《LSTM更新计算过程详解》
LSTM(长短期记忆网络)通过"记忆处理工厂"的机制有效处理长序列信息。其核心包含三个控制门:遗忘门决定保留多少旧记忆,输入门控制新记忆的准入,输出门筛选当前要传递的关键信息。通过六个关键公式,LSTM实现了"筛选旧记忆-生成候选记忆-更新核心记忆-输出关键信息"的完整流程。其中细胞状态(ct)作为长期记忆载体,通过门控机制实现信息的动态更新与传递,解决了传统RNN的梯度消失问题。这种结构使LST
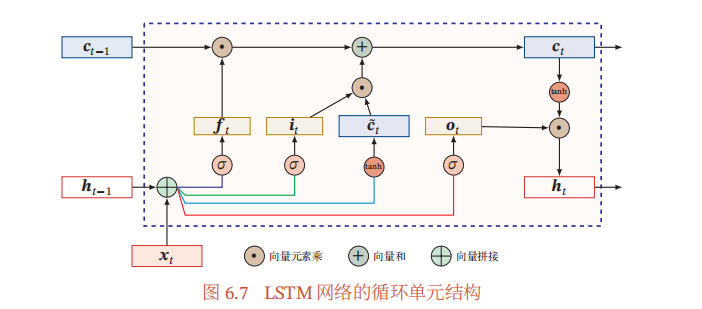
LSTM(长短期记忆网络)是循环神经网络(RNN)的一种变体, 由于其能够有效处理长序列数据,避免梯度消失和梯度爆炸问题,我们可以把 LSTM 想象成一个 “信息处理小车间”,一步一步来看。
第一步:准备原材料
在每一个时间点 t(比如处理一句话里的第 t 个单词时),车间会拿到两个 “原材料”:
- 当下的输入 xt:可以理解为这个单词本身的信息。
- 上一个时间点传过来的隐藏状态 ht−1:相当于之前所有单词处理后,剩下的 “关键记忆碎片”。
然后把这俩原材料 “拼接” 到一起,为后续生产做准备。
第二步:生成四个 “控制工具”
用拼接好的原材料,生产出四个关键的 “控制工具”,它们决定了信息怎么流:
- 遗忘门 ft:像个 “筛子”,决定上一时刻的细胞状态 ct−1(可以理解为更核心、更长期的记忆)里,哪些信息要 “筛掉”(遗忘)。
- 输入门 it:像个 “闸门”,决定当下新生成的候选细胞状态 c~t(新的临时记忆)里,哪些能 “放进” 核心记忆里。
- 输出门 ot:像个 “出口闸门”,决定最终要把多少核心记忆(细胞状态 ct)转化成当前的隐藏状态 ht,传递给下一个环节。
- 候选细胞状态 c~t:是当下时间点 t 生成的 “新临时记忆”,要不要用,得看输入门让不让进。
第三步:更新核心记忆(细胞状态 ct)
核心记忆 ct 的更新是 “旧记忆筛选 + 新记忆准入” 的结合:
- 先通过遗忘门 ft,对上一时刻的核心记忆 ct−1 做筛选(比如 “昨天的核心记忆里,关于‘苹果’的部分,今天还需不需要留着?”)。
- 再通过输入门 it,对新生成的临时记忆 c~t 做筛选(比如 “今天新学到的‘水果’相关临时记忆,有多少能变成核心记忆?”)。
- 最后把筛选后的 “旧记忆残留” 和 “新记忆准入部分” 加起来,就得到了当前时刻的核心记忆 ct。
第四步:产出当前隐藏状态 ht
现在核心记忆 ct 已经更新好了,但不是所有核心记忆都要 “对外输出”。这时候输出门 ot 就起作用了:它会筛选 ct 里的内容,再通过 tanh 函数(把值压缩到 -1 到 1 之间,方便传递),生成当前时刻的隐藏状态 ht。这个 ht 既包含了当前时间点的关键信息,又能传递给下一个时间点 t+1 继续处理。
简单总结就是:LSTM 每一步都在 “筛选旧记忆、筛选新记忆、更新核心记忆、输出当前关键记忆”,通过这一套流程,把长序列里的信息慢慢传递下去。
下图是有关LSTM的计算公式:
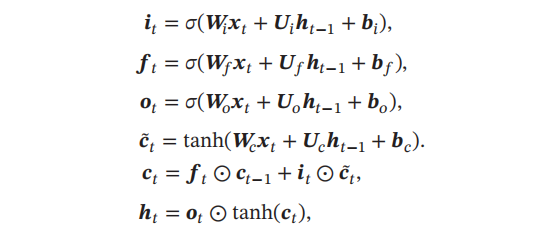
我们可以把 LSTM 想象成一个 “记忆处理工厂”,每个公式就是工厂里不同工序的 “操作指南”,下面来详细解释:
1. 输入门(it=σ(Wixt+Uiht−1+bi))
- 作用:决定 “当前新信息能进多少到核心记忆里”。
- 通俗解释:
- xt 是当前时间步的 “新原料”(比如文本里的当前单词)。
- ht−1 是上一步工厂传过来的 “二手信息”(之前处理的单词留下的关键记忆)。
- Wi 和 Ui 是 “筛选规则”(权重矩阵),bi 是 “规则微调项”(偏置)。
- 把 xt、ht−1 用规则加工后,再通过 σ(Sigmoid 函数,输出 0 - 1 之间的数),得到 it。it 就像个 “准入证”,值越接近 1,说明当前新信息越能大量进入核心记忆;越接近 0,越难进入。
- 官方符号解释:
- it:输入门在时间步 t 的输出,σ 是 Sigmoid 激活函数,用于将值映射到 0 到 1 之间,控制当前输入信息的更新比例。
- Wi:输入门中输入 xt 对应的权重矩阵。
- xt:时间步 t 的输入。
- Ui:输入门中上一时间步隐藏状态 ht−1 对应的权重矩阵。
- ht−1:上一时间步 t−1 的隐藏状态。
- bi:输入门的偏置项。
2. 遗忘门(ft=σ(Wfxt+Ufht−1+bf))
- 作用:决定 “上一步的核心记忆要忘多少”。
- 通俗解释:
- 同样用当前 “新原料”xt 和上一步 “二手信息”ht−1,结合 “遗忘规则”Wf、Uf 和 “微调项”bf 加工。
- 再通过 σ 得到 ft,它也是 0 - 1 之间的数。越接近 1,说明上一步核心记忆保留得越多;越接近 0,忘得越多。比如之前记的 “旧知识”,现在判断没用了,就通过 ft 大量遗忘。
- 官方符号解释:
- ft:遗忘门在时间步 t 的输出,控制上一时间步细胞状态 ct−1 的遗忘比例。
- Wf:遗忘门中输入 xt 对应的权重矩阵。
- Uf:遗忘门中上一时间步隐藏状态 ht−1 对应的权重矩阵。
- bf:遗忘门的偏置项。
3. 输出门(ot=σ(Woxt+Uoht−1+bo))
- 作用:决定 “当前核心记忆能输出多少给下一个步骤”。
- 通俗解释:
- 还是用 xt、ht−1,结合 “输出规则”Wo、Uo 和 “微调项”bo 加工。
- 经 σ 得到 ot(0 - 1 之间)。越接近 1,核心记忆输出得越多;越接近 0,输出得越少。比如当前核心记忆里,只有部分信息对下一步有用,就通过 ot 筛选输出。
- 官方符号解释:
- ot:输出门在时间步 t 的输出,控制当前细胞状态 ct 对隐藏状态 ht 的输出比例。
- Wo:输出门中输入 xt 对应的权重矩阵。
- Uo:输出门中上一时间步隐藏状态 ht−1 对应的权重矩阵。
- bo:输出门的偏置项。
4. 候选细胞状态(c~t=tanh(Wcxt+Ucht−1+bc))
- 作用:生成 “当前新的候选核心记忆”。
- 通俗解释:
- 用 xt、ht−1,结合 “候选记忆生成规则”Wc、Uc 和 “微调项”bc 加工。
- 然后通过 tanh 函数(输出 -1 到 1 之间的数),得到 c~t。这是当前时间步产生的 “新记忆候选”,之后能不能进核心记忆,要看输入门 it 的 “准入证”。
- 官方符号解释:
- ~t:候选细胞状态,tanh 激活函数将值映射到 −1 到 1 之间,是当前时间步可能更新到细胞状态中的新信息。
- Wc:候选细胞状态中输入 xt 对应的权重矩阵。
- Uc:候选细胞状态中上一时间步隐藏状态 ht−1 对应的权重矩阵。
- bc:候选细胞状态的偏置项。
5. 细胞状态更新(ct=ft⊙ct−1+it⊙c~t)
- 作用:更新 “核心记忆”。
- 通俗解释:
- ct−1 是上一步的核心记忆,先和遗忘门 ft 逐元素相乘(⊙ 表示逐元素乘),得到 “遗忘后剩下的旧记忆”。
- 候选细胞状态 c~t 和输入门 it 逐元素相乘,得到 “被允许进入的新记忆”。
- 把这两部分相加,就得到当前时间步的核心记忆 ct。相当于 “旧记忆筛选后 + 新记忆准入后 = 新核心记忆”。
- 官方符号解释:
- ct:时间步 t 的细胞状态,由遗忘门控制保留的上一时间步细胞状态与输入门控制加入的候选细胞状态相加得到,⊙ 表示向量的逐元素相乘。
- ct−1:上一时间步 t−1 的细胞状态。
6. 隐藏状态输出(ht=ot⊙tanh(ct))
- 作用:生成 “当前要传递给下一个步骤的关键信息”。
- 通俗解释:
- 先对核心记忆 ct 做 tanh 处理(把值压缩到 -1 到 1 之间,方便传递)。
- 再和输出门 ot 逐元素相乘,得到隐藏状态 ht。这就是当前时间步筛选后,要传递给下一个时间步的 “关键记忆碎片”。
- 官方符号解释:
- ht:时间步 t 的隐藏状态,由输出门控制细胞状态 ct(经过 tanh 激活后)的输出得到。
简单来说,LSTM 通过这 6 个公式,完成了 “筛选旧记忆、生成新候选记忆、更新核心记忆、输出关键记忆” 的全过程,从而能更好地处理长序列数据(比如长文本、时间序列等),记住远距离的关键信息~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)