Qwen3-VL架构及核心模块
Qwen3-VL基于2.5版本进行升级,主要包括:带有细粒度语义提取能力的图文对齐encoder(SigLIP2)、解决长视频探索问题的位置编码(MoPE-I)、更丰富和深层次的模态融合机制(DeepStack)以及增强视频处理能力的时间编码(TimeStack)。通过上述架构更新,连通多阶段训练,Qwen3-VL实现更优异的性能表现。
Qwen3-VL架构及核心模块
整体架构
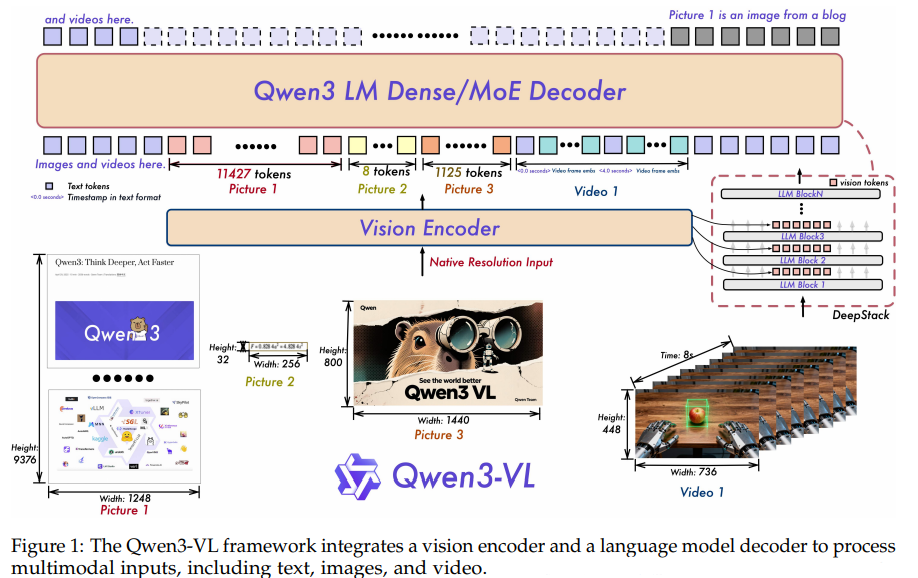
- Decoder:在Qwen3的基础上构建Qwen3-VL;
- Qwen-encoder:选用SigLIP2结构作为视觉encoder,并从官方权重进行初始化进行动态输入尺度的continue training;此外,选用Interleave版的MRoPE来避免分离的 t , h , w t, h, w t,h,w在长视频场景collapse;
- Vision-Language Merger部分,同Qwen2.5-VL一样压缩 2 × 2 2\times2 2×2的visual feature为1个visual token,同时融了DeepStack多层注入机制和time-stamp标记token token。
具体细节
1. SigLIP2
SigLIP及SigLIP2是由Google Research提出的视觉-语言模型,全程为Sigmoid Language-Image Pre-training,从根本上改变CLIP的训练范式。
1.1 SigLIP的范式革新
CLIP的重要思想在于其对比学习的思路——contrastive learning,将正样本对(训练集中相对应的图文对)之间的距离拉近,而负样本对(批次内所有其它图文对)距离拉远,来实现模态对比。InfoNCE损失函数使用softmax计算正样本对的概率,通过最大化这个概率实现上述训练目标。然而, InfoNCE中的softmax操作需要对批次内所有样本的相似度得分进行两两求和并归一化,带来极大的计算量和数值不稳定性。为解决这个问题,SigLIP将“多选一”多分类问题变为若干独立的“是或否”二元分类问题,只判断任意一组图文对是否匹配。
从损失函数公式的角度,假设由图像编码器(例如ViT)生成的N个图像embedding为 I 1 , . . . I N {I_1, ... I_N} I1,...IN,文本编码器(例如Transformer)生成的N个文本embedding T 1 , . . . , T N {T_1, ..., T_N} T1,...,TN,InfoNCE损失函数定义为: L CLIP = − 1 2 N ( ∑ i = 1 N log exp ( sim ( I i , T i ) / τ ) ∑ j = 1 N exp ( sim ( I i , T j ) / τ ) + ∑ i = 1 N log exp ( sim ( I i , T i ) / τ ) ∑ j = 1 N exp ( sim ( I j , T i ) / τ ) ) \mathcal{L}_{\text{CLIP}} = -\frac{1}{2N} \biggl( \sum_{i=1}^{N} \log \frac{\exp(\text{sim}({I}_i, {T}_i) / \tau)}{\sum_{j=1}^{N} \exp(\text{sim}({I}_i, {T}_j) / \tau)} + \sum_{i=1}^{N} \log \frac{\exp(\text{sim}({I}_i, {T}_i) / \tau)}{\sum_{j=1}^{N} \exp(\text{sim}({I}_j, {T}_i) / \tau)} \biggr) LCLIP=−2N1(i=1∑Nlog∑j=1Nexp(sim(Ii,Tj)/τ)exp(sim(Ii,Ti)/τ)+i=1∑Nlog∑j=1Nexp(sim(Ij,Ti)/τ)exp(sim(Ii,Ti)/τ))其中, N N N是批次大小, s i m ( ) sim() sim()代表相似度, τ \tau τ是固定的温度超参数。SigLIP对应的损失函数则为 L SigLIP = − 1 N 2 ∑ i = 1 N ∑ j = 1 N log σ ( y i j ⋅ ( τ ⋅ sim ( I i , T j ) + b ) ) \mathcal{L}_{\text{SigLIP}} = -\frac{1}{N^2} \sum_{i=1}^{N} \sum_{j=1}^{N} \log \sigma(y_{ij} \cdot (\tau \cdot \text{sim}(I_i, T_j) + b)) LSigLIP=−N21i=1∑Nj=1∑Nlogσ(yij⋅(τ⋅sim(Ii,Tj)+b))其中, y i j y_{ij} yij是样本标签,对正样本, y i j = 1 y_{ij}=1 yij=1,负样本则是 y i j = − 1 y_{ij}=-1 yij=−1; σ \sigma σ代表Sigmoid函数,里面的 τ \tau τ和 b b b分别为可学习的温度参数和偏置项。
温度参数控制着Sigmmoid函数的缩放,较大的 τ \tau τ会是曲线变得陡峭,微小的相似度差异会被放大,使输出迅速趋近0或1;相反,较小的 τ \tau τ使曲线平缓。因此 τ \tau τ的学习机制通常会在训练过程中逐渐增大,在训练早期对不确定的预测给予更“软”的概率,避免过早的在错误预测上收敛,训练晚期则做出明确区分。
偏置项 b b b主要处理数据不平衡问题,通过将 b b b初始化为较大的负数,在训练开始时,无论相似度为多少, τ × s i m + b \tau\times sim+b τ×sim+b都是很大的负数,使 σ ( ) \sigma() σ()的输出接近0。相当于告诉模型:默认情况下任何一对图文都不匹配。在这种设定下,只有当一个正样本对的相似度足够高,能够克服这个负偏置时,模型才会产生显著的非零梯度。这有效防止模型在训练初期被占比很高的负样本“淹没”;随着训练的进行,模型会逐渐学习到一个合适的 b b b值。
根据Sigmoid损失的设计,其优势除了在分布式训练时对批次内数据解耦以规避跨设备通信、避免softmax中数值不稳定性之外,还更灵活的处理一个图像多个正样本文本的情形,更符合真是世界数据的特性。
1.2 SigLIP2的算法演进
由CLIP改进至SigLIP,模型本质都是跨模态信息对齐的projector,而SigLIP2则通过多任务学习策略,使模型掌握更加丰富和细粒度的视觉信息,更贴近一个encoder的角色。
SigLIP2在SigLIP Sigmoid对齐损失织袜, 增加了细粒度理解(LocCa)和提高patch特征质量(SILC & TIPS)2项训练目标。细粒度理解,Localization and Captioning,在图像编码器(ViT)的输出上附加一个文本decoder,引导decoder执行下列3个任务——Image Captioning(生成描述整个图像的文本)、Expression Prediction(指定特定描述所对应图片中的坐标)、Grounded Captioning(为给定bounding box坐标描述其中内容)。Patch特征任务,类似DINO框架的自监督+掩码方案训练编码器的表征能力,但是在训练阶段的最后20%才引入。
SigLIP2的整体训练框架如图: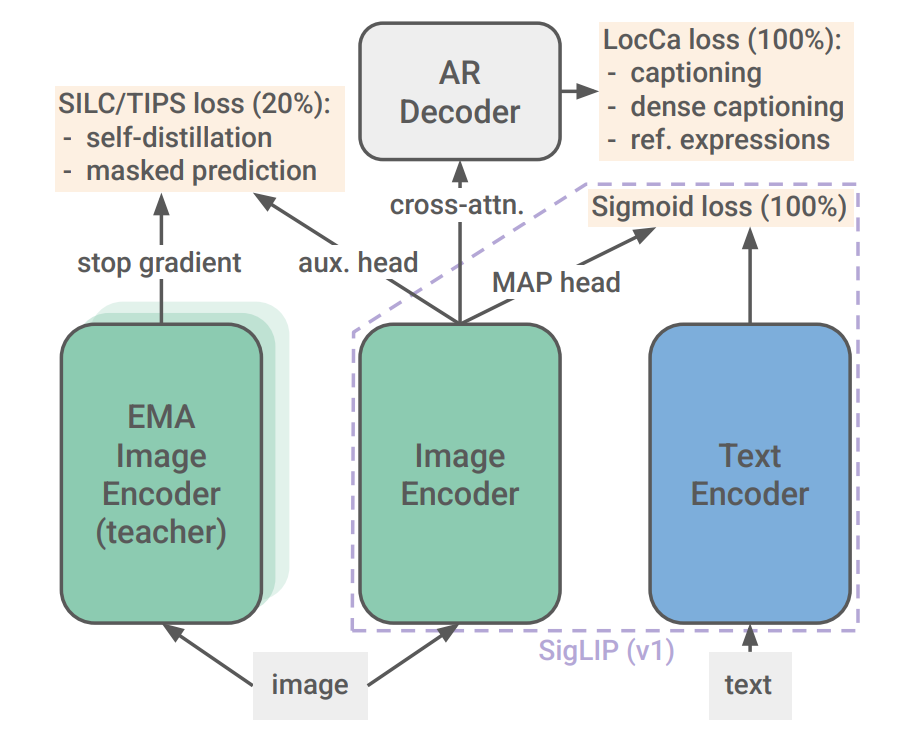
SigLIP的图片embedding由patch embedding经过multi-head attention pooling得到,及使用一个可学习的query对patch embedding进行attention操作,得到各patch的加权和。
顺便提一句,SigLIP2训练了一个能接收可变尺度输入的变体——NaFlex,将图片resize使其 w / h w/h w/h都是patch size(一般为256)的倍数,同时保持尽可能接近其原始长宽比,来适配一些要求保持图像原始比例的任务(如OCR)。
2. MRoPE
M-RoPE(Multi-modal Rotary Position Embedding)作为RoPE的扩展框架,提供面向多模态数据的维度分解方案,支持视频、图像等具有时空结构的数据。
其核心思想是将位置编码从单一维度扩张到多维张量空间,每个维度拥有独立的旋转频率。例如,对于多模态场景,位置编码分解为时间(temporal)、高度(height)、宽度(width)三个正交维度。
2.1 基本定义
标准 RoPE 将位置为 m m m 的输入向量 x m ∈ R D x_m \in \mathbb{R}^D xm∈RD 通过旋转矩阵变换:
R θ , m = ( cos m θ 0 − sin m θ 0 sin m θ 0 cos m θ 0 ⋱ cos m θ D / 2 − 1 − sin m θ D / 2 − 1 sin m θ D / 2 − 1 cos m θ D / 2 − 1 ) \mathbf{R}_{\theta, m} = \begin{pmatrix} \cos m\theta_0 & -\sin m\theta_0 \\ \sin m\theta_0 & \cos m\theta_0 \\ & & \ddots \\ & & & \cos m\theta_{D/2-1} & -\sin m\theta_{D/2-1} \\ & & & \sin m\theta_{D/2-1} & \cos m\theta_{D/2-1} \end{pmatrix} Rθ,m=
cosmθ0sinmθ0−sinmθ0cosmθ0⋱cosmθD/2−1sinmθD/2−1−sinmθD/2−1cosmθD/2−1
其中频率 θ i = b − 2 i / D \theta_i = b^{-2i/D} θi=b−2i/D, b b b 为基数(通常取 10000 10000 10000), i ∈ [ 0 , D / 2 − 1 ] i \in [0, D/2 - 1] i∈[0,D/2−1] 为维度索引。
RoPE 的复数形式表示为 R o P E ( x m , m ) = W q x m ⋅ e i m θ \mathrm{RoPE}(\mathbf{x}_m, m) = \mathbf{W}_q \mathbf{x}_m \cdot e^{im\mathbf{\theta}} RoPE(xm,m)=Wqxm⋅eimθ,其中 θ = [ θ 0 , θ 1 , … , θ D / 2 − 1 ] \theta = [\theta_0, \theta_1, \dots, \theta_{D/2-1}] θ=[θ0,θ1,…,θD/2−1]。
对于多模态输入,位置索引扩展为三元组 ( t , h , w ) (t, h, w) (t,h,w),分别代表时间维度(视频帧或文本序列索引)、垂直空间坐标和水平空间坐标。每个token的位置由 ( t , h , w ) (t, h, w) (t,h,w)唯一确定:
- 文本token: h = w = 0 h=w=0 h=w=0,仅 t t t递增
- 图像token: t = 0 t=0 t=0, h h h和 w w w根据二位网络坐标赋值
- 视频token: t t t随帧递增, h h h和 w w w在单帧内按空间位置赋值
2.2 公式表示
M-RoPE通过递归方式组合各维度的旋转操作。对于三维位置 ( t , h , w ) (t, h, w) (t,h,w): R θ ( x , t , h , w ) = R θ , t ( R θ , h ( R θ , w ( x , w ) , h ) , t ) \mathbf{R}_{\theta}(\mathbf{x}, t, h, w) = \mathbf{R}_{\theta, t}\big( \mathbf{R}_{\theta, h}\big( \mathbf{R}_{\theta, w}(\mathbf{x}, w), h \big), t \big) Rθ(x,t,h,w)=Rθ,t(Rθ,h(Rθ,w(x,w),h),t)其中每个维度的旋转矩阵独立定义: R θ , d ( x , p d ) = R θ d , p d ⋅ x , d ∈ { t , h , w } \mathbf{R}_{\theta, d}(\mathbf{x}, p_d) = \mathbf{R}_{\theta_d, p_d} \cdot \mathbf{x}, \quad d \in \{t, h, w\} Rθ,d(x,pd)=Rθd,pd⋅x,d∈{t,h,w}频率向量 θ d \mathbf{\theta}_d θd在各维度空间共享: θ d , i = b − 2 i / D , i = 0 , 1 , . . . , D / 2 − 1 \theta_{d,i} = b^{-2i/D}, \quad i = 0, 1, ..., D/2 - 1 θd,i=b−2i/D,i=0,1,...,D/2−1
实际实现中,M-RoPE通过特征维度分割避免递归计算,将特征维度 D D D分为 D = D t + D h + D w D=D_t+D_h+D_w D=Dt+Dh+Dw,各维度独立计算后拼接: M R o P E ( x , t , h , w ) = c o n c a t ( R o P E ( x : D t , t ) , R o P E ( x D t : D t + D h , h ) , R o P E ( x D t + D h : D , w ) ) \mathrm{MRoPE}(\mathbf{x}, t, h, w) = \mathrm{concat}\big( \mathrm{RoPE}(\mathbf{x}_{:D_t}, t), \mathrm{RoPE}(\mathbf{x}_{D_t:D_t+D_h}, h), \mathrm{RoPE}(\mathbf{x}_{D_t+D_h:D}, w) \big) MRoPE(x,t,h,w)=concat(RoPE(x:Dt,t),RoPE(xDt:Dt+Dh,h),RoPE(xDt+Dh:D,w))
2.3 MRoPE-Interleave
MRoPE-I的主要思路来源于对frequency allocation的分析,MRoPE的spatial frequency通常排布在高频位置,导致模型捕获空间尺度关系的能力受限,进而破坏细粒度空间推理的任务表现。因此,MRoPE-I模式将 t / w / h t/w/h t/w/h在嵌入维度上交错排列,示意图如下。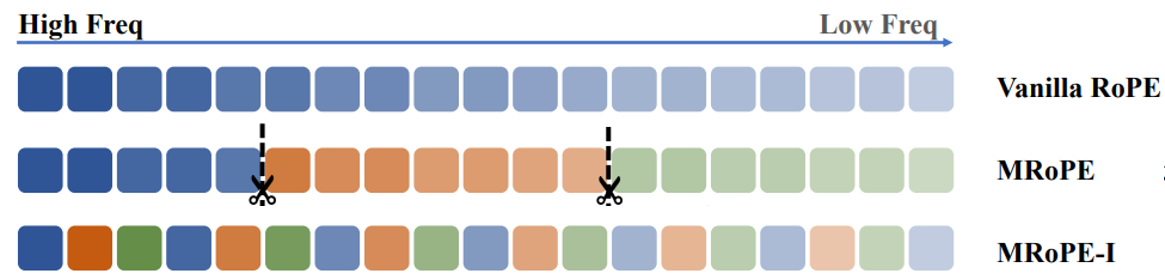
此外,MRoPE-I还设计spatial-reset方法,将每个图片/视频的 w / h w/h w/h编码从0重置,解决MRoPE中类似LLM对initial tokens的attention sink——即,模型对图像/视频的关注会集中在左上角区域,以及在初始帧。spatial-reset的另一个好处是可以将时间和空间的相对变化解耦,对于位置 ( t 1 , w 1 , h 1 ) (t_1, w_1, h_1) (t1,w1,h1)和 ( t 2 , w 2 , h 2 ) (t_2, w_2, h_2) (t2,w2,h2),MRoPE给出的相对位置是 ( t 2 − t 1 , t 2 + w 2 − t 1 − w 1 , t 2 + h 2 − t 1 − h 1 ) (t_2-t_1, t_2+w_2-t_1-w_1, t_2+h_2-t_1-h_1) (t2−t1,t2+w2−t1−w1,t2+h2−t1−h1),而加入spatial reset后相对位置变为 ( t 2 − t 1 , w 2 − w 1 , h 2 − h 1 ) (t_2-t_1, w_2-w_1, h_2-h_1) (t2−t1,w2−w1,h2−h1)。
对比MRoPE(左)和添加spatial reset的MRoPE(右):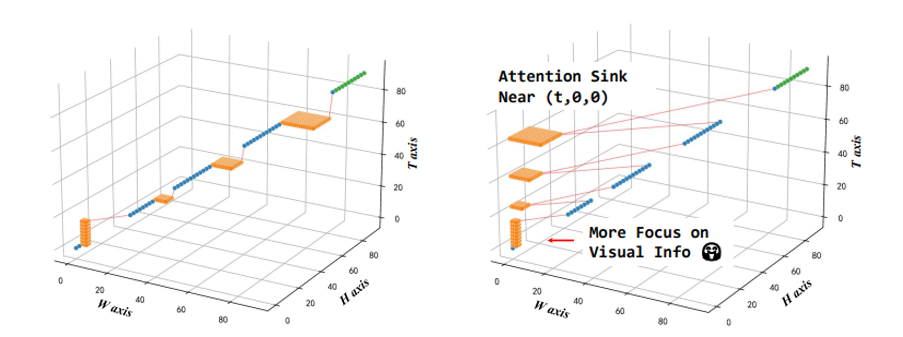
DeepStack
DeepStack是针对基础的vision-language projector的交互浅层化问题,视觉信息只输入LLM的第一层,后续仅靠注意力建模,缺乏逐层深化的交互。因此DeepStack将原始图像上采样得到high-resolution图像,并使用空间dilation取子区域。原图依旧输入LLM的第一层,后面的各子区域分别以残差的方式添加到LLM后续的指定层(一般默认每隔1层),而剩余的LLM层依旧保留原始的注意力交互。这个流程可以参照伪代码:
def forward(H0, X_stack, l_start, n, vis_pos):
H = H0
for idx, layer in enumerate(self.layers):
if idx >= l_start and (idx - l_start) % n == 0:
# 注入对应层的高分辨率 token
H[vis_pos] += X_stack[(idx - l_start) // n]
H = layer(H)
return H
上面的过程被成为DeepStack-L,即,将token堆叠注入LLM的decoder层;同时,文章还提出一种DeepStack-V的方法,将token堆叠注入ViT前期的指定层,用来提升特征提取能力。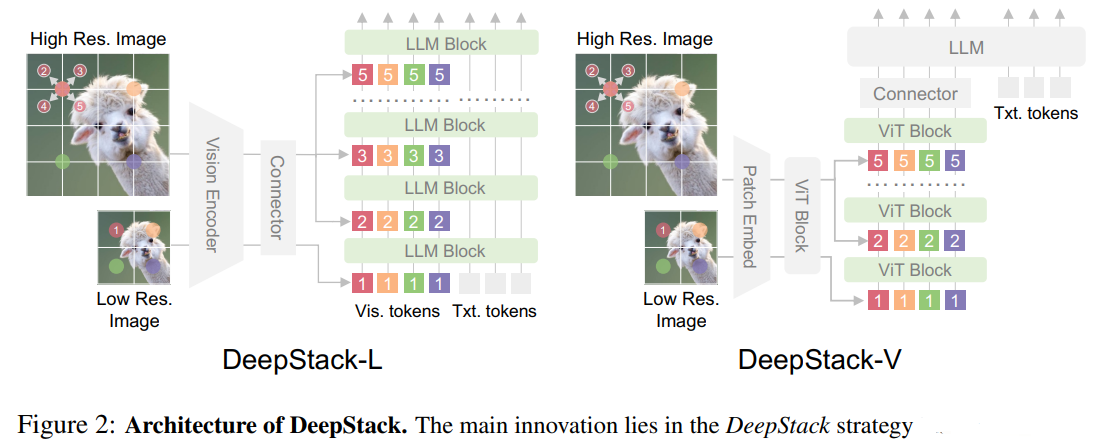
相比于之前优化visual特征提取的scaling方案(比如对图片进行多角度crop,或使用多个encoder再以MoE的方式拼接特征维度),DeepStack没有增加新的网络参数,也没有增加上下文长度,仅使用简单的残差加法,在保证计算效率的同时提高性能。
Video Timestamp
是在video抽取的各帧之前加上文本形式的时间标记,如”Second[2.0]“。这样做的好处是给视频模型提供绝对时间信息;并且因为是文本形式,可以直接借助LLM的语言能力进行理解。
训练阶段
1. pre-train阶段
| 阶段 | 训练模式 | 训练目标 | 训练集 | 序列长度 |
|---|---|---|---|---|
| ① vision-language alignment | 训练merger,冻结其他部分 | to bridge the modality gap | 67B tokens | 8192 |
| ② multimodal pre-training | 训练全部参数 | 整体的end-to-end训练 | 1T tokens;VL数据 & text-only数据,包含少量视频数据来训练temporal能力 | 8192 |
| ③ long-concext pre-training | 训练全部参数 | 训练长文本能力 | 1T tokens;text-only任务比例增加来训练长文本理解能力 | 32768 |
| ④ ultra-long-context pre-training | 训练全部参数 | 增强长文本分析、长视频总结能力 | 100B tokens | 256KB |
2. post-train阶段
为提高模型的指令遵从和推理能力,执行SFT, distillation, RL。
Reference
[1]Bai, S., “Qwen3-VL Technical Report”, arXiv e-prints, Art. no. arXiv:2511.21631, 2025. doi:10.48550/arXiv.2511.21631.
[2]Tschannen, M., “SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features”, arXiv e-prints, Art. no. arXiv:2502.14786, 2025. doi:10.48550/arXiv.2502.14786.
[3]Huang, J., “Revisiting Multimodal Positional Encoding in Vision-Language Models”, arXiv e-prints, Art. no. arXiv:2510.23095, 2025. doi:10.48550/arXiv.2510.23095.
[4]Meng, L., “DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs”, arXiv e-prints, Art. no. arXiv:2406.04334, 2024. doi:10.48550/arXiv.2406.04334.
[5]Chen, S., Lan, X., Yuan, Y., Jie, Z., and Ma, L., “TimeMarker: A Versatile Video-LLM for Long and Short Video Understanding with Superior Temporal Localization Ability”, arXiv e-prints, Art. no. arXiv:2411.18211, 2024. doi:10.48550/arXiv.2411.18211.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)