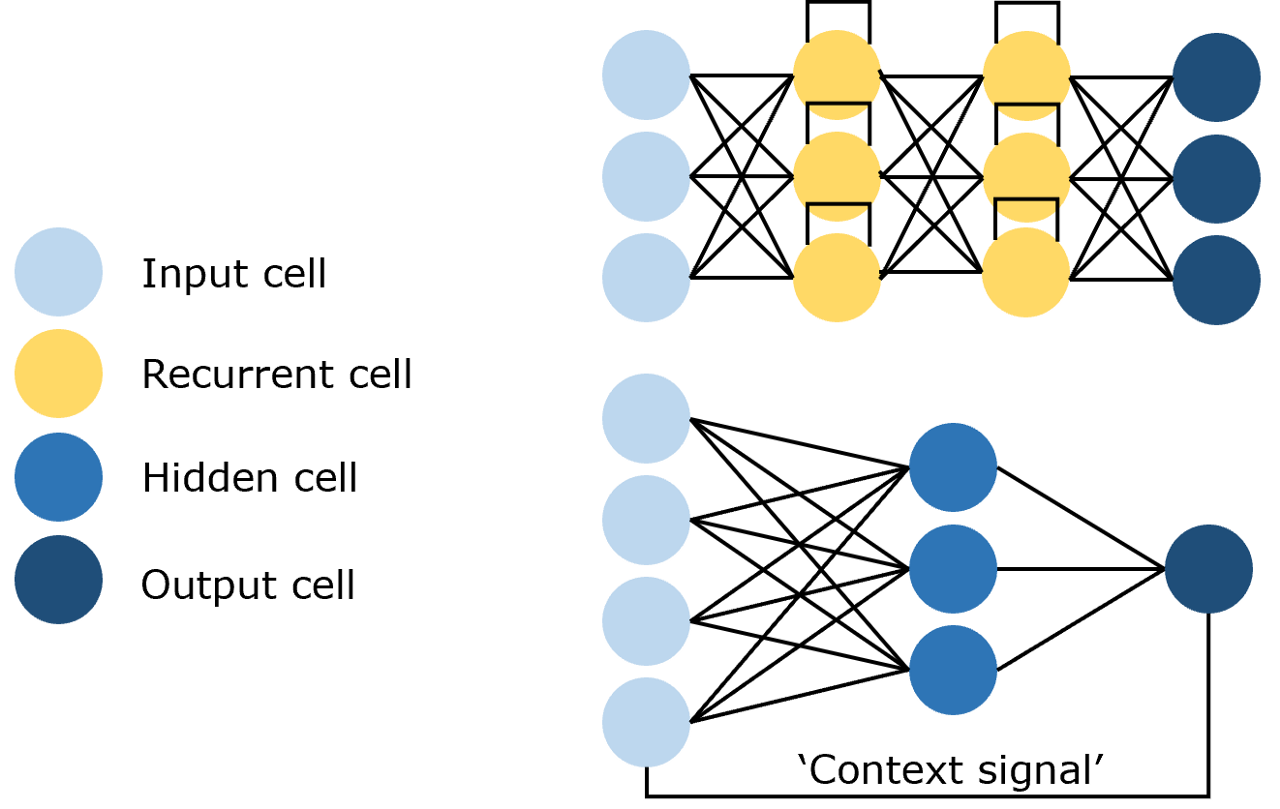
NLP任务中需要处理的文本往往以序列的形式出现,在注意力机制提出之前,专用于处理序列、时许数据的RNN常用来处理NLP任务。但以RNN为基础框架的模型虽然参数量较小,但训练时间成本较高,且对于远距离的相关关系的捕捉效果不佳。于是便有了接下来引入了注意力机制(Attention)的神经网络——Transformer。
二、注意力机制核心概念
注意力机制的本质是模拟人类认知中的“聚焦”能力,在接受到信息时选择性的关注关键部分。其核心由三个变量构成:
- Query(Q):查询向量
- Key(K):键向量
- Value(V):值向量
举例解释,若Q是“查找2024年奥运会举办地”,K是新闻全文的每个词,V是对应词的语义向量,注意力机制会计算Q与每个K的相关性,权重高的V被重点关注,最终输出“巴黎”的语义表示。
以字典为例,假设查询值 Query 为“fruit”,所查询的文本内容为字典形式,字典中的键对应注意力机制中的键(Key),字典中键对应的值对应注意力机制中的值(Value)。
{
"apple": 10,
"banana": 5,
"chair": 2
}进一步将键值对进行组合得到最终的Value,对三个 Key 分别赋予权重如下
{
"apple": 0.6,
"banana": 0.4,
"chair": 0
}进而得到查询到的值应该是:
举出这么一个简单的例子来帮助理解接下来给出的注意力机制的计算公式:
在这个公式中,如果Q和K对应的维度比较大,直接计算
会出现两个关键问题:
- 点积的期望和方差会随着
线性增长,比如
- 在利用softmax进行放缩时容易受影响,Softmax的输出会“偏向”极大值,其他值几乎被压缩到0,导致梯度集中在少数位置,模型训练时候容易出现梯度消失/爆炸的情况,参数更新不稳定。
在公式中加入缩放因子,它的作用是把
的数值范围拉回到合理区间,使Softmax输出的概率分布更加“均匀”,避免极端偏向,梯度传递稳定。
三、注意力机制的几种类型
1.自注意力
在实际应用中,我们往往只需要计算Query 和 Key 之间的注意力结果,很少存在额外的真值Value。这就涉及到了注意力机制中的一种变形——自注意力(Self_attention)即是计算本身序列中每个元素相对于其他元素的注意力分布,拟合输入语句中每一个token对其他所有token的关系。代码实现形式为
2.掩码注意力
<BOS>[MASK][MASK][MASK][MASK]
<BOS> I [MASK][MASK][MASK]
<BOS> I like [MASK][MASK]
<BOS> I like you [MASK]
<BoS> I like you </EOS>3.多头注意力
一次注意力机制智能拟合一种相关关系,单一的注意力机制难以在短时间内拟合文本中全部相关关系,Transformer中使用多头注意力机制(Multi-Head Attention),对同一文本语料进行多次注意力计算,每次计算都拟合不同相关关系,将多次计算的结果耦合输出,以此来完成对深层语言信息的拟合。
多头注意力机制的结构示意图如下:
其优势在于:
- 捕捉多维度语义:不同的头可以在不同的子空间中学习到不同的注意力模式。比如在处理自然语言文本时,有的头可能更关注语法结构(如主谓宾关系 ),有的头可能更关注语义关联(如同义词、上下位词关系 ),这样综合多个头的信息,能让模型更全面地理解序列语义。
- 增强模型表达能力:相比单头注意力,多头注意力引入了更多的可学习参数(多个投影矩阵和输出矩阵 ),增加了模型的复杂度,从而提升了模型拟合复杂数据分布的能力,有助于在各种自然语言处理任务(如机器翻译、文本分类、问答系统等 )中取得更好的效果。
- 缓解注意力集中问题:单头注意力可能会过度集中在少数关键元素上,而多头注意力通过多个头分散注意力计算,可以让模型更均衡地关注序列中的不同部分,挖掘更多有价值的信息。
在 Transformer 模型里,编码器和解码器都广泛使用了多头注意力机制。以编码器为例,输入序列经过多头注意力后,能从多个角度捕捉输入序列内部的语义依赖关系,为后续的前馈神经网络等操作提供更丰富的语义表示;解码器中的多头注意力,除了处理自身已生成序列的自注意力(带掩码 ),还会和编码器的输出进行多头注意力计算,从而融合源序列和目标序列的语义信息,更好地实现如机器翻译等生成任务。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)