DPO优化:从偏好数据到高效模型对齐
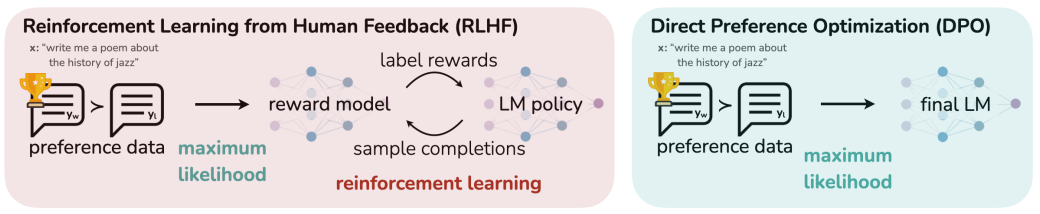
DPO(直接偏好优化)简化了传统RLHF流程,绕过显式奖励模型训练,直接利用偏好数据优化语言模型。其核心思想是将RLHF的奖励建模和强化学习合并为一个分类损失函数.
DPO (Direct Preference Optimization) 学习笔记
十月十三日更新
一、 核心思想:为何需要 DPO?
传统的基于人类反馈的强化学习(RLHF)通常是一个复杂的三阶段过程:
- 监督微调 (SFT):让模型具备基础能力。
- 训练奖励模型 (Reward Model, RM):用人类偏好数据(例如,回答A比回答B好)训练一个独立的模型,让它学会给回答打分。
- 强化学习 (RL):使用 PPO 等算法,让语言模型在奖励模型的指导下进行优化,以产生能获得更高分数的回答。
这个流程虽然有效,但存在一些问题:训练过程复杂、不稳定,且需要维护两个大型模型(语言模型和奖励模型)。奖励模型(RM)的准确性成为了整个流程的瓶颈,如果奖励模型的效果不佳,那么后续的所有强化学习阶段都会受此影响。
DPO 的核心思想 是一种范式转移:我们能否跳过显式训练奖励模型这一步,直接利用偏好数据来优化语言模型本身?
DPO 巧妙地证明了,我们可以通过一个简单的分类目标,直接优化语言模型,使其行为与人类偏好对齐。它将“拟合奖励模型”和“强化学习”这两个步骤合并成了一个等价的、更简单的损失函数。
二、 关键概念与定义
在推导之前,我们先明确几个关键定义:
- 策略 (Policy) π\piπ:指语言模型本身。我们希望优化的目标策略记为 πθ\pi_{\theta}πθ。
- 参考策略 (Reference Policy) πref\pi_{ref}πref:通常是经过 SFT 阶段的模型。它的作用是作为优化的起点和锚点,防止模型在优化过程中“能力退化”或偏离太远。
- 人类偏好数据:数据集中的每个样本包含一个问题(prompt)xxx,一个被人类偏爱的回答(winner)ywy_wyw,和一个不被偏爱的回答(loser)yly_lyl。记为 (x,yw,yl)(x, y_w, y_l)(x,yw,yl)。
- 奖励函数 r(x,y)r(x, y)r(x,y):一个未知的、潜在的函数,它能够根据人类的偏好给出一个分数。在传统 RLHF 中,我们需要拟合它;在 DPO 中,我们绕过它。
三、 DPO 公式推导:从 RLHF 目标到分类损失
DPO 的推导从 RLHF 的通用目标出发,通过一系列数学变换,最终得到了一个简单的分类损失函数。
第一步:从带约束的强化学习目标出发
在 RLHF 中,我们的优化目标是最大化奖励,同时不与参考策略 πref\pi_{ref}πref 偏离太远。这个目标可以写成如下形式:
maxπEx∼D,y∼π(y∣x)[r(x,y)]−βDKL(π(y∣x)∣∣πref(y∣x))\max_{\pi} E_{x \sim D, y \sim \pi(y|x)}[r(x,y)] - \beta D_{KL}(\pi(y|x) || \pi_{ref}(y|x))πmaxEx∼D,y∼π(y∣x)[r(x,y)]−βDKL(π(y∣x)∣∣πref(y∣x))
- E[⋅]E[\cdot]E[⋅] 项表示最大化期望奖励。
- DKL(⋅)D_{KL}(\cdot)DKL(⋅) 项是 KL 散度,作为惩罚项,防止 π\piπ 与 πref\pi_{ref}πref 相差过大。β\betaβ 是控制惩罚强度的超参数。
可以证明,这个优化问题的最优解 π∗(y∣x)\pi^*(y|x)π∗(y∣x) 具有以下形式:
π∗(y∣x)=1Z(x)πref(y∣x)exp(1βr(x,y))\pi^*(y|x) = \frac{1}{Z(x)} \pi_{ref}(y|x) \exp\left(\frac{1}{\beta} r(x,y)\right)π∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))
相关证明运用了拉格朗日乘子法和KKT约束条件,具体过程详见文末。
其中Z(x)Z(x)Z(x) 是一个配分函数,用于确保所有可能回答 yyy 的概率之和为1。它的具体形式是:
Z(x)=∑yπref(y∣x)exp(1βr(x,y))Z(x) = \sum_{y} \pi_{ref}(y|x) \exp\left(\frac{1}{\beta} r(x,y)\right)Z(x)=y∑πref(y∣x)exp(β1r(x,y))
这个公式非常关键,它建立了最优策略 π∗\pi^*π∗、参考策略 πref\pi_{ref}πref 和潜在奖励函数 r(x,y)r(x,y)r(x,y) 之间的桥梁。
第二步:反解奖励函数
既然我们知道了最优策略和参考策略的关系,我们可以反过来,从这个关系中解出奖励函数 r(x,y)r(x,y)r(x,y)。
对上面的最优策略公式稍作变换:
exp(1βr(x,y))=π∗(y∣x)⋅Z(x)⋅1πref(y∣x)\exp\left(\frac{1}{\beta} r(x,y)\right) = \pi^*(y|x) \cdot Z(x) \cdot \frac{1}{\pi_{ref}(y|x)}exp(β1r(x,y))=π∗(y∣x)⋅Z(x)⋅πref(y∣x)1
两边取对数:
1βr(x,y)=log(π∗(y∣x)πref(y∣x))+logZ(x)\frac{1}{\beta} r(x,y) = \log\left(\frac{\pi^*(y|x)}{\pi_{ref}(y|x)}\right) + \log Z(x)β1r(x,y)=log(πref(y∣x)π∗(y∣x))+logZ(x)
最终得到:
r(x,y)=βlog(π∗(y∣x)πref(y∣x))+βlogZ(x)r(x,y) = \beta \log\left(\frac{\pi^*(y|x)}{\pi_{ref}(y|x)}\right) + \beta \log Z(x)r(x,y)=βlog(πref(y∣x)π∗(y∣x))+βlogZ(x)
这个公式告诉我们,任何语言模型策略(这里指最优策略 π∗\pi^*π∗)都可以被看作是相对于参考策略 πref\pi_{ref}πref 的一个隐式奖励函数。奖励分数与两个策略对同一个回答的概率比值的对数成正比。
第三步:将奖励函数与人类偏好关联
现在,我们把人类偏好数据 (x,yw,yl)(x, y_w, y_l)(x,yw,yl) 引入。我们假设人类的偏好符合 Bradley-Terry 模型。该模型指出,人类更偏爱 ywy_wyw 而不是 yly_lyl 的概率 P(yw≻yl∣x)P(y_w \succ y_l | x)P(yw≻yl∣x) 可以由它们各自的奖励分数差通过一个 logistic 函数来建模:
P(yw≻yl∣x)=σ(r(x,yw)−r(x,yl))P(y_w \succ y_l | x) = \sigma(r(x, y_w) - r(x, y_l))P(yw≻yl∣x)=σ(r(x,yw)−r(x,yl))
其中 σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}σ(z)=1+e−z1 是 logistic sigmoid 函数,
具体为什么使用这个公式见文章后。
现在,我们将第二步中反解出的奖励函数表达式代入上式:
r(x,yw)−r(x,yl)=[βlogπ∗(yw∣x)πref(yw∣x)+βlogZ(x)]−[βlogπ∗(yl∣x)πref(yl∣x)+βlogZ(x)]r(x, y_w) - r(x, y_l) = \left[ \beta \log\frac{\pi^*(y_w|x)}{\pi_{ref}(y_w|x)} + \beta \log Z(x) \right] - \left[ \beta \log\frac{\pi^*(y_l|x)}{\pi_{ref}(y_l|x)} + \beta \log Z(x) \right]r(x,yw)−r(x,yl)=[βlogπref(yw∣x)π∗(yw∣x)+βlogZ(x)]−[βlogπref(yl∣x)π∗(yl∣x)+βlogZ(x)]
代入后 配分函数 logZ(x)\log Z(x)logZ(x) 在相减的过程中被完美地消掉了, 这极大地简化了问题。
r(x,yw)−r(x,yl)=β(logπ∗(yw∣x)πref(yw∣x)−logπ∗(yl∣x)πref(yl∣x))r(x, y_w) - r(x, y_l) = \beta \left( \log\frac{\pi^*(y_w|x)}{\pi_{ref}(y_w|x)} - \log\frac{\pi^*(y_l|x)}{\pi_{ref}(y_l|x)} \right)r(x,yw)−r(x,yl)=β(logπref(yw∣x)π∗(yw∣x)−logπref(yl∣x)π∗(yl∣x))
第四步:构建最终的 DPO 损失函数
我们的目标是让我们的模型 πθ\pi_{\theta}πθ 尽可能地接近这个理论上的最优策略 π∗\pi^*π∗。所以,我们用 πθ\pi_{\theta}πθ 来替换 π∗\pi^*π∗,然后最大化所有人类偏好数据的对数似然。
最大化 P(yw≻yl∣x)P(y_w \succ y_l | x)P(yw≻yl∣x) 等价于最小化它的负对数似然:
LDPO(πθ,πref)=−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))]L_{DPO}(\pi_{\theta}, \pi_{ref}) = -E_{(x, y_w, y_l) \sim D} \left[ \log \sigma \left( \beta \log\frac{\pi_{\theta}(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log\frac{\pi_{\theta}(y_l|x)}{\pi_{ref}(y_l|x)} \right) \right]LDPO(πθ,πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
这就是最终 DPO 损失函数。我们来解读一下这个损失函数:
- 它是一个分类损失。形式上,它非常像一个二元交叉熵损失。
- logπθ(yw∣x)πref(yw∣x)\log\frac{\pi_{\theta}(y_w|x)}{\pi_{ref}(y_w|x)}logπref(yw∣x)πθ(yw∣x):可以看作是我们的模型 πθ\pi_{\theta}πθ 认为“更优回答” ywy_wyw 相对于参考模型的“优势”或“改进幅度”。
- logπθ(yl∣x)πref(yl∣x)\log\frac{\pi_{\theta}(y_l|x)}{\pi_{ref}(y_l|x)}logπref(yl∣x)πθ(yl∣x):同理,是模型认为“更差回答” yly_lyl 的“改进幅度”。
- 核心优化目标:为了最小化这个损失函数,模型必须最大化偏好回答 ywy_wyw 的相对概率,同时最小化非偏好回答 yly_lyl 的相对概率。
通过优化这个简单的损失函数,我们间接地、但数学上等价地完成了传统 RLHF 中复杂的奖励建模和强化学习两个步骤。
四、详细公式推导
1. 最优策略 π∗\pi^*π∗ 公式推导
对于目标函数 J(π)=Ex∼D,y∼π(y∣x)[r(x,y)]−βDKL(π(y∣x)∣∣πref(y∣x))J(\pi) = E_{x \sim D, y \sim \pi(y|x)}[r(x,y)] - \beta D_{KL}(\pi(y|x) || \pi_{ref}(y|x))J(π)=Ex∼D,y∼π(y∣x)[r(x,y)]−βDKL(π(y∣x)∣∣πref(y∣x)),在其约束条件(π\piπ 必须是一个有效的概率分布,即 ∑yπ(y∣x)=1\sum_y \pi(y|x) = 1∑yπ(y∣x)=1)下的最优解 π∗\pi^*π∗ 是什么。
推导方法:
这是一个在函数空间内寻找最优函数的问题,并且带有一个等式约束。解决这类问题的标准方法是拉格朗日乘子法。
为了简化,我们固定一个 prompt xxx,寻找最优的策略函数 π(y∣x)\pi(y|x)π(y∣x)。目标函数可以写为:
J(π)=∑yπ(y∣x)r(x,y)−β∑yπ(y∣x)logπ(y∣x)πref(y∣x)J(\pi) = \sum_y \pi(y|x)r(x,y) - \beta \sum_y \pi(y|x) \log\frac{\pi(y|x)}{\pi_{ref}(y|x)}J(π)=y∑π(y∣x)r(x,y)−βy∑π(y∣x)logπref(y∣x)π(y∣x)
约束条件是:∑yπ(y∣x)−1=0\sum_y \pi(y|x) - 1 = 0y∑π(y∣x)−1=0
步骤 1: 构建拉格朗日函数
我们将目标函数与约束条件结合,构建拉格朗日函数 L(π,λ)L(\pi, \lambda)L(π,λ):
L(π,λ)=(∑yπ(y∣x)r(x,y)−β∑yπ(y∣x)logπ(y∣x)πref(y∣x))−λ(∑yπ(y∣x)−1)L(\pi, \lambda) = \left( \sum_y \pi(y|x)r(x,y) - \beta \sum_y \pi(y|x) \log\frac{\pi(y|x)}{\pi_{ref}(y|x)} \right) - \lambda \left( \sum_y \pi(y|x) - 1 \right)L(π,λ)=(y∑π(y∣x)r(x,y)−βy∑π(y∣x)logπref(y∣x)π(y∣x))−λ(y∑π(y∣x)−1)
其中 λ\lambdaλ 是拉格朗日乘子。我们的目标是找到使 LLL 取得极大值的 π\piπ。
步骤 2: 对 π(y∣x)\pi(y|x)π(y∣x) 求偏导
为了找到极值点,我们将 LLL 对每一个 π(y∣x)\pi(y|x)π(y∣x) 求偏导,并令其等于 0。我们把 π(y∣x)\pi(y|x)π(y∣x) 看作一个自变量。
∂L∂π(y∣x)=0\frac{\partial L}{\partial \pi(y|x)} = 0∂π(y∣x)∂L=0
我们逐项进行求导:
- ∂∂π(y∣x)(∑yπ(y∣x)r(x,y))=r(x,y)\frac{\partial}{\partial \pi(y|x)} \left( \sum_y \pi(y|x)r(x,y) \right) = r(x,y)∂π(y∣x)∂(∑yπ(y∣x)r(x,y))=r(x,y)
- ∂∂π(y∣x)(−β∑yπ(y∣x)logπ(y∣x)πref(y∣x))\frac{\partial}{\partial \pi(y|x)} \left( -\beta \sum_y \pi(y|x) \log\frac{\pi(y|x)}{\pi_{ref}(y|x)} \right)∂π(y∣x)∂(−β∑yπ(y∣x)logπref(y∣x)π(y∣x)): 这一项需要用到链式法则和乘法法则。
- logπ(y∣x)πref(y∣x)=logπ(y∣x)−logπref(y∣x)\log\frac{\pi(y|x)}{\pi_{ref}(y|x)} = \log\pi(y|x) - \log\pi_{ref}(y|x)logπref(y∣x)π(y∣x)=logπ(y∣x)−logπref(y∣x)
- ddz(zlogz)=logz+1\frac{d}{dz}(z \log z) = \log z + 1dzd(zlogz)=logz+1
- 所以,∂∂π(y∣x)(−βπ(y∣x)(logπ(y∣x)−logπref(y∣x)))=−β(logπ(y∣x)−logπref(y∣x)+1)=−β(logπ(y∣x)πref(y∣x)+1)\frac{\partial}{\partial \pi(y|x)} \left(-\beta \pi(y|x)(\log\pi(y|x) - \log\pi_{ref}(y|x))\right) = -\beta (\log\pi(y|x) - \log\pi_{ref}(y|x) + 1) = -\beta \left(\log\frac{\pi(y|x)}{\pi_{ref}(y|x)} + 1\right)∂π(y∣x)∂(−βπ(y∣x)(logπ(y∣x)−logπref(y∣x)))=−β(logπ(y∣x)−logπref(y∣x)+1)=−β(logπref(y∣x)π(y∣x)+1)
- ∂∂π(y∣x)(−λ(∑yπ(y∣x)−1))=−λ\frac{\partial}{\partial \pi(y|x)} \left( -\lambda (\sum_y \pi(y|x) - 1) \right) = -\lambda∂π(y∣x)∂(−λ(∑yπ(y∣x)−1))=−λ
将所有导数项合并,得到:
∂L∂π(y∣x)=r(x,y)−β(logπ(y∣x)πref(y∣x)+1)−λ=0\frac{\partial L}{\partial \pi(y|x)} = r(x,y) - \beta \left(\log\frac{\pi(y|x)}{\pi_{ref}(y|x)} + 1\right) - \lambda = 0∂π(y∣x)∂L=r(x,y)−β(logπref(y∣x)π(y∣x)+1)−λ=0
步骤 3: 求解 π(y∣x)\pi(y|x)π(y∣x)
现在我们从上式中解出 π(y∣x)\pi(y|x)π(y∣x):
r(x,y)−β−λ=βlogπ(y∣x)πref(y∣x)r(x,y) - \beta - \lambda = \beta \log\frac{\pi(y|x)}{\pi_{ref}(y|x)}r(x,y)−β−λ=βlogπref(y∣x)π(y∣x)r(x,y)−β−λβ=logπ(y∣x)πref(y∣x)\frac{r(x,y) - \beta - \lambda}{\beta} = \log\frac{\pi(y|x)}{\pi_{ref}(y|x)}βr(x,y)−β−λ=logπref(y∣x)π(y∣x)1βr(x,y)−1−λβ=logπ(y∣x)πref(y∣x)\frac{1}{\beta}r(x,y) - 1 - \frac{\lambda}{\beta} = \log\frac{\pi(y|x)}{\pi_{ref}(y|x)}β1r(x,y)−1−βλ=logπref(y∣x)π(y∣x)
两边同时取指数:
exp(1βr(x,y)−1−λβ)=π(y∣x)πref(y∣x)\exp\left(\frac{1}{\beta}r(x,y) - 1 - \frac{\lambda}{\beta}\right) = \frac{\pi(y|x)}{\pi_{ref}(y|x)}exp(β1r(x,y)−1−βλ)=πref(y∣x)π(y∣x)
π(y∣x)=πref(y∣x)exp(1βr(x,y))exp(−1−λβ)\pi(y|x) = \pi_{ref}(y|x) \exp\left(\frac{1}{\beta}r(x,y)\right) \exp\left(-1 - \frac{\lambda}{\beta}\right)π(y∣x)=πref(y∣x)exp(β1r(x,y))exp(−1−βλ)
步骤 4: 利用约束条件确定常数项
观察上式,exp(−1−λβ)\exp\left(-1 - \frac{\lambda}{\beta}\right)exp(−1−βλ) 这一项是一个与 yyy 无关的常数(因为 λ\lambdaλ 是一个常数)。这个常数的作用就是进行归一化,以满足我们的约束条件 ∑yπ(y∣x)=1\sum_y \pi(y|x) = 1∑yπ(y∣x)=1。
我们将这个常数项记为 1/Z(x)1/Z(x)1/Z(x),这里的 Z(x)Z(x)Z(x) 就是配分函数。它只与 xxx 有关,因为 λ\lambdaλ 是为固定的 xxx 而计算的。
所以,最优策略 π∗(y∣x)\pi^*(y|x)π∗(y∣x) 的形式就是:
π∗(y∣x)=1Z(x)πref(y∣x)exp(1βr(x,y))\pi^*(y|x) = \frac{1}{Z(x)} \pi_{ref}(y|x) \exp\left(\frac{1}{\beta} r(x,y)\right)π∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))
其中 Z(x)=∑yπref(y∣x)exp(1βr(x,y))Z(x) = \sum_y \pi_{ref}(y|x) \exp\left(\frac{1}{\beta} r(x,y)\right)Z(x)=∑yπref(y∣x)exp(β1r(x,y)),以确保 ∑yπ∗(y∣x)=1\sum_y \pi^*(y|x) = 1∑yπ∗(y∣x)=1。
2. Bradley-Terry 模型与 Logistic Sigmoid 函数的推导
为什么人类对两个选项的偏好概率,可以用它们潜在奖励分数的差值,通过 logistic sigmoid 函数来建模?即 P(yw≻yl∣x)=σ(r(x,yw)−r(x,yl))P(y_w \succ y_l | x) = \sigma(r(x, y_w) - r(x, y_l))P(yw≻yl∣x)=σ(r(x,yw)−r(x,yl)) 是如何得出的。
这个模型的得出并非凭空捏造,它源于选择理论中的一个基本公理,并有一种非常直观和自然的推导方式。
推导方法:基于 Luce’s Choice Axiom
Luce’s Choice Axiom (卢斯选择公理) 是描述理性选择行为的一个基本原则。对于一个包含多个选项的集合,选择其中任一选项的概率,正比于该选项的“价值”或“强度”。
步骤 1: 定义价值/强度
假设每一个回答 yyy 都有一个潜在的、不可观测的、正数“价值”评分,我们记为 v(y)v(y)v(y)。这个 v(y)v(y)v(y) 直接关联到我们所说的奖励 r(x,y)r(x,y)r(x,y)。一个非常自然且常用的关联方式是指数关系:
v(y)=exp(r(x,y))v(y) = \exp(r(x,y))v(y)=exp(r(x,y))
选择指数关系有两个好处:
- 保证价值为正:无论奖励 rrr 是正还是负,其指数 exp(r)\exp(r)exp(r) 永远是正数,符合价值的定义。
- 数学性质良好:指数和对数运算在后续推导中非常方便。
步骤 2: 应用 Luce’s Choice Axiom
根据卢斯选择公理,在两个选项 ywy_wyw 和 yly_lyl 中,选择 ywy_wyw 的概率等于 ywy_wyw 的价值占两者总价值的比例:
P(yw≻yl∣x)=v(yw)v(yw)+v(yl)P(y_w \succ y_l | x) = \frac{v(y_w)}{v(y_w) + v(y_l)}P(yw≻yl∣x)=v(yw)+v(yl)v(yw)
步骤 3: 代入指数价值并化简
现在,我们将 v(y)=exp(r(x,y))v(y) = \exp(r(x,y))v(y)=exp(r(x,y)) 代入上式:
P(yw≻yl∣x)=exp(r(x,yw))exp(r(x,yw))+exp(r(x,yl))P(y_w \succ y_l | x) = \frac{\exp(r(x, y_w))}{\exp(r(x, y_w)) + \exp(r(x, y_l))}P(yw≻yl∣x)=exp(r(x,yw))+exp(r(x,yl))exp(r(x,yw))
为了得到我们熟悉的形式,我们对这个分式的分子和分母同时除以分子本身,即 exp(r(x,yw))\exp(r(x, y_w))exp(r(x,yw)):
P(yw≻yl∣x)=exp(r(x,yw))exp(r(x,yw))exp(r(x,yw))exp(r(x,yw))+exp(r(x,yl))exp(r(x,yw))=11+exp(r(x,yl)−r(x,yw))P(y_w \succ y_l | x) = \frac{\frac{\exp(r(x, y_w))}{\exp(r(x, y_w))}}{\frac{\exp(r(x, y_w))}{\exp(r(x, y_w))} + \frac{\exp(r(x, y_l))}{\exp(r(x, y_w))}}= \frac{1}{1 + \exp(r(x, y_l) - r(x, y_w))}P(yw≻yl∣x)=exp(r(x,yw))exp(r(x,yw))+exp(r(x,yw))exp(r(x,yl))exp(r(x,yw))exp(r(x,yw))=1+exp(r(x,yl)−r(x,yw))1
步骤 4: 关联 Logistic Sigmoid 函数
我们知道 logistic sigmoid 函数的定义是 σ(z)=11+e−z\sigma(z) = \frac{1}{1 + e^{-z}}σ(z)=1+e−z1。
观察上一步的结果,我们可以做一个简单的变换:
r(x,yl)−r(x,yw)=−(r(x,yw)−r(x,yl))r(x, y_l) - r(x, y_w) = - (r(x, y_w) - r(x, y_l))r(x,yl)−r(x,yw)=−(r(x,yw)−r(x,yl))所以,P(yw≻yl∣x)=11+exp(−(r(x,yw)−r(x,yl)))P(y_w \succ y_l | x) = \frac{1}{1 + \exp(-(r(x, y_w) - r(x, y_l)))}P(yw≻yl∣x)=1+exp(−(r(x,yw)−r(x,yl)))1
令 z=r(x,yw)−r(x,yl)z = r(x, y_w) - r(x, y_l)z=r(x,yw)−r(x,yl),上式就变成了:P(yw≻yl∣x)=11+e−z=σ(z)=σ(r(x,yw)−r(x,yl))P(y_w \succ y_l | x) = \frac{1}{1 + e^{-z}} = \sigma(z) = \sigma(r(x, y_w) - r(x, y_l))P(yw≻yl∣x)=1+e−z1=σ(z)=σ(r(x,yw)−r(x,yl))

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)