基于HanLP的地址信息识别:识别出人名、地址和电话号码
类定义了一个私有静态常量,用于存储直辖市列表。该列表在后续处理地址时,用于识别和特殊处理直辖市地址。// 定义直辖市列表private static final List<String> MUNICIPALITIES = Arrays.asList("北京市", "天津市", "上海市", "重庆市");
摘要:本文介绍了一个Java工具类AddressUtils,它借助HanLP自然语言处理库,实现从给定文本中提取人名、地址和电话号码的功能。该工具类通过正则表达式识别电话号码,并利用HanLP的分词和词性标注功能区分人名与地址,同时对直辖市地址进行了特殊处理。
关键词:Java;HanLP;文本信息提取;正则表达式
一、引言
在文本处理的众多场景中,从自然语言文本里提取特定信息,人名、地址和电话号码。AddressUtils类,结合正则表达式和HanLP库的功能,能够较为准确地从文本中提取这些关键信息,为后续的数据分析、信息整理等工作提供支持。
二、AddressUtils类设计
2.1 类结构与常量定义
AddressUtils类定义了一个私有静态常量MUNICIPALITIES,用于存储直辖市列表。该列表在后续处理地址时,用于识别和特殊处理直辖市地址。
// 定义直辖市列表
private static final List<String> MUNICIPALITIES = Arrays.asList("北京市", "天津市", "上海市", "重庆市");
2.2 核心方法extractInfo
extractInfo方法是该类的核心,负责从输入文本中提取人名、地址和电话号码。
- 电话号码提取:
使用正则表达式1[3 - 9]\\d{9}匹配电话号码。若找到匹配的电话号码,将其保存到phoneNumber变量中,并从原始文本中移除该电话号码,以便后续对剩余文本进行人名和地址的提取。
// 使用正则表达式识别电话号码
Pattern phonePattern = Pattern.compile("1[3 - 9]\\d{9}");
Matcher phoneMatcher = phonePattern.matcher(text);
String phoneNumber = "";
if (phoneMatcher.find()) {
phoneNumber = phoneMatcher.group();
// 从原始文本中移除电话号码
text = text.replace(phoneNumber, "").trim();
}
- 直辖市地址处理:
遍历直辖市列表,检查文本是否以直辖市名称开头。如果是,则将直辖市名称从文本中移除,同时不单独处理省份,因为直辖市本身就是省级行政区。
// 检查是否为直辖市地址
for (String municipality : MUNICIPALITIES) {
if (text.startsWith(municipality)) {
// 直辖市直接添加到地址中,不单独处理省份
text = text.substring(municipality.length()).trim();
break;
}
}
- 人名和地址提取:
利用HanLP库对处理后的文本进行分词和词性标注。遍历标注结果,根据词性nr(表示人名)和ns(表示地名)来分别构建人名和地址字符串。对于既不是人名也不是地名的词,认为可能是地址的一部分,也添加到地址字符串中。
// 使用 HanLP 进行分词和词性标注
List<Term> termList = HanLP.segment(text);
StringBuilder name = new StringBuilder();
StringBuilder address = new StringBuilder();
for (Term term : termList) {
if ("nr".equals(term.nature.toString())) { // nr 表示人名
name.append(term.word);
} else if ("ns".equals(term.nature.toString())) { // ns 表示地名
address.append(term.word);
} else {
// 非人名和地名,可能是地址的一部分,继续添加
address.append(term.word);
}
}
最后,将提取到的人名、地址和电话号码作为数组返回。
return new String[]{name.toString().trim(), address.toString().trim(), phoneNumber};
2.3 main方法测试
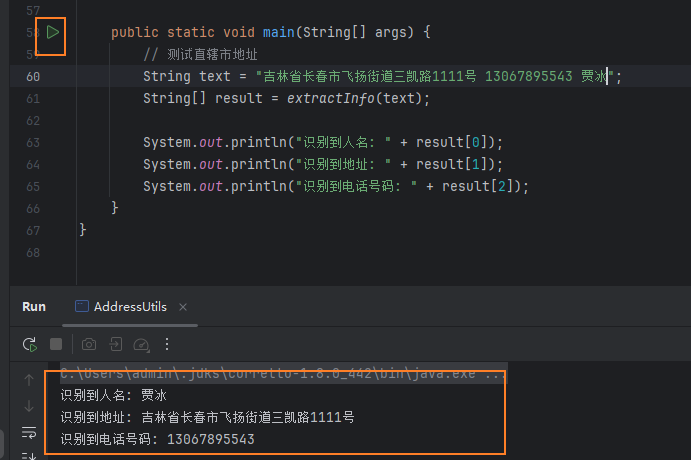
main方法提供了一个简单的测试示例,输入一段包含人名、地址和电话号码的文本,调用extractInfo方法进行信息提取,并将结果打印输出。
public static void main(String[] args) {
// 测试直辖市地址
String text = "吉林省长春市飞扬街道三凯路1111号 13067895543 贾冰";
String[] result = extractInfo(text);
System.out.println("识别到人名: " + result[0]);
System.out.println("识别到地址: " + result[1]);
System.out.println("识别到电话号码: " + result[2]);
}
三、结论
AddressUtils类通过正则表达式和HanLP库的功能,实现了对文本中人名、地址和电话号码的有效提取。在实际应用中,这种工具类可以应用于信息采集、文本分析等多个领域。然而,由于自然语言的复杂性,该工具类可能在一些特殊或复杂的文本情况下存在局限性,例如某些生僻地名、不规范的地址表述等。未来可以进一步优化算法,增强对更多复杂文本情况的处理能力,提高信息提取的准确性和鲁棒性。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)