大模型笔记:KV cache
假设模型最终生成了四个token可以发现重复地计算,但其实只计算一次就行了——>把每一步(计算记为一步)计算的KV缓存起来。
·
1 为什么要使用KV cache
假设模型最终生成了四个token
- 对于第一个token,他的attention的计算方法为:
- 有了第一个token之后,生成第二个token的时候:

- sottmaxed表示已经逐行softmax后的结果

- 同理,对于第三个token:


可以发现重复地计算
,但其实只计算一次
就行了
——>把每一步(计算记为一步)计算的KV缓存起来
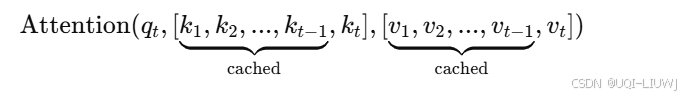
KV缓存仅应在推理阶段使用。若在训练中启用,可能会导致意外错误。
2 代码实现

3 huggingface中的kv cache
- DynamicCache(默认缓存)
DynamicCache是多数模型默认使用的缓存类,它支持动态扩展缓存大小,随着生成的进行不断增长- 若不想使用缓存,可在
generate()中设置use_cache=False
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import os
model = AutoModelForCausalLM.from_pretrained(
"gpt2",
device_map="auto", # 自动分配到所有可用设备(优先 GPU)
torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left")
model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt")
generated_ids = model.generate(**model_inputs,use_cache=False)- 内存高效缓存
- KV 缓存通常会占据大量内存,尤其在长上下文生成任务中可能成为瓶颈
- 此类缓存策略通常牺牲部分速度换取显著的内存节省,对大模型和显存有限的场景尤为重要
-
Offloaded Cache(缓存卸载) 将除当前层以外的 KV 缓存移至 CPU,仅将当前层的缓存保留在 GPU
每一层处理完毕后,该缓存异步卸载或预取
使用方法:在generate()函数中设置cache_implementation="offloaded"
Quantized Cache(量化缓存) QuantizedCache通过将 KV 缓存量化为更低精度(如 int2、int4、int8)来减少内存占用。目前支持两种后端:
- HQQQuantizedCache:支持 int2、int4、int8;
- QuantoQuantizedCache(默认):支持 int2、int4。

这里补充说一下“axis-key: 1” 是什么意思
-
这里的
axis-key: 1表示:当我们要对Key张量做量化时,我们“按第 1 个维度”(也就是 num_heads)来分块处理或量化。 -
为什么要这么做呢?
-
如果直接对整个张量整体量化,会丢失太多信息
-
所以通常采取 “按某个维度切片,再分别量化每一块” 的策略,以减少信息损失
-
axis = 1(num_heads):按注意力头切分,然后量化
-
每个注意力头在语义上是相互独立的
-
不同注意力头的信息分布不同,一起压缩会让模型变笨
-
拆开来量化可以保留更多细节,压缩损失小
-
-
- 提速优化缓存
- Static Cache(静态缓存)
- 预先分配固定大小的 KV 缓存,可避免动态扩容和触发编译重算
- 使用方法:generate里面设置:cache_implementation="static"
- Offloaded Static Cache(卸载静态缓存)
- 与
OffloadedCache类似,但 KV 缓存大小为固定值 - 使用方法:generate里面设置:cache_implementation="offloaded_static"
- 与
- Sliding Window Cache(滑动窗口缓存)
- 该缓存只保留最近
sliding_window个 token 的 KV 对 - 适用于支持滑窗注意力的模型(如 Mistral)
- 老 KV 会被丢弃
- 使用方法:generate里面设置:cache_implementation="sliding_window"
- 该缓存只保留最近
- Static Cache(静态缓存)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)