基于大语言模型的文史知识库构建研究
本文立足于文史知识库构建的实际需求,以典故知识分析为案例,设计了三项面向大语言模型的评测任务(典故知识结构化整理、用典判断和典故识别),并系统评测了多种模型在该系列任务上的表现。实验结果表明,大语言模型能够较为高效地完成文本结构化处理类的工作,并表现出一定的文史知识判断能力,而检索增强生成、微调模型等策略均能有效提升大模型的文史知识。进一步地,本文在大语言模型能力、调用方式、引导策略等方面获得了有
摘 要:高质量的文史知识库是开展数字人文研究的基石。近年来,大语言模型凭借其强大的语言理解与生成能力,为人文学科知识的深度加工带来了新的机遇。本文以典故知识分析为案例,通过典故知识结构化整理、用典判断和典故识别三项任务,评估了大语言模型在文史知识提取和加工方面的能力。实验结果显示,经合理的提示设计,大语言模型能够有效地完成文史知识整理,并表现出一定的文史知识判断能力;此外,小样本学习、检索增强及微调策略均能显著提升模型处理文史知识问题的能力。据此,文章讨论了大语言模型在文史知识加工领域的应用策略,包括模型选择、调用方式、提示与微调等引导机制,并提出了基于大语言模型构建文史知识库的基本路径。进一步地,文章展望了大语言模型在数字人文领域的未来应用方向。
关键词:大语言模型 知识库 典故 数字人文 文史知识
引 言
数据科学的研究范式正在推动“新文科”的发展,人文学科研究者尝试使用数据量化人文知识,利用技术解决人文问题。近年来,大数据挖掘[1]、网络分析[2]和自然语言处理[3]等技术被引入文史研究,形成了极具交叉学科特色的数字人文方向。以古典文学领域为例,刘石(2020)提出,随着数字人文技术的发展,数据分析技术和方法越来越具有针对性和有效性,其能更清晰地揭示隐藏在文学史背后的作家与社会之间、作家与作家之间、文本与文本之间的直接与间接、显性与隐性的多种关联,能以全知型的视角系统整体地还原和呈现文学史的立体景观,改变传统的思维方式和研究范式。[4]然而,现有技术的应用仍然存在可拓展的空间:目前的数据挖掘更多关注文本浅层特征,如字、词级的形式特征,较少涉及深层语义信息或抽象概念;有监督模型的训练往往依赖大量人工标注数据,而人文领域的数据往往对标注员有高于一般标注任务的知识要求,进一步提高了标注的难度与成本。
近年来,以ChatGPT为代表的大语言模型发展迅速,表现出了极强的语言理解和生成能力,为人文知识的挖掘和加工提供了新的契机。在无需标注数据额外训练的前提下,大语言模型不仅能生成合乎语法及逻辑的内容,还能够完成角色模拟、故事和诗歌写作等创意任务。因而,相关技术正在广泛地改变各领域的学术研究方式。《自然》(Nature)杂志针对全球1,659名科研工作者的调查显示,当被问及十年内AI工具在自己的研究领域内有多大用处时,超半数受访者认为“非常重要”或“必不可少”。[5]在人文社科领域,越来越多的研究表明,大语言模型在数据生产与标注方面可以扮演重要角色。在数据生产层面,大语言模型可以基于其所学习的数据进行社会行为模拟,具有替代人类被试的潜力,例如通过模拟国际冲突中的参与国决策及其后果,[6]推演社会固有集体现象的发生。[7]在数据标注层面,模型可以辅助完成数据的整理、归类及分析。Ziems等针对语言学、文学、心理学、历史学、政治学、社会学等人文社会学科关注的问题设计了二十余个评测任务,以评估大语言模型在相关领域文本数据分析上的表现。[8]其实验发现,在标签分类任务上,大语言模型与人类标注一致性尚可,在开放的生成式任务上,模型表现往往能超过众包平台的标注员。因此,虽然模型还无法完全替代人类来加工文本,但可以作为机器标注员加入人类团队,以降低标注成本,提升标注效率和多样性。
由此可见,大语言模型在数字人文领域有很强的应用潜力。然而,在模型落地应用的过程中,仍然面临一系列问题有待讨论:第一,在文史知识加工中,大语言模型擅长哪些工作?又存在哪些不足?第二,如何选择合适的模型及其调用方式,以实现高效的数据处理?第三,模型虽有很强的通用能力,但并非领域专家,如何通过提示设计、微调等策略引导模型,使其更好地辅助专家完成专业性任务?
为回答上述问题,本文拟以典故知识分析为案例,系统评测大语言模型在典故知识结构化整理、用典判断和典故识别三项任务中的表现。典故以高度凝练的形式承载了丰富的中华文化知识。以此为切入点,不仅能有效挑战大模型的知识储备和理解能力,还能为文史知识库的构建提供思路方法的支持,进而促进数据驱动的人文研究的发展。具体来说,在上述三个任务上,实验将对比GPT-4o、GPT-4o-mini、Qwen-Max(通义千问)、Qwen-Turbo这四个国内外评测表现最优且效率出色的模型,并引入提示设计、检索增强、微调等多种模型应用策略,以期得出大语言模型在数字人文领域的实践应用建议,并提出利用大语言模型构建文史知识库的方法路径。
一、典故知识分析任务设计
刘石提出,目前古典文学的大数据分析还处于检索的基础阶段,要实现技术对文本的深入分析,如史论验证、作品归属和风格变化等问题,则需要进一步拓展当前的文学资源建设与知识挖掘技术,“以上研究设想的实现,建立在两个基础之上。其一,古代文学经典文本数据的结构化……其二,利用大数据技术构建多样化文本分析系统”[9]。受其思路启发,本文着眼于典故知识库的构建需求,设计了三项面向大语言模型的典故知识分析任务,分别为典故知识结构化整理、用典判断和典故识别。接下来,本节将介绍三种任务的设计思路和具体形式,并对大语言模型的选择和使用方法进行说明。
(一)任务形式
**1.**典故知识结构化整理
任务一“典故知识结构化整理”旨在应用模型实现专家知识的结构化整理。在文史领域,为服务于文献阅读和研究,专家们编撰了大量的工具书。然而,这些工具书的词条往往采用自然语言的文本形式进行描述。如果能够对其进行结构化解析,进而构建一个系统的知识库,这将为大规模的知识查询、统计分析等研究提供重要支持。例如,表1示例出自《中国典故大辞典》[10](以下简称《辞典》)。该条目描述了典故“五马”的来源、释义及例句。表1右侧展示了该条目在知识库的存储格式,其中,典故“五马”的各类信息已整理归入对应的“键”,使计算机能够准确且高效地检索条目及相关信息。

表1 典故知识结构化整理示例
但是,文史领域工具书的格式对结构化自动整理提出了挑战:首先,采用自然语言描述的工具书往往缺乏显式的切分标记,机器难以像人类一样辨识和理解每个知识实体的边界;其次,由不同专家合作编撰的工具书,语言表述格式可能具有不一致性,这会导致解析规则之间的冲突;再次,即使在同一领域内,不同的大型工具书也可能采用不同的编撰格式,这使得整理来自不同来源的内容时,需要耗费大量的时间和精力。
此前,结构化整理主要依赖于人工编写正则表达式,这一过程包含识别字符串中存在的模式并使用正则符号提取对应的文本内容。在使用正则表达式解析《辞典》时,边界误判问题尤为突出。以来源和释义的边界判断为例,如表1所示,《辞典》的标准格式通常是先引用诗文以说明来源,再解释典故的释义。为了区分来源与释义的边界,既可以识别来源的结束标记,也可以识别释义的开始标记。然而,如果以诗文引用结束的双引号作为来源的结束标记,则无法处理《辞典》中包含的还对诗文引用再做注解和补充笺注的条目。如果以释义中的术语,如“指”“谓”“因以”等作为释义的标记,则无法处理如表1中的例子,即先对典故做整体说明,再详细解释释义的情形。此外,《辞典》条目中还存在多个出处或释义、缺少释义或例句、直接描述典故来源等多种格式,每种情况都要编写对应的正则表达式。
大语言模型可以基于文本进行语义理解,同时长于形式语言,有望应对上述问题。为评测大模型进行结构化知识整理的能力,本文以《辞典》数据为对象,人工挑选了100条数据作为测试集A,这些数据均衡地涵盖了《辞典》中条目的所有编撰格式,具有多样的语言表述,能够较好地代表工具书数据的整体情况。
**2.**用典判断
任务二“用典判断”属于文本分析层面任务,旨在要求模型判断给定句子是否用典,并输出理由。与任务一侧重整理已有工具书中的知识不同,任务二需要从未标注的语料中挖掘用典信息,属于知识加工型任务。需要指出的是,古代汉语中的语词表达具有高度歧义性,如例1、例2中都出现“桃李树”,但只有例2使用了“桃李不言,下自成蹊”的典故。此外,作者用典时并非简单使用某个固定词语或词组,而会对其表述进行变换,如例3、例4所示“宋玉悲秋”典故的不同典形。考虑到用典表达的歧义性和多样性,该任务能够有效评估大语言模型对深层语义信息的理解能力。

例1. 应似园中桃李树,花落随风子在枝。(未用典)
例2. 自是桃李树,何畏不成蹊。(用典)
例3. 当时宋玉悲感,向此临水与登山。(用典)
例4. 楚客忆江蓠,算宋玉未必为秋悲。(用典)
围绕该任务,我们通过人工标注的方式采集了100条数据,其中用典和未用典比例为1∶1,称为测试集B。
**3.**典故识别
任务三“典故识别”同样属于文本分析层面任务,除了要求模型判断是否用典外,还需给出具体使用何典,这对模型的文史知识面进行了深度考察。该任务同属于知识加工型任务,是计算机辅助构建文史知识库的重要环节。值得一提的是,古人表达高度凝练,可能在同一个句子中使用多个典故,如例5使用了“抱石疑玉”和“探骊得珠”这两个典故。因此,典故识别是三个任务中最具挑战性的任务。
例5. 抱石耻献玉,沉泉笑探珠。
同样地,我们通过人工标注采集了100条数据作为测试集C,其中用典数据为90条,包含40条使用单典数据和50条使用多典数据,另有10条未用典条目。
(二)大语言模型选择
如表1所示,大语言模型通常有三种访问方式:通过网页或APP访问、使用API调用和下载开源模型使用,每种方式下可用的模型列表不同。考虑到本研究有数据批量处理和参数设置的需求,我们选择以API方式调用模型,并将Temperature参数设置为0,[11]以确保实验结果的一致性和稳定性。

表2 大语言模型的三种访问方式
在选择具体的模型时,模型性能效果和使用成本是两项重要因素。首先,我们参考了多个大模型综合能力评测基准。其中,LMSYS Chatbot Arena[12]国际评测采用大模型匿名对战的方式计算模型胜率,SuperCLUE[13]和OpenCompass[14]等专门针对模型中文能力开展了多种类型的测试。综合多个排行榜结果,选定目前表现最优的GPT-4o和Qwen-Max模型,此外,另选择了GPT-4o-mini和Qwen-Turbo这两个响应速度快、成本低的经济型模型作为参照。[15]
(三)大语言模型提示与微调
在利用大语言模型完成特定任务时,可以通过提示设计和微调模型等方法对其进行引导。提示设计旨在为模型提供必要的背景知识和清晰的任务导引,提示词的质量对模型表现有重要影响。通常,可采用思维链、小样本学习、检索增强生成、系统指令等策略来丰富提示信息,以指导模型更好地回答问题。其中,思维链(Chain-of-Thought,简称CoT)指要求模型分步骤解决问题,较为适合复杂任务场景;小样本学习(Few-Shot Learning,简称FSL)指通过提供少量示例,令模型更好地理解任务目标,从而仿照示例回答问题;检索增强生成(Retrieval-Augmented Generation,简称RAG)则是利用外部专业数据库查询与问题有关的信息,将查询结果加入提示词,为模型作答提供参考;在调用API或本地部署模型时,系统指令(System Message)出现在首轮对话中,用于指定角色、领域、环境和能力等背景信息,能够增强对大模型的引导及限制。除了上述提示设计策略外,用户还可针对任务形式专门构造一批问答数据集,用于模型微调(Fine-tuning),使得模型较为系统地学习某类知识。在典故知识分析的三个任务中,本研究综合运用了多种提示策略和微调方法。附录展示了各任务所使用的提示词。
任务一“典故知识结构化整理”旨在生成符合规范的解析字符串。为帮助模型理解《辞典》条目的组织形式及各实体的核心内容,我们首先阐述了这些条目的整体结构。对于超出普遍格式的条目,如包含多个来源或多个释义的情况,我们进一步明确了模型应遵循的整理规则,并规定了统一的输出格式。最后,我们通过一个实例示范了理想的输出格式。
在任务二“用典判断”中,我们概述了“用典”的特征,要求模型针对“是否用典”(Label)进行判断,并要求模型输出“用典位置”(Span)和“用典依据”(Evidence)信息,以便检查模型判断的合理性。此外,本研究还对微调模型的效果进行了对比分析。我们从人工标注数据集中按用典和未用典1∶1的比例,随机采样了200条数据,构建了问答格式的微调数据集,并使用GPT-4o-mini模型进行了微调。为保持微调和输出的格式的一致性,微调模型仅生成“是否用典”(Label)和“用典位置”(Span)结果。
任务三“典故识别”引入了基于外部知识库的检索增强生成方法,并对比了不同背景信息对检索增强生成的效果。具体来说,对于每一条待判断的语料,我们使用了古汉语预训练语言模型BERT模型[16]为语料生成句向量,并在外部典故库中进行句子检索匹配和排序,得到与该语料相似度最高的十条候选典故数据,[17]每条数据包含典故名称、释义与例句信息。我们对这些信息的不同组合方式及其在检索增强生成中的效果进行了横向对比。附录中展示了典故名称作为检索增强信息的提示词。
二、实验结果与分析
在实验阶段,我们采用前述方法调用模型,在测试集A、B、C上进行了实验。针对“典故知识结构化整理”任务,我们逐一校验了模型的生成结果,统计了模型整理正确率及各类错误的数量;在用典判断和典故识别任务中,我们以人工标注的结果为基准,采取自动评估的方式,分别计算了这两个分类任务的精确率、召回率、F1值等评估指标。其中,典故识别的多分类结果通过微平均法计算,“未使用典故”也被视为一个独立的分类标签。下文将依次介绍每项任务的评测结果。
(一)典故知识结构化整理
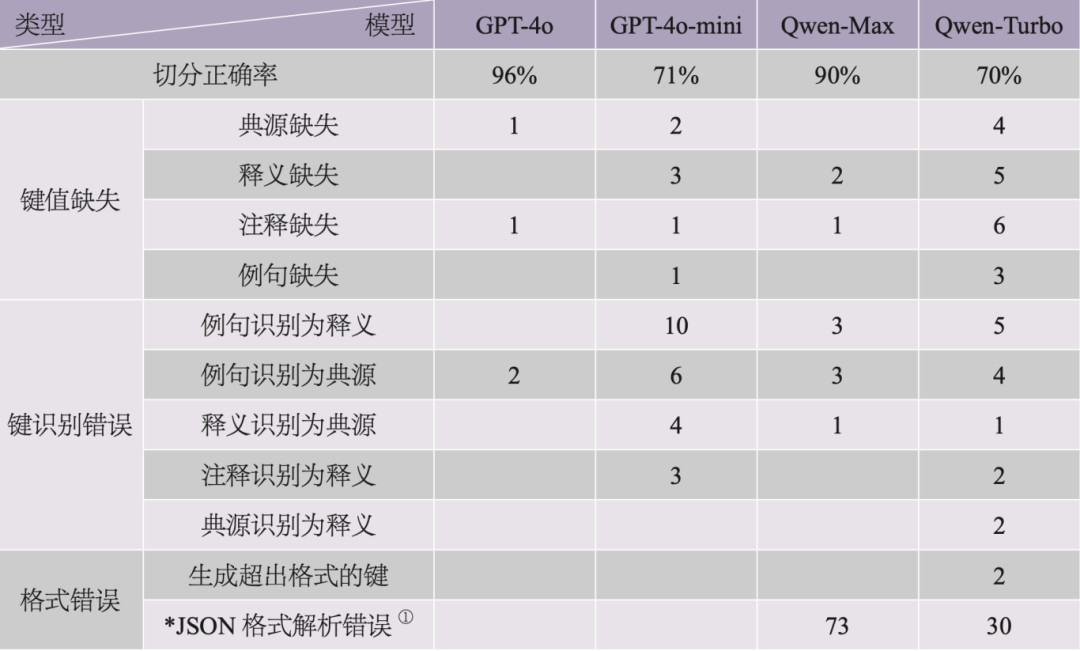
表3展示了各模型在执行任务一时的表现。首先,GPT-4o和Qwen-Max的解析准确率均达到90%及以上,显示出大模型在进行文本结构整理和知识库构建方面的能力。在某些实例中,大模型甚至表现出超越人类判断的潜力。以例6中的“一字褒贬”条目为例,模型结果与人工整理有显著差异。《辞典》中先说明了该典故的本义,随后指出其引申义。人工整理时,倾向于将本义与引申义合并,而大模型则严格遵循指令,将多个释义分别存储为独立的键值。尽管前者更符合人类的阅读习惯,后者则更契合知识库整理的规范。此外,大模型还依据语义,将“一字褒贬”的两条例句正确归类至对应的释义下,这是基于字符串表层形式的正则表达切分所难以实现的功能。a
[18]
表3 典故知识结构化整理结果
例6.
《辞典》条目:

一字褒贬 晋杜预《春秋经传集解序》:“《春秋》虽以一字为褒贬,然皆须数字以成言。”孔颖达疏:“《庄二十五年》:‘陈侯使女叔来聘。’传曰:‘嘉之,故不名。’《僖二十五年》:‘卫侯毁灭邢。’传曰:‘同姓也,故名。’褒则书字,贬则称名,褒贬在于一字。”原谓《春秋》笔法严谨,一字即寓褒贬之意。后亦泛指论人议事用词严谨而有分寸。南朝梁刘勰《文心雕龙·征圣》:“故《春秋》以一字为褒贬。”唐柳宗元《上扬州李吉甫相公献所著文启》:“又不得献薄技于前,以希一字之褒贬。”
大模型输出结果(Qwen-Turbo):

{“典故名称”:“一字褒贬”,“典故来源”:“晋杜预《春秋经传集解序》:“《春秋》虽以一字为褒贬,然皆须数字以成言。”孔颖达疏:“《庄二十五年》:‘陈侯使女叔来聘。’传曰:‘嘉之,故不名。’《僖二十五年》:‘卫侯毁灭邢。’传曰:‘同姓也,故名。’褒则书字,贬则称名,褒贬在于一字。””,“释义列表”:[{“释义”:“原谓《春秋》笔法严谨,一字即寓褒贬之意。”,“例句”:[“南朝梁刘勰《文心雕龙·征圣》:“故《春秋》以一字为褒贬。””]},{“释义”:“后亦泛指论人议事用词严谨而有分寸。”,“例句”:[“唐柳宗元《上扬州李吉甫相公献所著文启》:“又不得献薄技于前,以希一字之褒贬。””]}]}

进一步分析发现,大模型执行结构化整理任务时,主要出现了三类错误:键值缺失、键识别错误和格式错误。“键值缺失”指某个键应有的值未能完整显示,且该信息未出现在其他键;如果该信息出现在了其他键下,则归为“键识别错误”。其中,大模型典型的错误表现为“将例句误识别为释义”以及“将例句/释义误识别为典源”。提示词规则要求将例句与对应的释义一起保存,且例句键的值可以为空。如果模型未能找到例句的对应释义,可能会将例句误作为释义或保留例句键为空值。为避免此类错误,可在提示词中进一步阐明规则。典源信息的识别错误主要发生在以“同”格式标识典故出处的条目中,如附录任务一的提示词中规则1和5所示。这类条目通常采取“同某典故”的方式,省略了典故来源和释义的详细说明。如果模型未能正确理解该格式,则可能将其他键的信息误识别为典故来源。针对这些复杂且对理解要求较高的任务,两个更高级的大模型(GPT-4o和Qwen-Max)表现出更好的适应性。因此,为提高准确率,可考虑使用这些更高级的模型,或通过提供更多示例来加强规则说明。
(二)用典判断
表4呈现了各模型在用典判断任务上的结果,其中精确率(Precision)为“模型正确识别用典数/模型识别用典数”,召回率(Recall)为“模型正确识别用典数/数据集中的真实用典数”,F1值通过公式F1=2×P×R/(P+R)计算,准确率(Accuracy)为“模型正确识别数/数据总条数”。结果显示,在所有未经微调的模型中,GPT-4o综合表现最优,Qwen-Turbo在各指标上较其他模型均有一定差距。GPT-4o和Qwen-Max在召回率上均达100%,即没有遗漏地识别出了所有用典条目,但其精确率较低,存在较多将未用典错误识别为用典的情况。经过微调后,GPT-4o-mini的精确率显著提升,召回率也达到90%,综合表现最佳,这充分证明了微调方法在该任务上的有效性。
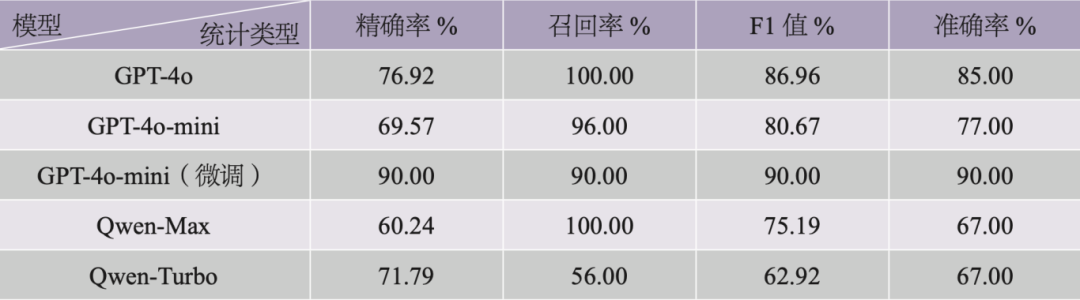
表4 用典判断实验结果
我们筛选出GPT-4o和Qwen-Max正确识别用典的条目,人工核验了两个模型划分出的用典位置和用典依据。在50个用典条目中,GPT-4o出现了3处用典位置错误和35处用典依据错误,而Qwen-Max有1处用典位置错误和33处用典依据错误。用典依据错误集中在“错误解释典故含义”和“错误解释典故出处”两处。这指向了大模型的幻觉问题,即在训练数据相对缺乏的领域,大模型会生成与事实不一致的回答。在例7中,大模型正确地识别出该句使用了典故的两处表达,并准确解释了“五斗禄”的含义和来源。然而,“七不堪”实际典出嵇康《与山巨源绝交书》,而非《庄子》。这表明,通用大语言模型在处理中国传统文化知识,尤其是典故方面,仍有所欠缺。不过,大模型已经掌握了一些典故的知识,如例8中,大模型正确地输出了典故“卖剑买牛”的相关信息。
例7. 输入语料:欲徇五斗禄,其如七不堪。

大模型输出结果(GPT-4o):““五斗禄”出自陶渊明的典故,陶渊明辞官时说“不为五斗米折腰”,指不愿为微薄的俸禄屈身。“七不堪”出自《庄子·人间世》,指七种不能忍受的情况。这句话的意思是想要追求微薄的俸禄,但又难以忍受多种困境,引用了古籍中的故事和言论,传达了丰富的意蕴,因此判断使用了典故。”,“allusion_span”:[“五斗禄”,“七不堪”](正确划分用典位置,错误解释典故出处。)

例8. 输入语料:薄有田园能自适,不妨卖剑买黄牛。

大模型输出结果(Qwen-Max):““卖剑买牛”是一个典故,源自《汉书·龚遂传》,讲述了龚遂劝导农民放弃争斗回归农耕生活的故事,后用以比喻放弃武力、从事生产或改业归农。此诗句中“卖剑买黄牛”即化用了这一典故,表达了一种由征战或武事转而追求田园自适生活的意向。”,“allusion_span”:[“卖剑买黄牛”](正确解释典故出处。)
(三)典故识别
任务一和任务二实验结果显示,GPT-4o模型在处理典故相关任务时表现更为优异。因此,在任务三中,我们选用GPT-4o模型来测试不同的RAG(即检索增强生成)策略,以进一步评估大模型在复杂任务中的表现。我们将未使用RAG的提示词作为基线,与各类RAG策略进行了对比,相关结果见表5。数据显示,所有RAG策略的效果均显著优于无检索增强的基线,这说明了在知识密集型任务中引入外部知识库的必要性。在引入RAG策略后,各组合识别的精确率都有显著提升,但召回率均略有下降。提供检索信息时,并非模型呈现越多信息越好,典故释义信息对大模型的理解帮助较为明显。
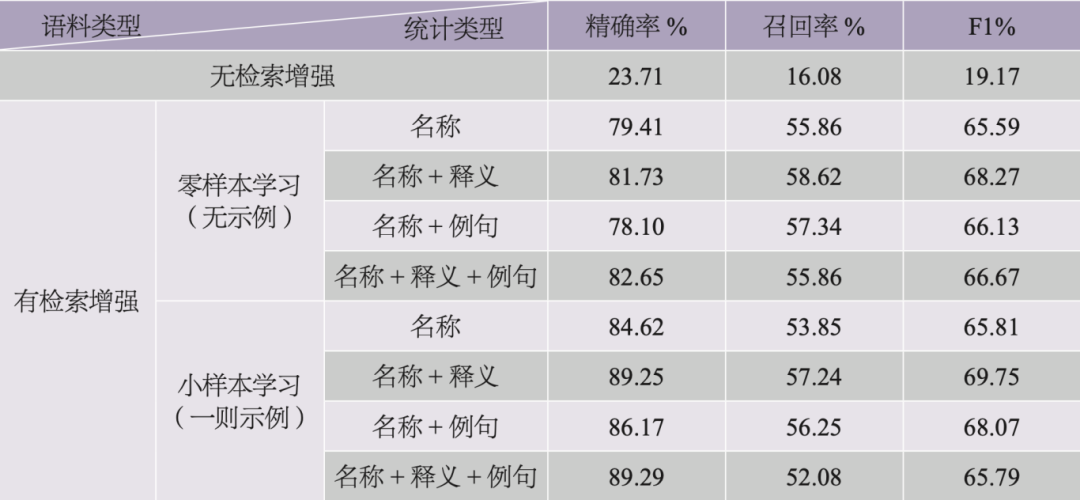
表5 典故识别实验结果
此外,RAG策略中的候选典故列表是通过句子向量相似度匹配得到,可能未包含或仅部分包含正确答案。对此,在构建数据集C时,我们特别标注了这些列表是否包含正确答案。表6展示了不同类型数据上RAG策略的表现,对于用典情形来说,检索结果对模型识别能力影响巨大,当用典信息在候选列表中时,模型能够较好地参考检索结果作答,平均正确识别典故数高;而当用典信息未被检索到时,模型几乎难以识别具体所用何典。对于未用典的情形,丰富的典故候选信息对模型的干扰较小,可见模型能够从语义层面分析当前语料是否与某一候选典故相关。
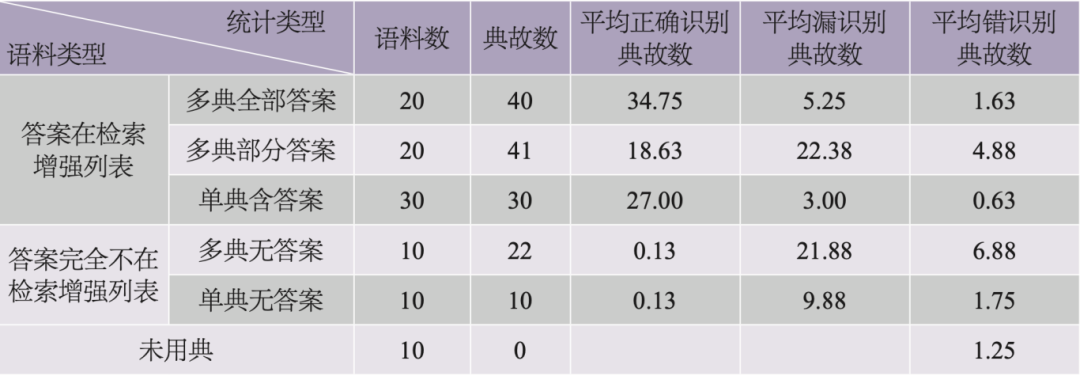
表6 检索增强类型及统计结果
三、大语言模型应用于文史知识整理的启示
由上述实验结果可见,大语言模型在执行结构化整理任务中的指令时表现出较高的准确率,而经过微调和检索增强后,大模型在典故判断和典故识别两个任务上的效果也取得了显著提升。基于这些实验,我们可以得到以下三点主要启示。
第一,大语言模型能够理解和处理文史知识,尤其在解析和整理已有知识方面表现突出。然而,在自主加工领域特定知识时,大模型仍存在一定的局限性。在结构化整理任务中,相较正则表达式等传统方法,大语言模型展示出明显优势。大模型不仅能够通过一套统一的规则处理工具书中的多种条目格式,还能凭借其语言理解能力,识别并处理缺乏显式标记的自然语言条目,从而应对超出格式规范的情况。但是,当涉及对典故的解释性任务,或在检索增强信息缺乏相关知识时,模型的表现仍然不够理想。面对这些对领域知识要求较高的任务时,人机协同至关重要。以“用典判断”任务为例,大语言模型在判断准确度上已经达到较高水平,能够在大规模数据处理中承担基础标注工作,专业人员则可以专注于深度加工,完成解释性等大模型尚不擅长的任务。同时,人工总结和校验的结果也可以用于模型调优,进而提升模型处理复杂任务的能力。
第二,选择合适的模型及调用方式对于高效的数据处理来说至关重要。在模型的选择过程中,需要综合考虑任务执行难度、模型处理效果和模型调用成本等多重因素。例如,在调用价格方面,GPT-4o与Qwen-Max相近,但均明显高于两个更小的模型。而在结构化整理任务中,GPT-4o的表现较其他模型显著更优,尤其是在处理大规模数据时,选择GPT-4o模型将大幅节约人工成本。此外,在确定了模型以后,参数设置同样对任务效果造成显著影响。因此,应当参考文档,设置合理的参数值。例如,为了追求模型反馈的一致性和稳定性,可以将Temperature或Top_p参数设为接近0的数值。而在执行创意度要求更高的任务时,适当提高Temperature参数,有助于模型生成丰富多样的回答。
第三,大语言模型在数字人文领域的应用潜力需要使用者的悉心引导。在提示设计中,可以通过以下几种策略有效激发大模型的相关领域知识:(1)在系统指令中为模型设定角色,帮助模型熟悉任务背景;(2)提供清晰具体的任务说明;(3)给出问题和答案示例;(4)对于复杂任务,可为模型设定分步骤解决思路;(5)可通过外部知识库或工具检索必要的专业知识作为参考,检索结果的相关性对模型分析能力有极大影响,因此RAG策略需选择精准、高效的检索匹配算法;(6)设置限制和要求,或要求模型输出后进行自查和纠错。此外,如果对模型输出有更强的控制需求,还可以通过构造数据集微调模型等方式,对模型进行定向、系统地引导。
四、总结与展望
本文立足于文史知识库构建的实际需求,以典故知识分析为案例,设计了三项面向大语言模型的评测任务(典故知识结构化整理、用典判断和典故识别),并系统评测了多种模型在该系列任务上的表现。实验结果表明,大语言模型能够较为高效地完成文本结构化处理类的工作,并表现出一定的文史知识判断能力,而检索增强生成、微调模型等策略均能有效提升大模型的文史知识。进一步地,本文在大语言模型能力、调用方式、引导策略等方面获得了有益启示。
本研究发现,经恰当的提示设计或微调,大语言模型能够有效促进数字人文领域的数据整理和语言文化信息挖掘工作,为文史知识库构建提供了新思路。一方面,可利用其强大的语言理解和生成能力,自动提取专家知识并组织为结构化形式,提升知识库构建效率。另一方面,可引导大模型从海量文献中挖掘隐性知识,拓宽和加深知识加工的广度和深度。在上述过程中,专家可审核模型提取的信息,并反馈领域知识指导模型优化。这种人机协同模式可兼顾效率和准确性,构建大规模、高质量的文史知识库,为数据驱动的人文研究提供支撑。
为了更好地利用大语言模型辅助人文研究,我们需要在以下两个方面继续努力:
(一)构建高质量的数据集以增强知识。在大语言模型的应用中,对大规模高质量数据集的需求尤为突出。首先,我们需要将稀缺的文史资源数字化,转换为计算机可识别、可处理的形式。其次,我们需要关注使用数据集的平衡性,尽可能提供全面丰富的数据,以帮助提升模型在文史知识方面的生成和加工能力。
(二)综合计算与人文视野分析结果。大数据与人工智能技术正在逐渐影响人文学科的研究范式。开展交叉方向课题研究时,需要首先正确定位技术在人文研究中的角色,从研究问题出发统摄全局;其次,需拓展传统研究的思路,理解并适应技术的逻辑,选择适合的技术手段;最后,需发挥人文研究者的批判思维和理论总结能力,以理论指导实验,分析错例并提出改进方案。
展望未来,大语言模型在数字人文领域具有广阔的应用前景。当下,多模态大语言模型、多智能体和数字人等前沿技术的发展,将会带来更多的应用契机。例如,多模态大语言模型可以更全面地分析历史文献、艺术作品和文化遗产;多智能体系统可以模拟复杂的人类社会互动和文化现象;数字人技术则为文化遗产的保护和传承提供了新的可能。这些创新应用不仅能加深和拓宽数字人文研究的深度和广度,也为文化传承和教育提供了新的路径。随着人工智能技术的不断进步,传统人文学科有望迎来新的发展机遇和挑战。正如袁毓林所呼吁的,“应该拥抱和投身于数据/计算密集型的第四/五范式”,因为“这是技术的催促,也是时代的召唤”。[19]
Leveraging Large Language Models for Building a Cultural and Historical Knowledge Base
Qiu Ziliang, Hu Renfen, Mo Kaijie, Wang Yupei, Liu Zhiying
Abstract: High-quality Cultural and Historical Knowledge Bases are crucial foundations for advancing digital humanities research. In recent years, Large Language Models (LLMs), with their outstanding language understanding and generation capabilities, have presented new opportunities for the deep processing of humanities knowledge. This study, using the analysis of classical Chinese allusions as a case study, evaluates the capabilities of LLMs in the extraction and processing of cultural and historical knowledge through three tasks: structuring allusions knowledge, determining the presence of allusions, and identifying specific allusions used. The experimental results demonstrate that, with well-designed prompts, LLMs can effectively accomplish the organization of cultural and historical knowledge and exhibit a certain degree of judgment in this domain. Additionally, strategies such as Few-Shot Learning, Retrieval-augmented Generation, and Fine-tuning significantly enhance the model’s ability to handle issues related to cultural and historical knowledge. Based on these findings, this paper discusses the application strategies for LLMs in the processing of cultural and historical knowledge, including model selection, deployment methods, prompting, and fine-tuning mechanisms. Furthermore, the paper outlines a fundamental approach for constructing a Cultural and Historical Knowledge Base using LLMs and explores potential future directions for the application of LLMs in digital humanities.
Keywords: Large Language Models; Knowledge Base; Classical Chinese Allusions; Digital Humanities; Cultural and Historical Knowledge
附录:典故知识分析三种任务采用的提示词

如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)