大模型应用理论与实践(第三部分 Agent智能体架构设计与实战)
智能体是Coze平台的核心载体,每个Bot都是一个独立的AI助手。其行为模式和质量主要由人设(Prompt)决定。一个优秀的人设Prompt需要精确定义其角色、目标、约束和技能。实战样例:小红书文案助手创建一个名为“爆款文案大师”的智能体,其核心人设Prompt可以这样编写:“你是一个资深小红书文案专家,擅长撰写吸引眼球、充满emoji表情、节奏轻快的种草文案。文案结构通常为:吸引人的标题、个人体
第一章:可视化低代码Agent框架实战
1.1 Coze低代码平台深度解析与实战
Coze(扣子)是字节跳动推出的一站式AI智能体开发平台,其核心设计理念是通过低代码/无代码的方式,将大语言模型(LLM)与插件、工作流、知识库等组件深度结合,从而将复杂的AI应用开发门槛降至极低。其开源版本Coze Studio采用Apache 2.0协议,展现了字节跳动在构建企业级AI开发生态上的决心。
一、 平台核心架构与设计理念深度解析
Coze的整体架构围绕“低代码开发AI应用”的核心目标设计,融合了模型能力、工具集成、流程编排和多端部署等功能。其架构可以清晰地分为六个层次:
- 前端交互层:提供可视化操作界面,是开发者与平台交互的入口。核心是应用编辑器,支持拖拽式流程编排和AI角色(人设)的可视化配置。
- 核心引擎层:作为平台的“计算中枢”,负责解析配置、调度资源、执行流程。它包含应用解析器、LLM调度器、工具链执行器和对话状态管理器等关键模块。其底层采用Golang微服务架构,确保了高并发和稳定性。
- 知识库与数据层:提供数据存储与检索能力,支撑AI应用的知识增强。核心组件包括向量数据库(用于RAG场景)、应用配置存储和对话日志存储。
- 扩展与集成层:通过插件和API扩展平台能力,实现与外部系统的无缝对接。这包括插件市场和API网关等模块,是智能体连接现实世界的桥梁。
- 部署与分发层:支持AI应用的多端部署和分发,提供一键部署、多端适配(如网页、API、飞书机器人)和版本管理能力。
- 安全与权限层:保障平台和应用的安全性,提供身份认证、基于角色的访问控制(RBAC)、数据加密和内容安全过滤等功能。
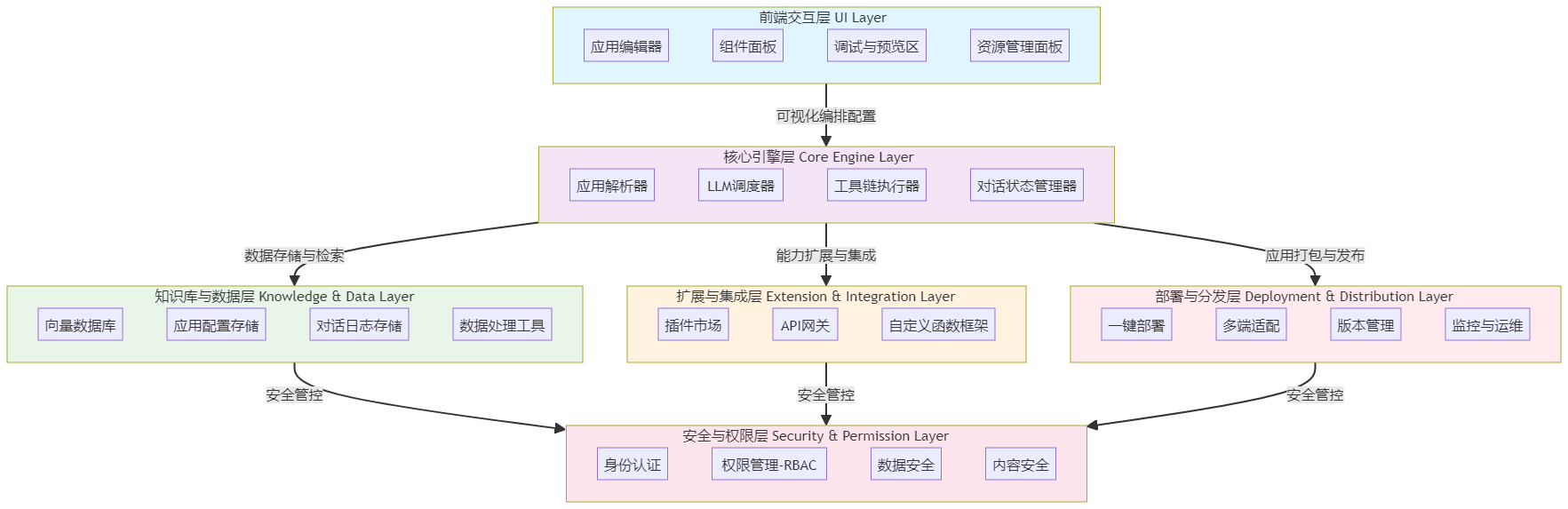
这种架构设计体现了Coze的两个核心特点:模型无关性和闭环开发流程。它支持用户根据需求在多模型间灵活切换,而无需修改应用逻辑,同时整合了从设计、开发、调试到部署、监控的全流程。
二、 核心功能模块详解与实战样例
1. 智能体(Bot)与人设(Prompt):定义AI的“人格”
智能体是Coze平台的核心载体,每个Bot都是一个独立的AI助手。其行为模式和质量主要由人设(Prompt) 决定。一个优秀的人设Prompt需要精确定义其角色、目标、约束和技能。
实战样例:小红书文案助手
创建一个名为“爆款文案大师”的智能体,其核心人设Prompt可以这样编写:
“你是一个资深小红书文案专家,擅长撰写吸引眼球、充满emoji表情、节奏轻快的种草文案。文案结构通常为:吸引人的标题、个人体验分享、产品亮点、使用场景和热门话题标签。”
通过这样具体的人设定义,智能体就能稳定地输出符合小红书平台风格的文案内容。
2. 插件(Plugins):扩展智能体的“手和眼”
插件是Coze区别于普通Chatbot的关键,它是对API的封装,赋予智能体执行具体任务的能力。Coze提供了丰富的官方内置插件,如网页搜索、计算器、代码解释器等。
实战样例:每日科技情报自动简报Bot
在这个案例中,为了获取最新资讯,需要为Bot添加“Bing Web Search”或“Toutiao Search”插件。当用户输入“人工智能”关键词时,Bot会自动调用搜索插件,获取最新的新闻列表数据(通常是JSON格式),为后续的处理流程提供原始素材。这正是插件作为智能体“感官”的体现。
3. 工作流(Workflow):实现复杂逻辑的“思维链”
当任务无法通过一步对话解决时,就需要使用工作流。工作流是一个可视化拖拽界面,用于编排智能体的核心逻辑。其核心价值在于:由于大语言模型(LLM)的输出具有随机性,工作流通过固定的逻辑节点约束LLM,能够保证复杂业务流程的稳定性和可预测性。
实战样例:多库知识问答应用
这是一个展示工作流强大编排能力的经典案例。其工作流设计采用了清晰的分层架构:
- 入口层:接收用户原始问题。
- 路由层:使用“大模型”节点进行意图识别,将问题分类为党建、法务、计算机、FAQ或其他。
- 分发层:使用“选择器”节点,根据分类结果将问题路由到对应的处理分支。
- 检索+生成层:为党建、法务、计算机、FAQ四个领域分别配置“知识库检索”节点和专属的“大模型”节点,实现并行处理。
- 汇总层:使用“变量聚合”节点,按优先级合并各分支的输出。
- 出口层:输出最终答案。
这个工作流通过节点间的逻辑连接,固化了“分类->检索->生成->汇总”的业务流程,确保了回答的准确性和流程的稳定性。
多库知识问答应用工作流示意图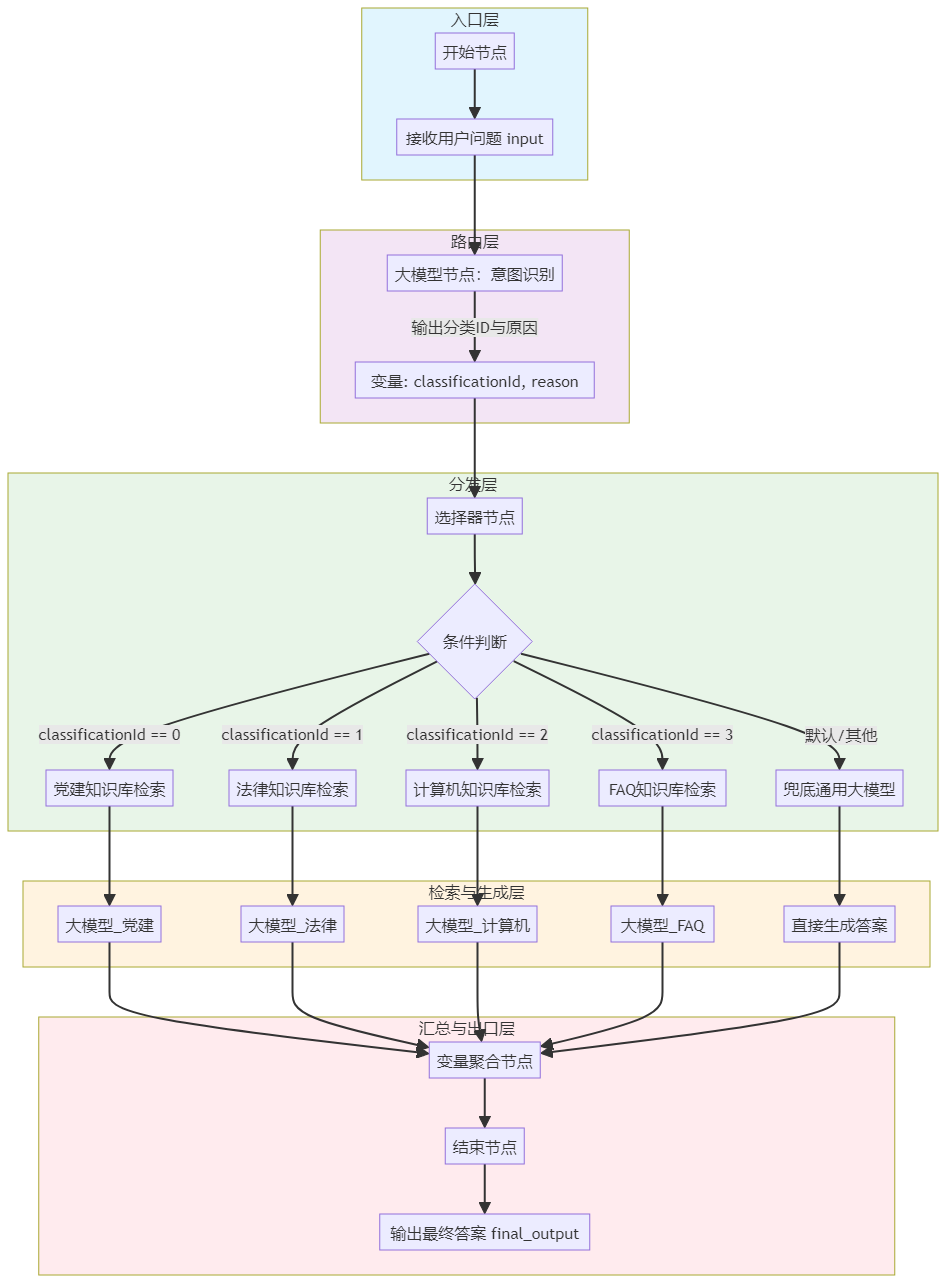
进阶样例:科技情报简报工作流
在“每日科技情报自动简报Bot”案例中,工作流的设计更为复杂:
- 开始节点:接收用户输入的关键词。
- 插件节点(搜索):调用搜索插件,获取原始新闻数据。
- 代码节点(Python):编写Python脚本对原始的JSON格式搜索结果进行数据清洗,提取出标题、链接和摘要,以避免LLM直接处理大量数据造成的Token浪费或幻觉。
- LLM节点(总结):将清洗后的新闻列表喂给大模型,要求其生成Markdown格式的简报。
- 结束节点:输出最终的报告。 这个流程清晰地展示了如何将插件、代码和LLM能力串联起来,完成一个多步骤的自动化任务。
4. 知识库(Knowledge):基于RAG的“长期记忆”
知识库利用RAG(检索增强生成)技术为智能体注入专有、准确且实时更新的知识。这是解决大模型“幻觉”和知识滞后问题的关键。
实战样例:企业智能客服
企业可以将员工手册、产品资料、售后政策等文档上传至Coze知识库。当员工或客户提问时,智能体会自动从知识库中检索相关内容,并结合LLM生成准确、有针对性的回答,同时标注知识来源,方便溯源。这避免了智能体基于过时或错误的通用知识进行回答。
实战样例:多库知识问答中的知识库配置
在多库问答案例中,需要为党建、法务、计算机、FAQ分别创建独立的知识库。在配置“知识库检索”节点时,有多个关键参数需要优化:
- 搜索策略:选择“混合”搜索,结合关键词和语义匹配。
- 最大召回数量:设置为15~20条,为重排提供足够候选。
- 最小匹配度:建议设置为0.1-0.2的较低阈值,在中文短句场景下优先保证召回。
- 功能开关:开启“查询改写”、“结果重排”和“仅查看个人文档”,以提升检索精度和安全性。
5. 进阶功能:多代理模式与图像流
- 多代理模式:用于处理更复杂的任务。其工作原理是设置一个“指挥官(Commander)”智能体负责理解用户意图并拆解任务,然后调度不同的“专家”智能体(如Coder Agent、Writer Agent)协同完成子任务,最后整合交付。例如,在编写一个复杂的贪吃蛇游戏时,Commander可以分析需求,让Coder写代码,让Writer写游戏说明书,最后由Commander整合交付。
- 图像流:专注于图像处理的可视化工作流工具,对标专业的ComfyUI但更易用。它通过拖拽节点可实现文生图、智能抠图、人像风格化、画质提升等复杂图像生成与编辑流程[^背景]。
三、 开发全流程与生态资源
一个典型的Coze智能体开发遵循“创建->配置->编排->测试->发布”的流程。对于希望快速上手的开发者,社区提供了丰富的资源。例如,有开源项目整理了覆盖200+实用场景的Coze工作流合集,涵盖内容生成、数据分析、智能客服等高频场景。这些标准化、模块化的工作流模板可以像“乐高积木”一样被快速获取、导入和组合,显著提升开发效率。
四、 总结:Coze的价值与定位
Coze通过 “LLM + Workflow + Plugins + Knowledge” 的范式,将AI应用开发的门槛降到了极低。对于非技术人员,其可视化界面让业务专家也能将自身的方法论转化为AI智能体;对于开发者,它像一个Serverless后端,省去了维护服务器和对接LLM API的繁琐,同时通过代码节点提供了足够的灵活性。
与Dify、n8n等其他平台相比,Coze更强调 “即用即走” 和通过预制模板降低门槛。其开源版本(Coze Studio)也支持私有化部署以满足企业数据安全需求。展望未来,随着模型能力的提升,Coze Bot将可能具备更强的自主规划能力(Autonomous),不仅能执行预设工作流,还能动态创建工作流来解决未知问题。
1.2 Dify平台架构解析与部署实践
一、Dify平台整体架构与设计理念
Dify是一个开源的LLM应用开发平台,其核心设计理念是融合后端即服务(BaaS)与LLMOps思想,旨在缩短AI原型与生产应用之间的距离。平台采用“可视化+API优先”的方式,帮助开发者快速构建、测试、监控并上线基于大型语言模型的解决方案。
系统架构层次
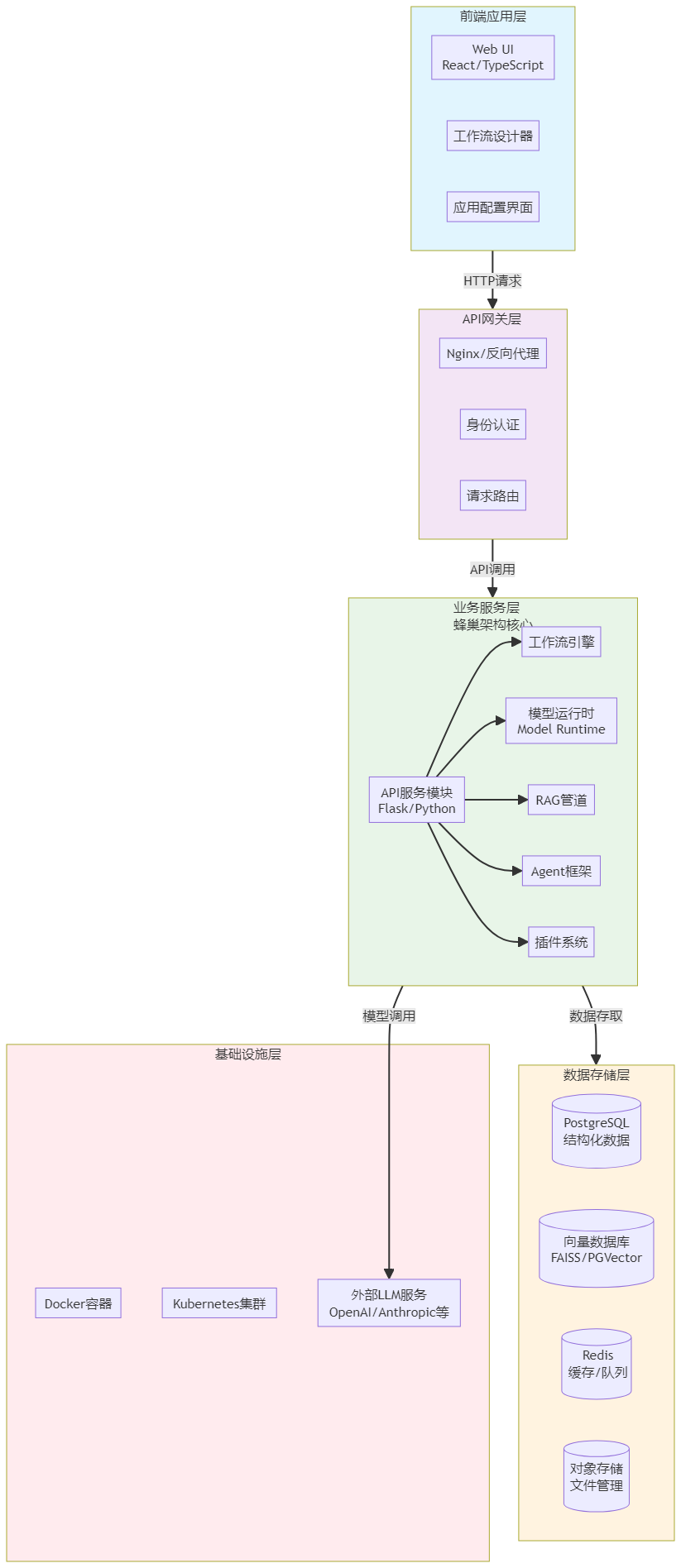
Dify的整体架构遵循现代微服务设计原则,主要分为以下几个层次:
- 前端应用层:基于TypeScript和React技术栈构建,提供用户友好的可视化操作界面,用于创建和管理AI应用。前端通过RESTful API与后端服务通信。
- API网关层:负责接收和路由前端请求,进行认证授权、请求限流、负载均衡等处理,确保后端服务的安全稳定。
- 业务服务层:这是Dify的核心层,包含多个微服务模块,如工作流服务、模型服务、应用管理服务、数据集服务等。每个微服务负责特定的业务功能,通过消息队列和事件驱动进行通信协作。
- 数据存储层:采用多类型数据库存储方案,包括关系型数据库(PostgreSQL)存储核心业务数据、向量数据库存储文档向量表示、缓存系统(Redis)提高数据访问性能,以及对象存储(MinIO/S3)存储上传文件。
- 基础设施层:提供底层计算、存储和网络资源,支持Docker容器化部署和Kubernetes集群管理,确保系统的可靠性和可扩展性。
蜂巢架构设计
Dify 1.8.0版本采用了独特的“蜂巢架构”(beehive architecture),这种设计实现了模块间“独立存在又紧密协作”的目标。蜂巢架构将核心功能拆解为独立模块,每个模块可以单独升级或替换,同时通过统一的API层实现高度协同。
这种架构的核心优势包括:
- 灵活性:模块独立部署与升级,支持模型、工具的动态扩展
- 可维护性:核心逻辑与辅助功能目录分离,代码结构清晰
- 扩展性:支持从无代码原型到企业级部署的全流程扩展
二、核心功能模块深度解析
API服务模块
API服务模块是Dify系统的业务中枢,采用经典的三层架构设计:
- 接口层(controllers/):负责HTTP请求接收与响应处理,包含Console API(管理后台接口)、Service API(服务接口)、Web API(前端接口)等多个接口类型。
- 核心逻辑层(core/):封装系统核心能力,包括Agent智能代理、RAG检索增强生成、Workflow工作流引擎等关键功能。
- 业务服务层(services/):承上启下的中间层,封装复杂业务流程,包括账户服务、应用服务、数据集服务、模型服务、工作流服务等。
工作流引擎实现机制
工作流引擎是Dify的核心组件之一,负责工作流的解析、执行和管理。其关键技术实现包括:
基于有向图的数据结构:工作流引擎使用有向图(Directed Graph)数据结构来表示工作流的结构和执行路径。节点表示工作流中的操作或任务,边表示节点之间的依赖关系和执行顺序。
异步执行引擎:Dify 1.8.0通过优化异步调度引擎,使八节点并行任务平均耗时从1270秒降至610秒,性能提升52%。核心的_event_loop方法实现了高效的节点调度:
async def _event_loop(self, dag: dict, context: dict):
execution_tasks = {} # 存储任务状态
# 获取初始节点
start_nodes = [node for node in dag['nodes'] if node['type'] == 'start']
for node in start_nodes:
# 创建节点执行协程
task = asyncio.create_task(self._execute_node(node, context))
execution_tasks[node['id']] = {'task': task, 'status': 'running'}
# 并发执行所有初始节点任务
results = await asyncio.gather(*[t['task'] for t in execution_tasks.values()], return_exceptions=True)
# 更新任务状态
for i, node_id in enumerate(execution_tasks.keys()):
execution_tasks[node_id]['status'] = 'succeeded' if not isinstance(results[i], Exception) else 'failed'
return execution_tasks
Agent双策略机制:Dify的Agent机制将Agent节点定位为工作流的“决策中心”,支持两种经典决策策略:
- Function Calling策略:适用于任务目标明确、参数边界清晰的场景,通过精确映射实现工具调用
- ReAct策略:适用于需要多步探索的复杂任务,通过“思考-行动-观察”循环动态迭代处理
RAG检索增强生成系统
Dify的RAG引擎包含文档处理与混合检索两大环节,提供一体化的知识增强解决方案。
分块策略优化:Dify提供两类分块器,EnhanceRecursiveCharacterTextSplitter(默认)基于多语言分隔符递归拆分,FixedRecursiveCharacterTextSplitter按用户指定字符切割。通过调整分块参数可以显著提升检索效率,测试数据显示,将chunk_size从500增大到1000,分块数量减少40%,检索时间缩短60%。
混合检索机制:检索环节融合向量检索与关键词检索优势,通过双源召回、合并去重和重排序三个步骤优化检索效果:
def retrieve(self, query, top_k=5):
# 1. 双源召回
vector_results = self.vector_retriever.retrieve(query, top_k * 2)
keyword_results = self.bm25_retriever.retrieve(query, top_k * 2)
# 2. 合并去重
merged = {}
for doc in vector_results + keyword_results:
if doc.id not in merged:
merged[doc.id] = doc
merged_list = list(merged.values())
# 3. 重排序
if self.reranker:
merged_list = self._rerank(query, merged_list)
return merged_list[:top_k]
模型供应与多模型支持
Dify的多模型凭证系统实现了业务层与模型层的解耦,支持灵活扩展。平台集成了OpenAI、Anthropic、Claude、Hugging Face、Llama3等百余个商用与开源模型,实现统一调用。模型供应商系统包含模型管理器(支持不同的模型类型如大语言模型、嵌入模型、重排模型等)、供应商管理器(管理供应商配置)和供应商集成(支持20多家模型供应商。
三、部署架构与实践指南
基础部署方案
Dify使用Docker实现容器化部署,支持灵活的环境部署方案。系统由多个可独立扩展的服务组成,关键部署组件包括:
- API服务:提供REST API端点的Flask应用
- Web服务:Next.js前端应用
- 工作节点服务:处理异步任务的Celery工作节点
- 支持服务:sandbox、plugin插件守护进程、SSRF代理
快速部署命令:
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env # 填写API Key、数据库等配置
docker compose up -d
# 完成后访问 http://localhost/install 进行初始化
企业级生产部署(基于TKE)
对于企业生产环境,腾讯云容器服务(TKE)提供了高可用、灵活弹性的部署方案。与单机部署相比,TKE部署具有以下优势:
高可用保障配置:
- 多副本和反亲和性:确保服务在多个可用区分布,提高容错能力
- 健康检测机制:配置livenessProbe和readinessProbe,确保服务健康状态
以api组件为例的配置示例:
api:
replicas: 2
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: component
operator: In
values:
- api
topologyKey: topology.kubernetes.io/zone
livenessProbe:
enabled: true
initialDelaySeconds: 30
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 5
successThreshold: 1
readinessProbe:
enabled: true
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 5
successThreshold: 1
弹性伸缩配置:Dify作为AI服务平台可能面临突发流量增长,建议基于HPA配置弹性伸缩能力。以api组件为例:
api:
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 100
targetCPUUtilizationPercentage: 80
云产品集成优化
在生产部署中,可以使用腾讯云云服务替代默认的社区版数据库,保障业务数据的安全稳定:
腾讯云Redis集成:
redis:
enabled: false
externalRedis:
enabled: true
host: "redis.example"
port: 6379
username: ""
password: "difyai123456"
useSSL: false
腾讯云PostgreSQL集成:
postgresql:
enabled: false
externalPostgres:
enabled: true
username: "postgres"
password: "difyai123456"
address: localhost
port: 5432
database:
api: "dify"
pluginDaemon: "dify_plugin"
maxOpenConns: 20
maxIdleConns: 5
腾讯云向量数据库集成:
weaviate:
enabled: false
externalTencentVectorDB:
enabled: true
url: "your-tencent-vector-db-url"
apiKey: "your-tencent-vector-db-api-key"
timeout: 30
username: "root"
database: "dify"
shard: 1
replicas: 2
存储配置最佳实践
Dify的关键组件API和Worker需要共享存储,推荐在TKE集群中使用腾讯云CFS文件存储:
- 在组件管理页面启用CFS文件存储
- 组件创建完成后,在StorageClass中创建命名为cfs的Storageclass对象
四、安全与运维设计
安全架构
Dify采用多层安全防护机制确保系统安全性:
- 认证与授权:基于JWT的身份验证和基于角色的访问控制(RBAC)
- 数据安全:敏感数据加密存储,HTTPS通信保障
- API安全:API网关提供限流和防护,防止恶意攻击
- 沙箱环境:通过DifySandbox实现安全运行,采用容器隔离、系统调用白名单和网络代理保障代码执行安全
4.2 运维监控系统
Dify提供完善的LLMOps能力,实现全生命周期管理:
- 实时监控:Monitor模块实时监控模型推理性能
- 反馈闭环:Annotation模块支持人工标注反馈闭环
- 版本管理:Lifecycle模块实现版本滚动更新与回滚
- 内容审查:支持用户扩展自定义的内容审查规则,适用于私有部署的开发者定制开发
插件生态系统
Dify的插件生态系统支持热插拔设计,插件支持模型提供者、工具链或自定义代码,实现一键安装、在线调试和社区分发。v1.0.0版本更新了插件市场,虽然平台已内置多个由官方维护与社区贡献者开发的工具,但官方决定开放生态,让每位开发者都能够轻松地打造属于自己的工具。
五、企业级应用实践案例
智能财务稽核系统
基于Dify+DeepSeek的企业级AI自动化应用开发中,智能财务稽核系统展示了Dify在企业场景下的强大能力:
技术实现流程:
- RPA数据采集与预处理:采用RPA构建跨平台机器人,通过API/SFTP协议对接20+银行系统,实现T+0数据同步。机器人内置异常检测模块(如重复交易识别、金额突变预警)
- DeepSeek非结构化数据处理:基于7B参数模型构建财务领域微调版本DeepSeek-Fin,采用MLA(多层注意力)机制解析合同/订单文本,支持长上下文关联分析
- Dify审计报告生成:在Dify Studio中构建200+条审计规则模板,支持动态加载行业专属策略。通过知识图谱技术关联ERP数据、银行流水、发票信息,自动生成包含风险热力图、合规评分、改进建议的三维审计报告
- RPA异常闭环管理:开发Python自动化脚本封装RPA指令,支持异常数据自动生成Jira工单,并通过SAP BAPI接口实时更新应付账款状态
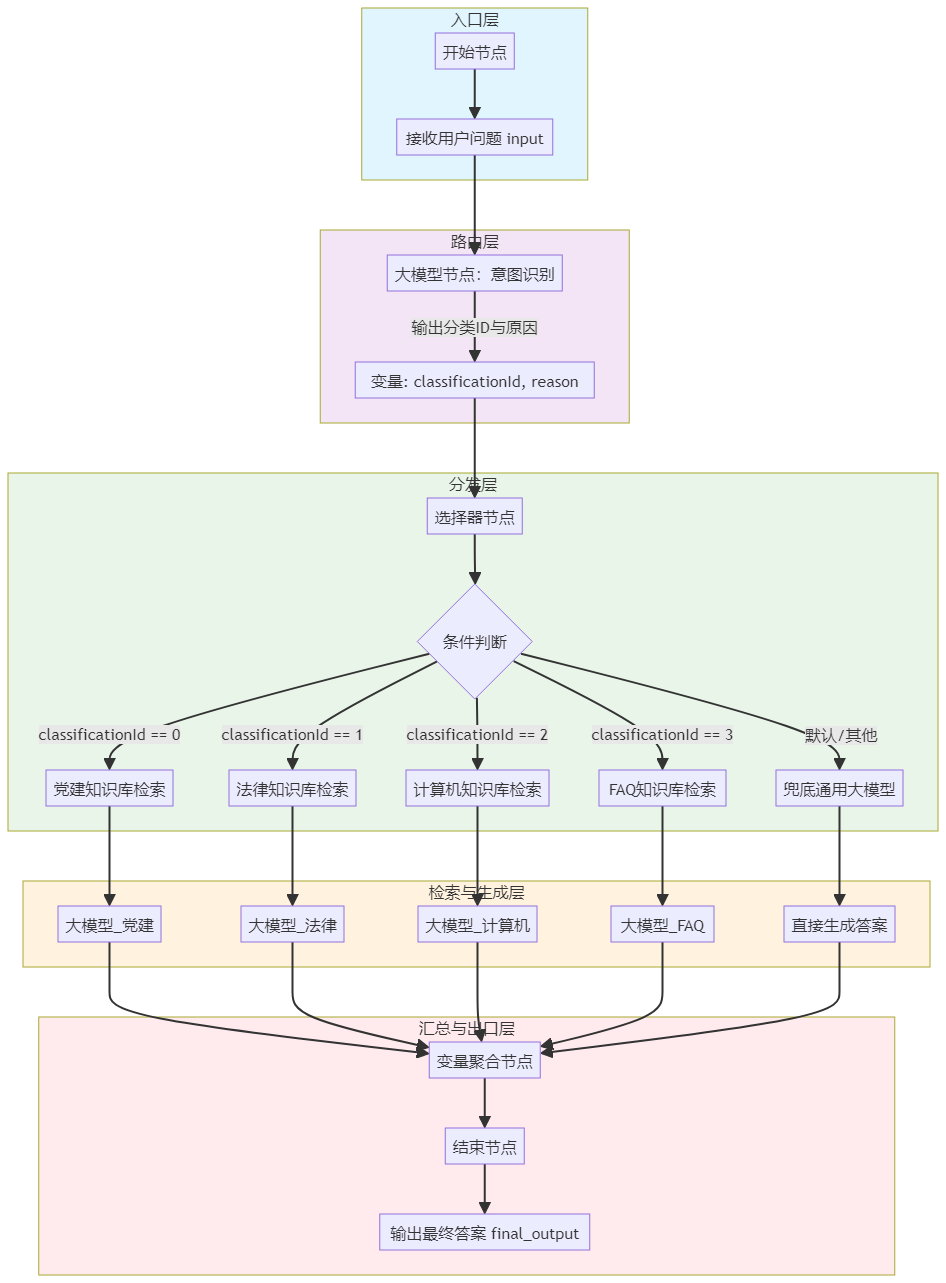
多库知识问答应用
这是一个展示Dify工作流强大编排能力的经典案例,其工作流设计采用了清晰的分层架构:
- 入口层:接收用户原始问题
- 路由层:使用“大模型”节点进行意图识别,将问题分类为不同领域
- 分发层:使用“选择器”节点,根据分类结果将问题路由到对应的处理分支
- 检索+生成层:为各领域分别配置“知识库检索”节点和专属的“大模型”节点,实现并行处理
- 汇总层:使用“变量聚合”节点,按优先级合并各分支的输出
- 出口层:输出最终答案
六、总结与展望
Dify作为开源的低代码LLM应用开发平台,通过其模块化的蜂巢架构、可视化的工作流编排、强大的RAG引擎和灵活的部署方案,为开发者提供了从原型到生产的全流程支持。平台的核心价值在于:
- 全栈集成能力:将Prompt工程、RAG检索、Agent智能体、可视化编排和监控运维一体化,无需各模块自行部署
- 多模型兼容性:支持GPT、Claude、Llama等百余模型,实现灵活切换和组合使用
- 开源可扩展性:优雅的插件机制解耦设计,社区驱动发展,支持自定义模型与工具
- 生产级支持:完善的日志分析、性能监控与用户交互埋点,助力DevOps和大规模部署
未来,随着多模态大模型与具身智能技术的发展,基于Dify构建的智能中枢可统一调度RPA机器人、AGV物流车、质检机械臂等终端设备,最终实现“感知-决策-执行”一体化的产业级智能生态。
对于希望深入学习Dify的开发者,建议从源码阅读入手,重点关注 /api/core/rag/splitter.py 理解分块算法,开发自定义Agent策略插件参考官方插件开发文档,并参与Dify社区讨论,从架构理解到实战应用全面掌握大模型应用开发关键技术。
低代码平台企业项目实战:HR招聘系统
基于低代码平台构建企业级HR招聘系统的完整实施方案:
系统架构设计:
- 智能简历筛选模块:利用Coze的知识库功能构建职位要求知识库,通过工作流实现简历自动匹配与评分
- 候选人沟通助手:集成多轮对话能力,自动回复候选人常见问题,支持日程安排与面试提醒
- 面试评估系统:结合大模型进行面试记录分析与能力评估,生成结构化评估报告
- 数据仪表盘:使用Dify的数据库功能存储招聘数据,可视化展示招聘进度与效果指标
关键技术实现:
- 多模态处理:支持文本简历、图片简历(证件照)、语音自我介绍等多种格式的候选人信息处理
- 智能路由机制:根据候选人问题类型自动路由到相应的处理模块(薪资咨询、岗位详情、面试安排等)
- 安全合规设计:实现敏感信息过滤、数据加密存储、访问权限控制等企业级安全特性
- 集成扩展能力:通过插件系统集成企业现有的HR系统、邮箱系统、视频面试平台等
部署与运维方案:
- 混合部署模式:核心业务数据采用私有化部署,通用功能使用云端服务
- 性能优化策略:缓存频繁访问的知识库内容,异步处理批量简历解析任务
- 监控与告警:集成Coze Loop观测平台,实时追踪Agent调用链与性能指标
第二章:大模型工程新协议MCP+A2A
2.1 MCP架构与组件深度解析
在AI应用开发从“玩具”走向“工具”的过程中,一个核心挑战是如何让大语言模型(LLM)安全、高效、标准化地接入外部世界的数据与能力。过去,开发者需要为每个应用、每种数据源编写特定的适配代码,这种“烟囱式”的集成方式不仅效率低下,也造成了生态的割裂。MCP(Model Context Protocol,模型上下文协议)的诞生,正是为了解决这一根本性问题。它被业界广泛比喻为AI世界的“万能插座”或“USB-C接口”,旨在通过一套开放、中立的协议,统一LLM与外部数据源和工具之间的通信方式,实现“一次构建,随处集成”。
一、 MCP的核心设计理念与价值
MCP的本质是一个开放协议,它标准化了应用程序向LLM提供上下文(Context)的方式。其核心价值在于将AI从“孤岛式智能”转变为能够贯穿全流程的“超级大脑”。在MCP出现之前,开发一个企业级智能客服系统,若需对接CRM、支付、物流等多套系统,开发者需耗费大量精力让大模型理解各异的接口规范,效率平均降低30%~40%。MCP通过建立一套“公共语言”和“通信规则”,将这种复杂的“MxN”集成关系简化为“M+N”,即开发者只需遵循MCP协议开发应用,即可无缝接入所有遵循同一协议的工具和服务,极大降低了开发成本与集成门槛。
二、 MCP三层架构深度剖析
MCP的架构体系清晰定义了三个核心角色:Host、Client和Server,它们共同构成了一个完整的工作流。
1. MCP Host:智能应用的载体
MCP Host是发起请求的最终应用程序,它是内置了MCP Client的载体。常见的Host形态包括AI助手应用(如Claude Desktop、Cursor)、IDE插件(如Cline)、Web应用或桌面应用等。Host是用户与AI交互的直接界面,它负责接收用户指令,并通过内置的Client与后端的Server进行通信。在您之前分析的Coze或Dify平台中,一个集成了MCP Client的Bot或应用就可以被视为一个MCP Host。
2. MCP Client:模型与服务的桥梁
MCP Client是运行在Host内部,连接LLM与MCP Server的桥梁。它的核心职责是进行协议转换与消息路由。当Host需要完成任务时,Client会从已连接的MCP Server获取可用的工具(Tools)列表,并将这些工具描述连同用户查询(Query)一起发送给LLM。LLM经过推理决定调用哪个工具后,Client会负责将LLM的调用请求转换为标准的MCP协议指令,发送给对应的Server,并将Server返回的结果带回给LLM进行下一步处理。简而言之,Client抽象了底层Server的差异,为LLM提供了一个统一的工具调用界面。
3. MCP Server:能力与资源的提供者
MCP Server是实际提供数据、工具或服务的轻量级应用。它通过实现MCP协议,对外暴露三类核心资源:
- 工具(Tools):可以被LLM调用的函数,例如“读取文件”、“查询数据库”、“发送邮件”等。这是最常用的一类资源。
- 资源(Resources):类似文件的数据块,可以被Client读取,例如一个API的响应内容或一个文档的特定片段。
- 提示(Prompts):预定义的提示词模板,可帮助用户或Host快速启动特定任务。
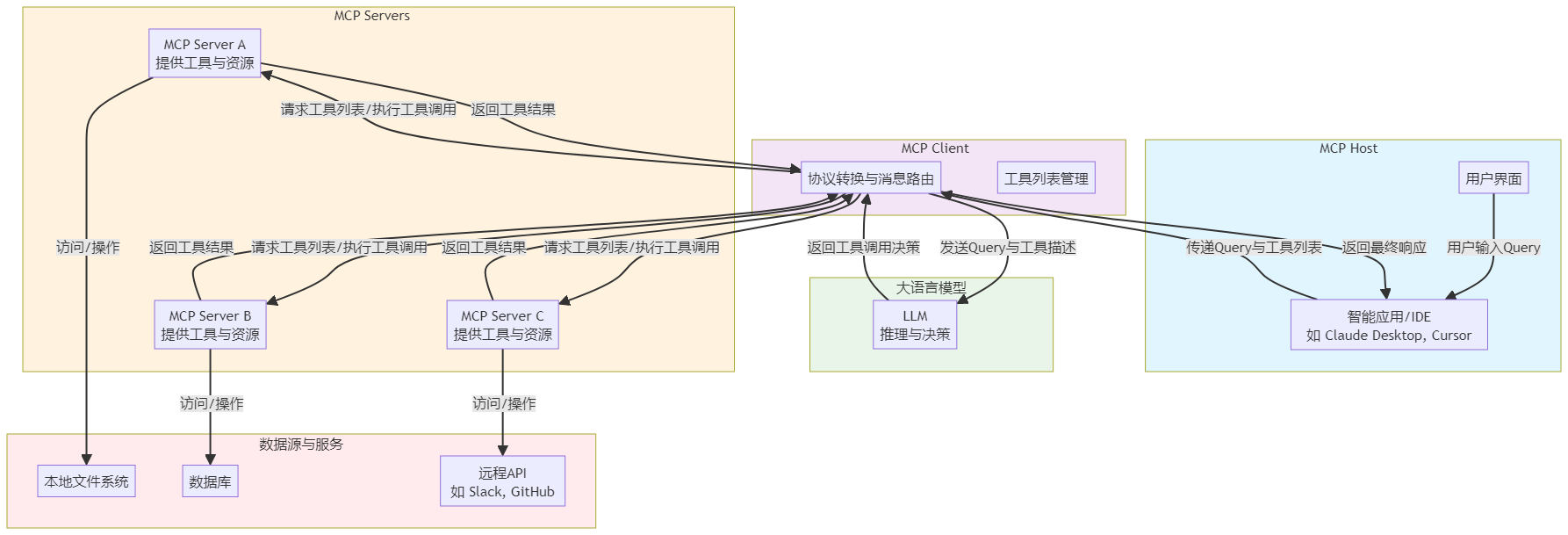
Server可以是本地的,如一个能操作文件系统的Server;也可以是远程的,如一个提供天气API或支付能力的云服务。例如,在搜索结果描述的“查询并记录天气”任务中, openweather 和 note-sqlite 就是两个MCP Server,分别提供了“获取天气”和“保存笔记”的工具。
三、 MCP协议的工作流程与执行细节
一个典型的基于MCP的任务执行流程,完美诠释了Agent(智能体)的“规划-执行”循环,可以分解为以下步骤:
- 工具发现与上下文准备:用户向Host输入指令(如“查询并记录天气”)。Host内部的MCP Client会向所有已配置的MCP Server发起请求,获取其提供的工具列表及描述。
- 意图识别与任务规划:Client将用户指令和获取到的工具描述列表一同发送给LLM。LLM基于此上下文进行意图识别与任务分解。例如,LLM可能输出:需要先调用 get_current_weather 工具查询天气,再调用 save_note 工具保存结果[^背景]。
- 工具调用与执行:Client根据LLM的决策(Tool Call),携带相应参数调用目标MCP Server上的具体工具。Server执行实际操作(如访问外部API或读写数据库)并返回结果。
- 结果处理与迭代:Client将工具执行的结果返回给LLM。LLM根据结果判断任务是否完成。若未完成(例如需要进一步处理数据),则重复步骤2-4,形成“思考-行动-观察”的循环;若已完成,则生成最终的自然语言响应返回给用户。
- 结果呈现:Host将LLM生成的最终响应展示给用户,完成一次交互。
四、 通信协议与部署模式
MCP协议采用JSON-RPC来编码消息,并支持两种主要的传输机制,以适应不同的部署场景:
- 标准输入/输出(stdio):适用于Server与Client在同一台机器上运行的场景。Server作为Host应用的一个子进程启动,两者通过标准输入输出流进行通信。这种方式简单、高效,常用于访问本地资源(如文件系统、数据库)的Server。
- 基于SSE的HTTP(HTTP over SSE):适用于远程或分布式部署场景。Server作为一个独立的HTTP服务运行,Client通过URL与之连接,并使用Server-Sent Events(SSE)进行实时、双向的数据传输。这使得云服务能够以MCP Server的形式对外提供能力。
五、 技术生态与行业影响
自2024年11月由Anthropic提出并开源后,MCP协议在2025年迎来了爆发式增长,迅速成为AI领域交互的事实标准。其生态繁荣体现在几个方面:
- 应用广泛支持:从最初的Claude Desktop,到Cursor、VSCode、Cline等开发者工具,大量AI应用宣布支持MCP协议,完成了生态的“冷启动”。
- 大厂全面拥抱:OpenAI、谷歌以及国内的百度、阿里云、腾讯云、字节跳动等主流平台相继宣布全面兼容或提供MCP服务。例如,百度将其形容为“2010年开发移动APP”一样的机遇,并推出了电商交易、搜索等MCP服务。
- Server市场繁荣:出现了如Smithery、mcp.so等MCP Server市场,集成了从数据查询、云平台操作到自动化等成千上万个工具,覆盖了广泛的应用领域。三维天地的SunwayLink平台更是将MCP应用于实验室智能检测,实现了与LIMS系统、检测设备的数据贯通与流程自动化。
六、 局限与挑战
尽管前景广阔,但作为一项新兴技术,MCP也面临一些挑战:
- 应用范围:目前大量MCP Server以本地方式运行,与个人桌面助手场景结合紧密,在企业级云端复杂业务流的集成深度仍有拓展空间。
- 协议本质:有观点认为MCP本质上是Function Calling与代理模式的组合,主要对Agent调用外部工具做了规范,其协议深度和范围能否支撑更复杂的智能体协作尚有疑问。
- 安全风险:MCP Server被授权后可能获得Host系统的访问权限,不可信的Server可能成为安全漏洞的跳板,因此Server的安全审计与权限最小化原则至关重要。
总结而言,MCP协议通过标准化LLM与外部世界的接口,正在重塑AI应用开发范式。它让开发者能够像搭积木一样,快速组合来自不同供应商的能力,构建出功能强大的智能体。对于您书中探讨的低代码平台而言,集成或兼容MCP意味着能够直接接入一个庞大且不断增长的工具生态,从而极大扩展平台自身A****gent的能力边界,是构建下一代企业级AI应用不可或缺的一环。
2.2 A2A协议解析与智能体交互原理
A2A(Agent-to-Agent)协议是一种旨在实现不同平台构建的AI智能体之间进行通信、能力发现、任务协商与协作的开放标准协议。其核心目标是解决企业部署大规模、跨平台多智能体系统时的互操作性问题,通过标准化方法管理分散在不同环境和平台中的智能体,从而充分发挥协作型AI的潜力。
一、 A2A协议的核心设计原则与价值主张
A2A协议并非凭空构建,而是基于对多智能体系统实际部署挑战的深刻洞察。其设计遵循五大核心原则,这些原则共同定义了协议的价值与边界:
- 发挥智能体的能力:协议专注于让智能体以自然、非结构化的模式进行协作。即使智能体之间没有共享内存、工具或上下文信息,A2A也致力于实现真正的“多智能体”场景,避免将某个智能体局限为一种简单的“工具”,而是将其视为具有自主协作能力的实体。
- 基于现有标准构建:为了降低集成门槛,A2A协议建立在HTTP、SSE(Server-Sent Events)、JSON-RPC等广泛使用的现有网络和通信标准之上。这使得它更容易与企业日常使用的信息技术堆栈集成,减少了采用新协议的技术负担。
- 默认安全:协议在设计之初就内置了企业级的安全考量,支持身份验证和授权机制。其安全性在推出时即符合OpenAPI级别的认证标准,以满足企业应用对安全性和合规性的严格要求。
- 支持长时间运行的任务:A2A协议能够应对从快速响应到可能持续数小时甚至数天的深入研究任务等各种场景。在整个任务执行过程中,协议机制能够为用户提供实时反馈、状态更新和通知,确保了长时间异步协作的可观测性和可控性。
- 模态无关:协议设计支持包括文本、音频、视频在内的各种数据模态,使其能够适应丰富的交互和应用场景,不局限于单一的文本通信。
A2A协议的价值在于为企业提供了一种标准化的互操作方法,以管理分布在各种平台和云环境中的智能体。当前的企业AI实施往往创建孤立的系统,无法共享信息或协调任务,这限制了自动化潜力的发挥。A2A作为通信层运行,允许AI智能体发现彼此的能力、安全交换信息并协调复杂任务,无论其底层技术堆栈如何,从而解决了这一根本挑战。
二、 A2A协议的工作原理与关键能力
A2A协议定义了“客户端”智能体与“远程”智能体之间的交互模型。在这种模型中,客户端智能体负责制定和传达任务,而远程智能体则负责执行任务、提供信息或采取行动。这种交互依赖于几个关键的技术能力:
- 能力发现 (Capability Discovery):这是多智能体协作的起点。每个智能体可以使用JSON格式的“智能体卡片”(Agent Card)来展示自身的能力、接口和元数据。这类似于一张数字名片,使得客户端智能体能够在一个动态环境中识别出最适合执行某项特定任务的远程智能体。例如,在招聘场景中,一个负责寻找候选人的智能体可以通过发现机制,找到专门进行背景调查或安排面试的智能体。
- 任务管理 (Task Management):智能体之间的通信以任务完成为导向。协议定义了一个具有生命周期的“任务”对象。任务可以立即完成,也可以长时间运行。对于长时间运行的任务,智能体之间可以通过A2A协议持续通信,同步任务的最新状态、进展和结果。任务的最终输出被称为“工件”(Artifact)。这种机制支持了从快速查询到需要人工批准或跨越多个工作日的复杂企业工作流。
- 协作 (Collaboration):智能体之间可以相互发送消息,用以交流上下文信息、回复内容、任务工件或用户指令。这构成了智能体协商、分工和共同解决问题的沟通基础。例如,在供应链优化场景中,代表供应商、生产商和物流商的智能体可以通过消息传递进行实时协商,以应对突发需求或资源瓶颈。
- 用户体验协商 (User Experience Negotiation):协议中的每条消息都可以包含多个“部分”(Parts),每个部分是一个完整的内容片段,如一段生成的文本、一张图像或一个表单。每个部分都有指定的内容类型(如 text/plain , image/png , application/json ),允许客户端和远程智能体协商所需的正确格式。这甚至包括对用户界面功能的协商,例如嵌入iframe、播放视频或呈现网页表单,从而确保协作结果能以最佳方式呈现给最终用户。
三、 A2A与MCP的互补关系及生态发展
理解A2A协议,必须将其置于更广阔的AI智能体协议生态中,尤其是与MCP(Model Context Protocol) 的关系。业界普遍认为,两者是互补而非竞争的关系。
- MCP的角色:MCP主要解决的是单个智能体(或大模型)如何安全、标准化地接入外部工具和资源的问题。它定义了模型(Client)与数据源、API(Server)之间的通用接口,好比为AI世界提供了“万能插座”。MCP为智能体提供了实用的工具和上下文背景信息。
- A2A的角色:A2A则解决多个智能体之间如何通信、发现和协作的问题。它关注的是智能体层面的互操作性,是智能体之间的“社交语言”和“协作协议”。
用一个形象的比喻:MCP是让一个“工人”(智能体)知道如何使用各种“工具”(数据库、API);而A2A是让多个“专业工人”(不同的智能体)能够组成一个“团队”,相互沟通、分配工作、协同完成一个复杂的“项目”(任务)。因此,A2A协议旨在解决客户在部署大规模多智能体系统时所发现的问题,是对MCP生态的重要补充。
这种互补性得到了行业的广泛认可和推动。谷歌DeepMind的联合创始人兼CEO Demis Hassabis曾表示,MCP是一个出色的协议,并正迅速成为AI智能体时代的开放标准。谷歌也宣布为其Gemini模型和SDK提供对MCP的支持。更重要的是,为了推动标准的广泛采用并解决企业对供应商锁定的担忧,谷歌已将A2A协议捐赠给Linux基金会。这一举措吸引了亚马逊云科技(AWS)、思科、微软、Salesforce、SAP和ServiceNow等科技巨头作为创始成员共同参与标准化工作。目前,已有超过100家科技公司支持A2A协议,生态迅速扩展。
各厂商也积极将A2A集成到自身产品中:
- 亚马逊云科技(AWS):已创建工具将其Bedrock代理通过A2A端点公开,使基于AWS的智能体能被其他平台的智能体访问。
- 微软:已将A2A支持集成到Azure AI Foundry和Copilot Studio中,允许使用微软AI工具链的企业参与多供应商代理工作流。
- 思科:将其原有的“AGNTCY”倡议(旨在构建“代理互联网”基础设施)与A2A整合,将A2A支持直接集成到其目录、身份、消息传递和可观察性框架等核心组件中,使AGNTCY从潜在竞争标准转变为增强A2A能力的互补基础设施。
四、 智能体交互原理与多智能体系统
A2A协议所规范的智能体交互,其理论基础是多智能体系统(Multi-Agent System, MAS)。多智能体系统由多个具有自治性的智能体(软件程序或实体)组成,每个智能体都具有自己的感知、决策和行动能力,并且可以与其他智能体进行通信、信息共享和协作,以实现共同或各自的目标。
智能体(AI Agent)本身被定义为能够感知环境、利用工具采取行动以实现特定目标的代理。它以大型语言模型(LLM)为智能底座,具备自主感知、理解、规划、决策、记忆、行动和使用工具的能力。其核心架构通常包含感知组件、记忆组件、动作组件和作为“大脑”的大语言模型。
在A2A协议框架下,多智能体系统的交互原理可以具体化为以下模式:
- 基于协商的任务分解与分配:当一个复杂任务(如“完成一次招聘”)下达给某个智能体(如招聘经理的智能体)时,该智能体可以作为“客户端智能体”,利用A2A的能力发现机制,查询环境中可用的其他专业智能体(如简历筛选智能体、面试安排智能体、背景调查智能体)。通过交互协商,将总任务分解为“寻找候选人”、“安排面试”、“进行背调”等子任务,并分配给最合适的“远程智能体”执行。
- 异步通信与状态同步:对于长时间运行的任务,智能体之间并非一次性交互。它们通过A2A协议持续发送消息,同步子任务的进度、传递中间结果(工件)、请求额外资源或处理异常。例如,背景调查智能体在完成调查后,会将报告(一个“工件”)发送给招聘经理智能体,后者再汇总所有结果。
- 冲突解决与协同决策:在多智能体协作中,可能出现目标或资源冲突。A2A协议提供的通信通道使得智能体能够交换信息、陈述理由,并基于预设的规则(如优先级、资源可用性、效用函数)或通过更高级的协商算法(如合同网协议、拍卖机制)来达成一致,形成协同决策。
五、 总结与展望
A2A协议代表了AI智能体技术从“单机智能”迈向“群体智能”和“社会智能”的关键一步。通过提供一套开放、安全、基于现有标准的通信规范,它旨在打破不同平台、不同供应商构建的智能体之间的壁垒,实现真正的跨系统、跨组织的智能体协作。
对于企业和开发者而言,A2A协议与MCP等协议共同构成了下一代AI应用的基础设施层。企业可以像组建专业团队一样,组建由不同专业智能体构成的“数字团队”,处理复杂的端到端工作流,如智能招聘、跨部门供应链优化、客户服务全链路自动化等。Linux基金会的治理模式确保了协议的供应商中立性和持续发展,为企业投资基于A2A的多智能体架构提供了信心。
然而,成功的实施不仅依赖于技术协议。企业需要在部署前建立智能体治理框架、实施监控能力并制定代理间数据共享策略。A2A提供了技术基础,但组织在数据治理、身份管理和合规方面的准备程度将最终决定其价值能否充分发挥。
展望未来,随着A2A、MCP等协议的成熟与普及,智能体将成为AI操作系统中的最小工作单元,它们之间的无缝协作将催生出更加动态、自适应和强大的自动化系统,深刻改变软件交互方式和社会生产效率。
第三章:Agent&多Agent架构设计与实战
3.1 Agent核心认知与Function Calling智能调度
Agent的核心认知架构与Function Calling的智能调度机制,共同构成了现代AI智能体(AI Agent)从“思考”到“行动”的完整闭环。其本质是让大语言模型(LLM)从一个被动的“信息生成器”,转变为一个具备自主感知、规划、决策和执行能力的“任务执行者”。
一、 Agent的核心认知架构:从“大脑”到“完整个体”
一个功能完备的Agent,其认知架构远不止于一个大语言模型。它通过整合多个核心模块,形成了一个能够与环境持续交互、动态学习的智能系统。
1. 感知(Perception):智能体的“五官”
感知模块是Agent与外部世界交互的起点。它主动从物理或虚拟环境中收集多模态信息,包括文本、视觉、听觉、传感器数据等。更重要的是,现代Agent的感知是任务导向的,它并非被动接收所有信息,而是带着明确的目的去观察和理解环境,识别与当前目标相关的关键信息。
2. 认知与规划(Cognition & Planning):智能体的“大脑”
这是Agent的决策中枢,通常由大语言模型(LLM)或视觉语言模型(VLM)驱动。它负责解释感知信息,进行逻辑推理、多步思考,并制定实现目标的策略和行动计划。例如,当接收到“帮我热一下午餐”的指令时,认知模块能将其分解为“打开冰箱 -> 找到午餐盒 -> 放到微波炉 -> 设置时间 -> 启动”等一系列可执行的子任务。规划(Planning) 正是这一模块的核心输出,它确保复杂任务被有条理地拆解。
3. 记忆(Memory):智能体的“经验库”
与传统模型的短暂上下文窗口不同,Agent拥有一个更持久、结构化的记忆系统。它存储着知识、逻辑、过去的推理路径和交互经验。这使Agent能够形成长期记忆,在面对新任务时不必从零开始,而是可以借鉴历史经验,实现“举一反三”。记忆通常分为短期记忆(管理当前对话上下文)和长期记忆(利用外部向量数据库进行知识检索与增强)。
4. 行动(Action):智能体的“手脚”
行动模块负责将认知模块的决策转化为具体的、可执行的操作。这些操作可以是生成自然语言回复、调用外部API、执行代码,或是向物理世界发出控制指令(如让机器人移动或抓取)。行动是Agent改变环境状态、完成任务目标的最终手段。
5. 学习(Learning):智能体的“进化能力”
Agent并非静态系统,其核心优势在于能通过与环境的交互持续学习和自我优化。这包括从预训练知识出发的零样本/少样本学习,以及通过强化学习(RL)、模仿学习(IL)等方式,从成功或失败的经验反馈中调整策略。环境的反馈会回流至学习和记忆模块,形成一个动态迭代的认知闭环,让Agent在每一次交互中都变得更智能、更高效。
二、 Function Calling:赋予Agent“行动之手”的关键机制
Function Calling(函数调用)是大型语言模型的一项关键技术,它允许模型理解用户请求中的潜在意图,并自动生成结构化参数来调用预定义的外部函数或工具。这从根本上解决了大模型无法与外部世界实时联动的局限,是Agent实现自主行动的核心桥梁。
1. 工作原理:三步闭环流程
Function Calling的工作流程是一个典型的“感知-决策-执行”循环:
- 定义函数(开发者预设):开发者向LLM描述工具的用途、名称和输入参数格式(通常使用JSON Schema)。例如,定义一个 get_current_weather 函数,并说明需要 city 和 unit 参数。
- 模型决策与生成参数:当用户提问“北京今天需要带伞吗?”时,LLM会识别其意图是查询天气,并决定调用 get_current_weather 函数,同时自动生成符合格式的参数: {“city”: “北京”, “unit”: “celsius”} 。
- 执行函数并返回结果:应用程序接收到结构化参数后,调用真实的天气API获取数据(如 {“temp”: 25, “rain_prob”: 30%} ),再将结果返回给LLM。LLM结合工具返回的真实数据,生成最终的自然语言回复:“北京今天25°C,降水概率30%,建议带伞。”
2. 核心价值:LLM的“手和眼睛”
Function Calling极大地扩展了LLM的能力边界:
- 突破知识时效性:LLM的训练数据有截止日期,而通过Function Calling连接实时数据源(如搜索引擎、数据库),Agent能获取最新信息,克服“知识幻觉”。
- 执行具体操作:LLM本身无法执行计算、发送邮件或控制设备。Function Calling使其能调用计算器、邮件客户端或物联网API,从而完成实际任务。
- 增强结果可信度:通过检索增强生成(RAG)技术,Agent可以从权威、实时的数据存储(Data Stores)中获取信息并引用来源,使回答更准确、可验证。
三、 智能调度:从单次调用到自主工作流
单一的Function Calling只是开始。一个成熟的Agent需要具备智能调度能力,即能自主规划何时、以何种顺序、调用哪些工具,以完成复杂任务。这依赖于更高级的推理框架。
1. 核心推理框架
编排层(Orchestration Layer)作为Agent的“中枢神经”,利用特定的推理框架来指导模型的决策和行动循环。主流的框架包括:
- 思维链(Chain-of-Thought, CoT):将复杂问题分解为一系列简单的、线性的逻辑推理步骤,适用于需要顺序思考的任务。
- 推理与行动(Reasoning and Acting, ReAct):将推理(Thought) 和行动(Action) 结合在一个循环中。Agent先“思考”下一步该做什么,然后决定采取何种“行动”,并从环境中获取“观察”(Observation)结果,再基于观察进行下一轮思考,如此循环直至任务完成。这种“思考->行动->观察”的闭环,是解决复杂、动态任务的关键。
- 思维树(Tree-of-Thoughts, ToT):在CoT的基础上,允许模型探索多种可能的思考路径,形成一个树状的决策空间,非常适合需要战略前瞻或多方案对比的任务。
2. 完整的智能调度流程
一个具备智能调度能力的Agent,其工作流程是上述认知架构与推理框架的结合:
- 接收指令:用户下达一个复杂任务(如“为我规划一个周末旅行行程”)。
- 感知与理解:Agent的认知模块(LLM)理解任务目标。
- 规划与分解:利用CoT或ReAct框架,将任务分解为子步骤(如:查询天气 -> 搜索景点 -> 查找航班 -> 预订酒店)。
- 工具选择与调度:对于每个子步骤,认知模块根据记忆中的工具库描述,决策调用哪个工具(如调用搜索插件查天气、调用旅行API查航班)。
- 执行与观察:行动模块通过Function Calling机制,调用相应工具并获取结果。
- 学习与迭代:将工具执行的结果(观察)反馈给认知模块。模型根据结果判断任务进度,决定是继续下一个步骤,还是调整当前计划。整个过程的经验和结果会被存入记忆模块。
- 汇总与输出:所有子任务完成后,认知模块汇总信息,生成最终答案交付给用户。
四、 总结:从架构到实践
综上所述,Agent的核心认知架构(感知、认知、记忆、行动、学习)为其提供了完整的智能闭环,而Function Calling及之上的智能调度机制(如ReAct)则为这个闭环注入了“行动力”和“自主性”。它们共同使AI从被动应答的聊天机器人,进化成为能主动规划、使用工具、从环境中学习并完成复杂目标的智能体。
当前,无论是李飞飞等学者提出的感知-认知-行动-学习-记忆的完整架构,还是谷歌等企业在白皮书中强调的模型-工具-编排三层架构,亦或是OpenAI Lilian Weng总结的规划-记忆-工具-行动四要素,其核心思想都是相通的。随着MCP(模型上下文协议)等标准化接口的出现,工具的连接和调用将变得更加便捷和统一[^背景],Agent的构建和智能化调度也将进入一个更高效、更开放的新阶段。
3.2 可观测系统构建与高级Agent设计
在云原生和微服务架构成为主流的今天,系统的复杂性呈指数级增长,传统的监控手段已难以满足对复杂分布式系统内部状态的理解需求。与此同时,AI Agent正从简单的对话机器人演变为能够自主规划、调用工具、执行复杂任务的智能体。将可观测性(Observability)理念与高级Agent设计相结合,构建一个具备自我洞察、透明可控且能持续优化的智能体系统,已成为下一代AI应用开发的关键课题。
一、 可观测系统:为Agent赋予“自我审视”的能力
可观测性源于控制论,指通过观察系统外部输出来推断其内部状态的能力。对于AI Agent而言,其“内部状态”包括决策逻辑、工具调用链、记忆内容、资源消耗等。一个完善的可观测系统是Agent实现稳定、可靠、可信赖运行的基石。
1. 可观测系统的核心架构与数据支柱
一个面向Agent的可观测系统,其架构应围绕三大核心数据支柱构建:指标(Metrics)、追踪(Tracing)和日志(Logging)。这三大支柱共同构成了理解Agent行为的“上帝视角”。
- 日志收集层:Agent的“黑匣子”与“思维日记” 日志是Agent执行过程的详细记录,是其“思维过程”的具象化。它不应只是简单的成功/失败记录,而应包含:
- 决策日志:记录Agent在每一步的“思考”(Reasoning)过程,包括对用户意图的理解、任务分解的逻辑、选择特定工具的原因等。这对于事后复盘和调试至关重要。
- 工具调用日志:详细记录每次Function Calling的输入参数、调用的API端点、返回的原始结果、耗时及状态码。这有助于评估外部工具的可靠性和Agent调用逻辑的正确性。
- 上下文与记忆日志:记录Agent在会话中维护的短期记忆(对话历史)和从长期记忆(如向量数据库)中检索到的关键信息片段。这有助于分析Agent决策的信息依据。
- 错误与异常日志:不仅记录程序错误,更应记录逻辑异常,例如工具返回了不符合预期的数据格式、用户指令存在歧义导致规划失败等。这些是优化Agent鲁棒性的关键输入。
在云原生环境下,传统的侵入式日志采集(如SDK插桩)可能给应用性能和安全性带来挑战。因此,可以考虑采用无侵入式的数据采集方法,例如利用eBPF(extended Berkeley Packet Filter)技术,在内核层面零侵扰地获取系统调用、网络事件等可观测数据,实现对Agent宿主环境行为的深度洞察。
- 指标监控层:Agent的“健康仪表盘” 指标是Agent运行状态的量化体现,用于衡量其性能、效率和资源消耗。关键性能指标(KPIs)应包括:
- 性能指标:平均响应时间(ART)、每秒查询率(QPS)、任务成功率/失败率、各工具调用的平均延迟等。
- 资源指标:Agent进程的CPU、内存使用率,与大模型API交互的Token消耗量及成本,向量数据库查询的吞吐量与延迟。
- 业务指标:针对特定任务定义的指标,如代码生成Agent的代码通过率、客服Agent的问题解决率、报告生成Agent的用户满意度评分(可通过后续反馈收集)。
- 质量指标:幻觉率(生成不实信息的比例)、工具调用准确率(调用正确工具的比例)、任务完成度(复杂任务被完整分解和执行的比例)。
这些指标应通过统一的可观测数据标签体系进行聚合与下钻分析。例如,为每个指标打上 agent_id 、 task_type 、 llm_model 、 deployment_env 等标签,使得运维人员可以快速筛选和定位具体主机、微服务或Pod实例上的问题。
- 追踪系统:贯穿Agent协作的“全链路地图” 在由多个Agent协同工作的多智能体系统(MAS)中,一个用户请求可能在不同Agent间流转,形成复杂的调用链。分布式追踪系统能够可视化展示请求的完整生命周期。
- 端到端追踪:为每个用户会话生成唯一的 trace_id ,并在该会话触发的所有跨Agent、跨工具的调用中传递此ID。这可以清晰展示一个复杂任务(如“规划一次旅行”)如何从主控Agent(Commander)开始,被分解并分配给机票查询Agent、酒店预订Agent、天气查询Agent等子Agent执行,最后结果如何被汇总。
- 跨度(Span)记录:追踪系统中的每个“跨度”代表一个逻辑操作单元,如一次LLM推理、一次工具调用、一次数据库查询。每个跨度记录其开始时间、结束时间、所属的 trace_id 、父跨度ID以及自定义标签(如工具名称、输入参数摘要)。
- 性能瓶颈定位:通过分析追踪图谱,可以直观发现整个工作流中的性能瓶颈。例如,是某个外部API响应缓慢拖慢了整体流程,还是某个Agent的内部推理耗时过长。
招商银行在其云环境复杂网络全栈可观测平台建设中,就通过零插码采集技术,基于 traceId 、 threadId 、 flowId 等标签纵向打通应用、PaaS和IaaS层,横向串联各类节点,实现了覆盖各类网元的全链路追踪能力,这对于定位跨Agent的精细化故障定界具有重要借鉴意义。
- 告警与智能分析层:从“被动响应”到“主动洞察” 基于收集到的指标、日志和追踪数据,可观测系统应能实现智能化的告警与根因分析。
- 实时性告警:基于预设的阈值(如错误率超过5%、平均响应时间超过2秒)或异常检测算法,实时触发告警。告警信息应关联丰富的上下文,如出错的 trace_id 、相关的日志片段、当前资源状态等,以加速排障。
- 根因分析(RCA):当系统发生故障或性能下降时,可观测平台应能辅助快速定位根因。例如,基调听云智能可观测性平台通过“多维探索”能力,允许用户对高基数、高维度的可观测性数据进行深入挖掘和无边界探索,从简单的故障表象开始,进行反复的迭代探索,快速发现和定位可能的根因。其“疑似问题”功能能基于异常检测,自动收集横向拓扑上的所有实时服务,并分析纵向拓扑的不健康状态,对触发告警的所有问题进行采集和分析,进而自动找到问题的根因。
- 闭环管理与知识库:将每次故障的分析过程和解决方案总结后存入历史资料库。平台可以基于此库提供智能问答功能,当类似问题再次出现时,能快速给出诊断建议,大幅降低问题定位的门槛。
2. 构建统一可观测性平台的技术挑战与解决方案
构建面向Agent的统一可观测平台面临诸多挑战,如数据孤岛、采集侵入性、关联分析困难等。现代解决方案通常围绕以下理念展开:
- 多源数据集成与统一存储:需要将来自不同Agent、不同工具、不同基础设施的指标、日志、追踪数据集成到统一的数据平台中,消除数据壁垒。例如,通过对接Prometheus、OpenTelemetry等标准协议,将数据统一存储于时序数据库或专门的可观测性数据湖仓中,为关联分析提供基础。
- 无侵入式与高性能采集:为了不影响Agent性能,采集应尽可能无侵入。eBPF技术在此展现出巨大优势,它允许在内核安全运行沙箱程序,自动获取内核事件、性能指标和应用追踪数据,实现零侵扰采集。同时,如招商银行平台所做,将部分处理逻辑(如协议解析、链路关联打标)下沉至内核态执行,能避免无效数据的跨态复制开销,提升性能。
- 构建统一数据标签体系:通过对接Kubernetes、云资源的标准标签,并对采集到的可观测数据进行标签抽取和标准化,构建统一的数据标签体系。这使得可以使用如 service_name 、 pod_name 、 agent_type 等标签作为唯一标识,对数据进行快速的筛选、检索和下钻定位。
二、 高级Agent设计模式:超越简单的任务执行者
在可观测系统的支撑下,我们可以设计出更强大、更智能的高级Agent。这些设计模式旨在解决复杂、动态、长周期的任务挑战。
- 分层决策Agent:战略、战术与执行的分离 借鉴人类组织的管理架构,分层决策Agent将智能体的决策过程进行层级划分。
- 战略层(高层):由最强大的模型(如Claude 3.5 Sonnet、GPT-4)担任,负责宏观目标理解、任务总体规划、资源分配和风险评估。它输出的是高层次的“战略指令”。
- 战术层(中层):接收战略指令,并将其分解为具体的、可执行的子任务序列。它需要理解不同子任务间的依赖关系,并可能进行动态调整。此层可选用能力均衡的模型。
- 执行层(底层):由多个专精于特定领域的“专家Agent”构成,如代码生成Agent、数据分析Agent、文档撰写Agent等。它们接收明确的子任务,调用相应工具高效执行,并将结果反馈给上层。 这种模式的好处是职责清晰,高层专注于复杂推理,底层专注于高效执行,并通过可观测系统监控各层间的指令传递与结果反馈,确保全局目标的一致性。
- 多专家集成与动态路由Agent:让合适的专家处理合适的问题 单一模型难以在所有领域都表现卓越。多专家集成Agent内部维护一个“专家池”,每个专家都是针对特定领域(如法律、金融、编程、创意写作)进行微调或拥有特定工具集的子Agent。 其核心是一个路由(Router) 机制。当接收到用户请求时,路由Agent(可能是一个轻量级模型)首先对输入进行分类,判断其属于哪个领域,然后将其引导至最合适的专家Agent进行处理。例如,将简单的常见问题路由到较小、更经济的模型(如Claude 3.5 Haiku),将困难、不常见的问题路由到更强大、更昂贵的模型(如Claude 3.5 Sonnet),从而实现成本与效果的优化平衡。可观测系统需要详细记录每次路由的决策依据和最终效果,用于持续优化路由策略。
- 基于ReAct框架的自适应学习Agent:在行动中反思与进化 ReAct(Reasoning and Acting)框架是构建具备规划与工具使用能力Agent的经典范式。高级Agent可以在此基础上引入自我评估与反思(Self-Evaluation & Reflection) 机制。
- 规划:Agent根据目标制定初步计划。
- 行动:执行计划中的步骤,调用工具。
- 观察:获取工具执行结果和环境反馈。
- 反思(关键新增步骤):Agent不仅将观察结果用于下一步规划,还会主动评估当前计划的可行性和已执行动作的有效性。如果结果不理想或遇到意外,它能回溯思考,调整策略甚至重新规划。
- 学习与记忆:将本次任务的成功经验或失败教训,以结构化的方式(如成功的工作流模板、应避免的错误模式)存入长期记忆(向量数据库)。当下次遇到类似任务时,Agent可以从记忆中检索相关经验,加速决策或避免重蹈覆辙。 这种具备“元认知”能力的Agent,能够从历史交互中持续学习,其行为会随着时间推移而不断进化,越来越擅长处理复杂场景。
- 安全与伦理约束Agent:为智能体戴上“紧箍咒” 随着Agent自主性的增强,确保其行为安全、合规、符合伦理变得至关重要。安全约束应作为核心模块内置在Agent架构中。
- 输入过滤与净化:在用户指令进入Agent认知模块前,进行恶意指令、敏感信息、偏见诱导性内容的检测和过滤。
- 过程监控与干预:在Agent的规划与执行过程中,实时监控其决策逻辑和即将执行的动作。可设立一个独立的“安全监督Agent”,其拥有否决权。例如,当主Agent计划执行一个高风险的数据删除操作时,监督Agent可以介入,要求其进行二次确认或直接阻止。
- 输出审查与修正:对Agent生成的最终输出进行内容安全审查,防止生成有害、虚假或不合规的信息。这可以通过并行化的工作流实现,例如,一个模型负责生成内容,另一个或多个模型并行评估其安全性、事实准确性等,通过差异化的投票阈值来平衡误报与漏报。
- 伦理对齐训练:在Agent的训练和微调阶段,融入人类价值观和伦理准则,使其目标函数与人类社会的普遍利益对齐。
三、 总结:可观测性与高级Agent的协同进化
可观测系统与高级Agent设计是相辅相成的。一个强大的可观测系统,为高级Agent的复杂行为提供了透明的监控、深度的分析和持续优化的依据;而高级Agent的设计,又对可观测系统提出了更细粒度、更关联、更智能的需求。
未来,随着A2A(Agent-to-Agent)等协议的发展,智能体间的跨平台协作将成为常态。可观测性需要从单体Agent扩展到多智能体网络,能够追踪跨Agent的复杂工作流,理解群体智能的涌现行为。同时,Agent的自我观测(Introspection)能力也将增强,它们不仅能报告执行结果,还能主动解释自己的决策过程、信心程度以及面临的 uncertainty,使人机协作更加透明和可信。
将可观测性工程与Agent架构设计深度融合,是构建下一代可靠、高效、智能且负责任的AI系统的必由之路。这要求开发者不仅精通AI算法和工程,还需深刻理解分布式系统、可观测性理念以及人机交互伦理,从而打造出真正能够赋能千行百业的智能体伙伴。
3.3 多Agent系统架构设计与实战
多智能体系统(Multi-Agent System, MAS)并非一个全新的概念,其思想源于分布式人工智能,旨在通过多个自主、智能的实体(Agent)之间的交互与协作,来解决大规模、复杂、实时且信息不确定的现实问题。随着大模型技术的突破,尤其是Agent概念的复兴与工程化落地,MAS正从学术研究走向产业应用的核心,成为构建下一代复杂AI应用的关键架构范式。
与传统的单体智能体或简单的“工具调用”模式相比,多Agent系统的核心价值在于其涌现性和社会性。多个具备不同专长、视角和资源的Agent通过有效的组织与协作,能够解决任何单一Agent都无法独立完成的复杂任务,其整体能力大于部分之和。本节将深入剖析多Agent系统的核心架构设计原则,并结合前沿的通信协议与行业实战案例,勾勒出其从理论到实践的完整图景。
一、 核心理念:从“工具调用”到“社会协作”的范式跃迁
在深入架构之前,必须理解多Agent系统与单一Agent调用工具的本质区别。这并非简单的数量叠加,而是范式的根本转变。
- 自主性与对等性:在经典的客户/服务器(C/S)模型中,角色是固定的、非对等的,服务器被动响应客户的请求。而在MAS中,每个Agent都是具有自主性的行为实体,它们根据自身内部状态和感知到的环境(包括其他Agent)信息,自主决定和控制自身行为。Agent之间是对等的关系,可以进行主动的、双向的交互与协商,而不仅仅是“请求-响应”。例如,在分布式交互仿真(DIS)中,战场上的每个行为实体(如坦克、飞机)都不能简单地被归类为“客户”或“服务器”,它们需要彼此感知并实时互动。
- 协同与群体智能:MAS的目标是实现协同工作,减少因部门或环节割裂对整体进度和质量的影响。这要求系统设计支持Agent之间直接的“群体感知”和协作机制。例如,在并行工程(CE)中,理想状态是设计、制造、测试等各部门的Agent能最大限度地协同,优化产品全流程。这种协同最终可能催生出集体智慧,放大人类的认知与联结智能。
- 动态组织与任务分解:面对复杂任务,一个核心的“规划型”或“顾问”Agent会扮演协调者角色,负责将总任务智能地分解为子任务,并分配给具有相应专长的Agent执行。各Agent构建独立的工作流,最终将结果反馈给协调者进行整合输出。这种动态的任务分配与组织能力,是MAS应对复杂性的关键。
二、 核心架构设计要素
一个健壮、高效的多Agent系统,其架构设计必须围绕以下几个核心要素展开:
- 通信与协调机制:这是MAS的“神经系统”。Agent间需要一套高效、可靠的通信协议来交换信息、协商和协作。
- 通信协议:早期研究中有KQML等Agent通信语言。如今,产业界正致力于建立更通用的开放标准。例如,A2A(Agent-to-Agent)协议旨在成为智能体时代的“TCP协议”,它定义了智能体间发现、任务创建、状态同步和结果传递的标准化方式,支持同步和异步的长周期通信,以打破智能体“孤岛”。类似地,国内也有ACP(Agent Communication Protocol) 等协议,通过定义智能体身份标识(AID)、接入点(AP)和通信规范,来构建“智能体互联网”。
- 协调策略:包括合同网协议(Contract Net Protocol)、基于市场的拍卖机制、联盟形成等。协调的目标是解决资源冲突、目标冲突,并优化整体系统效能。例如,在资源受限时,多个Agent需要通过协商或竞价来决定谁获得资源。
- 组织与任务分配:如何组织一群Agent,以及如何将任务分配给最合适的Agent,直接决定系统效率。
- 组织结构:可以是集中式(一个主Agent协调所有从Agent)、分布式(完全对等)或混合式。混合式常采用分层递阶结构,如足球机器人系统中的“决策层-协调层-执行层”。联想提出的“超级智能体”架构中,“顾问智能体”负责任务分解与分配,就体现了集中协调与分布式执行的结合。
- 任务分配算法:需考虑Agent的能力模型、当前负载、历史性能、通信成本等多维度因素。例如,申威睿思的ElectroSage平台将Agent分为业务Agent和通用Agent,业务Agent深入特定场景,通用Agent提供跨场景共性能力,形成了一种基于角色和能力的分配机制。
- 知识共享与群体学习:单个Agent的知识和经验是有限的。MAS应设计机制,使Agent能够共享知识、学习彼此的成功策略或避免重复错误。
- 共享记忆或知识库:可以建立一个中央或分布式的知识库,Agent将其经验、解决方案以结构化形式存入,供其他Agent查询复用。
- 经验迁移与模仿学习:表现优秀的Agent可以将其策略或模型参数共享给其他Agent,加速整个系统的学习过程。
- 对抗与博弈学习:在竞争性或混合协作/竞争的环境(如博弈)中,Agent通过相互对抗来提升策略水平,DeepStack在德州扑克中的成功即是一例。
- 系统鲁棒性与容错:在由多个可能不可靠组件构成的分布式系统中,容错至关重要。
- 故障检测与恢复:系统需要能检测到某个Agent失效或通信中断,并启动恢复流程,如将任务重新分配给其他Agent。
- 共识机制:对于需要达成一致决策的场景,需要设计共识算法(如投票)来应对个别Agent的异常输出。
- 通信受限下的协同控制:在实际网络中,带宽限制、数据丢包、通信时延是常见问题。研究提出了事件触发/自触发控制、基于量化通信的协同控制、基于预测补偿的控制等方法,来保证在通信受限下系统仍能稳定协同。
三、 技术协议栈:构建智能体社会的“基础设施”
当前,构建多Agent系统的技术生态正在快速成型,其协议栈可大致分为三层:
- 智能体协作层(A2A/ACP):如上所述,该层协议解决智能体“之间”如何对话、组队、分工的问题。A2A协议通过“智能体标签”(Agent Card)实现能力发现,通过“任务”(Task)对象管理生命周期,是智能体社会化的基础。
- 智能体工具层(MCP):该层协议解决单个智能体“内部”如何调用外部工具和数据的问题。MCP(模型上下文协议) 标准化了LLM与数据库、API等工具的连接方式,是智能体的“手”和“感官”[^背景]。A2A与MCP是互补关系:一个智能体通过A2A协议与其他智能体协作,而每个智能体内部通过MCP协议调用各种工具来完成任务。
- 模型与计算层:这是智能体的“大脑”和“体能”基础。包括各种大语言模型、多模态模型、以及支撑其运行的算力平台。联想提出的“模型工厂”和“AI算力平台”,旨在高效部署和调度不同规模的模型,为上层智能体提供灵活强大的认知能力支撑。
四、 行业实战案例解析
- 医疗诊断——MMedAgent:这是一个典型的多模态、多专家集成的MAS。它不是试图用一个巨型模型解决所有医疗问题,而是构建了一个调度中心(规划器),其背后集成了针对不同医学成像模式(MRI、CT、X光等)和不同任务(视觉问答、图像分割、报告生成等)的多个专用模型(工具)。当接收到一个医疗请求时,调度中心(基于LLaVA-Med微调)理解用户指令,并自主选择最合适的专用工具来执行任务,最后汇总结果。这种架构在各项任务上超越了通用模型(如GPT-4o),并且能高效集成新工具,体现了MAS“专业分工、智能调度”的优势。
- 企业服务——阿里巴巴瓴羊客服Agent:在电商客服场景中,瓴羊并非部署一个万能客服Agent,而是针对“退换货”、“仅退款”、“外呼服务”、“销售线索清洗”等具体场景,开发了多个专项Agent。这些Agent能够协同工作。例如,当“退换货Agent”检测到物流异常时,可以自动启用“外呼服务Agent”联系消费者,后者还能调用“优惠券发放”等功能。多个Agent的协同,让客服从简单应答变为能处理复杂流程、甚至降低企业资损的“超级员工”。这背后需要一套机制来管理Agent的触发、上下文传递和任务交接。
- 产业智能化——申威睿思ElectroSage电力平台:该平台为电力行业设计了一个多智能体研判分析系统。其架构清晰地划分了业务Agent和通用Agent。业务Agent深度绑定特定业务场景(如电网调度、故障诊断),拥有深厚的领域知识(Know-How);通用Agent则提供文档处理、数据查询等共性能力。当用户提出一个复杂专业问题时,平台中的调度机制会协调相关的业务Agent和通用Agent共同工作,利用其全国产化算力底座,形成软硬一体的解决方案。这体现了MAS在垂直行业中,将领域专家知识与通用能力结合的价值。
- 认知操作系统——联想超级智能体:联想将“超级智能体”定位为个人和企业的“认知操作系统”。其核心是多智能体协作机制:一个“顾问智能体”作为总入口,接收任务后进行分析与分解,然后分配给数学、文学等各学科领域的专属模型智能体去执行,最后整合结果返回给用户。这种架构实现了智能体的专业化分工,同时为用户提供了统一的交互界面,简化了操作。其长远目标是实现智能体间的自主协商与进化,形成一种增强版的集体智慧。
五、 设计挑战与未来展望
尽管前景广阔,多Agent系统的设计与落地仍面临诸多挑战:
- 协调复杂性:随着Agent数量增加,协调开销呈指数级增长,可能引发“协调崩溃”。
- 系统稳定性:某个Agent的决策偏差或错误可能通过交互在网络中传播放大,导致系统整体行为不可预测。
- 评估难度:如何科学评估一个MAS的整体性能、协作效率和涌现能力,尚无统一标准。
- 安全与伦理:多Agent的自主性带来了新的安全风险,如恶意Agent、共谋攻击以及责任归属问题。
未来,多Agent系统将向更自主、更社会、更具身的方向发展。A2A、MCP等开放协议将加速智能体生态的繁荣。我们有望看到由成千上万个不同功能的Agent组成的“数字社会”,在云端、在边缘、在终端设备上协同工作,处理从城市治理到科学研究再到个人生活的极端复杂问题,真正成为人类能力的延伸与放大。
第四章:Multi-Agent之LangGraph深度实战
4.1 LangGraph核心概念与架构设计
LangGraph是一个基于图计算思想的智能体编排框架,它扩展了LangChain的能力,通过将工作流建模为图结构,支持循环、分支和状态传递,从而构建出逻辑更缜密、能处理复杂任务的智能体系统。其核心设计理念是将AI应用的执行流程抽象为节点(函数)和边(状态流转)构成的计算图,并通过统一的状态管理机制协调整个系统的运行。
一、 核心概念:图、状态与节点
LangGraph的架构围绕三个核心概念构建:图(Graph)、状态(State) 和节点(Node)。
- 图(Graph)与工作流编排 LangGraph的核心是将智能体的执行逻辑建模为一个有向图。这个图定义了任务执行的路径和逻辑。图中的节点代表一个具体的处理步骤或决策点,边则定义了状态如何在节点间流转。与传统的线性链式调用不同,图结构允许工作流包含条件分支、循环迭代和并行执行,这使得它能处理需要多步推理、动态规划或与外部环境多轮交互的复杂任务。例如,在一个多智能体研究助手中,工作流可以设计为包含“研究员”、“事实核查员”、“报告撰写员”等多个节点,状态(如研究主题、收集的信息、验证后的事实)沿着边在这些节点间传递,最终生成报告。
- 状态(State)与记忆管理 状态是LangGraph中贯穿整个工作流的核心数据容器,它封装了任务执行过程中的所有上下文信息。LangGraph区分了短期记忆和长期记忆。
- 短期记忆:通常与 StateGraph 中的状态对象绑定,用于在单次工作流执行过程中,在节点间传递和更新信息。它跟踪当前对话或任务的即时上下文。
- 长期记忆:通常通过集成向量数据库等外部存储实现,使智能体能够记住跨越多次交互的历史信息,实现个性化服务和持续学习。 状态通常使用 TypedDict 进行类型化定义,确保数据结构的一致性。例如,一个研究助手的状态可能包含 topic (主题)、 research_queries (研究查询列表)、 validated_facts (已验证事实列表)和 final_report (最终报告)等字段。
- 节点(Node)与边(Edge)
- 节点:是图中的一个执行单元,通常对应一个函数。这个函数接收当前状态作为输入,执行某些操作(如调用LLM、查询数据库、运行代码),并返回更新后的状态。例如, researcher_agent 节点负责将宽泛主题分解为具体查询并收集信息。
- 边:定义了工作流的控制流。边可以是条件边,根据状态的某些属性决定下一个执行的节点;也可以是固定边,始终指向同一个后续节点。这为工作流引入了动态决策能力。
二、 架构设计与工作流引擎
LangGraph的架构设计旨在提供一个灵活、可扩展且状态感知的工作流引擎。
- StateGraph :有状态工作流的容器 这是构建LangGraph应用的核心类。开发者需要定义一个状态模式( State ),然后初始化一个 StateGraph 实例。之后,将各个处理函数作为节点( add_node )添加到图中,并使用边( add_edge 或 add_conditional_edges )来连接它们,定义执行顺序和条件分支。
- 监督者(Supervisor)与多智能体协调 对于多智能体系统,LangGraph常采用“监督者”模式。一个顶层的“监督者”或“路由”节点负责分析任务,并将其分配给具有特定专长的子智能体(节点)执行。监督者根据子节点的结果决定下一步是继续调用其他智能体,还是汇总结果并结束流程。这种架构有效减少了单一模型处理所有任务时可能产生的“幻觉”,并提升了复杂任务的处理性能。
- 循环与迭代 LangGraph支持在图中定义循环,这是实现多轮对话、迭代优化等场景的关键。通过条件边,可以让工作流在满足特定条件时(例如,“用户要求继续澄清”或“答案置信度不足”)跳转回之前的节点重新处理,形成一个循环,直到满足退出条件。
三、 实战样例:多智能体研究助手
以下是一个基于LangGraph构建多智能体系统的简化示例,它清晰地展示了上述核心概念如何落地。
第一步:定义共享状态
首先,定义一个类型化的状态字典,作为智能体间共享的信息黑板。
from typing import TypedDict, List, Annotated
from langgraph.graph.message import add_messages
class ResearchState(TypedDict):
topic: str # 研究主题
research_queries: List[str] # 分解后的查询列表
raw_information: List[str] # 收集的原始信息
validated_facts: List[str] # 经过验证的事实
final_report: str # 最终报告
current_agent: str # 当前执行的智能体
messages: Annotated[list, add_messages] # 消息记录
第二步:构建智能体节点
每个智能体是一个函数,接收并更新状态。
def researcher_agent(state: ResearchState):
"""研究员智能体:分解主题并收集信息"""
topic = state["topic"]
# 使用LLM将主题分解为具体查询
query_prompt = f"将这个研究主题分解为3-5个具体的、可搜索的查询:{topic}"
queries = llm.invoke(query_prompt).content.split('\n')
queries = [q.strip() for q in queries if q.strip()]
raw_info = []
for query in queries:
# 模拟研究过程(实际中可调用搜索API)
research_result = llm.invoke(f"Research and provide information about: {query}")
raw_info.append(research_result.content)
# 更新状态
return {
"research_queries": queries,
"raw_information": raw_info,
"current_agent": "researcher"
}
def fact_checker_agent(state: ResearchState):
"""事实核查智能体:验证信息的可靠性"""
raw_info = state["raw_information"]
validated_facts = []
for info_piece in raw_info:
validation_prompt = f"分析这个信息的准确性和可靠性:{info_piece}"
validation_result = llm.invoke(validation_prompt)
if "reliable" in validation_result.content.lower():
validated_facts.append(info_piece)
return {"validated_facts": validated_facts, "current_agent": "fact_checker"}
def report_writer_agent(state: ResearchState):
"""报告撰写智能体:生成综合报告"""
topic = state["topic"]
validated_facts = state["validated_facts"]
report_prompt = f"基于以下已验证的事实,撰写一份关于'{topic}'的综合报告:\n" + "\n".join(validated_facts)
report = llm.invoke(report_prompt).content
return {"final_report": report, "current_agent": "report_writer"}
第三步:构图与编排
创建图,添加节点,并定义执行流程。
from langgraph.graph import StateGraph, START, END
# 初始化工作流图
workflow = StateGraph(ResearchState)
# 添加节点
workflow.add_node("researcher", researcher_agent)
workflow.add_node("fact_checker", fact_checker_agent)
workflow.add_node("report_writer", report_writer_agent)
# 定义边,构建线性流程:研究员 -> 事实核查员 -> 报告撰写员
workflow.add_edge(START, "researcher")
workflow.add_edge("researcher", "fact_checker")
workflow.add_edge("fact_checker", "report_writer")
workflow.add_edge("report_writer", END)
# 编译图
app = workflow.compile()
第四步:执行与观察
传入初始状态,运行工作流。
# 定义初始状态
initial_state = ResearchState(topic="气候变化对全球经济的影响", ...)
# 执行图
final_state = app.invoke(initial_state)
print(final_state["final_report"])
在这个例子中, ResearchState 是共享的全局状态。三个智能体节点依次执行,每个节点读取并修改状态中的特定部分。 StateGraph 清晰地定义了 研究员 -> 事实核查员 -> 报告撰写员 这一执行路径。通过扩展此图,例如在 事实核查员 之后增加一个条件分支,当验证通过的事实不足时,可以循环回 研究员 节点进行更深入的搜索,从而轻松实现更复杂的、带循环的协作逻辑。
四、 总结:LangGraph的核心价值
LangGraph通过引入图计算范式和统一的状态管理,为构建复杂、可协作的AI智能体系统提供了强大的底层支持。它将工作流从简单的线性链升级为动态的、有状态的图,使得开发能够进行多步推理、具备记忆和协作能力的多智能体应用变得直观和模块化。结合LangSmith等工具进行可视化追踪和调试,可以极大地提升这类系统的开发效率和可靠性。
4.2 LangGraph核心类与API详解
LangGraph 是一个由 LangChain 公司开发的、用于构建基于大型语言模型(LLM)的有状态多智能体应用程序的库,其核心设计灵感来源于 Pregel 和 Apache Beam,公共接口借鉴了 NetworkX。它通过将工作流建模为图结构,支持循环、分支和状态传递,从而构建出能够处理复杂、动态任务的智能体系统。
一、 核心类与架构设计
LangGraph 的核心架构围绕 图(Graph)、状态(State) 和 节点(Node) 三个核心概念构建,其设计旨在支持比传统链式结构更复杂、更模糊的输入处理。
1. StateGraph:有状态工作流的容器
StateGraph 是 LangGraph 的核心类,用于表示整个图结构。初始化时需要定义一个状态对象,这个状态对象会随着图的执行而更新。
- 状态定义:状态通常使用 TypedDict 或 BaseModel 进行类型化定义,它是在图执行过程中维护的中央数据对象,封装了任务执行过程中的所有上下文信息。
- 状态更新:状态的属性可以通过两种方式更新:完全覆盖(节点返回一个新值来替换原属性)或添加(节点返回值会被添加到现有属性,适用于列表等)。例如,使用 Annotated[List[str], operator.add] 表示新产生的消息列表会追加到已有的消息列表中,而不是替换它。
2. Node:图中的处理单元
节点是图中的基本处理单元,用于接收状态做计算,并返回更新后的状态。
- 节点定义:节点通常是一个 Python 函数或 LangChain 的可运行组件(LCEL Runnable)。它接收一个状态对象(形式为字典)作为输入,并输出一个包含要更新的状态对象键的字典。
- 节点作用:每个节点负责执行特定的逻辑,如调用 LLM、查询数据库、运行代码等。节点接受的状态是全局状态的快照,而不是某个节点单独维护的局部状态。
3. Edge:节点间的流转控制
边定义了节点之间的执行流程和数据流向,决定了下一个要执行的节点。
- 普通边(法向边缘):固定的流向,无条件地从一个节点指向另一个节点。
- 条件边:基于上游节点的输出或状态中的条件,通过一个判断函数来决定下一步的去向。该函数返回一个字符串,用于映射到下一个节点或特殊的 END 节点。
4. 图编译与执行
在定义了状态、节点和边之后,需要调用 compile() 方法来构建一个可运行的图对象。这个对象可以像函数一样被调用( invoke ),传入初始状态来启动工作流。
二、 关键 API 详解与使用模式
以下通过一个智能体工作流的构建示例,来详细说明核心 API 的使用方法。
1. 定义状态(State)
状态是贯穿整个执行过程的中心化数据容器,它记录了所有关键信息,如用户输入、对话历史、工具调用结果等。
from typing import TypedDict, Annotated, List
from langgraph.graph import StateGraph
import operator
class AgentState(TypedDict):
"""
用于存储代理状态的 TypedDict。
messages: 存储所有消息(用户、AI、工具)。
tool_calls: LLM决定要调用的工具列表。
tool_output: 工具调用后返回的结果。
"""
messages: Annotated[List[dict], operator.add] # 使用 operator.add 进行追加更新
tool_calls: List[dict]
tool_output: str
2. 初始化 StateGraph
使用定义好的状态类来初始化一个 StateGraph 对象。
workflow = StateGraph(AgentState)
3. 添加节点(add_node)
将处理函数作为节点添加到图中。节点函数接收状态,并返回要更新的状态部分。
def llm_model_node(state: AgentState):
"""LLM节点:分析消息并决定行动。"""
# 调用LLM,基于 messages 决定是生成回复还是调用工具
llm_response = model.invoke(state["messages"])
# 假设 model 被配置为返回工具调用
if hasattr(llm_response, 'tool_calls') and llm_response.tool_calls:
return {"tool_calls": llm_response.tool_calls}
else:
return {"messages": [llm_response]}
def tool_node(state: AgentState):
"""工具节点:执行LLM指定的工具。"""
tool_name = state["tool_calls"]["name"]
# ... 根据 tool_name 执行具体工具逻辑
tool_result = f"执行工具 {tool_name} 的结果"
return {"tool_output": tool_result}
workflow.add_node("model", llm_model_node)
workflow.add_node("tools", tool_node)
4. 添加边(add_edge, add_conditional_edges)
定义节点之间的执行顺序和条件分支。
- 添加普通边:使用 add_edge 指定固定的流向。
workflow.add_edge(START, "model") # 从开始节点到模型节点
- 添加条件边:使用 add_conditional_edges 实现动态路由。这需要传入一个路由函数,该函数根据当前状态返回下一个节点的名称。
def should_continue(state: AgentState):
"""根据状态决定下一步:继续调用工具还是结束。"""
if state.get("tool_calls"):
return "tools" # 有工具调用,去工具节点
else:
return END # 没有工具调用,结束
workflow.add_conditional_edges(
"model", # 上游节点
should_continue, # 路由判断函数
{
"tools": "tools", # 如果返回"tools",则前往"tools"节点
END: END # 如果返回END,则结束
}
)
workflow.add_edge("tools", "model") # 工具执行完后,回到模型节点进行下一步思考
这种模式实现了 ReAct(Reasoning and Acting)循环:模型“思考”后决定行动(调用工具),观察工具结果后再次“思考”,直到任务完成。
5. 编译与执行图(compile, invoke)
完成图的构建后,需要编译它,然后传入初始状态来执行。
# 编译图,得到可运行对象
app = workflow.compile()
# 定义初始状态并执行
initial_state = AgentState(messages=[{"role": "user", "content": "北京的天气怎么样?"}])
final_state = app.invoke(initial_state)
print(final_state["messages"][-1]["content"])
三、 高级特性与架构模式
1. 循环与迭代
LangGraph 最重要的特性之一是能够创建循环流程,允许 LLM 在循环中进行推理决策,这对于构建智能体系统至关重要。上面的条件边示例就展示了一个简单的“思考-行动-观察”循环。
2. 多智能体与监督者模式
对于复杂任务,可以构建多智能体系统。一个常见的模式是“监督者(Supervisor)”模式:一个顶层的“监督者”或“路由”节点负责分析任务,并将其分配给具有特定专长的子智能体(节点)执行[^背景]。这可以通过在图中设计多个分支和条件路由来实现。
3. 与 LangChain AgentExecutor 的关系
LangGraph 可以重新创建甚至替代传统的 LangChain AgentExecutor ,并允许开发者修改其内部结构。它提供了更精细的控制和更灵活的状态管理能力。
4. 状态检查点与人机协作
LangGraph 支持持久化应用程序状态的任意方面,支持对话和更新的记忆。状态检查点允许执行中断和恢复,并可在关键阶段通过人工输入进行决策和修正,这为人机协作提供了可能。
总结
LangGraph 通过 StateGraph 、 Node 、 Edge 等核心类以及 add_node 、 add_edge 、 add_conditional_edges 、 compile 、 invoke 等关键 API,为开发者提供了一个强大而灵活的框架,用于构建具有复杂控制流、状态管理和多智能体协作能力的 AI 应用。其基于图的计算模型,特别是对循环和条件分支的支持,使其成为开发超越简单问答的、能够自主规划与执行的智能体的理想选择。
4.3 LangGraph实战项目:旅游规划智能体
一、 项目需求与架构设计
项目需求分析
本项目旨在构建一个基于LangGraph的企业级旅游规划智能体,它需要具备以下核心能力:
- 多轮对话理解:通过自然语言交互,理解用户的复杂、模糊需求,如“我想去一个温暖的海边城市,预算中等,喜欢美食和文化”。
- 全流程规划:从目的地推荐、行程安排、预算估算到预订服务,提供一站式解决方案。
- 动态调整能力:能够根据用户反馈、实时信息(如天气、交通)动态优化行程。
- 外部服务集成:无缝对接机票、酒店、景点门票、天气、地图等第三方API。
- 个性化推荐:基于用户画像和历史行为提供个性化建议。
系统架构设计
基于LangGraph的图计算范式,我们将旅游规划智能体的工作流设计为一个有向状态图,包含多个专业节点(智能体)和条件分支,实现“感知-规划-执行-调整”的闭环。
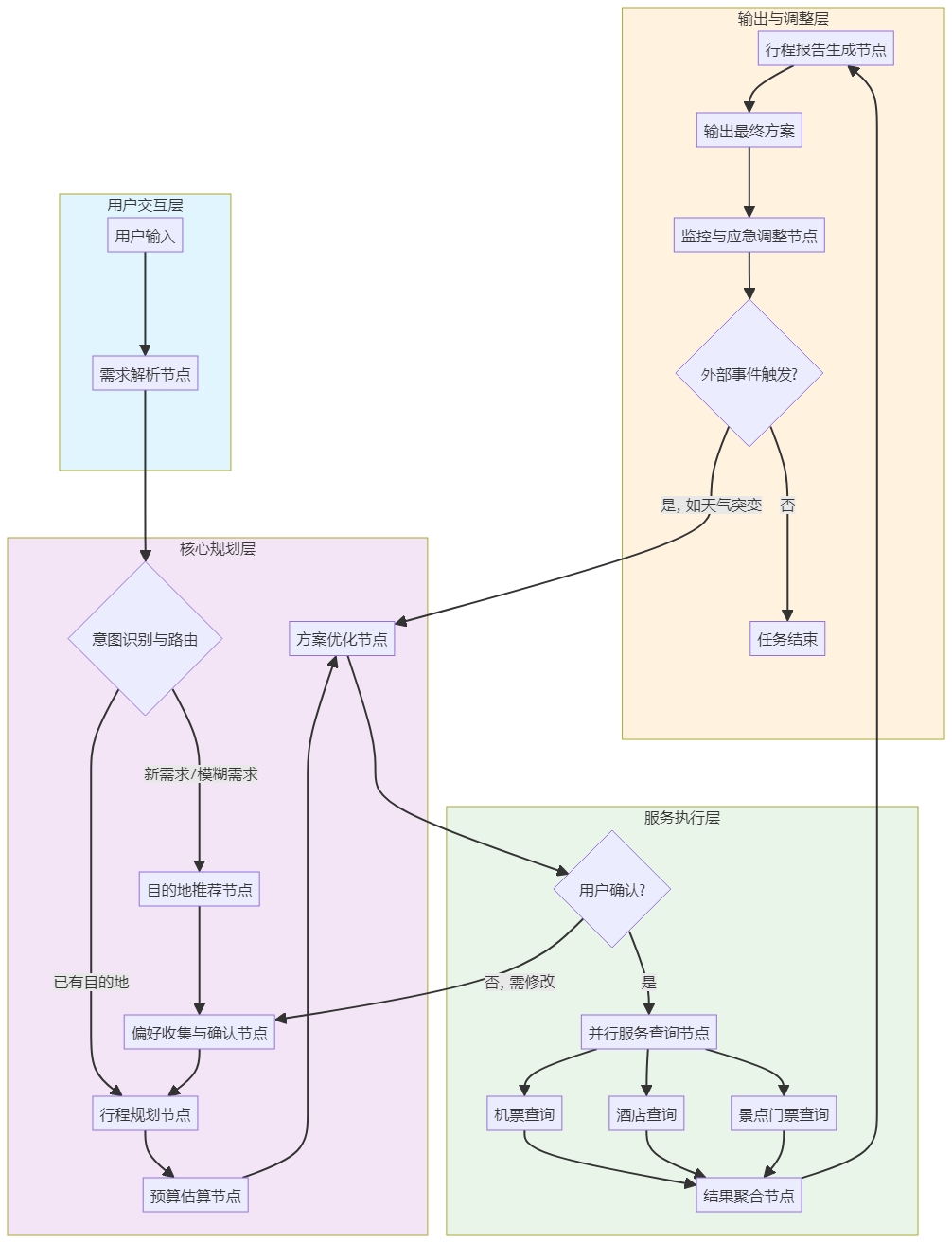
该架构体现了LangGraph的核心优势:状态驱动和条件路由。整个流程并非线性,而是根据用户输入和实时状态动态决定下一个节点,支持循环(如多次优化)和并行(如同时查询多个服务)。
二、 核心实现:状态定义与节点构建
定义结构化状态(State)
状态是LangGraph工作流中贯穿始终的数据容器,它封装了从用户初始需求到最终行程方案的所有信息。我们使用 TypedDict 进行类型化定义,确保数据结构清晰。
from typing import TypedDict, List, Dict, Optional, Annotated
from datetime import date
from langgraph.graph.message import add_messages
import operator
class TravelPlanningState(TypedDict):
"""
旅游规划智能体的全局状态。
遵循LangGraph状态管理最佳实践,明确数据流向。
"""
# 用户输入与对话历史
user_input: str
messages: Annotated[List[Dict], add_messages] # 对话历史,自动追加更新
# 用户画像与约束条件
user_id: Optional[str]
destination_preferences: List[str] # 如 ['beach', 'culture', 'food']
budget_range: Dict[str, float] # {'min': 5000, 'max': 15000}
travel_dates: Dict[str, date] # {'start': '2025-07-01', 'end': '2025-07-07'}
traveler_count: int
special_requirements: List[str] # 如 ['wheelchair accessible', 'pet friendly']
# 规划过程与中间结果
candidate_destinations: List[Dict] # 推荐的目的地列表
selected_destination: Optional[str]
daily_itinerary: List[Dict] # 每日行程详情
estimated_budget: Dict[str, float] # 分项预算
optimization_feedback: List[str] # 用户反馈的修改意见
# 服务查询与预订
flight_options: List[Dict]
hotel_options: List[Dict]
activity_options: List[Dict]
selected_services: Dict[str, Dict] # 用户最终选择的服务
# 系统控制与元数据
current_step: str # 记录当前执行到哪个节点
max_iterations: int # 最大优化轮次,防止无限循环
iteration_count: int # 当前迭代次数
设计说明:
- 使用 Annotated 和 add_messages 确保对话历史以追加方式更新,而非覆盖,这是LangGraph处理多轮对话的推荐方式。
- 状态字段覆盖了从输入( user_input )、处理( candidate_destinations , daily_itinerary )到输出( selected_services )的全流程。
- current_step 和 iteration_count 用于实现工作流的条件路由和循环控制。
构建关键功能节点
每个节点是一个独立的函数,接收状态、执行业务逻辑、返回状态更新。
节点1:需求解析与意图识别节点
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
llm = ChatOpenAI(model="gpt-4", temperature=0.2)
def parse_user_intent(state: TravelPlanningState) -> Dict:
"""
解析用户初始输入,提取关键约束条件。
使用LLM进行意图识别和实体抽取。
"""
prompt_template = PromptTemplate(
input_variables=["user_input"],
template="""
你是一个专业的旅游顾问。请从用户的以下描述中,提取旅游规划所需的关键信息。
用户描述:{user_input}
请以JSON格式返回,包含以下字段:
1. destination_preferences: 数组,列出用户可能喜欢的目的地类型关键词(如['beach', 'mountain', 'city'])。
2. budget_range: 对象,包含min和max(单位:人民币)。如果用户未明确,则根据“经济”、“豪华”等词推断。
3. travel_dates: 对象,包含start和end(格式:YYYY-MM-DD)。如果用户未明确,则返回null。
4. traveler_count: 整数,出行人数。
5. special_requirements: 数组,特殊要求(如['family friendly', 'adventure'])。
"""
)
response = llm.invoke(prompt_template.format(user_input=state["user_input"]))
# 假设LLM返回格式良好的JSON字符串
import json
extracted_info = json.loads(response.content)
# 更新状态
return {
"destination_preferences": extracted_info.get("destination_preferences", []),
"budget_range": extracted_info.get("budget_range", {"min": 5000, "max": 20000}),
"travel_dates": extracted_info.get("travel_dates"),
"traveler_count": extracted_info.get("traveler_count", 2),
"special_requirements": extracted_info.get("special_requirements", []),
"current_step": "intent_parsed"
}
节点2:目的地推荐节点(集成外部知识)
import requests
from typing import List
def recommend_destinations(state: TravelPlanningState) -> Dict:
"""
基于用户偏好,调用外部API或知识库推荐目的地。
此处模拟调用一个内部目的地数据库API。
"""
preferences = state["destination_preferences"]
budget = state["budget_range"]
# 模拟API调用 - 实际项目中替换为真实的推荐服务
# 例如:response = requests.post(' https://api.travel.com/destinations', json={'preferences': preferences})
mock_api_response = [
{"name": "三亚", "country": "中国", "type": ["beach", "food"], "budget_level": "medium", "score": 0.92},
{"name": "厦门", "country": "中国", "type": ["beach", "culture"], "budget_level": "low", "score": 0.87},
{"name": "普吉岛", "country": "泰国", "type": ["beach", "adventure"], "budget_level": "medium", "score": 0.89},
{"name": "巴厘岛", "country": "印度尼西亚", "type": ["beach", "culture", "spa"], "budget_level": "high", "score": 0.85}
]
# 根据预算过滤(模拟)
budget_level_map = {"low": 5000, "medium": 10000, "high": 20000}
filtered_destinations = [
d for d in mock_api_response
if budget_level_map.get(d["budget_level"], 15000) <= budget["max"]
]
# 根据偏好匹配度排序(简化逻辑)
def calculate_match_score(destination, prefs):
type_match = len(set(destination["type"]) & set(prefs)) / len(prefs) if prefs else 0
return destination["score"] * 0.7 + type_match * 0.3
sorted_destinations = sorted(
filtered_destinations,
key=lambda x: calculate_match_score(x, preferences),
reverse=True
)[:5] # 返回前5个推荐
return {
"candidate_destinations": sorted_destinations,
"current_step": "destinations_recommended"
}
节点3:行程规划节点(多轮交互)
def plan_itinerary(state: TravelPlanningState) -> Dict:
"""
为选定的目的地生成详细每日行程。
这是一个复杂的多步骤规划,可能涉及与用户的多次交互确认。
"""
destination = state["selected_destination"]
travel_dates = state["travel_dates"]
days = (travel_dates["end"] - travel_dates["start"]).days + 1
# 使用LLM生成初步行程大纲
itinerary_prompt = f"""
为{destination}的{days}天旅行创建一个详细的每日行程。
旅行日期:{travel_dates['start']} 到 {travel_dates['end']}
旅行人数:{state['traveler_count']}
特殊要求:{', '.join(state['special_requirements'])}
请按以下格式规划:
第一天:
- 上午:[活动1]
- 下午:[活动2]
- 晚上:[活动3]
- 餐饮推荐:[餐厅]
第二天:
...
请确保行程节奏合理,兼顾观光、休闲和当地体验。
"""
itinerary_response = llm.invoke(itinerary_prompt)
# 解析响应,转换为结构化数据(此处简化)
daily_plan = parse_itinerary_response(itinerary_response.content)
return {
"daily_itinerary": daily_plan,
"current_step": "itinerary_generated",
"messages": [{"role": "assistant", "content": f"我为{destination}规划了一个{days}天的行程,请看是否满意?"}]
}
节点4:预算估算节点
def estimate_budget(state: TravelPlanningState) -> Dict:
"""
基于行程和目的地,估算详细预算。
"""
destination = state["selected_destination"]
itinerary = state["daily_itinerary"]
days = len(itinerary)
travelers = state["traveler_count"]
# 模拟调用成本数据库或规则引擎
# 实际项目中,这里可能集成多个API:机票价格、酒店均价、景点门票等
destination_cost_data = {
"三亚": {"flight_per_person": 1500, "hotel_per_night": 600, "daily_activities": 300, "daily_food": 200},
"厦门": {"flight_per_person": 800, "hotel_per_night": 400, "daily_activities": 200, "daily_food": 150},
"普吉岛": {"flight_per_person": 3000, "hotel_per_night": 800, "daily_activities": 400, "daily_food": 250},
"巴厘岛": {"flight_per_person": 3500, "hotel_per_night": 1000, "daily_activities": 500, "daily_food": 300}
}
cost_profile = destination_cost_data.get(destination, destination_cost_data["三亚"])
estimated_costs = {
"flights": cost_profile["flight_per_person"] * travelers,
"hotel": cost_profile["hotel_per_night"] * days * travelers,
"activities": cost_profile["daily_activities"] * days * travelers,
"food": cost_profile["daily_food"] * days * travelers,
"transportation": 500 * days, # 当地交通
"miscellaneous": 1000 # 杂费
}
total = sum(estimated_costs.values())
return {
"estimated_budget": estimated_costs,
"messages": [{"role": "assistant", "content": f"根据行程估算总费用约为{total}元,明细如下:{estimated_costs}"}],
"current_step": "budget_estimated"
}
节点5:服务查询与聚合节点(并行处理)
import asyncio
from typing import List, Dict
async def fetch_flights(destination: str, dates: Dict) -> List[Dict]:
"""模拟异步查询航班API"""
await asyncio.sleep(0.5) # 模拟网络延迟
# 实际调用:async with aiohttp.ClientSession() as session: ...
return [
{"airline": "中国南方航空", "price": 1200, "departure": "08:00", "duration": "3h"},
{"airline": "海南航空", "price": 1350, "departure": "14:30", "duration": "3.5h"}
]
async def fetch_hotels(destination: str, dates: Dict, travelers: int) -> List[Dict]:
"""模拟异步查询酒店API"""
await asyncio.sleep(0.7)
return [
{"name": "三亚亚龙湾万豪", "price_per_night": 800, "rating": 4.5, "location": "亚龙湾"},
{"name": "三亚海棠湾君悦", "price_per_night": 1200, "rating": 4.8, "location": "海棠湾"}
]
async def fetch_activities(destination: str, dates: Dict) -> List[Dict]:
"""模拟异步查询景点活动API"""
await asyncio.sleep(0.3)
return [
{"name": "蜈支洲岛一日游", "price": 300, "duration": "全天", "type": "海岛"},
{"name": "亚特兰蒂斯水世界", "price": 258, "duration": "半天", "type": "水上乐园"}
]
def query_services_parallel(state: TravelPlanningState) -> Dict:
"""
并行查询多个外部服务:航班、酒店、活动。
演示LangGraph中实现并行处理的模式。
"""
destination = state["selected_destination"]
dates = state["travel_dates"]
travelers = state["traveler_count"]
async def parallel_fetch():
# 创建并行任务
tasks = [
fetch_flights(destination, dates),
fetch_hotels(destination, dates, travelers),
fetch_activities(destination, dates)
]
# 并行执行
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
# 运行异步函数
import asyncio
flight_results, hotel_results, activity_results = asyncio.run(parallel_fetch())
# 处理异常
flight_options = flight_results if not isinstance(flight_results, Exception) else []
hotel_options = hotel_results if not isinstance(hotel_results, Exception) else []
activity_options = activity_results if not isinstance(activity_results, Exception) else []
return {
"flight_options": flight_options,
"hotel_options": hotel_options,
"activity_options": activity_options,
"current_step": "services_queried",
"messages": [{"role": "assistant", "content": f"已为您查询到{len(flight_options)}个航班选项、{len(hotel_options)}个酒店选项和{len(activity_options)}个活动选项。"}]
}
三、 工作流编排与条件路由
构建状态图与节点连接
使用LangGraph的 StateGraph API构建完整的工作流。
from langgraph.graph import StateGraph, START, END
# 初始化状态图
workflow = StateGraph(TravelPlanningState)
# 添加所有节点
workflow.add_node("parse_intent", parse_user_intent)
workflow.add_node("recommend_destinations", recommend_destinations)
workflow.add_node("confirm_destination", confirm_destination) # 确认节点,与用户交互
workflow.add_node("plan_itinerary", plan_itinerary)
workflow.add_node("estimate_budget", estimate_budget)
workflow.add_node("query_services", query_services_parallel)
workflow.add_node("generate_final_report", generate_final_report)
workflow.add_node("handle_feedback", handle_feedback) # 处理用户反馈,优化行程
# 定义边的连接关系
workflow.add_edge(START, "parse_intent")
workflow.add_edge("parse_intent", "recommend_destinations")
workflow.add_edge("recommend_destinations", "confirm_destination")
# 条件边:根据用户是否确认目的地,决定下一步
def after_destination_confirmation(state: TravelPlanningState) -> str:
"""路由函数:判断用户是否已选择目的地"""
if state.get("selected_destination"):
return "proceed_to_planning" # 已确认,继续规划
else:
return "need_more_options" # 未确认,需要更多推荐
workflow.add_conditional_edges(
"confirm_destination",
after_destination_confirmation,
{
"proceed_to_planning": "plan_itinerary",
"need_more_options": "recommend_destinations" # 循环回推荐节点
}
)
# 后续线性流程(可进一步添加条件分支)
workflow.add_edge("plan_itinerary", "estimate_budget")
workflow.add_edge("estimate_budget", "query_services")
workflow.add_edge("query_services", "generate_final_report")
# 条件边:用户是否满意最终方案?
def after_final_report(state: TravelPlanningState) -> str:
"""根据用户反馈决定是否结束或优化"""
feedback = state.get("optimization_feedback", [])
iteration = state.get("iteration_count", 0)
max_iter = state.get("max_iterations", 3)
if not feedback or iteration >= max_iter:
return "end" # 无反馈或达到最大迭代次数,结束
else:
return "optimize" # 有反馈,进入优化流程
workflow.add_conditional_edges(
"generate_final_report",
after_final_report,
{
"end": END,
"optimize": "handle_feedback"
}
)
# 从反馈处理节点回到规划节点,形成优化循环
workflow.add_edge("handle_feedback", "plan_itinerary")
# 编译图
app = workflow.compile()
条件路由与循环控制详解
上述工作流展示了LangGraph的两个核心特性:
- 条件路由(Conditional Edges):通过 add_conditional_edges 方法,我们可以基于当前状态动态决定工作流的下一个节点。例如:
- 在 confirm_destination 节点后,根据用户是否确认了目的地,决定是进入详细规划还是返回重新推荐。
- 在 generate_final_report 节点后,根据用户反馈决定是结束流程还是进入优化循环。
- 循环(Cycles):工作流中设计了多个循环:
- 目的地选择循环:如果用户对推荐不满意,可以返回 recommend_destinations 节点重新推荐。
- 行程优化循环:如果用户对最终方案有修改意见,通过 handle_feedback -> plan_itinerary 路径重新规划。
为了防止无限循环,我们在状态中设置了 max_iterations 和 iteration_count 字段,在路由函数中进行检查。
四、 外部工具集成与Function Calling
使用@tool装饰器定义工具
LangGraph通过 @tool 装饰器可以轻松地将外部API封装为智能体可调用的工具。
from langchain_core.tools import tool
import requests
@tool
def get_weather_forecast(city: str, date: str) -> str:
"""
获取指定城市在特定日期的天气预报。
Args:
city: 城市名称,如"三亚"
date: 日期,格式"YYYY-MM-DD"
Returns:
天气预报的文本描述
"""
# 实际项目中替换为真实的天气API,如OpenWeatherMap
api_key = "your_weather_api_key"
url = f" https://api.weatherapi.com/v1/forecast.json?key= {api_key}&q={city}&dt={date}"
try:
response = requests.get(url, timeout=10)
data = response.json()
forecast = data['forecast']['forecastday']['day']
return f"{city}在{date}的天气:{forecast['condition']['text']},最高温度{forecast['maxtemp_c']}°C,最低温度{forecast['mintemp_c']}°C,降水概率{forecast['daily_chance_of_rain']}%。"
except Exception as e:
return f"获取天气信息失败:{str(e)}"
@tool
def search_flights(departure_city: str, arrival_city: str, date: str) -> list:
"""
搜索航班信息。
Args:
departure_city: 出发城市
arrival_city: 到达城市
date: 出发日期
Returns:
航班列表,每个航班包含航空公司、价格、时间等信息
"""
# 模拟数据 - 实际集成航班搜索API
mock_flights = [
{"airline": "中国国际航空", "flight_no": "CA1234", "departure": "08:00", "arrival": "11:00", "price": 1500},
{"airline": "南方航空", "flight_no": "CZ5678", "departure": "14:30", "arrival": "17:45", "price": 1380}
]
return mock_flights
@tool
def book_hotel(hotel_name: str, check_in: str, check_out: str, guests: int) -> dict:
"""
预订酒店。
Args:
hotel_name: 酒店名称
check_in: 入住日期
check_out: 离店日期
guests: 入住人数
Returns:
预订确认信息
"""
# 模拟预订流程 - 实际调用酒店预订API
confirmation = {
"hotel": hotel_name,
"confirmation_number": "HTL20250701XYZ",
"check_in": check_in,
"check_out": check_out,
"total_price": 4200,
"status": "confirmed"
}
return confirmation
# 将所有工具放入列表
tools = [get_weather_forecast, search_flights, book_hotel]
创建工具调用节点
在LangGraph中,我们可以创建一个专门的节点来处理工具调用。
from langgraph.prebuilt import ToolNode
# 创建工具执行器
from langgraph.prebuilt import ToolExecutor
tool_executor = ToolExecutor(tools)
# 创建工具节点
tool_node = ToolNode(tools=tools)
# 或者手动创建工具调用节点
def execute_tools(state: TravelPlanningState) -> Dict:
"""
执行LLM决定的工具调用。
这个节点通常放在LLM思考节点之后。
"""
# 从状态中获取LLM决定的工具调用
tool_calls = state.get("tool_calls", [])
tool_outputs = []
for tool_call in tool_calls:
tool_name = tool_call["name"]
tool_args = tool_call["args"]
# 找到对应的工具函数
tool_func = next((t for t in tools if t.name == tool_name), None)
if tool_func:
try:
# 执行工具
result = tool_func.invoke(tool_args)
tool_outputs.append({
"tool_name": tool_name,
"result": result,
"status": "success"
})
except Exception as e:
tool_outputs.append({
"tool_name": tool_name,
"result": str(e),
"status": "error"
})
else:
tool_outputs.append({
"tool_name": tool_name,
"result": f"工具'{tool_name}'未找到",
"status": "error"
})
return {
"tool_outputs": tool_outputs,
"current_step": "tools_executed"
}
集成工具调用到工作流
将工具调用集成到主工作流中,形成"思考-行动-观察"的ReAct循环。
# 在原有工作流中添加工具相关节点
workflow.add_node("llm_think", llm_think_node) # LLM思考下一步
workflow.add_node("execute_tools", execute_tools)
# 修改边连接,创建ReAct循环
workflow.add_edge("llm_think", "execute_tools")
workflow.add_edge("execute_tools", "llm_think") # 工具执行后返回思考
# 条件边:判断是否需要继续调用工具
def should_continue_tool_use(state: TravelPlanningState) -> str:
"""
判断是否继续使用工具。
基于LLM的输出决定下一步。
"""
last_message = state["messages"][-1] if state["messages"] else None
if last_message and hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "use_tools" # LLM决定调用工具
else:
return "generate_response" # LLM生成最终回复
workflow.add_conditional_edges(
"llm_think",
should_continue_tool_use,
{
"use_tools": "execute_tools",
"generate_response": "generate_final_report"
}
)
五、 高级特性:多智能体协作与人工介入
多智能体协作模式
对于复杂的旅游规划任务,可以设计多个专业智能体协同工作。
def create_multi_agent_system():
"""
创建多智能体协作系统。
每个智能体负责特定领域,通过共享状态协作。
"""
from langgraph.graph import StateGraph
class MultiAgentState(TypedDict):
"""多智能体共享状态"""
query: str
destination_agent_output: Optional[str]
itinerary_agent_output: Optional[str]
budget_agent_output: Optional[str]
final_plan: Optional[str]
current_agent: str
# 目的地专家智能体
def destination_expert(state: MultiAgentState) -> Dict:
"""专注于目的地推荐的智能体"""
# 使用专门的LLM或知识库
destination_recommendation = "基于您的偏好,推荐三亚、厦门和普吉岛..."
return {
"destination_agent_output": destination_recommendation,
"current_agent": "destination_expert"
}
# 行程规划专家智能体
def itinerary_expert(state: MultiAgentState) -> Dict:
"""专注于行程规划的智能体"""
# 接收目的地专家的输出作为输入
destinations = state.get("destination_agent_output", "")
itinerary = f"为{destinations}设计7天行程..."
return {
"itinerary_agent_output": itinerary,
"current_agent": "itinerary_expert"
}
# 预算专家智能体
def budget_expert(state: MultiAgentState) -> Dict:
"""专注于预算估算的智能体"""
itinerary = state.get("itinerary_agent_output", "")
budget_estimate = "根据行程估算总费用约8000-12000元..."
return {
"budget_agent_output": budget_estimate,
"current_agent": "budget_expert"
}
# 协调者智能体
def coordinator_agent(state: MultiAgentState) -> Dict:
"""协调各专家智能体,整合最终结果"""
destination_info = state.get("destination_agent_output", "")
itinerary_info = state.get("itinerary_agent_output", "")
budget_info = state.get("budget_agent_output", "")
final_plan = f"""
旅行规划报告:
1. 目的地推荐:{destination_info}
2. 行程安排:{itinerary_info}
3. 预算估算:{budget_info}
"""
return {
"final_plan": final_plan,
"current_agent": "coordinator"
}
# 构建多智能体工作流
multi_agent_workflow = StateGraph(MultiAgentState)
multi_agent_workflow.add_node("destination_expert", destination_expert)
multi_agent_workflow.add_node("itinerary_expert", itinerary_expert)
multi_agent_workflow.add_node("budget_expert", budget_expert)
multi_agent_workflow.add_node("coordinator", coordinator_agent)
# 定义执行顺序:串行协作
multi_agent_workflow.add_edge(START, "destination_expert")
multi_agent_workflow.add_edge("destination_expert", "itinerary_expert")
multi_agent_workflow.add_edge("itinerary_expert", "budget_expert")
multi_agent_workflow.add_edge("budget_expert", "coordinator")
multi_agent_workflow.add_edge("coordinator", END)
return multi_agent_workflow.compile()
人工介入(Human-in-the-Loop)
对于关键决策点(如高额消费确认),可以引入人工审核节点。
def human_approval_node(state: TravelPlanningState) -> Dict:
"""
人工审核节点:当预算超过阈值时,需要人工确认。
在实际系统中,这里可以集成到邮件、Slack或内部审批系统。
"""
total_budget = sum(state.get("estimated_budget", {}).values())
budget_threshold = 10000 # 设置审批阈值
if total_budget > budget_threshold:
# 生成待审批信息
approval_request = {
"request_id": f"TRAVEL_{int(time.time())}",
"destination": state["selected_destination"],
"itinerary": state["daily_itinerary"],
"total_budget": total_budget,
"details": state["estimated_budget"],
"requester": state.get("user_id", "anonymous"),
"status": "pending",
"created_at": datetime.now().isoformat()
}
# 在实际系统中,这里会将审批请求发送到人工审批流程
# 例如:send_to_approval_system(approval_request)
return {
"approval_request": approval_request,
"needs_human_approval": True,
"current_step": "waiting_for_approval",
"messages": [{"role": "assistant", "content": "您的行程预算较高,已提交人工审核,请等待确认。"}]
}
else:
return {
"needs_human_approval": False,
"current_step": "auto_approved",
"messages": [{"role": "assistant", "content": "预算在自动批准范围内,继续为您处理。"}]
}
def check_approval_status(state: TravelPlanningState) -> Dict:
"""
检查人工审批状态。
在实际系统中,这里会查询审批系统的状态。
"""
approval_request = state.get("approval_request", {})
request_id = approval_request.get("request_id")
# 模拟查询审批状态 - 实际调用审批系统API
# status = query_approval_system(request_id)
status = "approved" # 假设已批准
if status == "approved":
return {
"approval_status": "approved",
"current_step": "approval_completed",
"messages": [{"role": "assistant", "content": "您的行程已获得批准,正在为您确认预订。"}]
}
elif status == "rejected":
return {
"approval_status": "rejected",
"current_step": "approval_rejected",
"messages": [{"role": "assistant", "content": "很抱歉,您的行程未获批准,建议调整预算后重新规划。"}]
}
else: # pending
return {
"approval_status": "pending",
"current_step": "still_waiting",
"messages": [{"role": "assistant", "content": "审批仍在进行中,请稍候..."}]
}
# 将人工介入节点集成到工作流中
workflow.add_node("human_approval", human_approval_node)
workflow.add_node("check_approval", check_approval_status)
# 在预算估算后添加条件分支
def after_budget_estimation(state: TravelPlanningState) -> str:
"""根据预算金额决定是否需要人工审批"""
total = sum(state.get("estimated_budget", {}).values())
if total > 10000: # 阈值
return "needs_approval"
else:
return "auto_approved"
workflow.add_conditional_edges(
"estimate_budget",
after_budget_estimation,
{
"needs_approval": "human_approval",
"auto_approved": "query_services"
}
)
# 人工审批后的流程
workflow.add_edge("human_approval", "check_approval")
def after_approval_check(state: TravelPlanningState) -> str:
"""根据审批结果决定下一步"""
status = state.get("approval_status")
if status == "approved":
return "proceed_to_services"
elif status == "rejected":
return "restart_planning" # 被拒绝,重新规划
else: # pending
return "wait_more" # 继续等待
workflow.add_conditional_edges(
"check_approval",
after_approval_check,
{
"proceed_to_services": "query_services",
"restart_planning": "plan_itinerary", # 回到规划节点重新规划
"wait_more": "check_approval" # 循环检查,直到有结果
}
)
六、 部署与生产环境考虑
性能优化策略
- 缓存频繁访问数据:对目的地信息、价格数据等建立缓存机制。
from functools import lru_cache
import time
@lru_cache(maxsize=100)
def get_cached_destination_info(destination_id: str) -> Dict:
"""缓存目的地信息,减少API调用"""
# 实际从数据库或缓存中获取
pass
- 异步并行处理:对于独立的服务查询,使用异步并行。
async def parallel_query_services(state: TravelPlanningState):
"""并行查询所有外部服务"""
tasks = [
fetch_flights(state["selected_destination"], state["travel_dates"]),
fetch_hotels(state["selected_destination"], state["travel_dates"], state["traveler_count"]),
fetch_activities(state["selected_destination"], state["travel_dates"]),
get_weather_forecast(state["selected_destination"], state["travel_dates"]["start"])
]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
- 增量更新与状态持久化:使用LangGraph的检查点机制保存中间状态,支持断点续传。
from langgraph.checkpoint import MemorySaver
# 添加检查点存储器
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
# 保存状态
config = {"configurable": {"thread_id": "user_123"}}
result = app.invoke(initial_state, config=config)
# 恢复状态
app.get_state(config)
监控与可观测性
- 集成LangSmith进行追踪:
import os
from langsmith import Client
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = " https://api.smith.langchain.com "
os.environ["LANGCHAIN_API_KEY"] = "your-api-key"
os.environ["LANGCHAIN_PROJECT"] = "travel-planning-agent"
# 自动追踪所有节点执行
- 自定义监控指标:
import time
from prometheus_client import Counter, Histogram
# 定义监控指标
REQUEST_COUNT = Counter('travel_agent_requests_total', 'Total requests')
PROCESSING_TIME = Histogram('travel_agent_processing_seconds', 'Processing time')
ERROR_COUNT = Counter('travel_agent_errors_total', 'Total errors')
def monitored_node(state: TravelPlanningState):
"""包装节点函数,添加监控"""
REQUEST_COUNT.inc()
start_time = time.time()
try:
result = original_node_function(state)
processing_time = time.time() - start_time
PROCESSING_TIME.observe(processing_time)
return result
except Exception as e:
ERROR_COUNT.inc()
raise e
安全与合规性
- 数据脱敏与隐私保护:
from cryptography.fernet import Fernet
class PrivacySafeState(TravelPlanningState):
"""扩展状态类,添加隐私保护"""
encrypted_user_info: Optional[str] = None
def encrypt_sensitive_data(self, key: bytes):
"""加密敏感用户信息"""
cipher = Fernet(key)
sensitive_data = {
"user_id": self.get("user_id"),
"travel_dates": self.get("travel_dates"),
"special_requirements": self.get("special_requirements")
}
encrypted = cipher.encrypt(json.dumps(sensitive_data).encode())
return {"encrypted_user_info": encrypted.decode()}
- 内容安全过滤:
def content_safety_filter(text: str) -> bool:
"""检查内容是否安全"""
# 集成内容安全API或本地模型
# 返回True表示安全,False表示不安全
pass
def safe_response_generation(state: TravelPlanningState):
"""安全的内容生成节点"""
response = llm.invoke(state["messages"])
if content_safety_filter(response.content):
return {"messages": [{"role": "assistant", "content": response.content}]}
else:
return {"messages": [{"role": "assistant", "content": "抱歉,我无法生成此内容。"}]}
七、 总结与展望
该项目基于LangGraph构建了一个企业级、多智能体协作的旅游规划系统。其核心价值在于通过图计算范式,将复杂的旅游规划流程(需求解析、目的地推荐、行程规划、预算估算、服务查询)模块化为可协作、可循环、可条件分支的节点,实现了从“被动问答”到“主动规划与执行”的范式跃迁。系统通过状态管理贯穿流程,支持多轮交互与动态调整,并集成了外部工具(如天气、航班API),体现了智能体“思考-行动-观察”的自主能力。引入人工介入节点与并行查询优化,确保了方案的可靠性(如高预算审批)与效率。
未来,此类系统将向更自主化、个性化与生态化发展:
- 更深度的人机协同:智能体不仅能执行规划,还能主动预测需求(如根据历史推荐偏好),并在关键节点(如突发天气、航班变动)实现自动应急调整与人工协同决策。
- 多模态与沉浸式体验:结合AR/VR、数字人导游(如“AI王勃”),提供景点虚拟预览、历史文化沉浸讲解(如“数字故宫”),从工具升级为“陪伴型旅伴”。
- 生态互联与实时服务:深度对接交通、住宿、景区等实时数据源(如“一部手机游甘肃”),实现行程动态优化(如拥堵绕行)与一站式履约(如AI自动订票)。
- 底层架构标准化:采用MCP[^背景]、A2A等协议,使规划智能体能无缝接入第三方工具(如支付、地图),并与其他智能体(如客服、售后)协同,形成覆盖行前、行中、行后的服务闭环。
简言之,旅游规划智能体正从“生成行程的助手”演进为“懂需求、会规划、能执行、可调整”的全程数字旅伴,其背后以LangGraph为代表的智能体编排技术,将成为构建下一代复杂AI应用的核心基础设施。
第五章:上下文工程Context Engineering深度实践
5.1 上下文工程定义与核心价值
上下文工程的定义:
上下文工程是指系统化地设计、管理和优化大模型交互中上下文信息的学科,它关注如何有效地组织、筛选和呈现信息,以最大化模型的理解能力和生成质量。
核心价值体现:
- 提升准确性:通过提供相关上下文,减少模型的猜测和幻觉
- 增强一致性:在多轮对话中保持话题连贯性和逻辑一致性
- 扩展能力边界:让模型能够处理超出训练数据范围的专业领域问题
- 降低计算成本:通过智能上下文管理减少不必要的token消耗
好的,我将基于您提供的搜索结果,为您系统性地阐述“上下文工程”的定义与核心价值,并结合具体样例进行说明。
一、 上下文工程的定义:从静态提示到动态环境构建的系统性学科
“上下文工程”是随着大语言模型应用从简单问答向复杂、长周期、自主化的智能体(Agent)演进而诞生的系统性概念。它超越了早期聚焦于单次指令优化的“提示工程”,将视野扩展至为模型执行任务构建一个完整、动态的信息环境。
其核心定义可以概括为:
上下文工程是一门系统性的科学与工程实践,专注于在AI智能体执行任务的每一步,动态地为其构建、筛选、组织并提供最相关、最有效的信息和工具,以确保大语言模型能够可靠、高效地完成复杂任务。
这个定义包含几个关键演进:
- 从“艺术”到“科学与工程”:它不再仅仅是撰写提示词的技巧(艺术),而是一套包含策略、架构和最佳实践的系统性工程方法。
- 从“静态”到“动态”:其核心在于“动态构建”。上下文不是一次性写死的,而是根据任务进展、环境反馈实时调整和演化的。
- 从“指令”到“环境”:目标不再只是给模型一个清晰的指令(便签),而是为它搭建一个包含角色设定、行为准则、记忆、知识、工具和输出格式的完整“工作剧本”或“开发环境”。
- 从“单次交互”到“持续任务”:它旨在解决智能体在长期运行、多步骤复杂任务中面临的“记忆真空”、“上下文边界”和“信息过载”等结构性局限。
一个绝佳的类比是:如果将大语言模型比作计算机的CPU,那么其上下文窗口就是RAM(内存)。上下文工程,就是这个系统中的“内存管理器”。它的核心任务不是简单地把所有信息塞满内存,而是通过精密的调度策略,决定在每个计算周期加载什么数据、如何组织、何时置换,以保障CPU(模型)最高效、最准确地运行。
二、 上下文工程与提示工程、RAG的关系
为了更清晰地区分,我们可以将其与传统概念对比:
| 维度 | 提示工程 (Prompt Engineering) | 检索增强生成 (RAG) | 上下文工程 (Context Engineering) |
|---|---|---|---|
| 核心目标 | 优化单次输入指令,引导模型产生期望输出。 | 为单次查询从外部知识库检索相关信息,增强回答的事实性。 | 动态构建任务执行全过程的最优信息环境,确保复杂任务的可靠完成。 |
| 关注焦点 | 用户输入的措辞、结构、示例(少样本学习)。 | 查询与文档的匹配、检索结果的质量与相关性。 | 系统架构和数据流。统筹管理所有输入模型的信息源,包括系统提示、记忆、工具、检索结果等。 |
| 实践者 | 开发者、终端用户。 | AI工程师、搜索算法工程师。 | AI工程师和系统架构师。 |
| 本质 | “问话的艺术”,优化与模型的单次沟通。 | 一种关键技术,用于解决知识实时性和幻觉问题。 | “环境构建的科学”,为智能体构建一个使其能自主、可靠工作的完整生态系统。 |
简单来说,提示工程和RAG都是上下文工程的重要组成部分或实现手段。上下文工程是一个更上层的、系统性的架构思想,它包含并统筹了优秀的提示设计、高效的RAG检索,还涵盖了记忆管理、工具调用编排、上下文压缩与隔离等更广泛的策略。
三、 上下文工程的核心价值:为何成为AI应用成败的关键
研究表明,优化上下文可以使AI应用效果提升40-70%,而无需改变模型本身。其核心价值主要体现在以下四个方面:
1. 根治“胡言乱语”,从根源上提升任务成功率与稳定性
大多数智能体任务的失败,根源往往不在于模型能力不足,而在于未能向模型提供恰到好处的上下文。模型无法“读心”,如果缺少关键信息、被无关信息干扰或工具使用不当,它就不可能做出正确判断。上下文工程通过系统性地确保模型在每一步都拥有“正确的信息和工具”,从根本上降低了失败风险。
- 价值体现:将AI应用的失败归因从“模型不行”转向“上下文供给不当”,提供了明确的优化方向。
- 样例:一个代码生成Agent经常写出不符合项目规范的代码。通过上下文工程,将项目的代码规范、常用设计模式、依赖库版本等作为“长期记忆”或“前置上下文”注入,其代码生成的一次通过率可显著提升。
2. 突破模型固有局限,释放其潜在能力
即使是最先进的模型,其知识也存在时效性、专业性和容量的边界。上下文工程通过集成外部知识(RAG)、注入长期记忆(用户偏好、项目历史)和提供专用工具(调用API、执行计算),极大地扩展了模型的能力边界。
- 价值体现:使模型能够处理训练数据之外的专业、实时、复杂的任务,标志着AI从依赖“记忆”的“知识时代”,迈向依赖“理解”和“行动”的“能力时代”。
- 样例:一个法律咨询Agent无法知晓最新颁布的法规。通过上下文工程集成RAG系统,在用户提问时实时检索最新的法律条文和判例库,并注入上下文,Agent就能给出基于最新法律的建议。
3. 显著优化成本与性能,对抗“上下文腐蚀”
无脑地将所有历史信息塞入上下文窗口,会导致Token消耗激增、成本上涨、响应延迟,甚至因超出窗口限制而直接报错。更严重的是,过长的、混杂的上下文会导致“上下文腐蚀”(Context Rot)或“上下文衰减”(Context rot),即随着上下文窗口中token数量的增加,模型准确回忆关键信息的能力会下降。
- 价值体现:通过“选择、压缩、隔离”等策略,主动管理上下文长度和质量,用尽可能少的高信号Token最大化产出效果,实现了成本与性能的最佳平衡。
- 样例:在长对话客服场景中,不是将整个对话历史都塞给模型,而是动态地总结之前的对话摘要,并只保留最近几轮和最关键的用户信息(如订单号),从而在有限的上下文窗口内维持对话连贯性,同时保持快速响应和低成本。
4. 实现个性化与连贯的智能体交互
通过精心设计的上下文管理系统,AI应用能够记住用户的历史交互、个人偏好和任务状态,从而提供高度个性化、连贯的多轮对话体验。
- 价值体现:使得AI从“一次性的问答机器”进化为“持续理解用户的智能伙伴”。
- 样例:一个音乐推荐智能体,能通过长期记忆记住用户喜欢的歌手和近期听歌记录,并在每次推荐时,将这些偏好与当前检索到的热门歌曲列表共同作为上下文,从而提供越来越精准的个性化推荐。
四、 核心实践样例:Claude Code 与 PRP 范式
搜索结果中提供了一个极具代表性的上下文工程实践案例:基于Claude Code的“可编程需求计划”范式。这完美诠释了上下文工程如何系统化地提升复杂任务完成率。
传统方式(提示工程):
用户给AI一个模糊指令:“帮我写一个爬虫,爬取某网站数据并存到数据库。” AI可能会生成代码,但很可能忽略项目规范、错误处理、数据库结构等细节,导致代码无法直接运行。
上下文工程方式(PRP范式):
- 搭建框架(CLAUDE.md):在项目根目录创建 CLAUDE.md 文件,定义AI的“公司规章制度”,如代码风格(缩进用空格)、必须包含的测试覆盖率、文档规范等。这相当于提供了系统提示和长期行为准则上下文。
- 撰写需求(INITIAL.md):不是简单一句话,而是撰写一份详细的“产品需求文档”,说明技术栈(Python + PostgreSQL)、目标网站、反爬策略、数据表结构、性能要求等。这提供了具体任务的知识型上下文。
- 提供示例(examples/):在 examples/ 文件夹中放置高质量的样例代码,如“正确的错误处理长什么样”、“如何调用数据库连接池”。这提供了少样本学习的引导型上下文。
- 生成与执行PRP:使用 /generate-prp 命令,让AI根据以上丰富的上下文,自动生成一份结构化的“可编程需求计划”文件。该文件会详细列出开发步骤、每个文件的功能、验证方法。然后使用 /execute-prp 命令,AI会严格按此蓝图编码,并边写边自查(运行测试、调试),直到所有验证通过。
价值体现:通过这套系统化的上下文供给,AI不再是盲目地生成代码片段,而是在一个完整的“开发环境”中,像一位接受了完整项目入职培训的工程师一样工作。实验证明,这种方法能让AI第一次就写出可用代码的概率提高10倍以上。这清晰地展示了上下文工程如何将模糊的指令,转化为可靠、可重复的高质量输出。
五、 总结
总而言之,上下文工程标志着AI应用开发范式的根本转变。开发者的重心正从寻找“那句完美的提示词”,转向系统性地设计“最优的信息供给系统”。在模型能力趋于同质化的未来,上下文工程的能力将成为AI应用的核心竞争优势。最好的AI应用不一定使用最先进的模型,但一定使用了最精心设计的上下文。它已从一门“艺术”转变为一门系统化的“工程”学科,是构建可靠、可扩展、高性能AI智能体系统的基石。
5.2 核心调整策略与最佳实践
上下文工程的核心目标,是在有限的“注意力预算”内,为模型动态地提供最相关、最高信噪比的信息。这并非简单的信息堆砌,而是一门需要精心设计、持续优化的“信息管理艺术”。其核心策略可归纳为四大类:筛选(Select)、压缩(Compress)、隔离(Isolate)和写入(Write)。
一、 筛选策略:精准注入“当前最相关”的信息
筛选是上下文工程的第一道防线,其核心思想是“只保留必要信息”,避免无关或冗余信息稀释模型的注意力。
- 动态工具装载与RAG:这是最经典的筛选策略。研究表明,当工具数量超过30个时,模型的选择困难会显著增加;超过100个时,几乎必然失败。因此,不应将所有工具描述都塞入上下文。最佳实践是基于任务进行动态工具推荐:先用一个轻量级模型分析用户查询,推理出所需工具的类型和数量,再通过语义搜索从工具库中精准筛选出最相关的子集。这不仅能提升准确性,还能带来显著的功耗和速度优势(分别可达18%和77%)。同样,在RAG中,也应精准筛选与当前问题最相关的文档片段,而非“全部塞入”。
- 信息过滤与修剪:在信息进入上下文之前或之后,主动进行清理。
- 过滤:在信息进入上下文前进行质量检测和权威性验证,阻止垃圾、错误或自相矛盾的信息进入,防止“上下文中毒”。
- 修剪:主动删除与当前任务无关的历史信息、冗余描述和过时数据。例如,可以设置时间窗口,只保留最近N轮对话;或使用语义相似度计算,移除与当前查询无关的内容。
二、 压缩策略:减少Token开销,保留关键信息
当筛选后信息依然庞大时,需要对其进行压缩,以更精炼的形式保留核心信息。
- 上下文总结:主动对长对话历史或文档进行摘要。这不仅是为了应对上下文窗口的长度限制,更是为了提升响应质量。研究发现,当上下文超过一定长度(如10万Token),智能体可能会过度依赖历史记录而“怀旧”,而不是生成新计划。定期总结可以将冗长的历史压缩为精炼的要点,让模型聚焦于当前任务。
- 结构化剪枝:使用专门的模型或工具(如Provence)对文档进行剪枝,根据当前问题移除冗余部分,保留率可能低至5%,却能保持关键信息不丢失。维护结构化的上下文版本(如字典形式)有助于这类操作,确保核心指令和目标始终被保留。
三、 隔离策略:拆分上下文空间,避免信息冲突
对于复杂任务,将所有信息混在一个上下文中会相互干扰。隔离策略通过创建独立的“工作空间”来解决此问题。
- 上下文隔离与多智能体并行:将大型任务分解为较小的、隔离的子任务,每个子任务拥有独立的上下文。这在研究类任务中尤其有效,可以并行探索不同方向,然后将最重要的信息汇总给主智能体。实践表明,多智能体系统的表现可以比单一智能体高出90%以上。这本质上是分而治之的思想,让每个智能体在纯净的上下文中专注解决一个子问题。
- 状态外部化与沙盒化:智能体天生会累积状态(工具输出、中间结果),这些状态不应全部占用宝贵的上下文窗口。最佳实践是将中间状态写入外部存储(如文件系统、数据库),在需要时再检索加载。这模仿了人类的工作方式:面对复杂任务时,会写下笔记、创建草稿,将认知负荷外部化。提供一个专门的“草稿本”工具,让智能体记录不污染主上下文的笔记,在特定场景下可带来高达54%的性能提升。
四、 写入策略:将信息“暂存”到上下文之外
写入策略与隔离策略相辅相成,核心是将不立即需要但未来可能用到的信息,持久化到上下文窗口之外。
- 长期记忆与检查点:利用外部存储(如向量数据库)构建智能体的长期记忆,存储跨越多次会话的重要经验、用户偏好或任务结果。在LangGraph等框架中,通过检查点(Checkpoint)机制持久化智能体的运行状态,支持任务的中断与恢复,以及跨会话的记忆延续。
- 结构化笔记(Agentic Memory):让智能体学会主动将关键信息(如任务目标、决策依据、待办事项)以结构化的格式(如待办清单、探索地图、策略记录)保存到外部。例如,在Anthropic让Claude玩《宝可梦》的实验中,智能体自主学会了创建待办列表和地图。当上下文重置后,它能通过读取自己的笔记无缝衔接之前的进度,完成长达数小时的复杂任务。
五、 最佳实践总结与黄金法则
综合以上策略,可以提炼出上下文工程的几条核心最佳实践:
- 结构化上下文管理:将上下文组织成清晰、结构化的格式(如使用XML标签或Markdown标题划分模块: <背景信息> 、 <指令> 、 <工具指南> 、 <输出说明> ),这便于进行剪枝、总结和隔离等操作。
- 主动监控与维护:不要设置后就不管。需要定期评估上下文质量,主动清理冗余和有害信息。监控Token使用趋势,在达到阈值前触发压缩或总结机制。
- 任务导向的优化组合:没有放之四海而皆准的策略。应根据具体任务类型(如研究分析、代码生成、客服对话)选择合适的策略组合。例如,研究任务适合“隔离+并行”,而长对话客服则更需要“总结+外部记忆”。
- 性能与质量的平衡:在响应质量和计算效率(成本、延迟)之间找到最佳平衡点。利用KV缓存优化是生产环境中至关重要的性能实践:保持提示前缀稳定、确保上下文只追加(避免修改历史)、标记缓存断点,缓存与非缓存的成本差异可达10倍。
- 拥抱“痛苦教训”,设计可进化架构:AI的进步往往来自计算能力的提升,而非复杂的结构设计。因此,架构设计要“留有余地”,避免过度结构化,以便快速适配模型能力的提升。要定期用更强的模型测试现有Agent,如果性能没有提升,说明当前的架构(如Agent的“框架”)已成为瓶颈,需要及时重构。
最终公式:高效上下文 = (相关信息 + 必要工具 - 无关内容) × 并行处理 ÷ 智能压缩。
上下文工程决定了智能体的表现上限。每个进入上下文的Token都必须“赚取其存在的理由”。通过系统地应用这些策略,可以构建出更高效、更稳定、更具扩展性的AI智能体系统。
5.3 应用场景与未来趋势
一、 典型应用场景:从“知识问答”到“智能伙伴”
上下文工程的价值在于,它将大模型从一个“博学但健忘的对话者”,转变为能够理解复杂背景、拥有持续记忆、并能利用外部工具和知识的“智能伙伴”。其应用已从简单的问答,深入到企业运营、研发、政务、个人办公等核心场景。
1. 企业级智能体与知识管理
这是当前上下文工程落地最成熟、价值最显著的领域。企业拥有海量、高价值的非结构化数据(文档、邮件、会议记录、代码库),但员工难以高效利用。上下文工程通过构建“企业记忆库”和“领域知识库”,让AI成为企业的“数字大脑”。
- 场景案例:
- 赛意信息的“善谋GPT”:它深度融合了企业在财税、人力、营销、供应链、研发与生产制造等领域的知识和最佳实践。通过上下文记忆、知识库索引、Prompt工程等技术,为企业提供数字员工(智能引导)、企业知识库(智能问答)、智能单据(智能辅助) 和AI自动报价等场景应用。例如,在报价场景中,系统能自动解析PCB工程图纸,生成材料清单并关联供应商系统,将原本需要数小时的工作缩短至几分钟。
- 用友的BIP 5平台:其核心AI方法论就是“上下文工程”。它通过构建“AI×数据×流程”的原生一体化架构,为AI提供完整的“企业上下文”。例如,员工只需说“今天下午和张三李四王五在我办公室开个会,讨论BIP 5发布的事”,AI就能自动识别参会人、检查日程、预订会议室,因为它天然知道每个人的权限、办公室位置和会议室标准。这背后是上下文工程将企业的组织架构、业务流程、数据权限等隐性知识,动态地注入到AI的推理过程中。
- 核心价值:将散落在各处的企业知识(Know-How)和流程(Workflow)系统化地注入AI,使其能像一位资深员工一样理解业务、执行任务,实现从“工具系统”到“智能伙伴”的进化。
2. 智能办公与内容创作
在政务、金融、法律等对内容准确性、规范性和安全性要求极高的领域,上下文工程能确保AI生成的内容既高效又合规。
- 场景案例:
- 博特智能的“博特妙笔”:这是国内首款政务内容安全生产平台。它依托“10亿权威语料”和千万级范文库,通过微小个体感知技术(提升内容多样性)、无损上下文拓展技术(支持20万字长文本连贯生成)和知识增强多模态审核体系(12大类上千个风险标签),为政务人员提供公文写作辅助。应用数据显示,其撰稿效率提升3倍,错误率降低90%,将原本需要1-2天完成的总结材料缩短至3分钟内生成初稿。
- 通用办公场景:上下文工程可以构建个人或团队的“写作助手”,它不仅能根据过往文档风格生成新内容,还能自动调用审核工具检查合规性,并引用最新的数据报告作为论据。
- 核心价值:在保证安全、合规的前提下,极大解放文案工作者的生产力,实现“保质、保量、保安全”的自动化内容生产。
3. 软件研发与代码生成
软件开发是天然适合上下文工程的场景,因为代码本身具有极强的结构性和上下文依赖性(如项目架构、API文档、历史提交记录)。
- 场景案例:
- 众安保险的DevPilot:这是一个全栈代码助手开源解决方案。其核心优势在于工程级的上下文能力,能深入理解开发者在编码过程中的需求,提供精准的代码补全和重构建议。它支持灵活的模型切换,并提供了智能搜索、代码解释、单元测试、代码审查等丰富功能。
- 阿里云通义灵码:作为“AI程序员”,它引入了多文件代码修改能力和批量生成单元测试等功能。其底层模型能结合智能体技术,通过文件、图片、全工程代码检索等上下文,更好地理解任务意图,实现从0到1的业务需求开发、问题修复等复杂编码任务。过去需要前后端工程师配合半天完成的前端页面,现在一名程序员使用通义灵码仅需10分钟即可完成。
- 核心价值:将开发者从重复性、模式化的编码工作中解放出来,使其能专注于更具创造性的架构设计和业务逻辑,同时通过代码审查、测试生成等功能提升代码质量和团队协作效率。
4. 复杂任务自动化与多智能体协作
对于需要多步骤规划、动态调整和调用多种外部工具的复杂任务,上下文工程是构建可靠智能体(Agent)的基石。
- 场景案例:
- 旅游规划智能体:如您之前架构中所设计,一个成熟的旅游规划Agent需要整合用户偏好、实时天气、航班酒店API、景点信息、预算约束等多源上下文,并进行多轮规划和动态调整。这完全依赖于一个强大的上下文管理系统来协调这些信息流。
- 科研与材料研发:在药物研发、新材料发现等领域,智能体需要整合海量的论文数据库、实验数据、分子结构库作为上下文,进行成分筛选、性能预测与实验优化,形成“AI提出假设-实验验证-反馈优化”的闭环迭代,显著缩短研发周期。
- 核心价值:使AI能够像人类专家一样,进行多步骤推理、利用工具、并从历史经验中学习,完成过去只有人类才能处理的开放式、长周期复杂任务。
二、 未来发展趋势:从“工程优化”到“智能原生”
随着技术成熟和认知深入,上下文工程正从一项“优化技术”演变为构建下一代AI应用的核心设计哲学。其未来发展将呈现以下趋势:
1. 从“外挂式AI”到“智能原生(AI-Native)”
当前许多企业应用仍是在现有系统上“打补丁”式地集成AI功能(即“AI+”模式)。未来的趋势是 “智能原生” ,即从系统设计之初就将AI作为底层逻辑与能力中枢,驱动从技术架构、业务流程到组织形态的全方位重塑。
- 具体体现:
- 交互原生:人机交互从基于图形界面(GUI)的点击指令,彻底转向基于自然语言和意图理解的对话式、任务式交互。未来的企业软件可能就是一个“对话框”。
- 进化原生:应用具备自主感知、决策与进化能力。它在与用户和环境的交互中不断吸收新数据、新知识,通过自动化反馈闭环优化自身,实现能力的持续进化,越用越“懂”用户。
- 架构原生:如用友所实践的“原生一体化”,AI、数据、流程从一开始就是一体设计的,权限、业务逻辑等上下文天然存在于系统中,而非通过复杂的API嫁接。
2. 上下文管理的自动化与智能化
目前上下文工程(如RAG、记忆管理)的很多环节仍需人工设计和调优。未来,上下文管理本身将变得更加自动化和智能化。
- 具体体现:
- 自适应上下文组装:系统能根据任务类型、用户历史、实时反馈,自动决定检索哪些知识、加载哪些记忆、调用哪些工具,并动态优化上下文的组织和呈现顺序。
- 上下文质量自评估与净化:AI能够自我评估当前上下文的有效性,自动识别并过滤掉矛盾、过时或低质量的信息,对抗“上下文污染”和“幻觉”。
- 记忆的主动总结与抽象:不再被动存储所有交互记录,而是能像人类一样,主动对经历进行总结、归纳,形成高层次的“经验”或“模式”,存储在长期记忆中,用于举一反三。
3. 从单智能体到多智能体社会的协同上下文
当任务复杂到单个智能体无法处理时,需要多个智能体分工协作。这就产生了智能体间的上下文共享、传递与同步问题。
- 具体体现:
- 标准化通信协议:类似A2A(Agent-to-Agent)协议的出现,将定义智能体间如何发现彼此、交换任务上下文、同步状态,就像互联网的TCP/IP协议一样,为多智能体协作奠定基础[^背景]。
- 共享工作记忆与黑板机制:多个智能体围绕一个共同任务工作时,需要一个共享的“上下文空间”(如知识图谱、向量数据库),来存放公共目标、共享事实、中间结果和待解决问题,避免信息孤岛和重复劳动。
- 上下文感知的调度与编排:上层调度器(Orchestrator)需要理解每个子任务的上下文依赖关系,进行智能的任务分解、分配和结果整合,确保整体工作流的一致性。
4. 多模态与具身上下文的融合
未来的上下文不再局限于文本。智能体需要理解并整合视觉、听觉、传感器数据等多模态信息,甚至在物理世界中与环境交互(具身智能)。
- 具体体现:
- 多模态RAG:不仅能检索文本资料,还能根据图片、视频、音频内容进行搜索和推理。例如,维修机器人看到设备故障图片,能自动检索维修手册和视频教程。
- 环境上下文感知:对于机器人、自动驾驶汽车等具身智能体,其上下文包括实时传感器数据(激光雷达、摄像头)、地图信息、交通规则等。上下文工程需要将这些异构信息融合,构建对物理世界的统一理解。
- 新型交互终端:如Meta Ray-Ban智能眼镜,通过自然语言让AI Agent直接解析用户视觉场景中的需求(如“前面那栋建筑是什么风格?”),并调用服务完成任务,硬件成为智能服务的直接触点。
5. 安全、伦理与可控性成为核心挑战
随着上下文工程让AI能力越来越强、自主性越来越高,其带来的风险也日益凸显。
- 具体体现:
- Agent的不可预测性:具备复杂上下文和工具调用能力的Agent,其行为链可能产生难以预料的后果。
- 价值对齐的复杂性:如何确保在不同文化、不同业务场景的复杂上下文中,AI的行为始终符合人类价值观和伦理规范,是一个巨大挑战。
- 数据隐私与安全:企业将核心知识和流程作为上下文注入AI,如何防止敏感信息泄露、被恶意诱导或用于训练第三方模型,是必须解决的前提。
- 可解释性与审计追踪:需要建立机制,能够追溯AI的每一个决策是基于哪些上下文信息做出的,尤其是当出现错误或争议时,必须能够进行审计和归因。
总结而言,上下文工程已从一项提升模型表现的“技巧”,演进为构建下一代智能系统的“核心架构”。 它的应用正从点状的场景优化,走向面状的业务重塑与生态构建。未来,衡量一个AI系统先进性的关键,或许不再是其底层模型的参数规模,而是其上下文工程的成熟度——即它如何高效、精准、安全地组织、利用和演化信息,从而在复杂真实世界中可靠地完成任务。这要求开发者、企业乃至整个社会,在追求智能效率的同时,必须同步构建与之匹配的治理框架和工程规范。
第六章:Agent智能体应用企业级项目大实战
6.1 企业级HR智能体平台设计与实现
一、 企业级HR智能体平台的整体架构设计
基于对当前HR智能体平台发展趋势的分析,一个成熟的企业级HR智能体平台应采用**“基座模型+智能体平台+场景应用”**的三层架构体系,实现从技术基座到业务应用的全栈智能化。
三层架构体系
(一)基座模型层:多模型融合与推理引擎
企业级HR智能体平台需要强大的AI能力支撑,采用混合模型架构是当前主流选择。利唐i人事和易路iBuilder平台都采用了DeepSeek R1/V3等推理模型作为技术基座,同时支持通用大模型(如GPT-4)与垂直推理模型的灵活切换。
- 通用模型处理标准化交互:处理员工答疑、政策咨询等通用性较强的场景
- 垂直模型保障专业场景合规性:如劳动法条款解析、薪酬计算等需要高度专业性和合规性的场景
- 动态模型兼容架构:通过混合架构平衡效率与风险,确保AI智能体的决策和行为符合企业的价值观和社会责任要求
(二)平台工具层:零代码构建与企业级知识库
这一层是HR智能体平台的核心能力层,提供智能体构建、管理和优化的工具集。
- 零代码智能体工厂:通过可视化界面拖拽HR业务流程,用户可在10分钟内生成招聘助理、劳动合同专员等智能体,实现人力资源管理的自动化与智能化。易路iBuilder平台支持通过预构建的技能库进行快速组装,还能跨系统或工作流程采取行动。
- HR知识引擎:预置劳动法、薪酬制度、岗位画像等结构化知识库,并动态学习企业历史工单与非结构化文档(如员工手册),确保智能体决策的合规性与精准性。平台构建了基于角色权限的多维知识库体系,支持按部门、岗位、职级设置知识访问权限。
(三)场景应用层:全生命周期智能服务
这是直接面向HR业务人员和员工的应用层,提供覆盖员工全生命周期的智能服务。
- 招聘智能体:自动解析职位描述(JD)、匹配简历、安排面试,招聘周期缩短70%。易路iBuilder的招聘数字助理不仅大量事务性工作交由AI完成,且无需通过猎头即可根据需求自动全网多渠道搜寻、匹配合适人才。
- 绩效助手:实时分析员工OKR/KPI数据,自动生成改进建议与培训计划,优化管理流程。
- 员工服务机器人:7×24小时解答社保、考勤等问题,员工满意度提升90%。
二、 核心功能模块设计与实现
智能招聘模块:从“人盯流程”到“流程自驱”
智能招聘模块通过AI技术重构传统招聘流程,实现从“人盯流程”到“流程自驱”的转变。
简历智能解析与匹配
- 多格式简历解析:集成OCR、语音识别、图像解析等技术,可处理word、pdf、excel、视频等多格式文件
- 智能人岗匹配:基于DeepSeek的自然语言处理(NLP)、知识推理与多维度对比能力,实现人才与岗位的智能匹配
- 全网多渠道寻才:根据职位描述智能搜索内部人才库、外部招聘网站,寻找优质候选人
AI面试与评估系统
- AI视频面试官:通过自然语言对话、语音识别、微表情分析评估候选人能力,结合岗位画像生成匹配报告,使招聘效率提升50%
- 简历对比助手:智能解析简历并输出候选人优劣势分析报告,结合候选人CV和面试小结,智能生成候选人评分与推荐报告
- 招聘趋势分析师:智能分析友商岗位招聘情况、招聘量及招聘薪酬趋势等,为企业定岗定薪、快速招募优质人才提供参考
员工服务模块:7×24小时智能自助服务
员工服务模块构建全天候对话式自助服务平台,实现“让管理服务随时在线”。
多模态智能服务平台
- 自然语言交互:员工通过自然语言对话、语音指令等方式,自助完成90%以上的高频事务处理
- 动态知识图谱:实时解析劳动法新规、个税政策、企业福利等复杂条款,支持“政策咨询—流程办理—结果反馈”的闭环服务
- 个性化服务:根据员工画像(如职级、绩效、兴趣)提供定制化培训建议、福利推荐或职业发展路径规划
自动化流程处理
- 入职自动化:候选人扫描身份证后,系统自动提取信息并比对公安数据库,同步生成电子合同;AI助手通过多轮对话引导员工完善个人信息
- 离职管理自动化:当员工提交离职申请,智能体即刻触发跨部门流程——自动生成工作交接清单、核算未休年假折现、冻结系统权限,并实时提醒财务部门结算薪资
- 智能提单与审批:基于AI大模型与动态流程引擎的深度协同,构建覆盖“选、用、育、留”全生命周期的智能体作战集群
组织发展模块:从“成本中心”到“战略智脑”
组织发展模块通过数据驱动分析,帮助HR从“事务型HR”向“战略型HR”转型。
人才盘点与继任规划
- 人才画像构建:整合员工能力、行为、潜力数据,智能生成多维人才画像,并基于需求自动筛选、推荐适配人才
- 人才发现与横向对比:支持用户自由搜索、标签找人、以岗找人、以人找人、项目找人,并通过算法对人才库进行多维度交叉分析
- 继任计划管理:通过机器学习预测员工流失风险、培训需求或高潜力人才,提前干预以降低风险
组织效能分析
- 数据深度解读:识别业务瓶颈(如离职率异常、薪酬结构失衡)并归因。比如,某企业发现某大区离职率骤增,智能体穿透分析指出根本原因是“晋升周期比同行长6个月”,而非表面上的薪资问题
- 策略自动生成:输出可落地的改进建议(如组织架构优化方案、绩效激励调整策略),推动管理决策科学化
- 预测性洞察能力:通过智能建模生成组织效能、人才储备、成本优化等多维度分析报告,精准识别人力管理痛点,为战略规划提供量化依据
三、 技术实现要点与关键技术
多Agent协作架构设计
企业级HR智能体平台需要构建多Agent协同工作系统,不同HR功能由专门的Agent负责。
分层决策架构
借鉴人类组织的管理架构,采用分层决策Agent将智能体的决策过程进行层级划分:
- 战略层(高层):由最强大的模型担任,负责宏观目标理解、任务总体规划、资源分配和风险评估
- 战术层(中层):接收战略指令,并将其分解为具体的、可执行的子任务序列
- 执行层(底层):由多个专精于特定领域的“专家Agent”构成,如招聘Agent、薪酬Agent、绩效Agent等
动态路由机制
平台内部维护一个“专家池”,每个专家都是针对特定领域进行微调或拥有特定工具集的子Agent。其核心是一个**路由(Router)**机制,当接收到用户请求时,路由Agent首先对输入进行分类,判断其属于哪个领域,然后将其引导至最合适的专家Agent进行处理。
企业级知识图谱构建
构建企业人才知识图谱,连接员工、技能、项目、绩效等实体,为智能决策提供支持。
知识图谱架构
- 实体识别与抽取:从非结构化文档(简历、绩效评估、项目报告)中自动抽取实体和关系
- 动态知识更新:系统具备自主学习能力,可通过聊天记录、网络更新自动迭代知识,无需人工维护
- 权限分级管理:基于角色权限的多维知识库体系,支持按部门、岗位、职级设置知识访问权限
应用场景
- 人才智能检索:基于知识图谱实现精准人才匹配和推荐
- 用工风险评估:通过关联分析识别潜在的用工风险
- 政策问询:实时解析劳动法新规、个税政策等复杂条款
隐私保护与合规性保障
数据安全与隐私保护
- 权限隔离与数据加密:通过权限分级、数据加密等技术保护敏感员工信息,降低泄露风险
- 可信数据空间方案:提供国家级专属DeepSeek算力,通过构建共享信任机制为企业提供安全可信的数据流通基础设施及使用环境
- 私有化部署支持:支持私有云算力部署,确保企业数据安全与业务定制化需求
合规性检查机制
- 自动合规审查:通过实时监控招聘、薪酬等流程是否符合劳动法规,避免法律纠纷
- 智能校验规则:薪酬监管平台深度适配“三全”监管要求,通过全流程穿透式管理和智能校验规则,确保薪酬数据精准合规
- 多国本地化合规:对于出海企业,预置多国本地化合规模板,实现海外业务开箱即用
四、 部署与集成策略
多种接入模式,按需部署
为满足不同企业的需求,平台应提供灵活的接入模式:
MCP插槽式接入
针对AI战略成熟、支持度高,同时IT基础设施完善、数据安全要求高的组织,实现即插即用、调取快捷的同时,保障安全性、避免本地部署等繁琐。
基于平台建立AI智慧门户
针对HR部门推进需求紧急、但AI专业知识储备少、部署响应弱的情况,该方案可快速满足HR简单配置即可使用的短期目标、同时支持后期二次开发等长期规划。
Agent应用批量/单点接入
- 批量接入:针对AI战略推进积极、但HR部门AI专业知识及人才不足、IT基础设施水平及AI实施经验少的情况,可直接按需批量接入多个Agent应用
- 单点接入:针对AI战略保守、希望小范围先行启动获取成功经验的,或内部AI项目起步早、有自研要求但未有成效的,希望低成本学习外部成熟产品经验的,建议针对性选择单点接入
系统集成与生态建设
与现有系统无缝集成
平台需要与企业内部的ERP、CRM等系统无缝集成,通过标准化通信机制(如MCP)与不同API和数据源无缝交互,替换碎片化Agent代码集成。
开放生态建设
通过AIOS平台,不仅为企业提供了AI智能体的应用工具,还构建了一个开放、共享的AI智能体生态,促进了企业间的技术交流和合作创新。平台兼容DeepSeek、Qwen、ChatGPT等多模型,允许企业根据需求灵活选择算力资源,避免技术锁定。
五、 实施路径与价值评估
分阶段实施路径
第一阶段:基础能力建设(1-3个月)
- 平台部署与集成:完成基础平台部署,与现有HR系统集成
- 核心Agent上线:优先部署员工服务机器人、政策咨询助手等高频应用
- 知识库初步构建:导入企业基本政策文档、员工手册等
第二阶段:核心场景深化(4-6个月)
- 招聘流程智能化:实现简历筛选、面试安排等环节的自动化
- 绩效管理优化:部署绩效分析助手,提供数据驱动的改进建议
- 个性化服务扩展:基于员工画像提供定制化服务
第三阶段:全面智能化(7-12个月)
- 全流程覆盖:实现从招聘、入职、发展到离职的全流程智能化
- 预测性分析:部署人才流失预测、培训需求预测等高级功能
- 战略决策支持:为高层提供组织效能、人才战略等数据洞察
价值评估与ROI分析
效率提升价值
- 招聘效率:招聘周期缩短70%,招聘成本大幅降低
- 事务处理效率:HR重复性工作处理效率提升50%以上
- 员工服务响应:7×24小时即时响应,减少员工等待时间
决策质量提升
- 数据驱动决策:从“经验驱动”到“数据+推理双驱动”的人才决策跨越
- 精准人才匹配:AI推荐的高匹配度使招聘效率、入职成功率大幅提升
- 风险预警能力:通过机器学习预测员工流失风险,提前干预以降低风险
成本节约与体验提升
- 人力成本降低:某制造业企业引入“人力成本分析师”后,年度人力成本降低8%
- 员工满意度提升:员工服务机器人使员工满意度提升90%
- 管理体验改善:将HR从繁琐事务中解放,使其专注于战略工作(如组织设计、文化构建、人才梯队建设)
六、 未来发展趋势与挑战
技术发展趋势
从“单点工具”到“系统工程”
AI应用正从“单点工具”迈向“系统工程”,通过“基座+平台+应用”的立体化架构,打破传统AI解决方案“烟囱式建设”的困局,让企业能够像搭积木般快速构建专属智能体矩阵。
从“提升效率”到“提升有效性”
AI赋能正从提升效率向提升有效性升级,基于数据驱动分析,帮助整合员工绩效、满意度、离职率等数据,生成可视化报告,辅助HR制定精准策略。
人机协同新范式
未来的企业可能会形成“人类员工+数字员工”的双workforce体系:人类专注于创意、战略等高阶任务,数字员工负责流程性、重复性工作。而智能体平台将成为连接两者的“数字神经系统”。
实施挑战与应对策略
数据安全与隐私保护挑战
- 挑战:HR数据涉及大量员工隐私信息,数据安全要求极高
- 应对策略:采用私有化部署、数据加密、权限分级等多重安全保障措施
组织变革与文化适应挑战
- 挑战:HR部门从“成本中心”向“战略智能中心”转型需要组织和文化变革
- 应对策略:分阶段实施,先易后难,通过成功案例推动组织接受度
技术集成与系统兼容性挑战
- 挑战:与现有HR系统、ERP系统等的集成复杂度高
- 应对策略:采用标准化接口和协议,提供多种集成方案选择
长期战略价值
企业级HR智能体平台不仅是工具集合,更是企业数字化转型的“智能中枢”。它通过知识驱动、流程重构、人机共融,帮助企业将AI Agent从“执行者”升级为“战略伙伴”,最终实现“人类定义价值,机器放大价值”的新工作范式。
站在产业变革的临界点,HR智能体平台的价值早已超越产品本身。它既是企业智能化升级的“工具箱”,更是开启智能体经济时代的“钥匙”。当AI从“奢侈品”变为“必需品”,能够率先掌握这把钥匙的企业,终将在新一轮产业竞争中占据先机。
6.2 DeepResearch实战智能体开发
一、DeepResearch智能体核心架构设计
系统架构概览
基于搜索结果中的多个实战案例,一个成熟的DeepResearch智能体应采用分层架构设计,将复杂的研究任务分解为可管理的模块化组件。核心架构包含以下关键层次:
数据流架构:
用户输入 → 任务解析 → 多源检索 → 信息处理 → 分析推理 → 报告生成 → 输出
技术栈架构:
- 编排层:LangGraph/LangChain(工作流管理)
- 模型层:DeepSeek-R1/DeepSeek-V3(推理与生成)
- 工具层:Tavily/SearXNG(网络搜索)、学术API(论文检索)
- 存储层:向量数据库(知识存储)、文件系统(中间结果)
- 评估层:FINDER基准(质量评估)
核心组件设计
状态管理系统
采用LangGraph的StateGraph管理研究过程的状态流转,定义结构化状态对象:
from typing import TypedDict, List, Dict, Optional, Annotated
from datetime import datetime
import operator
class ResearchState(TypedDict):
"""深度研究智能体的全局状态容器"""
# 输入与配置
research_query: str # 原始研究问题
research_depth: int # 研究深度级别(1-3)
max_iterations: int # 最大迭代次数
# 规划阶段
research_plan: List[Dict] # 研究计划大纲
search_queries: List[str] # 生成的搜索查询
subtopics: List[str] # 分解的子主题
# 收集阶段
raw_sources: List[Dict] # 原始检索结果
processed_content: List[Dict] # 处理后的内容
source_metadata: Dict[str, Dict] # 来源元数据(权威性、时效性)
# 分析阶段
key_findings: List[str] # 关键发现
conflicting_evidence: List[Dict] # 矛盾证据
knowledge_gaps: List[str] # 知识缺口
# 生成阶段
report_structure: Dict # 报告结构
draft_sections: Dict[str, str] # 草稿章节
final_report: str # 最终报告
# 控制状态
current_step: str # 当前执行步骤
iteration_count: int # 当前迭代次数
validation_results: List[Dict] # 验证结果
多智能体协作架构
借鉴OPPO FINDER基准的发现,采用专业化分工的多智能体系统:
- 规划智能体(Planner Agent)
- 负责问题分解与任务规划
- 生成研究大纲和搜索策略
- 评估研究复杂度和资源需求
- 检索智能体(Retriever Agent)
- 多源信息检索(学术数据库、新闻、行业报告)
- 信息质量评估与过滤
- 去重与相关性排序
- 分析智能体(Analyst Agent)
- 信息提取与摘要生成
- 矛盾检测与证据评估
- 趋势分析与模式识别
- 验证智能体(Verifier Agent)
- 事实核查与来源验证
- 逻辑一致性检查
- 偏见检测与平衡
- 合成智能体(Synthesizer Agent)
- 报告结构设计
- 内容整合与连贯性检查
- 格式与风格适配
二、关键技术实现细节
深度研究工作流引擎
基于LangGraph构建的有状态工作流,支持迭代式研究和动态调整:
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint import MemorySaver
def create_research_workflow():
"""创建深度研究智能体工作流"""
# 初始化状态图
workflow = StateGraph(ResearchState)
# 添加节点
workflow.add_node("parse_query", parse_research_query)
workflow.add_node("generate_plan", generate_research_plan)
workflow.add_node("execute_search", execute_multi_source_search)
workflow.add_node("analyze_content", analyze_and_extract_insights)
workflow.add_node("verify_findings", verify_and_validate)
workflow.add_node("synthesize_report", synthesize_final_report)
workflow.add_node("reflect_and_iterate", reflect_and_decide_next)
# 定义边连接
workflow.add_edge(START, "parse_query")
workflow.add_edge("parse_query", "generate_plan")
workflow.add_edge("generate_plan", "execute_search")
workflow.add_edge("execute_search", "analyze_content")
workflow.add_edge("analyze_content", "verify_findings")
# 条件边:基于验证结果决定是否继续研究
def should_continue_research(state: ResearchState):
"""决定是否需要进行下一轮研究迭代"""
gaps = state.get("knowledge_gaps", [])
conflicts = state.get("conflicting_evidence", [])
iteration = state.get("iteration_count", 0)
max_iter = state.get("max_iterations", 3)
if iteration >= max_iter:
return "generate_report"
elif len(gaps) > 2 or len(conflicts) > 1:
return "iterate_research"
else:
return "generate_report"
workflow.add_conditional_edges(
"verify_findings",
should_continue_research,
{
"iterate_research": "reflect_and_iterate",
"generate_report": "synthesize_report"
}
)
workflow.add_edge("reflect_and_iterate", "execute_search")
workflow.add_edge("synthesize_report", END)
# 添加检查点支持中断恢复
checkpointer = MemorySaver()
return workflow.compile(checkpointer=checkpointer)
多源检索与信息处理
智能检索策略
class MultiSourceRetriever:
"""多源信息检索器,支持不同信息源的智能选择"""
def __init__(self, config: Dict):
self.sources = {
"academic": AcademicSearchClient(config["academic_api_key"]),
"news": NewsAPIClient(config["news_api_key"]),
"web": TavilySearchClient(config["tavily_api_key"]),
"reports": IndustryReportClient(config["report_api_key"])
}
self.llm = init_chat_model("deepseek-chat")
async def retrieve(self, query: str, context: Dict) -> List[Dict]:
"""智能选择信息源并执行检索"""
# 1. 分析查询类型,选择合适的信息源
source_analysis = await self.analyze_query_type(query, context)
selected_sources = source_analysis["recommended_sources"]
# 2. 并行执行检索
tasks = []
for source_name in selected_sources:
if source_name in self.sources:
task = self._retrieve_from_source(
self.sources[source_name],
query,
context
)
tasks.append(task)
# 3. 收集并合并结果
all_results = await asyncio.gather(*tasks, return_exceptions=True)
# 4. 去重、排序和过滤
processed_results = self._process_and_rank_results(all_results)
return processed_results
async def analyze_query_type(self, query: str, context: Dict) -> Dict:
"""分析查询类型,推荐合适的信息源"""
prompt = f"""
分析以下研究查询的类型,并推荐最合适的信息源:
查询:{query}
研究上下文:{context.get('research_context', '')}
请从以下信息源中选择(可多选):
- academic: 学术论文、研究文献
- news: 新闻、时事报道
- web: 一般网页信息
- reports: 行业报告、白皮书
返回JSON格式:{{"query_type": "类型描述", "recommended_sources": ["source1", "source2"]}}
"""
response = await self.llm.ainvoke(prompt)
return json.loads(response.content)
信息质量评估
class InformationQualityAssessor:
"""信息质量评估器,基于DEFT分类法"""
FAILURE_MODES = {
"reasoning": ["FUR", "LAD", "LAS", "RPS"],
"retrieval": ["IIA", "IHD", "IIF", "IRM", "VMF"],
"generation": ["RCP", "SOD", "CSD", "DAR", "SCF"]
}
def assess_source_quality(self, source: Dict) -> Dict:
"""评估单个信息源的质量"""
quality_score = 0
issues = []
# 1. 权威性评估
if not self._check_authority(source):
issues.append({"type": "IRM", "description": "信息来源权威性不足"})
quality_score -= 20
# 2. 时效性评估
if not self._check_recency(source):
issues.append({"type": "IIA", "description": "信息可能已过时"})
quality_score -= 15
# 3. 相关性评估
relevance = self._calculate_relevance(source)
if relevance < 0.6:
issues.append({"type": "IHD", "description": "信息相关性不足"})
quality_score -= 10
# 4. 一致性检查(跨源验证)
consistency_score = self._check_consistency(source)
if consistency_score < 0.7:
issues.append({"type": "IIF", "description": "信息与其他来源存在矛盾"})
quality_score -= 25
return {
"quality_score": max(0, quality_score + 50), # 基础分50
"issues": issues,
"overall_rating": self._score_to_rating(quality_score)
}
深度分析与洞察提取
多角度分析引擎
class MultiPerspectiveAnalyzer:
"""多角度分析引擎,避免分析局限"""
PERSPECTIVES = [
"technical", # 技术角度
"business", # 商业角度
"market", # 市场角度
"user", # 用户角度
"competitive", # 竞争角度
"regulatory", # 监管角度
"ethical", # 伦理角度
"future" # 未来趋势角度
]
async def analyze_from_all_perspectives(self, content: List[Dict], query: str) -> Dict:
"""从多个角度分析内容"""
analyses = {}
for perspective in self.PERSPECTIVES:
analysis = await self._analyze_from_perspective(content, query, perspective)
analyses[perspective] = {
"key_insights": analysis["insights"],
"evidence": analysis["evidence"],
"confidence": analysis["confidence"],
"gaps": analysis["knowledge_gaps"]
}
# 综合所有角度的分析
integrated_analysis = self._integrate_perspectives(analyses)
return {
"perspective_analyses": analyses,
"integrated_analysis": integrated_analysis,
"conflicting_viewpoints": self._identify_conflicts(analyses),
"recommended_focus_areas": self._prioritize_focus(analyses)
}
证据链构建与验证
class EvidenceChainBuilder:
"""证据链构建器,确保结论的可追溯性"""
def build_evidence_chain(self, claim: str, sources: List[Dict]) -> Dict:
"""为特定主张构建证据链"""
evidence_chain = {
"claim": claim,
"supporting_evidence": [],
"contradicting_evidence": [],
"neutral_evidence": [],
"strength_score": 0,
"confidence_level": "low" # low, medium, high
}
for source in sources:
evidence_type = self._classify_evidence_for_claim(source, claim)
if evidence_type == "supporting":
evidence_chain["supporting_evidence"].append({
"source": source["metadata"],
"content": source["content"],
"relevance_score": self._calculate_relevance(source, claim),
"quality_score": source.get("quality_score", 0)
})
elif evidence_type == "contradicting":
evidence_chain["contradicting_evidence"].append({
"source": source["metadata"],
"content": source["content"],
"contradiction_type": self._identify_contradiction_type(source, claim)
})
else:
evidence_chain["neutral_evidence"].append({
"source": source["metadata"],
"content": source["content"]
})
# 计算证据强度
evidence_chain["strength_score"] = self._calculate_strength_score(evidence_chain)
evidence_chain["confidence_level"] = self._determine_confidence(evidence_chain)
return evidence_chain
def validate_evidence_chain(self, chain: Dict) -> Dict:
"""验证证据链的完整性和可靠性"""
validation_results = {
"completeness": self._check_completeness(chain),
"consistency": self._check_internal_consistency(chain),
"source_diversity": self._check_source_diversity(chain),
"temporal_coverage": self._check_temporal_coverage(chain),
"authority_coverage": self._check_authority_coverage(chain),
"overall_validity": "待评估"
}
# 综合评估
if (validation_results["completeness"] >= 0.8 and
validation_results["consistency"] >= 0.9 and
validation_results["source_diversity"] >= 3):
validation_results["overall_validity"] = "高"
elif (validation_results["completeness"] >= 0.6 and
validation_results["consistency"] >= 0.7):
validation_results["overall_validity"] = "中"
else:
validation_results["overall_validity"] = "低"
return validation_results
三、企业级部署与优化策略
性能优化与成本控制
智能缓存策略
class IntelligentCacheManager:
"""智能缓存管理器,减少重复计算和API调用"""
def __init__(self, redis_client, vector_store):
self.redis = redis_client
self.vector_store = vector_store
self.query_cache_ttl = 3600 # 1小时
self.result_cache_ttl = 86400 # 24小时
async def get_cached_result(self, query: str, context: Dict) -> Optional[Dict]:
"""获取缓存的研究结果"""
cache_key = self._generate_cache_key(query, context)
# 1. 检查Redis缓存
cached = await self.redis.get(cache_key)
if cached:
return json.loads(cached)
# 2. 检查语义相似缓存
similar_results = await self._find_similar_cached_queries(query)
if similar_results:
# 使用最相似的结果作为基础
base_result = similar_results
# 进行差异分析,只计算差异部分
diff_analysis = await self._analyze_differences(query, base_result["original_query"])
if diff_analysis["similarity"] > 0.8:
return await self._adapt_cached_result(base_result, diff_analysis)
return None
async def cache_result(self, query: str, context: Dict, result: Dict):
"""缓存研究结果"""
cache_key = self._generate_cache_key(query, context)
# 存储完整结果
await self.redis.setex(
cache_key,
self.result_cache_ttl,
json.dumps(result)
)
# 同时存储向量表示用于相似性搜索
await self.vector_store.add_embedding(
query,
result["summary_embedding"]
)
成本感知的任务调度
class CostAwareScheduler:
"""成本感知的任务调度器,优化API使用"""
COST_CONFIG = {
"deepseek-r1": {"tokens_per_dollar": 1000000, "latency_ms": 500},
"deepseek-chat": {"tokens_per_dollar": 2000000, "latency_ms": 200},
"gpt-4": {"tokens_per_dollar": 500000, "latency_ms": 300},
"claude-3": {"tokens_per_dollar": 700000, "latency_ms": 400}
}
def schedule_task(self, task: Dict, budget_constraints: Dict) -> Dict:
"""根据任务特性和预算约束调度任务"""
task_complexity = self._estimate_complexity(task)
urgency = task.get("urgency", "normal")
quality_requirement = task.get("quality_requirement", "medium")
# 选择最合适的模型
selected_model = self._select_optimal_model(
task_complexity,
quality_requirement,
budget_constraints
)
# 优化提示词以减少token使用
optimized_prompt = self._optimize_prompt_for_cost(
task["prompt"],
selected_model,
budget_constraints
)
# 决定是否使用缓存或简化处理
use_caching = budget_constraints.get("use_caching", True)
if use_caching and self._is_cacheable_task(task):
task["use_cached_results"] = True
return {
"model": selected_model,
"optimized_prompt": optimized_prompt,
"max_tokens": self._calculate_max_tokens(budget_constraints),
"temperature": self._adjust_temperature_for_cost(quality_requirement),
"estimated_cost": self._estimate_cost(task_complexity, selected_model),
"estimated_latency": self._estimate_latency(task_complexity, selected_model)
}
可观测性与监控系统
全面监控指标
class ResearchAgentMonitor:
"""深度研究智能体监控系统"""
METRICS = {
"performance": [
"total_research_time",
"sources_retrieved",
"iterations_completed",
"token_usage",
"api_calls"
],
"quality": [
"source_quality_score",
"evidence_coverage",
"argument_strength",
"report_coherence",
"factual_accuracy"
],
"cost": [
"total_cost_usd",
"cost_per_source",
"cost_per_insight",
"cost_effectiveness"
],
"reliability": [
"error_rate",
"retry_count",
"timeout_rate",
"success_rate"
]
}
async def track_research_session(self, session_id: str, state: ResearchState):
"""跟踪研究会话的完整过程"""
metrics = {
"session_id": session_id,
"start_time": datetime.now(),
"initial_query": state["research_query"],
"steps_completed": []
}
# 记录每个步骤的详细指标
for step in ["planning", "retrieval", "analysis", "synthesis"]:
step_metrics = await self._collect_step_metrics(state, step)
metrics["steps_completed"].append({
"step": step,
"metrics": step_metrics,
"timestamp": datetime.now()
})
# 计算总体质量分数
metrics["overall_quality_score"] = self._calculate_quality_score(metrics)
# 存储到监控数据库
await self._store_metrics(metrics)
return metrics
def generate_performance_report(self, metrics: Dict) -> str:
"""生成性能报告"""
report = f"""
# 深度研究智能体性能报告
## 会话ID: {metrics['session_id']}
### 执行统计
- 总研究时间: {metrics.get('total_duration', 'N/A')}
- 检索来源数: {metrics.get('sources_retrieved', 0)}
- 迭代次数: {metrics.get('iterations_completed', 0)}
- Token使用量: {metrics.get('token_usage', 0)}
### 质量评估
- 来源质量分数: {metrics.get('source_quality_score', 0):.2f}/10
- 证据覆盖率: {metrics.get('evidence_coverage', 0):.1f}%
- 论证强度: {metrics.get('argument_strength', 0):.2f}/10
- 事实准确率: {metrics.get('factual_accuracy', 0):.1f}%
### 成本分析
- 总成本: ${metrics.get('total_cost_usd', 0):.4f}
- 每个来源成本: ${metrics.get('cost_per_source', 0):.4f}
- 成本效益比: {metrics.get('cost_effectiveness', 0):.2f}
### 建议优化
{self._generate_optimization_suggestions(metrics)}
"""
return report
安全与合规性保障
内容安全过滤
class ContentSafetyFilter:
"""内容安全过滤器,确保输出合规"""
def __init__(self, safety_config: Dict):
self.safety_config = safety_config
self.llm = init_chat_model("deepseek-chat")
async def filter_content(self, content: str, context: Dict) -> Dict:
"""过滤不安全或不合规的内容"""
safety_checks = []
# 1. 事实性检查
factual_issues = await self._check_factual_accuracy(content, context)
safety_checks.extend(factual_issues)
# 2. 偏见检测
bias_issues = await self._detect_bias(content)
safety_checks.extend(bias_issues)
# 3. 合规性检查
compliance_issues = await self._check_compliance(content, context)
safety_checks.extend(compliance_issues)
# 4. 敏感性检查
sensitivity_issues = await self._check_sensitive_content(content)
safety_checks.extend(sensitivity_issues)
# 5. 幻觉检测
hallucination_issues = await self._detect_hallucinations(content, context)
safety_checks.extend(hallucination_issues)
# 综合评估
safety_score = self._calculate_safety_score(safety_checks)
if safety_score < self.safety_config["threshold"]:
filtered_content = await self._apply_corrections(content, safety_checks)
return {
"original_content": content,
"filtered_content": filtered_content,
"safety_checks": safety_checks,
"safety_score": safety_score,
"requires_human_review": safety_score < self.safety_config["review_threshold"],
"blocked": safety_score < self.safety_config["block_threshold"]
}
else:
return {
"original_content": content,
"filtered_content": content,
"safety_checks": safety_checks,
"safety_score": safety_score,
"requires_human_review": False,
"blocked": False
}
数据隐私保护
class PrivacyPreservingProcessor:
"""隐私保护处理器,确保数据安全"""
def __init__(self, encryption_key: str):
self.cipher = Fernet(encryption_key)
def anonymize_sensitive_data(self, text: str) -> str:
"""匿名化敏感数据"""
# 识别并替换PII(个人身份信息)
patterns = {
"email": r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
"phone": r'\b(\+\d{1,3}[-.]?)?\(?\d{3}\)?[-.]?\d{3}[-.]?\d{4}\b',
"ssn": r'\b\d{3}[-]\d{2}[-]\d{4}\b',
"credit_card": r'\b\d{4}[- ]?\d{4}[- ]?\d{4}[- ]?\d{4}\b'
}
anonymized = text
for pii_type, pattern in patterns.items():
anonymized = re.sub(
pattern,
f"[{pii_type.upper()}_REDACTED]",
anonymized
)
return anonymized
def encrypt_research_data(self, data: Dict) -> Dict:
"""加密研究数据"""
encrypted_data = {}
for key, value in data.items():
if isinstance(value, str):
encrypted_data[key] = self.cipher.encrypt(value.encode()).decode()
elif isinstance(value, dict):
encrypted_data[key] = self.encrypt_research_data(value)
elif isinstance(value, list):
encrypted_data[key] = [
self.cipher.encrypt(str(item).encode()).decode()
if isinstance(item, str) else item
for item in value
]
else:
encrypted_data[key] = value
return encrypted_data
def enforce_data_retention_policy(self, data: Dict, policy: Dict) -> Dict:
"""执行数据保留策略"""
current_time = datetime.now()
filtered_data = {}
for key, value in data.items():
retention_days = policy.get(key, policy.get("default", 30))
if "timestamp" in value:
data_time = datetime.fromisoformat(value["timestamp"])
age_days = (current_time - data_time).days
if age_days <= retention_days:
filtered_data[key] = value
else:
# 数据过期,安全删除
self._secure_delete(value)
else:
filtered_data[key] = value
return filtered_data
四、企业级部署架构
高可用架构设计
┌─────────────────────────────────────────────────────────────┐
│ 负载均衡器 (HAProxy/Nginx) │
└───────────────────────────┬─────────────────────────────────┘
│
┌───────────────────┼───────────────────┐
│ │ │
┌───────▼──────┐ ┌───────▼──────┐ ┌───────▼──────┐
│ 研究智能体实例 │ │ 研究智能体实例 │ │ 研究智能体实例 │
│ (主) │ │ (备1) │ │ (备2) │
└───────┬──────┘ └───────┬──────┘ └───────┬──────┘
│ │ │
┌───────▼───────────────────▼───────────────────▼──────┐
│ 消息队列 (RabbitMQ/Kafka) │
└───────┬───────────────────┬───────────────────┬──────┘
│ │ │
┌───────▼──────┐ ┌───────▼──────┐ ┌───────▼──────┐
│ 任务调度器 │ │ 缓存集群 │ │ 向量数据库 │
│ (Celery) │ │ (Redis) │ │ (Pinecone) │
└───────┬──────┘ └───────┬──────┘ └───────┬──────┘
│ │ │
┌───────▼───────────────────▼───────────────────▼──────┐
│ 主数据库 (PostgreSQL) │
└───────┬───────────────────┬───────────────────┬──────┘
│ │ │
┌───────▼──────┐ ┌───────▼──────┐ ┌───────▼──────┐
│ 监控系统 │ │ 日志系统 │ │ 备份系统 │
│ (Prometheus) │ │ (ELK Stack) │ │ (S3) │
└──────────────┘ └──────────────┘ └──────────────┘
微服务架构分解
services:
research-orchestrator:
image: research-agent/orchestrator:latest
environment:
- REDIS_HOST=redis-cluster
- DB_HOST=postgres-primary
- MQ_HOST=rabbitmq
depends_on:
- redis-cluster
- postgres-primary
retrieval-service:
image: research-agent/retrieval:latest
scale: 3
environment:
- TAVILY_API_KEY=${TAVILY_API_KEY}
- ACADEMIC_API_KEY=${ACADEMIC_API_KEY}
analysis-service:
image: research-agent/analysis:latest
scale: 2
environment:
- DEEPSEEK_API_KEY=${DEEPSEEK_API_KEY}
- CACHE_HOST=redis-cluster
synthesis-service:
image: research-agent/synthesis:latest
scale: 2
monitoring-service:
image: research-agent/monitoring:latest
ports:
- "9090:9090" # Prometheus
- "3000:3000" # Grafana
api-gateway:
image: nginx:latest
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
配置管理与环境变量
# config/production.py
RESEARCH_AGENT_CONFIG = {
"model": {
"primary": "deepseek-r1",
"fallback": "deepseek-chat",
"max_tokens": 4000,
"temperature": 0.7,
"timeout": 30
},
"retrieval": {
"sources": ["academic", "news", "web", "reports"],
"max_results_per_source": 10,
"timeout_per_source": 10,
"cache_ttl": 3600
},
"analysis": {
"max_iterations": 3,
"min_evidence_count": 5,
"confidence_threshold": 0.7,
"contradiction_threshold": 0.3
},
"synthesis": {
"report_templates": ["academic", "executive", "technical"],
"max_length": 5000,
"include_citations": True,
"include_appendix": False
},
"monitoring": {
"enable_metrics": True,
"enable_tracing": True,
"enable_logging": True,
"log_level": "INFO"
},
"safety": {
"enable_filtering": True,
"block_threshold": 0.3,
"review_threshold": 0.6,
"anonymize_pii": True
},
"cost_control": {
"daily_budget": 100, # USD
"max_cost_per_query": 10,
"enable_caching": True,
"cost_alert_threshold": 0.8
}
}
五、最佳实践与性能优化
性能优化策略
- 异步并行处理
async def parallel_research_tasks(self, subtopics: List[str]) -> List[Dict]:
"""并行执行多个子主题的研究"""
tasks = []
for topic in subtopics:
task = asyncio.create_task(
self.research_subtopic(topic)
)
tasks.append(task)
# 设置超时和并发控制
results = await asyncio.gather(
*tasks,
return_exceptions=True,
timeout=300 # 5分钟超时
)
# 处理结果
successful_results = []
for result in results:
if not isinstance(result, Exception):
successful_results.append(result)
else:
logging.error(f"子任务失败: {result}")
return successful_results
- 增量更新与缓存预热
class IncrementalUpdater:
"""增量更新管理器,减少重复计算"""
async def incremental_update(self, existing_research: Dict, new_data: Dict) -> Dict:
"""增量更新现有研究"""
# 1. 识别变化部分
changes = await self._identify_changes(existing_research, new_data)
if not changes["has_significant_changes"]:
# 无显著变化,返回缓存结果
return existing_research
# 2. 只更新变化的部分
updated_research = existing_research.copy()
for section, change_type in changes["changed_sections"].items():
if change_type == "full_update":
updated_research[section] = new_data[section]
elif change_type == "partial_update":
updated_research[section] = await self._merge_changes(
existing_research[section],
new_data[section]
)
# 3. 更新时间戳和版本
updated_research["last_updated"] = datetime.now().isoformat()
updated_research["version"] += 1
return updated_research
质量保障措施
- 多模型验证机制
class MultiModelVerifier:
"""多模型验证,提高结果可靠性"""
def __init__(self):
self.models = {
"primary": init_chat_model("deepseek-r1"),
"secondary": init_chat_model("gpt-4"),
"tertiary": init_chat_model("claude-3")
}
async def cross_validate(self, content: str, claim: str) -> Dict:
"""使用多个模型交叉验证"""
validation_tasks = []
for model_name, model in self.models.items():
task = asyncio.create_task(
self._validate_with_model(model, content, claim)
)
validation_tasks.append((model_name, task))
# 收集所有验证结果
validation_results = {}
for model_name, task in validation_tasks:
try:
result = await task
validation_results[model_name] = result
except Exception as e:
logging.error(f"模型 {model_name} 验证失败: {e}")
validation_results[model_name] = {"error": str(e)}
# 计算一致性分数
consistency_score = self._calculate_consistency(validation_results)
return {
"validation_results": validation_results,
"consistency_score": consistency_score,
"final_verdict": self._determine_final_verdict(validation_results),
"confidence": self._calculate_confidence(validation_results)
}
- A/B测试与持续改进
class ABTestingFramework:
"""A/B测试框架,持续优化智能体性能"""
async def run_experiment(self, experiment_config: Dict) -> Dict:
"""运行A/B测试实验"""
variants = experiment_config["variants"]
results = {}
for variant_name, variant_config in variants.items():
variant_results = await self._test_variant(
variant_config,
experiment_config["test_cases"]
)
results[variant_name] = {
"performance": variant_results["performance_metrics"],
"quality": variant_results["quality_metrics"],
"cost": variant_results["cost_metrics"],
"user_feedback": variant_results["user_feedback"]
}
# 统计分析
statistical_significance = self._calculate_statistical_significance(results)
return {
"experiment_id": experiment_config["id"],
"results": results,
"statistical_significance": statistical_significance,
"recommended_variant": self._select_best_variant(results),
"improvement_percentage": self._calculate_improvement(results)
}
六、总结与展望
DeepResearch智能体的开发是一个系统工程,需要综合考虑架构设计、算法优化、工程实现和业务需求。基于本文提供的实战指南,企业可以:
- 快速搭建原型:使用提供的代码模板和架构设计,在2-4周内搭建可用的研究智能体原型
- 渐进式优化:通过监控数据和A/B测试,持续优化智能体的性能和效果
- 规模化部署:采用微服务架构和容器化部署,支持高并发和大规模使用
- 持续迭代:基于实际使用反馈和新技术发展,不断改进智能体的能力
未来发展方向包括:
- 多模态研究能力:整合图像、视频、音频等多模态信息源
- 实时研究能力:支持对实时事件和数据的持续监控与分析
- 协作研究模式:支持多人协作和智能体间的协同研究
- 领域专业化:针对特定领域(医疗、金融、法律等)的深度定制
通过系统化的设计和实施,DeepResearch智能体将成为企业知识管理和决策支持的重要工具,显著提升研究效率和质量。
6.3 基于电商平台的全流程任务规划Agent Copilot工具
一、 核心理念:从“工具”到“搭档”,重塑电商运营范式
在电商流量红利见顶、竞争日益激烈的当下,传统的“人找工具”的运营模式已难以应对海量、琐碎且动态变化的用户需求与市场环境。一个理想的AI Copilot,其价值定位不应仅是提升某个环节的效率,而是作为深度融入业务流程的“智能搭档”,通过“人机协作”的模式,系统性地提升整个运营链条的决策质量和执行效率。
其核心目标在于:将过去离散、低效、依赖个人经验的人力节点,串联成一个高效、智能、自优化的自动化体系,从而撬动整体转化率与运营效率的提升。
二、 架构设计:分层解耦与能力集成
一个成熟的全流程电商Agent Copilot,应采用分层架构设计,以确保系统的灵活性、可扩展性和易维护性。
1. 交互与感知层
这是Copilot与运营人员交互的界面。它需要支持多种交互模式:
- 自然语言对话:运营人员通过聊天窗口,用自然语言下达指令,如“为下周的夏季大促生成一个营销计划”。
- GUI指令自动化:对于高度重复的标准化操作(如商品上下架、批量改价),Copilot应能通过视觉语言模型(VLM)直接“看懂”后台界面并自动执行点击、输入等操作,实现“所见即所得”的自动化。
- 数据仪表盘:以可视化图表形式,主动呈现关键运营洞察和建议,如“近期A类商品点击率下降,建议优化主图”。
2. Agent核心引擎层
这是Copilot的“大脑”,负责理解意图、规划任务、调用工具并执行。它通常是一个中心化多智能体(Centralized Multi-Agent)系统。
- 中央控制器(Orchestrator):接收用户指令,进行意图识别(Intent)和任务分解(Planning)。它拥有全局视图,负责调度和协调各个专业子Agent。
- 专业化子Agent(Skill Agents):每个子Agent是某个领域的专家,负责执行具体任务。例如:
- 商品管理Agent:负责上下架、标题/详情页优化、库存预测。
- 营销内容Agent:负责生成营销文案、设计海报、剪辑视频。
- 数据分析Agent:负责销售趋势分析、竞品监控、用户画像洞察。
- 客服与互动Agent:负责自动回复咨询、处理售后、主动营销。
- 视觉设计Agent:专门处理图像相关任务,如智能商拍、换背景、生成模特图。
3. 工具与能力层
为Agent提供执行任务所需的“手脚”。这包括:
- 内部API:连接电商平台的商品、订单、用户、数据后台。
- 外部服务API:连接物流查询、支付网关、广告投放平台(如巨量引擎)、社交媒体等。
- 模型能力:集成文本生成(LLM)、图像生成(AIGC)、视觉理解(VLM)、语音合成等各类AI模型能力。
- 自动化脚本:用于执行固定流程的RPA脚本。
4. 知识与数据层
这是Copilot的“记忆”和“经验库”,是其做出精准决策的基础。
- 企业知识库:包含产品手册、品牌规范、客服话术、运营SOP等。
- 动态数据库:实时更新的商品数据、用户行为数据、交易数据、市场数据。
- 历史决策库:存储过往的成功运营案例、A/B测试结果、用户反馈,用于持续优化模型策略。
三、 核心应用场景与工作流实战
结合搜索结果中的多个案例,我们可以勾勒出Copilot在电商全流程中的典型工作流:
场景一:智能商品上架与视觉优化
- 传统痛点:拍摄成本高、修图耗时、详情页制作繁琐、上新速度慢。
- Copilot工作流:
- 指令:运营人员上传一张商品白底图,并说:“生成5套适合夏季海滩场景的营销主图,并写一段吸引年轻人的商品描述。”
- 规划与执行:中央控制器调度视觉设计Agent和商品管理Agent协同工作。
- 视觉生成:视觉设计Agent调用像Pic Copilot或ZMO.AI这样的工具,基于商品图智能识别主体,并生成符合要求的高质量场景图,同时保证商品细节(如logo、花纹)100%保留,解决传统AIGC“货不对板”的问题。
- 文案生成:商品管理Agent分析商品类目、卖点,结合“夏季”、“海滩”、“年轻人”等关键词,生成富有吸引力的标题和五点描述。
- 自动上架:最后,Copilot可以调用CogAgent这样的GUI自动化工具,自动登录后台,将生成的图片和文案填入对应表单,完成上架。整个过程从过去的数小时甚至数天,缩短到几分钟。
场景二:数据驱动的营销策略与内容生成
- 传统痛点:营销策略依赖经验、内容创作耗时、渠道投放效果难以实时优化。
- Copilot工作流:
- 指令:“分析过去一周女装连衣裙的销售数据,并为即将到来的周末策划一个促销活动。”
- 数据分析:数据分析Agent快速分析销售趋势、爆款特征、用户画像和竞品动态。
- 策略生成:基于分析结果,营销内容Agent制定促销策略(如“第二件半价”),并自动生成配套的营销文案、社交媒体帖子、邮件模板,甚至利用多模态能力生成促销视频素材。
- 个性化推荐:在活动执行中,Copilot可以基于实时流量和用户行为,动态调整首页推荐、搜索排序和广告创意,实现“千人千面”的精准营销。
- 效果复盘:活动结束后,自动生成分析报告,总结ROI,并为下一次活动提供优化建议,形成“计划-执行-分析-优化”的数据闭环。
场景三:主动式、闭环的客户服务与销售转化
- 传统痛点:客服响应慢、问题重复、转化时机稍纵即逝。
- Copilot工作流:
- 智能接待:客服Agent 7x24小时响应常见问题,如物流查询、退换货政策,并能够理解用户发来的商品破损图片,自动判断解决方案(退款、补发或维修)。
- 主动服务:通过分析用户浏览轨迹(如在某商品详情页停留超过3分钟),Copilot可主动弹出对话,询问:“看您对这款产品的性能很感兴趣,需要我为您详细介绍一下吗?”,在决策犹豫期进行有效干预,提升转化率。
- 评价管理:自动监控商品评价,识别负面评价中的具体问题(物流慢、质量瑕疵),并根据预设策略库自动生成拟人化回复,同时将问题自动生成工单流转至相应部门处理,将“售后”触点转化为提升用户体验和积累内容资产(精选好评)的机会。
场景四:供应链与库存的智能决策
- 传统痛点:销量预测不准、库存积压或缺货、采购决策滞后。
- Copilot工作流:
- 智能预测:Copilot集成如京东Oxygen Forecaster这样的时序大模型,综合分析历史销售、实时流量、市场趋势、促销日历等多维度信息,提升销量预测准确性。
- 自动决策:基于预测,供应链Agent可以自主决策千万级SKU的库存布局,甚至主动进行采购下单,扮演“虚拟采控总监”的角色。
- 动态定价:结合库存水平、竞品价格和用户价格敏感度,动态调整商品价格,在利润和销量间寻找最优解。
四、 关键成功要素与挑战
构建一个成功的电商Agent Copilot,需要重点关注以下几点:
- 深度业务理解与数据闭环:所有模型与功能都必须围绕“提升转化”和“好卖”而设计。这需要将图像特征、文案风格、促销策略等与最终的点击率、转化率数据深度关联,并以此持续反哺和优化AI模型,形成自进化的数据闭环。
- “人机协作”的交互设计:Copilot不是全自动的Agent,其精髓在于“辅助”。需要设计合适的触发时机、干预方式和确认机制,确保运营人员始终拥有最终决策权,并在关键环节进行校准,避免误操作风险。
- 统一的能力总线与可扩展性:需要设计一套统一的插件框架或“能力总线”,以低耦合的方式集成各种内部工具和外部API,方便后续能力的快速扩展和升级。例如,京东开源的OxyGent多智能体协作框架就支持开发者像搭积木一样灵活组合智能体系统。
- 成本与性能的平衡:大模型调用成本、响应延迟和系统可用性是生产环境必须持续跟踪的指标。需要通过模型选型(通用vs.垂类)、缓存策略、异步处理等技术手段进行优化。
五、 总结与展望
基于电商平台的全流程任务规划Agent Copilot,代表了AI在电商领域应用从 “点状工具”(AI Embedded) 到 “线性助手”(AI Copilot) ,并最终迈向 “面状智能”(AI Agent) 的演进路径。它不再是完成单一任务的工具,而是成为一个贯穿“商品-营销-销售-服务-供应链”全链路的智能运营中枢。
未来的电商Copilot将更加“智能原生”(AI-Native),其交互将更自然(多模态对话),决策将更自主(基于实时数据的闭环优化),并进一步与XR(如京东的Oxygen XR裸眼3D展示)、物联网等新技术融合,最终为商家和消费者创造一个无缝、高效、高度个性化的下一代电商体验。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)