Q CLI+Bedrock知识库,构建端到端智能问答系统
这一挑战尤为关键,因为网站FAQ中的问题通常按类别组织,在原始上下文中意义清晰,但一旦脱离分类结构,同样的问题可能变得模糊不清。该阶段主要解决的问题是从网页中快速、自动提取结构化信息,特别是对于常见问题解答(FAQ)页面,能够自动化提取问答对并将其转化为结构化数据,可以为知识库建设、客户支持系统和智能问答机器人提供信息资源。比如以下网页,Q&A已经使用问答形式将客户关心的问题和答案做了分类整理,但

传统企业通常将常见问题(FAQ)发布在网站上,方便客户自助查找信息。然而,随着生成式AI技术的迅速发展与商业渗透,这些企业正积极探索构建智能问答系统的新途径。这类系统不仅能显著提升客户体验,还能有效降低人工支持成本,实现客户服务的智能化转型。
本文将详细分享如何利用Amazon Q CLI和Amazon Bedrock知识库快速构建端到端的智能问答系统。本例将从网页爬取FAQ开始,到构建高效知识库,实现全流程自动化,帮助企业轻松迈入AI客户服务新时代。
智能问答系统构建
解决方案分为两个核心阶段。
1
数据采集阶段
利用Amazon Q CLI和Playwright MCP Server自动从网页爬取Q&A问答对,整理到Excel表中。
该阶段主要解决的问题是从网页中快速、自动提取结构化信息,特别是对于常见问题解答(FAQ)页面,能够自动化提取问答对并将其转化为结构化数据,可以为知识库建设、客户支持系统和智能问答机器人提供信息资源。
下文将分享如何利用Amazon Q CLI和Playwright MCP Server快速构建一个自动化工作流,实现网页爬取、内容识别和问答对提取。
2
知识库构建阶段
将结构化数据导入Amazon Bedrock知识库,构建Q&A系统。
该阶段主要解决的核心问题是:如何将结构化的Q&A对Excel文件转化为智能可查询的知识库,并确保系统能准确理解和匹配用户问题。这一挑战尤为关键,因为网站FAQ中的问题通常按类别组织,在原始上下文中意义清晰,但一旦脱离分类结构,同样的问题可能变得模糊不清。
例如,“如何修改订单”这一问题在不同业务场景下可能有完全不同的答案。需要确保智能问答系统不仅存储问答对,还能根据上下文进行问题分类,以实现精准的语义匹配和回答检索。
架构图如下:
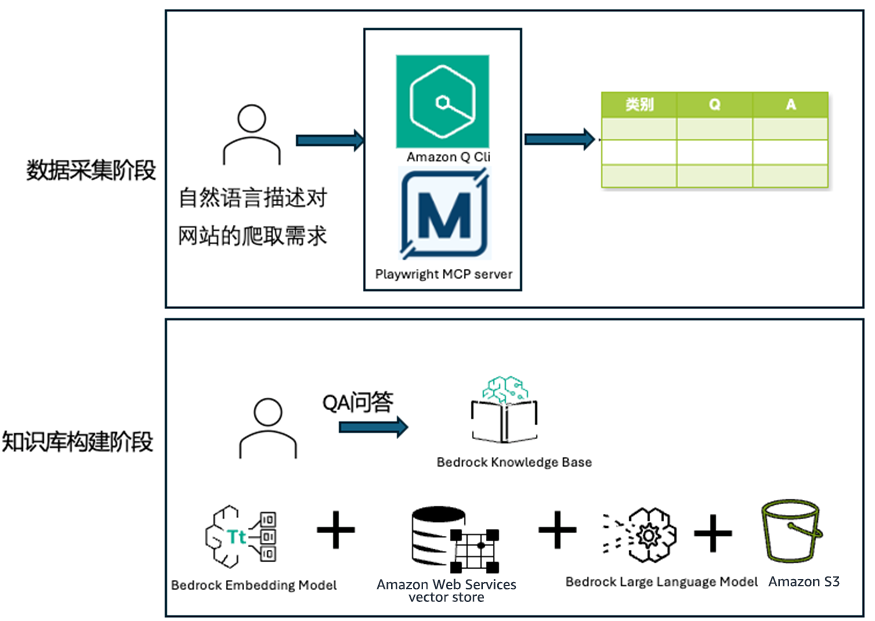
基于Amazon Q CLI+Playwright
MCP Server的自动化数据采集
Amazon Q CLI是亚马逊云科技推出的一款命令行工具,作为Amazon Q Developer的一部分,它允许开发者直接在命令行界面与Amazon Q的人工智能能力进行交互。为了延伸Amazon Q CLI调用外部工具的能力,Amazon Q CLI从1.9.0版本开始支持MCP,借助外部MCP Server,可以极大扩充Amazon Q CLI的能力。
Playwright是一款开源浏览器自动化框架,提供了跨浏览器的自动化测试和网页交互能力。Playwright MCP Server则是基于MCP协议为大语言模型(LLM)提供了使用Playwright进行浏览器自动化的能力,具有以下核心功能。
-
网页导航与交互:允许AI模型打开网页、点击按钮、填写表单等。
-
屏幕截图和网站文字获取:捕获当前网页的截图,帮助AI分析页面内容。
-
JavaScript执行:在浏览器环境中运行JavaScript代码,实现复杂交互等。
Amazon Q CLI集成Playwright MCP Server后,在Amazon Q CLI中通过自然语言交互就能够实现网页的打开、点击,网页文字内容的读取存储和解析,无需手工操作处理。
比如以下网页,Q&A已经使用问答形式将客户关心的问题和答案做了分类整理,但如果想导入知识库,就需要把网站的内容导出到Excel文件,便于后续处理。
下文将逐步展示Amazon Q CLI集成Playwright MCP Server后的强大能力。
1
配置Amazon Q CLI集成
Playwright MCP Server
在Amazon Q CLI中集成MCP Server非常简单,在Amazon Q Developer的安装目录,通常是~/.aws/amazonq/mcp.json文件中配置Playwright MCP Server,您可参阅代码库。
配置playwright MCP Server:
https://github.com/executeautomation/mcp-playwright
{ "mcpServers": { "playwright": { "command": "npx", "args": ["-y", "@executeautomation/playwright-mcp-server"] } }}左右滑动查看完整示意
启动Amazon Q Chat可以看到配置的Playwright MCP Server已经正常启动。
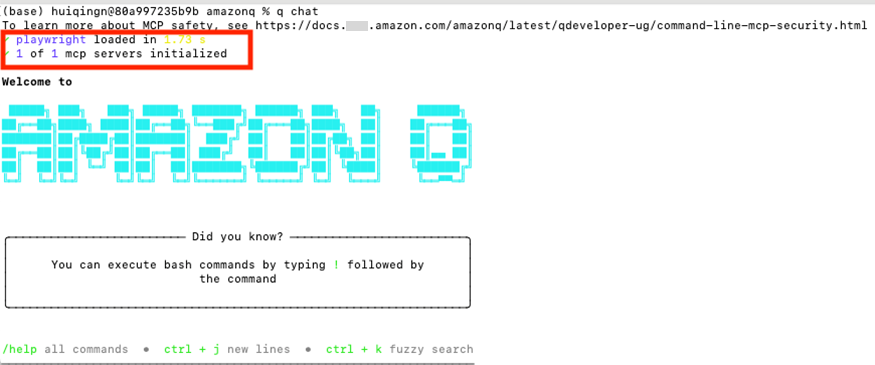
2
通过自然语言交互实现爬网
在Amazon Q Chat中输入以下提示词。
访问https://www.lalamove.com/en-sg/faq,点击[data-section=”business”];只获取页面的文字内容而非html内容,然后将文字内容保存到”lalamove_personal_faq.txt”
可以看到Amazon Q已经开始理解需求,并调用Playwright MCP Server提供的合适工具开始爬网。它分别使用:
-
playwright_navigate工具打开指定的网站;
-
playwright_click点击上面网页的“Business”链接;
-
playwright_get_visible_text工具获得网站上的文字内容;
-
fs_write将文字内容保存在本地文件。
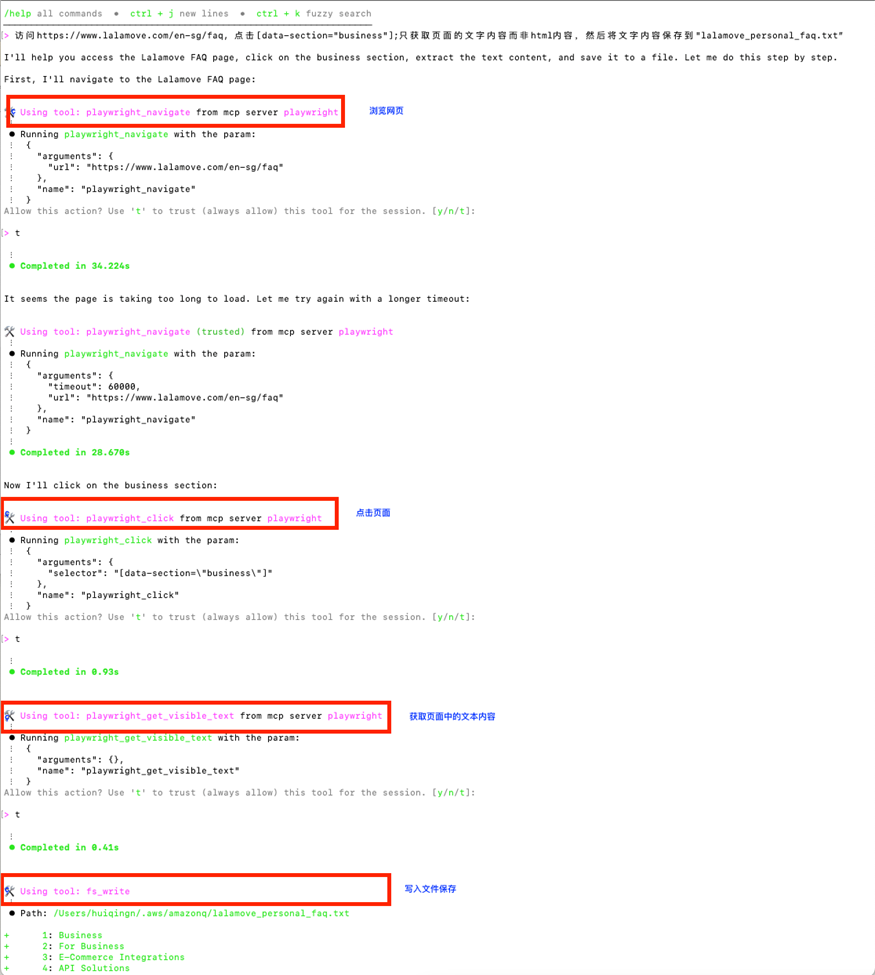
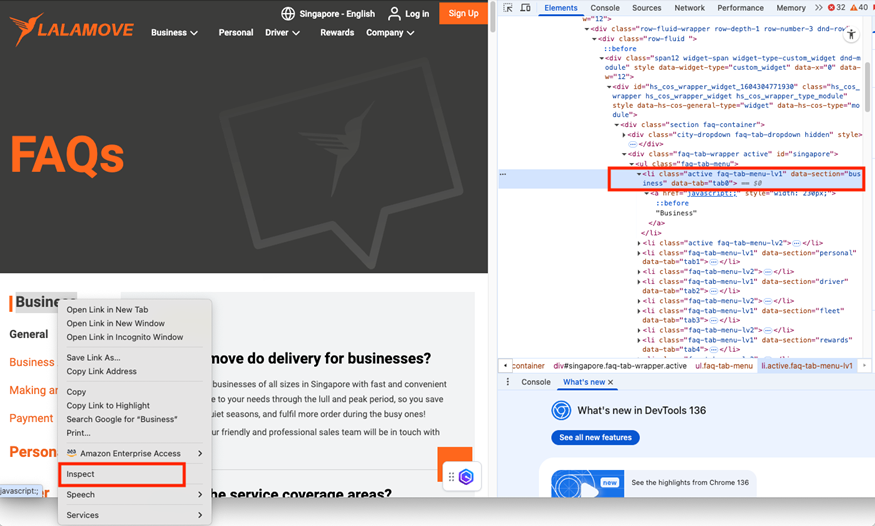
值得一提的是,您会发现以下提示词中特别添加了点击[data-section=”business”]。
访问https://www.lalamove.com/en-sg/faq,点击[data-section=”business”];只获取页面的文字内容而非html内容,然后将文字内容保存到”lalamove_personal_faq.txt”
这是因为网站中有多个“business”字样,如果不做特别说明,LLM通常会根据开发习惯猜测点击时使用的selector,将该参数传递给Playwright工具。当与实际情况不符时,Playwright往往难以点击到正确的链接。
通过如下方法获得准确的selector放入指令中,LLM就可以生成准确参数,实现精准点击。
3
通过自然语言交互
实现文本到Excel的转换
继续与Amazon Q CLI进行交互。
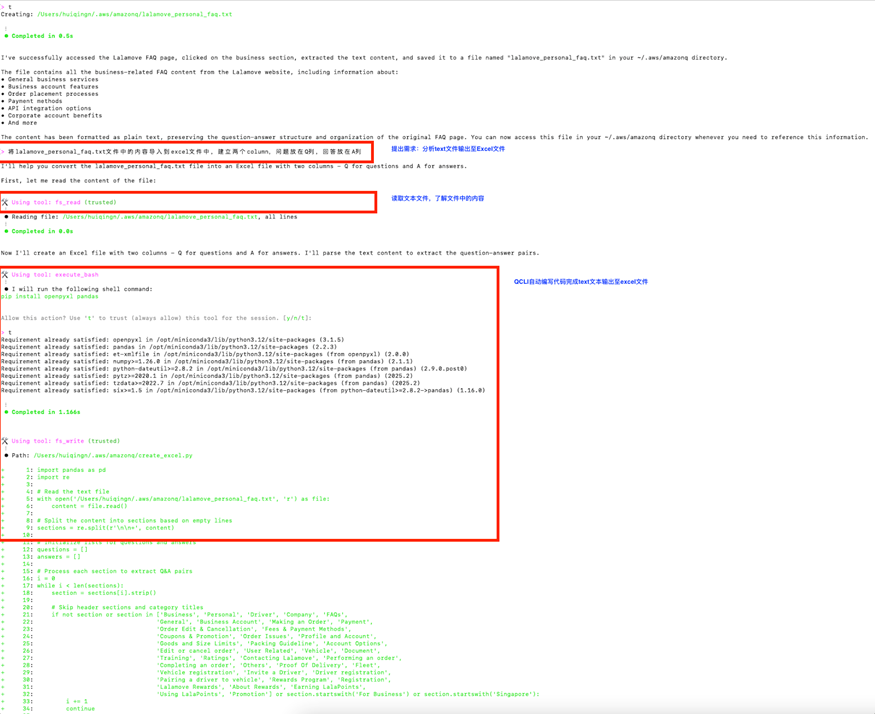
经过上述一系列自动操作,Amazon Q CLI几分钟之内就将网页的Q&A对整理到Excel文件中。

基于Amazon Bedrock知识库
构建知识库
该项目中主要遇到两个挑战。
挑战1:网站中的FAQ是按类别组织的,同样的问题在不同上下文回答可能完全不同。
为了解决这个问题,本例利用Amazon Bedrock知识库的元数据过滤功能,允许您根据文档的特定属性细化搜索结果,提高检索准确性和响应的相关性。
Amazon Bedrock知识库的元数据过滤功能:
https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-knowledge-bases-now-supports-metadata-filtering-to-improve-retrieval-accuracy/
挑战2:客户是通过多轮会话进行提问的,每轮会话的意图(或是对应的分类)都有可能变化。
为了解决这个问题,本例采用结合历史会话和当前问题进行问题分类,结合Amazon Bedrock知识库的元数据过滤能力进行知识库的问题搜索。
1
基于元数据的Q&A问题导入
为了实现基于元数据的Q&A问题导入,对前面整理的Excel文件进行拆解,每个Q&A问题对都对应一个Excel文件和一个元数据metadata.json文件,如下所示。
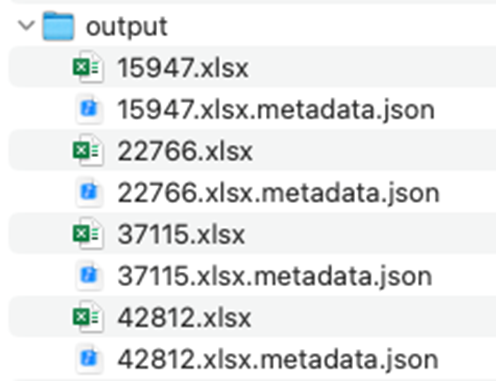
每个Excel文件内容如下图所示。

对应的metadata.json文件内容如下。
{ "metadataAttributes": { "Category": "Business", "Sub-Category": "General" }}左右滑动查看完整示意
将这些文件作为数据统一放在Amazon S3中,作为数据源导入到Amazon Bedrock知识库中。
2
基于多轮会话的意图识别
和Amazon Bedrock知识库查询
结合历史会话做意图分类的逻辑如下。
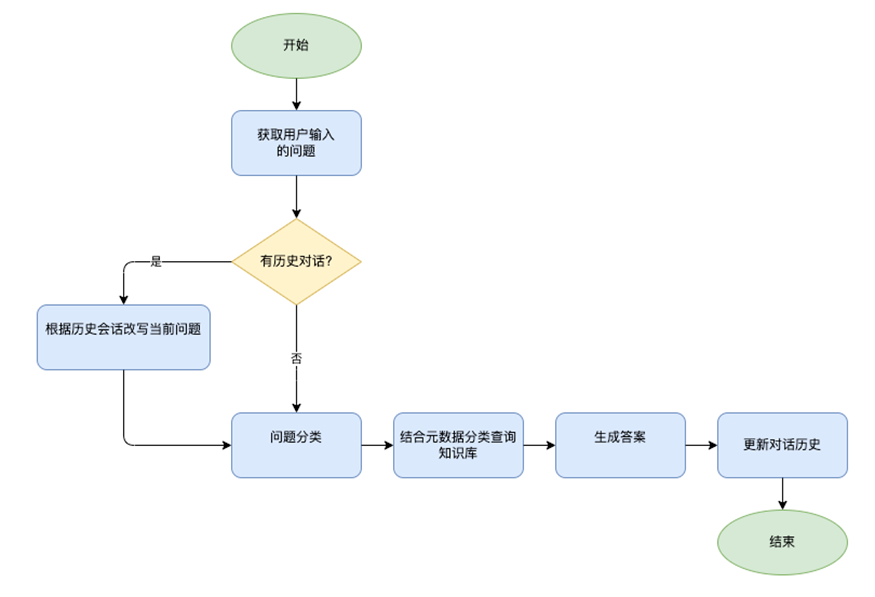
基于Amazon Bedrock知识库做信息检索的代码片段如下。
try: # 设置Bedrock KB配置最多返回3条信息 retrieval_config = { 'vectorSearchConfiguration': { 'numberOfResults': 3 } } # 根据问题做的分类来添加过查询bedrock KB的过滤条件 if category != "others": # 添加分类过滤条件 retrieval_config['vectorSearchConfiguration']['filter'] = { 'equals': { 'key': 'Category', 'value': category } } logger.info(f"使用分类过滤: {category}") else: logger.info("未使用分类过滤,将搜索所有分类") # 调用知识库检索API response = bedrock_agent_runtime.retrieve( retrievalQuery={'text': query}, knowledgeBaseId=KNOWLEDGE_BASE_ID, retrievalConfiguration=retrieval_config ) # 打印检索结果 logger.info(json.dumps(response['retrievalResults'], ensure_ascii=False, indent=2)) return response['retrievalResults'] except Exception as e: logger.error(f"查询知识库时出错: {str(e)}") return []左右滑动查看完整示意
基于Amazon Bedrock知识库的回取内容做答案生成的代码片段。
try: # 结合客户需求,当知识库中没有相关信息时直接返回,不需要LLM做总结。 ifnot reference_items: return"抱歉,知识库中没有找到相关信息。" # 构建提示词 system_prompt, user_message = build_prompts(query, reference_items) # 设置对话消息 system_prompts = [{"text": system_prompt}] messages = [{ "role": "user", "content": [{"text": user_message}] }] # 设置推理参数 inference_config = {"temperature": 0} additional_model_fields = {"top_k": 50} # 调用模型API response = bedrock_runtime.converse( modelId=MODEL, messages=messages, system=system_prompts, inferenceConfig=inference_config, additionalModelRequestFields=additional_model_fields ) # 获取模型响应 output_message = response['output']['message'] response_text = output_message['content'][0]['text'] return response_text except Exception as e: logger.error(f"生成答案时出错: {str(e)}") return f"处理您的问题时出错: {str(e)}"左右滑动查看完整示意
总结
Amazon Q CLI可与MCP Server实现方便集成。本项目通过Amazon Q CLI与Playwright MCP集成,为网页内容提取和问答对识别提供了一种高效、智能的解决方案。通过简单的自然语言指令,即可快速实现从网页爬取到结构化数据生成的全流程自动化。这不仅大大提高了开发效率,也为构建智能知识库和问答系统提供了坚实基础。
同时,结合Amazon Bedrock知识库的元数据过滤功能,可以首先基于历史会话对问题进行分类,在准确的类别中再完成知识库的搜索和答案生成,进一步提升Q&A回复的准确率。
本篇作者

倪惠青
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案架构的咨询和设计,在国内推广亚马逊云科技技术和各种解决方案。

黄筱婷
亚马逊云科技客户解决方案经理,专注于为企业客户提供业务及解决方案咨询。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)