BELL:评估大型语言模型可解释性的基准
Syed Ahmed
syed_ahmed12@infosys.com
Karthick Selvaraj
karthick.s50@infosys.com
Bharathi Vokkaliga Ganesh
bharathi_ganesh01@infosys.com
ReddySiva Naga Parvathi Devi
reddy.devi@infosys.com
负责任AI办公室
Infosys Limited, Bangalore, India
摘要
大型语言模型(LLMs)在自然语言处理(NLP)领域展现了卓越的能力,但其决策过程往往缺乏透明性。这种不透明性引发了对信任、偏差和模型性能的严重担忧。为了解决这些问题,理解和评估LLMs的可解释性至关重要。本文介绍了一种标准化的基准测试技术,即BELL(Benchmarking the Explainability of Large Language Models),旨在评估大型语言模型的可解释性。为了评估LLMs的推理能力,采用了多种引发思考的技术,包括链式思维(CoT)、线程思维(ThoT)、重读CoT、重读ThoT、验证链(CoVe)、幻觉、思维图(GoT)和逻辑思维(LoT)。这些评估使用open-orca数据集进行,通过一系列全面的指标来衡量解释的质量。这些指标涵盖了连贯性、不确定性、幻觉以及相对于模型内部推理的余弦相似度等因素。通过系统地将各种LLMs与这一基准进行比较,目标是识别出能够提供更透明和可靠解释的模型。这一基准测试技术为研究人员和从业者提供了一个有价值的工具,用于选择适合需要可解释性和问责制任务的LLMs。为了促进可重复性和推动更广泛的采用,我们已将每种提出的和使用的可解释性技术实现为开源软件,代码和必要资源可在https://github.com/Infosys/Infosys-Responsible-AI-Toolkit获得。
关键词:#可解释性, #解释性, #推理, #模型透明度, #自然语言处理(NLP), #大型语言模型(LLM), #思维引发, #OpenOrca, #AI相关性, #AI连贯性, #AI幻觉, #思维链, #思维线程, #思维图, #逻辑思维, #重读, #验证链, #基准测试, #模型评估
1. 引言
大型语言模型已经革新了自然语言处理和生成型人工智能(AI),这一点已在众多基础研究中得到证明[1]。这些模型的卓越能力吸引了广泛的关注,使各种应用成为可能。LLMs被用于诸如翻译[2]、内容生成、内容摘要、文章撰写[3]以及增强搜索功能(Bing Chat[4])等任务。LLMs的影响还扩展到了软件开发领域,例如Code Llama[5]帮助工程师。它们的应用还涵盖了金融部门[6]、科学研究[7][8],包括艺术[9]、教育[10]、海洋学[11]、法律[12]、政治科学[13]、医学[14][15]等领域,展示了其广泛和多样的影响。
然而,随着LLMs的指数级增长,也带来了与其可解释性和解释性相关的挑战。首先,由于LLMs的多样输出和生成能力,理解它们如何得出特定响应变得困难。这种缺乏透明性可能导致不可预测[16]和潜在误导性的输出,使得确保对其性能的信任变得更加复杂。其次,训练数据集中的偏差[17]可能会影响LLM输出的公平性和解释性。例如,一个模型可能由于数据偏差而偏向某些观点,从而使某些输出难以解释或证明。第三,训练集中包含敏感数据可能会损害LLMs在确保隐私方面的解释性[18]。此外,用户对准确且符合人类期望的响应的高期望突显了LLMs需要以与人类价值观一致的方式进行解释的需求,因为错位可能导致伦理问题并降低对其应用的信任。
为了解决这些挑战,有必要解决LLMs可解释性和解释性的核心问题。如何系统地评估其决策过程的透明性?建立如BELL这样的强大基准测试使研究人员能够批判性地评估和比较LLMs,促进开发优先考虑透明性和责任的模型。这种方法不仅解决了当前的关切,还为未来值得信赖的人工智能系统的进步奠定了基础。本文的主要贡献包括:
- 标准化基准测试:本文介绍了标准化基准测试BELL,采用多种引发思考的技术,如CoT、ThoT、GoT、ReRead、LoT、CoVe和幻觉,系统地评估LLMs的推理能力。这些方法提供了一种结构化的方法来评估模型决策的解释性和透明性。
-
- 指标:本文描述了一组评估指标,包括连贯性、不确定性和余弦相似度,以定量测量LLM解释的质量和透明度。
本工作的关键贡献之一是公开发布我们的可解释性技术和相应评估指标的实现,使社区能够轻松采用和扩展我们的发现。代码库可在Infosys-Responsible-AI-Toolkit/responsible-ai-llm-explain at master Infosys/Infosys-Responsible-AI-Toolkit访问。
- 指标:本文描述了一组评估指标,包括连贯性、不确定性和余弦相似度,以定量测量LLM解释的质量和透明度。
本文的结构如下:第2节介绍背景及相关工作,第3节介绍设计用于评估LLMs可解释性的基准测试。第4节详细说明数据集和评估指标,第5节概述研究结果。最后一节,第6节,总结并提出未来研究的方向。
2. 背景
2.1 解释性
像ChatGPT这样高效的闭源LLMs的兴起引发了对这些模型的极大兴趣。同时,开源替代方案如Granite[19]、Llama[20]也获得了显著的欢迎。LLMs的日益普及也吸引了专注于模型解释性和可解释性的研究人员的关注。理解LLMs在训练过程中能力如何演变对于分析其在下游任务中的形成和功能至关重要。此外,研究推理过程和上下文的影响对于揭示模型行为的见解非常重要。然而,由于LLMs固有的大量参数和复杂的非线性结构,这种分析具有挑战性。
大多数关于解释性和解释性的研究集中在宏观层面的LLMs上,定性分析其行为。该领域的许多研究利用提示来探索这些方面[21][22]。
尽管如此,一小部分研究通过提示微调[23]或激活分析等探测方法探索LLMs的内部运作。相比之下,机械解释性旨在基于变压器的基本行为发展理论。这些方法侧重于检查驱动LLM创建的核心组件,并通过注入或训练特定模块来分析其内部表示。然而,将探测或机制解释性技术应用于封闭的基础模型存在重大挑战,因为其内部架构和参数通常无法访问。在这种情况下,探索引发思考的技术提供了一种替代方案,无论模型是开源还是闭源,都能验证其推理能力。
2.2 推理
大型语言模型(LLMs)中的推理涵盖了其逻辑分析信息、解决问题并根据提供的上下文得出结论的能力。这种能力使LLMs能够执行需要批判性思维的任务,如推断、识别关系和做出决策。链式思维(CoT)提示、线程思维(ThoT)方法、思维图(GoT)和其他框架[24-30]被广泛用于增强推理能力。这些方法促进了将复杂问题分解为较小的中间步骤,从而使推理过程更加有条理和高效。
推理的整合显著增强了LLMs的可解释性,通过明确详细说明得出结论的步骤,确保模型的输出更加透明和易懂。这种清晰度使用户能够理解结果背后的逻辑,从而更全面地评估模型的可靠性和准确性。此外,结构化的推理过程通过展示结果是如何得出的,增强了对系统的信心。
此外,推理促进了人类与AI之间的无缝协作。通过将计算问题解决策略与人类思维过程对齐,LLMs变得更加直观和易于互动。这种对齐增强了用户信任和依赖,从而提高了AI系统在各种现实场景中的实际应用效果和效率。
CoT、ThoT和GoT等推理框架的进步显著提升了LLMs的逻辑推理能力。然而,尽管有这些创新,LLMs在可解释性方面的基准测试仍存在关键差距。当前的基准测试通常强调性能指标,而忽略了对一致、可解释推理过程的需求。这种局限性在需要信任和透明的任务中尤为令人担忧,因为不忠实的推理会削弱LLMs输出的可靠性。针对这一缺陷,我们的工作重点是对LLMs进行可解释性基准测试,旨在评估和改进其提供与预测一致的连贯和透明推理的能力。
3. 大型语言模型可解释性基准测试(BELL)
大型语言模型中的引发思考技术是用于组织和指导模型推理过程的策略,帮助它产生逻辑、连贯和专注的响应。这些方法通过简化复杂问题为较小的步骤、考察不同可能性并提高清晰度,模拟人类的问题解决和批判性思维。
在本研究中,我们探讨了使用引发思考策略如何增强大型语言模型有效处理复杂推理任务的能力。我们展示了简单的提示工程技术,如链式思维、线程思维、图式思维、逻辑思维、重读和验证链,可以使大型模型自然地具备推理能力。
图1展示了利用LLMs增强推理和评估过程的综合架构。该过程从输入开始,包括数据集和作为后续阶段基础的LLM。“技术” & "引发思考"阶段涵盖了各种推理技术(从第3.1节到第3.2节讨论),包括CoT、ThoT、重读CoT、重读Thot、CoVe、幻觉。这些组件由提示模板引导,生成结构化的解释。此阶段的输出基于指标(在第4.2节中讨论)进行评估,如余弦相似度、不确定性量化、连贯性和幻觉。这些评估共同确定最终得分,代表系统的输出,确保推理和决策任务的稳健和系统化方法。该架构突出了将多种推理方法与定量评估相结合,以评估LLMs在复杂问题解决中的推理能力。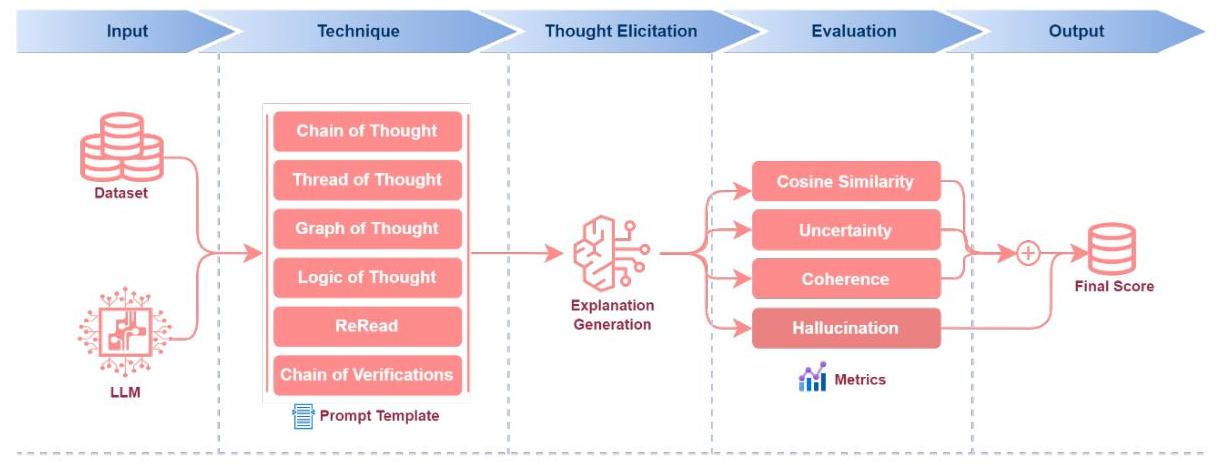
图1:建议的架构
3.1 链式思维(CoT):
链式思维(CoT)推理,由Wei等人引入[31],是一个每个步骤都以前一步骤为基础的过程,形成通向解决方案的结构化路径。这种方法通过将复杂问题分解为更小的步骤,帮助LLMs解决复杂问题,类似于人类以逐步方式连接想法。例如,在解决数学问题时,模型首先定义变量,然后应用相关方程,最后逐步计算结果。CoT方法已被证明可以显著提高模型的准确性,特别是在推理过程涉及多个阶段时,因为它允许模型在每个步骤验证和完善其思维过程。这种方法在增加如GPT-3等大型模型在推理密集型任务中的能力方面证明是有价值的,突显了如何促使这些模型生成详细的、逐步的解释。
3.2 线程思维(ThoT):
线程思维(ThoT)由Zhou等人[32]提出,是一种旨在改善大型语言模型在涉及多个相互关联的信息片段的复杂任务中的逻辑连贯性和一致性的新颖推理框架。例如,在分析冗长、杂乱的文档时,模型被提示将文本分解为可管理的部分,逐步分析每个段落——总结并分析——然后综合见解以形成连贯的理解。这种技术特别适用于需要长期推理或涉及模糊或混乱上下文的任务,因为它使模型能够在引入新信息时调整其思维过程。ThoT减少了当推理步骤被孤立对待时可能出现的逻辑错误或不一致的风险,使模型的响应更加可靠和可解释。
3.3 重读
Xu等人提出的重读技术[35]通过引入“重读”过程改进了大型语言模型的推理能力,在此过程中模型重新审视其提示。该技术旨在增强模型根据对上下文的更深入理解纠正错误和调整推理的能力。通过提示模型重新检查其提示,重读允许模型解决歧义和不一致。例如,在面对复杂问题时,模型首先阅读问题以掌握一般上下文,然后重新阅读以捕捉更细微的细节和细微差别。这种双重遍历方法使模型能够完善其理解,从而产生更准确和连贯的响应。Xu[35]证明,这种迭代方法显著提高了模型在复杂任务上的表现,特别是那些需要多步推理或澄清模糊查询的任务。进一步分析表明,由于其适应性,它可以轻松与其他引发思考的技术结合以获得更好的结果。我们将其与CoT和ThoT结合,获得了不同的改进解释并进行了基准测试。
3.4 验证链(CoVe):
Dhuliawala等人提出的验证链(CoVe)[36]解决了大型语言模型中的幻觉问题,即模型生成看似合理但不正确的信息。CoVe引入了一个多步骤过程,其中模型首先起草初步响应,然后生成验证问题以核对输出。模型独立回答这些问题以避免来自初始响应的偏见,随后生成最终经过验证的答案。这种方法通过允许模型对其推理进行深思熟虑并确保其准确性来纠正错误。
3.5 思维图(GoT):
Besta等人提出的思维图(GoT)[33]通过将思维过程组织成图结构来增强大型语言模型的推理能力。在此框架中,每个推理步骤表示为一个节点,步骤之间的关系通过边捕获,从而清楚地跟踪依赖关系和逻辑流程。例如,在计划旅行时,GoT可以探索不同的日期选项,同时考虑每个日期对潜在住宿和活动选择的影响,创建一个相互连接的决策网络。这使得相比简单的推理链更具灵活性和情境感知的问题解决成为可能。GoT提高了模型连贯推理和生成准确响应的能力。它还增强了可解释性,因为图结构提供了对模型推理路径的透明视图。
3.6 逻辑思维(LoT):
Tongxuan等人提出的逻辑思维(LoT)[34]将逻辑推理直接集成到大型语言模型的情境理解中。这种方法专注于将演绎和归纳推理等逻辑原则明确融入模型的决策过程中,使其能够进行更有条理和准确的推理。通过在问题情境中嵌入逻辑,LoT增强了模型得出可靠结论的能力,特别是在需要形式推理或复杂问题解决的任务中。该方法还通过使推理步骤透明且逻辑上有据可查来增强可解释性。
4 实验设置
实验是在64位Windows 10操作系统上进行的,使用的是配备16 GB专用GPU内存的Nvidia NC16as_T4_v3 GPU配置。实验环境配置了Python以及必要的库和依赖项,以支持基于转换器的模型的实现和执行。
4.6 数据集
OpenOrca数据集[37]是FLAN集合的增强版本,包含大约100万次GPT-4完成和320万次GPT-3.5完成。每个条目包括来自FLAN集合的问题,提交给GPT-4或GPT-3.5,并记录相应的响应。该数据集适用于语言建模、文本生成和文本增强等任务,是开发和评估推理生成型AI模型的宝贵资源。
该数据集涵盖了一系列多样的类别,如数学问题解决、情感分析等。为了进行本研究,评估专门针对数学问题解决类别进行。
4.7 质量评估指标
- 余弦相似度:余弦相似度是一种用于评估生成响应与基准或参考响应对齐程度的方法。生成和参考响应被转换为模型嵌入空间中的向量表示,并计算余弦相似度以衡量它们之间的语义相似度。该技术有助于评估模型输出是否捕捉到参考的预期含义或上下文,使其在文本生成、摘要和问答等任务中评估性能非常有价值,使用公式(1)。
余弦相似度 =A.B∣∣A∣∣∣∣B∣∣ \text { 余弦相似度 }=\frac{A . B}{||A||||B||} 余弦相似度 =∣∣A∣∣∣∣B∣∣A.B
这里,AAA 和 BBB 是生成和参考响应的嵌入,A.BA . BA.B 是它们的点积,∣∣A∣∣||A||∣∣A∣∣ 和 ∣∣B∣∣||B||∣∣B∣∣ 是它们的大小,如下所示。
∣∣A∣∣=∑i=1nAi2,∣∣B∣∣=∑i=1nBi2 ||A||=\sqrt{\sum_{i=1}^{n} A_{i}^{2}},||B||=\sqrt{\sum_{i=1}^{n} B_{i}^{2}} ∣∣A∣∣=i=1∑nAi2,∣∣B∣∣=i=1∑nBi2
其中,AiA_{i}Ai 和 BiB_{i}Bi 分别是向量 AAA 和 BBB 的分量,nnn 是向量的维度。
- 不确定性:不确定性表示模型对其预测或生成响应的信心程度。它突出显示模型可能在理解输入时缺乏清晰度或面临歧义的情况。例如,对于不完整或模糊的查询,不确定性更高。通过评估不确定性,更容易识别可能需要验证或改进的响应。该指标对于提高模型的可靠性和性能至关重要。它还有助于过滤低置信度输出或将人类参与的系统集成到决策中。
-
- 连贯性:连贯性指的是生成响应在逻辑上的一致性和与输入或周围文本的情境对齐程度。它衡量思想的流动和响应的内部一致性。连贯的响应始终围绕主题,并保持清晰、有条理的叙述。连贯性确保模型的输出有意义并保持与输入的相关性,从而提高文本生成、摘要和对话的质量。高连贯性对于生成类似人类且情境适当的响应至关重要。
-
- 幻觉:大型语言模型中的幻觉是指模型生成事实错误、无意义或虚构的输出的现象,即使这些输出听起来合理或语法正确。借助G-Eval指标和orca数据集的余弦相似度,可以从LLM响应中检测到幻觉分数。
- 幻觉分数 =1−(0.8=1-(0.8=1−(0.8 * 评估指标平均值 )−(0.2)-(0.2)−(0.2 * 相似度评分平均值)
5 结果
通过对语言模型的可解释性进行详细的评估过程,对语言模型的性能进行评估。这包括计算每个生成响应的关键指标,如连贯性和不确定性,以衡量输出的逻辑一致性和信心。此外,还计算每个响应与预定义基准响应之间的余弦相似度,以评估与预期结果的对齐情况。为了进行全面评估,这些单独的指标取平均值以得出每个响应的综合得分。最后,通过对数据集中所有响应取平均值,获得模型的整体可解释性最终得分。这种方法提供了一种系统且定量的措施,有效地评估语言模型的可解释性。评估结果从图1到图7展示。
- (D) === 响应数据集。
-
- (R_i)=(\mathrm{R} \_ \mathrm{i})=(R_i)= 数据集(D)中的第(i)个响应。
-
- (E_i)=\left(\mathrm{E} \_\mathrm{i}\right)=(E_i)= 第(i)个响应(R_i\mathrm{R} \_\mathrm{i}R_i)生成的解释。
-
- (B_i)=\left(\mathrm{B} \_\mathrm{i}\right)=(B_i)= 第(i)个响应(R_i\mathrm{R} \_\mathrm{i}R_i)的预定义基准响应。
-
- ( {\{{ 连贯性 }(E_i))=\}(\mathrm{E} \_\mathrm{i}))=}(E_i))= 与响应(R_i\mathrm{R} \_\mathrm{i}R_i)相关的解释的连贯性得分。
-
- ( {\{{ 不确定性 }(E_i))=\}(\mathrm{E} \_\mathrm{i}))=}(E_i))= 与响应(R_i)\left(\mathrm{R} \_\mathrm{i}\right)(R_i)相关的解释的不确定性得分。
-
- ( {\{{ CosSim }(E_i,B_i))=\}(\mathrm{E} \_\mathrm{i}, \mathrm{B} \_\mathrm{i}))=}(E_i,B_i))= 解释(E_i\mathrm{E} \_\mathrm{i}E_i)与基准响应(B_i\mathrm{B} \_\mathrm{i}B_i)之间的余弦相似度得分。
-
- (n) === 数据集(D)中的响应总数。
-
- ( {\{{ OverallScore }\}} ) === 给定引发技术的最终整体可解释性得分。
-
- {\{{ OverallScore }=frac{1}{n}\}=\operatorname{frac}\{1\}\{n\} \quad}=frac{1}{n} sum_ {i=1}∧{n}\\{\mathrm{i}=1\}^{\wedge}\{n\} \quad \backslash{i=1}∧{n}\ left ((\quad( frac {{\{\{{{ 连贯性 }(E_i)+\}(\mathrm{E} \_\mathrm{i})+}(E_i)+ {不确定性 }(E_i)+{CosSim}(E_i,B_i)}{3}\\}(\mathrm{E} \_\mathrm{i})+\{\operatorname{CosSim}\}(\mathrm{E} \_\mathrm{i}, \mathrm{B} \_\mathrm{i})\}\{3\} \backslash}(E_i)+{CosSim}(E_i,B_i)}{3}\ right )))
-
- ( {\{{ 幻觉 }(E_i))=\}(\mathrm{E} \_\mathrm{i}))=}(E_i))= 与响应(R_i\mathrm{R} \_\mathrm{i}R_i)相关的解释的幻觉得分。
-
- ( {\{{ Model_Score }\}} ) = Avg ( {\{{ OverallScore }\}} ) - ( {\{{ 幻觉 }(E_i)\}(\mathrm{E} \_\mathrm{i})}(E_i) )
| 模型 | CoT | ThoT | 重读
CoT | 重读
ThoT | CoVe | 幻觉 | 模型
得分 |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| GPT-4 | 85.28 | 92.39 | 91.91 | 91.37 | 85.14 | 19.42 | 87.78 |
| Gemma-2 9B | 72.91 | 91.73 | 90.41 | 91.8 | 83.08 | 25.07 | 84.15 |
| Mistrat 7B | 79.93 | 90.34 | 79.94 | 89.71 | 88.33 | 26.4 | 83.64 |
| Llama-3.2 3B | 76.95 | 88.7 | 88.76 | 86.8 | 82.21 | 31.96 | 81.91 |
| Llava-1.6 7B | 58.81 | 86.87 | 85.93 | 87.95 | 82.13 | 25.1 | 79.43 |
| Nemotron-
mini-4B-instruct | 79.79 | 75.44 | 74.94 | 78.37 | 78.46 | 26.4 | 76.95 |
| Llama-3.2 1B | 75.7 | 83.19 | 84.03 | 83.19 | 67.51 | 34.33 | 76.55 |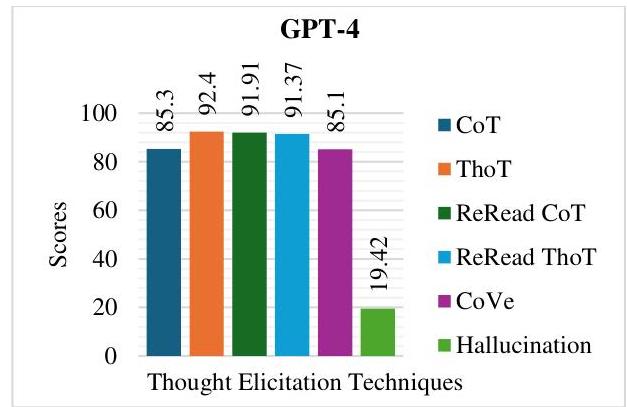
- ( {\{{ Model_Score }\}} ) = Avg ( {\{{ OverallScore }\}} ) - ( {\{{ 幻觉 }(E_i)\}(\mathrm{E} \_\mathrm{i})}(E_i) )
图1:GPT-4的评估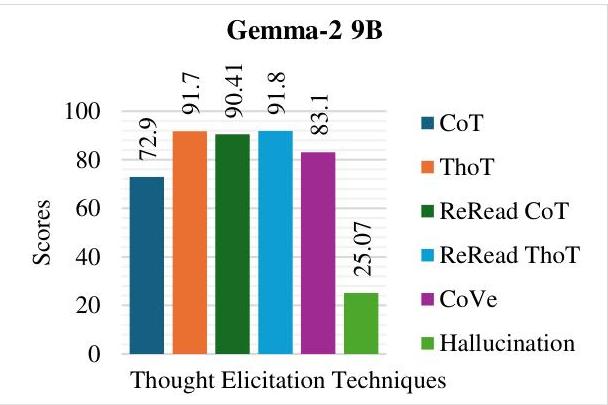
图2:Gemma-2 9B的评估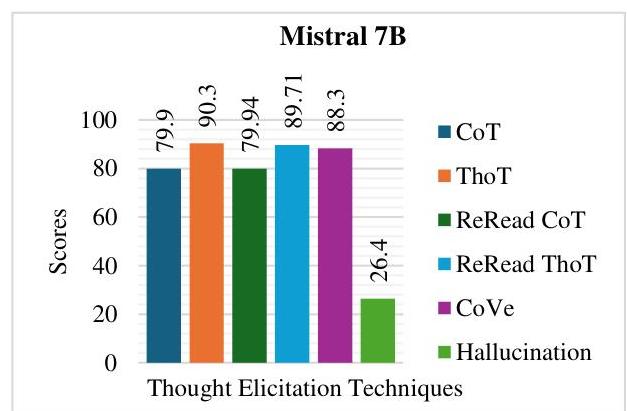
图3:Mistral 7B的评估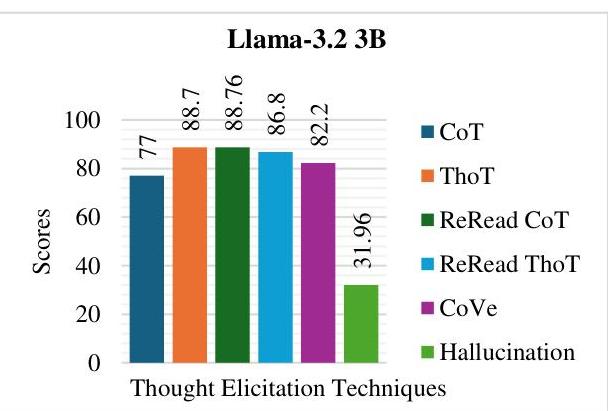
图4:Llama-3.2 3B的评估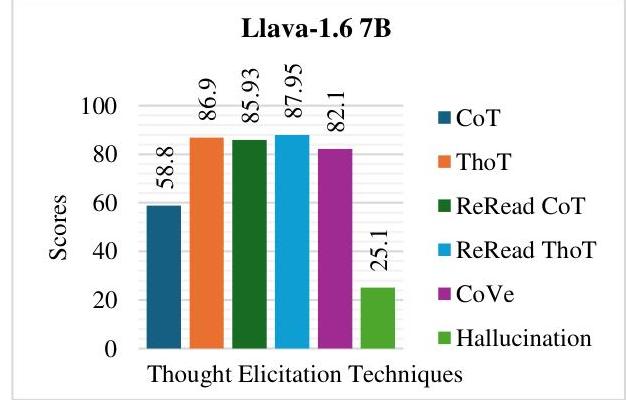
图5:Llava-1.6 7B的评估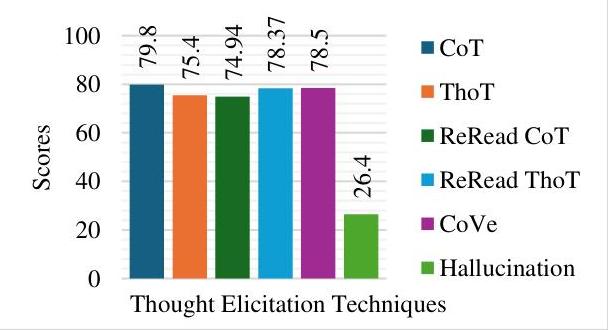
图6:Nemotron-Mini-4B-Instruct的评估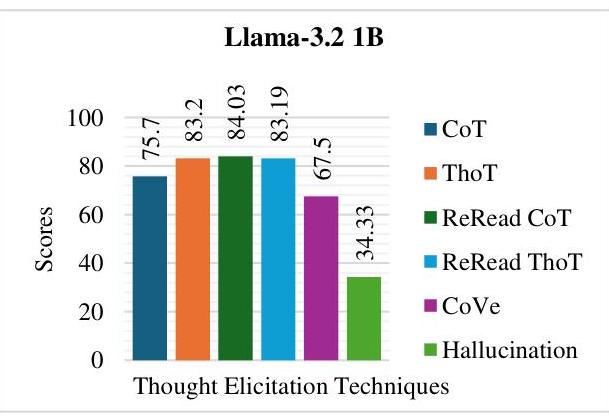
图7:Llama-3.2 1B的评估
在本研究中,我们评估了多种模型上的推理技术,包括链式思维、线程思维、重读CoT、重读ThoT、验证链和幻觉,使用余弦相似度、不确定性和连贯性。在所评估的模型中,GPT-4的表现最为出色,表现出强大的顺序推理能力,CoT得分为85.28,ThoT(92.39)和重读技术领先。Gemma-2 9B和Mistral 7B在几个类别中紧随其后,尽管它们在推理和幻觉控制方面与GPT-4相比存在一些差距。
较小的模型如Llama-3.2 1B表现出明显的局限性,尤其是在CoVe和幻觉得分方面,其可靠性明显低于所评估的较大模型。尽管在ThoT和重读技术方面表现适中,但像Llava-1.6 7B和Nemotron-mini-4B-instruct这样的模型在连贯性和验证任务中遇到困难,反映出其受限的推理能力。幻觉得分进一步突显了差异,GPT-4保持最低的19.42分,而较小的模型则面临超出可接受阈值的挑战。
总体而言,这些发现强调了较大模型在推理任务中的优越性以及小型架构需要显著改进的需求。
6 结论和未来工作
本文所呈现的发现强调了可解释性的多面性。没有单一的“最佳”XAI技术;相反,最优选择很大程度上取决于特定的应用领域、所解释的AI模型的特性以及解释的目标受众。本研究评估了多种模型上的几种推理技术,揭示了较大的模型,如GPT-4,始终优于较小的模型。这是通过使用推理技术,如链式思维(CoT)、线程思维(ThoT)、重读技术和验证链(CoVe)来演示的。GPT-4表现出卓越的顺序推理能力和最小的幻觉,确立了其在推理任务中的主导地位。相反,较小的模型,包括Llama-3.2 1B和Llava-1.6 7B,在连贯性和验证方面显示出显著的局限性,突显了对其推理能力进行针对性改进的需求。结果强调,虽然较小模型的表现适中,但较大模型在复杂推理任务中更为可靠。
未来的研究将探索更广泛的模型,特别是最新和新兴架构,这些架构在推理能力方面提供了增强。此外,我们计划使用来自医疗保健、法律和科学研究等领域的多样化数据集评估模型的推理能力,以了解模型在不同领域中的泛化能力。
作为研究人员,我们在本白皮书中的目标是为严格评估和比较可解释AI(XAI)技术奠定基础框架。我们探讨了理解各种XAI方法的优势、劣势和适用性至关重要的多种方法、指标和考虑因素。我们的基准测试努力,尽管提供了初步的见解,但为构建真正透明和值得信赖的人工智能系统提供了重要的起点。我们强烈鼓励读者——同行研究人员、从业者和政策制定者——在其工作中利用本文所提供的见解和方法。具体来说,我们敦促您利用我们在这里提供的代码,位于Infosys-Responsible-AI-Toolkit/responsible-ai-llm-explain at master - Infosys/Infosys-Responsible-AI-Toolkit,并通过开发新的可解释性技术&评估指标、策划多样化和富有挑战性的基准数据集以及评估更广泛的新兴XAI技术来扩展此处的工作。
缩略词:
- BELL - 大型语言模型可解释性基准测试
-
- LLM - 大型语言模型
-
- NLP - 自然语言处理
-
- CoT - 链式思维
-
- ThoT - 线程思维
-
- GoT - 思维图
-
- LoT - 逻辑思维
-
- CoVe - 验证链
-
- GPT - 生成式预训练变换器。
-
- GPU - 图形处理单元
-
- FLAN - 微调语言网络
参考文献
[1] Diksha Khurana, Aditya Koli, Kiran Khatter, and Sukhdev Singh. 自然语言处理:现状、当前趋势和挑战。多媒体工具与应用,2023。
[2] Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. 使用大型语言模型的多语言机器翻译:实证结果与分析,2023。
[3] Ann Yuan, Andy Coenen, Emily Reif, and Daphne Ippolito. Wordcraft:使用大型语言模型进行故事创作。在智能用户界面中,第841-852页,2022。
[4] 使用大型语言模型增强搜索,2023。 https://medium.com/whatnot-engineering/enhancing-search-using-large-language-models-f9dcb988bdb9。
[5] Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin 等人。 Code Llama:开放的基础模型用于编码。 arXiv 预印本 arXiv:2308.12950,2023。
[6] Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. BloombergGPT:用于金融的大型语言模型,2023。
[7] Microsoft Research AI4Science 和 Microsoft Azure Quantum。 大型语言模型对科学发现的影响:使用GPT-4的初步研究,2023。
[8] Xianjun Yang, Junfeng Gao, Wenxin Xue, and Erik Alexandersson. Pllama:用于植物科学的开源大型语言模型,2024。
[9] Zhengqing Yuan, Huiwen Xue, Xinyi Wang, Yongming Liu, Zhuanzhe Zhao, and Kun Wang. ArtGPT-4:使用增强型MiniGPT-4进行艺术视觉语言理解,2023。
[10] Jingsi Yu, Junhui Zhu, Yujie Wang, Yang Liu, Hongxiang Chang, Jinran Nie, Cunliang Kong, Ruining Chong, XinLiu, Jiyuan An, Luming Lu, Mingwei Fang, and Lin Zhu. Taoli Llama. https://github.com/blcuicall/taoli,2023。
[11] Ziqiang Zheng, Jipeng Zhang, Tuan-Anh Vu, Shizhe Diao, Yue Him Wong Tim, and Sai-Kit Yeung. MarineGPT:解锁“海洋”的秘密,2023。
[12] Shengbin Yue, Wei Chen, Siyuan Wang, Bingxuan Li, Chenchen Shen, Shujun Liu, Yuxuan Zhou, Yao Xiao, Song Yun, Xuanjing Huang, and Zhongyu Wei. Disc-LawLLM:微调大型语言模型以提供智能法律服务,2023。
[13] Mitchell Linegar, Rafal Kocielnik, and R Michael Alvarez. 大型语言模型与政治科学。政治科学前沿,5:1257092,2023。
[14] Xinlu Zhang, Chenxin Tian, Xianjun Yang, Lichang Chen, Zekun Li, and Linda Ruth Petzold. AlpacaRE:用于医疗应用的指令调优大型语言模型,2023。
[15] Kai Zhang, Jun Yu, Zhiling Yan, Yixin Liu, Eashan Adhikarla, Sunyang Fu, Xun Chen, Chen Chen, Yuyin Zhou, Xiang Li, Lifang He, Brian D. Davison, Quanzheng Li, Yong Chen, Hongfang Liu, and Lichao Sun. BioMedGPT:统一且通用的生物医学生成预训练变换器,用于视觉、语言和多模态任务,2023。
[16] Isabelle Augenstein, Timothy Baldwin, Meeyoung Cha, Tanmoy Chakraborty, Giovanni Luca Ciampaglia, David Corney, Renee DiResta, Emilio Ferrara, Scott Hale, Alon Halevy 等人。 大型语言模型时代的事实性挑战,2023。
[17] Appen。 揭示翻译与LLMs性别偏差之间的联系,2023。
[18] Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 越狱:LLM安全训练如何失败? arXiv 预印本 arXiv:2307.02483,2023。
[19] Granite Foundation Models,2024: https://www.ibm.com/downloads/documents/usen/10a99803c92fdb35
[20] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. LLaMA:开放且高效的基语言模型。 arXiv 预印本 arXiv:2302.13971,2023。
[21] Jaehun Jung, Lianhui Qin, Sean Welleck, Faeze Brahman, Chandra Bhagavatula, Ronan Le Bras, and Yejin Choi. 助产士式提示:带有递归解释的逻辑一致推理。 在经验方法自然语言处理(EMNLP)中,2022。
[22] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 大型语言模型是零样本推理器。 在NeurIPS中,2022。
[23] Jacob-Junqi Tian, David Emerson, Sevil Zanjani Miyandoab, Deval Pandya, Laleh SeyyedKalantari, and Faiza Khan Khattak. 大型语言模型的软提示微调以评估偏差。 arXiv 预印本 arXiv: 2306.04735,2023。
[24] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. 链式思维提示引发大型语言模型中的推理。 在NeurIPS中。
[25] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023a. 思维树:用大型语言模型进行深思熟虑的问题解决。 CoRR, abs/2305.10601。
[26] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2023. 思维图:用大型语言模型解决复杂问题。 CoRR, abs/2308.09687。
[27] Yao Yao, Zuchao Li, and Hai Zhao. 2023b. 超越链式思维,有效的图式思维推理在大型语言模型中。 CoRR, abs/2305.16582。
[28] Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V. Le, and Ed H. Chi. 2023. 最少到最多提示法使大型语言模型能够进行复杂推理。 在第十一届国际学习表示会议,ICLR 2023,卢旺达基加利,2023年5月1-5日。 OpenReview.net。
[29] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 自我一致性改进了语言模型中的链式思维推理。 在第十一届国际学习表示会议,2022。
[30] Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STAR:用推理引导推理。 神经信息处理系统进展,35:15476-15488,2022。
[31] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E.H., Xia, F., Le, Q., & Zhou, D. (2022). 链式思维提示引发大型语言模型中的推理。 ArXiv, abs/2201.11903。
[32] Zhou, Y., Geng, X., Shen, T., Tao, C., Long, G., Lou, J., & Shen, J. (2023). 线程思维:解开混乱的上下文。 ArXiv, abs/2311.08734。
[33] Besta, Maciej & Blach, Nils & Kubicek, Ales & Gerstenberger, Robert & Podstawski, Michal & Gianinazzi, Lukas & Gajda, Joanna & Lehmann, Tomasz & Niewiadomski, Hubert & Nyczyk, Piotr & Hoefler, Torsten. (2024). 思维图:用大型语言模型解决复杂问题。 人工智能协会会议论文集。 38. 17682-17690. 10.1609/aaai.v38i16.29720。
[34] Tongxuan, Liu & Xu, Wenjiang & Huang, Weizhe & Wang, Xingyu & Wang, Jiaxing & Yang, Hailong & Li, Jing. (2024). 逻辑思维:将逻辑注入到大型语言模型的情境中以实现全面推理。 10.48550/arXiv.2409.17539。
[35] Xu, X., Tao, C., Shen, T., Xu, C., Xu, H., Long, G., & Lou, J. (2023). 重读改进了大型语言模型中的推理。 自然语言处理中的经验方法会议。
[36] Dhuliawala, Shehzaad & Komeili, Mojtaba & Xu, Jing & Raileanu, Roberta & Li, Xian & Asli, Celikyilmaz & Weston, Jason. (2024). 验证链减少了大型语言模型中的幻觉。 3563-3578. 10.18653/v1/2024.findings-acl. 212。
[37] Mukherjee, Subhabrata, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi 和 Ahmed Hassan Awadallah. “Orca:从GPT-4的复杂解释痕迹中进行渐进学习。”
参考论文:https://arxiv.org/pdf/2504.18572

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 11
11 0
0- 0



 已为社区贡献178条内容
已为社区贡献178条内容

所有评论(0)