Day02-苍穹外卖
Day02-苍穹外卖
五一度假结束,继续奋斗了!!!
---------------------------------------------------------------------------------------------------------------------------------
前言:
我打算用15天的时间写完黑马程序员的苍穹外卖,为了督促自己以及记录项目知识点,所以用项目笔记的方式鞭策自己
今日所学:
- 开发一个功能的具体执行流程
- 有关项目的一些注意点和不同点
1.开发一个接口功能的具体流程
这里以新增员工为例
1.1 先看需求
打开Apifox,进入管理端接口项目,在员工项目里找到新增员工,查看需求,具体看以下几个:
1.请求参数中哪些是必须写的
2.返回的响应数据中哪些是必要返回的
3.请求路径
4.请求方式
比如以新增员工接口为例:
请求参数需要两样东西,一个是放在header中JWT校验码,一个是以json形式传入的有关employeeDTO的body参数【这里id是自增的,所以是可选参数】
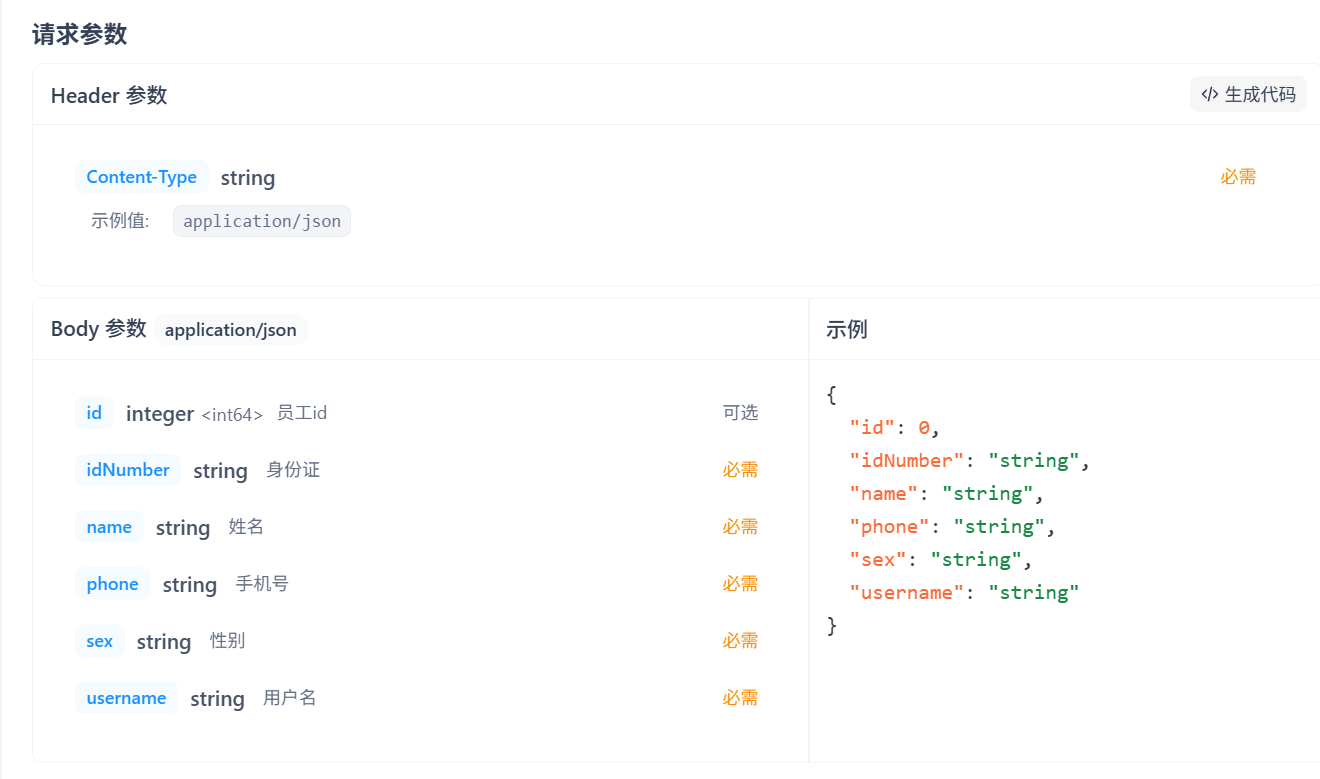
返回的响应数据
这里只有code的是必选的,其他都可以返回null
因此对应Result.success()即可
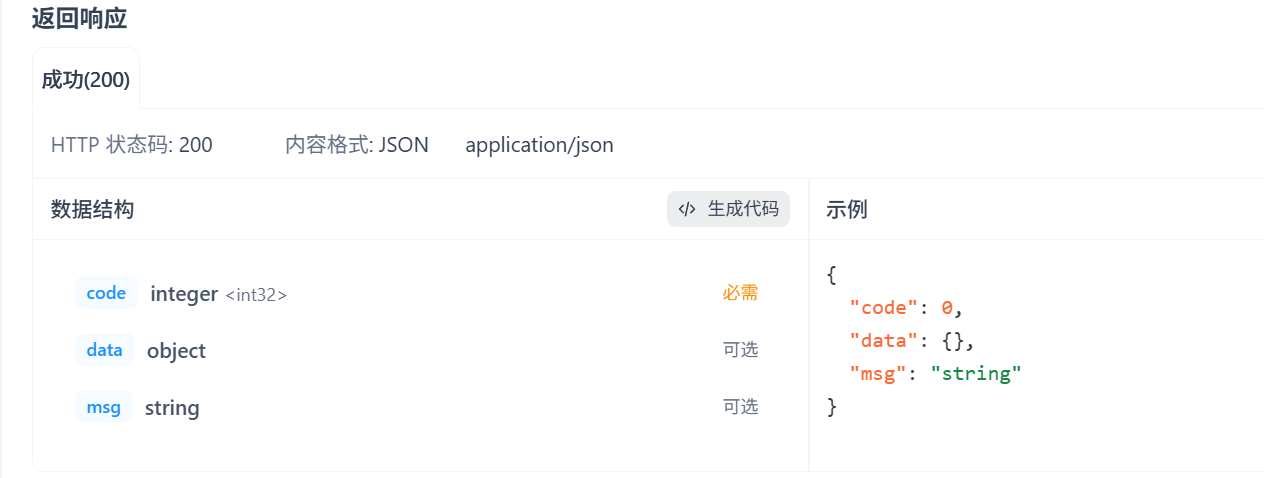
请求路径
请求方式
看文档怎么写你跟着怎么写就行
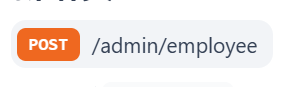
这里说下请求路径是admin/employee的原因:
我们这个项目分为管理端和用户端,管理端发出的请求,我们统一使用/admin作为前缀;用户端发出的请求,我们统一使用/User作为前缀,而现在我们写的是管理端的接口
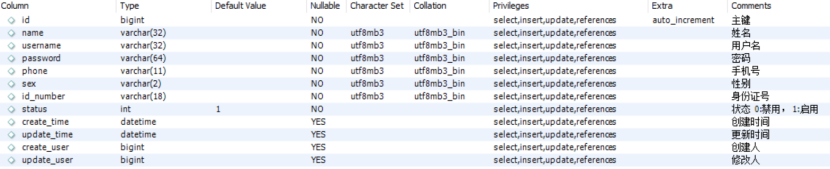
1.2 数据库设计
创建相应的employee表
1.3 代码开发
在说具体代码逻辑之前,我在说下使用employeeDto来封装返回给前端的数据而不是用employee的原因:
给前端提交的数据和实体类中的数据属性差异比较大
下面是employeeDTO的属性(也是前端所需要提交给后端的属性)
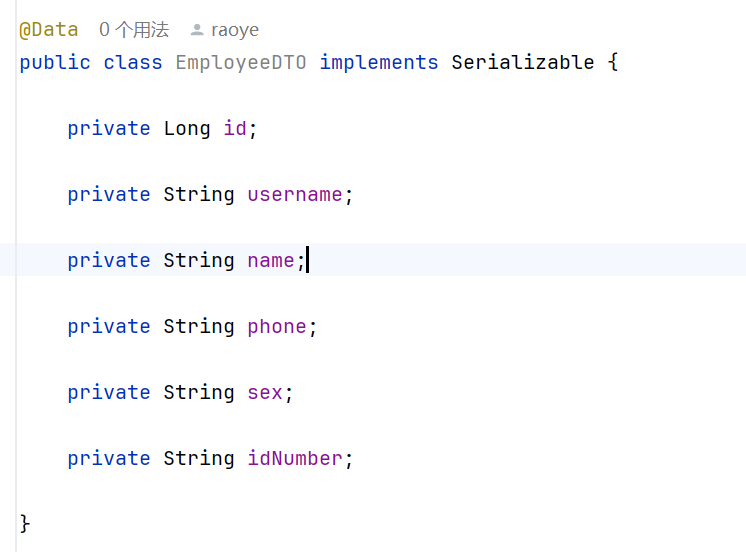
而在employee表中,在上面属性的基础上多出来以下属性:
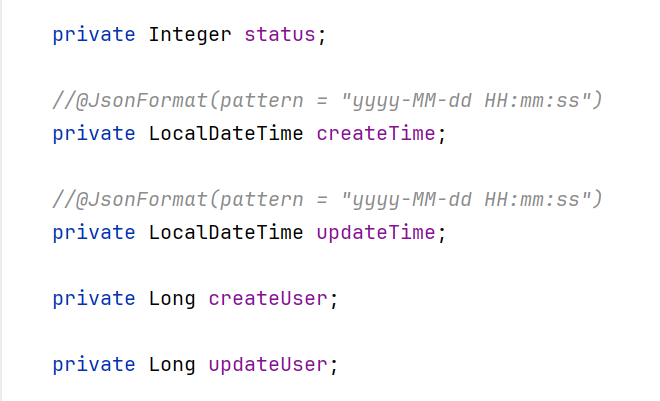
如果我们直接用employee的话,这些属性前端也需要提交,非常的不方便和多余
接下来是具体的代码逻辑:
先写controller层,按接口文档是提交数据,我们写postMapping(请求路径类上已经写好了),为了测试更清晰,API注解写好。因为提交的是json数据,所以要写@RequestBody注解。这里我们稍微复习一下:
@RequestParam是提交参数
@pathVariable 是提交路径
然后要注意的是我们给前端的数据是封装到employeeDto里的,所以传入的参数是dto而不是employee

这里写完一个方法或者是接口以后记得把注释(/**+enter回车)一并加上,养成一个好习惯
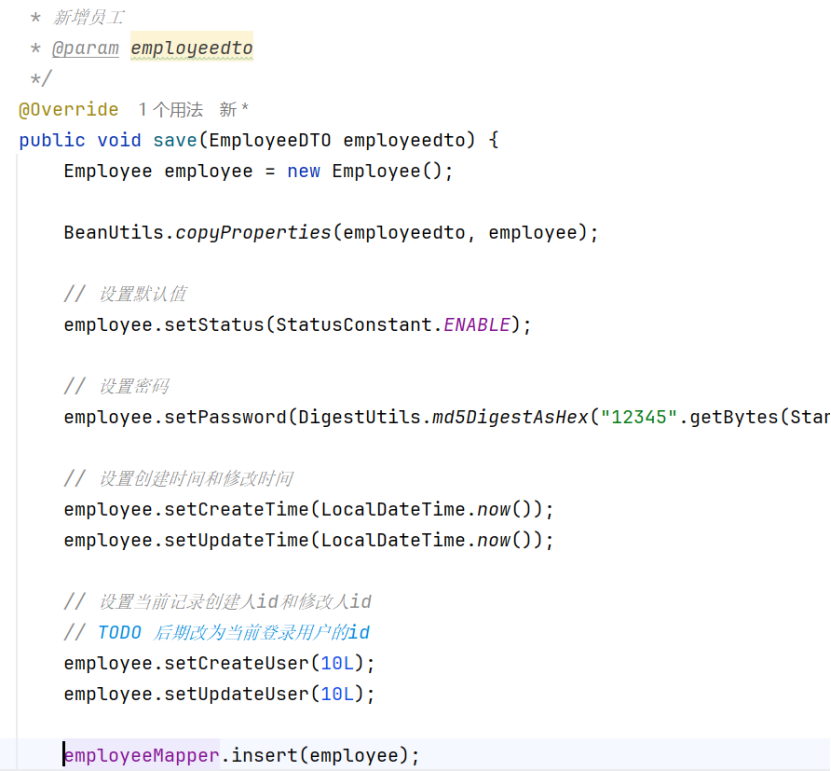
下面是service层(实现类)
这里是让employeeDTO 和employee进行一个数据的”交接”,因为数据库最后储存的还是employee格式的数据,数据从前端先是传给DTO,在从DTO通过BeanUtils类中的copyProperties 传给employee,最后将其他没有传递的数据设置上相应的值
这里注意记录创始人和修改人应该是动态的
所以放置了一个TODO等待修改
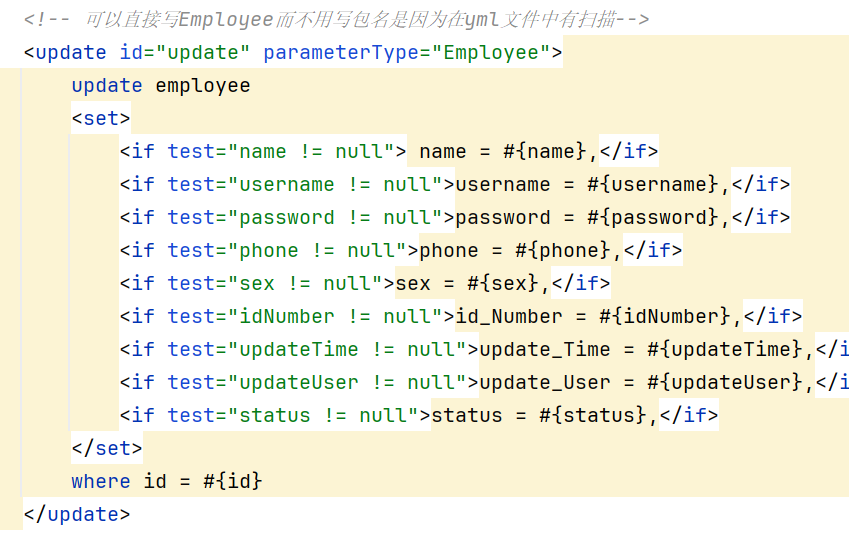
再接下来是mapper层,注意变量名字写对并且一一对应
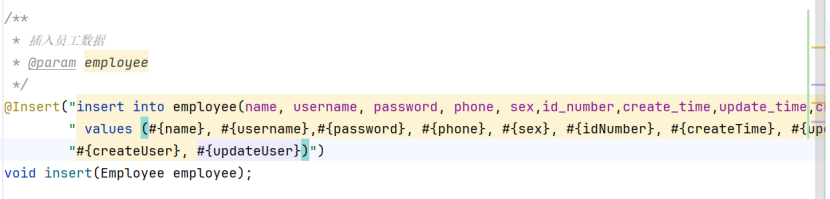
这里稍微说下idNumber能跟id_number对应上的原因:
yml文件存在这个配置文件
两种命名方式可以一一对应

1.4代码测试
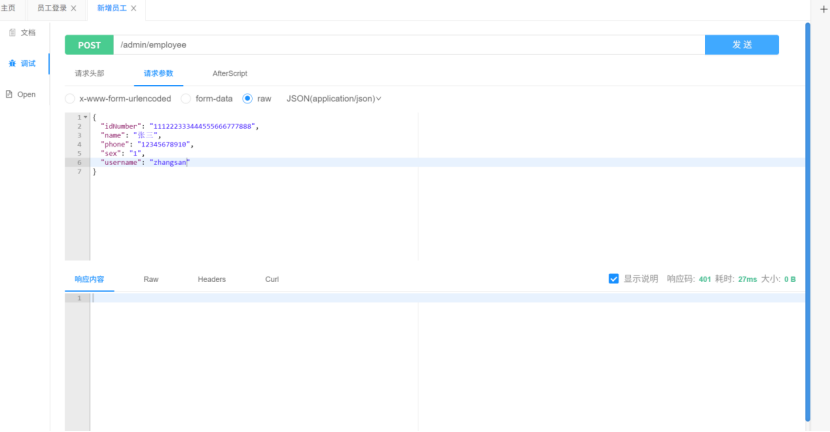
这里显示401因为该项目有一个全局拦截器JwtTokenAdminInterceptor(JWT令牌校验),
所以请求的参数里应该带个token进行校验
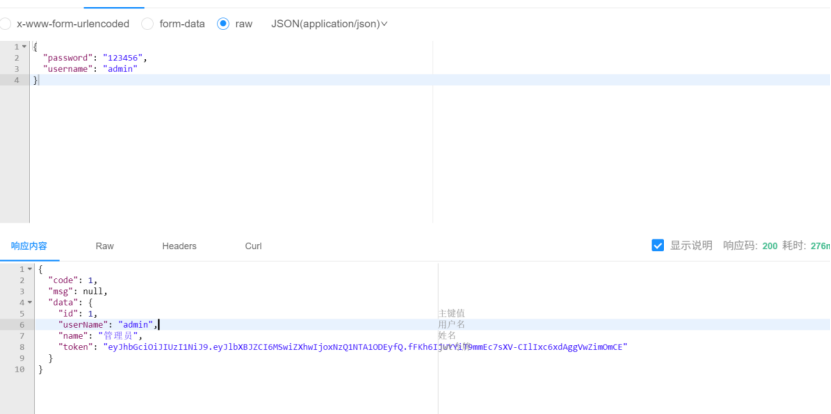
从员工登录这获取token
在文档管理添加全局变量token,记得参数名和配置文件中参数名保持一致
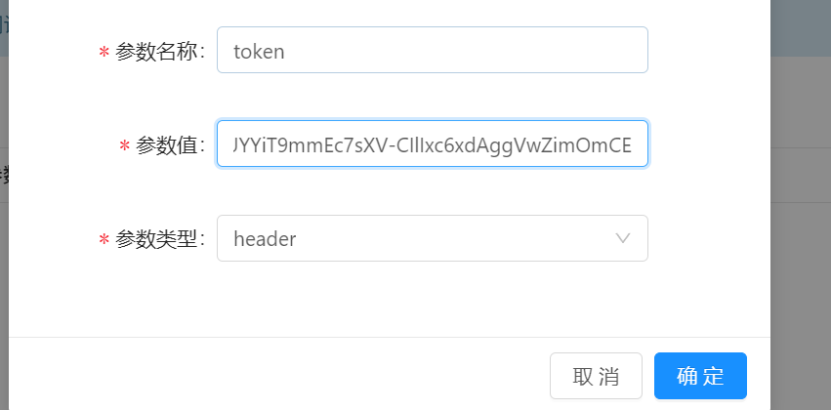

加入token后,重新请求(记得要关闭后重新打开)可以看到请求成功
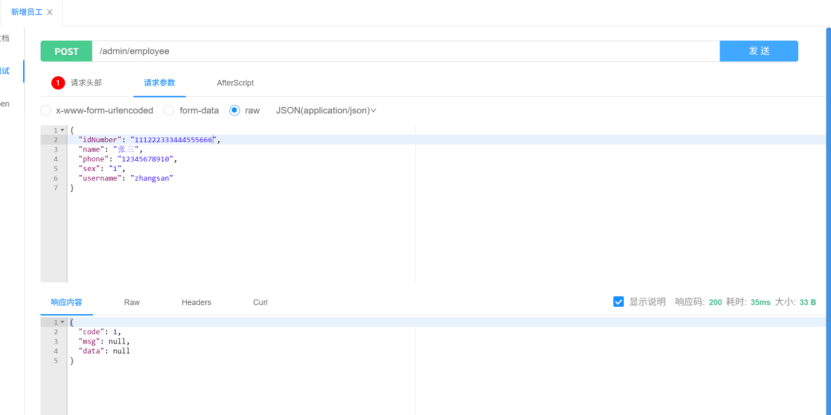
1.5 完善功能
第一个问题: 账号已存在的异常被抛出后没有被处理(响应码500)

解决方法:
在GlobalExceptionHandler类(接全局抛出异常的那个类)中加入关于SQL异常的处理
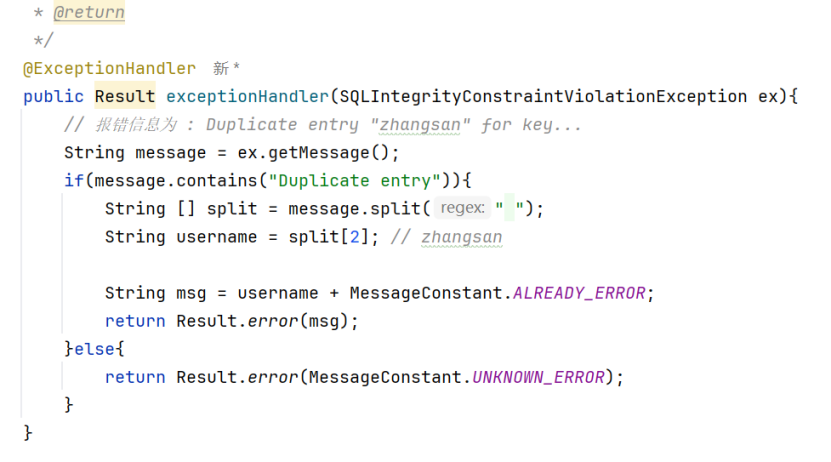
该代码逻辑是如果找到有关“账号已存在”的错误信息字段(Duplicate entry),就按报错都特定顺序找到其姓名,后续输出异常信息
当然,如果没能找到,就以sql的未知错误来处理,记得要加上全局异常处理的注解@ExceptionHandler
修改完进行代码测试可以看到以下效果(这里添加重复的账号)
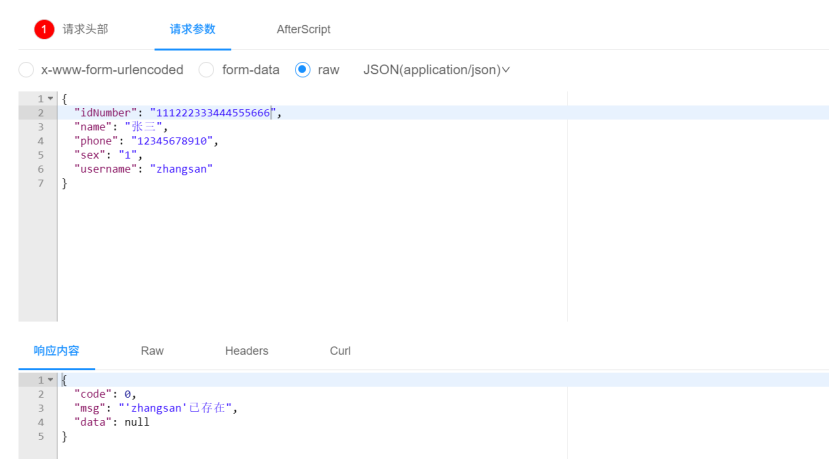
第二个问题:
没能动态的根据用户的id生成相应的createUser
解决方法:
使用ThreadLocal
ThreadLocal不是一个Thread,而是Thread定义的一个局部变量

他的作用是为每个线程提供一个单独的储存空间,具有隔离效果,只有在线程内才能获得相应的值,线程外是不能访问的
而每次请求都相当于一个单独的线程
因此可以用这个动态的生成id
具体方案:
- 添加账户前,我们需要进行令牌校验,而在解析校验令牌的时候就可以拿到相应的用户id
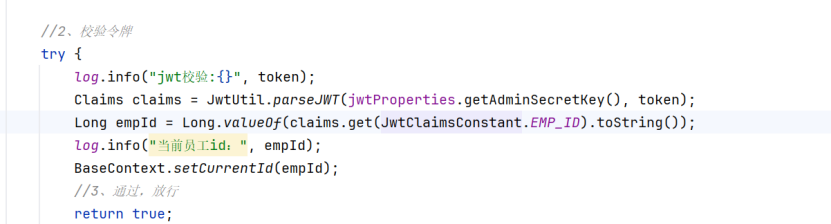
这里使用BaseContext.setCurrentId(empId)给这个线程添加id的值
2.通过校验后执行controller-service-mapper层,运行到service层时用getCurrentId()填充createUser

2. 开发其他功能的一些注意事项和创新点
因为开发流程大抵是相同的,所以在这我只挑一些内容进行记录
2.1 PageHelper运行原理
疑问:
这两行看起来毫不相干的代码时如何连起来完成分页查询的
答案:
根据上面所讲的ThreadLocal
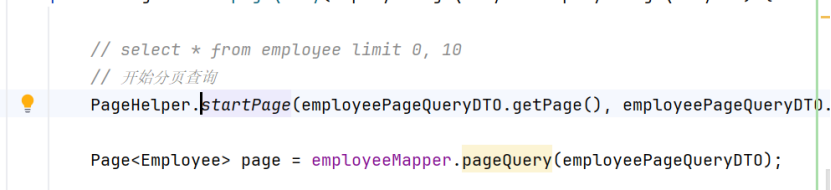
打开startPage源码,可以看到startPage函数里有一个setLocalPage函数
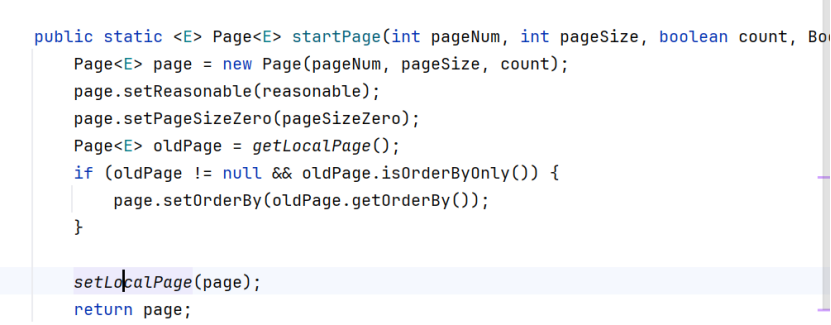
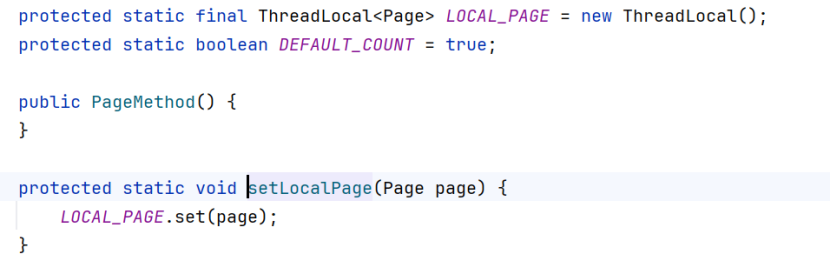
打开这个方法,可以看到这里定义了一个ThreadLocal变量LoCAL_PAGE,以及setLocalPage方法,这个方法用set()给Page数据储存在线程空间里(page中封装了页码和每页展示数,即limit后第一个数和第二个数,下面一行代码是page的对象创建)。
Page<E> page = new Page(pageNum, pageSize, count(boolean))
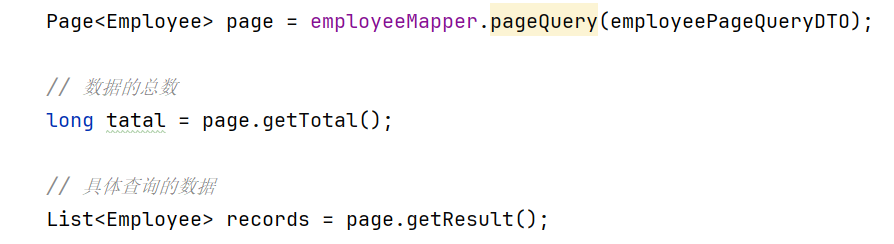
接着在执行employee.pageQuery()的时候会用get()给这几个数取出来,而具体查询到的数据会封装到Page<E>中return返回
这里我们用Page<employee>类型的变量接收
最后得到数据总数和取出这些数据使用相应封装的getTotal(), getResult()方法即可
2.2 java对象序列化
目的:将createTime,updateTime由数组转化成日期格式(json格式)
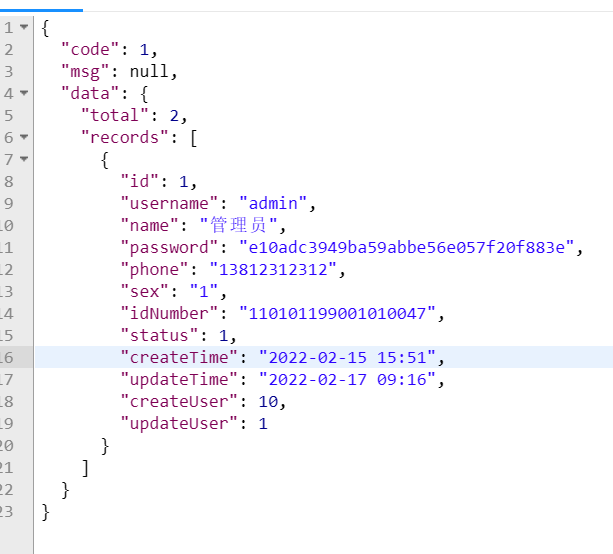
这里只要在配置类中(WebMVCConfiguration)中重写extendMessageConverters方法即可
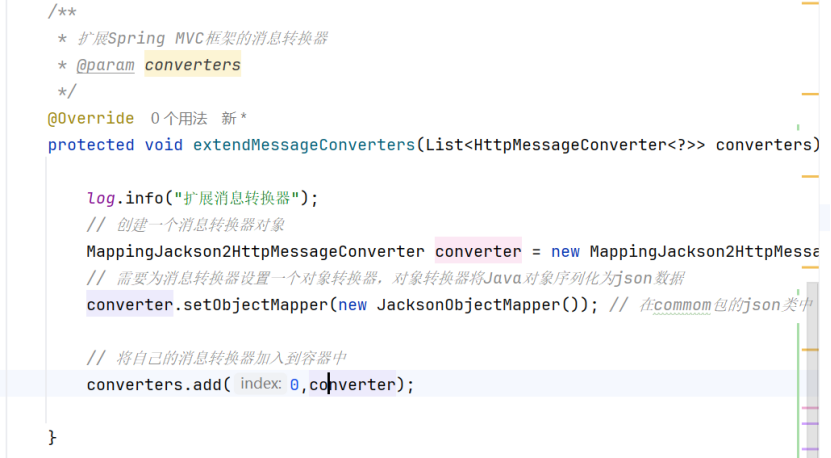
其中JacksonObjectMapper是我们定义的json包下的一个类
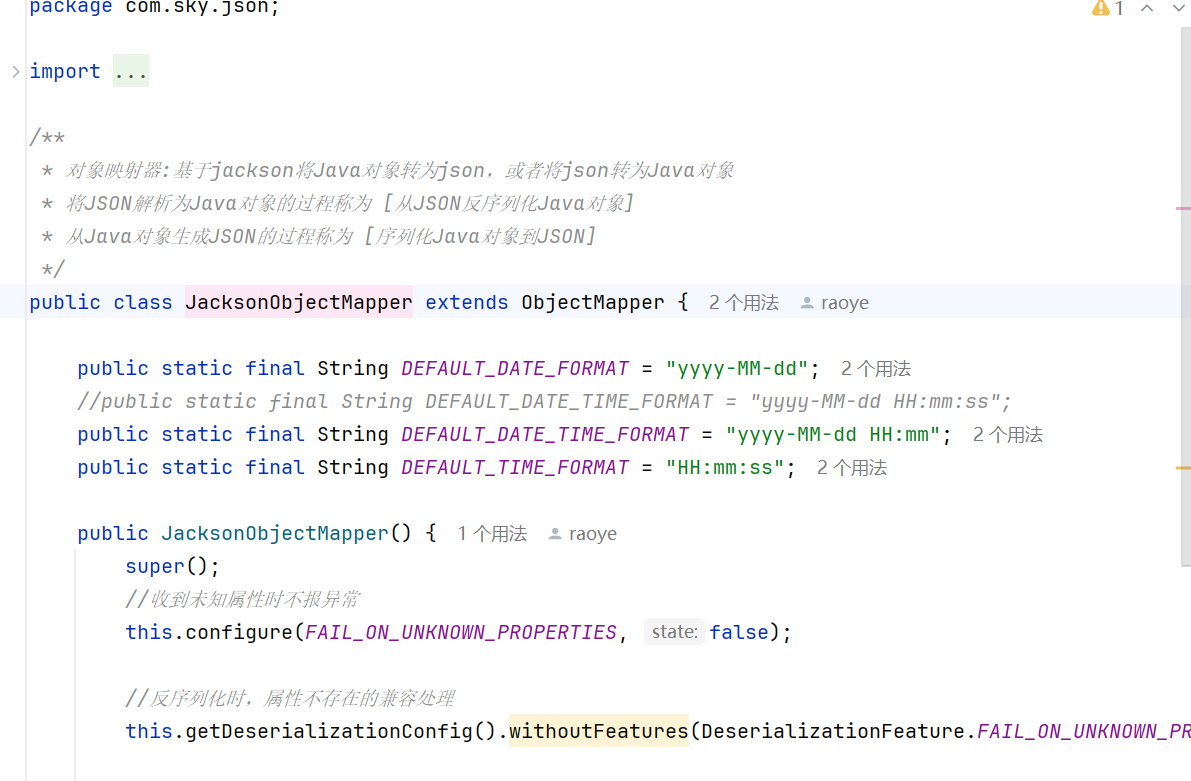
2.3 小技巧
2.3.1builder创建对象

这个就相当于new employee()一个对象,然后用set方法给id,status填充好,只不过更方便一点
当然,记得给相应类(这里是employee)上加上builder注解

2.3.2 动态SQL写全类名
通常情况下,使用mapper的动态SQL的话,我们要写全类名(比如resultType)
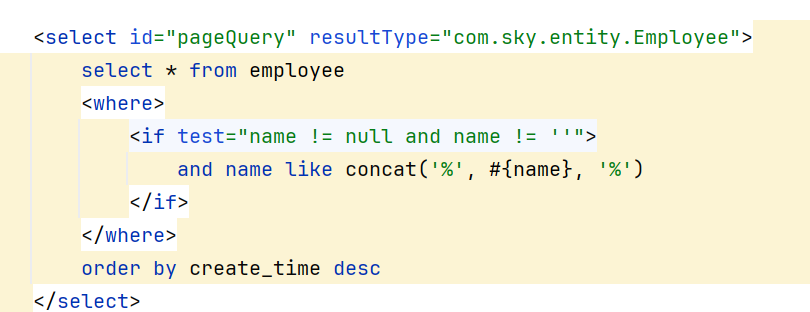
如果不想写,可以在yml文件中加上这么一块(type-aliases-packge)
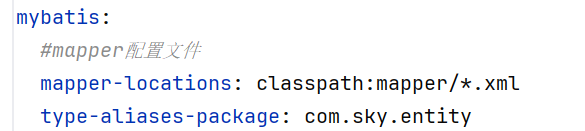
这样就可以直接写类名了(因为在yml文件中有扫描)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)