大模型系列(七)---A Survey on Large Language Models for Recommendation
prompt tuning和instruction tuning的区别主要是,prompt tuning的训练任务是一个特定的任务,而instruction tuning的训练任务是多个任务。比如,“Zero-shot recommendation as languagemodeling”挖掘电影推荐任务的提示,“Large language models arezero-shot rankers
本篇是大模型用于推荐系统综述论文的阅读(翻译)笔记,论文名称”A Survey on Large Language Models for Recommendation“,由中国科学技术大学、BOSS直聘、香港科技大学的研究者发表于2023年的 Information Retrieval,论文地址:https://arxiv.org/pdf/2305.19860.pdf
Abstract
LLM用于推荐系统的关键是用LLM基于文本的高质量表示特征和外部知识建立用户和推荐item之间的相关性。
综述将基于LLM的推荐方法分为两大类:判别式LLM推荐和生成式LLM推荐,并总结了每种方法的技术和性能。
建立了一个LLM用于推荐系统的github论文库,地址是 https://github.com/WLiK/LLM4Rec
Introduction
相比于传统的推荐系统,基于LLM的推荐模型能更有效地捕捉上下文信息、综合用户查询、项目描述和其他数据。
在用户交互行为有限的稀疏推荐场景中,LLM通过zero/few shot能力为推荐系统带来新的可能性。
凭借语言生成能力,基于LLM的推荐系统能提升推荐结果的可解释性。
生成式语言模型能提升推荐系统的个性化能力和上下文相关性。
本综述的贡献:
1、系统性的综述了基于LLM的推荐系统相关研究。
2、第一篇专门针对生成式LLM推荐系统的综述。
3、从建模范式的角度出发,将LLM推荐系统分为三个独立的范式。
4、分析了现存方法的优缺点和局限性。
建模范式和分类
在推荐系统中应用LLM的范式可以分为三个类别:
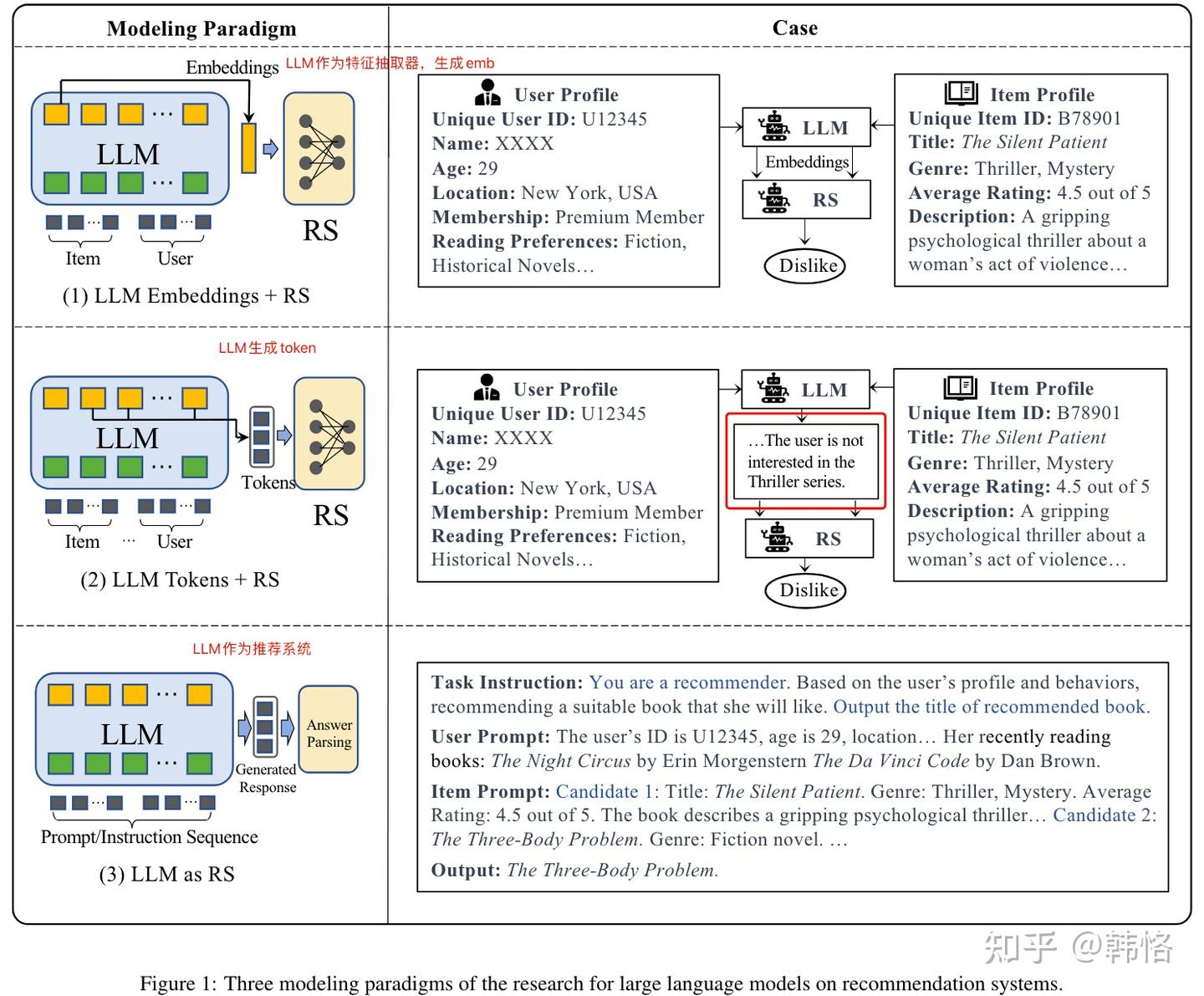
1、LLM Embeddings + RS。将LLM作为特征抽取器,输入用户或item特征,LLM输出特征的embedding,推荐系统使用该embedding进行推荐。
2、LLM Tokens + RS。给LLM输入用户和item的特征,LLM生成具有潜在偏好信息的token,推荐系统使用该token进行推荐。
3、LLM as RS。将LLM作为推荐系统,输入用户偏好、用户行为和任务的instruction,由LLM生成推荐结果。
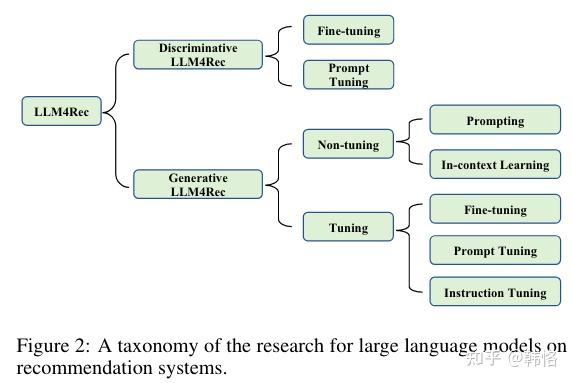
将现有的工作从生成和判别的角度进行划分,可以分为判别式LLM推荐系统和生成式LLM推荐系统,判别式属于上述的范式1,生成式属于上述范式的2和3。
三个范式示例:
LLM应用于推荐系统任务的研究分类如下:
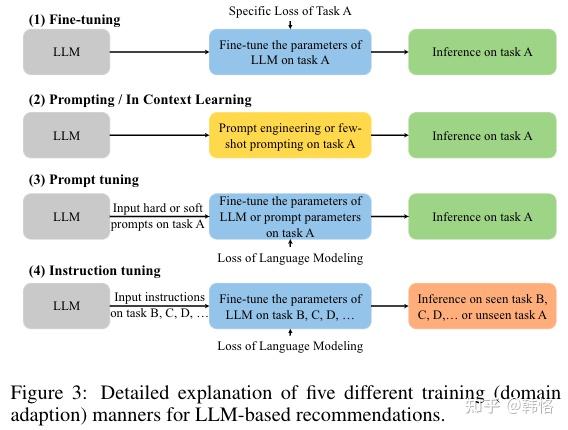
上图中,不同的tuning说明如下:
判别式LLM推荐
1、 推荐领域的LLM主要指的是BERT系列模型,依托于模型在自然语言理解上的能力,这类模型在下游任务中通常被当做embeeding提取器,并通过fine-tuning将预训练模型的表示和特定数据对齐(在特定数据上fine-tuning,使得模型适用于特定领域)。
2、除了fine-tunning,也有一些prompt tuning的训练策略研究。
fine-tuning
fine-tuning过程包括用已经学好的参数初始化预训练语言模型、用推荐数据集继续训练模型两步。推荐数据集通常包括用户和item的交互、item的描述、用户画像和其他任务相关的上下文特征。fine-tuning阶段的学习目标可能和预训练阶段不同,模型参数也会在特定任务数据集的训练下进行更新,以使模型适用于特定的推荐任务。
大多基于bert的推荐方法可以被归于此类。比如,学习用户表示的U-BERT(U-BERT: pre-training user representationsfor improved recommendation),在无标签行为数据上进行半监督用户建模的UserBERT(Userbert: Contrastiveuser model pre-training),轻量级重排模型BECR(Lightweight composite re-ranking for efficient keyword search with BERT),用于排序的端到端多任务学习框架(A multi-task learning framework for productranking with BERT)。其他特定任务、场景上的研究还包括组推荐(pre-training user representations forephemeral group recommendation)、搜索匹配(Reprbert: Dis-tilling BERT to an efficient representation-based relevancemodel for e-commerce)、ctr预估(Ctr-bert: Cost-effective knowledge distillation for billion-parameter teacher models)、BERT用于推荐(Bert4rec: Sequen-tial recommendation with bidirectional encoder represen-tations from transformer和Resetbert4rec: A pre-trainingmodel integrating time and user historical behavior for se-quential recommendation)、序列表示学习( To-wards universal sequence representation learning for rec-ommender systems)、基于大模型编码器的子序列推荐(Exploring the upperlimits of text-based collaborative filtering using large lan-guage models: Discoveries and insights和Opt: Open pre-trained transformer language models)。
值得一提的是,针对问题“将itemID的embedding替换为最好的模态编码器后,纯基于模态的推荐系统(MoRec) 是否能优于或者匹配纯基于ID的模型 (IDRec) ?”,论文“Where to go next for recommender sys-tems? id-vs. modality-based recommender models revis-ited”表明,在经典推荐框架下,MoRec能打平甚至优于IDRec。
总的来说,将BERT的fine-tuning应用到推荐系统,可以融合语言模型中蕴含的外部知识和用户个性化偏好信息,进而提升推荐准确度;此外,这种方式也对新item的冷启具有一些效果。
prompt tuning
prompt tuning试图通过硬、软提示和label word verbalizer(不知道怎么翻译) 将推荐目标和预训练loss进行对齐。比如,论文“What does BERT know about books, movies and mu-sic? probing BERT for conversational recommendation”使用BERT的NSP任务头的输出来判断搜索词、推荐query-doc的相关性,实验表明,不经过任何fine-tune的BERT模型可以对相关item进行排序;“Improving conversational recommendationsystems’ quality with context-aware item meta informa-tion”开发了一个对话式推荐系统,系统使用基于BERT的编码器将推荐item直接编码成embedding; “Prompt learning for news recommendation”将提示学习范式用于新闻推荐,做法是将用户对候选新闻的点击预测转化为完形填空任务。该工作实验表明,使用多个prompt集成后,推荐系统的性能获得显著提升。
生成式LLM推荐
不同于判别式LLM需要将LLM中学到的表示和推荐任务进行对齐,生成式LLM应用in-context学习、prompt tuning、instruction tuning等技术直接生成推荐结果。
根据是否调整模型参数,生成式LLM推荐方法可以分为两大范式:不微调和微调。
不微调范式
将LLM应用与推荐任务时,不改变模型参数。根据prompt是否包括示例,可以分为prompting和in-context 学习两类。
prompting
这类工作旨在设计更合适的指令和提示,以帮助LLM更好的理解和完成推荐任务。
相关工作包括“Is chatgpt a good recommender? Apreliminary study”,论文系统的评估了ChatGPT在5个推荐任务上的性能;“Uncovering chatgpt’s capabilities inrecommender systems”分析了ChatGPT在point-wise、pair-wise、list-wise三个信息检索任务上的能力;“Large languagemodels are competitive near cold-start recommenders forlanguage-and item-based preferences”设计了三个提示模版,对应只使用item属性、只使用用户偏好和用户偏好与item特征融合的推荐任务;“ Towards open-world recommen-dation with knowledge augmentation from large languagemodels”引入了因子提示(factorization prompting)。
也有一些工作专注于特定推荐任务的prompt设计。比如,“Zero-shot recommendation as languagemodeling”挖掘电影推荐任务的提示,“Large language models arezero-shot rankers for recommender systems”提出了两个提升序列推荐能力的提示方法。为解决输入词长度受限的问题,“ Is chatgptgood at search? investigating large language models as re-ranking agent”提出了滑动窗口提示策略。
除了直接生成推荐结果,LLM还可以用于特征生成。“A first look at llm-powered generativenews recommendation”介绍了3种提示,可以将LLM用于新闻推荐任务的特征增强;“Zero-shot next-item recommendation using large pretrained lan-guage models”设计了2种提示,可以用LLM生成用户偏好关键词,以及从用户交互历史中抽取有代表性的电影,以提高电影推荐的效果。
此外,LLM还可以用于推荐系统的控制器。“Chat-rec:Towards interactive and explainable llms-augmented rec-ommender system”设计了一个基于ChatGPT的交互推荐框架,框架通过多轮对话理解用户的需求,然后调用推荐系统得到推荐结果;“Generative recommen-dation: Towards next-generation recommender paradigm”提出了一个生成式推荐框架,框架使用LLM控制什么时候推荐已有的item,什么时候生成一个新的item给用户。
In-context 学习
In-context学习是可以将GPT-3和其他LLM模型快速应用到新任务的技术,给模型少量的输入和label对,模型可以在不改变参数的前提下针对没见过的输入给出预测label。
这个方向的工作主要是尝试如何在提示中加入示例,以让LLM更好的理解推荐任务。“Large language models arezero-shot rankers for recommender systems”将输入交互序列作为示例,“Is chatgpt a good recommender? Apreliminary study”和“Uncovering chatgpt’s capabilities inrecommender systems”对不同的推荐任务设计示例模板,“Rethinking theevaluation for conversational recommendation in the era oflarge language models”使用合适的示例控制LLM的输出格式和内容。
微调范式
微调范式可以分为三类:fine-tuning、prompt tuning、instruction tuning。fine-tuning的方式和判别LLM推荐类似,LLM被用作提取用户或item表示的编码器,模型参数在特定loss函数作用下或下游推荐任务上进行更新。prompt tuning和instruction tuning的输出是文本,模型参数在语言模型的loss下训练。prompt tuning和instruction tuning的区别主要是,prompt tuning的训练任务是一个特定的任务,而instruction tuning的训练任务是多个任务。
fine-tuning
“Generative sequential recommendationwith gptrec”提出了基于GPT-2的生成式序列推荐模型GPTRec,“Do llms understand userpreferences? evaluating llms on user rating prediction”将用户的历史交互作为提示,并将推荐中的评分预测任务建模成多类别分别和回归任务。“Exploring the upperlimits of text-based collaborative filtering using large lan-guage models: Discoveries and insights”研究不同LLM模型对基于本文的协同过滤的影响,论文发现使用更强的LLM作为文本编码器可以获得更好的推荐效果。
prompt tuning
在这个范式中,LLM输入用户和item的信息,输出用户对item的偏好或用户可能感兴趣的item。
“Stanford alpaca:An instruction-following llama model”提出的TALLRec使用两阶段进行微调:首先在自指示(self-instruct)数据上fine-tuning,然后使用用户的历史序列作为输入、yes或者no的反馈作为输出进行推荐任务微调。“Genrec: Large language model for generative recommen-dation”提出的GenRec使用LLM的生成能力直接生成推荐item,做法是将已经得到的item转化成提示,然后用LLM生成下一个item。“ Palr: Personalization aware llmsfor recommendation”使用LLM生成用户偏好,以将LLM应用于推荐的多阶段方法。”Leveraging large language models in conversational rec-ommender systems“提出的RecLLM包含一个对话管理模块,用一个LLM和用户对话,一个使用LLM的排序模块来匹配用户偏好,一个基于LLM的用户模拟器生成用户对话来优化系统。”Pbnr: Prompt-based news recommender sys-tem“提出的PBNR用设计好的模板将用户和新闻组织起来作为提示输入到LLM中,为了提高LLM在新闻推荐任务中的效果,PBNR在训练中使用了排序loss和语言生成loss。”Gpt4rec:A generative framework for personalized recommenda-tion and user interests interpretation “将推荐任务定义成查询query生成+搜索问题,使用LLM生成多样、可解释的用户兴趣表示,并将其作为查询query。
在fine-tuning的基础上也可以继续promp tuning,以获得更好的性能。”Towards unified conversationalrecommender systems via knowledge-enhanced promptlearning“设计一个名叫UniCRS的基于知识增强提示学习的对话式推荐系统,作者先冻结了LLM的参数,然后通过提示学习训练推荐任务的软提示。”Per-sonalized prompt learning for explainable recommendation“借助LLM的生成能力得到对推荐结果用户可理解的说明。
Instruction tuning
这个范式是指用不同的指令对LLM进行微调,以让模型适用于多个任务。这样微调后的模型zero-shot能力更强。
”Recommendation aslanguage processing (RLP): A unified pretrain, personal-ized prompt & predict paradigm (P5)“在5类指令上微调T5模型,”M6-rec: Generative pre-trained language models are open-ended recommendersystems“在3类任务上微调M6模型,”GBERT: pre-training user representations forephemeral group recommendation“设计了39个指令模板,并自动化地生成了大量用户个性化指令数据来微调一个3b的FLAN-T5-XL模型。实验结果表明,这种方法可以击败包括GPT3.5在内的多个竞品模型。
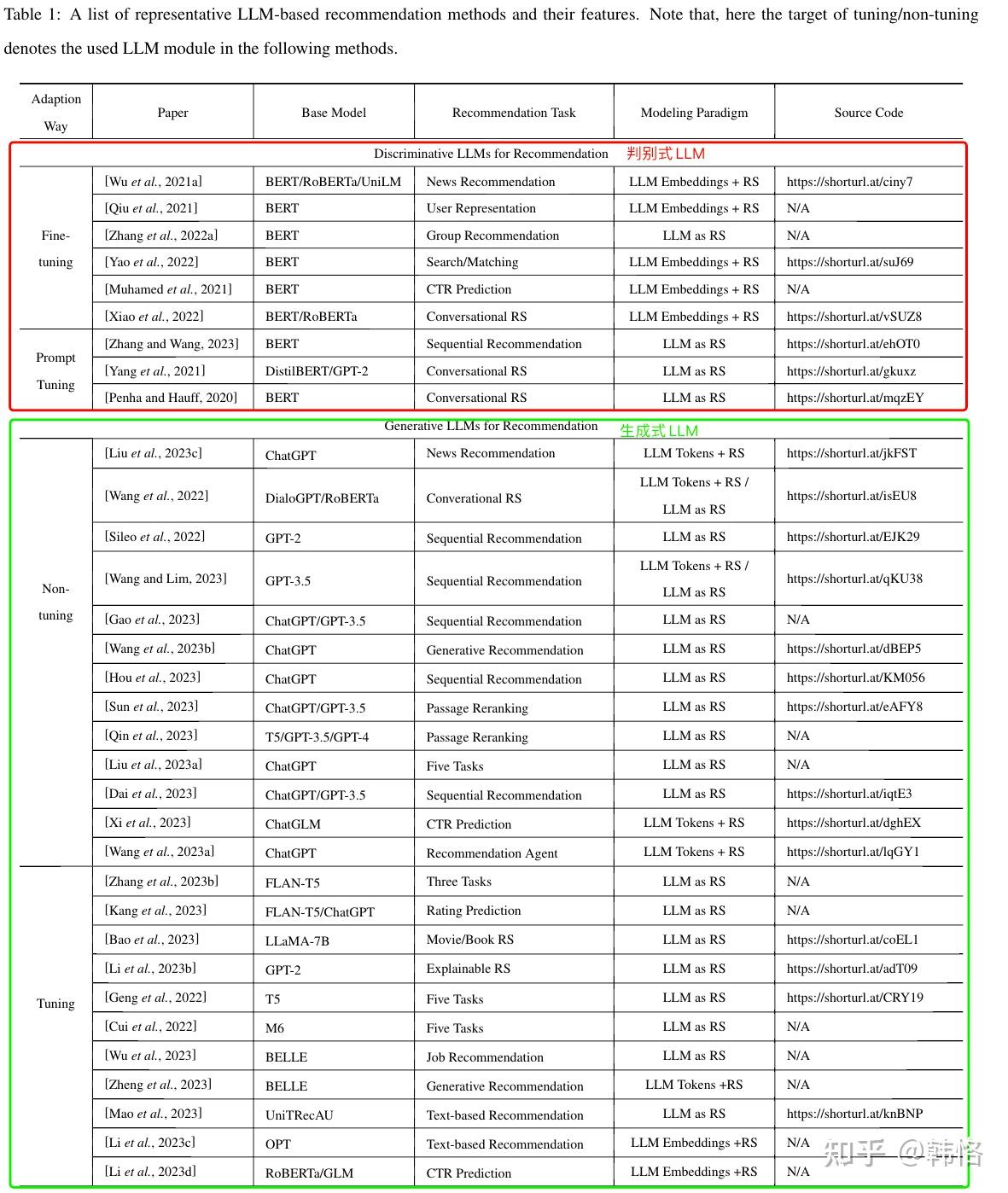
判别式、生成式LLM推荐方法整理如下:
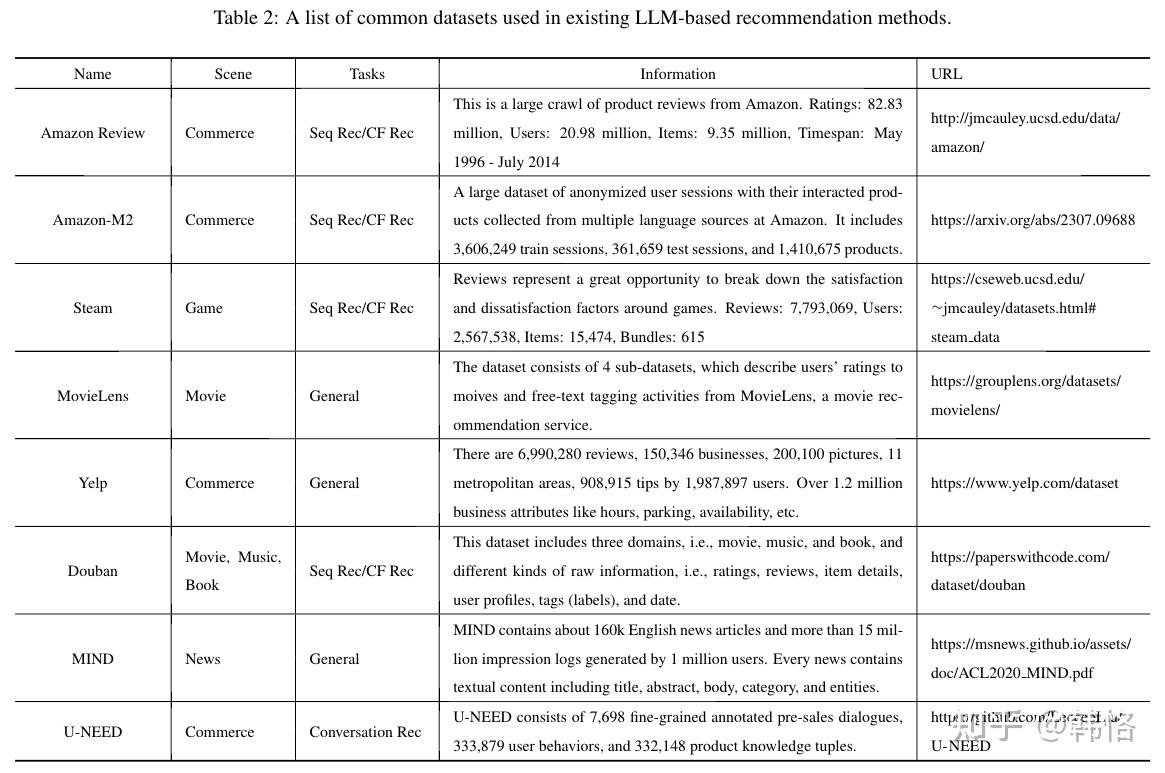
基于LLM的推荐方法使用的公共数据集整理如下:
共识
模型偏差
模型的偏差包括位置偏差(position bias)、流行度偏差(popularity bias)和公平性偏差(fairness bias)。
- 位置偏差。生成式LLM推荐范式中,用户行为序列、推荐候选item等信息以文本序列的方式输入到模型中的,这会带来语言模型内在的位置偏差问题,比如候选item的输入顺序影响LLM推荐模型的排序结果--LLM给输入序列中前面的item更高的优先级。” To-wards universal sequence representation learning for rec-ommender systems “采用随机采样的方式缓解位置偏差的影响。
- 流行度偏差。LLM的排序结果受被排序item的流行度影响,原因是流行的item在LLM的训练语料里出现的概率更高,导致LLM在排序时给其更高的位次。因为流行度偏差问题与LLM的训练语料相关,该问题的解决依然面临挑战。
- 公平性偏差。该偏差指的是预训练模型显示出与某些敏感属性相关的不确定性问题,比如推荐结果受用户的性别或种族主导。公平性偏差受训练数据影响,导致模型在进行推荐时,会假设用户属于某个特定的群组,这在商业部署时可能导致争议性问题。
推荐任务的提示设计
- 用户、item表示。单纯地用item名称表示item、用用户交互序列的item名称表示用户信息对于建模用户和item来说是不足的,将用户的异构行为序列(如电商场景的点击、添加、购买)转化为自然语言输入到模型中很有必要。ID类特征在传统的推荐模型中被证明很有用,但如何将其放入提示中以提高个性化推荐的效果是一个挑战。
- 有限的文本长度。输入文本长度限制了用户行为序列和候选item的长度,解决该问题的方法包括”Zero-shot next-item recommendation using large pretrained lan-guage models“中提出的从用户行为序列中选择有代表性的item作为输入和”Is chatgptgood at search? investigating large language models as re-ranking agent“提出的滑动窗户输入候选item的方法。
有前景的能力探索
- zero/few-shot推荐的能力。这个能力有助于解决推荐系统冷启动问题,但如何选择有代表性的示例是个难点。
- 推荐解释的能力。可以使用LLM的生成能力给推荐结果生成一个好的解释说明。
评估相关问题
- 生成结果控制。LLM的生成结果可能和我们预期不一致,比如模型生成结果的格式和预期不符,甚至拒绝提供结果。此外,生成模型在list-wise的推荐任务上效果欠佳。
- 评估指标。因为基于LLM的推荐模型可能生成不在历史数据里的item(不曾给用户推荐过的item),如何评估该item的好坏是一个开放问题。
- 数据集。缺少适合LLM效果评测的测试集。
- 其他问题还包括模型继续训练时的知识遗忘问题、模型在线部署时计算成本高的问题等。
总结
- 论文整理了大模型应用于推荐系统的相关连接。
- 将现存的工作分为判别模型和生成模型两类。
- 第一篇针对生成式LLM推荐系统的综述。
- 总结了LLM用于推荐场景的共识和挑战。
最后,再次安利github库,作者整理了大量文献的论文地址、代码地址、开源数据集地址和开源出来的大模型地址。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)