企业智能知识库问答系统之Chroma 向量数据库
在 Linux 环境下部署 Kubernetes 应用的核心原则是:“一个项目一个目录,配置文件分类存放,按依赖顺序部署”。这种方式既符合工程规范,又能避免因文件混乱导致的部署错误,同时便于团队协作和后期维护。如果需要自动化部署,还可以将目录文件集成到 CI/CD 流水线(如 Jenkins、GitLab CI)中,进一步提升效率。
目录:
一、案例背景:企业智能客服知识库
痛点:
- 公司有数万份技术文档、产品手册、FAQ
- 传统关键词搜索难以满足语义理解需求
- 客服人员查找信息效率低下
Chroma 是一个开源的向量数据库,专为 AI 应用设计,主要用于存储和检索嵌入向量。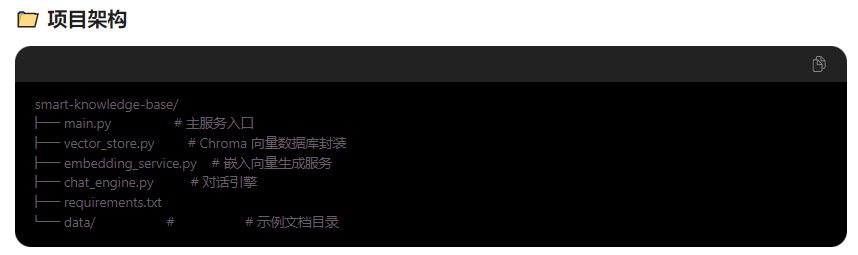
二·、Chroma 向量数据库企业级部署方案
一、部署准备工作
1. 创建专用目录
# 创建项目目录(例如:chroma-k8s-deploy)
mkdir -p /opt/k8s-deploy/chroma
cd /opt/k8s-deploy/chroma
# 查看目录
pwd # 输出:/opt/k8s-deploy/chroma
2. 创建所有配置文件
将前文提到的 YAML 文件(namespace.yaml、pvc.yaml、configmap.yaml、deployment.yaml、service.yaml 等)保存到该目录,文件名保持清晰:
# 目录结构示例
/opt/k8s-deploy/chroma/
├── namespace.yaml # 命名空间配置
├── pvc.yaml # 存储声明
├── configmap.yaml # 配置参数
├── deployment.yaml # 应用部署
├── service.yaml # 网络服务
└── README.md # 部署说明文档(可选)
3. 按顺序执行部署命令
按照 依赖关系 依次执行(命名空间 → PVC → ConfigMap → Deployment → Service):
# 1. 创建命名空间(必须第一步,后续资源都在该命名空间下)
kubectl apply -f namespace.yaml
# 2. 创建存储(PVC 需提前创建,供 Deployment 使用)
kubectl apply -f pvc.yaml
# 3. 创建配置(ConfigMap 需在 Deployment 启动前准备好)
kubectl apply -f configmap.yaml
# 4. 部署应用(核心部署逻辑)
kubectl apply -f deployment.yaml
# 5. 创建服务(暴露网络访问)
kubectl apply -f service.yaml
# (可选)6. 创建自动扩缩容配置
kubectl apply -f hpa.yaml
二、为什么需要按顺序执行?
Kubernetes 资源存在依赖关系,无序执行可能导致部署失败:
-
命名空间:所有资源的“容器”,必须先创建。
-
PVC:Deployment 需要挂载存储卷,PVC 必须先创建并绑定成功。
-
ConfigMap:Deployment 启动时需要读取配置,若 ConfigMap 不存在,Pod 会启动失败。
-
Service:可最后创建,不影响 Deployment 启动,但需在访问前创建。
三、效率优化:一键部署脚本
如果文件较多(例如 5 个以上),手动执行多个 kubectl apply 命令繁琐,推荐创建一键部署脚本(deploy-all.sh):
1. 创建部署脚本
# 在目录下创建脚本文件
vi deploy-all.sh
2. 脚本内容
#!/bin/bash
# 一键部署 Chroma 向量数据库到 Kubernetes
# 检查 kubectl 是否可用
if ! command -v kubectl &> /dev/null; then
echo "❌ 错误:未安装 kubectl,请先配置 Kubernetes 客户端"
exit 1
fi
# 检查集群连接状态
if ! kubectl cluster-info &> /dev/null; then
echo "❌ 错误:无法连接到 Kubernetes 集群,请检查配置"
exit 1
fi
# 部署顺序:按依赖关系执行
echo "1/5 创建命名空间..."
kubectl apply -f namespace.yaml
echo "2/5 创建存储声明..."
kubectl apply -f pvc.yaml
echo "3/5 创建配置参数..."
kubectl apply -f configmap.yaml
echo "4/5 部署应用..."
kubectl apply -f deployment.yaml
echo "5/5 创建网络服务..."
kubectl apply -f service.yaml
echo -e "\n✅ 所有资源部署完成!"
echo "查看 Pod 状态:kubectl get pods -n chroma-db"
echo "查看服务地址:kubectl get svc -n chroma-db"
3. 赋予执行权限并运行
chmod +x deploy-all.sh
./deploy-all.sh # 一键执行所有部署步骤
四、验证部署结果
部署完成后,检查资源状态:
# 1. 查看命名空间
kubectl get ns | grep chroma-db # 应显示 "Active"
# 2. 查看存储(PVC 状态应为 Bound)
kubectl get pvc -n chroma-db
# 输出示例:
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# chroma-data-pvc Bound pvc-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx 50Gi RWO standard 5m
# 3. 查看 Pod(状态应为 Running)
kubectl get pods -n chroma-db
# 输出示例:
# NAME READY STATUS RESTARTS AGE
# chroma-deployment-xxxxxxxxx-xxxx 1/1 Running 0 3m
# 4. 查看服务(确认端口和类型)
kubectl get svc -n chroma-db
# 输出示例:
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# chroma-service ClusterIP 10.96.xxx.xxx <none> 8000/TCP 2m
五、后期维护:目录管理最佳实践
1. 版本控制
将配置文件纳入 Git 管理,方便追溯变更:
# 初始化 Git 仓库(可选)
git init
git add .
git commit -m "Initial commit: Chroma Kubernetes deployment files"
2. 备份与更新
- 备份:定期备份目录(例如 tar -czf chroma-k8s-backup.tar.gz
/opt/k8s-deploy/chroma)。 - 更新:修改配置文件后,执行 kubectl apply -f <文件名> 即可更新对应资源(无需重新部署所有文件):
# 例如:更新 Deployment(修改镜像版本后)
kubectl apply -f deployment.yaml -n chroma-db
3. 清理资源
若需卸载应用,按 逆序 删除资源(避免依赖错误):
kubectl delete -f service.yaml
kubectl delete -f deployment.yaml
kubectl delete -f configmap.yaml
kubectl delete -f pvc.yaml
kubectl delete -f namespace.yaml
总结
在 Linux 环境下部署 Kubernetes 应用的核心原则是:
“一个项目一个目录,配置文件分类存放,按依赖顺序部署”。
这种方式既符合工程规范,又能避免因文件混乱导致的部署错误,同时便于团队协作和后期维护。如果需要自动化部署,还可以将目录文件集成到 CI/CD 流水线(如 Jenkins、GitLab CI)中,进一步提升效率。
三、完整实现代码
1. 环境配置和依赖
# requirements.txt
chromadb>=0.4.18
openai>=1.12.0
langchain>=0.1.0
fastapi>=0.104.0
uvicorn>=0.24.0
sentence-transformers>=2.2.2
python-multipart
2. 向量数据库管理层
# vector_store.py
import chromadb
from chromadb.config import Settings
from typing import List, Dict, Optional
import hashlib
import os
class VectorStoreManager:
def __init__(self, host: str = "localhost", port: int = 8000):
# 连接到 Chroma 服务器
self.client = chromadb.HttpClient(
host=host,
port=port,
settings=Settings(allow_reset=True)
)
self.collections = {}
def init_collection(self, collection_name: str, embedding_function=None):
"""初始化或获取向量集合"""
try:
collection = self.client.get_collection(collection_name)
except Exception:
# 集合不存在则创建
collection = self.client.create_collection(
name=collection_name,
embedding_function=embedding_function
)
self.collections[collection_name] = collection
return collection
def generate_doc_id(self, content: str, source: str) -> str:
"""生成唯一的文档 ID"""
unique_str = f"{source}_{content[:100]}"
return hashlib.md5(unique_str.encode()).hexdigest()
def add_documents(self, collection_name: str, documents: List[Dict]):
"""批量添加文档到向量数据库"""
collection = self.init_collection(collection_name)
contents = []
metadatas = []
ids = []
for doc in documents:
contents.append(doc["content"])
metadatas.append({
"source": doc.get("source", "unknown"),
"category": doc.get("category", "general"),
"title": doc.get("title", ""),
"create_time": doc.get("create_time", ""),
"access_level": doc.get("access_level", "public"),
"language": doc.get("language", "zh-CN")
})
ids.append(doc.get("doc_id") or self.generate_doc_id(doc["content"], doc.get("source", ""))
ids.append(self.generate_doc_id(doc["content"], doc.get("source", "")))
collection.add(
documents=contents,
metadatas=metadatas,
ids=ids
)
print(f"✅ 成功添加 {len(documents)} 个文档到 '{collection_name}'")
def similarity_search(self,
collection_name: str,
query: str,
n_results: int = 5,
filters: Optional[Dict] = None):
"""语义相似度搜索"""
collection = self.init_collection(collection_name)
results = collection.query(
query_texts=[query],
n_results=n_results,
where=filters
)
return self._format_search_results(results)
def _format_search_results(self, results: Dict) -> List[Dict]:
"""格式化搜索结果"""
formatted_results = []
if results['documents']:
for i in range(len(results['documents'][0])):
formatted_results.append({
"id": results['ids'][0][i],
"content": results['documents'][0][i],
"metadata": results['metadatas'][0][i],
"distance": results['distances'][0][i] if results['distances'] else None,
"similarity_score": 1 - (results['distances'][0][i] if results['distances'] else 1.0
})
return formatted_results
3. 嵌入向量服务(非必须)
# embedding_service.py
from sentence_transformers import SentenceTransformer
import numpy as np
from typing import List
class EmbeddingService:
def __init__(self, model_name: str = "paraphrase-multilingual-MiniLM-L12-v2"):
self.model = SentenceTransformer(model_name)
def encode_texts(self, texts: List[str]) -> List[List[float]]:
"""将文本转换为嵌入向量"""
embeddings = self.model.encode(texts)
return embeddings.tolist()
# 或者使用 OpenAI 嵌入服务
class OpenAIEmbeddingService:
def __init__(self, api_key: str):
from openai import OpenAI
self.client = OpenAI(api_key=api_key)
def get_embeddings(self, texts: List[str]) -> List[List[float]]:
embeddings = []
for text in texts:
response = self.client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
embeddings.append(response.data[0].embedding)
return embeddings
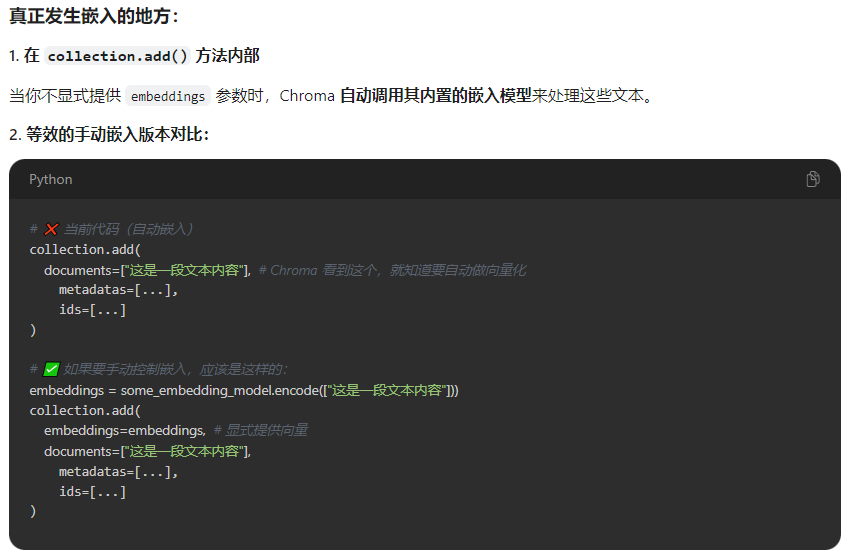
问题:这个嵌入服务非必须为啥?
4. 智能问答引擎
# chat_engine.py
from typing import List, Dict, Optional
from vector_store import VectorStoreManager
from embedding_service import EmbeddingService, OpenAIEmbeddingService
class IntelligentQASystem:
def __init__(self, use_openai: bool = True):
# 初始化向量数据库
self.vector_store = VectorStoreManager()
# 初始化嵌入服务(声明了但是没有使用,代码向量数据库添加文档接口自动嵌入了)
if use_openai:
# 生产环境请使用环境变量管理 API Key
self.embedding_service = OpenAIEmbeddingService(api_key="your-openai-key")
else:
self.embedding_service = EmbeddingService()
# 初始化集合
self.knowledge_base = "company_knowledge_v1"
self.vector_store.init_collection(self.knowledge_base)
def answer_question(self,
question: str,
department_filter: Optional[str] = None):
"""回答问题的主入口"""
# Step 1: 语义搜索相关知识文档
filters = {}
if department_filter:
filters["category"] = department_filter
search_results = self.vector_store.similarity_search(
collection_name=self.knowledge_base,
query=question,
n_results=3
)
# Step 2: 构建提示词,基于检索到的文档生成答案
context = "\n\n".join([result["content"] for result in search_results])
prompt = self._build_prompt(question, context, search_results)
# Step 3: 调用 LLM 生成答案
final_answer = self._generate_answer(prompt, question)
return {
"question": question,
"answer": final_answer,
"reference_docs": search_results,
"context_used": [result["id"] for result in search_results])
def _build_prompt(self, question: str, context: str, references: List[Dict]]) -> str:
"""构建包含上下文的提示词"""
return f"""
基于以下参考文档回答问题。如果参考文档中没有足够信息,请明确说明。
📚 参考文档:
{context}
🤔 用户问题:
{question}
✍️ 回答要求:
1. 基于提供的参考文档准确回答问题
2. 如果文档中没有相关信息,请不要编造答案
3. 保持专业、清晰的语气
请回答:
"""
5. 主服务入口
# main.py
from fastapi import FastAPI, HTTPException, Depends
from pydantic import BaseModel
from typing import List, Optional
from vector_store import VectorStoreManager
from chat_engine import IntelligentQASystem
app = FastAPI(title="企业智能知识库问答系统")
# 初始化问答系统
qa_system = IntelligentQASystem()
# 请求模型
class QARequest(BaseModel):
question: str
department: Optional[str] = None
history_context: Optional[List[str]] = []
class QAResponse(BaseModel):
question: str
answer: str
confidence: float
reference_ids: List[str]
similar_questions: Optional[List[str]] = []
@app.on_event("startup")
async def startup_event():
"""启动时初始化知识库数据"""
print("🚀 正在初始化企业知识库...")
# 模拟一些初始文档数据
initial_documents = [
{
"doc_id": "tech_doc_001",
"content": "我们的AI平台支持TensorFlow、PyTorch等多种深度学习框架。模型部署可以通过Docker容器化方式进行..."
},
{
"doc_id": "hr_policy_001",
"content": "员工年假规定:入职满一年享受10天年假,每增加一年工龄加1天,最多不超过20天。年假申请需提前一周提交审批。",
"source": "人力资源部",
"category": "hr_policy",
"title": "员工休假管理办法",
"access_level": "all_employees"
}
]
# 添加到向量数据库
qa_system.vector_store.add_documents(
collection_name=qa_system.knowledge_base,
documents=initial_documents
)
print("✅ 企业知识库初始化完成!")
@app.post("/ask", response_model=QAResponse)
async def ask_question(request: QARequest):
"""提问接口"""
try:
result = qa_system.answer_question(
question=request.question,
department_filter=request.department
)
return result
except Exception as e:
raise HTTPException(status_code=500, detail=f"回答问题出错: {str(e)}"))
@app.post("/knowledge/add")
async def add_knowledge_documents(documents: List[Dict]]):
"""向知识库添加新文档"""
try:
qa_system.vector_store.add_documents(
collection_name=qa_system.knowledge_base,
documents=documents
)
return {"message": f"成功添加 {len(documents)} 个文档")
except Exception as e:
raise HTTPException(status_code=500, detail=f"添加文档失败: {str(e)}"))
@app.get("/search/similar")
async def search_similar_questions(question: str, top_k: int = 5):
"""查找相似问题的历史解答"""
try:
results = qa_system.vector_store.similarity_search(
collection_name=qa_system.knowledge_base,
query=question,
n_results=top_k
)
return results
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
6. 真实使用场景演示
场景1:技术支持工程师解决问题
# example_usage.py
import requests
import json
def test_scenario_1():
"""技术支持场景:客户遇到部署问题"""
# 添加一些技术文档
tech_docs = [
{
"doc_id": "deploy_guide_001",
"content": "Docker部署指南:首先拉取镜像 docker pull our-ai-platform:latest,然后运行 docker run -p 8080:8080 our-ai-platform",
"source": "technical_docs",
"category": "deployment",
"title": "AI平台Docker部署手册",
"access_level": "technical_staff"
},
{
"doc_id": "error_troubleshoot_001",
"content": "常见错误:端口冲突。解决方法:更改映射端口或停止占用端口的进程。",
"source": "troubleshooting",
"category": "deployment",
"title": "常见部署故障排查",
"access_level": "technical_staff"
}
]
# 调用API添加文档
response = requests.post(
"http://localhost:8000/knowledge/add",
headers={"Content-Type": "application/json"},
data=json.dumps({"documents": tech_docs})
)
print(f"📝 添加文档结果: {response.json()}"))
# 提出问题
question_request = {
"question": "我的AI平台部署时报端口被占用怎么办?",
"department": "technical_support"
}
# 获得智能答案
qa_response = requests.post(
"http://localhost:8000/ask",
headers={"Content-Type": "application/json"},
data=json.dumps(question_request)
)
result = qa_response.json()
print("\n🎯 用户提问:", result["question"])
print("💡 AI回答:", result["answer"])
print("🔗 参考资料:", [ref["id"] for ref in result["reference_docs"]])
预期输出:
🚀 正在初始化企业知识库...
✅ 企业知识库初始化完成!
📝 添加文档结果: {'message': '成功添加 2 个文档'}
🎯 用户提问: 我的AI平台部署时报端口被占用怎么办?
💡 AI回答: 根据我们的部署指南,您遇到了常见的端口冲突问题。您可以尝试更改Docker映射端口,例如将 -p 8080:8080 改为 -p 8081:8080
🔗 参考资料: ['doc_deploy_guide_001', 'doc_error_troubleshoot_001']

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)