DeepSeek-R1强化训练基石:GRPO
GRPO是一种专为大型语言模型设计的强化学习算法,通过组内采样比较替代传统PPO的价值网络,显著降低计算开销。其核心流程包括生成多样化回答、计算标准化优势、KL散度约束和策略更新。GRPO在可验证奖励任务中表现优异,但也存在长度偏差等问题,后续改进算法如Dr. GRPO、GSPO等针对性地优化了优势计算和稳定性。该算法为LLM强化学习提供了高效简洁的新范式。
文章优先发布在微信公众号——“LLM大模型”,有些文章未来得及同步,可以直接关注公众号查看
群相对策略优化(Group Relative Policy Optimization, GRPO)是一种专为大型语言模型(LLM)在可验证奖励(Verifiable Rewards)场景下设计的高效强化学习算法。
其核心创新在于完全摒弃了传统PPO中的价值网络(Critic),转而通过组内采样相对比较(Intra-Group Relative Comparison)来估计优势函数,从而在显著降低计算与内存开销的同时,保留了强化学习强大的优化能力。
1. 从 PPO 的瓶颈到 GRPO 的诞生
在 LLM 对齐的 RLHF(Reinforcement Learning from Human Feedback)范式中,PPO 是事实上的标准算法。然而,其在应用于 LLM 时面临严峻挑战:
- 资源瓶颈:PPO 需要一个与策略模型(Actor)规模相当的价值模型(Critic),导致训练资源需求翻倍。
- 训练困难:在数学、代码等推理任务中,奖励是稀疏且延迟的(仅在序列末尾给出),为每个中间 token 训练一个准确的价值函数极其困难。
GRPO 应运而生,其目标是在移除 Critic 的前提下,依然能提供稳定、有效的策略梯度信号。它通过一个简洁而深刻的洞见实现了这一目标:对于一个给定的问题,一个回答的好坏,可以通过与同一问题下其他候选回答的比较来衡量。
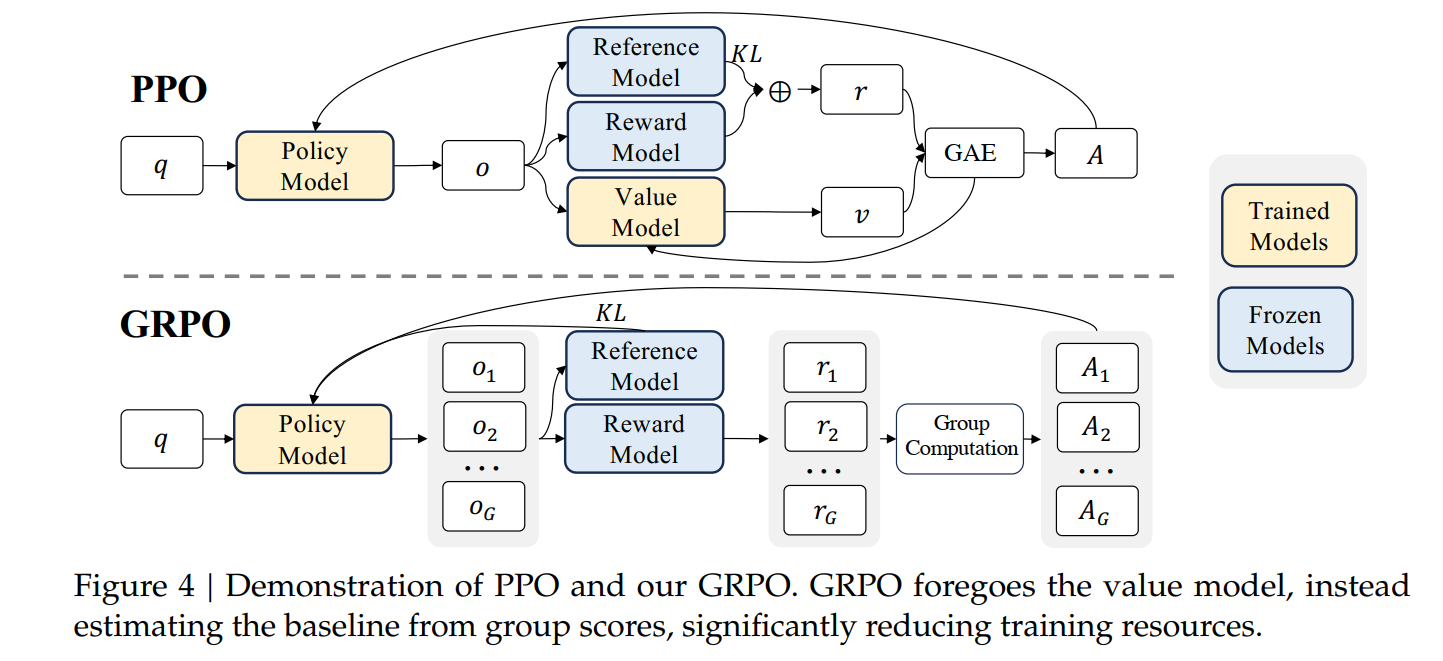
2. GRPO 核心算法:四步流程的深度剖析
GRPO 是一个在线(online)算法,其训练循环可分解为以下四个紧密耦合的步骤。
2.1 步骤一:生成补全
目的:为后续的相对比较创建多样化的候选集。
技术细节:
- 输入:从提示池 P(Q)P(Q)P(Q) 中采样一个批次的提示 {q}\{q\}{q}。
- 采样策略:对于每个提示 qqq,使用当前旧策略 πθold\pi_{\theta_{\text{old}}}πθold(即上一轮优化结束时的模型)生成 GGG 个独立的回答(补全){oi}i=1G\{o_i\}_{i=1}^G{oi}i=1G。
- 多样性控制:为确保组内回答的多样性,采样过程通常采用非确定性方法:
- 温度采样(Temperature Sampling):调整 softmax 温度 τ>1\tau > 1τ>1 以增加输出的随机性。
- Top-p 采样(Nucleus Sampling):累积概率质量超过 ppp 的最小词集上进行采样。
- 关键超参数:组大小 GGG。GGG 越大,优势估计越准确,但计算开销线性增长。实践中 G∈{4,8,16}G \in \{4, 8, 16\}G∈{4,8,16} 是常见选择。
内在逻辑:此步骤体现了 GRPO 的主动数据生成特性。模型不是被动学习,而是通过与自身交互,动态构建用于自我评估的“小环境”。
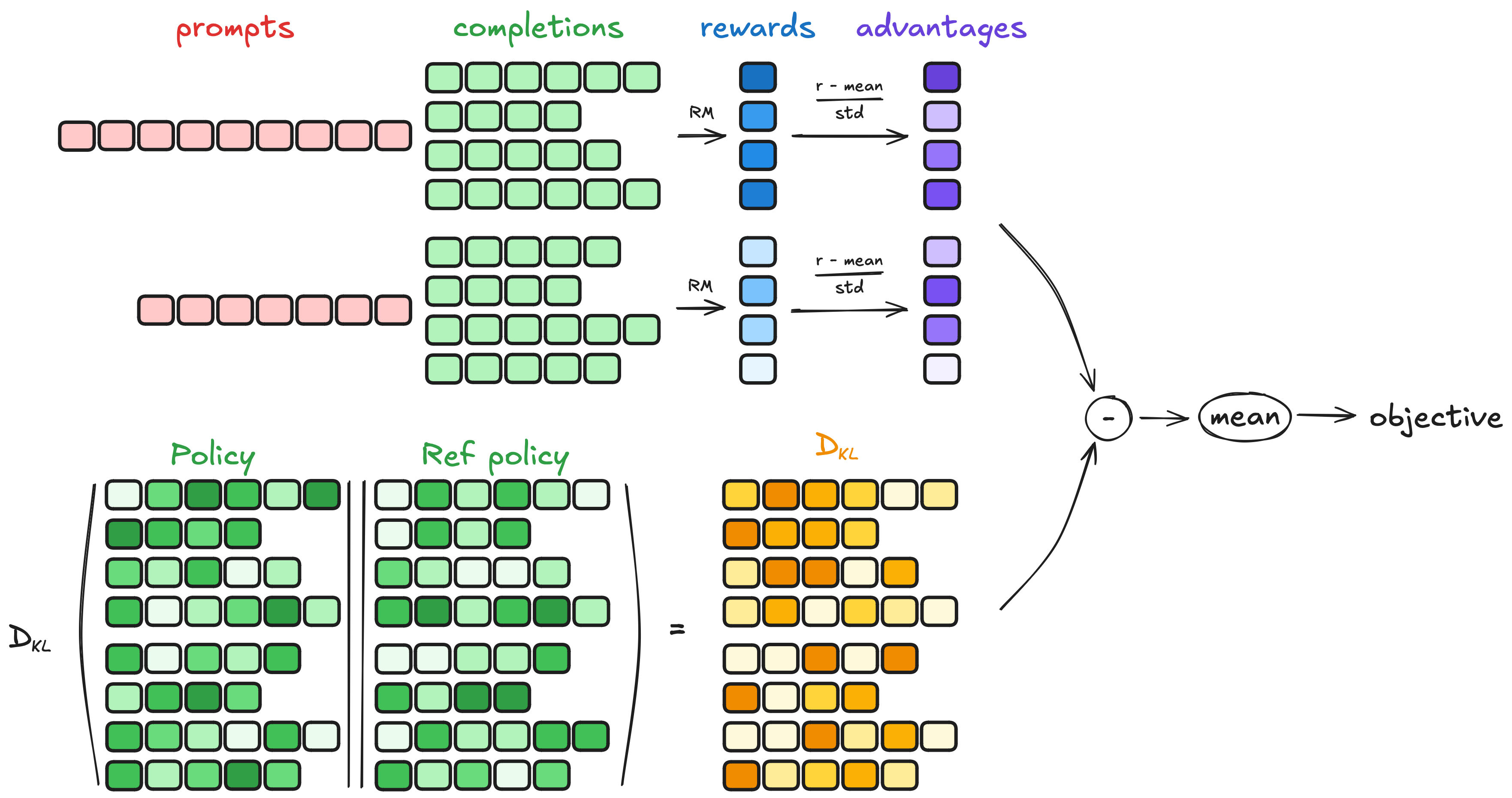
2.2 步骤二:计算优势
目的:将绝对奖励转化为指导策略更新的相对优势信号。
技术细节:
- 奖励获取:使用一个参数固定的奖励模型 R\mathcal{R}R 或程序化验证器,为每个回答 oio_ioi 计算标量奖励 ri=R(q,oi)r_i = \mathcal{R}(q, o_i)ri=R(q,oi)。
- 组内统计量计算:对于当前组 {oi}i=1G\{o_i\}_{i=1}^G{oi}i=1G,计算奖励向量 r={r1,...,rG}\mathbf{r} = \{r_1, ..., r_G\}r={r1,...,rG} 的均值和标准差:
μr=1G∑j=1Grj,σr=1G∑j=1G(rj−μr)2+δ \mu_{\mathbf{r}} = \frac{1}{G} \sum_{j=1}^G r_j, \quad \sigma_{\mathbf{r}} = \sqrt{\frac{1}{G} \sum_{j=1}^G (r_j - \mu_{\mathbf{r}})^2 + \delta} μr=G1j=1∑Grj,σr=G1j=1∑G(rj−μr)2+δ
其中 δ\deltaδ 是一个极小的常数(如 1e−81e^{-8}1e−8),用于防止 σr=0\sigma_{\mathbf{r}} = 0σr=0 时的除零错误。 - 优势估计:计算回答级别的优势,并将其广播到该回答的所有 token:
∀t∈{1,...,∣oi∣},A^i,t=ri−μrσr \forall t \in \{1, ..., |o_i|\}, \quad \hat{A}_{i,t} = \frac{r_i - \mu_{\mathbf{r}}}{\sigma_{\mathbf{r}}} ∀t∈{1,...,∣oi∣},A^i,t=σrri−μr
这意味着序列 oio_ioi 中的每个 token ttt 都会根据整个回答的最终质量来调整其生成概率。
内在逻辑:这是 GRPO 最核心的创新。μr\mu_{\mathbf{r}}μr 作为一个动态、自适应的基线,自动处理了问题难度的差异。标准化 σr\sigma_{\mathbf{r}}σr 则保证了优势信号的数值稳定性。
2.3 步骤三:估计 KL 散度
目的:约束策略更新,防止其过度偏离一个安全的参考点。
技术细节:
- 参考策略:πref\pi_{\text{ref}}πref 通常是监督微调(SFT)后的模型,在 RL 训练中参数冻结。
- KL 散度近似:为避免直接计算 KL 散度的高成本,GRPO 采用 Schulman et al. (2020) 提出的近似器:
DKL(πθ∥πref)i,t=πref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−log(πref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t))−1 \mathbb{D}_{\text{KL}}\left(\pi_\theta \| \pi_{\text{ref}}\right)_{i,t} = \frac{\pi_{\text{ref}}(o_{i,t} | q, o_{i,<t})}{\pi_\theta(o_{i,t} | q, o_{i,<t})} - \log \left( \frac{\pi_{\text{ref}}(o_{i,t} | q, o_{i,<t})}{\pi_\theta(o_{i,t} | q, o_{i,<t})} \right) - 1 DKL(πθ∥πref)i,t=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−log(πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t))−1
该近似器仅需计算两个策略在当前 token 上的概率比值,计算效率极高。 - 正则化强度:通过超参数 β\betaβ 控制 KL 惩罚的强度。β\betaβ 的选择至关重要,通常需要根据任务和模型进行调优。
内在逻辑:KL 惩罚是 GRPO 稳定性的基石。它在鼓励模型探索高奖励区域的同时,设置了一道“安全护栏”,防止模型为了最大化奖励而产生语法错误、事实性错误或有害内容。
2.4 步骤四:计算损失与更新
目的:整合优势信号和 KL 约束,形成可优化的损失函数。
技术细节:
-
重要性采样比率(Importance Sampling Ratio):
ri,t(θ)=πθ(oi,t∣q,oi,<t)πθold(oi,t∣q,oi,<t) r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} | q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, o_{i,<t})} ri,t(θ)=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)
该比率用于纠正因使用 πθold\pi_{\theta_{\text{old}}}πθold 生成的数据来训练 πθ\pi_\thetaπθ 而产生的分布偏移。 -
基础损失函数:
LGRPO(θ)=−1G∑i=1G1∣oi∣∑t=1∣oi∣[ri,t(θ)A^i,t−βDKL[πθ∥πref]i,t] \mathcal{L}_{\text{GRPO}}(\theta) = -\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left[ r_{i,t}(\theta) \hat{A}_{i,t} - \beta \mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]_{i,t} \right] LGRPO(θ)=−G1i=1∑G∣oi∣1t=1∑∣oi∣[ri,t(θ)A^i,t−βDKL[πθ∥πref]i,t] -
裁剪损失函数(推荐):为增强稳定性,通常采用 PPO 的裁剪机制:
LGRPOclip(θ)=−1G∑i=1G1∣oi∣∑t=1∣oi∣[min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t)−βDKL[πθ∥πref]i,t] \mathcal{L}_{\text{GRPO}}^{\text{clip}}(\theta) = -\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left[ \min \left( r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_{i,t} \right) - \beta \mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right]_{i,t} \right] LGRPOclip(θ)=−G1i=1∑G∣oi∣1t=1∑∣oi∣[min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t)−βDKL[πθ∥πref]i,t]
其中 ϵ\epsilonϵ 是裁剪范围(通常为 0.1 或 0.2)。 -
优化:通过标准的梯度上升(因为目标是最大化期望回报)来更新策略参数 θ\thetaθ。
内在逻辑:损失函数是 GRPO 所有设计思想的集成。它通过 min 和 clip 操作实现了“信任区域”更新,通过 KL 项实现了策略约束,共同确保了高效而稳定的训练。
3. GRPO 的优势、局限与演进
3.1 核心优势
- 高效性:移除 Critic,内存和计算开销减半。
- 简洁性:系统架构从“四模型”简化为“三模型”。
- 有效性:在可验证奖励任务上性能卓越,能有效提升模型的复杂推理能力。
3.2 固有局限与后续演进
GRPO 的简洁设计也暴露了一些新问题,催生了一系列改进算法:
| 问题 | GRPO 的表现 | 改进算法 | 解决方案 |
|---|---|---|---|
| 长度偏差 | 负优势时,长错误回答惩罚被稀释 | Dr. GRPO, DAPO | 采用 token 级损失聚合,确保每个 token 贡献均等 |
| 难度偏差 | 简单/难题组内 σr→0\sigma_{\mathbf{r}} \to 0σr→0,优势被放大 | Dr. GRPO | 移除优势标准化,仅用中心化优势 A^i=ri−μr\hat{A}_i = r_i - \mu_{\mathbf{r}}A^i=ri−μr |
| Token 级不稳定性 | Token 级重要性采样噪声大,易导致崩溃 | GSPO | 在 序列级别 计算和裁剪重要性比率 |
| 对异常值敏感 | 算术平均易受极端奖励值影响 | GMPO | 使用 几何平均 替代算术平均 |
| 长度膨胀 | 模型倾向于生成冗长回答以提高正确率 | GFPO | 拒绝采样:仅用符合简洁性等指标的精英子集更新 |
| 过度工程化 | 各种技巧组合效果不明确 | LitePPO | 有原则的简约:仅保留鲁棒优势归一化和 token 级聚合 |
GRPO 通过其精巧的“组相对优势估计”机制,成功地在 LLM 强化学习的效率与性能之间架起了一座桥梁。它不仅是 DeepSeek-R1 等高性能模型成功的关键,更开启了一个“无评论家、基于组”的研究新范式。
GRPO 是一个关于如何通过深刻洞察问题本质,用简洁设计解决复杂工程挑战的典范。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)