51c大模型~合集180
这个基准会基于任务的一个个关键节点,也就是 “里程碑”,对在动态 GUI 环境中执行任务的 Agent 进行精确打分,避免了 “不是满分,就是零分” 的单一评判标准,并且覆盖了社交、影音、购物、旅行、外卖等多个领域的国产主流 App。光聪明还不够,反应慢也是硬伤。即使是提到的大多数面向消费者的 AI 功能,比如视觉智能和 iMessage、FaceTime 中的实时翻译,早在今年 6 月的 WWD
我自己的原文哦~ https://blog.51cto.com/whaosoft/14174583
#AgentScope
阿里AgentScope发布,掀翻了国产Agent的餐桌
在近年来,人工智能从单一模型到多模态、从AI Agent到Agentic AI的过渡,从工具调用到完整工作流,已经形成了一个由“智能体”驱动的全新生态。阿里的通义实验室最新发布了一款能够对标LangGraph的企业级智能体开发框架AgentScope 1.0,它将消息驱动与分层架构深度融合,为企业级应用提供了一套开箱即用、可扩展且易维护的方案。我们先来看看效果:


阿里先后发布过一个Mobile-Agent和Qwen-Agent,其中Qwen-Agent就是网页版Qwen的后端使用智能体框架,虽说也很稳定,但是略显简陋,后面有退出专为编程设计的Qwen-code,可以说阿里在智能体开发框架方脉年积累的经验也着实不少了,这次推出的AgentScope,可以看出来,这是一款集大成者,是一款非常全面、稳定的企业级的智能体开发框架。
在大语言模型(LLMs)快速发展的推动下,Agent能够将内在知识与动态工具使用相结合,大幅提升了其处理现实任务的能力。顺应这一发展趋势,AgentScope 在新版本(1.0)中实现了重大改进,旨在全面支持基于工具的灵活、高效智能体 - 环境交互,助力智能体应用构建。具体而言,团队提炼了智能体应用所需的核心基础组件,并提供统一接口和可扩展模块,使开发者能够轻松利用最新技术进展(如新型模型和模型上下文协议 MCPs)。此外,我们将智能体行为基于 ReAct 范式构建,并依托系统化的异步设计提供高级智能体层基础设施 —— 这不仅丰富了人机交互与智能体间交互的模式,还提升了执行效率。在此基础上,我们集成了多个针对特定实际场景的内置智能体。AgentScope 还提供了完善的工程化支持,为开发者打造友好体验:我们设计了带有可视化工作室界面的可扩展评估模块,让长轨迹智能体应用的开发更易于管理和追踪;同时,AgentScope 提供运行时沙箱(runtime sandbox)以确保智能体安全执行,并助力其在生产环境中快速部署。通过这些增强特性,AgentScope 为构建可扩展、自适应且高效的智能体应用奠定了实用基础。
更多关于AgentScope 1.0的内容可以阅读原文:
- 论文链接:https://arxiv.org/abs/2508.16279
- 开源仓库:https://github.com/agentscope-ai/agentscope
- huggingface:https://huggingface.co/papers/2508.16279
,时长04:02
智能体层基础设施
本章围绕智能体层核心架构、内置智能体及多智能体协作模式展开,核心是基于ReAct范式构建高效、灵活的智能体运行体系:
- 基于ReAct范式的架构:以ReAct范式(结合推理与行动)为核心架构,智能体具备三大核心功能——Reply(接收用户查询后推理、行动并生成响应)、Observe(处理外部信息并更新内部状态,不生成用户响应)、Handle Interrupt(处理外部中断信号,支持人机协作)。同时提供三大关键特性:实时控制(通过asyncio取消机制暂停ReAct循环,保留中断上下文)、并行工具调用与动态工具供应(单推理步骤生成多并行工具调用,通过
reset_equipped_tools动态激活/停用工具组)、状态持久化与非侵入式定制(基于StateModule实现状态管理,通过钩子函数修改运行时行为)。 - 内置智能体:包含三类场景化智能体——深度研究智能体(集成Tavily搜索MCP,核心能力为查询扩展、分层反思、过程总结,结合记忆模块生成报告)、浏览型智能体(集成Playwright MCP,支持子任务分解、视觉-文本信息融合、多标签浏览、长网页分块处理)、元规划智能体(支持分层任务分解、动态工作智能体实例化、持久状态管理,可自动切换“简单ReAct模式”与“规划模式”)。
- 多智能体协作:支持两种核心范式——“智能体作为工具”(主智能体调用专业智能体处理子任务,智能体可独立开发、无缝集成)、“智能体对话”(通过Pipeline封装交互模式<顺序/条件/循环>,通过MsgHub实现集中消息广播,保障多智能体上下文同步)。
开发者友好体验
本章聚焦降低开发门槛的工具集,通过评估、可视化与运行时系统覆盖开发全流程:
- 评估模块:采用分层架构(Task:单个评估单元,含输入与真值;SolutionOutput:标准化智能体输出,含执行轨迹;Metric:支持分类/数值型指标;Benchmark:聚合任务形成评估 suite),提供两类评估器——GeneralEvaluator(单进程顺序执行,适合调试)、RayEvaluator(基于Ray分布式计算,适合大规模评估),支持结果持久化与中断续跑。
- Studio可视化平台:核心功能包括——聊天机器人式对话与追踪(实时流传输消息/追踪数据,可视化交互流程,关联对话与执行轨迹)、评估结果可视化(生成性能分布图表,计算置信区间,支持失败轨迹对比)、内置副驾驶Friday(检索技术资源<代码示例/文档>,展示框架高级功能<实时控制/动态工具>)。
- Runtime运行时系统:双核心架构——Engine(将智能体部署为FastAPI服务,支持A2A等多智能体通信协议)、Sandbox(提供隔离环境,支持文件系统/浏览器等专用场景,接口统一),简化部署流程并保障工具执行安全。
典型应用
本章通过5个实操案例展示框架落地能力,覆盖常见智能体应用场景:
- 用户-助手对话:通过ReAct智能体(指定模型/工具集/记忆)与UserAgent构建,支持OpenAI、DashScope等多模型提供商,以消息交互实现对话,用户输入“exit”终止流程。
- 多智能体对话:用MsgHub管理参与者(如教师/学生/医生智能体),通过SequentialPipeline控制发言顺序,支持动态移除参与者并广播状态(如“Bob离开”)。
- 深度研究智能体:基于ReAct扩展,集成Tavily搜索MCP,可自动分解研究任务、补充知识缺口、生成结构化分析报告,适用于学术/市场研究。
- 浏览型智能体:集成Playwright MCP建立状态ful连接,支持网页快照捕捉、分块处理长网页、自动导航/点击,可响应“查询股票价格”等自动化指令。
- 元规划智能体:含规划/工作两类工具集,支持复杂任务分解(如Meta股票分析报告)、工作智能体动态管理,具备状态持久化能力,适合多步骤工作流(数据采集-分析-生成)。
....
#AI还没等到它的「牛顿」
KAN作者刘子鸣~
大家新年快乐!今天和大家分享 KAN 作者刘子鸣最新发布的一篇博客。
过去的一年,我们见证了 Scaling Laws 持续发力,模型能力不断刷新天花板。虽然 AI 社区从未停止对可解释性的探索,但在工程进展如此迅猛的当下,我们对模型内部机制的理解,似乎总是慢了半拍。
刘子鸣在博客中,借用科学史提出了一个发人深省的观点:如果参照物理学的发展史,今天的 AI 可能还远未在这个时代的「牛顿力学」时刻,而是仍处于「第谷(Tycho)时代」,一个拥有大量观测和实验,却尚未来得及系统性总结规律的早期阶段。

我们拥有海量的实验数据和强大的模型,却缺乏对底层现象的系统性梳理。他指出,为了追求短期性能指标,AI 领域跳过了「理解」这一关键步骤,这实际上是在背负高昂的「认知债务」。
更为矛盾的是,当前的学术发表机制往往偏爱「完美的故事」或「巨大的性能提升」,导致大量像「第谷的观测记录」那样碎片化但极具价值的「AI 现象学」工作被忽视。
为此,刘子鸣呼吁建立一种「平易近人的现象学」:不以即时应用为导向,回归到用 Toy Model(玩具模型)进行可控的、多视角的假设驱动探索。他宣布将身体力行,通过博客分享「半成品」的实验笔记,并计划在清华大学开设相关课程,邀请社区共同偿还这笔认知债务,推动 AI 从「炼丹」走向真正的物理学。
明星数据科学家 Jeremy Howard 也在评论区表示赞同,长期以来「实验性观察」几乎无法在 AI/ML 期刊和会议上发表,这种现象无疑阻碍了该领域的发展。

AI 物理学需要思维模式的转变
大家都知道,物理学领域主要沿着「第谷 — 开普勒 — 牛顿」这一科研范式发展,而如果借用这一类比来理解 AI 的发展阶段,那么今天的 AI 研究很大程度上仍然停留在「第谷阶段」,即以「实验与观察」为主的阶段。
但即便是在「观察」这一层面,业界目前所做的事情也极其原始:大多数人关注的仍然只是少数几个基于性能的指标调优。这背后,源于物理学与 AI 在目标上的根本差异。
物理学的目标是通过「理解世界来改变世界」,其中「理解」本身占据着核心地位。因此,这个领域对那些能够提供洞见即便(暂时)没有实际用途的工作,也具有极高的容忍度。
相比之下,AI 的目标则是「直接改变世界」,近些年 Scaling Laws 的盛行使得整个领域得以跳过「理解」这一阶段,直接进入对 AI 本身进行改造和强化。但这似乎构成了一种认知债务(cognitive debt)—— 这种债务迟早是要偿还的,如果不是现在,那也会是在未来。
因此,现在就谈论 AI 的「牛顿力学」阶段还为时过早,即使是在基础现象学层面,仍处于非常早期的阶段。AI 的现象学可以是相对宏观的 —— 连接不同的模型,例如涌现与 Scaling laws,也可以更微观 —— 聚焦于训练动态,例如 Grokking、双下降(double descent)或稳定性边缘(edge of stability)……
我们首先需要发现更多现象,只有这样,我们才会有动力去建立模型,并发展理论来研究它们。
为什么 AI 现象学如此难以发展?
为什么 AI 现象学的发展如此困难?一个原因是论文发表文化在其中扮演了重要角色。
总结来看,当前可发表的工作往往只有两类:在性能上有显著提升的工作(在这种情况下,现象学似乎「没有必要」),或者拥有一个足够吸引人的「故事」。
而所谓「好故事」,通常有两种形式:
- 普适性(Universality):该现象必须在大量不同设定中都能被验证,稳定性边缘(edge of stability)就是一个例子。但这类工作对投稿的要求极高。
- 惊奇性(Surprise):现象必须足够反直觉、足够出人意料。这种情况非常罕见,也高度不可预测,grokking 就是代表性案例。
这也解释了为什么 AI 领域中被反复引用的现象学例子如此之少。在「AI 物理学」仍处于如此早期阶段的情况下,却对现象学提出了过高的期望,反而抑制了它的发展。
朱泽园所写的《大语言模型的物理学》是一项非常出色的工作,但从我与朋友们的交流来看,大家普遍的感受是:这很有意思,但不知道如果自己想进入这个领域,该从哪里开始。
同样的情况也出现在我们自己的工作《叠加导致稳健的神经缩放》《 Superposition Leads to Robust Neural Scaling》中。很多人好奇这样的「故事」是如何被构思出来的。
我无法代表整个 AI 物理学领域的整个研究群体,但从个人经验来看,我花费了大量时间去「包装」一个故事 —— 这既「浪费」自己的时间,也在无形中拉大了与读者之间的距离。
更重要的是,能够被包装成故事的现象极其稀少。许多我个人觉得非常有趣的现象,因为无法整理成一篇论文,最终只能被随意丢弃。
迈向更易理解的现象学
因此,我倡导一种更易于接近、更具包容性的现象学研究方式。这种方法将比当前的 AI 现象学更宽容,也更接近物理学中现象学的精神。它应当:
- 不以即时可用性为导向;
- 不被要求包装成一个完整的「故事」;
- 不限制分析工具,只要它们在描述、预测上是有效的。
同时,它将强调:
- 可控性:使用玩具模型来简化和抽象现实场景,使得结果能够用最少的资源复现(理想情况下,一台笔记本加一个 CPU 就足够了)。
- 多视角刻画:从尽可能多的角度和指标来描述研究对象 —— 就像「盲人摸象」。
- 好奇心或假设驱动的探索:现象应当能够带来新的洞见,定性结果已经足够,定量结果当然更好。
这种「可接近的现象学」也许不容易发表在主流 AI 会议上,但它对于社区建设具有极高价值。
比如,研究者 A 发现了一个现象(关键在于把它公开出来),B 将其与自己此前观察到的现象联系起来,C 将二者统一,D 进行理论分析,E 再将这些洞见转化为算法改进。最终,这五个人可以一起写一篇论文。
但在传统模式下,A 可能只会在一个很小的圈子里合作。就我对 AI 物理学社区的理解,目前这个领域仍然高度碎片化,往往按应用领域分割。例如,做视觉的研究者通常只与其他视觉研究者合作,他们的直觉也主要由视觉任务塑造。
那我们能够做什么
就我个人的经验来看,我是先从写博客开始的,开始以博客文章的形式,分享我们自己的「AI 现象学」研究。读者应当抱有这样的预期:这是同事在分享阶段性结果 —— 工作可能并不完整,但原始数据和思考过程会被透明地呈现出来。
目标有三点:
- 一是迫使自己记录观察结果:正如前面所说,无法写成论文的现象往往会被丢弃。这个尝试部分受到苏剑林博客的启发 —— 他的博客更偏向数学原理,而我的将更强调实验观察(现象学)、「物理直觉」,以及在必要时提供一些(半)定量分析,为未来的数学研究提供问题和直觉。
- 二是吸引志同道合的研究者与学生:如果你对这些问题感兴趣,欢迎联系我,一起探索。
- 课程准备:我计划在清华大学开设一门《Physics of AI》课程。这些博客文章(及配套代码)未来可能会成为课程材料。
那么对于你来说,该如何开始:
- 一是找到你真正关心的问题:例如,研究扩散模型损失函数的参数化方式,或复现已有现象(如 Grokking)。
- 定义一个简单的玩具模型:例如,李天宏与何恺明的 JIT 论文使用一个二维螺旋数据集来研究损失参数化。而理解 grokking 的最好方式就是自己亲手训练一个模加任务。
- 致力于彻底理解这个玩具模型:这是最困难的一步。由于发表文化的影响,我们往往急于从玩具模型跳到更真实的模型。一旦玩具模型给出了「正向结果」,我们就会立刻离开。这是一种监督式使用玩具模型。而我认为,玩具模型在无监督使用时,才能真正展现其力量。既然是玩具,就应当以孩童般的好奇心去对待它,反复把玩,从所有可能的角度理解它(就像盲人摸象)。
当然,我无法保证这些洞见会立刻转化为性能提升,但我相信:如果整个领域持续积累这样的理解,最终一定会发生一次类似渗流(percolation)的相变。
参考链接:
https://x.com/ZimingLiu11/status/2006810684546494522
https://kindxiaoming.github.io/blog/2025/physics-of-ai/
....
#董事长稚晖君发布上纬新材首款机器人
能塞书包还能骑机器狗
2025年的最后一天,上市公司上纬新材董事长彭志辉(稚晖君)发布了一款能装进书包的机器人产品——上纬启元Q1。

这是全球首款最小尺寸(0.8m)、实现全身力控的人形机器人,也是智元机器人联合创始人稚晖君担任上纬新材董事长以来,发布的首款xx智能机器人产品。
虽然体型迷你,但大机器人能做的,启元Q1也能做。

大机器人做不了的,启元Q1还能做。

(我骑过狗你骑过吗?)
而前段时间让网友猜疯了的 “大有可为” 神秘海报,也终于在这次的发布视频中正式揭晓答案。
其中醒目的1.88,既不是身高,也不是售价,而是启元Q1的体积(立方米)——一个被压缩到背包级的人形机器人尺寸。
启元Q1是一款怎样的机器人?
从产品定位上看,稚晖君这次的新作启元Q1,是一款面向个人用户、开发者,科研、陪伴、创作场景的小尺寸人形机器人。
相较于市面上的全尺寸人形机器人,启元Q1最直观的突破的就是把体型和重量狠狠压缩——
甚至能主动来个双折叠,被你揣进书包。

值得一提的是,这种小型化设计,并不只是为了方便携带。更轻的重量,让机器人本身更耐造,也把使用和试错成本一起打了下来,更适合个人和小团队反复折腾。
在产品能力上,启元Q1反复强调了一个关键词——全身力控。
简单来说,全身力控并不意味着机器人“力气更大”,而是全身关节都能感知和调节受力。
传统机器人更多是“按角度走动作”,一旦遇到外力干扰,往往要么硬顶、要么停机。
而具备全身力控的机器人,在被推、被拉、与环境接触时,会根据外力变化实时调整动作,避免僵硬对抗。

这一能力让机器人在被推、被拉或与环境接触时,表现出更自然的物理交互特性,也是xx智能落地过程中较为关键的一项基础能力。
在使用场景上,启元Q1可以充分满足各类用户的需求。
在科研与教育场景中,它支持开放的SDK与HDK接口,可用于xx智能算法验证、教学实验和动作规划研究。
小尺寸带来的直接好处是——不需要复杂防护结构,随拿随用,适合高频实验。
在个人交互场景中,启元Q1接入启元灵心平台,支持自然语言对话、知识问答、英语教学和动作示范,并通过柔性阻抗控制,让人机交互更接近“可长期共处”的状态。
而在创作者和极客用户方向,启元Q1采用模块化结构设计,支持3D打印外壳和外观定制,并可通过灵创平台编排动作、语音和行为逻辑,为二次创作留出了足够空间。
这些能力背后,真正的技术难点集中在一个地方——关节系统。
高性能人形机器人通常依赖QDD(Quasi-Direct Drive)准直驱关节,来实现力控和高动态动作,但这一方案长期面临的问题是:性能好,但难以做小、做轻。
在启元Q1上,上纬启元对QDD关节进行了系统性重构——从材料选择、结构布局,到控制算法的协同设计,将核心关节模块压缩至不到鸡蛋大小,同时保留了力控性能和动态响应能力。
也正因如此,启元Q1成为目前首个在小尺寸形态下实现全身力控的小尺寸人形机器人。
机器人即产品
这次启元Q1的发布,可以被视为稚晖君此前探索的“机器人即服务(RaaS)”路径,在个人机器人市场上的一次延伸。
而这,也恰恰对应了当前xx智能厂商的普遍趋势——在持续服务科研、生产力和开发需求的同时,开始主动探索面向个人用户的产品形态。
长期以来,无论是在工厂中的劳动力替代,还是科研中的实验载体,机器人始终被定义为一种工具。
而今年开始,松延动力推出的Bumi人形机器人(售价 9998 元),以及维他动力推出的大头BoBo机器狗(售价 9988 元),都在指向一个相似方向——
体型更小、价格更低、可被个人用户实际拥有和使用的xx智能产品。
这些产品在保持科研与开发属性的同时,更加关注体积、价格、耐用性和可玩性,而这,也意味着xx智能正从“实验工具”,逐步走向“可使用的产品”。
在2025年即将收官之际,启元Q1正是这一趋势下的一个具体落点——
在科研与产业应用之外,机器人开始被真正放入个人与开发者的日常使用场景之中。
而回看上纬新材的节奏,这一变化并非突然发生:
- 11月6日完成控股权交割,智元系实现绝对控股,彭志辉入选董事候选人。
- 11月25日董事会换届,稚晖君出任董事长。
- 12月31日,发布首款xx智能机器人产品。
短短两个月,这家以材料业务起家的上市公司,就已经是不折不扣的A股xx智能第一股了。
....
#Drift-aware Collaborative Assistance Mixture of Experts for Heterogeneous Multistream Learning
给多流数据配「私教+外援」,漂移来了也不慌
本文作者为:En Yu, Jie Lu, Kun Wang, Xiaoyu Yang, Guangquan Zhang。所有作者均来自于悉尼科技大学(UTS)澳大利亚人工智能研究院(AAII)。
在智慧城市、社交媒体、工业物联网等真实开放动态环境中,数据往往以多流(Multistream)形式并发产生。然而,现实世界并非完美的实验室,这些数据流往往存在异构性,且分布变化各不相同,伴随着复杂的异步概念漂移。
如何让模型既能 “专精” 于单一流的特性,又能 “博采众长” 利用流间相关性,同时还能自适应分布变化?
悉尼科技大学(UTS)研究团队提出了一种全新的漂移感知协作辅助混合专家学习框架 —— CAMEL (Collaborative Assistance Mixture of Experts Learning)。
CAMEL 巧妙地将混合专家模型(MoE)引入流式学习,通过 “私有专家” 与 “辅助专家” 的协作机制,以及自动化专家生命周期管理,完美解决了异构多流学习中的关键问题。该工作已被 AAAI 2026 接收为 Oral 论文。
- 论文标题:Drift-aware Collaborative Assistance Mixture of Experts for Heterogeneous Multistream Learning
- 论文链接:https://arxiv.org/abs/2508.01598
01 引言
在真实应用场景中,数据通常以连续且无限的数据流形式产生,其生成机制往往呈现显著的非平稳性,即数据的联合概率分布随时间发生不可预测的概念漂移。这一特性与经典机器学习所依赖的独立同分布(I.I.D.)假设存在根本冲突。
然而,现有研究大多聚焦于单一或同构数据流的漂移建模,难以应对真实世界中普遍存在的多源异构数据流情形。以智能城市为例,交通传感器、气象观测、公共交通记录及社交媒体等信息流在时间尺度与演化模式上彼此独立,却潜藏着重要的动态关联。若能在概念漂移过程中有效挖掘并利用这些跨流关系,将显著提升决策的准确性与鲁棒性。
现有的方法往往陷入两难:要么假设所有流是同构的,强行统一处理导致模型失配;要么采用静态模型,一旦某个流发生漂移,重新训练会导致 “灾难性遗忘”,而增量微调又可能因为流之间的不同步演化而引发 “负迁移” 。
为此,作者正式定义了异构多流学习(HML)问题,并提出 CAMEL 框架。这是一种动态的、通过协作辅助的混合专家学习框架,通过模块化设计在 “专精 — 协作 — 适应” 之间取得平衡。

图 1:CAMEL 整体框架。每个流的 MoE 模块利用动态的私有专家库和专用的辅助专家,通过多头注意力进行协作融合。系统遵循 “测试 - 诊断 - 适应” 的循环,通过自主专家调节器动态管理专家生命周期以响应漂移信号。
02 方法论与架构设计
研究团队面向 HML 场景下的三大核心挑战:内在异构性、多流知识融合以及异步概念漂移,设计了一套模块化的漂移感知架构。
挑战一:内在异构性
传统的多流学习方法通常假设所有流共享特征空间与标签空间,但现实中不同流可能具有不同维度 (

) 与任务目标 (

)。
CAMEL 为每个流配置异构感知的 “独立系统”:
- 特征对齐: 为每一个数据流
-

- 配备了专属的 特征提取器
-

- ,将不同维度的原始输入映射到一个公共的潜在空间
-

- ,为后续的特征交互奠定基础。
- 任务专精:在输出端,配备了任务特定分类头
-

- ,独立处理各自的分类任务,确保决策层与标签空间的语义对齐。
挑战二:多流知识融合
多流数据的核心价值在于流之间的潜在相关性,但盲目融合所有流的信息会导致负迁移。
CAMEL 除了为每个流维护一组捕捉自身特性的私有专家库外,还引入了一个辅助专家,它利用多头注意力机制:以当前流的特征

作为 Query;以所有其他并发流的特征

作为 Key 和 Value;生成上下文向量

。通过这种机制,模型能够自主决定从哪些流中借力。如果其他流无帮助时,注意力权重会自然衰减,从而自适应抑制负迁移。
挑战三:异步概念漂移
面对数据分布的非平稳性,CAMEL 设计了自主专家调优器 ,在专家粒度上实现模型容量的在线伸缩,遵循 “测试 - 诊断 - 适应” 的闭环逻辑:
- 漂移检测:利用基于最大均值差异(MMD)的漂移检测器监控特征分布变化。
- 增量式扩展(Add & Freeze): 当检测到漂移且伴随性能显著下降时, 实例化一个新的私有专家学习新概念,并冻结旧专家以规避灾难性遗忘。
- 自适应剪枝(Prune): 对于长期利用率(由路由网络权重决定)低下的冗余专家,"
-

- " 执行剪枝操作,维持模型的稀疏性与推理效率。
由于每个流拥有独立的

,CAMEL 能够自适应地处理多流之间的异步漂移,即只在需要的时候对相关流进行架构调整。
03 理论分析与实验验证
理论分析:基于多任务学习理论,论文证明了 CAMEL 的泛化误差上界。 定理 1 表明,CAMEL 的期望风险由平均经验风险、流间不相似度

以及样本复杂度项构成。这意味着,辅助专家通过注意力机制最小化了流间的不相似度代价,而路由网络平衡了协作与专精。这为 CAMEL 在复杂环境下的鲁棒性提供了数学解释。

实验验证:为了验证 CAMEL 的有效性,研究团队构建了包含 12 个合成流和 4 个真实数据集(涵盖了天气、新闻、信用卡信息等)的 8 大基准场景。
表 1 中的结果表明,CAMEL 在几乎所有场景中实现了最先进的平均准确率,显著超越了单流基线(SRP、AMF、IWE)和多流方法(MCMO、OBAL、BFSRL)。CAMEL 的优越性在异构环境中尤为明显,现有的多流方法由于依赖共享特征或标签空间而失败。相比之下,CAMEL 的流特定模块能够在输入异构下实现稳健的性能。该框架还通过其协作辅助机制有效利用潜在的流间相关性,超越了单流方法。

表 1:各方法在所有基准上的分类准确率(%)。红色代表最优,蓝色代表次优。
04 结语
CAMEL 的提出标志着多流学习从 “静态同构” 向 “动态异构” 迈出了关键一步。 该框架以私有专家保障流内专精,以辅助专家挖掘跨流关联,并通过自动化的专家生命周期管理在漂移下实现持续适应与效率控制,为复杂、动态演化的异构多流场景提供了一种可扩展的解决方案。
....
#英伟达、AMD本月起或涨价
5090两千美元变五千
GPU 涨价看来正在变成定局。
据一些科技媒体及供应链报告,英伟达、AMD 将在 2026 年初上调 GPU 价格。

来自 Board Channels、Wccftech 等消息源的报道称,英伟达、AMD 计划在未来几个月内对旗下的在售 GPU 逐步涨价。其中 AMD 预计在 1 月份开始上调价格,英伟达预计在 2 月份涨价。
预计此次涨价将首先影响部分消费级 GPU,如英伟达的 GeForce RTX 50 系列和 AMD 的 Radeon RX 9000 系列。英伟达的旗舰 GPU 产品 RTX 5090 于 2025 年 1 月发布,官方建议售价为 1999 美元,但预计今年的实际价格将飙升至 5000 美元。

以此开始,涨价很可能涵盖两家公司的所有产品线,不仅包括消费级 GPU,还包括用于 AI 数据中心和服务器的 GPU。消息人士透露,显卡厂商何时想要提高 GPU 价格取决于他们自己。但很明显,如果他们从 AMD 和英伟达那里以更高的价格采购包含显存的模块,他们将别无选择,只能尽快提高 GPU 价格。
显然,此次提价的驱动因素是 GPU 成本结构中内存占比的快速增长。由于最近几个月来 GPU 内存价格飙升,维持现有 GPU 价格已十分困难。
一位业内人士解释说:「最近,内存成本在 GPU 整体制造成本中的平均占比已超过 80%。」
比如 RTX 5070 Ti 上搭载的 16GB GDDR7 内存,其采购成本已经从 2025 年 5 月的 65-80 美元,涨到了 12 月的 210-260 美元。英伟达及其合作伙伴(华硕、微星、七彩虹等)在 2025 年上半年执行的是 2024 年底签下的长协合同。当时显存价格还处于合理区间,因此 RTX 5070 Ti 能以 749 美元左右的官方建议零售价平稳上市。
然而,绝大多数旧合约在 2025 年底到期(英伟达的合同截止到今年 1 月,AMD 的合同截止到去年 12 月)。厂商在续签 2026 年采购协议时,面临的是已经翻了数倍的现货价格。
在科技公司对于 AI 芯片的旺盛需求推动下,内存生产商三星和 SK 海力士正在将原本属于 GDDR7 的生产线改造,用于生产利润更高的 HBM4(用于 Blackwell Ultra AI 芯片)。
类似的,AI 数据中心使用的 GPU 也是通过长期合同供应的,而内存价格的上涨可能会反映在 2026 年签订的新合同上。英伟达旗舰级 AI GPU H200 的售价在 3-4 万美元之间,预计今年价格还会进一步上涨。每块 H200 都包含六颗第五代高带宽显存(HBM3E)。
由于内存的涨价,今年的笔记本电脑整机价格也可能会面临调整,一些反向升级的 8GB 机型将会上市,16GB 及以上内存的机型价格将大幅上涨。研究机构 TrendForce 表示,DRAM 内存供应非常紧张,以至于各大品牌正在重新设计产品线并提高价格以保护库存。
最近的反应来自华硕。根据官方声明,其将于 1 月 5 日起上调部分产品价格,理由是人工智能需求推动 DRAM 和存储成本上涨。

虽然华硕尚未透露具体涨幅,但可以观察类似的情况:戴尔此前已宣布涨价 30%。
参考内容:
http://www.boardchannels.com.cn/thread-130155-1-1.html
https://mobile.newsis.com/view/NISX20251229_0003458273
https://wccftech.com/amd-and-nvidia-are-expected-to-hike-gpu-prices-early-2026/
....
#Deep Research
系统学习Deep Research,这一篇综述就够了
近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期研究流程,由此催生了 Deep Research(DR)这一新方向。
然而,随着相关工作的快速涌现,DR的概念也在迅速膨胀并趋于碎片化:不同工作在系统实现、任务假设与评价上差异显著;相似术语的使用进一步模糊了其能力边界。
正是在这一背景下,来自山东大学、清华大学、CMU、UIUC、腾讯、莱顿大学等机构共同撰写并发布了目前最全面的深度研究智能体综述《Deep Research: A Systematic Survey》。文章首先提出一条由浅入深的三阶段能力发展路径,随后从系统视角系统化梳理关键组件,并进一步总结了对应的训练与优化方法。
GitHub:https://github.com/mangopy/Deep-Research-Survey
Website:https://deep-research-survey.github.io/
论文地址:https://deep-research-survey.github.io/static/doc/Deep-Research-Survey.pdf
什么是 Deep Research
DR 并非某一具体模型或技术,而是一条逐步演进的能力路径。综述刻画了研究型智能体从信息获取到完整科研流程的能力提升过程。基于对现有工作的梳理,可将这一演进划分为三个阶段。
阶段 1:「Agentic Search」。模型开始具备主动搜索与多步信息获取能力,能够根据中间结果动态调整查询策略,其核心目标在于持续地找对关键信息。这一阶段关注的是如何高效获取外界信息。
阶段 2:「Integrated Research」。模型不再只是信息的收集者,而是能够对多源证据进行理解、筛选和整合,最终生成逻辑连贯的报告。
阶段 3:「Full-stack AI Scientist」。模型进一步扩展到完整的科研闭环,具备提出研究假设、设计并执行实验,以及基于结果进行反思与修正的能力。这一阶段强调的不仅是推理深度,更是自主性与长期目标驱动的科研能力。

Deep Research 的四大核心组件

1. 查询规划
查询规划主要负责在当前状态下,决定下一步应该查询什么信息。具体分为三类规划策略:
- 顺序规划,将复杂问题拆解为线性的子问题序列,模型根据前一步的检索结果逐步推进,适用于依赖关系明确的研究任务。
- 并行规划,同时生成多个相对独立的子查询,用于加速搜索或降低单一搜索路径带来的信息缺失。
- 树状规划,显式建模子问题之间的层级与分支关系,允许模型在研究过程中进行探索与回溯。
相比传统 RAG 中一次性生成查询的做法,DR 将 “如何提问” 本身纳入推理过程,使模型能够在多轮研究中动态调整推理路径。

2. 信息获取
论文从三个维度对现有的信息获取方法进行归纳。
(1)何时检索:不同于固定步数或每轮必检索的策略,DR 智能体需要根据当前不确定性与信息缺口,动态判断是否触发检索,以避免冗余查询或过早依赖外部信息。
(2)检索什么: 在确定检索时机后,从 Web 或外界知识库中做检索,包括多模态和纯文本信息。
(3)如何过滤检索信息:面对噪声较高的检索结果,系统通常引入相关性判断、一致性校验或证据聚合机制,对外部信息进行筛选与整合。
3. 记忆管理
在开放任务中,智能体往往需要跨越多轮交互、多个子问题与不同信息源。记忆模块是支撑 DR 系统长期运行与持续推理的核心基础设施,为系统提供状态延续和经验累积,使模型能够使用长期长线推理任务。现有工作通常将记忆管理过程拆解为四个相互关联的阶段:记忆巩固、记忆索引、记忆更新与记忆遗忘。

4. 答案生成
与传统生成任务不同,DR 场景的问答更强调结论与证据之间的对应关系,以及整体论证过程的逻辑一致性。因此,通常需要智能体显式整合多源证据与中间推理结果,使输出不仅在语言层面连贯,还能够支持事实核验与过程回溯。

如何训练与优化 Deep Research 系统?
文中总结了三类具有代表性的方法:
提示工程:通过精心设计的多步提示构建研究流程,引导模型执行规划、检索与生成等步骤,适合快速构建原型。其效果高度依赖提示设计,泛化能力有限。
监督微调:利用高质量推理轨迹,对智能体进行监督微调。该方法直观有效,但获取覆盖复杂研究行为的标注数据成本较高。
智能体强化学习: 通过强化学习信号直接优化 DR 智能体在多步决策过程中的行为策略,无需复杂人工标注。主要细分为两种做法:
- 端到端优化:输入到输出的完整决策过程,联合优化查询规划、检索、信息整合与报告生成等多个环节。这种方式有助于智能体学会协调各个模块,但是面临奖励稀疏、训练不稳定以及采样成本高等问题。
- 优化特定模块:仅对查询规划或调度等关键模块施加强化学习信号。在保持系统其他模块稳定性的同时,学习何时检索、如何推理等单一策略。这种模块化训练显著降低了训练难度,更易于在现有系统中落地。
Deep Research 真正难在哪里?
Deep Research 的核心挑战并不在于单一能力的提升,而在于如何在长期、开放且不确定的研究流程中,实现稳定、可控且可评估的系统级行为。现有工作主要面临以下几方面的关键难题。
(1)内部知识与外部知识的协同: 研究型智能体需要在自身参数化知识与外部检索信息之间做出动态权衡,即在何时依赖内部推理、何时调用搜索工具。
(2)训练算法的稳定性:面向长线任务的训练往往依赖强化学习等方法,但优化过程中容易出现策略退化或熵坍缩等问题,使智能体过早收敛到次优行为模式,限制其探索多样化的推理路径。
(3)评估方法的构建: 如何合理评估研究型智能体仍是开放问题。综述系统梳理了现有 benchmark。

尽管相关数据集不断涌现,构建可靠且高效的评估方法仍有待深入探索,尤其是在开放式任务中如何对 report-level 的模型输出进行全面评估。当前广泛采用的 LLM-as-a-judge 范式在实践中展现出便利性,但仍不可避免地受到顺序偏差,偏好 hacking 等问题的影响,限制了其作为测评方法的可靠性。
(4)记忆模块的构建:记忆模块的构建是 DR 系统中最具挑战性的部分之一。如何在记忆容量、检索效率与信息可靠性之间取得平衡,并将记忆机制稳定地融入端到端训练流程,仍是当前研究中的关键难题。
结语 Deep Research
Deep Research 并非对现有 RAG 的简单扩展,而是智能体在能力、动作空间以及应用边界上的一次转变:从单轮的答案生成,走向面向开放问题的深度研究。目前,该方向仍处于早期阶段,如何在开放环境中构建既具自主性、又具可信性的 Deep Research 智能体,仍是未来值得持续探索的重要问题。本文的 survey 也会持续更新,总结最新的进展。
....
#谷歌三年逆袭
草蛇灰线,伏脉千里
2025 年 12 月 1 日,硅谷再次拉响了「红色警报」。
不过这一次,发出警报的不是谷歌,而是 OpenAI。
当 OpenAI CEO 萨姆・奥特曼在内部备忘录中宣布进入最高级别的「红色警报」状态,暂停广告、医疗 AI 智能体等所有非核心项目,将全部资源集中于改进 ChatGPT 时,整个科技圈都意识到风向变了。
三年前的同一幕还历历在目。
2022 年 11 月 30 日,ChatGPT 横空出世,短短五天用户突破百万,两个月突破一亿。谷歌内部迅速拉响「红色警报」,CEO 桑达尔・皮查伊甚至召回了已「隐退」多年的两位创始人拉里・佩奇和谢尔盖・布林参与高层会议。
彼时的谷歌,在自己最擅长的 AI 领域,被一家成立仅七年的创业公司杀了个措手不及。
在一段低谷时期,谷歌员工们聚集在走廊里,公开表达对谷歌可能沦为下一个雅虎的担忧。
而今,剧情反转。
谷歌推出 Gemini 3 大语言模型、Nano Banana 图像生成模型、Veo3 视频生成模型以及 TPU 芯片,在各个战线全面开花,重夺技术制高点。
短短三年时间,从被动挨打到主动进攻,谷歌的逆袭绝非偶然。
攻守易形,谷歌究竟做对了什么?
内部反思:从慢公司到快公司
2022 年 12 月,ChatGPT 的用户数在 5 天内突破百万,谷歌召开了一场不寻常的全体员工大会。
会议气氛紧张而激烈。
一位员工提出了最受关注的问题:「这对谷歌来说是不是一个错失的机会?考虑到我们已经拥有 LaMDA 很长时间了。」
这个问题获得了大量员工的支持,直指核心痛点:谷歌明明手握先进技术,却眼睁睁看着竞争对手率先占领市场。
谷歌 AI 负责人杰夫・迪恩坦承,谷歌面临着比小型创业公司大得多的「声誉风险」,因此行动「比小型创业公司更加保守」。
作为全球搜索引擎的霸主,谷歌不能容忍错误信息损害其品牌,但这种过度的风险厌恶,恰恰导致了早期的被动局面。
这场会议之后,谷歌的行动也麻利起来,要求「一百天内打造一个能与 ChatGPT 抗衡的产品。」
一份内部备忘录写道:「由于 ChatGPT 的出现,LaMDA 团队被要求优先开发对 ChatGPT 的回应。在短期内,这优先于其他项目。」
谷歌内部开始密集测试 Bard 和其他聊天机器人。
Bard 可以在 LaMDA 的基础上进行开发,但必须更新其知识库并引入新的安全措施。谷歌的基础设施团队将最优秀的员工调去释放更多服务器,以完成所有这些调整。他们几乎耗尽了公司一些数据中心的电力,冒着设备烧毁的风险,同时迅速设计新工具,以更安全地应对不断增长的电力需求。
尽管新的计算能力陆续上线,但 Bard 仍会产生「幻觉」,并以不恰当或冒犯性的方式回应。
面对百日期限,谷歌能做的最好的事情就是尽可能多地发现和修复错误。一些通常专注于处理虐待儿童图像等问题的承包商,转而测试 Bard。
以往推出 AI 项目前,谷歌的大约十几个人的负责任创新团队会花几个月独立测试系统,检查是否存在不良偏见和其他缺陷。但对于 Bard,这个审查过程被压缩。
新模型和功能发布速度太快,审查人员即使周末和晚上都加班也跟不上。当时有人提出推迟 Bard 发布,意见被否决了。
2023 年 2 月 8 日,谷歌举行 Bard 人工智能演示直播。在演示视频中,Bard 回答詹姆斯・韦伯太空望远镜时出现事实性错误,导致 Alphabet 股价下跌近 9%, 市值蒸发了约 1000 亿美元。
谁也没想到如此微不足道的事情会导致股价暴跌,毕竟 ChatGPT 也会犯下各种愚蠢的错误。
领导层向团队保证,没人会因此丢掉工作,但快速吸取教训。「我们是谷歌,不是初创公司,我们不能轻易地说,『哦,这只是技术缺陷』。我们会被点名批评,我们必须以谷歌的方式做出回应。」
谷歌内部留言板 Memegen 上的一篇帖子写道:「Bard 的发布和裁员都太仓促、草率和短视了,请恢复长远眼光。」
望远镜事件后,皮查伊安排了 8 万名员工花费两到四个小时对 Bard 进行内部测试,并为 Bard 项目增派了数百名员工。在团队的 Google Docs 中,皮查伊的头像开始每天出现,频率超过以往任何产品。
由此可见,谷歌一改以往「追求完美才发布」的传统,转变为「先发布再迭代」的敏捷策略。
到了 2024、2025 年,谷歌的节奏进一步加快。
皮查伊在内部会议上直言:「我需要大家内化紧迫感,加快公司运转速度。竞争正在激烈变化,我们的主要业务也面临着前所未有的挑战。」
这并不是空喊口号。
为了打破那种长期的「慢」,谷歌在 2024 年至 2025 年间启动了历史上最大规模的组织扁平化行动。
据内部统计,谷歌裁撤了约 35% 的负责小团队的经理岗位,特别是那些直接下属少于三人的管理层,消除「经理的经理」这一冗余层级,确保指令能够从决策层直接触达一线的算法工程师,减少沟通损耗和决策摩擦 。
在产品研发模式上,谷歌实验室的联合负责人乔什・伍德沃德在负责 Gemini 应用期间,打破了谷歌传统的长周期路线图,引入类似创业公司的快速迭代机制 。
伍德沃德会在 X 或 Reddit 等社交媒体平台直接回应用户的反馈,并将这些反馈实时转化为工程师的修复任务,形成高效的反馈闭环。
过去,谷歌被戏称为「硅谷最大的养老院」,前 CEO 埃里克・施密特曾炮轰公司因过度追求「生活与工作平衡」而丧失斗志。
在这一点上,谷歌也有了转变。
内部备忘录显示,谷歌联合创始人谢尔盖・布林曾在今年 2 月对 AI 部门表示,员工应每日到岗,每周 60 小时是「最佳效率区间」。布林强调,人工智能领域竞争迅猛,公司必须「全速推进」以维持领先。
Gemini 项目组遍布全球八个时区,数百个协作聊天室昼夜同步。
哈萨比斯长期以来习惯于在伦敦与家人共进晚餐,然后工作到凌晨 4 点,他说:「回想起来,每一天都感觉像过了一辈子。」
组织重组:成立新谷歌 DeepMind
谷歌内部,曾经有两支「神仙打架」级别的 AI 天团。
一支是伦敦的 DeepMind,掌门人是德米斯・哈萨比斯;另一支是山景城的 Google Brain,由传奇工程师杰夫・迪恩坐镇。
DeepMind 以强化学习和通用人工智能为愿景,偏向于基础科学突破,如 AlphaFold、AlphaGo;而 Google Brain 则更侧重于深度学习的基础设施建设以及与谷歌现有产品的深度集成。
两支队伍虽然同属谷歌体系,但往往在人才和算力分配上存在激烈的竞争,甚至在某些研究方向上重复造轮子。
2023 年 4 月,谷歌宣布组织大重组,将 Google Brain 和 DeepMind 合并,成立新的 Google DeepMind 部门,DeepMind 联合创始人德米斯・哈萨比斯出任 CEO,获充分自主权。
杰夫・迪恩出任谷歌首席科学家,他将从具体的部门管理中抽身,转而从技术架构的高度指导 Google DeepMind 和 Google Research 的研发方向。
谷歌通过这次合并,确立了哈萨比斯作为谷歌 AI 唯一统帅的地位,结束了两大实验室长达数年的资源内耗和技术分歧。
合作开始后,迪恩、哈萨比斯和詹姆斯·马尼卡向董事会提交了一份计划,让两个团队联合打造迄今为止最强大的语言模型。
哈萨比斯想把这个项目命名为 Titan,但董事会不太喜欢,最终采纳了迪恩提出的 Gemini 这个名字。
统一后的团队获得了前所未有的资源支持:最优先的TPU集群、最自由的架构试验权,最强工程师与科学家。
2024年,Gemini产品团队从搜索部门转移到DeepMind,这是DeepMind首次直接负责面向消费者的产品。
2025年初,谷歌 AI Studio 团队和为该公司 Gemini 系列模型开发 API 的团队并入 Google DeepMind。
谷歌打破了部门墙,AI成为全公司的核心战略,而非某个研究部门的专属项目。搜索、云计算、广告、硬件等各个业务线都围绕AI进行重组,形成「AI优先」的全新文化。
创始人回归:打破官僚主义
2019 年,谢尔盖・布林辞去 Alphabet 的日常管理职务,虽然仍是董事会成员,但基本不再参与运营决策,只是偶尔去硅谷办公室查看其「登月计划」项目的进展情况。
这种情况在 2023 年发生变化,已经退居幕后的布林被重新拉回战场。
2023年1 月 24 日,布林提交了多年来的首次代码访问权限申请,该申请与谷歌的自然语言聊天机器人 LaMDA 有关。
据桑达尔・皮查伊透露,布林开始花费大量时间与谷歌 AI 团队在一起,并且亲自参与技术工作。
「谢尔盖现在花更多时间在办公室里,他真的在写代码,过去一年里我最美好的回忆之一就是和谢尔盖一起坐在大屏幕前,看着损失曲线训练这些模型。」
,时长00:37
亲自审查 Gemini 模型的训练损耗曲线,这在大型科技公司的联合创始人中是极其罕见的 。
在神经网络训练中,损耗曲线反映了模型参数在迭代过程中的误差收敛情况,其形态直接预示了模型的最终性能。布林对这些底层细节的关注,迫使研发团队必须在每一个技术细节上追求卓越,而非仅仅满足于完成项目汇报。
据布林透露,他现在有个新习惯,喜欢一边开车一边与 Gemini 进行实时对话,讨论数据中心的电力和成本等问题。「他车里用的 Gemini 型号比现在市面上的产品好得多。」这是典型的谷歌式「dogfooding」。
(注:dogfood 是硅谷的行话,意思是在正式发布前让员工试用自家产品。)
,时长00:54
除了直接参与到模型训练的技术细节中,布林还要和谷歌内部的官僚主义做抗争。
谷歌内部有份清单规定哪些工具可以用来写代码,而 Gemini 竟在禁止列表里,「理由是 Gemini 必须保持纯粹,不能用它…… 反正一堆特别奇怪的理由,让我完全无法理解」。
他与相关人员发生了激烈争执,最终通过皮查伊才解决了这个问题。
,时长01:10
布林还用 Gemini 进行了一次创新尝试。他在谷歌内部聊天中询问 Gemini:在这个聊天空间里,谁应该得到晋升?Gemini 选择了一位默默无闻的年轻女工程师。
布林表示,「我甚至没注意到她,她平时并不太爱发言,特别是在那次PR评审时」,但 AI 检测到了她的实际贡献。
布林随后找到该工程师的直属经理求证,得到回应:「你说得对,她一直在努力工作,做了很多事情。」最终这位工程师获得了晋升。
,时长00:30
此外,布林的存在极大地简化了招聘流程。
在硅谷,顶级 AI 研究员往往更倾向于与同样具备深厚技术底蕴的创始人对话,布林多次亲自给已经离职的顶级科学家打电话,邀请他们重返谷歌参与「决定人类未来」的 Gemini 项目。
创始人的回归意义重大。他重新聚焦 Gemini 等旗舰项目,参与技术开发和决策,同时直接介入打破内部的流程障碍。
当一个项目需要快速决策时,创始人可以直接拍板,而不是在各个部门之间反复协调。
人才召回:老兵的价值
在 2023 年的大规模裁员和人才流失阴影下,外界曾一度认为谷歌的 AI 核心人才已经流失殆尽。
然而,谷歌在 2024 年和 2025 年实施了一场「回旋镖计划」。
据 2025 年底的内部数据,谷歌当年招聘的 AI 软件工程师中,有约 20% 是曾经在谷歌工作、后来离职或跳槽、最终又被请回来的「老兵」。
这些「老谷歌人」对公司文化、技术架构、内部系统都了如指掌,能够迅速上手,大幅降低磨合成本。
其中,最具代表性的就是 Transformer 论文作者之一 Noam Shazeer 的回归。

他曾因谷歌拒绝推出他的聊天机器人项目而于 2021 年离职创办了 Character.AI。
2024 年,谷歌支付了高达 27 亿美元的许可费给 Character.AI,实质上是为了将 Noam Shazeer 及其团队召回 DeepMind 。
这种近乎「赎身」式的召回,向外界传递了一个强烈的信号:谷歌愿意为顶级人才付出任何代价。
Shazeer 回归后被任命为 Gemini 项目的共同负责人,他的存在极大地增强了谷歌在复杂算法架构上的研发底气 。
谷歌吸引老兵回归的核心筹码被称为「基础设施羡慕」。虽然 Meta 等对手开出了高达 1 亿美元的签字费,但谷歌提供的条件是研究员在任何地方都无法获得的:
能够直接调度拥有数十万个 TPU 节点的超级计算集群,以及处理来自搜索、YouTube 等九个拥有超过 10 亿用户的产品所产生的真实世界数据。
对于追求技术突破的高级研究员来说,这种级别的算力和数据资源,比单纯的薪酬更具诱惑力 。
为了留住这些召回的老兵,谷歌还彻底改革了激励机制和职级体系。
在 2025 年的薪酬改革中,谷歌将高绩效 AI 人才的报酬更多地与产品落地指标(如模型推理效率、用户活跃度)而非仅仅是论文发表量挂钩。
竞争远未结束
当 OpenAI 拉响「红色警报」时,外界惊呼谷歌已经完成了逆袭。
但竞争远未结束。
奥特曼在内部信中透露,OpenAI 即将发布一款性能超越 Gemini 3 的推理模型,同时正在研发代号为 Garlic 的新模型。
而 Anthropic 的 Claude 也在企业市场攻城略地,Meta 则以惊人的薪酬挖角顶尖人才。
当模型能力趋同时,竞争的焦点将从技术转向应用,谁能让 AI 真正融入用户的日常生活,谁能构建起难以复制的生态壁垒,谁能在监管和伦理的约束下持续创新。
从这个角度看,谷歌的翻身仗只是万里长征的第一步。在这场似乎没有终点的 AI 竞赛中,唯一确定的是:
没有永恒的领跑者,攻守之势随时可能再次转换。
参考链接:
https://x.com/Yuchenj_UW/status/2000068339104936058?s=20
https://www.businessinsider.com/google-larry-page-sergey-brin-help-chatgpt-code-red-2023-1
....
#百页综述《Memory in the Age of AI Agents: A Survey》
最火、最全的Agent记忆综述,NUS、人大、复旦、北大等联合出品
在过去两年里,记忆(Memory)几乎从 “可选模块” 迅速变成了 Agent 系统的 “基础设施”:对话型助手需要记住用户习惯与历史偏好;代码 / 软件工程 Agent 需要记住仓库结构、约束与修复策略;深度研究型 Agent 需要记住已阅读的证据链、关键假设与失败路径,没有 memory 的智能体难以跨任务保留有效经验,难以稳定维护用户偏好与身份设定,也难以在长周期协作中保持行为一致、避免反复犯同样的错误。与此同时 Memory 概念在迅速膨胀、也在迅速碎片化:很多论文都声称自己在做 “agent memory”,但实现方式、目标假设、评价协议差别巨大,多术语并行又进一步模糊了边界。
在这样的背景下,来自新加坡国立大学、中国人民大学、复旦大学、北京大学等顶级学术机构共同撰写并发布了百页综述《Memory in the Age of AI Agents: A Survey》,尝试用统一视角为快速扩张、却日益碎片化的 “Agent Memory” 重新梳理技术路径。
- 论文链接: https://arxiv.org/abs/2512.13564
- Github 链接: https://github.com/Shichun-Liu/Agent-Memory-Paper-List
综述首先指出传统的 “长 / 短期记忆” 二分法,已经不足以描述当代系统里更复杂的结构形态与动态机制:有的记忆是显式 token 存储,有的写进参数,有的驻留在潜在状态;有的服务于事实一致性,有的服务于经验迁移,有的服务于单次任务的工作台管理 —— 如果继续用简单时间尺度切分,就很难真正解释这些差异。
基于此,该综述提出一个统一的分析框架:Forms–Functions–Dynamics(三角框架)。它试图分别回答三类核心问题:

记忆以什么形式存在(Forms)——What Carries Memory? 是外部 token、参数,还是潜在状态?
记忆解决什么问题(Functions)——Why Agents Need Memory? 它服务于事实一致、经验成长,还是任务内工作记忆?
记忆如何运转与演化(Dynamics)——How Memory Evolves? 它如何形成、如何被维护与更新、又如何在决策时被检索与利用?
概念辨析:Agent Memory 到底
和 LLM Memory、RAG、Context Engineering 有何不同?
在大量工程实践中,“Memory” 这个词往往被迅速简化为几个具体实现:一个向量数据库加上相似度检索,或者干脆等同为更长的上下文窗口、更大的 KV cache。在这种理解下,只要模型 “还能看到过去的信息”,系统似乎就已经具备了记忆能力。然而,综述明确指出:这些技术与 Agent Memory 确实存在交集,但在研究对象和问题层级上并不等价。

Agent Memory:持久的、可自我演化的 “认知状态”
Agent Memory 关注的是智能体持续维持的认知状态,它不仅 “存”,还要能在交互中不断更新、整合、纠错、抽象,并跨任务保持一致性。独特性在于维护一个 persistent and self-evolving cognitive state,并把事实与经验整合在一起。Agent Memory 关心的是 “智能体知道什么、经历过什么,以及这些东西如何随时间变化”,包括把反复交互沉淀成知识、从成功 / 失败中抽象程序性知识、跨任务保持身份一致性等。
LLM Memory:“模型内部机制 / 长序列处理”
确实存在一条与 Agent Memory 不同、但同样重要的研究路线 —— 真正意义上的 LLM-internal memory。这类工作关注的不是智能体如何在长期交互中积累经验,而是模型在内部计算过程中如何更有效地保留和利用序列信息。这些方法的核心问题是:在一次或有限次推理过程中,如何避免早期 token 的信息衰减,如何在计算与显存受限的前提下保持对长距离依赖的建模能力。其研究对象,本质上是模型内部的状态与动态。它们并不假设模型是一个长期存在、需要跨任务保持身份与目标的自主体,也不要求模型与环境进行持续交互或做出一系列有后果的行动决策。换言之,这些方法即便不引入 agentic 行为,也完全成立:模型依然可以在单次问答、长文档理解或摘要等任务中受益。
RAG:“静态知识访问”
RAG 通常强调从外部知识库检索静态信息以提升回答事实性;它可以是 Agent Memory 的一部分实现,但如果系统没有长期一致性、没有演化机制、没有跨任务的 “自我”,那么它更像 “知识访问模块”,而非完整记忆系统。这个差别在综述的概念对照图说明里也被点明:RAG 更接近 “static knowledge access”。
Context Engineering:“当下推理的外部脚手架”
Context Engineering 的目标常常是:在上下文窗口受限时,如何组织提示、压缩信息、构建工具输出格式等 —— 它优化的是 “此刻模型看到什么”。而论文强调:Context Engineering 是外部脚手架;Agent Memory 是支持学习与自主性的内部基底。前者优化当下接口,后者维持跨窗口、跨任务的持续认知状态。
Forms:记忆的载体是什么?
综述把 agent memory 的形式归纳为三大类:token-level /parametric/latent。
这三类的差别聚焦于:信息以什么表示、在哪里存、如何读写、以及可解释性与可塑性的取舍。
Token-level Memory:最 “显式” 的记忆层
token-level memory 的定义非常直观:它把信息存成持久、离散、可外部访问与检查的单元;这里的 token 不仅是文字 token,也可以是视觉 token、音频帧等,只要是可写、可检索、可重排、可修改的离散元素即可。
为什么它在工程里最常见?因为它天然具备三种优势:
1. 透明:你能看到存了什么;
2. 可编辑:能删改、能纠错;
3. 易组合:适合作为检索、路由、冲突处理的 “中间层”,并与 parametric/latent memory 协同。
但 token-level 并不是 “一个向量库” 那么简单。进一步按 “拓扑结构复杂度” 可以把它分成三种组织方式:

- Flat Memory(1D):没有显式拓扑关系,记忆像序列 / 离散单元一样累积(例如片段、轨迹)。它的优点是实现简单、写入快;缺点是检索与更新容易退化成 “相似度匹配 + 越存越乱”。
- Planar Memory(2D):单层结构化组织,记忆单元之间通过图、树、表等关系连接,但不分层。它更适合多跳推理、关系约束与一致性维护;代价是构建与维护结构更复杂。
- Hierarchical Memory(3D):多层结构并带跨层链接,形成 “分层 / 立体化” 的记忆体系。它的动机往往是:既要保留细节,又要形成抽象总结,并让检索可以在不同粒度之间切换。
这反应了当记忆规模增大,单纯堆历史就会暴露弊端,必须引入结构(2D)与分层抽象(3D),才能让长期存在的外部记忆真正可用。
Parametric Memory:把记忆 “写进权重”
Parametric memory 的定义是:信息存储在模型参数中,通过参数空间的统计模式编码,并在前向计算中被隐式访问。它更像人类 “内化后的直觉”:不用每次检索外部库,模型直接学会并记住这些内容。但代价同样明显:
- 需要训练 / 更新权重(成本高)
- 难以精确编辑与审计
- 容易和遗忘、分布漂移、灾难性遗忘问题纠缠在一起

Latent Memory:藏在隐状态 / 连续表示里的 “动态记忆”
Latent memory 的定义是:记忆以模型内部隐状态、连续表示或演化的潜在结构存在,可在推理时或交互周期中持续更新,用于捕捉上下文相关的内部状态。

它介于 “外部显式存储” 和 “权重内化” 之间:比 token-level 更紧凑、更接近模型计算过程;比 parametric 更容易在推理期更新,但也往往更难解释、更难审计。

Functions:记忆的功能是什么?
这一分类角度是这篇综述的核心观点之一,它不再用 “长 / 短期” 这种时间尺度粗分,而是用功能角色把 agent memory 分成三类:
- Factual memory(事实记忆):记录来自用户与环境交互的知识
- Experiential memory(经验记忆):从任务执行中增量提升解决问题的能力
- Working memory(工作记忆):管理单个任务实例中的工作区信息
这三个概念的价值在于:它们对应的是三种完全不同的 “记忆失败模式”,也对应三类不同的系统设计。

Factual Memory:让智能体 “记住世界”,并且可核查
事实记忆的一个关键目标,是提供一个可更新、可检索、可治理(governable)的外部事实层,让系统在跨 session / 跨阶段时有稳定参考。 这类记忆不只面向 “用户偏好”,也面向 “环境事实”:长文档、代码库、工具状态、交互轨迹等。
环境事实记忆能成为持续可更新、可审计、可复用的外部事实层;在协作维度还能维持跨 agent、跨阶段一致性,从而支撑多来源信息与长周期任务下的稳健执行。
如果你做过 “多轮对话 + 多工具 + 多资料” 的系统,你会非常熟悉这种痛点:事实一旦散落在历史对话里,就会反复被遗忘、被误引、被编造。事实记忆的意义,就是把 “可核查的世界状态” 从临时上下文里抽出来,变成可维护的对象。
Experiential Memory:让智能体 “吃一堑长一智”
经验记忆的定义更像能力的积累:它把历史轨迹、提炼后的策略、交互结果编码为可持久检索的表示。它与工作记忆不同:工作记忆管 “眼前这一题”,经验记忆关心 “跨 episode 的长期积累与迁移”。
综述把经验记忆与认知科学里的非陈述性记忆(程序性 / 习惯系统)类比,同时指出 agent 的独特优势:它往往用显式数据结构存储,因此反而具备生物体没有的能力 —— 可以内省、编辑、并对自己的程序性知识做推理。经验记忆给了智能体一种避免频繁参数更新的持续学习路径,把交互反馈转化为可复用知识,帮助系统纠错、抽象启发式、编译常规行为,从而减少重复计算并提升决策质量。
经验记忆按抽象层级分成三类:
- Case-based:几乎不加工的历史记录,强调保真度,用作 in-context exemplars;
- Strategy-based:从轨迹中蒸馏可迁移的推理模式 / 工作流,作为规划脚手架;
- Skill-based:把策略进一步落到可执行技能(代码片段、API 协议等),成为可组合的执行底座。

Working Memory:让智能体在 “单次任务里” 不被信息淹没
工作记忆听起来像短期记忆,但在 agent 场景里,它最典型的问题不是时间短,而是:即时输入太大、太杂、模态太高维(长文档、网页 DOM、视频流……),在固定 attention / 上下文预算下必须建立一个 “可写工作区”。
- 一类是 single-turn working memory:目的就是单次调用之内 “减 token”,包括 hard/soft/hybrid 压缩,以及输入内容结构化、抽象化;
- 另一类为 multi-turn working memory:关注多轮之间的状态维持与压缩、针对子任务的折叠剪切、使用 planning 管理记忆等等。

Dynamics:记忆是如何运转的?
如果说 Forms 解决 “记忆放哪儿”、Functions 解决 “记忆干嘛用”,那 Dynamics 解决的就是:记忆系统如何运转。
记忆的生命周期可以概括为三段:Memory Formation(形成)—Memory Evolution(演化)—Memory Retrieval(检索),并强调三者构成一个相互反馈的循环:形成阶段抽取新信息;演化阶段做整合、冲突消解与剪枝;检索阶段提供面向当前任务的访问;推理结果与环境反馈又反过来影响下一轮形成与演化。

Formation:从 “原始上下文” 到 “可存可取的知识”
Formation 阶段把原始上下文(对话、图像等)编码成更紧凑的知识。动机非常直接:full-context prompting 会带来计算开销、内存压力、以及在超长输入上的推理退化,因此需要把关键信息蒸馏成更高效的表示。
formation 操作进一步分成五类:语义总结、知识蒸馏、结构化构建、潜在表示、以及参数内化。这五类几乎对应了 Forms 的三种载体:总结 / 结构化更偏 token-level;潜在表示偏 latent;参数内化对应 parametric。
Retrieval:决定 “记忆是否真的能帮你做决策”
retrieval 形式化为一个操作:在每个时间步,根据当前观察与任务构造查询,并返回相关记忆内容;返回的记忆信号会被格式化成 LLM 策略可直接消费的文本片段或结构化摘要。
检索不必每步发生,可能只在任务初始化发生,也可能间歇触发或持续触发;而 “短期 / 长期” 效果往往不是因为搭载了两个模块,而是由 formation/evolution/retrieval 的触发节奏决定的。这点对工程实践有指导意义:很多系统并非缺一个长期库,而是触发策略不对、导致记忆无法进入决策回路。

Evolution:记忆库也需要 “维护与新陈代谢”
Evolution 阶段的任务是把新增记忆与已有记忆整合,通过合并相关条目、冲突消解、剪枝等机制,让记忆保持可泛化、连贯且高效。
这也是为什么 “记忆系统” 迟早会走向更复杂的治理问题:删什么、留什么、如何避免自相矛盾、如何避免隐私泄漏、如何给多智能体共享时加规则…… 这些都属于 evolution 的范畴。

资源整理:Benchmark 与开源框架
综述专门用 Section 6 汇总 benchmarks 与开源框架资源,这是支持实证研究与落地开发的关键基础设施,方便相关科研工作者查阅。


前沿展望:下一代记忆系统走向何方?
与其把记忆当作一个检索插件,不如把它当作智能体长期能力的 first-class primitive,作为 agent 的核心功能之一:
- 从 Memory Retrieval 到 Memory Generation(记忆从 “找出来” 变成 “生成出来”);
- 从 Hand-crafted 到 Automated Memory Management(记忆系统从 “人工写规则” 变成 “自动管理”);
- 从 Heuristic Pipelines 到 RL-driven Control(从启发式流程走向强化学习端到端优化);
并进一步讨论这些变化如何与多模态、多智能体协作、可信安全等主题交织。
记忆检索 vs 记忆生成:从 “取片段” 到 “做抽象”
传统检索范式把记忆看成一个已经 “写好” 的仓库:当前任务需要什么,就从向量库 / 图结构 / 重排器里把最相关的片段找出来拼进上下文,核心指标是检索的 precision/recall。大量工作围绕索引、相似度、重排、结构化来提升 “找得准不准”。 但 Agent 真正的长期能力不只依赖 “取回旧文本”,而更依赖一种面向未来的抽象:
- 记忆不必是原始碎片,它可以被压缩、重组、重写成更适合后续推理的表示;
- 尤其当原始记录冗余、噪声大、与任务不对齐时,“拼接式检索” 往往把上下文塞满,却不一定让模型更会做事。
这有两条主线:
1)Retrieve-then-Generate:先检索,再把检索到的材料重写成更紧凑、更一致、更任务相关的 “可用记忆”,如 ComoRAG、G-Memory、CoMEM 这类思路,保留可追溯的历史 grounding,同时提升可用性;
2)Direct Generation:不显式检索,直接从当前上下文 / 交互轨迹 / 潜在状态中生成记忆表示,比如用 “潜在记忆 token” 的方式绕开传统查库。
而未来则更关注三个方面:
- Context-adaptive(上下文自适应):不是一刀切总结,而要能随任务阶段与目标动态调整粒度与抽象层次;
- Integrate heterogeneous signals(融合异质信号):把文本、代码、工具输出、环境反馈等碎片 “熔成” 统一表示;
- Learned & self-optimizing(可学习且自优化):什么时候生成、生成成什么样,不再靠人工规则,而由优化信号(例如 RL 或长期任务表现)驱动,与推理 / 决策共同进化。
自动化记忆管理:从 “写规则” 到 “让 Agent 自己管记忆”
如今很多搭载 memory 的 Agent 其记忆行为本质仍是工程规则 —— 写什么、什么时候写、怎么更新 / 怎么取,都靠提示词、阈值、人工策略。这样做的好处是成本低、可解释、可复现,适合快速原型;但缺点也同样致命:僵硬、难泛化,在长程或开放式交互里容易失效。因此近期开始出现让 Agent 自主参与记忆管理的方向:
- 让模型把细粒度条目自动聚类成更高层抽象单元;
- 引入专门的 “memory manager” 代理来处理更新。

但很多方法仍被手工规则牵引,或只在狭窄目标上优化,因此离通用自动记忆还有距离。而未来可能的路线有两条:
第一条是把记忆操作显式接入决策:
不再把记忆当外部模块,而是让 Agent 在每一步都能通过工具调用式接口执行 add/update/delete/retrieve,并且 “知道自己做了什么记忆动作”。这会让记忆行为更连贯、更透明、更能与当前推理状态对齐。
第二条是走向自优化的记忆结构:
不仅仅 “分层存储”,更要让记忆库能动态链接、索引、重构,使存储结构本身随时间自组织,从而减少对手工规则的依赖,最终支持更鲁棒、可扩展的自主记忆。
强化学习 × 记忆:记忆控制正在被 RL “内化” 进策略
在 Memory 中引入 RL 是一种从 pipeline 到 model-native 的转向:早期大量系统要么是阈值 / 语义检索 / 拼接等启发式;要么看起来很 “agentic”,但其实只是 prompt 驱动,模型并没受过任何有效记忆控制的训练。
随后出现 RL-assisted memory:只对记忆生命周期的某一环节上 RL,比如:
- 用轻量 policy gradient 给检索到的 chunk 排序(后重排);
- 训练记忆写入 / 压缩 / 折叠工作记忆的策略(Context Folding、Memory-as-Action、MemSearcher、IterResearch 等)。这一类已经展示出很强的潜力,RL 很可能会在未来记忆系统里扮演更中心角色。
下一阶段则更可能是 Fully RL-driven memory。它需要满足两个理想特点:
1)尽量减少人类先验:
目前很多记忆系统借鉴人类认知(海马体 / 皮层类比)、预设层级(episodic/semantic/core),这些抽象对早期探索很有价值,但未必是人工智能体在复杂环境中的最优结构。若进入 fully RL-driven,Agent 有机会在优化驱动下 “发明” 新的记忆组织形式、存储 schema、更新规则。
2)让 Agent 对全生命周期拥有完整控制:
许多 RL 方法只覆盖 “写入” 或 “短期折叠”,却没把长期整合、演化、检索策略真正统一起来。论文认为,要让形成 - 演化 - 检索多粒度协同运转,几乎必然需要端到端 RL,因为仅靠启发式或提示词无法在长时域里协调这些复杂交互。
当记忆成为可学习、可自组织、与 Agent 共进化的子系统时,它就不再是外挂,而会成为长期能力与持续学习的基础设施。
多模态记忆:缺的不是 “能存图”,而是 “跨模态统一语义与时间”
随着 Agent 走向xx、交互式环境,信息来源天然是多模态的:视觉、动作、环境反馈等都会进入记忆系统。未来真正的难点不是把图片 / 视频 “塞进库”,而是让记忆支持异质信号的统一存取与推理。当前的两个关键缺口在于:
- 目前没有真正 “omnimodal” 的记忆系统,大多仍是单模态特化或松耦合;
- 多模态记忆需要从被动存储走向支持抽象、跨模态推理与长期适应。
多智能体共享记忆:从 “各聊各的” 到 “共享认知底座”
MAS 的早期范式:每个 agent 有自己的局部记忆,通过消息传递来协作。这避免直接干扰,但会带来冗余、上下文割裂、沟通开销爆炸,团队规模和任务时长一上来就撑不住。因此出现中心化共享记忆,其作为团队共同 ground truth:支持联合注意、减少重复、利于长程协作;但也引入新问题:记忆污染、写冲突、缺少基于角色 / 权限的访问控制。
共享记忆会从仓库进化为主动管理的集体表示,有三条可能的方向:
- agent-aware shared memory:读写与角色、专长、信任绑定,使聚合更结构化、更可靠;
- learning-driven management:不靠手工同步 / 总结 / 冲突解决策略,而训练 agent 在长期团队收益下决定何时写、写什么、怎么写;
- 面向开放与多模态场景,共享记忆需要保持时间与语义一致性,作者认为 latent memory 可能是一条有前景的路径。
可信记忆:隐私、可解释与抗幻觉,必须成为 “第一原则”
当记忆进入长期、个性化、跨会话存储后,问题已经不再是传统 RAG 的 “是否会胡说”,而是一个更大的可信系统工程:因为 Agent 记忆会保存用户偏好、历史交互、行为痕迹等潜在敏感信息,风险维度从 factuality 扩展到隐私、安全、可控与可审计。
(1)隐私保护:需要更细粒度的权限记忆、由用户主导的保留策略、加密或端侧存储、必要时的联邦访问;并可结合差分隐私、记忆脱敏 / 删改、以及可验证的 “遗忘” 机制(例如衰减式遗忘或用户擦除接口)来降低泄露风险。
(2)可解释性:不仅要看到 “记忆内容”,还要能追踪 “访问路径”:哪些条目被取了、如何影响生成、是否被误用;甚至支持反事实分析(“如果不取这条记忆,会怎样”)。论文提出未来可能需要可视化记忆注意、因果图、面向用户的调试工具等成为标配。
(3)抗幻觉与冲突鲁棒性:在冲突检测、多文档推理、不确定性建模上继续推进;包括低置信检索时的拒答 / 保守策略、回退到模型先验、或用多智能体交叉核验等。论文还特别提到,机制可解释性方法(例如在表示层面定位幻觉来源)可能会成为 “诊断 + 干预” 的新工具箱。
结语:把 “记忆” 当作
智能体的 first-class primitive
通过 Forms/Functions/Dynamics 的统一视角,记忆不再是附属插件,而是智能体实现时间一致性、持续适应与长程能力的关键基底;未来随着 RL 融合、多模态与多智能体场景兴起,以及从检索中心走向生成式记忆的趋势,记忆系统将变得更可学习、更自组织、更具适应性。
....
#Awe Dropping
苹果发布会:耳机测心率、手表听音乐、iPhone Air超级薄
北京时间 9 月 10 日凌晨 1 点,伴随着 Tim Cook 的一声「Good Morning」,这场主题为「Awe Dropping」的 2025 苹果秋季新品发布会正式拉开帷幕。

,时长02:29
发布会持续 75 分钟,AirPods、Apple Watch 和 iPhone17 系列轮番上阵,其中印象最深刻的卖点就是:耳机测心率、手表听音乐、iPhone Air 超级薄。😂

今年的 iPhone 17 系列总共分为四款机型,价格如下:
- iPhone 17 起售价 799 美元 / 5999 元;
- iPhone Air 起售价 999 美元 / 7999 元;
- iPhone 17 Pro 起售价 1,099 美元 / 8999 元;
- Pro Max 起售价 1,199 美元 / 9999 元;Pro Max 首次可选配高达 2TB 的存储空间,售价 1,999 美元 / 17999元。
以上机型都将于 9 月 12 日星期五开始预订,并计划于下周五(9 月 19 日)发货。
至于大众瞩目的 AI 功能,发布会上介绍的可谓是少之又少。即使是提到的大多数面向消费者的 AI 功能,比如视觉智能和 iMessage、FaceTime 中的实时翻译,早在今年 6 月的 WWDC 大会上就已经展示过了,而且这些功能也并不是苹果的创新,谷歌和三星等竞争对手早在一年前就推出了类似的功能。
更有意思的是,发布会开始前半小时,苹果的股价就先跌为敬,发布会后股价下跌 1.48%,并且盘后价还在继续跌。

iPhone Air
刚刚,苹果发布了史上最薄的 iPhone——iPhone Air,厚度仅为 5.6 毫米,重 165 克,配备 6.5 英寸 ProMotion 显示屏,刷新率最高可达 120Hz,峰值亮度为 3000 nits。

苹果称,iPhone Air 的设计是迄今为止最耐用的,其陶瓷护盾两侧包裹着钛金属框架。
iPhone Air 配备了全新的 A19 Pro 处理器,这是目前最强大的 iPhone 芯片,并且搭载了苹果自研的 C1x 调制解调器,比 C1 快两倍。
此外,iPhone Air 还采用了苹果的新 N1 芯片设计,支持 Wi-Fi 7、蓝牙 6 和 Thread 技术。
尽管如此薄,苹果承诺 iPhone Air 具备全天电池续航,支持最多 27 小时的视频播放,使用售价 99 美元的 iPhone Air MagSafe 电池时,电池续航可达 40 小时。苹果还表示,iOS 26 中的自适应电源模式将帮助设备更加高效。

值得注意的是,iPhone Air 仅支持 e-SIM 卡。仅有 A3518 国行版可在中国大陆激活,并且目前仅支持中国联通。

iPhone Air 配备了 4800 万像素的双摄融合相机系统和一颗 1200 万像素长焦镜头。其还配备了一种新系统,可结合前后摄像头,让你在拍摄自己视频的同时还能捕捉眼前的景物。

1800 万像素的自拍相机还支持居中拍摄功能,这项功能在普通版 iPhone 17 上也有,可以自动将所有人纳入照片中,无需将手机旋转至横屏模式。
为了让 iPhone Air 变得如此薄,苹果在多个方面进行了技术创新和优化,包括调制解调器和芯片。摄像头的设计也经过特别处理,X 光图显示它被紧密集成在手机内,摄像头的设计为平面而非通常的凸起。

iPhone Air 提供黑色、白色、米色和浅蓝色款式。

苹果还发布了几个新配件,包括超薄 MagSafe 电池以及半透明外壳。这两款配件均可搭配一条新的斜挎背带。



iPhone Air 的发布与即将于 9 月 15 日发布的 iOS 26 同步。更新后的操作系统将带来全新的 Liquid Glass 设计语言,使一些导航元素和图标呈现出泡泡状的透明外观,曾在测试期间引发了一些用户的分歧。
iPhone Air 起售价为 7999 元,提供 256GB 存储,最大 1TB 版本售价 11999 元。
iPhone 17 Pro 和 Pro Max
iPhone 17 Pro 和 Pro Max 是 iPhone 17 系列的高端型号。

Pro 系列回归使用铝合金机身,搭载史上最大电池,并在背面采用了一个全新的全宽摄像头平台。

并且首次在三个摄像头上都使用了 4800 万像素传感器,长焦镜头分辨率更高,还配备了比之前大 56% 的传感器,,支持最高 8 倍的光学变焦。
下面是 𝕏 博主 @Zedd 分享的一段实拍视频,看起来效果非常好:
,时长00:09
https://x.com/Zedd/status/1965487516787880307
此外,自拍相机具备 1800 万像素传感器,并支持 Center Stage 功能,可以动态调整画面,确保每个人都出现在照片中,而且无需将手机旋转到横屏模式自拍。
视频拍摄方面新增了「双重捕捉」功能,可以同时使用前后摄像头录制视频,支持 ProRes RAW、Log 2 和 genlock 专业视频功能。苹果宣称其 Pro iPhone 足以满足专业摄影师的需求。
Pro 系列有三种颜色:银色、蓝色和橙色,并从钛金属回归到更坚固的铝合金机身,采用抗刮擦的 Ceramic Shield 玻璃。

iPhone 17 Pro 的屏幕尺寸与去年 16 Pro 相似,后者为 6.3 英寸,而 17 Pro Max 为 6.9 英寸。屏幕依旧支持 ProMotion,最高 120Hz 的刷新率,最高亮度提升至 3000nits,今年四款 iPhone 均支持此亮度。

与新 Air 一样,两个 Pro 型号搭载了 A19 Pro 芯片。这是一款 3nm 工艺的芯片,拥有六核 CPU,苹果表示这是「所有智能手机中最快的」,还配备六核 GPU。
与 Air 不同,Pro 系列配备了苹果迄今为止最大的电池,带来史上最长的电池续航,Pro Max 支持最高 37 小时的视频播放。充电支持更快的 25W MagSafe 无线充电。

iPhone 17 Pro 起售价为 8999 元,Pro Max 起售价为 9999 元,均提供 256GB 存储。这是 Pro 系列的价格小幅上涨,但与 16 Pro 的 256GB 版本一致。Pro Max 首次可配备最高 2TB 存储,售价为 17999 元。
iPhone 17

至于常规款 iPhone 17, 我们简单看看其参数即可:
- A19 芯片,采用第三代 3 纳米制程
- 6.3 英寸超视网膜 XDR 显示屏
- 后摄 4800 万像素,融合式主摄 + 融合式超广角摄像头
- 1800 万像素 Center Stage 前摄
- 正面配备超瓷晶面板 2
- 支持 120Hz 自适应刷新率
- 颜色:薰衣草紫、鼠尾草绿、青雾蓝、白、黑
- 价格:5999 元(256GB),7999 元(512GB)

N1 芯片
苹果在 iPhone 17 系列中推出了自家研发的无线网络芯片 ——N1。

这个芯片支持最新的网络技术,比如 Wi-Fi 7、蓝牙 6 和智能家居协议 Thread。以前,苹果的设备是使用博通的芯片来支持蓝牙和 Wi-Fi,但现在苹果使用 N1 芯片来提升 AirDrop 和个人热点等功能的性能和可靠性。
iPhone 17 全系列都会配备这款 N1 芯片。
此外,苹果还发布了新一代的 C1X 5G 调制解调器,它的速度是上一个版本 C1 芯片的两倍。
AirPods Pro 3
苹果 AirPods Pro 3 是该产品三年来首次重大更新,引入了新的心率传感器,并改进了主动降噪 (ANC) 功能和实时翻译功能。
AirPods Pro 3 现已开放预订,售价 249 美元 / 1899 元,将于 9 月 19 日开始发货。

苹果提升了 AirPods Pro 3 的音质,带来更宽广的声场和更佳的降噪效果。采用泡沫填充耳塞,使其主动降噪(ANC)效果比上一代 AirPods Pro 提升一倍,并称其为「全球最佳的入耳式无线耳机 ANC」。

AirPods Pro 3 引入了一个新的实时翻译功能,用户只需用一个简单的手势,就可以开始翻译对方说的语言。同时,主动降噪功能会降低说话者的音量,帮助用户更集中精力听到翻译内容。
实时翻译不仅翻译单个单词,还会翻译整个短语的意思,尤其是当两个人都佩戴 AirPods Pro 时,翻译效果更好。如果其中一方没有免提功能,还可以选择用 iPhone 作为显示屏,实时显示对方说话内容的转录,并翻译成对方偏好的语言。
苹果提升了 AirPods Pro 的舒适性、稳定性和耐用性,特别适合运动时使用。苹果分析了大量耳朵形状的数据,优化了 AirPods Pro 的设计,使它们更小、更符合耳道的自然结构,并且提供五种不同尺寸的耳塞。此外,AirPods Pro 3 还具备 IP57 级防汗防水功能,即使在剧烈运动或大雨中使用也不怕损坏。

进一步提升健身体验的功能是心率监测。苹果为 AirPods Pro 3 定制了最小的心率传感器,结合机器学习算法和加速度计数据,精确测量心率。同时,它还通过新 AI 模型进行活动和卡路里跟踪,并结合 Apple Heart 和 Movement Study 的数据,帮助用户更好地追踪运动情况。
同时,苹果还为用户提供了「Workout Buddy」功能,利用 Apple Intelligence 在运动时激励用户、追踪锻炼数据和健身历史记录。
在电池方面,AirPods Pro 单次充电的续航时间从 6 小时提高到了 8 小时,而对于助听器用户,透明模式下的续航时间达到了 10 小时,比上一代增加了 4 个小时。
Apple Watch
苹果更新了三款 Apple Watch。

苹果发布的 Apple Watch Series 11 是迄今为止最薄的 Apple Watch,起售价 399 美元 / 2999 元,今天开始接受预订,并将于 9 月 19 日开始发货。

首款支持 5G 连接,配备了重新设计的蜂窝天线,在信号较弱的区域提供更好的覆盖,并具备实时翻译功能。

它还能够监测高血压,并使用光学心率传感器和新算法在后台追踪血压变化。新增的睡眠评分功能帮助评估睡眠质量。

电池续航最长可达 24 小时,配备 Ion-X 玻璃,抗刮擦能力是上一代的两倍。
铝合金版本将提供亮黑色、太空灰、玫瑰金和银色;抛光钛金属版本将提供自然色、金色和灰色。


(左右滑动查看图片)
苹果还发布了新款入门级 Apple Watch SE 3,配备更快的 S10 处理器、更长的电池续航(续航达 18 小时)、更强的前玻璃、5G 蜂窝连接和温度传感器,且终于支持常亮显示。

40mm 型号起售价 1999 元,9 月 19 日发售,现已开始接受预订。SE 3 还将提供更大的 44mm 型号(2199 元起),且两款都将有午夜色和星光色铝合金表壳。

SE 3 还支持双击和手腕轻甩手势、睡眠呼吸暂停检测、睡眠评分、回顾性排卵估算、2 倍更快充电、通过扬声器播放音乐和播客等功能。
此外,苹果还发布了 Apple Watch Ultra 3,新增 5G、最长 42 小时电池续航和卫星连接功能。其屏幕边缘更接近,显示区域更大,支持高血压提醒和睡眠评分。

起售价 799 美元 / 6499 元,提供自然色和黑色钛金属款,9 月 19 日发售。

Ultra 3 继承了 Ultra 2 的特点,专为运动员和运动爱好者设计,具有大电池寿命(Apple 承诺 Apple Watch Ultra 2 在正常使用下可达 36 小时)、明亮的显示屏和改进的 GPS 功能。
除了新款手表,苹果还将在今年秋季发布 watchOS 26,其中包括由 Apple Intelligence 驱动的 Workout Buddy、改进的 Smart Stack、手腕轻甩手势来关闭通知,以及苹果的新 Liquid Glass 设计语言。
网友评论
苹果发布会还没开始,就被网友剧透个差不多,还多次承包微博热搜。
尤其是 iPhone 17 的外观设计,社交平台上吵翻了天。

很多人打差评,有说长得像电子秤,有说长得像充电宝,总之丑得很有辨识度,甚至华为 Mate 60 Pro 的井盖镜头都能看顺眼了,毕竟配上个小黄人手机壳。
但也有人认为,年年说丑,年年卖爆。
对此,你怎么看?
请在手机微信登录投票
买吗? 单选
买!
不买!
犹豫。
参考链接:
https://www.youtube.com/watch?v=H3KnMyojEQU
https://www.theverge.com/news/772434/apple-iphone-17-event-news
....
#AI应用元年,这场标杆赛事见证了中国创新速度与野心
一场关于未来金融智能的集体预演,见证了创业者们的冲刺,也折射出一个行业的进化。
2025 年的 AI ,正在上演「双线长跑」。
一端是大模型底层的持续进化,远未触顶;另一端是场景应用集中爆发。
来自 a16z 最新发布的全球百强 GenAI 应用榜单,释放出一个清晰信号,在「 AI 如何改造行业」应用上,中国玩家已展现出全球领先优势。
与此同时,国务院印发的「人工智能+」行动计划又添了一把柴。AI 的赋能范围,正从新质生产力的试点,扩展到全社会,被视作未来现代化的核心引擎。
这股脉动,在 AFAC2025金融智能创新大赛上体现得淋漓尽致。作为连续举办三年的金融智能标杆赛事,它已成为海内外 AI 创业团队的聚合地。在为期三个月的赛程中,11 支队伍从初创组脱颖而出——
获奖方案直击真实金融痛点,覆盖底层技术突破与复杂系统工程,落地性极强,跨界创新尤为显著。

11支获奖团队的项目方向、技术亮点和应用场景,大都直击真实金融痛点,落地性极强,「跨界」创新明显。
现在正处于一个「转折点」,其规模和影响力不亚于十年前的互联网创业浪潮,评委们直言。
但与那时不同,AI 已不再是「附加选项」,而是新兴企业的底层基础设施——速度更快,范围更广,也更难以回避。「在这场竞赛中,中国跑在了前列。」Roselake Ventures 共同创始人及合伙人阳靳光说。
中国的应用落地速度是全球领先的,另一位评委、xcube.co 首席幕僚长兼董事、新加坡金融科技节和 GFTN 日本论坛官方大使 Eelee Lua 相信,到 2030 年,AI 将在技术突破和产业落地上带来「更多重大」的创新。
「归巢」父子兵
11 支获奖队伍中,有一对组合比较特别:32 岁的徐周明和 60 岁的父亲徐俊。
今年大赛出现了一个显著趋势:来自美国、英国、新加坡、日本等地的 AI 人才集体「归巢」,回国创业和参赛。参赛者年龄跨度从 20 岁到 65 岁,创业热情跨越世代。徐氏父子的故事,正是这股浪潮的缩影。
徐周明是「 90 」后,本科就读于香港(数学与金融双学位),毕业后进入顶尖投行做持牌交易员,拿下 CFA 证书,随后转向家族办公室和对冲基金。
2019 年,他决定把「 AI + 金融」的直觉转化为事业,在大湾区创立香港凤凰涅盘科技。
初创组答辩现场,徐周明进行方案分享。
这一次,他们带来的项目被称为「反洗钱 3.0 」,技术核心是群体学习:结合联邦学习与区块链,解决数据共享与隐私保护的难题。
传统联邦学习虽然能让数据留在各银行本地,但聚合过程仍依赖中央处理器,一旦被黑客攻击,就可能通过反推泄露敏感信息。
徐周明的方案,是彻底「去中心化」——在联邦学习框架中引入区块链和智能合约,让不同节点随机承担聚合任务:这一轮可能在 A 银行完成,下一轮可能在 B 银行完成,从根源上消除中央节点的单点风险。
与他并肩的是父亲徐俊,自称「老行政」。在内地行政体系工作多年,他更关注原则与方向,「我们的技术要为祖国、为社会服务。」
徐俊在初创组答辩现场,为台上正在路演的儿子徐周明拍摄记录。
父子同台并非噱头,而是一种中国式创业的缩影:国际先导与本土落地的对接。
香港的金融环境提供了跨境、跨国的先导性难题,逼迫团队更早面对数据主权与隐私计算。他们的体系已在香港部分金融机构试点,并得到数码港等机构支持。
来到上海参赛,则让他们有机会把国际化经验与技术移植到内地——而内地,尤其是上海,拥有广阔的落地土壤。
「海归团队常常被批评水土不服。」徐周明承认。父亲的加入,恰好补齐沟通与制度上的短板。对这对「父子兵」而言,技术与制度、全球视野与本土语境,正试图在同一条赛道上同步加速。
硬核创新,跨界浪潮
如果说「归巢」是一大趋势,那么「跨领域」则是另一条清晰的注脚。
像徐周明那样,把联邦学习与区块链放进同一套方案的案例并不少见。光通信、卫星遥感、图计算、区块链等技术,正与金融场景叠加,参赛方的出身各异,却指向相似的目标:缩短时延,降低风险,提升合规效率。
冠军项目来自光通科技。他们用光通信技术重塑金融交易网络,搭建起一条比高铁还快的金融专用信息高速公路。
自研的 2 Tbit/s 光模块,按团队说法,足以支撑每秒数百万张高清图片的传输。而关键部件——硅光微环调制器、PIN 探测器和封装平台——全部自研,目标直指国产化与安全合规。
而拿了二等奖的岙邗科技,则把卫星遥感的「天眼」对准了金融风控。他们提出「卫星遥感+信贷立体化风控全周期监测方案」,已在部分金融客户中落地。
所谓「全周期」,是利用卫星每 15-30 分钟的重访能力,持续追踪目标的时序变化;而「立体化」,则能从三维角度获取信息,比如估算树木高度、区分树种。
负责人陈镜荣举了个例子:台风过境后的江浙农田,农户只需在保险 App 上标注地块,后台就能通过卫星影像自动估算淹水面积与倒伏程度,赔付额度随即生成。
初创组答辩现场,陈镜荣进行方案分享。
过去几百万亩地要靠大批调查员逐户走访,既耗时又难免夹杂人情因素,他告诉我们,如今赔付误差被控制在 5% 以内,赔付周期从数月缩短至数天,甚至数小时。
支撑该方案的,是自研的 5 nm 级高光谱分光器(可用于分析地质成分),主动多极化微波成像雷达(可穿透云层与沙尘暴等极端天气成像),以及多种遥感影像智能解译算法与低照度图像增强技术。
另一位二等奖获得者图盾科技,则把学术界的「图计算」带入金融风控一线,把行业普遍仅约 10% 的风险识别率提升到 50% 以上。该项目去年还斩获日内瓦与纽伦堡发明金奖。
团队负责人秦宏超博士留校任教于北京理工大学,曾参与国家重点研发任务,并首次将图计算方法应用于金融风控。
初创组答辩现场,秦宏超进行方案分享。
以票据中介识别为例,秦宏超解释说,传统方法多聚焦单一用户的交易数据,如短期内票据流转的数量、金额,容易将建筑企业的高频大额流转误判为异常,误报频繁。
图盾的方案则在学习用户金融特征的基础上,引入图神经网络,深度建模由票据流转形成的关系网络,使系统能够理解用户之间的业务往来与资金流向。同时叠加时序建模与多源数据融合,分析个体时序交互与群体(同伙或关联方)行为模式。
只有当某个用户在金融行为、关系网络、时序交互与群体模式等多个维度同时「高亮」时,才会被判定为高风险。在一次银行测试中,图盾提交的 200 余个名单里,55% 被确认为疑似票据中介,远超行业均值。
「我们的技术在百万级数据集上 2 秒内挖掘出 5 个节点的时序模式,而传统数据库的 join 操作需要上千秒才能完成。 更重要的是,不需要额外的高配算力,银行现有设备就能支持。」秦宏超强调。
多元与包容
大多数获奖项目有着相似的轮廓——
直击金融的核心痛点:反欺诈、反洗钱、信用评估等;成果不再停留在 PPT,而是真实运行在银行、证券、保险乃至对冲基金的业务中。
例如,金蝶征信凭借一套「足够成熟」的知识图谱增强风控大模型,已与两百余家金融机构建立紧密合作。
图盾科技的方案也在五家银行、证券所、蚂蚁集团的产学研合作项目以及一家反洗钱公司中落地应用
但在同一个舞台上,还闪耀着另一种光。
大三学生李天一和他的团队「厦门蓝天之上科技有限公司」,带来了一款与金融智能并不密切相关的应用:让手语在屏幕上实时转化为文字。它也没有炫目的技术,却让这个舞台更显多元与包容。
初创组答辩现场,李天一进行方案分享。
李天一就读于闽南理工学院机械电子与工程专业,团队核心成员来自厦门大学生命科学学院。灵感源于一次支教:在特殊教育学校里,听障孩子在课堂与生活中仍被沟通高墙隔绝,能不能用 AI 为他们做点什么?
由于市面上缺乏高质量的手语数据集,他们只能亲自采集、逐帧标注:录制视频,切分图像,再一点点加标签。如今,团队已覆盖上百类基础手语。
在实验室中,模型准确率可超过 80%;但在真实环境里,光照、角度、背景噪声常使效果打折。如何让模型更具泛化能力,成了李天一和他的团队必须攻克的课题。
算力有限,他们更多依赖免费或低成本的云资源。李天一坦言,工作量太大,但愿意慢慢补。
这次参赛契机也很朴素,「朋友介绍来的,听说有奖金。」他笑说。平日他们靠算法比赛奖金维持运转与研发,「如果拿到奖金,就买器件、上设备,继续打磨产品。」
是舞台,也是孵化器、风向标
在 AFAC 的舞台上,奖金有时被定义为一种燃料。李天一已经为它找好了去处,投向一个智能假肢项目。
而对那些历经赛事洗礼的老将来说,它的吸引力不在奖金数字,而是赛道专业与场景真实。
徐周明曾活跃在各类创新赛事,累积斩获 80 余项奖项。他强调,区别于那些「泛行业」舞台,AFAC 的专注与专业性,反倒让他们更有底气展示「真东西」。
这种专业不仅刻在赛题上,更写进评审团的构成与一次次点拨里。
近五十位来自技术、产业和资本的评委,台上「问诊」、台下拆解,从企业出海到落地挑战、从合规难点到资本语言,甚至为团队开出「组队」处方,帮助他们寻找通向未来的路径。
阳靳光把非洲、中东、东南亚的早期投资与孵化清单带进赛场,他在区块链、物联网、机器人领域的下注,正好与不少项目的「跨界融合」相互呼应。年轻团队希望借 AFAC 完成从 0 到 1 ,他则用资本吸引力与跨境落地的标尺,为他们衡量可行与不可行。
来自新加坡的 Eelee Lua 则凭借 17 年的金融科技与合规经验,帮参赛者判断方案是否能真正走到市场那一端。
例如,金蝶征信计划出海,将技术能力延伸至东南亚、美洲市场。农产品种植的周期,中外类似,这类数据可以复用。但要真正落地,还需要当地金融机构的配合与本地化改造。这正是投资人和顾问网络发挥作用的地方。
针对岙邗科技的遥感影像数据安全与合规挑战,评委建议探索「存算分离」模式:影像数据归属客户,团队仅负责处理分析,从而规避敏感风险,陈镜荣坦言,这是一个意想不到的解法。
李天一带走的启发则更具转向意味:尝试「用公益的心做商业化」,把手语识别模型适配到银行大屏,或在碳排放等产业场景寻找落点——「以前没想到这个方向」,他说,也许会在上海先行试水。
秦宏超记得评委的叮嘱,「找合伙人要抓紧,但不要太急。」眼下,他正在准备在 9 月 10 日开幕的上海外滩大会上,用 demo show 打出名声,扩大可见度。
「他们渴望合作,却缺少渠道。」在阳靳光看来,像 AFAC 这类赛事,正是搭建桥梁的机会,让中国创业者被更多人看见,也让海外市场找到连接的通路。
而对更多团队而言,它也是一座通往上海的桥。
我们正准备在上海落地注册公司,拓展长三角的业务。陈镜荣透露,岙邗科技已经对接了张江的一家硬科技孵化器。「这个孵化器本身就专注航天、光电等硬核方向,和我们非常契合,还有潜在的客户资源。」
徐周明也与本地金融机构建立起更紧密的联系,期待推动实质落地,将产品落地到上海。
最终,大家的收益并不止于方法论、资源与曝光,还有思想的拓展。「有些想法,也许现在用不上,但三五年后可能就能落地。或者它在一个市场不适用,却在另一个市场能打开局面。」陈镜荣说。
新一轮 AI 应用浪潮席卷而来,AFAC 也不再只是一个竞赛的名字。它在悄然生成另一种角色:创业的孵化器、行业的风向标。
三年来,越来越多的项目在这里找到落地的路径,越来越多的想法在这里获得启发与验证。它把资本、技术、产业和政策拉到同一张桌子上,把「可能」推向「可行」。
它是一场关于未来金融智能的集体预演,见证了创业者们的冲刺,也折射出一个行业的进化。它让不同的人在这里相遇,未来中国 AI 创业领军者,或许会在这片舞台上第一次被看见。
....
#Real-Time Detection of Hallucinated Entities in Long-Form Generation
AI胡说八道这事,终于有人管了?
想象一下,如果 ChatGPT 等 AI 大模型在生成的时候,能把自己不确定的地方都标记出来,你会不会对它们生成的答案放心很多?

上周末,OpenAI 发的一篇论文引爆了社区。这篇论文系统性地揭示了幻觉的根源,指出问题出在奖励上 —— 标准的训练和评估程序更倾向于对猜测进行奖励,而不是在模型勇于承认不确定时给予奖励。可能就是因为意识到了这个问题,并找出了针对性的解法,GPT-5 的幻觉率大幅降低。
随着 AI 大模型在医疗咨询、法律建议等高风险领域的应用不断深入,幻觉问题会变得越来越棘手,因此不少研究者都在往这一方向发力。除了像 OpenAI 那样寻找幻觉原因,还有不少人在研究幻觉检测技术。然而,现有的幻觉检测技术在实际应用中面临瓶颈,通常仅适用于简短的事实性查询,或需要借助昂贵的外部资源进行验证。
针对这一挑战,来自苏黎世联邦理工学院(ETH)和 MATS 的一项新研究提出了一种低成本、可扩展的检测方法,能够实时识别长篇内容中的「幻觉 token」,并成功应用于高达 700 亿(70B)参数的大型模型。

- 论文标题:Real-Time Detection of Hallucinated Entities in Long-Form Generation
- 论文地址:https://arxiv.org/abs/2509.03531
- 代码地址:https://github.com/obalcells/hallucination_probes
- 项目地址:https://www.hallucination-probes.com/
- 代码和数据集:https://github.com/obalcells/hallucination_probes
该方法的核心是精准识别实体级幻觉,例如捏造的人名、日期或引文,而非判断整个陈述的真伪。这种策略使其能够自然地映射到 token 级别的标签,从而实现实时流式检测。

通过 token 级探针检测幻觉实体。在长文本生成场景(Long Fact、HealthBench)中,线性探针的性能远超基于不确定性的基线方法,而 LoRA 探针则进一步提升了性能。该探针同样在短文本场景(TriviaQA)以及分布外推理领域(MATH)中表现出色。图中展示的是 Llama-3.3-70B 模型的结果。
为实现这一目标,研究人员开发了一种高效的标注流程。他们利用网络搜索来验证模型生成内容中的实体,并为每一个 token 标注是否有事实依据。基于这个专门构建的数据集,研究人员通过线性探针(linear probes)等简洁高效的技术,成功训练出精准的幻觉分类器。


在对四种主流模型家族的评估中,该分类器的表现全面超越了现有基准方法。尤其是在处理长篇回复时,其效果远胜于语义熵(semantic entropy)等计算成本更高的方法。例如,在 Llama-3.3-70B 模型上,该方法的 AUC(分类器性能指标)达到了 0.90,而基准方法仅为 0.71。此外,它在短式问答场景中也展现出优越的性能。
值得注意的是,尽管该分类器仅使用实体级标签进行训练,它却能有效识别数学推理任务中的错误答案。这一发现表明,该方法具备了超越实体检测的泛化能力,能够识别更广泛的逻辑错误。

虽然原始数据集的标注成本高昂,但研究发现,基于一个模型标注的数据可被复用于训练针对其他模型的有效分类器。因此,研究团队已公开发布此数据集,以推动社区的后续研究。
方法概览
用于 token 级幻觉检测的数据集构建
为了训练能够在 token 级别检测幻觉的分类器,研究者需要一个对长文本中的幻觉内容有精确标注的数据集。这个过程分为两步:(1) 生成包含事实与幻觉内容的混合文本 ;(2) 对这些文本进行准确的 token 级标注,以识别哪些 token 属于被捏造的实体。下图展示了该标注流程。

token 级标注流水线。
- 数据生成
研究者在 LongFact 数据集的基础上,创建了一个规模扩大 10 倍、领域更多样化的提示集 LongFact++。
LongFact++ 包含主题查询、名人传记、引文生成和法律案件等四类提示,旨在诱导大语言模型生成富含实体的长文本,作为后续标注的原材料。
- token 级标注
与传统方法将文本分解为 atomic claims 不同,该研究专注于标注实体(如人名、日期、引文等),因为实体有明确的 token 边界,易于进行流式检测。他们使用带有网络搜索功能的 Claude 4 Sonnet 模型来自动完成标注流程。
该系统会识别文本中的实体,通过网络搜索验证其真实性,并将其标记为「Supported」(有证据支持)、「Not Supported」(被证实是捏造的)或「Insufficient Information」(信息不足)。
- 标签质量
为验证标注质量,研究者进行了两项检查。首先,人类标注员的标注结果与大模型自动标注结果的一致性为 84%。其次,在一个包含已知错误(人工注入)的受控数据集中,该标注流程的召回率为 80.6%,假阳性率为 15.8% 。
训练 token 级探针
探针是一个附加在语言模型上的幻觉检测器,它由一个线性的「价值头」和可选的 LoRA 适配器组成。价值头读取模型中间层 ℓ 的隐藏状态

,并输出一个 token 级的幻觉概率 :

训练的总损失函数

是一个组合,它既包括用于训练幻觉分类器的探针损失

,也包括一个用于约束模型行为变化的正则化项

。
为了解决幻觉信号通常集中在少数几个关键 token 上的问题,研究者设计了一种结合了逐词损失和跨度最大值损失 的混合损失函数 。其公式如下:

这个设计的巧妙之处在于:对于一个被标记为幻觉的文本片段,只要其中至少有一个 token 的幻觉分数很高,损失函数就会给予奖励,从而让探针学会更精确地聚焦于关键错误信号 。
实验结果
在长文本设置中(LongFact 和 HealthBench),token 级探针在两个主要模型上的表现都显著优于基线方法(表 1)。简单的线性探针始终实现了 0.85 以上的 AUC 值,而 LoRA 探针进一步提升了性能,将 AUC 推高到 0.89 以上。

相比之下,基于不确定性的基线方法表现均不佳,AUC 值均未超过 0.76。在短文本设置中(TriviaQA),基线方法比长文本设置中表现更强,但探针仍然领先。LoRA 探针始终实现了超过 0.96 的 AUC 值,线性探针也表现良好。值得注意的是,本文提出的探针在 MATH 数据集上也取得了强劲的结果。这种分布外的性能表明,本文提出的方法捕获了正确性的信号,这些信号的泛化性超出了其最初针对的虚构实体。
作者在三个次要模型上复制了长文本结果,每个模型仅使用 2000 个其自身长文本生成的注释样本进行训练。结果是相似的:LoRA 探针再次优于线性探针,在 LongFact 生成上的 AUC 值在 0.87-0.90 之间。次要模型的完整结果显示在表 5 中。

虽然 LoRA 探针的 AUC 值在多个设置中接近或超过 0.9,但长文本上的 R@0.1 最高约为 0.7,即在 10% 假阳性率下,检测器能够识别出大约三分之二的幻觉实体。这些结果既突出了相对于标准基于不确定性基线方法的实际收益,也表明在这类方法能够广泛应用于高风险场景之前,仍有进一步改进的空间。
更多细节请参见原论文。
....
#MobiAgent
人人都能炼专属Agent,上海交大开源端侧Agent全栈工具链,真实场景性能超GPT-5!
打开手机,让 AI Agent 自动帮你完成订外卖、订酒店、网上购物的琐碎任务,这正成为智能手机交互的新范式。
一个能自主处理大部分日常任务的个人专属智能体,正在从科幻走进现实。
然而,通往 “解放双手” 的最后一公里却并不好走。如何高效地训练和在手机端部署 Agent 模型,长期以来似乎都是少数大厂的 “自留地”。从高质量操作数据的获取,到模型的训练与适配,再到移动端 APP 的优化,重重门槛将绝大多数开发者和普通用户挡在门外,也极大地限制了移动端 Agent 的生态发展。
就在刚刚,这一局面迎来了新的破局者。
来自上海交通大学 IPADS 实验室的团队,正式开源了一套名为 MobiAgent 的移动端智能体 “全家桶”。
- 论文地址: https://arxiv.org/abs/2509.00531
- AgentRR 论文:https://arxiv.org/abs/2505.17716
- 项目仓库: https://github.com/IPADS-SAI/MobiAgent
- 模型:https://huggingface.co/IPADS-SAI/collections
- APP:https://github.com/IPADS-SAI/MobiAgent/releases/download/v1.0/Mobiagent.apk
这套框架,首次将从 0 到 1 构建手机 Agent 的全流程完整地向所有用户开放。这意味着,从收集手机操作轨迹数据开始,到训练出一个能听懂自然语言指令、帮你处理日常事务的专属 Agent,再到最终将它部署在自己的手机上,现在,人人都能上手 DIY。
当然,光能 “炼” 还不够,性能必须能打。为了验证 MobiAgent 的真实能力,研究团队直接在国内 Top 20 的 App 上进行了实测。结果显示,7B 规模的 MobiAgent 模型,在任务平均完成分上,不仅超越了 GPT-5、Gemini 2.5 Pro 等一众顶级闭源大模型,也优于目前最强的同规模开源 GUI Agent 模型。
除了 Agent 能力之外,团队还为 Agent 设计了一个独特的 “潜记忆加速器”。面对点外卖、查地图这类高频重复操作,MobiAgent 能够 “举一反三”,通过学习历史操作来简化决策,靠 “肌肉记忆” 完成 Agent 任务,最终将端到端的任务性能提升了 2-3 倍。这样一套集 “数据捕获、模型训练、推理加速、自动评测” 于一体的四位一体框架,可以说,彻底打通了移动智能体从开发到落地的 “最后一公里”。
这,或许才是普通人真正想要的 Agent。那么,MobiAgent 究竟是如何做到的?
,时长00:51
Agent 养成全攻略:三步走
要让 AI 学会玩手机,首先得让它看懂人是怎么操作的。MobiAgent 的第一大核心,就是贡献了一套 AI 辅助的敏捷数据收集 “流水线”。
过去,给 AI 准备 “教材”(标注数据)又贵又慢。现在,MobiAgent 用一个轻量级小工具,就能记录下人类在手机上的所有点击、滑动、输入等操作轨迹。对于一些简单的任务,这一录制过程甚至可以完全交给大模型完成,进一步提高了数据收集的效率。

MobiAgent数据收集与自进化流程
但只有操作还不够,AI 得理解 “为什么” 这么做。于是,团队使用通用的 VLM 模型(例如 gemini-2.5-pro),让它对着操作记录,“脑补” 出每一步的思考过程和逻辑,自动生成高质量的 “带思路” 的训练数据。最后,也是最重要的一步,这些数据会经过一个自动化 “精炼流水线”,调整数据的难易平衡比例、输入任务描述、历史信息长度等等,让训练出的 Agent 模型具有更强的泛化能力。
有了高质量的教材,下一步就是训练。MobiAgent 的 "大脑"MobiMind,被设计成了一个分工明确的 “三人小组”:
- Planner(规划师): 负责理解复杂任务,进行拆解。
- Decider(决策者): 看着当前手机屏幕,决定下一步干啥。
- Grounder(执行者): 负责把 “点搜索按钮” 这种指令,精准定位到屏幕上的坐标并点击。
这种 “各司其职” 的架构,让模型训练起来更高效,能力也更强。
让 Agent 拥有 “肌肉记忆”,速度飙升 3 倍
光聪明还不够,反应慢也是硬伤。你肯定不想让 Agent 帮你买杯咖啡,结果思考了半分钟。为此,MobiAgent 团队祭出了第二个大杀器:AgentRR(Agent Record&Replay)加速框架。这个框架的核心思想,就跟我们人类的 “肌肉记忆” 一样:对于重复做过的事,直接凭经验搞定,不用再过一遍大脑。

AgentRR系统架构
AgentRR 会把智能体执行过的任务轨迹,通过树的形式记录在一个叫 ActTree 的结构里。当接到一个新任务时,一个超轻量的 “潜意识”(Latent Memory Model)会迅速判断:
这个任务我是不是做过类似的?前几步是不是可以照搬?
比如,无论是 “搜附近的火锅店” 还是 “搜附近的电影院”,点开地图 App、点搜索框这两步都是完全一样的。AgentRR 就能直接 “复用” 这段操作,跳过大模型的思考过程,从而大幅提升效率。效果有多好?在模拟真实用户使用习惯(80% 请求集中在 20% 任务)的测试中,动作复用率高达 60%-85%。反映在实际任务上,就是 2 到 3 倍的性能提升。

不同请求分布下,AgentRR 的动作复用率
真实场景大比拼:谁是 「手机操作之王」?
是骡子是马,拉出来遛遛。为了公平地评判各大模型的真实能力,团队还专门打造一个更贴近现实的移动端智能体评测基准:MobiFlow。这个基准会基于任务的一个个关键节点,也就是 “里程碑”,对在动态 GUI 环境中执行任务的 Agent 进行精确打分,避免了 “不是满分,就是零分” 的单一评判标准,并且覆盖了社交、影音、购物、旅行、外卖等多个领域的国产主流 App。

MobiFlow智能体评测基准
最终的评测结果,MobiAgent(MobiMind-Decider-7B + MobiMind-Grounder-3B 的组合)在绝大多数 App 上都取得了最高分,尤其是在购物、外卖这类复杂任务上,优势非常明显。相比之下,像 GPT 和 Gemini 这样的大模型,虽然也能完成一些任务,但有时会 “走捷径”,比如把所有要求一股脑全塞进搜索框,依赖 App 自身的 AI 搜索能力。这种 “偷懒” 的做法一旦遇到不支持 AI 搜索的 App,完成率就大幅下降。更重要的是,MobiAgent 在所有测试中都能正确终止任务,而 GPT-5 在 11 个 App 上都出现了 “无限循环” 卡住的问题。



总结
MobiAgent 的出现,不仅在性能上树立了新的标杆,更重要的是,它通过开源整个技术栈,极大地降低了定制化、私有化移动智能体的门槛。从日常应用的 Agent 开发,到每个人的个性化专属助理,想象空间被彻底打开。
或许,那个 “能动口就不动手” 的智能移动时代,就快到来了。
项目成员介绍
MobiAgent核心开发团队主要由上海交通大学IPADS实验室(并行与分布式系统研究所)的端侧智能体研究小组的本科生和硕士生,以及John班的实习生组成。主要指导教师为上海交通大学人工智能学院助理教授冯二虎。
....
#An AI system to help scientists write expert-level empirical software
谷歌AI新里程碑:一个能「做研究」的系统诞生了,用LLM+树搜索编写专家级软件
大模型在科研领域越来越高效了。
昨天,谷歌发表了一篇重磅文章,提出了一个能够帮助科研人员编写「专家级」科研软件的 AI 系统。
该系统融合了大语言模型和传统树搜索,能够自动编写和优化科研任务中所需的软件程序,能够获取多种渠道的现有知识,整合并且重组这些知识来构建一个新的研究思路。
谷歌生成,该系统不仅稳定达到专家水平,还常常超越人类。在基因组学、公共健康、数值分析等多个领域,这套系统的表现甚至超过了顶尖研究团队和国家级集成系统。
- 论文标题:An AI system to help scientists write expert-level empirical software
- 论文链接:https://www.alphaxiv.org/abs/2509.06503v1
如此这般,科研人员在各个领域的研究中都能够使用这一 AI 系统来构建全新的研究思路和实证程序,能够更高效地进行科学研究。

AI 在科研领域的应用一直以自动化的特性为主,能够辅助科研人员进行可行性验证,完成一些重复的高强度工作,减少科研人员在重复验证、调试程序等工作上浪费的时间,更能够激发科研人员的创新思维。
谷歌的这个系统能够实现研究思路的整合与重组,在科研任务中能够创建一些新的策略,构建更高效的模型,让 AI 系统介入科研领域的创新过程,从一次性代码生成的工具,转变为由量化目标指导的迭代、搜索驱动的软件演进。
不过也有网友表达了 AI 深入科研领域的担忧:

谷歌这一次的 AI 系统仍然具有很大的局限性,系统的构建目标是「可评分的科学任务」—— 即那些可以通过准确率、误差率或基准测试排名等指标来量化软件性能的计算问题,虽覆盖了广泛的科研领域,但未提及那些不可量化评估的任务表现。
值得一提的是,前谷歌搜索成员 Deedy Das 分享了这个工作,而他最感兴趣的是论文附录中的 Prompt。


论文中使用的指令:「请创建一种算法,结合两种策略的优点,形成一种真正出色的混合策略,并且其得分要高于任一单独策略。」说明优秀的结果并不总需要非常复杂的 Prompt 指令。
论文详细内容如下:
本研究引入了一个 AI 系统,该系统能自动为科学计算任务创建专家级的实证软件。该系统结合了大型语言模型和树搜索算法,以迭代地生成、评估和完善科学软件解决方案。其核心创新在于,LLM 不仅用于一次性代码生成,而是作为系统搜索过程中一个智能的「变异」引擎,能够整合并重组科学文献中的研究思路。

图 1: (a) 系统架构:展示了可评分问题与研究思路如何输入到大语言模型(LLM),由其生成代码,并在沙盒环境中进行评估,结果以树搜索结构进行组织。(b) 性能对比:不同方法的成功率比较,结果显示结合专家指导的树搜索(TS)取得了最高成功率。(c) 研究思路来源:包括专家知识、学术论文,以及 AI 生成的重组方案。
问题与方法
本系统的目标是「可评分的科学任务」—— 即那些可以通过准确率、误差率或基准测试排名等指标来量化软件性能的计算问题。这类任务涵盖了从基因组学到流行病学再到图像分析等广泛的科学计算应用。
该方法论围绕三个核心组件协同工作:
1. 基于 LLM 的代码变异
不同于从零生成代码,LLM 会持续重写并优化已有的候选代码。系统利用 LLM 对编程逻辑和领域上下文的理解,结合研究思路和性能反馈,进行智能化修改和改进。
2. 树搜索导航
代码生成过程被嵌入到树搜索算法中,以系统化方式探索庞大的软件解空间。搜索过程在「利用」(集中改进已有的优质解)和「探索」(寻找全新方法)之间取得平衡,使用了一种受 AlphaZero 启发的 PUCT 算法变体。
3. 研究思路的融合
该系统的一大特色是能够通过多种渠道引入外部知识:
- 直接注入来自科学论文和教材的研究思路
- 利用如 Gemini Deep Research 等工具生成 LLM 研究见解
- 程序化地重组已有成功方案,形成混合策略
该系统在 Kaggle playground 竞赛中开发与迭代,因其具有快速迭代周期和清晰的人类表现基准,成为理想的测试平台。
跨科学领域的主要成果
基因组学:单细胞 RNA 测序
在从单细胞 RNA 测序数据中去除技术批次效应同时保留生物学信号的挑战性任务中,该系统发现了 40 种新方法,其性能优于 OpenProblems 排行榜上所有已发表的方法。性能最佳的方法 BBKNN (TS) 通过将 ComBat 校正的 PCA 嵌入与批次平衡 K 近邻相结合,比现有最佳方法(ComBat)提高了 14%。

图 2:树搜索进展图,显示了迭代过程中性能的提高,并在突破点处标注了关键算法创新。该系统发现了优化批次感知图构建和实现 ComBat 基因表达校正的方法。
地理空间分析:卫星图像分割
在使用 DLRSD 数据集进行卫星图像的密集像素级语义分割时,该系统的前三名解决方案显著优于最近的学术论文,平均交并比分数大于 0.80。这些解决方案基于现有架构(UNet++、SegFormer),但优化了它们与强大的预训练编码器和广泛数据增强策略的集成。

图 3:卫星图像分割结果示例,显示原始图像(顶行)、真实掩模(中行)和系统预测(底行)。系统成功分割了包括机场、跑道、飞机和基础设施在内的各种特征。
神经科学:全脑神经活动预测
在斑马鱼大脑中建模超过 70,000 个神经元的活动(ZAPBench)时,系统生成的最佳模型在多步预测方面优于所有基线,并且训练速度比竞争视频模型快几个数量级。该系统成功地将生物物理神经元模拟器(Jaxley)整合到高性能解决方案中。
时间序列预测
在涵盖 28 个不同时间序列数据集的 GIFT-Eval 基准测试中,该系统在多个数据集上的性能优于排行榜。值得注意的是,它从头开始创建了一个统一的预测库,该库能自适应地配置到不同的数据集,并将时间序列分解为各个组成部分。

图 4:系统发现的成功预测方法的分布。梯度提升方法(GBM)和集成方法在各种预测任务中是最常成功的策略。
数值分析:复杂积分
对于评估具有无限限度的振荡积分(其中 scipy.integrate.quad () 等标准算法完全失效)时,演化出的代码正确评估了 19 个留出积分中的 17 个,误差在 3% 分数误差之内。该解决方案实现了复杂的数学启发式方法,包括域划分和欧拉变换以加速级数。
技术创新:研究思路与重组
一个关键的创新是研究思路的系统集成及其智能重组。该系统可以分析不同方法的核心原理,并合成创建混合方法的指令。

图 5:方法重组结果分析,显示原始方法与其组合版本之间的性能比较。绿色条表示成功的改进,红色条表示性能下降,而蓝色表示原始方法的性能。
总结
这项研究表明,AI 不仅能够实现自动化,还能在多个科学领域系统性地超越人类在科研软件开发中的表现。系统在生物信息学、流行病学、地理空间分析、神经科学和数值分析等领域中,持续取得专家级,甚至超越人类水准的成果,显示出其广泛的适用性。
该方法标志着科研软件开发范式的转变:从「一次性代码生成」走向「以可量化科学目标为导向」的迭代式、搜索驱动的软件进化。通过将开发周期从「数周甚至数月」缩短至「数小时或数天」,这一系统有效解决了科研中的关键瓶颈问题,有潜力加速所有以可量化指标衡量的计算研究。
系统在大规模解空间中进行系统化探索,融合多元研究思路,并能大海捞针般的找出高质量解决方案。这种能力预示着它可能从根本上改变科研软件的开发方式:
既能让更多研究者平等获取先进的分析工具,也能不断拓展科学探索在计算能力上的边界。
.....
#HyperTASR
港大InfoBodied AI团队首发xx表征新范式,构建任务自适应的感知框架
本文的共同第一作者为香港大学 InfoBodied AI 实验室的博士生孙力和吴杰枫,合作者为刘瑞哲,陈枫。通讯作者为香港大学数据科学研究院及电机电子工程系助理教授杨言超。InfoBodied AI 实验室近年来在 CVPR,ICML,Neurips,ICLR 等顶会上有多项代表性成果发表,与国内外知名高校,科研机构广泛开展合作。
,时长00:59
- 标题:HyperTASR: Hypernetwork-Driven Task-Aware Scene Representations for Robust Manipulation
- 作者:Li Sun, Jiefeng Wu, Feng Chen, Ruizhe Liu, Yanchao Yang
- 机构:The University of Hong Kong
- 原文链接: https://arxiv.org/abs/2508.18802
出发点与研究背景
在xx智能中,策略学习通常需要依赖场景表征(scene representation)。然而,大多数现有多任务操作方法中的表征提取过程都是任务无关的(task-agnostic):
无论xx智能体要 “关抽屉” 还是 “堆积木”,系统提取的特征的方式始终相同(利用同样的神经网络参数)。
想象一下,一个机器人在厨房里,既要能精准抓取易碎的鸡蛋,又要能搬运重型锅具。传统方法让机器人用同一套 "眼光" 观察不同的任务场景,这会使得场景表征中包含大量与任务无关的信息,给策略网络的学习带来极大的负担。这正是当前xx智能面临的核心挑战之一。
这样的表征提取方式与人类的视觉感知差异很大 —— 认知科学的研究表明,人类会根据任务目标和执行阶段动态调整注意力,把有限的感知资源集中在最相关的物体或区域上。例如:找水杯时先关注桌面大范围区域;拿杯柄时又转向局部几何细节。
那么,xx智能体是否也可以学会 “具备任务感知能力的场景表征” 呢?

创新点与贡献
1. 提出任务感知场景表示框架
我们提出了 HyperTASR,这是一个用于提取任务感知场景表征的全新框架,它使xx智能体能够通过在整个执行过程中关注与任务最相关的环境特征来模拟类似人类的自适应感知。
2. 创新的超网络表示变换机制
我们引入了一种基于超网络的表示转换,它可以根据任务规范和进展状态动态生成适应参数,同时保持与现有策略学习框架的架构兼容性。
3. 兼容多种策略学习架构
无需大幅修改现有框架,即可嵌入到 从零训练的 GNFactor 和 基于预训练的 3D Diffuser Actor,显著提升性能。
4. 仿真与真机环境验证
在 RLBench 和真机实验中均取得了显著提升,验证了 HyperTASR 在不同表征下的有效性(2D/3D 表征,从零训练 / 预训练表征),并建立了单视角 manipulation 的新 SOTA。
HyperTASR 概述
在这项工作中,我们提出了 HyperTASR —— 一个基于超网络的任务感知场景表征框架。它的核心思想是:xx智能体在执行不同任务、处于不同阶段时,应该动态调整感知重点,而不是一直用一套固定的特征去看世界。
- 动态调节:根据任务目标和执行阶段,实时生成表示变换参数,让特征随任务进展而不断适配。
- 架构兼容:作为一个独立的模块,可以无缝嵌入现有的策略学习框架(如 GNFactor、3D Diffuser Actor)。
- 计算分离:通过超网络建立 “任务上下文梯度流(task-contextual gradient)” 与 “状态相关梯度流(state- dependent gradient)” 的分离,大幅提升学习效率与表征质量。
换句话说,HyperTASR 让xx智能体在执行任务时,像人类一样 “看得更专注、更聪明”。
任务感知的场景表示 (Task-Aware Scene Representation)

传统的xx智能体操作任务(Manipulation)学习框架通常是这样的:
1. 从观测

提取一个固定的场景表征

2. 在动作预测阶段,再利用任务信息

,共同预测执行的动作:

这种做法的局限在于:表征提取器始终是任务无关的。不管是 “关抽屉” 还是 “堆积木”,它提取的特征都一样。结果就是:大量无关信息被带入策略学习,既降低了策略学习的效率,也增加了不同任务上泛化的难度。
受到人类视觉的启发,我们提出在表征阶段就引入任务信息:

这样,场景表示能够随任务目标与执行阶段动态变化,带来三个好处:
- 更专注:只保留与当前任务相关的特征
- 更高效:过滤掉无关信息
- 更自然:和人类逐步完成任务时的视觉注意模式一致
超网络驱动的任务条件化表示 (Hypernetwork-Driven Task-Conditional Representation)
HyperTASR 的详细结构如 Figure 2 所示。为了实现任务感知,我们在表征提取器后加入了一个 轻量级的自编码器:

其中:
-

- :编码器,
-

- :编码器参数
-

- :解码器
-

- :原始表征,
-

- :任务感知表征
引入自编码器的一大优势在于,自编码器适用于不同的场景表征形式(2D/3D 表征都有对应的自编码器),另外自编码器可以维持原来场景表征的形式,无须调整后续策略网络的结构。
关键在于:

不是固定的,而是由超网络根据任务与执行状态动态调节的:

这里:
-

- 任务目标(如 “拧上绿色瓶子”)
-

- 任务进展编码(task progression)
-

- 由超网络
-

- 生成的动态参数
这样,场景表征不仅会随任务不同而变化,也会在任务的执行过程中不断动态迁移。
这种设计的优势:
1. 梯度分离:任务上下文与状态相关信息在梯度传播中分离,增强可解释性和学习效率
2. 动态变换:不是简单加权,而是真正改变表征函数,使得表征更加灵活
实验验证
HyperTASR 的另一个优势是模块化、易集成。这种 “即插即用” 的设计让 HyperTASR 可以同时增强 从零训练和预训练 backbone 两类方法。我们分别把它嵌入到两类主流框架中进行验证:
1.GNFactor(从零训练):使用 3D volume 表征
2.3D Diffuser Actor(基于预训练):使用 2D backbone 提取特征再投影到 3D 点云
我们只使用了行为克隆损失(Behavior Cloning Loss)作为我们网络的训练损失。

仿真实验
在仿真环境 RLBench 中的 10 个任务上进行训练,实验结果如 Table 1 所示:
- 集成到 GNFactor 后,在无需特征蒸馏模块的情况下(训练无需额外的监督信息),成功率超过基线方法 27%;
- 集成到 3D Diffuser Actor 后,首次让单视角操作成功率突破 80%,刷新纪录。
在此基础上,我们进一步通过网络的梯度进行了注意力可视化:

从 Figure 3 中我们可以观察到:
- 传统方法的注意力往往分散在背景和无关物体;
- HyperTASR 的注意力始终集中在任务相关的物体上,并随着任务进度动态变化。
另外,我们进行了消融实验,证明了 HyperTASR 设计中,引入任务进展的合理性,以及证明了使用超网络相比于直接利用 Transformer 将任务信息融合到场景表征里,能够获得更大的性能提升。
真机实验
我们采用 Aloha 进行了真机 manipulation 实验。如 Table 2 所示,在 6 个实际任务中,HyperTASR 在仅每个任务 15 条示教样本的有限条件下达到了 51.1%,展示了在真实环境操作中的强泛化能力。

一些真机实验对比结果如下:

参考
[1] Ze, Yanjie, et al. "Gnfactor: Multi-task real robot learning with generalizable neural feature fields." Conference on robot learning. PMLR, 2023.
[2] Ke, Tsung-Wei, Nikolaos Gkanatsios, and Katerina Fragkiadaki. "3D Diffuser Actor: Policy Diffusion with 3D Scene Representations." Conference on Robot Learning. PMLR, 2025.
....
#iPhone 17
狂登热搜,iPhone 17「挤爆牙膏」!5999起价,AirPods变身同声传译
苹果年度科技盛宴如约而至,iPhone家族再添新丁!从超薄iPhone Air到性能怪兽iPhone 17 Pro Max,再到全能选手AirPods Pro 3,这些创新能否再次定义智能设备的未来?
一年一度的苹果「科技届春晚」,来了!
从性能狂飙的A19 Pro芯片,到全球首款极致轻薄的iPhone Air,再到全新三摄融合的iPhone 17 Pro Max,以及支持心率监测与实时翻译的AirPods Pro 3……
苹果用一场堪称「硬件风暴」的发布会,把AI、影像、芯片、续航、设计推向了前所未有的高度。

内容速看
- iPhone Air颜值爆表,薄得不行。但实在装不下实体SIM卡槽,中国联通不得不给这款手机开绿灯办理eSIM。
- iPhone 17终于配备了高刷屏,相较上一代iPhone 16升级幅度大且全面,是这一代iPhone当之无愧的「性价比之王」。
- iPhone 17 Pro和iPhone 17 Pro Max仍然是当之无愧的新机皇,全新一体化机身更省电了。
- A19 Pro纸面性能数据爆表,只等新机抵达各大数码评测博主手里,然后屠榜了。
- Apple Watch升级较为常规,但健康管理和预警可能救你一命!
- AirPods Pro 3带来了一项革命性的功能——实时翻译:可以捕捉环境音中的人声并翻译后直接通过耳机播放,让你和外国人无缝交流。
感兴趣的朋友,可以关注一下抢购时间:
·现在,AirPods Pro 3即可开始预购,9月19日正式发售,每人限购6副。
· 9月11日早9点,Apple Watch开始接受预购,9月19日正式发售,所有款式每款每人限购6只。
·9月12日晚8点,iPhone开始接受预购,9月19日正式发售,所有机型每款每人限购2部
苹果的股价在一路暴跌
iPhone 17家族登场
苹果挤爆牙膏
iPhone Air:史上最薄,国行版eSIM来了
首先,是苹果有史以来最薄的手机——iPhone Air。
全新iPhone Air仅5.6毫米厚、重165克,虽然如此纤薄,iPhone Air的性能一点也不差。
它配备了6.5英寸显示屏和A19 Pro芯片,显示屏拥有120Hz的ProMotion。
iPhone Air在户外使用时拥有高达3000尼特的峰值户外亮度——这也是iPhone有史以来最高的亮度。
面对如此薄的机身,iPhone Air的框架由钛金属打造,背面和正面都有超瓷晶(Ceramic Shield)保护。
苹果宣称其比以往的任何iPhone都耐用。
iPhone Air背面有一个明显的突起平台,用于容纳相机、扬声器和芯片。
这个设计扩展了电池空间,使其能够提供全天的电池续航能力。
iPhone Air提供四种配色:太空黑、云白、浅金和天蓝。
价格分别为7999元、9999元和11999元(256G、512G、1TB)。
9月12日开始预售,并于9月19日开始发售。
iPhone Air引入了全新的Center Stage(居中)前置相机。
这是iPhone上首款方形前置传感器,具备更广视野,最高可拍摄1800万像素照片。
用户不再需要为横向自拍而旋转手机——竖握iPhone即可拍摄纵向或横向的照片与视频。
前置相机还支持4K HDR的视频录制,可同时使用前后摄录制。
背面是一个4800万像素融合式摄像头系统,按照苹果的说法,它相当于将多个摄像头融合一体。
这款定制主摄支持28mm与35mm焦段,2.0µm的四合一像素传感器配合传感器位移式光学图像防抖(OIS)功能,在低光环境下表现出色。
用户还可使用2倍长焦功能来拉近与拍摄对象的距离,该镜头搭载了经过优化的光像引擎(Photonic Engine)。
为iPhone Air设计的新图像处理管线具有与多摄像头系统同级的焦点控制功能,可实现新一代人像拍摄,自动捕捉景深信息,供用户后期在照片app中将照片转为人像模式。
iPhone Air 还支持最新一代摄影风格,包括新的「珠光」风格,可提亮肤色,并赋予整张照片明艳活力。
左右滑动查看
iPhone Air可拍摄4K60 fps杜比视界视频,并支持运动模式。视频声音则采用空间音频录制。
iPhone Air能设计得如此轻薄,得益于A19 Pro、N1和C1X三款芯片。此外,iPhone Air的能效也创下了iPhone历来新高。
这使得iPhone Air拥有不错的游戏性能,甚至足以驱动生成式 AI 模型在设备端顺畅运行。
,时长00:09
iPhone Air搭载了Apple设计的全新网络无线芯片N1,支持Wi-Fi 7、蓝牙 6和Thread技术。iPhone Air还搭载了由Apple设计的新版蜂窝调制解调器C1X,速度较C1提升至最多2倍。
有了这些最新芯片加持、为电池留足空间的内部架构加上软件优化,让iPhone Air电池能效表现成为亮点。
不过,iPhone Air的电池容量仅3000毫安时出头,具体续航时间还要实际体验。
值得一提的是,iPhone Air是首款在所有地区都不支持实体SIM卡的iPhone。
按照苹果的说法,采用eSIM设计可以节省内部空间,有助于实现极致轻薄的形态。
有意思的是,根据iPhone Air国行页面显示,iPhone Air目前似乎仅支持中国联通,而且需要前往营业厅进行身份验证。
苹果为最新的iPhone Air推出了一系列新配件,包括:
- iPhone Air MagSafe保护壳,提供霜雾色和暗影色两种配色。
- 纤薄轻盈的iPhone Air防护边框提供四种与机身同色系的色彩,完美贴合机身四周。
- 斜挎挂绳采用100%再生纱线制造,具有舒适的垂坠感,内嵌的柔性磁体和不锈钢滑扣可轻松调节长度。
- iPhone Air MagSafe电池,具有轻薄设计,可无缝贴合设备背部。与iPhone Air配合使用时,可提供长达40小时的视频播放时间。
左右滑动查看
你觉得这款全新的手机怎么样?是你的菜吗?
iPhone 17 Pro:首次装上均热板,最耐用「拍照神器」
这次的iPhone 17 Pro从里到外,采用了全新设计:
全新外壳、全新散热、全新芯片、全新屏幕、全新续航、全新相机、全新的视频处理能力
同样,颜色也是全新的三款:银色、星宇橙色和深蓝色。
外观与结构全面焕新,线条更利落,手感与质感同步升级,「从里到外都换了代」
性能最强的Pro系列,依旧是「iPhone中的iPhone」:
- 最新的航空级铝合金机身:这代设计的核心,让出更大空间,让整机在强度、续航与可靠性上全面进阶。
- 最耐用的背板:传统玻璃升级为Ceramic Shield(超瓷晶)材质,抗跌耐刮能力进一步提升
- 最好的硬件:最强的摄像头、最强的芯片A19 Pro
- 最强的视频处理能力:满足专业拍摄,本次发布全程由iPhone 17 Pro Max拍摄
为释放性能与深度优化电池布局,苹果这次采用铝合金一体式机身。
全新的机身设计不仅腾出了更多的空间,前凸的摄像头设计巧妙融合了天线,保障了信号和视频性能。
航空级铝合金不仅格外轻盈,散热比之前使用的金属钛快20倍,长时间用手机不怕烫。
背后技术是铝制机身+vapor chamber(均热板)技术,把核心元件产生的热量主动导出,大面积扩散与散热,带来更持续稳定的性能与更舒适的温感。
该散热系统采用装有去离子水的液冷腔,可将热量导出整个系统
此外,新机身更好的保护背板,加上新的Ceramic Shield(超瓷晶)材质,造出来迄今最耐用的iPhone。
这次的iPhone 17 Pro采用最新的3纳米A19 Pro芯片,速度相比上一代的A18 Pro最高提升30%,性能更强。
再加上更大的内存,以及硬件加速光追技术,iPhone 17 Pro上玩游戏更带劲。
新机身,腾出了空间,电池更大,加上新的自适应电池管理,iPhone 17 Pro Max成为史上最耐用的手机:
视频播放最长可达39小时,更长的续航为旅行、通勤与外拍提供了真正的「全天候」底气。
iPhone 17 Pro和iPhone 17 Pro Max配有专业级相机。
后置三枚摄像头采用前凸设计:
全系均为Fusion(融合)相机,4800万像素,借助多帧融合在不同光照环境下稳态输出解析力与动态范围。
各后置摄像头具体参数如下:
全新Fusion长焦镜头,新增8×光学变焦。
全新的四棱镜远摄镜头,支持最长达200mm等效焦距,是iPhone有史以来最远的远摄焦段。
传感器面积增大56%,在弱光、运动场景中具备更高的进光与更好的信噪比表现。
结合深度学习和机器学习,苹果还升级了光像引擎,数码变焦最高可达40倍。
一部iPhone 17 Pro顶八颗镜头
前置摄像头则为1800万像素,并支持Center Stage(人物自动居中),而且视角更广、分辨率更高。

苹果首次支持前后置摄像头同时摄影,见证精彩的历史瞬间,同时录下自己的瞬间反应。
这次的发布会的全部视频由iPhone拍摄。其中17 Pro Max支持更多专业级摄像需求
· 支持ProRes RAW采集,后期空间更大、成片质感更专业。
· 新增Genlock(外部同步锁相)与视频同步功能,便于多机位协作拍摄与专业片场流程对接,画面/时间轴轻松对齐。
……
整体来看,iPhone 17 Pro的升级点集中在「结构散热、性能平台、影像系统与耐用续航」四大方向:
- 均热板+铝机身的热路设计改善了长时间高负载的稳定性;
- A19 Pro带来更强的CPU/GPU峰值与持续性能;
- 三摄4800万像素的全系一致性与更大底传感器,配合新长焦把远摄与夜拍拉齐到「主摄级」水准;
- 而超瓷晶前后双面与抗反射镀膜,则把「看得清、用得住」的体验落到了日常每一秒。
此外,还推出了新的手机保护壳等配件;iOS系统支持更多AI功能;iPhone 17 Pro Max提供最高2TB容量。
国内,iPhone17 Pro起售价为8999元;iPhone17 Pro Max起售价为9999元。
iPhone 17:有高刷,是真正的性价比之选
iPhone 17相较于上一代iPhone 16,各方面都进行了相当有诚意的大幅度升级。
iPhone 17本次带来了五种配色:黑色、白色、薰衣草紫色、鼠尾草绿色、青雾蓝色。
看起来和上一代的iPhone 16差不多?
如果你观察仔细,可以发现,新iPhone 17边框变窄了,因而屏幕从6.1英寸增大到了6.3英寸。
本代iPhone 17终于成为了真正的性价比之选,不再只是便宜的遮羞布。
其中最大的原因是,iPhone 17终于用上了OLED高刷屏。
1-120Hz的ProMotion自适应刷新率技术加持,补上了前代基础款最大的短板。
户外屏幕最大亮度也从上一代的2000尼特增加到3000尼特,强光下屏幕能看得更清楚了。
iPhone 17使用的芯片是A19,而不是其他三款的A19 Pro,纸面数据上差了1个GPU核心,真实性能差距有待真机测试。
iPhone 17也无缘iPhone 17 Pro和Pro Max的VC均热板,散热能力也会导致性能释放存在客观差距。
但不要过于担心,不是A19弱,而是A19 Pro太强,除非是玩大型游戏,否则日常使用中大概率不会感受到明显的性能差距。
此外,iPhone 17的续航也从上一代的22小时视频播放增加到30小时视频播放,大幅增加了36%。
充电速度也直接从上一代的20W来到了40W。
摄像头也有了很大升级。
后置摄像头方面,上一代的那颗1200万像素超广角镜头,这一代升级成了4800万像素融合式超广角镜头。
前置摄像头方面升级巨大,从1200万的前摄直接升级到了和iPhone 17 Pro Max同款的1800万像素的Center Stage前置摄像头。
随之带来的同步双拍功能更是王炸,让你可以同时使用前摄和后摄,可以在演唱会现场录制舞台Vlog的同时,与你的好朋友保持视频通话。

起步存储容量相比上一代也提升到256GB了。毕竟,128GB如今实在是捉襟见肘了。
iPhone 17国行256GB版本售价5999元,512GB版本售价7999元。
加量不加价!不知道你觉得这6000块值不值呢?
四款全新芯片,性能直接拉满
C1X:能效最强的调制解调器
Apple设计的新版蜂窝调制解调器C1X。
C1X的速度较C1提升至最多2倍,运行同样的蜂窝网络技术时比iPhone 16 Pro的调制解调器速度更快,同时整体能耗降低30%。
这使得C1X刷新了iPhone调制解调器的能效纪录。
N1:自研网络无线芯片
这枚Apple设计的全新网络无线芯片支持Wi-Fi 7、蓝牙 6和Thread技术。
除了驱动最新一代无线连接技术,N1芯片还改善了个人热点和隔空投送等功能的整体表现和可靠性。
A19:比上一代至少快了20%
基础款iPhone 17将搭载A19系统芯片,而其他型号搭载A19 Pro。
这些芯片可能采用了台积电最新的第三代纳米N3P工艺节点。
A19拥有六个CPU核和五个GPU核。
六个CPU核包含四个效率核心和两个性能核心,而GPU在硬件加速光线追踪、网格着色和MetalFX上采样方面继续取得进展。
左右滑动查看
GPU性能上,A19比上一代A18快20%,而iPhone型号越老,提速效果越明显。
A19 Pro:手机上跑大模型
A19 Pro是手机中最快的CPU。在CPU方面,苹果继续推动单线程性能。
这款强劲的A19 Pro配备了全新的6核CPU,能提升日常任务的性能和效率。
苹果还将能效核心的末级缓存提升了50%,专为提升日常处理各项任务时的能源效率。
图形处理器(GPU)在A19 Pro上也迎来了重大升级。
苹果推出了第二代动态缓存(Dynamic Caching)架构, 将16位浮点运算速率翻了一番,并构建了全新的统一图像压缩技术。
不仅如此,GPU的另一项重大更新与人工智能(AI)相关:将神经网络加速器(Neural Accelerators)内置于每个GPU核心之中, 带来了高达A18 Pro三倍的GPU峰值算力。
这让iPhone拥有了MacBook Pro级别的算力,能够完美胜任GPU密集型的AI工作负载。
AirPods Pro 3
私人教练+同声传译,终极音频体验
这次全新升级的AirPods Pro 3,可以说是一个集终极音频、私人健康管理和跨语言沟通于一体的超级个人智能设备。
首先,是作为一个耳机的根本——音质。
在全新「多端口声学架构」的加持下,AirPods Pro 3能精准控制进入耳内的气流,营造出众的空间音频聆听体验。
配合新一代自适应均衡功能,低音响应和声场都得到了增强——用户不仅能听清每一种乐器,而且人声也更为生动清晰。
其次,是堪称全球顶尖的主动降噪功能。
在降噪效果上,AirPods Pro 3最高达上一代产品的2倍,是初代产品的4倍。
这得益于超低噪声麦克风、先进的计算音频技术,以及内部注入泡棉的新款耳塞套带来的更强被动隔音效果。
续航方面,开启主动降噪模式后的AirPods Pro 3,听歌时长最长可达8小时,比上一代提升了整整33%。
左右滑动查看
第三,是首次内置了苹果最小的定制心率传感器!
通过定制的光电容积描记法(PPG)传感器,AirPods Pro 3能以每秒256次的频率发射不可见的红外光脉冲,来测量血流中的光吸收量。
结合AirPods中的加速感应器、陀螺仪、GPS传感器融合技术,以及iPhone上全新的设备端AI模型,你可以:
- 可以开启多达50种不同的体能训练
- 追踪心率和卡路里消耗
- 闭合「活动」圆环,并在「健身」app中赢取奖章
最后,是由苹果智能驱动的、革命性的实时翻译功能!
启用后,对方说的话就会被翻译成你的首选语言,并通过AirPods播放。
而你只需将iPhone横屏放置,就可以实时向对方显示你所说话语的翻译文本。

当两人都戴着AirPods时,主动降噪功能会降低对方说话的物理音量,让你在保持交流的同时,更容易专注于听取翻译内容。
目前,实时翻译功能支持英语、法语、德语、葡萄牙语和西班牙语,并将在今年年底前新增四种语言:意大利语、日语、韩语和中文(简体)。
Apple Watch Series 11
升级5G,新增高血压预警
Apple Watch Series 11带来了两项的开创性功能:高血压通知和睡眠分数。
首先,让我们聚焦本次更新的核心亮点,也是最具突破性的一项功能——高血压通知。
利用先进的光学心率传感器,Apple Watch Series 11会分析你的血管对心跳的细微反应,并通过一个基于超过10万名参与者的海量数据训练而成的机器学习算法,在后台持续地识别高血压的迹象。
一旦检测到持续的迹象,它会立即向你发送通知,提醒关注自己的血压状况。
Apple Watch Series 11带来的第二个重磅功能,就是全新的睡眠分数。
这个分数综合了影响睡眠质量的多个核心维度:睡眠时长、入睡规律、夜间清醒、睡眠阶段。
在你睡着之后,Apple Watch会利用强大的传感器采集心率、手腕温度、血氧和呼吸频率等数据,甚至发现可能的睡眠呼吸暂停。
到了早上,「睡眠」app会在Apple Watch上提供一个总分和评级,并清晰地分解出各项关键因素,让你知道应该优先改善哪个方面来提升睡眠。
强大的功能,离不开坚实的硬件支撑。
在这一方面,Apple Watch Series 11也得到了全面地升级。
- 电池续航延长至最长24小时;同时支持快充,15分钟即可充入长达8小时的电量
- 铝合金款的表面抗刮性直接提升至2倍!这得益于苹果在本就坚固的Ion-X玻璃之上,增加了一层自研的陶瓷涂层,通过物理气相沉积工艺实现了在原子层面与玻璃的紧密结合
- 采用了更快的5G网络,以及重新设计的多频段蜂窝天线——在必要时会同时启用两个系统天线,显著提升信号强度
参考资料:HJNK 25%
https://www.apple.com/apple-events/event-stream/
....
#LLM-based Agentic Reasoning Frameworks
Agent时代来临:一文读懂大模型Agentic Reasoning框架
近年来,大型语言模型(LLM)的推理能力取得了显著进展,催生了众多展现出接近人类水平性能的LLM-based Agent系统。然而,这些系统虽然都以LLM为核心,但其推理框架在引导和组织推理过程上却各有千秋。
本文介绍一篇全面的综述论文,它对基于LLM的 Agentic Reasoning Frameworks (智能推理框架)进行了系统性的梳理和分析。研究者们提出了一个统一的分类法,将现有方法分解为 单智能体 、 基于工具 和 多智能体 三大类,并深入探讨了这些框架在科学发现、医疗、软件工程、社会模拟等多个领域的应用。该综述旨在为研究社区提供一个全景式的视图,帮助理解不同框架的优势、适用场景和评估方法。
- 论文标题: LLM-based Agentic Reasoning Frameworks: A Survey from Methods to Scenarios
- 作者: BINGXI ZHAO ,LIN GENG FOO, PING HU , CHRISTIAN THEOBALT,HOSSEIN RAHMANI ,JUN LIU
- 机构: 北京交通大学、兰卡斯特大学、马克斯·普朗克计算机科学研究所、电子科技大学
- 论文地址: https://arxiv.org/abs/2508.17692
研究背景与意义
随着LLM的爆发式增长,学术界和工业界都在积极探索如何利用LLM构建能够执行复杂、多步推理任务的智能体(Agent)。如下图所示,自2023年以来,关于LLM Agent框架的出版物数量呈快速增长趋势,显示了该领域日益增长的重要性。

然而,这种快速发展也带来了挑战:不同研究在框架设计、模型改进和技术实现上的界限变得模糊,使得横向比较不同项目的优劣变得困难。因此,一篇能够系统性地总结现有Agentic Reasoning框架的进展和应用场景的综述文章显得尤为及时和必要。它不仅能帮助研究者厘清概念,还能为Agentic框架的标准化和安全发展提供清晰的路线图。
Agentic Reasoning框架分类
这篇综述的核心贡献之一是提出了一个清晰的Agentic Reasoning框架分类法。作者将复杂的Agent系统解构为三个循序渐进的类别:单智能体方法、基于工具的方法和多智能体方法。

这三个层次共同构成了一个完整的Agentic Reasoning体系:
- 单智能体方法 (Single-agent Methods) :专注于增强单个智能体的内在推理能力。
- 基于工具的方法 (Tool-based Methods) :通过调用外部工具来扩展智能体的能力边界。
- 多智能体方法 (Multi-agent Methods) :通过多个智能体之间的不同组织和互动范式,实现更灵活、更强大的集体推理能力。
单智能体方法
单智能体方法旨在从“外部引导”和“内部优化”两个角度提升单个Agent的认知和决策能力。
提示工程 (Prompt Engineering)
提示工程通过精心设计的提示来引导Agent的推理过程,主要包含四种技术:

- 角色扮演 (Role-playing) :为Agent分配特定角色(如“你是一位专业的AI研究员”),以激发其特定领域的表现。
- 环境模拟 (Environmental-simulation) :将Agent置于一个精心设计的虚拟环境中,使其能够利用多模态信息或外部能力进行推理。
- 任务描述 (Task-description) :清晰地重构和表达任务,明确目标、约束和输出格式。
- 上下文学习 (In-context Learning) :在推理前或推理中为Agent提供若干示例(few-shot examples),引导其学习。
自我提升 (Self-improvement)
自我提升机制使Agent能够通过反思和自主学习来动态调整其策略。主要有三种范式:

- 反思 (Reflection) :Agent分析已完成的轨迹,生成文本摘要并存入其上下文,为下一步推理提供参考。
- 迭代优化 (Iterative Optimization) :在单个任务中,Agent生成初始输出,与既定标准或反馈进行比较,并不断迭代优化,直到满足终止条件。
- 交互式学习 (Interactive Learning) :Agent与动态环境互动,经验(如发现新物品)可以触发其高层目标的更新,从而实现持续、开放式的学习。
基于工具的方法
当面对需要与外部环境进行复杂交互的场景时,简单的单实体工具抽象已不足够。论文将基于工具的推理流程分解为三个基本阶段:工具集成、工具选择和工具利用。

- 工具集成 (Tool Integration) :研究如何将工具整合到Agent的推理过程中,主要有API、插件和中间件三种模式。
- 工具选择 (Tool Selection) :解决从工具箱中为当前任务选择最合适工具的问题,分为自主选择、基于规则选择和基于学习选择。
- 工具利用 (Tool Utilization) :关注如何有效操作选定的工具以生成期望的输出,包括顺序使用、并行使用和迭代使用。
多智能体方法
对于需要多样化专业知识或复杂问题分解的任务,多智能体系统(Multi-agent Systems, MAS)应运而生。其核心原则是“分而治之”,但挑战在于实现有效的协调。论文从组织架构和个体交互两个维度对此进行分析。

- 组织架构 (Organizational Architectures) :
- 中心化 (Centralized) :由一个中心Agent负责全局规划、任务分解和结果合成,协调性强但存在性能瓶颈。
- 去中心化 (Decentralized) :所有Agent地位平等,通过点对点通信进行决策,鲁棒性好但效率可能较低。
- 层级化 (Hierarchical) :将Agent组织成树状或金字塔结构,上层负责战略规划,下层负责具体执行,适用于可清晰分解的任务。
- 个体交互 (Individual Interactions) :
- 合作 (Cooperation) :所有Agent以最大化集体利益为共同目标。
- 竞争 (Competition) :Agent追求个体利益最大化,可能存在冲突。
- 协商 (Negotiation) :在合作与竞争之间取得平衡,有利益冲突的Agent通过沟通和妥协达成共识。
Agentic Reasoning的应用场景
该综述详细探讨了Agentic Reasoning框架在多个前沿领域的应用,展示了其巨大的潜力。

科学发现
在生物化学领域,Agent系统被用于药物发现、基因实验设计、化学合成等。例如,BioDiscovery-Agent框架通过迭代设计基因扰动实验,并整合先验知识来指导其推理上下文,从而高效识别基因功能。

医疗健康
在医疗领域,Agent系统可用于辅助诊断、临床管理和环境模拟。例如,AIME框架通过两个“自博弈”循环进行持续优化:内部循环中,医生Agent根据评论家模块的实时反馈优化其在模拟对话中的行为;外部循环中,优化的模拟对话数据被用于微调推理系统。

软件工程
在软件工程中,Agent系统能够处理代码生成、程序修复和全周期软件开发。下表展示了多种Agentic编码框架在主流代码生成基准测试上的性能(Pass@1),可以看出基于Agent的框架(如AgentCoder, MetaGPT)在GPT-4等强大基础模型上,性能显著优于传统的提示方法。

社会与经济模拟
Agentic框架为模拟复杂的社会和经济动态提供了强大的工具。在社会模拟中,每个个体都由一个LLM-based Agent驱动,拥有独特的个人资料、目标和动态更新的上下文。通过与他人和环境的互动,Agent可以独立决策,从而在群体层面涌现出复杂且真实的社会现象。

下表汇总了不同的社会模拟方法及其规模。

总结与展望
这篇综述论文 首次提出了一个统一的方法论分类法,系统性地阐明了Agentic框架内的核心推理机制和方法。通过将Agent系统分解为单智能体、基于工具和多智能体三个层次,为分析和理解该领域提供了清晰的视角。
论文的价值在于:
- 系统的知识梳理:为快速发展的LLM Agent领域提供了第一个系统的、框架层面的分类和综述。
- 统一的形式化语言:引入了一套形式化语言来描述推理过程,清晰地展示了不同方法对关键步骤的影响。
- 广泛的应用场景分析:深入研究了Agent框架在多个关键领域的应用,并对代表性工作进行了深入分析。
- 指明未来方向:论文最后展望了未来的六个研究方向,包括推理的可扩展性与效率、开放式自主学习、动态推理框架、推理中的伦理与公平、安全性以及可解释性等,为后续研究提供了宝贵的指导。
CV君认为,这篇综述是所有希望了解、研究或应用LLM Agent的研究人员和工程师的必读文献。它不仅全面总结了现有工作,更重要的是提供了一个结构化的思维框架,帮助研究人员更好地驾驭这个充满机遇和挑战的新兴领域。
....
.
#克服 LLM 推理中的不确定性
刚刚,Thinking Machines Lab首次发长文,揭开LLM推理不确定性真相
真正的元凶是缺乏批次不变性。
就在今天,由 OpenAI 前 CTO Mira Murati 成立于今年 2 月的人工智能初创公司 Thinking Machines Lab,发了第一篇文章 ——《克服 LLM 推理中的不确定性》(Defeating Nondeterminism in LLM Inference)。

这篇博客属于 Thinking Machines Lab 新提出的博客栏目 Connectionism,意为「连接主义」。该公司表示:「我们相信,分享才能让科学更好地发展。Connectionism 将涵盖与我们的研究一样广泛的主题:从核函数数值计算到提示工程。Connectionism 这一名称可以追溯到 AI 的早期年代。它曾是 20 世纪 80 年代的一个研究分支,专注于神经网络及其与生物大脑的相似性。」
此外,Thinking Machines Lab 联合创始人、著名技术博主翁荔(Lilian Weng)还在转推中透露了一个消息,Connection Machine,即「连接机」,难道他们的产品要来了?

真是让人期待呢。

地址:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
博客主要作者为 Horace He,这位 PyTorch 核心开发者于今年 3 月从 Meta 离职,加入了 Thinking Machines。

接下来看博客原文内容。
可复现性(reproducibility)是科学进步的基石。然而,从大语言模型中获得可复现的结果却非常困难。
例如,你可能会发现:即使是向 ChatGPT 提出同一个问题多次,也可能得到不同的回答。这本身并不令人意外,因为语言模型生成结果的过程涉及采样 —— 这个过程会将模型的输出转换为一个概率分布,并以概率方式选择一个 token。
更令人惊讶的是,即使我们将温度参数调到 0(理论上使采样过程变为确定性),大语言模型的 API 在实际中仍然不是确定性的。研究者已经对此有诸多讨论。
即使是在你自己的硬件上,使用开源推理库(如 vLLM 或 SGLang)运行推理,采样过程依然不是确定性的。
为什么大语言模型的推理引擎不是确定性的呢?
一个常见的假设是:浮点运算的非结合性(non-associativity)与并发执行的某种组合会导致不确定性,这取决于哪个并发核心首先完成。我们将这种解释称为「LLM 推理不确定性的『并发 + 浮点』假设」。例如,一篇最近的 arXiv 论文(arXiv:2506.09501)写道:
GPU 中的浮点运算具有非结合性(non-associativity),意味着 (a+b)+c≠a+(b+c),这是由于精度有限和舍入误差所致。这一特性会直接影响 transformer 架构中注意力得分和 logit 的计算,因为在多线程中进行的并行操作,其执行顺序不同会导致结果差异。
虽然这个假设并不完全错误,但它并没有揭示事情的全貌。
例如,即使在 GPU 上,对相同的数据反复进行相同的矩阵乘法运算,每次的结果也都是每一位都相同的。我们确实在使用浮点数,GPU 也确实具有高度并发性。
那为什么在这个测试中却看不到不确定性呢?

要理解大语言模型推理不确定性的真正原因,我们必须更深入地探究。
不幸的是,甚至连「LLM 推理是确定性」的这一说法的定义都很难明确。或许令人困惑的是,以下这些看似矛盾的说法实际上同时都是真实的:
- GPU 上的一些核(kernel)是不确定性的。
- 然而,语言模型在前向传播过程中使用的所有核都是确定性的。
- 此外,像 vLLM 这样的 LLM 推理服务器的前向传播过程,也可以被认为是确定性的。
- 尽管如此,从使用推理服务器的任何用户的角度来看,结果却是不确定性的。
在这篇文章中,我们将解释为什么「并发 + 浮点」假设没有达到目的,揭露 LLM 推理不确定性背后的真正罪魁祸首,并解释如何克服不确定性并在 LLM 推理中获得真正可重复的结果。
原罪:浮点数的非结合性
在讨论不确定性之前,有必要先解释一下为什么存在数值差异。毕竟,我们通常将机器学习模型视为遵循交换律或结合律等结构性规则的数学函数。我们的机器学习库难道不应该提供数学上正确的结果吗?
罪魁祸首是浮点非结合性(floating-point non-associativity)。也就是说,对于浮点数 a、b、c,有:

讽刺的是,正是打破结合律让浮点数变得有用。
浮点数之所以有用,是因为它们允许动态的精度。为了便于解释,我们将使用十进制(而不是二进制),其中浮点数的格式为:尾数 * 10^ 指数。这里还将使用 3 位数字作为尾数,1 位数字作为指数。(注:在计算机科学中,尾数(mantissa,或有效数)是浮点数中用来表示精度的部分,它决定了数字的有效数字位数和精度。)
例如,对于值 3450,我们可以将其精确表示为 3.45*10^3。我们也可以将更小的值(例如 0.486)表示为 4.86*10^-1。这样,浮点数既可以表示非常小的值,也可以表示非常大的值。在科学领域,我们可以说浮点数使我们能够保持有效数的个数恒定。
如果两个浮点数的指数相同,它们的加法运算看起来与整数加法类似。例如:

但是,如果两个浮点数的指数不同,例如 1230 和 23.4,又会发生什么情况呢?理论上,它们的和应该是 1253.4。然而,由于浮点数运算只能保留 3 位有效数字,因此结果会被舍入为 1.25×10³(或 1250)。

表示 1230 需要 3 位有效数字,表示 23.4 也需要 3 位有效数字。但是,这两个数相加的结果(1253.4)却需要 5 位有效数字才能精确表示。因此,我们的浮点数格式必须舍弃最后两位(34)。某种程度上,这相当于我们在相加之前,将原来的 23.4 四舍五入为 20.0。
然而,这样做会导致信息丢失。请注意,只要我们对两个不同阶位(即不同指数)的浮点数进行加法运算,就会发生这种情况。而实际应用中,我们经常需要对不同指数的浮点数进行加法运算。事实上,如果我们能够保证所有浮点数的指数都相同,那么我们完全可以只使用整数!
换句话说,每次以不同顺序相加浮点数时,结果都有可能完全不同。举个极端的例子,对于某个数组,根据加法顺序的不同,其求和结果可能出现 102 种不同的结果。

虽然这是导致输出结果不一致的根本原因,但它并不能直接解释不确定性行为的来源。它也无法帮助我们理解为什么浮点数的加法顺序会改变、这种情况在什么时候发生、以及我们如何避免它。
答案藏在核函数(kernel)的实现方式中。
为什么核函数计算中数字加法顺序并非总是固定的?
如前所述,解释核函数计算中数字加法顺序不一致的一个常见原因是「并发性 + 浮点运算」假设。
该假设认为,如果并发线程的执行顺序是不可预测的,并且累加操作的顺序依赖于并发线程的执行顺序(例如原子加法 /atomic adds),那么最终的累加结果也会变得不可预测。
然而,令人困惑的是,尽管这种现象会导致核函数计算结果的不确定性,但并发机制(以及原子加法)实际上与大型语言模型推理中的不确定性无关!
为了解释真正的罪魁祸首是什么,我们首先需要了解为什么现代 GPU 核函数很少需要使用原子加法。
什么时候需要使用原子加法操作?
GPU 通常会同时在多个核心(即流处理器)上并行运行程序。由于这些核心之间没有内置同步机制,因此如果它们需要相互通信,就会很麻烦。例如,如果所有核心都需要对同一个元素进行累加,就可以使用原子加法(有时也称为 fetch-and-add)。原子加法是不确定性的,结果的累加顺序完全取决于哪个核心先完成计算。
具体来说,假设你要使用 100 个核心对一个包含 100 个元素的向量进行求和(例如 torch.sum ())。虽然可以并行加载所有 100 个元素,但最终我们必须将结果汇总为一个值。一种实现方法是使用某种原子加法操作,硬件保证所有加法操作都会执行,但并不保证执行顺序。

原子加法操作可以确保每个核心的计算结果都能最终反映在总和中。但是,它并不能保证这些结果的累加顺序。累加顺序完全取决于哪个核心先完成计算,这是一种不确定性行为。
因此,多次执行相同的并行程序可能会产生不同的结果。这通常就是人们所说的不确定性,即,使用完全相同的输入数据执行两次相同的程序,但最终结果却可能不同。这被称为运行间不确定性(run-to-run nondeterminism),例如,运行两次完全相同的 Python 脚本,即使依赖库版本完全相同,结果也可能不同。
虽然并发的原子加法操作会使核函数的执行结果变得不可预测,但对于大多数核函数来说,原子加法并非必需。
事实上,在 LLM 的典型前向传播过程中,通常根本不需要使用原子加法。这可能令人感到意外,因为并行化计算中的归约操作通常可以从原子加法中获益。但实际上,原子加法在大多数情况下并非必需,主要原因有两点。
1. 通常情况下,批处理维度上的并行性已经足够,因此我们无需在归约维度上进行并行化。
2. 随着时间的推移,大多数神经网络库都采用了各种策略,以在不牺牲性能的情况下实现结果的可预测性。
由于上述两个因素,对于绝大多数神经网络操作来说,不使用原子加法几乎不会带来性能损失。
当然,仍然有少数常见操作在不使用原子加法时会遭遇显著的性能下降。例如,PyTorch 中的 scatter_add(即 a [b] += c)。不过,在大语言模型中唯一常用且依赖原子加法的操作,是 FlashAttention 的反向传播(backward)。
然而,LLM 的前向传播过程中并不涉及任何需要原子加法的操作。因此,LLM 的前向过程本质上是运行间确定的(即每次运行结果一致)。

维基百科上写道:一个确定性算法是在给定特定输入的情况下,始终产生相同输出的算法。而在这里,只要输入完全相同(即推理服务器处理的请求完全一致),前向传播就总是会生成完全相同的输出。
然而,前向传播本身是确定性的并不意味着整个系统也是确定性的。比如,如果某个请求的输出依赖于并行用户的请求(例如 batch-norm 这样的操作),那么由于每个请求都无法预知其他并发请求的内容,从单个请求的视角来看,整个 LLM 推理过程就会是不确定性的。
事实证明,我们的请求输出确实依赖于其他并发用户的请求。但这并不是因为跨 batch 泄露了信息,而是因为我们的前向传播过程缺乏批次不变性(batch invariance),这导致同一个请求的输出会受到前向传播中 batch size(batch size)变化的影响。
批次不变性与确定性
为了说明什么是批次不变性,我们可以简化问题,只关注矩阵乘法(matmul)。你可以假设所有的 matmul 实现都是运行间确定的,也就是说,同样的输入,每次运行都会得到相同的结果。
但它们并不是批次不变的。换句话说,当 batch size 发生变化时,batch 中的每个元素可能会得到不同的计算结果。
从数学角度来看,这是一种相当反常的性质。理论上,矩阵乘法在 batch 维度上应当是独立的,batch 中其他元素的存在与否,或 batch 的大小,都不应影响某个具体元素的计算结果。
然而,我们通过实验证据可以发现,现实情况并非如此。

请注意,这里的确定性是指每次运行结果都相同。如果你多次运行该脚本,它会始终返回相同的结果。
但是,如果将非批处理不变的核函数用作更大推理系统的一部分,则整个系统可能变得不确定性。当你向推理端点发送请求时,从用户角度来看,服务器的负载情况是不可预测的。负载决定了核函数的 batch size,从而影响每个请求的最终结果。

如果你把某种核函数不具备不变性的属性(例如:batch size)与该属性本身的不确定性(例如:服务器负载情况)组合在一起,就会得到一个不确定性的系统。
换句话说,几乎所有大语言模型推理端点之所以是不确定的,主要原因就是负载(以及由此决定的 batch size)本身具有不确定性!这种不确定性并非仅限于 GPU,使用 CPU 或 TPU 运行的 LLM 推理端点也会存在同样的问题。因此,如果我们想避免推理服务器中的不确定性,就必须确保核函数对 batch size 具有不变性。
为了理解如何实现这一点,我们首先需要了解为什么核函数默认情况下并不具备批处理不变性。
我们如何使核具有批次不变性?
为了确保 Transformer 模型的实现与 batch size 无关,我们必须确保模型中的每个核心模块都与 batch size 无关。幸运的是,我们可以假设每个逐点运算(pointwise operation)都与 batch size 无关。因此,我们只需要担心涉及的 3 个操作:RMSNorm、矩阵乘法和注意力。
巧合的是,这些操作的难度正好是依次递增的。要想在保持合理性能的同时实现批次不变性,每一种操作都需要一些额外的考量。我们先从 RMSNorm 开始谈起。
RMSNorm

RMSNorm 实现方式:

批次不变性的要求是,无论核函数的 batch size 如何,每个元素的归约顺序都必须保持不变。需要注意的是,这并不意味着我们必须始终使用相同的归约策略。例如,即使我们改变了要进行归约的元素数量,只要归约顺序不变,我们的算法仍然可以满足批处理不变性的要求。
因此,只有当 batch size 影响到归约策略时,我们才会打破批次不变性。
让我们来看一下 RMSNorm 的标准并行化策略。一般来说,并行算法都会从尽量减少核心之间的通信中获益。在这里,为了方便讨论,你可以假设我们所说的核心(cores)就是指 SM(Streaming Multiprocessors,流处理多处理器)。更具体地说,这里重要的性质是:核函数启动的线程块(threadblocks)数量多于 SM 的数量。
基于这一点,一种可行的策略就是:将每个 batch 元素分配给一个核心,就像上图展示的那样。
当我们增加 batch size 时,并不会影响归约策略;如果 batch size = 200 已经能为核函数提供足够的并行性,那么 batch size = 2000 显然也同样能够提供足够的并行性。

另一方面,减小 batch size 也会带来一些挑战。由于我们为每个批次元素分配一个核心,减小 batch size 会导致核心数量大于批次元素数量,从而造成部分核心闲置。遇到这种情况,优秀的核函数工程师会采用前面提到的解决方案之一(原子加法或分段求和),从而保持良好的并行性,进而提升性能。然而,这会改变求和策略,导致该核函数不再具备 batch size 不变的特性。

最简单的解决方案就是直接忽略这些情况。这并不是完全不合理的,因为当 batch size 很小时,核函数通常本来就能很快执行,因此即使出现一些减速,也不会造成灾难性的影响。
如果我们必须优化这种场景,一种方法是:始终使用一种在极小 batch size 下也能提供足够并行度的归约策略。这样的策略会在 batch size 较大时导致过度并行,从而无法达到峰值性能,但它可以让我们在整个 batch size 范围内都获得尚可(虽然不是最佳)的性能表现。
批次不变矩阵乘法

从本质上讲,你可以把矩阵乘法看作是一次逐点运算后接一次归约。那么,如果我们通过将输出划分为小块来并行化矩阵乘法,就能得到一种类似的数据并行核函数策略,使得每一次归约都在单个核心内完成。
与 RMSNorm 类似,矩阵乘法的批次维度(M 和 N)也可能变得过小,迫使我们必须沿归约维度(K)进行拆分。尽管有两个批次维度,矩阵乘法仍然需要每个核心有更多的工作量才能有效利用张量核心。例如,对于一个 [1024, K] x [K, 1024] 的矩阵乘法和一个标准的 [128, 128] 二维 tile 大小,数据并行策略最多只能将其分配到 64 个核心上,这不足以使 GPU 达到饱和。
在矩阵乘法中沿归约维度进行拆分被称为 Split-K 矩阵乘法。与 RMSNorm 的情况一样,使用这种策略会破坏批次不变性。

矩阵乘法还有一个额外的复杂性,即张量核心指令。对于归约操作,我们可以一次只处理一行;但高效的矩阵乘法核函数必须一次性操作一整个 tile。
每条张量核心指令(例如 wgmma.mma_async.sync.aligned.m64n128k16)在内部可能有不同的归约顺序。选择不同张量核心指令的一个原因可能是 batch size 非常小。例如,如果我们使用的张量核心 PTX 指令操作的是一个长度为 256 的 tile,但 batch size 只有 32,那我们几乎浪费了所有的计算资源!当 batch size 为 1 时,最快的核函数通常根本不使用张量核心。

因此,确保矩阵乘法批次不变性的最简单方法是:编译一个固定的核函数配置,并将其用于所有形状的计算。尽管这会损失一些性能,但在 LLM 推理场景下,这种损失通常不是灾难性的。特别是,Split-K 策略在 M 和 N 维度都很小时才最被需要,而幸运的是,在我们的应用场景中,N 维度(即模型维度)通常都相当大!

批次不变性注意力机制

在实现了矩阵乘法的批次不变性之后,注意力机制又引入了两个额外的难题 —— 这也很贴切,因为它正好包含两次矩阵乘法。
1. 与 RMSNorm 和矩阵乘法仅在特征维度上进行归约不同,注意力机制现在需要在特征维度和序列维度上都进行归约。
2. 因此,注意力机制必须处理各种影响序列处理方式的推理优化(例如分块预填充、前缀缓存等)。
因此,为了在 LLM 推理中实现确定性,我们的数值计算必须对两个因素保持不变:一是单次处理的请求数量,二是每个请求在推理引擎中的切分方式。
我们首先来了解一下注意力机制的标准并行策略,该策略最初由 FlashAttention-2 提出。与 RMSNorm 和矩阵乘法类似,其默认策略是数据并行策略。由于归约是沿着键 / 值(K/V)张量进行的,因此数据并行策略只能沿着查询(Q)张量进行并行化。
例如,根据推理引擎的选择,一个序列可能被分成几个部分处理(如在分块预填充中),也可能一次性处理完毕(如果预填充未被分割)。为了实现批次不变性,对于一个给定的 token,其归约顺序必须独立于其所在序列中同时被处理的其他 token 的数量。
如果你将 KV 缓存中的 K/V 值与当前正在处理的 token 的 K/V 值分开进行归约(就像在 vLLM 的 Triton 注意力核函数中那样),这个目标就无法实现。例如,在处理序列中的第 1000 个查询 token 时,无论 KV 缓存中有 0 个 token(预填充阶段)还是 999 个 token(解码阶段),其归约顺序都必须完全相同。

为解决此问题,我们可以在注意力核函数运行前就更新 KV 缓存和页表,从而确保无论处理多少个 token,我们的键和值始终具有一致的内存布局。
加上这一额外处理(以及前文提到的所有措施,如使用一致的 tile 大小),我们便能实现一个批次不变性的注意力机制!
然而,这里存在一个重要问题。与矩阵乘法不同,LLM 推理中的注意力计算形状通常确实需要一个拆分 - 归约核函数(split-reduction kernel),这类核函数常被称为 Split-KV 或 FlashDecoding。这是因为如果我们不沿着归约维度进行并行,就只能沿着批次维度、头维度和查询长度维度进行并行。
在注意力的解码阶段,查询长度非常小(通常为 1),因此除非 batch size 非常大,否则我们往往无法使 GPU 达到饱和状态。不幸的是,这种情况不像在 RMSNorm 和矩阵乘法中那样容易被忽略。例如,如果你的 KV 缓存非常长,即使只处理一个请求,注意力核函数的计算也可能耗时很长。

此外,常用于注意力的拆分 - 归约策略也给批次不变性带来了挑战。例如,FlashInfer 的平衡调度算法会选择能够使 GPU 所有核心饱和的最大拆分大小,这使得其归约策略并非批次不变的。然而,与 RMSNorm / 矩阵乘法不同,无论 batch size 如何,仅仅选择一个固定的拆分数量是不够的。
相反,为了实现批次不变性,我们必须采用固定拆分大小策略。换言之,我们固定的不是拆分的数量,而是每个拆分块的大小,这样最终会得到一个可变的拆分数量。通过这种方式,我们可以保证无论正在处理多少个 token,我们总是执行完全相同的归约顺序。

实现
我们基于 vLLM,通过利用其 FlexAttention 后端和 torch.Library,提供了一个确定性推理的演示。通过 torch.Library,我们能够以一种非侵入式的方式替换掉大部分相关的 PyTorch 算子。
你可以在 thinking-machines-lab/batch-invariant-ops 找到「批次不变性」核函数库,以及在「确定性」模式下运行的 vLLM 示例。
地址:https://github.com/thinking-machines-lab/batch_invariant_ops
实验
完成结果的不确定性程度如何?
我们使用 Qwen3-235B-A22B-Instruct-2507 模型,在温度为 0 的设置下,使用提示词「Tell me about Richard Feynman」(非思考模式)采样了 1000 次完成结果,每次生成 1000 个 token。
令人惊讶的是,我们得到了 80 个不同的完成结果,其中最常见的一个出现了 78 次。
通过观察这些结果的差异,我们发现它们在前 102 个 token 上实际上是完全相同的!
首次出现差异是在第 103 个 token。所有的结果都生成了「Feynman was born on May 11, 1918, in」这个序列。然而,接下来,其中 992 次结果生成了「Queens, New York」,而另外 8 次则生成了「New York City」。
然而,当我们启用批次不变性核函数后,全部 1000 次结果都变得完全相同。这正是我们期望采样器应有的表现,但若不使用我们的批次不变性核函数,就无法实现确定性结果。
性能
目前,我们还没有投入精力优化批次不变性核函数的性能。不过,我们还是进行了一些实验来验证其性能是否仍在可用范围内。
我们搭建了一个配备单块 GPU 的 API 服务器,运行 Qwen-3-8B 模型,并请求生成 1000 个序列,输出长度控制在 90 到 110 个 token 之间。

性能下降的主要原因在于 vLLM 中的 FlexAttention 集成尚未经过深度优化。尽管如此,我们看到其性能并未出现灾难性下降。
真正的在策略强化学习
正如研究人员所指出的,训练和推理之间的数值差异会隐式地将我们的在策略强化学习(on-policy RL)转变为离策略强化学习(off-policy RL)。
当然,如果我们甚至无法从两次相同的推理请求中获得每一位都相同的结果,那么在训练和推理之间获得每一位都相同的结果也是不可能的。因此,确定性推理使我们能够修改训练堆栈,从而在采样和训练之间获得每一位都相同的结果,最终实现真正的在策略强化学习。
我们在 Bigmath 上,使用 RLVR 设置进行了实验,其中强化学习策略由 Qwen 2.5-VL instruct 8B 模型初始化,最大 rollout 长度为 4096。
如果我们不使用离策略校正(即重要度加权)进行训练,我们的奖励会在训练中途崩溃;而添加离策略校正项则可以使训练顺利进行。但是,如果我们在采样器和训练器之间实现了每一位都相同的结果,我们就完全处于在策略状态(即 KL 散度为 0),同样可以顺利地进行训练。
我们还可以绘制采样器和训练器之间对数概率的 KL 散度,其中所有 3 次运行都表现出显著不同的行为。在使用重要度加权运行时,KL 散度保持在 0.001 左右,并伴有偶尔的峰值。然而,在不使用重要度加权的情况下运行,最终会导致 KL 散度在大约与奖励崩溃同一时间出现峰值。当然,在运行「真正的在策略强化学习」时,我们的 KL 散度始终保持为 0,这表明训练策略和采样策略之间不存在任何差异。

总结
现代软件系统往往由多层抽象构成。在机器学习中,当我们遇到不确定性和一些微妙的数值差异时,人们往往会倾向于视而不见。
毕竟,我们的系统本来就是「概率性的」,再多一点不确定性又有何妨?单元测试挂掉时,把 atol/rtol 调大点有什么问题?训练器和采样器之间的对数概率差异,应该不是真正的 bug 吧?
我们拒绝这种消极心态。只要稍微多做一些努力,我们就能理解不确定性的根源,甚至真正解决它们!
我们希望这篇博文能为社区提供一套可靠的思路,帮助大家在推理系统中应对不确定性,并激励更多人深入理解自己的系统。
....
#Autonomous Code Evolution Meets NP-Completeness
英伟达的AI已经开始接管整个项目了?SATLUTION自主进化代码库登顶SAT竞赛
AI 开发复杂软件的时代即将到来?
近年来,以 Google 的 AlphaEvolve 为代表的研究已经证明,AI 智能体可以通过迭代来优化算法,甚至在某些小型、独立的编程任务上超越人类。然而,这些工作大多局限于几百行代码的「算法内核」或单个文件。

但现实世界的软件,比如一个顶级的 SAT 求解器,是一个庞大而复杂的系统工程,包含数百个文件、精密的编译系统和无数相互关联的模块。手动打造一个冠军级求解器不仅需要极高的领域知识,而且投入产出比越来越低。
为此,NVIDIA Research 的研究人员提出了 SATLUTION,首个将 LLM 代码进化能力从「算法内核」扩展到「完整代码库」规模的框架。SATLUTION 能够处理包含数百个文件、数万行 C/C++ 代码的复杂项目,并在被誉为「计算理论基石」的布尔可满足性(SAT)问题上,取得了超越人类世界冠军的性能。
- 论文标题:Autonomous Code Evolution Meets NP-Completeness
- 论文地址:https://arxiv.org/pdf/2509.07367
SATLUTION 框架通过协调 LLM 智能体,在严格的正确性验证和分布式运行时反馈的指导下,直接对 SAT 求解器的代码库进行迭代优化。值得一提的是,在这一过程中,它还会同步地「自我进化」其进化策略与规则。
基于 2024 年 SAT 竞赛的代码库与基准,SATLUTION 进化出的求解器不仅在 2025 年的 SAT 竞赛中击败了人类设计的冠军,而且在 2024 年的基准测试集上,其性能也同时超越了 2024 年和 2025 年两届的冠军。

SATLUTION 在 2025 年 SAT 竞赛基准测试中的惊人表现。图中柱状图的高度代表 PAR-2 分数(一种衡量求解器性能的指标,越低越好)。左侧颜色渐变的柱体是 SATLUTION 进化出的求解器家族,它们的分数显著低于人类设计的 2025 年竞赛冠军(蓝色)和亚军(绿色)。
SATLUTION 是如何工作的?
SATLUTION 围绕 LLM 智能体、一套动态规则系统以及一个严格的验证与反馈循环构建。
双智能体架构
该系统由两个协同工作的 LLM 智能体驱动,基于 Cursor 环境和 Claude 系列模型实现。
规划智能体:负责高层次的战略制定。在进化周期的初始阶段,它会分析作为起点的求解器代码库及其性能,提出有潜力的修改方向。在后续周期中,它会综合考量累积的代码变更、性能指标和历史失败记录,为下一次迭代制定新的进化计划。
编码智能体:负责执行具体的开发任务。它根据规划智能体的蓝图,直接对 C/C++ 求解器代码库进行编辑和实现。其职责还包括管理辅助任务,例如更新 Makefile 等构建系统配置、修复编译错误以及调试功能性或执行时错误。
规则系统:引导与约束
规则系统是确保进化过程高效和稳定的关键。它为智能体的探索提供了必要的引导,有效减少了在无效或错误方向上的尝试。
在进化开始前,研究人员为系统设定了一套静态规则,编码了基础的领域知识和硬性约束。这包括:基本的 SAT 启发式算法原则、严格的正确性要求(如必须为无解实例生成 DRAT 证明)、统一的代码库目录结构规范以及详细的评估协议。
实验表明,在缺少这套初始规则的情况下,智能体的表现会显著下降,容易产生偏离目标的修改。
该框架的一个核心特点是规则库本身能够动态演进。在每个进化周期结束后,一个分析器会对过程中的编译错误、验证失败和新出现的失效模式进行复盘,并自动提出规则补丁。
例如,系统可以根据一次失败的经验,自动向规则库中添加一个新的「禁止代码模式」,从而防止智能体在未来重复同样的错误。这使得规则系统与求解器代码共同进化,不断提升框架的整体效率和鲁棒性。
验证与评估流程
为保障代码质量和求解的正确性,每个新生成的求解器版本都必须通过一个严格的流程。
- 两阶段验证
第一阶段是编译和基本功能测试。 系统会尝试编译新代码,成功后在一个包含 115 个简单 CNF 实例的测试集上运行,以捕捉编译错误、段错误等基础问题。
第二阶段是完整的正确性验证。 通过第一阶段的求解器会在一个更大的、结果已知的基准测试集上运行。对于其输出的每一个结果,系统都会进行核查:如果报告「可满足」(SAT),则验证所给出的赋值是否正确;如果报告「不可满足」(UNSAT),则使用外部检查工具验证其生成的 DRAT 证明的有效性。
只有完全通过这两个阶段验证的求解器,才会被认为是「正确」的,并进入下一步的性能评估。
- 分布式评估与反馈
通过验证的求解器会被部署到一个由 800 个 CPU 节点组成的集群上,在完整的 SAT Competition 2024 基准测试集(包含 400 个实例)上进行并行评估。这种大规模并行使得整个评估过程可以在大约一小时内完成,从而为智能体提供近乎实时的性能反馈。
反馈指标非常详尽,包括已解决的 SAT/UNSAT 实例数量、不同时间段内解决的实例分布、内存使用情况,以及作为核心驱动指标的 PAR-2 分数(一种对未解决实例进行高额时间惩罚的平均运行时指标)。
实验结果
SATLUTION 在 70 个进化周期的实验中,展现了清晰且稳健的性能提升轨迹。
根据论文中对 2024 年基准测试集的性能追踪图表(图 8)显示,在最初的 5-10 个迭代周期中,系统取得了快速进展,这主要是因为它整合了多个初始种子求解器的互补优势。
随后,性能提升的速度有所放缓,但仍在持续进行,表明智能体开始处理更细微和复杂的优化问题。
大约在第 50 次迭代时,SATLUTION 进化出的求解器在 2024 年的基准上已经开始优于 2025 年的人类设计冠军。
到第 70 次迭代结束时,其性能已稳定地超越了所有用于比较的基准求解器。整个过程表现出高度的稳定性,由于验证保障措施的存在,没有发生过严重的性能衰退。

SATLUTION 自进化性能曲线。
整个 SATLUTION 自我进化实验过程的总计成本低于 20000 美元。相比之下,由人类专家开发一个具有竞争力的 SAT 求解器通常需要数月乃至数年的持续工程投入,而 SATLUTION 在数周内便取得了超越顶尖人类水平的成果。
更多细节请参见原论文。
....
#CTF-Dojo 和 Cyber-Zero
大模型智能体不止能写代码,还能被训练成白帽黑客
当人们还在惊叹大模型能写代码、能自动化办公时,它们正在悄然踏入一个更敏感、更危险的领域 —— 网络安全。
想象一下,如果 AI 不只是写代码的助手,而是能够像「白帽黑客」一样,在不破坏系统的前提下模拟攻击、发现漏洞、提出修复建议,会带来怎样的改变?
这个问题,最近由 Amazon AWS AI 的 Q Developer 团队给出了答案。他们在 arXiv 上同时发布了两篇论文,提出了训练网络安全大模型的全新方法:Cyber-Zero 和 CTF-Dojo。这两项研究不仅是学术探索,更像是一次「实战演练」的预告,预示着大模型智能体正在从通用任务走向网络安全的前线。
论文 1: Cyber-Zero: Training Cybersecurity Agents without Runtime
链接: https://arxiv.org/abs/2508.00910
论文 2: Training Language Model Agents to Find Vulnerabilities with CTF-Dojo
链接:https://arxiv.org/abs/2508.18370
网络安全
大模型落地的一座特殊堡垒
在通用任务上,大模型的训练已经形成了相对成熟的范式:海量数据、长时间预训练、再经过对齐与微调。但网络安全场景不同,其核心难点在于训练环境与数据的高度敏感性。
事实上,闭源大模型已经在安全攻防方向展现出一定潜力。Google 的 Project Zero 团队就曾使用 Gemini 系列模型探索漏洞发现,一些初创公司甚至尝试构建基于闭源模型的「AI 红队」,用来模拟攻击并进行防御验证。实际案例表明,这些强大的闭源模型确实具备了发现漏洞、自动化执行攻击步骤的潜力。
然而问题在于,这些模型的训练范式和数据集完全不透明。我们无法得知它们是如何习得攻防知识的,也无法验证模型的安全性与可靠性。更重要的是,闭源模型无法被研究者和企业安全团队自主改造或控制,这本身在安全领域是一种潜在风险。
另一方面,如果要让模型从零开始学会攻防,传统思路需要搭建真实运行环境,以生成交互轨迹。但这种方式成本高、风险大,甚至可能在实验中触发不可控的攻击。而高质量的安全攻防数据本就极度稀缺。漏洞利用和修复往往涉及复杂的环境状态、系统调用和长时间推理,很难像自然语言文本那样容易转化为标准语料。
这意味着,如果继续沿用传统方式,「AI 白帽黑客」可能永远只能停留在实验阶段。Amazon 团队正是瞄准了这个瓶颈,提出了两个互补的解决方案:Cyber-Zero 致力于「如何生成安全而高效的训练数据」,而 CTF-Dojo 则专注于「如何在实战中训练模型发现漏洞」。
Cyber-Zero
无需真实环境的模拟训练场
Cyber-Zero 的核心思想是「runtime-free training」,即完全不依赖真实运行环境,而是通过已有知识和语言建模生成训练所需的高质量行为轨迹 (trajectories)。
团队注意到,公开的 CTF(Capture The Flag)竞赛 writeups 是极其宝贵的资源。它们记录了参赛者如何分析题目、尝试攻击、定位漏洞以及最终解题的过程。Cyber-Zero 正是基于这些 writeups,构建出高质量的训练轨迹。
具体来说,系统首先从 writeups 中提取关键步骤和思路,然后通过设定不同的人格(persona),让大模型在纯文本环境中模拟攻防双方的对话与操作。例如,攻击者 persona 会生成可能的利用路径,防御者 persona 会进行应对。这一过程中生成的长序列交互被视作行为轨迹,用于训练网络安全智能体。

实验表明,这种免运行时的轨迹生成不仅规模可观,而且多样性丰富,覆盖了常见的攻防模式。与真实环境生成的轨迹相比,Cyber-Zero 的数据在漏洞定位、攻击路径推理等任务上的训练效果毫不逊色,甚至在部分指标上表现更优。这意味着,AI 白帽黑客可以在一个完全安全的虚拟训练营中反复优化,而不必担心成本和风险。

团队还得出几项关键发现:
- 通用的软件工程智能体(SWE Agents)无法直接迁移至网络安全任务。写代码 ≠ 找漏洞,两类技能之间存在明显鸿沟。
- 模型规模与性能密切相关:参数更大的模型更擅长维持长程推理链,跨多步组合命令,并在多轮交互中保持状态连贯,这对复杂攻防至关重要。
- 经过 Cyber-Zero 轨迹微调的 32B 智能体,性能已接近闭源模型 Claude-3.7-Sonnet,而推理成本仅为其 1%。
这些结果一方面凸显了 Cyber-Zero 的实用价值:它不仅能安全、低成本地生成训练数据,还能让模型通过微调在安全任务上具备实用能力;另一方面也指出了研究方向:如果不针对安全任务进行专门优化,即便是大规模的通用 SWE 智能体也难以承担白帽黑客的角色。
CTF-Dojo
让 AI 在实战中学会发现漏洞
如果说 Cyber-Zero 提供的是一个「虚构的训练场」,它通过解析 CTF writeups 与 persona 模拟,在纯文本空间中生成攻防轨迹,让模型在完全无风险的虚拟环境中学习;那么 CTF-Dojo 就是一个「真实的战场」。它直接构建可运行的 CTF 攻防环境,让智能体能够真正执行命令、与系统交互、发现并利用漏洞。前者强调规模化、安全、高效的数据生成,后者强调贴近实战的攻防演练,两者一虚一实,形成互补。
CTF-Dojo 的核心难点在于:如何在大规模下为 LLM 智能体提供稳定的运行环境。传统 SWE(软件工程)代理通常需要专家手动配置环境才能运行,而每个任务的准备工作往往耗时数周,极大限制了研究规模。为此,Amazon 团队提出了 CTF-Forge,一种能够在几分钟内自动搭建运行时的容器化工具,可以快速部署数百个挑战实例,显著降低了人力成本。

研究团队选择了全球最具代表性的 pwn.college CTF Archive 作为种子数据。该数据集收录了数百个来自顶级赛事的高质量题目,涵盖六大类别,从 Web 漏洞、二进制利用到密码学挑战一应俱全。通过精心筛选,并排除测试数据中已包含的题目,最终形成了 658 个独立任务实例,为智能体训练提供了坚实的基础。
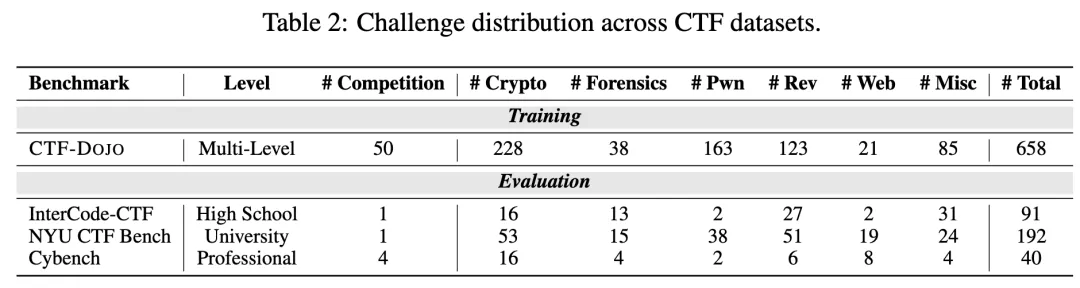
然而,最初实验表明,开源模型在这些复杂任务上的成功率极低。大部分 OSS 模型只能完成少数挑战,生成的轨迹也质量参差不齐。为了提高可用样本的产出率,团队引入了三项推理阶段增强技术:
- 将公开的赛题笔记(writeups) 作为提示,帮助模型更快锁定解题方向;
- 运行时增强:通过在执行过程中动态修改环境配置或任务约束,把过于复杂的挑战「降维」,从而提升模型完成任务的成功率;
- 教师模型多样化:不仅依赖单一模型生成解题轨迹,而是同时调用多种不同类型的大模型(包括开源和闭源),让它们各自贡献成功案例,以此获得更丰富、更具多样性的训练样本。
最终,团队主要依赖 Qwen3-Code-480B 和 DeepSeek-V3-0324 两个强大的开源模型,收集到来自 274 个挑战的 1000+ 成功轨迹。在去除冗余、限制每个任务实例的最大样本数后,最终得到了 486 条高质量、经过运行验证的轨迹。
基于这些数据,研究团队对 Qwen3 系列模型(8B、14B 和 32B 参数规模)进行了训练,并在多个网络安全基准任务上评估了效果。结果显示,经过 CTF-Dojo 训练的模型,在 EnIGMA+ 基准(源自前作 Cyber-Zero)上取得了最高 11.6% 的绝对提升,不仅超过了开源基线模型,还表现出与闭源模型接近的水平。更重要的是,随着训练样本数量的增加,性能呈现出清晰的可扩展性,证明了在真实环境轨迹驱动下,大模型在网络安全任务上的潜力可以被系统性激发。
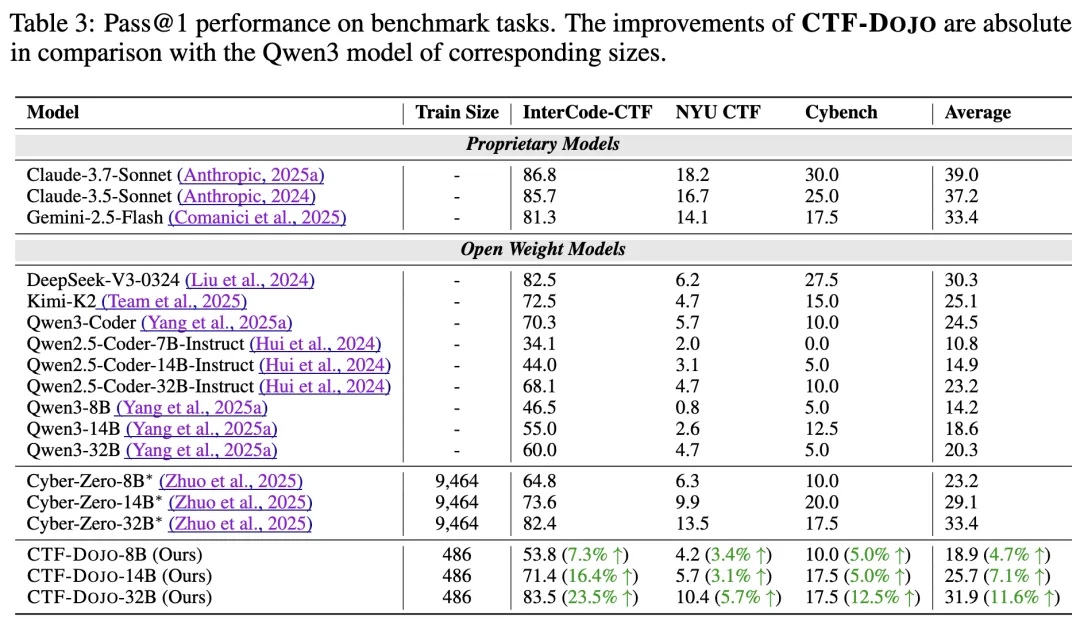
这些结果意味着,CTF-Dojo 不仅解决了过去「环境难以大规模配置」的工程难题,还验证了一个核心科学问题:网络安全智能体的性能能够随着执行数据的增加而持续提升。在已有 SWE 代理无法泛化的情况下,CTF-Dojo 给出了一条清晰的道路:通过规模化、自动化的运行环境收集轨迹,推动模型逐步逼近人类白帽黑客的实战水平。
从虚拟到实战的组合拳
把 Cyber-Zero 和 CTF-Dojo 放在一起看,就会发现它们形成了一个闭环。Cyber-Zero 提供的是安全、可扩展的训练数据来源,相当于一个虚拟训练营;而 CTF-Dojo 则是实战武馆,让模型在真实挑战中不断迭代。前者解决了数据与成本的问题,后者解决了能力习得与迁移的问题。两者结合,为 AI 白帽黑客的成长提供了完整路径。
这种设计思路的意义在于,它不仅追求理论上的可行性,还强调在生产环境中真正可部署。正如论文中展示的实验结果,Cyber-Zero 的数据生成和 CTF-Dojo 的环境构建都能规模化运行,且能在真实任务上带来可验证的性能提升。这标志着 AI 在网络安全方向正在逐步进入应用落地阶段。
未来意义与挑战
AI 白帽黑客蕴藏广阔前景:在企业安全团队中,它可以作为虚拟成员,自动扫描代码、发现潜在漏洞,并提出修复建议;在红队演练中,它可以充当对手角色,帮助测试防御系统;在教育场景中,它可以成为学员的「陪练」,提供个性化的挑战和反馈。更长远来看,随着成本降低和技术成熟,中小企业也有望借助这样的系统获得「普惠安全」。
但与此同时,这项技术的双重用途属性不容忽视。正如研究团队在论文中强调的那样,虽然 Cyber-Zero 和 CTF-Dojo 的初衷是帮助开发者和研究人员在软件部署前发现并修复漏洞,但同样的能力也可能被滥用于进攻目的,比如自动化发现外部系统的漏洞,甚至开发恶意工具。特别是 Cyber-Zero 的「免运行时」方法,降低了训练高性能网络安全智能体的门槛,使其更容易被更广泛的群体获取和使用。这种民主化的趋势既意味着安全研究的普及,也意味着风险的扩散。
实验结果已经证明,基于虚拟轨迹或执行验证数据训练的模型,能够在多个基准任务上达到接近甚至媲美闭源前沿模型的性能。这表明先进网络安全能力的民主化不仅在技术上可行,而且正在快速到来。如何确保这类能力更多地服务于防御,而不是被滥用于攻击,将是未来亟需讨论的议题。
在未来研究方向上,团队提出了几个值得关注的思路。一个是构建实时更新的 CTF 基准:通过 CTF-Forge 自动重建比赛环境,把来自活跃 CTF 赛事的挑战容器化,用于动态评测和轨迹采集,实现可扩展、实时的 benchmark。另一个方向是强化学习,即让网络安全智能体直接与动态环境交互,并通过结构化奖励获得反馈。这种范式有望突破单纯模仿学习的局限,使模型能够发展出更普适、更具适应性的策略,更好地应对未知的安全问题。
因此,未来的关键在于平衡开放与安全。在推动技术进步与普及的同时,建立有效的安全护栏,需研究者、开发者、安全机构与政策制定者协同努力,确保这类强大工具以负责任的方式被开发和使用。唯有如此,才能真正增强整体网络防御能力,迎接一个更安全的智能时代。
参考资料:
[1] Zhuo, T. Y., Wang, D., Ding, H., Kumar, V., & Wang, Z. (2025). Cyber-Zero: Training Cybersecurity Agents without Runtime. arXiv preprint arXiv:2508.00910.
[2] Zhuo, T. Y., Wang, D., Ding, H., Kumar, V., & Wang, Z. (2025). Training Language Model Agents to Find Vulnerabilities with CTF-Dojo. arXiv preprint arXiv:2508.18370.
[3] https://x.com/terryyuezhuo/status/1962009753472950294
[4] https://github.com/amazon-science/Cyber-Zero
.....
#AgentGym-RL
交互扩展时代来临:创智复旦字节重磅发布,昇腾加持,开创智能体训练新范式
强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 曾指出,人工智能正在迈入「经验时代」—— 在这个时代,真正的智能不再仅仅依赖大量标注数据的监督学习,而是来源于在真实环境中主动探索、不断积累经验的能力。正如人类通过实践理解世界、优化行为一样,智能体也必须在交互中积累经验、改进策略,才能掌握长期决策的能力。
无独有偶,特斯拉前 AI 负责人,OpenAI 联合创始人 Andrej Karpathy 进一步指出,环境的多样性与真实性,是智能体获得泛化能力、应对复杂任务的关键前提。缺乏丰富的环境,智能体就无法充分暴露于多样化情境,也难以从经验中形成稳健的决策策略。
在这一背景下,复旦、创智、字节的研究者们基于智能体自我进化框架 AgentGym,全新打造了多环境强化学习智能体训练框架 AgentGym-RL。
本文的第一作者为复旦大学自然语言处理实验室博士生奚志恒,通讯作者为复旦大学自然语言处理实验室的桂韬教授和张奇教授。
这一框架是首个无需监督微调、具备统一端到端架构、支持交互式多轮训练,且在多类真实场景中验证有效的 LLM 智能体强化学习框架,为 LLM 智能体的强化学习提供了全新的解决方案。
依托 AgentGym-RL 框架,研究人员创新性地提出了智能体范式下扩展测试时计算的新路径 —— 扩展环境交互(Scaling Interaction)。其核心是通过增加训练与测试阶段模型和外部环境的交互回合数,让模型借助多轮反馈逐步完善决策、提升表现。
相较于传统测试时扩展方法,新路径优势显著:传统方法局限于模型内部,仅靠延长思维链消耗更多 Token,缺乏与外部环境的实时互动,难以应对复杂任务的动态场景需求;而扩展交互轮次突破了这种封闭式推理,允许模型依据每轮反馈动态修正策略,最终以更结构化的决策流程、更高效率的问题解决路径完成任务,成为智能体范式下表现更优的测试时扩展方案。
然而,长交互轮次训练面临着容易出现崩溃的问题。针对这一痛点,研究团队再次突破,提出了 ScalingInter RL 交互轮次扩展策略,通过分阶段增加模型最长交互轮次限制,使智能体能够先在短交互轮次下掌握基础技能,再逐步过渡到中长交互轮次解决复杂任务,平衡了智能体训练过程中的探索与利用,有效规避了模型崩溃的风险,成功构建了稳定的交互轮次扩展训练范式。
借助 AgentGym-RL 这一统一框架,结合 ScalingInter-RL 算法的稳定扩展能力,研究团队取得了令人瞩目的成果:
仅仅是 7B 大小的模型,在多个真实任务导向的环境中经过长轮次交互训练后,竟逐步掌握了理解任务目标、预测行动后果、规划多步操作等复杂任务处理技能。从自主浏览界面、精准筛选选项,到对比参数、执行操作,整个过程流畅高效,展现出前所未有的自主决策水平。在五种测试环境、26 项测试任务中,它不仅超越了 100B 以上的大型开源模型,还追平了 OpenAI o3、谷歌 Gemini 2.5 Pro、DeepSeek r1 等顶尖商业模型的水平,充分彰显出 AgentGym-RL 框架与交互轮次扩展范式的强大潜力与竞争力,也为人工智能在 「经验时代」 的发展注入了强劲动力。

商业模型、开源模型以及本文强化学习模型在不同智能体任务中的表现。
从网页导航到科学实验,从文字游戏到实体交互,这套兼容 PPO、GRPO 等主流算法的模块化框架,正为开源社区推开自主智能体研发的全新大门。
论文标题:AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
论文地址:https://arxiv.org/abs/2509.08755
项目主页:https://agentgym-rl.github.io
代码地址:https://github.com/WooooDyy/AgentGym-RL
环境框架地址:https://github.com/WooooDyy/AgentGym
研究背景:从 「数据密集」 到 「经验密集」
构建能够在复杂现实场景中完成多轮决策的自主 LLM 智能体,是人工智能领域一个新兴且快速发展的前沿方向。
Sutton 曾强调,人工智能的发展正从 「数据密集型」 向 「经验密集型」 转型:早期模型依赖海量标注数据进行监督学习,如同通过教科书间接获取知识;而真正的智能体应当像人类一样,在真实环境中通过 「做中学」积累经验,在持续交互中理解环境规则、预测行动后果、优化长期目标。
而在这一过程中,构建真实、多样、贴合现实需求的交互环境则成为了强化学习的重中之重。真实的环境是智能体获得有效经验的基础,只有还原场景中的动态变化与不确定因素,才能避免智能体陷入 「实验室表现优异、落地即失效」 的困境;环境的多样化是智能体具备泛化能力的前提,只有覆盖多类型任务场景的交互逻辑,才能让智能体在新场景中快速迁移已有经验。
然而, 当前大多数现有研究局限于单轮任务,缺乏与复杂环境的多轮交互机制。虽然最近有研究尝试扩展 RL 以训练具有多轮能力的 LLM 智能体,但这些工作仍然存在任务场景单一、环境适配性差、优化稳定性低等问题,使得智能体无法接触到足够丰富的环境信息,难以生成和利用第一手经验,自然难以应对现实世界复杂多变的任务。因此,该领域目前仍然缺乏一个统一的、端到端的、交互式多轮 RL 框架,能够在广泛的实际场景和环境中有效地从头开始训练 LLM 智能体,而无需依赖监督微调(SFT)作为初步步骤。
为填补这一空白,研究团队提出了 AgentGym-RL,一个通过强化学习训练 LLM 智能体进行多轮交互式决策的新框架。该框架的研究工作围绕着推动智能体高效学习和决策展开,主要有以下贡献:
- 提出并开源 AgentGym-RL 框架:这是一个全新的、统一的、模块化且灵活的端到端 RL 框架,专为智能体多轮交互式决策而设计,包含丰富多样的场景和环境,让 「从经验学习」 有了标准化的实验场。
- 引入 ScalingInter-RL 方法:这是一种基于渐进式交互轮数拓展的强化学习训练方法,使智能体能够逐步适应环境,优化其交互模式、行为和技能,最终在探索和利用之间实现更好的平衡。
- 验证框架和方法的有效性:通过大量实验验证了 AgentGym-RL 和 ScaleInter-RL 能够显著且稳定地提升智能体性能,使其在复杂任务处理能力上与顶尖商业模型形成对标甚至实现性能反超。
AgentGym-RL:为经验时代打造的自主智能体训练基础设施
AgentGym-RL 集成了多种环境、丰富的轨迹数据和全面的基准测试,通过标准化环境操作接口,将复杂的环境配置流程简化为便捷的模块化操作。该框架以 AgentGym 为基础进行迭代升级,通过优化模型与环境的交互协议、强化分布式并行计算架构、引入强化学习训练模块等方式进行改进。
其核心目标,就是为 LLM 智能体构建一个能够持续产生 「有效经验」 的生态,让「经验驱动学习」不再依赖零散的实验设置,而是具备可复现、可扩展的坚实基础。
模块架构
AgentGym-RL 框架主要包含环境、代理和训练三个组件。
- 环境模块中,每个环境打包为独立服务,支持并行请求,环境客户端通过 HTTP 连接服务器,向代理暴露如获取观测、动作等 API,涵盖多场景、环境、任务和数据实例,为 LLM 代理训练提供支持
- 代理模块封装语言模型代理与环境的交互逻辑,支持多种提示和采样配置,扩展长期规划、自我反思等高级机制。
- 训练模块实现支持在线算法的统一强化学习管道,管理经验收集等,支持课程学习和交互扩展,高度模块化,支持多训练方法,训练过程可分布在多节点。
AgentGym-RL 架构图:采用解耦化设计,兼具灵活性与可扩展性,能够支持多种场景、环境类型及算法的应用与适配。
多样化的环境
AgentGym-RL 框架包含多种环境和丰富的任务,涵盖了网页导航、文字游戏、xx控制、科学探索和深度搜索等多个类别 —— 精准对应了语言智能体领域的重要推动者、OpenAI 研究科学家姚顺雨所说的 「AI 下半场落地场景」,每一类环境都指向真实世界中 AI 需要解决的实际问题。该框架支持主流的 RL 算法,并配备了广泛的实际场景:
- 网页导航:对应 WebArena 等环境,包含电商、Reddit 论坛、GitLab 协作开发、OpenStreetMap 地图、CMS 内容管理系统等 5 个子任务,共 372 个训练查询和 50 个测试查询。智能体需模拟人类与网页交互,完成在线购物、信息提取、表单填写等操作,涉及地图、计算器等工具的使用。
- 深度搜索:对应基于搜索引擎的环境,涵盖 NQ、TriviaQA、PopQA 等 7 个数据集的任务。智能体需通过动态生成搜索查询、调用浏览器和 Python 解释器等工具,从外部源获取信息并整合,完成多轮检索与推理任务。
- 电子游戏:对应 TextCraft 等环境,这是一种类 Minecraft 的文本制作游戏。任务按制作树深度分为 1-4 级,智能体需通过自然语言交互使用制作、 inventory 管理等 API,完成从简单到复杂的物品制作任务。
- xx控制:对应 BabyAI 等环境,这是一个可控的网格世界,任务按最终目标分为 6 个子集。智能体需通过自然语言指令导航,执行移动、拾取物体、开门等动作,涉及空间推理和环境交互能力。
- 科学任务:对应 SciWorld 等环境,选取 8 个子任务。智能体需在模拟的科学场景中,使用实验室仪器相关 API 进行实验(如测量温度、连接电路、混合化学物质),完成科学探索和假设验证任务。
多种强化学习算法
AgentGym-RL 提供全面的算法支持,涵盖不同的学习方法,包括监督微调(SFT)、直接偏好优化(DPO)、拒绝采样和在线 RL 算法等。在线 RL 是 AgentGym-RL 的核心,支持多种主流在线 RL 算法,如近端策略优化(PPO)、组近端策略优化(GRPO)、增强型 REINFORCE(REINFORCE++)和基于回合的策略优化(RLOO)等。
ScalingInter-RL:交互扩展新策略
基于 AgentGym-RL 框架,研究团队创新性地提出了 ScalingInter-RL 方法,通过扩展智能体在训练过程中的交互轮数,平衡智能体对环境的探索与利用,显著提升智能体在复杂环境中的学习和决策能力。
ScalingInter-RL 算法示意图
ScalingInter-RL 方法的核心在于逐步、动态地扩展智能体与环境的交互轮次。
在训练的初始阶段,智能体的主要任务是快速学习基本技能,解决相对简单的问题。此时,ScalingInter-RL 会限制交互轮次,引导智能体集中精力利用已有的知识和策略,尽可能高效地完成任务。这种策略就像是为智能体制定了一个循序渐进的学习计划,让它在稳固的基础上逐步成长。
随着训练的稳步推进,智能体已经掌握了一定的基础能力,此时 ScalingInter-RL 会适时地增加交互轮次。这一举措鼓励智能体勇敢地探索更多未知的领域,尝试不同的行动和策略。通过这种方式,智能体能够避免陷入固定的思维模式和行动路径,不断优化自己的行为,从而更好地应对复杂多变的环境。
在实际应用中,这种策略展现出了显著的优势。在网页导航任务中,初始阶段,智能体通过有限的交互轮次,迅速掌握了基本的网页操作技能,如点击链接、填写表单等。随着训练的深入,交互轮次的增加使得智能体能够更加深入地探索网页的各种功能和结构,学会了根据不同的任务需求,灵活地调整操作策略,从而更加高效地完成任务。在科学任务中,智能体在初期利用有限的交互学习基本实验操作,随着交互轮次的增多,能够更全面地探索实验条件和变量之间的关系,优化实验步骤,提高实验成功率。
实验
为了全面验证 AgentGym-RL 框架的稳定性和有效性,研究团队开展了一系列广泛且深入的实验。这些实验覆盖了丰富多样的场景和环境,旨在模拟智能体在实际应用中可能面临的各种复杂情况,从而全面、准确地评估智能体的性能。
实验涵盖了五个主要场景,包括网页导航、深度搜索、数字游戏、xx任务和科学任务。
主要结果
在 5 个不同场景(Web 导航、深度搜索、数字游戏、xx任务、科学任务)中,使用 AgentGym-RL 框架训练的开源模型展现出了出色的多轮交互决策能力。
进一步,通过 ScalingInter-RL 方法的优化,这些模型实现了显著的性能提升,甚至超越了一些大型商业闭源模型。在网页导航任务中,ScalingInter-7B 模型的总体准确率达到了 26.00%,大幅超越了 GPT-4o 的 16.00%,与 DeepSeek-R1-0528 和 Gemini-2.5-Pro 的表现相当;在科学场景中,ScalingInter-7B 模型以 57.00% 的总体得分创下新的最优成绩,远超所有开源和专有模型,包括排名第二的专有模型 OpenAI o3(41.50%)。
因篇幅所限,此处仅展示部分实验结果,更多详细结果请查阅论文。实验结果表明,经 ScalingInter-RL 算法训练的模型在多个环境中均达到了领先水平,实现了显著的性能提升。
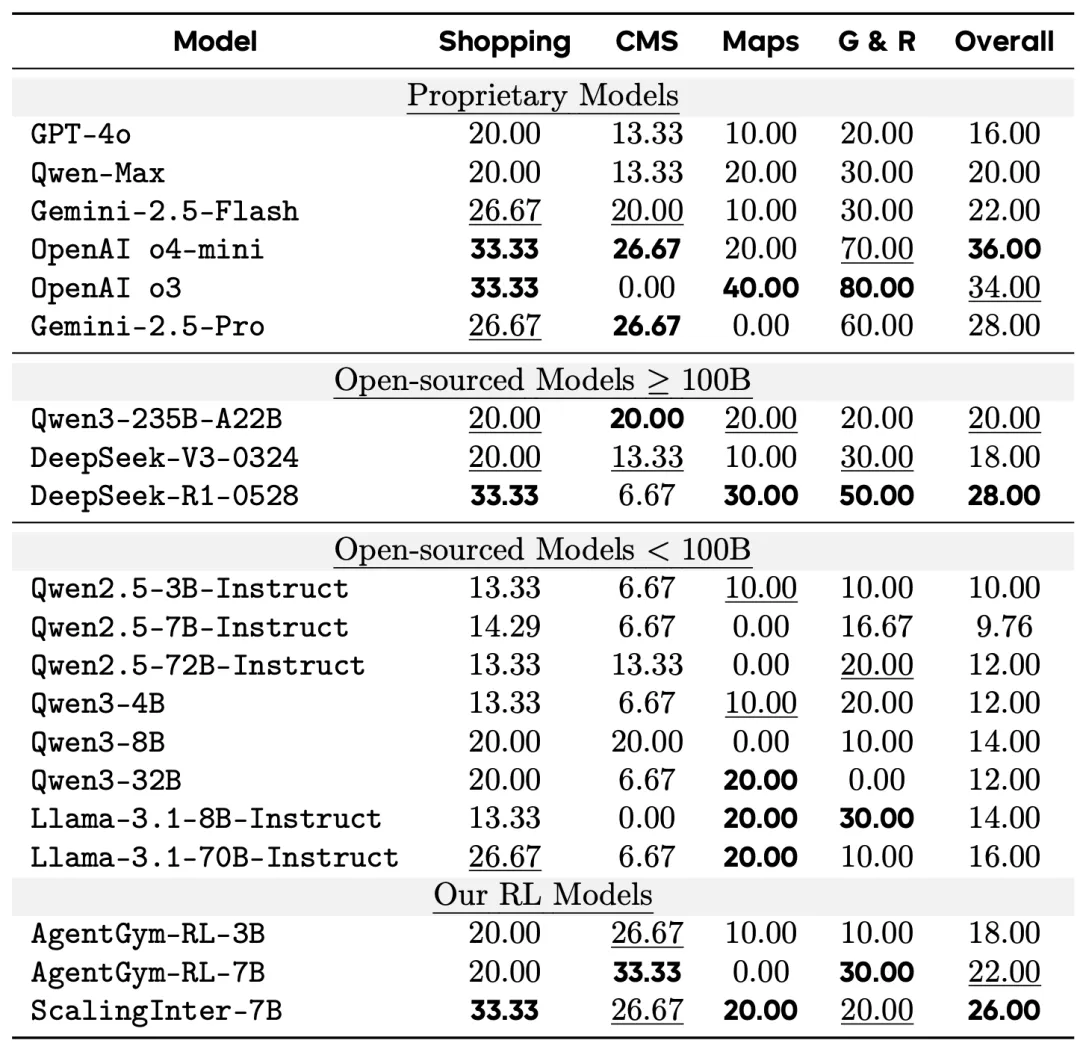
在 WebArena 环境下的实验结果。
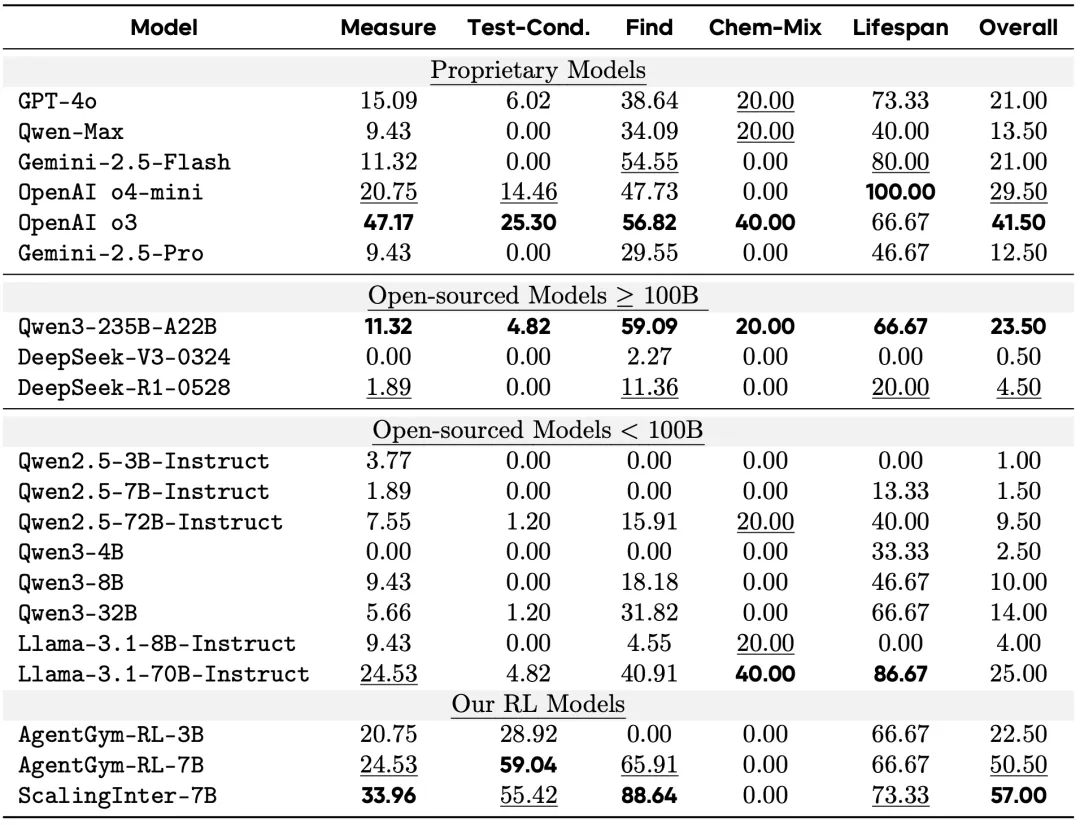
在 SciWorld 环境下的实验结果。
ScalingInter-RL 展现更稳定高效的强化学习优化动态
ScalingInter-RL 方法在训练稳定性与效率上显著优于传统方案。实验表明,训练周期内,采用该方法的智能体奖励值始终保持上升趋势,而固定轮次模型 150 步后奖励值衰减 32%。这种稳定性源于其渐进式交互设计 —— 通过动态调整交互深度,使智能体在技能积累阶段避免因探索过度导致的策略震荡,在优化阶段又能保持足够的行为多样性。
效率方面,ScalingInter-RL 方法同样提升显著。TextCraft 任务中,ScalingInter-RL 以传统方法 60% 步数达成 89% 成功率;WebArena 导航任务里,单位计算量性能增益是 PPO 算法 1.8 倍,适合大规模多场景训练。
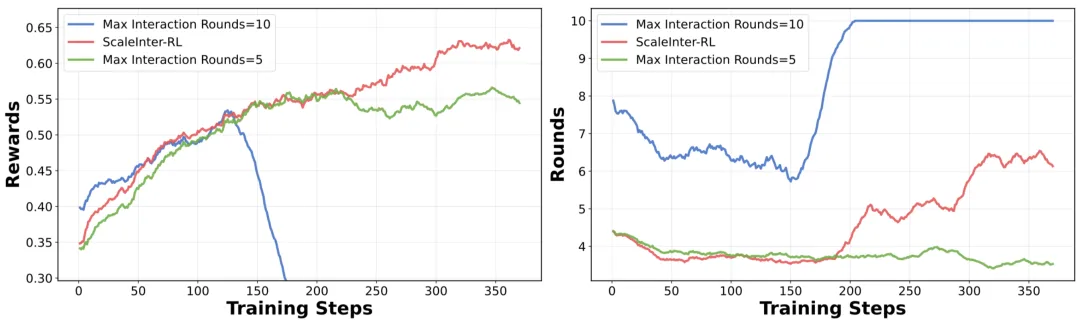
ScalingInter-RL和传统RL算法的训练动态对比
后训练与测试时计算量比模型规模具有更高的缩放潜力
实验得出一个关键见解:有策略地投入后训练计算和测试时计算,比仅仅增加模型的参数数量更具影响力。7B 参数的 ScalingInter-RL 模型在经过本文研究者的强化学习框架训练后,不仅超过了其他同等规模的开源模型,还显著优于参数规模近其十倍的更大模型。
这表明,针对性的训练与推理计算投资,比单纯扩大模型参数更具性价比。
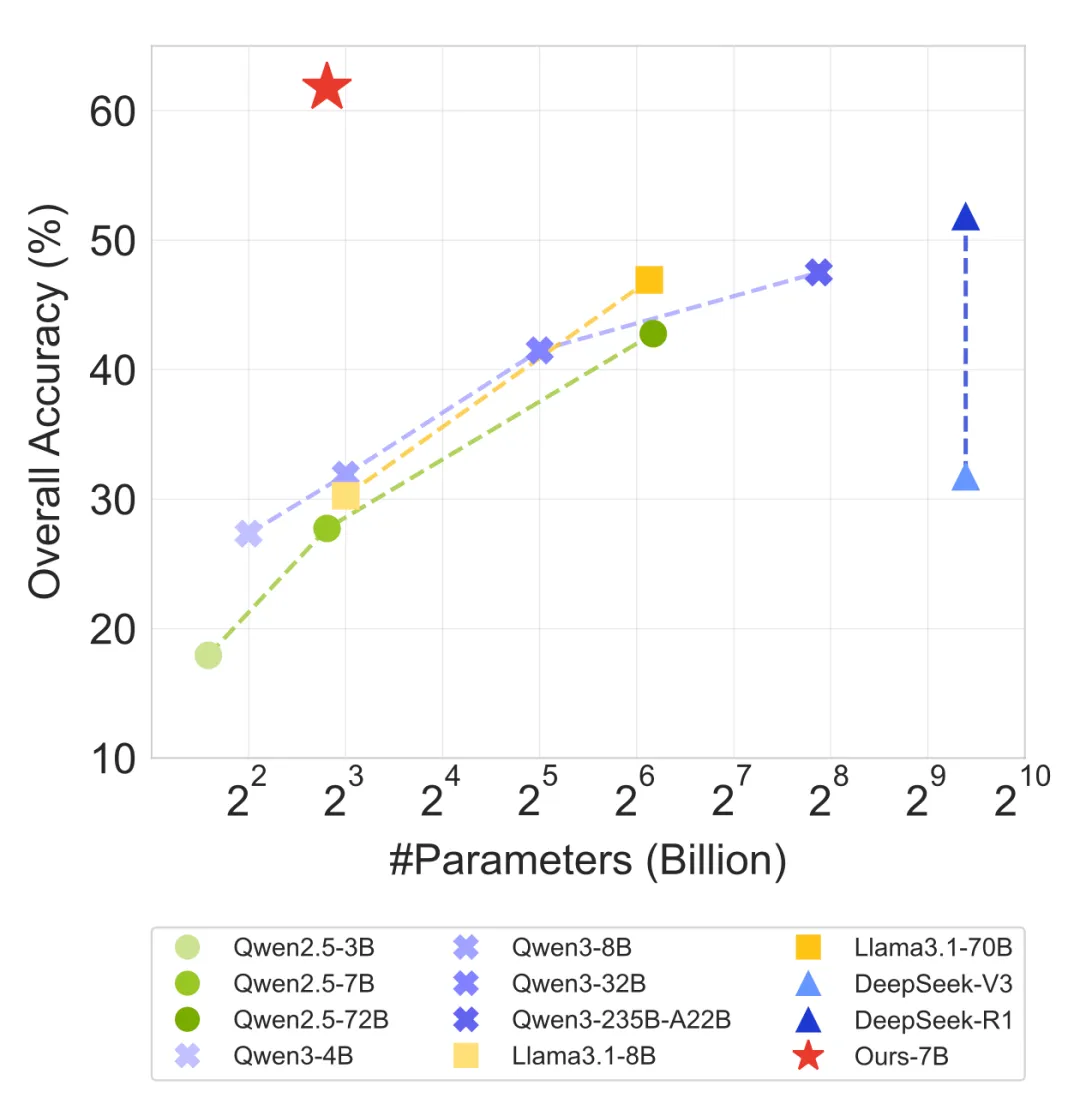
本文框架和方法通过后训练,显著提升了7B参数规模开源模型的能力,不仅超过了其他同等规模的开源模型,且显著优于参数规模近其十倍的更大模型。
环境结构是决定强化学习效率的关键因素
不同场景的结构特性对 RL 训练效果产生显著分化影响。在规则明确、反馈清晰的环境(如 TextCraft、BabyAI、SciWorld)中,RL 能带来大幅性能提升;而在开放式环境(如 WebArena、SearchQA)中,性能提升则有限。
这表明,环境的规则明确性、状态可观测性和奖励稀疏度,共同构成了 RL 算法效率的边界条件 —— 当环境复杂度超出智能体的状态表征能力时,即使最优训练策略也难以发挥作用。
讨论
研究团队从三个角度调查了智能体表现如何随推理时计算增加:
- 扩展交互轮次:随着推理时交互轮次的增加,所有模型的性能均呈现上升趋势,其中经 AgentGym-RL 训练的智能体始终保持领先优势,验证了交互扩展对环境探索的重要性。
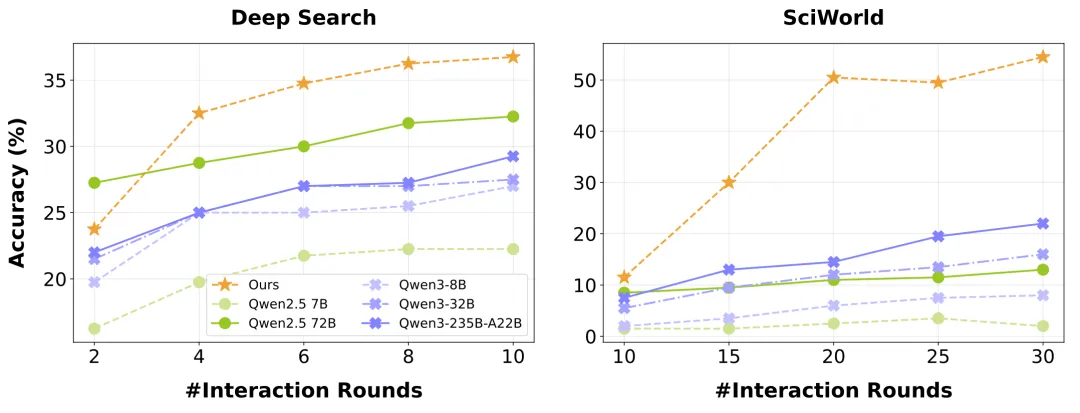
随着测试时交互轮次的增加,所有模型的性能均呈现上升趋势。
- 扩展采样数量:在并行采样方面,增加采样数量(K 值)能显著提升 Pass@K 指标,且经 RL 训练的模型在相同采样预算下表现更优。
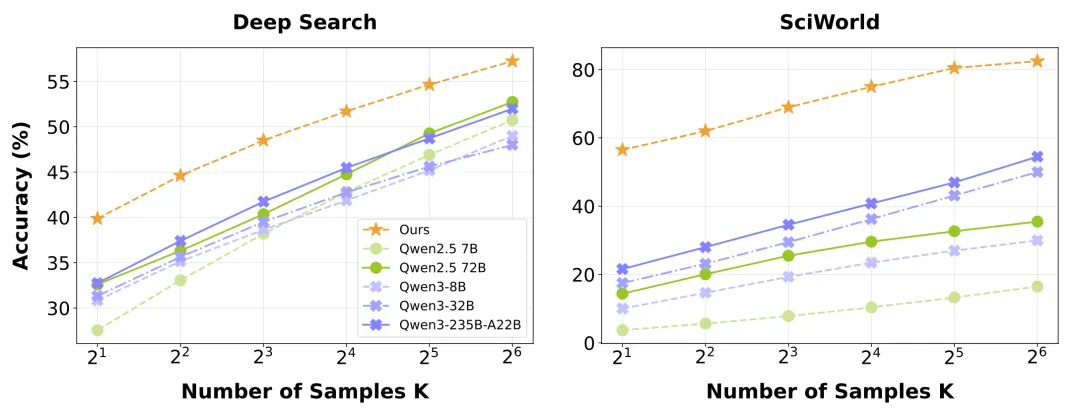
随着采样数量的增加,所有模型的性能均呈上升趋势。
- 不同 RL 算法比较:对比 GRPO 与 REINFORCE++ 两种主流 RL 算法发现,GRPO 在 TextCraft、BabyAI 和 SearchQA 任务上均显著优于 REINFORCE++。即使 3B 参数的 GRPO 模型,其性能也超过 7B 参数的 REINFORCE++ 模型,表明算法选择对性能的影响可能大于模型规模。
模型在不同强化学习算法下的测试结果
真实交互示例
不妨聚焦这些真实交互场景 —— 在以 BabyAI 为代表的xx任务中,该研究中的智能体展现出了卓越性能。以 「找到黄色小球并带回起点」 这一任务为例,其不仅要求智能体具备基础的路径规划与避障能力,还涉及更为复杂的长程依赖与顺序规划逻辑。跨步骤的信息利用能力、动态化的探索策略,以及对多阶段任务的全局把控能力,使得该任务的难度远超单一反应类操作。
而基于 AgentGym-RL 框架、经 ScalingInter 算法训练的智能体,正是在这类高难度场景中展现出了令人瞩目的表现。它不仅能精准理解任务核心目标,还能在多扇彩色门与未知房间构成的复杂环境中,开展有条理的探索活动,合理规划行动顺序;当确认某一区域无探索价值后,更能主动离开并转向新的探索路径。尤为难得的是,它能高效利用已获取的环境信息,将分散在不同时间节点的观察结果串联起来,构建连贯的决策链路。正是这种跨步骤的信息整合能力与动态调整机制,让它在复杂环境中始终保持清晰且高效的任务执行能力。
,时长00:15
而在以 WebArena 环境为代表的真实网页交互场景中,智能体需要面对充斥着大量噪音的网页界面,真正的功能入口往往被隐藏在层层标签页和复杂的交互逻辑之下。若缺乏对页面结构的理解,智能体很容易陷入低效的穷举式搜索。然而,基于 AgentGym-RL 框架、经 ScalingInter 算法训练后,智能体能够主动点击 「Sales」 标签页,精准锁定与任务相关的入口,并进一步利用内置的 「Filter」 功能进行筛选,而不是依赖低效的遍历查看。这一系列操作表明它已经掌握了网页的结构与规则,并能基于探索经验选择更高效的策略,从而显著提升任务的准确性与执行效率。
,时长00:42
结论与展望:以经验学习开启 AI 下半场的自主智能体时代
AgentGym-RL 框架的推出,不仅是自主 LLM 智能体训练领域的一次技术突破,更标志着 AI 行业向「经验时代」的深度迈进。
从技术层面看,AgentGym-RL 通过统一的端到端 RL 框架,解决了自主智能体训练中 「场景单一、算法割裂、效率低下」 的痛点,让 「从经验中学习」 成为标准化、可复现的技术路径;而 ScalingInter-RL 方法则通过渐进式交互轮次扩展,平衡了经验探索与利用的关系,让智能体能够像人类一样 「循序渐进积累能力」。实验数据充分证明了这一方案的价值:7B 参数的开源模型在 26 项任务中对标甚至超越顶级闭源模型,为 AI 下半场的技术发展提供了新范式。
然而,探索的道路永无止境。未来,本文研究者们将重点关注以下三个方向:
1. 通用能力升级:使智能体打破 「领域壁垒」,在全新环境和面对未知工具时仍能进行高效决策;
2. 复杂场景拓展:向更长周期、更贴近物理世界的任务拓展,例如机器人操作、现实场景规划等,以应对更丰富的感官输入和庞大的行动空间;
3. 多智能体协同:从 「单打独斗」 转向 「团队协作」,探索多智能体系统的训练模式,以解锁更复杂的群体决策能力。
AgentGym-RL 框架已全面开源,期待与全球研究者携手,共同推动下一代智能体的发展,让人工智能在现实世界中展现出更卓越的 「行动力」!
本研究得到了华为昇腾 AI 处理器的算力支持。在昇腾和开源社区的努力下,诸多大模型训练框架均已支持昇腾 AI 处理器。此外,昇腾联合 vllm 社区推出了 vllm-ascend 框架,极大提升了百亿乃至千亿级参数量的大模型在国产算力上的推理效率。在本研究中,昇腾 910B NPU 在多个实验阶段中发挥作用 ,提高了研究效率。
....
#3000亿美元OpenAI大单
让世界首富位置换人了
甲骨文正在美国全国开建 AI 基础设施,可能还要贷款买 GPU。
昨晚,老牌科技公司甲骨文(Oracle)突然成为了全球关注的焦点。
该公司发布了截至 8 月 31 日的 2026 财年第一财季业绩:总营收 149 亿美元,同比增长约 12%,低于市场预期,但剩余的履约义务(RPO,即未交付合同总值)达到 4550 亿美元,同比暴增 359%。
这家软件巨头报告说,受人工智能算力需求驱动,其云业务收入到 2030 财年将跃升至 1440 亿美元,较当前财年不到 200 亿美元的业务预测有大幅增长。
受该消息影响,甲骨文股票直接涨了超过 35%。

现年 81 岁的甲骨文联合创始人拉里・埃里森(Larry Ellison)的身家瞬间增加 1000 亿美元,一度飙升至 3930 亿美元,超越了埃隆・马斯克(3850 亿美元),成为全球首富。
不过在当天收盘时,甲骨文股价稍稍回撤,马斯克再次领先。
埃里森拥有甲骨文高达 41% 的股份。
马斯克在商界树敌众多,埃里森也饱受恶评,不过埃里森却被认为是马斯克的人生导师,两人关系很好。埃里森在 2018 年至 2022 年期间担任过特斯拉董事会成员,并向马斯克收购推特(Twitter,现 X)注资了 10 亿美元。
据《华尔街日报》等媒体报道,甲骨文所说的未交付大单,很大一部分来自于 OpenAI。知情人士称,OpenAI 与甲骨文签署了一份合同,将在大约五年内购买价值 3000 亿美元的算力,该合约远远超出了 OpenAI 目前的收入。
这将是有史以来最大的云计算合同,甲骨文将需要 4.5 千兆瓦的电力容量,大致相当于四百万户家庭的用电量。
OpenAI 与甲骨文的合同将于 2027 年开始生效,未来还有很多不确定性。迄今为止,OpenAI 还没有进入盈利阶段。该公司于 6 月份披露,其年收入约为 100 亿美元,不到其平均每年需支付的 600 亿美元成本的五分之一。
在另一边,在新合同签署后,甲骨文未来收入的很大一部分会集中在单一客户身上,其可能还要举债购买数据中心所需的 AI 芯片。
甲骨文在 6 月份提交的一份文件中首次透露了这笔交易,当时它披露已达成一项云服务协议,该协议将使其自 2027 年起每年获得超过 300 亿美元的收入。随着更多数据中心的上线,这家云计算巨头将从 OpenAI 处获得更多的年度收入。OpenAI 在 7 月份宣布与甲骨文达成了一项 4.5 千兆瓦的电力协议,但并未透露合同的具体规模。
OpenAI 的巨额投入延续了 CEO 山姆・奥特曼长期以来的激进理念。除了搞 AI 基础设施建设,他还试图与博通合作开发定制 AI 芯片,打造一款 iPhone 竞争对手,这让 OpenAI 的烧钱速度远超所有初创公司。去年秋天,奥特曼还曾告诉投资者,OpenAI 要到 2029 年才能盈利,并预计在此之前将亏损 440 亿美元。
不论是新一代 AI 模型的研发还是大规模技术落地,OpenAI 面临的最大挑战一直是计算资源的短缺。这也是整个 AI 行业正在面临的问题。摩根士丹利 (Morgan Stanley) 表示,从今年到 2028 年,科技巨头在芯片、服务器和数据中心基础设施的支出预计将达到 2.9 万亿美元。
仅看 OpenAI,甲骨文与 OpenAI 的合作并非首次。自 2024 年夏天起,OpenAI 开始通过甲骨文获取计算服务。2025 年 1 月,OpenAI 进一步扩大了供应渠道,不再单独依赖主合作方微软的 Azure 作为唯一云服务提供商。为满足激增的算力需求,OpenAI 甚至在今年春季与竞争对手谷歌签署了云服务合同。
OpenAI 在算力上的大项目,就是其与软银合作的 5000 亿美元「星际之门」(Stargate)项目。OpenAI 表示,「星际之门」是其所有数据中心业务的品牌,甲骨文的交付被视为「星际之门」的一部分。
基于这个计划,甲骨文正在与数据中心建设商 Crusoe 等公司合作。据知情人士透露,他们计划在全美多个州建立数据中心。
在硅谷,甲骨文被视为「上个时代的恐龙」。该公司成立至今已有 48 年,业务主要围绕数据库等企业级软件服务。直到 2016 年,该公司才将云计算视为其未来的重要发展战略。
在 2021 年,甲骨文开始大幅度转型,对产品进行云化重构,并投入大量资金加强云业务,又一次走上了发展的快车道。但由于云计算领域竞争激烈,有亚马逊、微软、谷歌等大玩家,甲骨文在行业内的地位并不稳固。就在最近几周,甲骨文还宣布进行大规模裁员,计划在全球削减 3000 多个工作岗位,减少涵盖了云基础架构,企业软件和公司功能的职位。
OpenAI 的大单或许可以一举改变云计算领域的态势,不过要说在 AI 时代卖铲子,最终的获益人可能还是英伟达。
就在甲骨文拿下大单的同时,有人翻出了去年底拉里・埃里森在演讲中的一段话:我和马斯克一起找黄仁勋吃饭,恳请他提供更多 GPU。
,时长02:56
参考内容:
https://techcrunch.com/2025/09/10/openai-and-oracle-reportedly-ink-historic-cloud-computing-deal/
....
.
#ST-Raptor
攻克大模型「表格盲区」!框架发布,实现复杂半结构化表格的精准理解与信息抽取
本工作核心作者为汤子瑞(上海交通大学)、牛博宇(上海交通大学)。合作者为李帛修、周炜、王健楠、李国良、张心怡、吴帆。通讯作者为上海交通大学计算机学院博士生导师周煊赫。团队长期从事人工智能与数据交叉研究。
半结构化表格是我们日常工作中常见的 “拦路虎”—— 布局五花八门、结构复杂多变,让自动化数据处理变得异常困难。
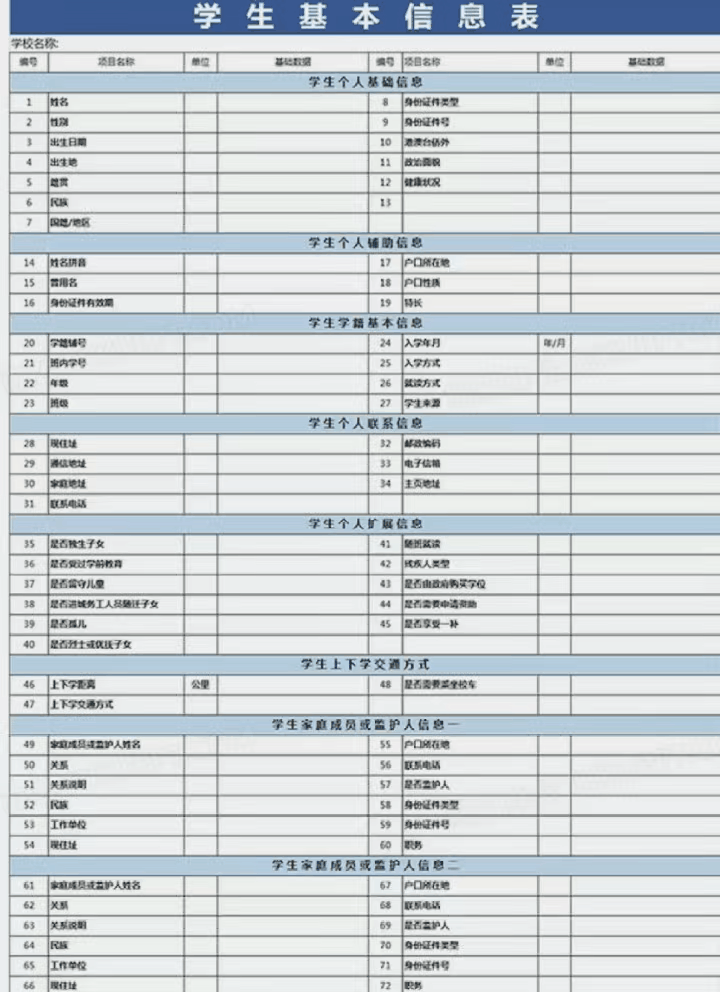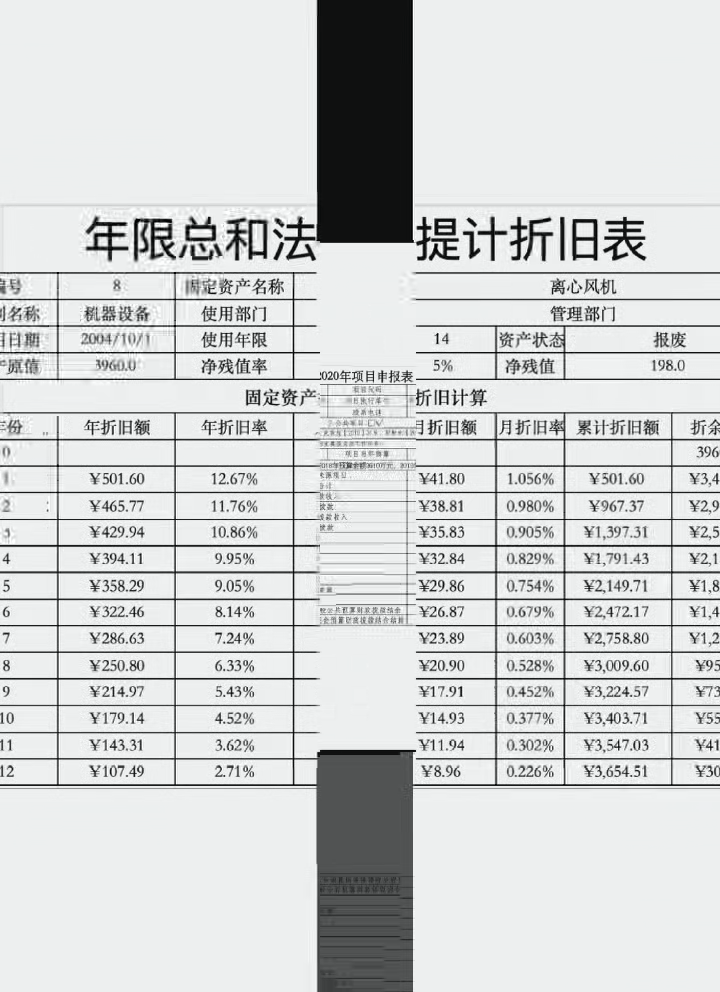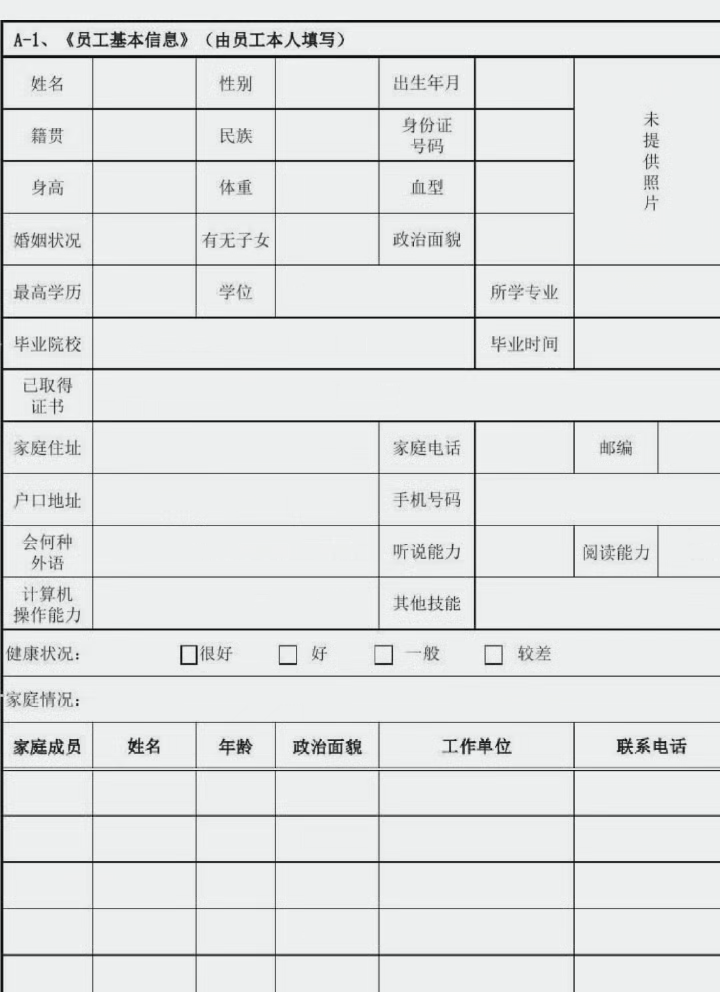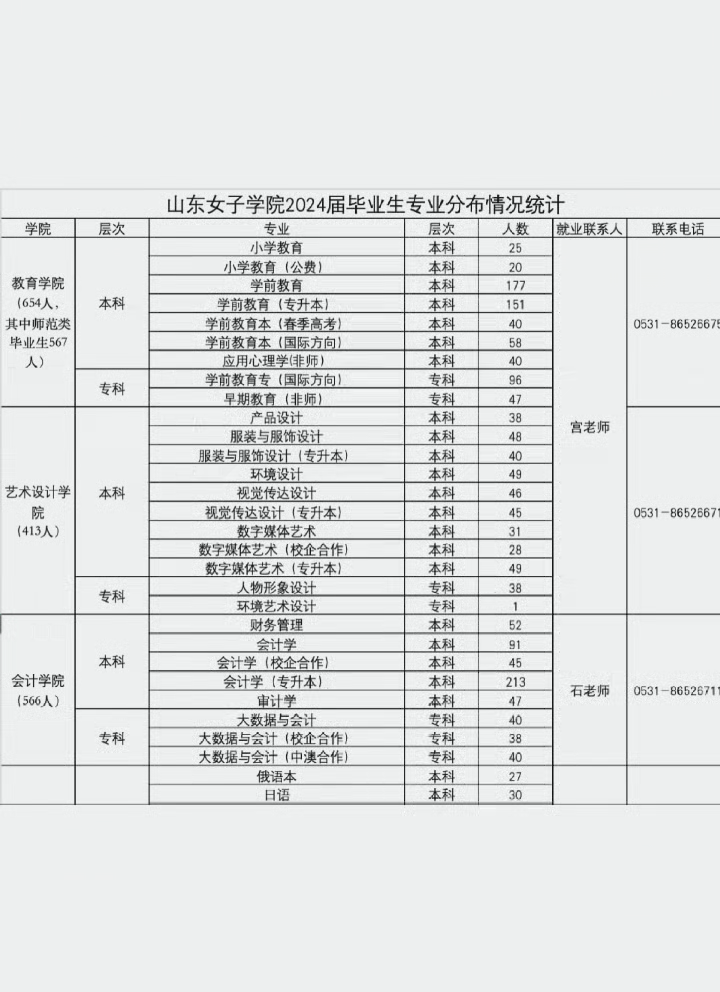
面对这样的挑战,传统的表格处理工具往往力不从心。研究发现,现有的大模型以及表格理解领域模型在 NL2SQL / 结构化表格已经有了较好的效果(准确率超 80%),但是在那些诸如金融报表、库存表、企业管理表等具有合并单元格、嵌套表格、层次结构等特征的复杂半结构化表格上表现明显退化。
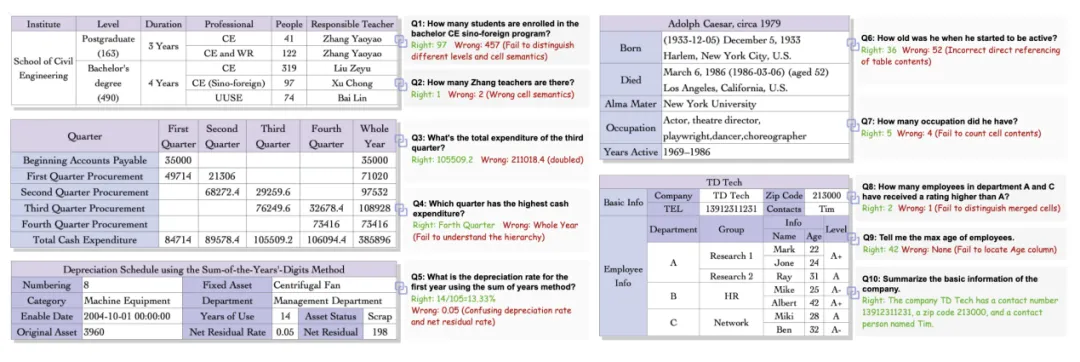
为了解决这一痛点,来自上海交通大学计算机学院、西蒙菲莎大学、清华大学、中国人民大学的合作团队,带来基于树形框架的智能表格问答系统(ST-Raptor),其不仅能精准捕捉表格中的复杂布局,还能自动生成表格操作指令,并一步步执行这些操作流程,最终准确回答用户提出的问题 —— 就像给 Excel 装上了一个会思考的 “AI 大脑”。
目前,该论文已被数据库领域国际顶尖学术会议 ACM SIGMOD 2026 接收。
论文标题:ST-Raptor: LLM-Powered Semi-Structured Table Question Answering
论文链接:https://arxiv.org/abs/2508.18190
项目仓库:https://github.com/weAIDB/ST-Raptor
该项目发布后得到广泛关注与转发:

现有的 NL2SQL 方法需要将半结构化表格转换为结构化表格处理,这通常会导致大量的信息丢失。此外,现有的 NL2Code 和多模态 LLM 问答都无法准确捕捉半结构化表格独特的信息组织方法,因此无法准确回答相应的问题。下图展示了一些基线方法在半结构化表格问答上的表现。在总共 100 个问题的回答中,大模型的错误率均较高,且其在涉及到表格结构理解,数据获取,问题推理三方面表现均不佳。
准确率低的原因主要由于以下几点:(1)半结构化表格结构个性化程度高,结构复杂多样且隐含了部分语义信息,大模型难以捕捉到布局的微妙之处。(2)在进行表格数据检索时,模型容易产生幻觉,造成失真。(3)模型对问题的理解能力不足,不能从表格里获取解决问题需要的信息。
HO-Tree
创新性的半结构化表格表示方案
为了定制解决半结构化表格信息的复杂分布问题,本文提出了层次正交树(HO-Tree)这一数据结构。HO-Tree 由 Meta Tree(MTree)和 Body Tree(BTree)嵌套组合形成,其中 MTree 代表了表头中的元数据,BTree 代表了表内容中的信息数据。
上图展示了构建 HO-Tree 的基本步骤。对于一个 excel 表格,首先将表内容转化为 HTML 格式并渲染,接着用 VLM 提取图片中的表头信息,在对齐后得到元信息组。接着,根据得到的元信息将表格进行分层级的区域划分,最后根据这一层级得到 HO-Tree。通过这一步骤,半结构化表格被转化为了计算机易于操作的数据形式,为后续处理提供了便利。
树上操作与流程设计
精准回答问题的 “手术刀”
在建构好 HO-Tree 之后,本文继续设计了一套在树上进行检索的操作,通过迭代地使用这些操作,LLM 可以按步骤分析表格,最终获取信息回答问题。这些操作可以分为以下四类:
- 数据获取操作:可以获取树上子节点,父节点等信息,递归地进行数据获取操作可以有效去除冗余信息,得到回答问题所必要的信息。
- 数据处理操作:根据问题需要的形式,将得到的数据进行处理(如求和,计数,按条件筛选等)。
- 对齐操作:将过程中的信息和表格内容进行对齐,增强检索时的健壮性。
- 推理操作:将获取的最终答案和问题进行对齐,得到满足格式要求的最终答案输出。
这些操作可以帮助 LLM 以直观的方法获取数据,分析表格,并且以可信的方式得到最终答案。结合这些操作,可以搭建一套流水线回答问题。如下图例子所示,在得到问题后,ST-Raptor 将其拆解为三个子问题,通过预定义的树上操作进行搜索,处理,最后经过推理得到答案。
实验结论
现有的表格数据集大多以结构化为主,一些半结构化的数据集也都并不涉及复杂嵌套关系,和真实情境不符。因此,本文构建了一个半结构化表格数据集 SSTQA,共有 102 张复杂的真实情境表格和 764 个针对这些表格的问题,总共包含了 19 个代表性的真实场景。如下图所示,在 SSTQA 上,ST-Raptor 相较其余方法而言,取得了很高的准确率提升,尤其是在结构复杂困难的表格上远超其余方法。
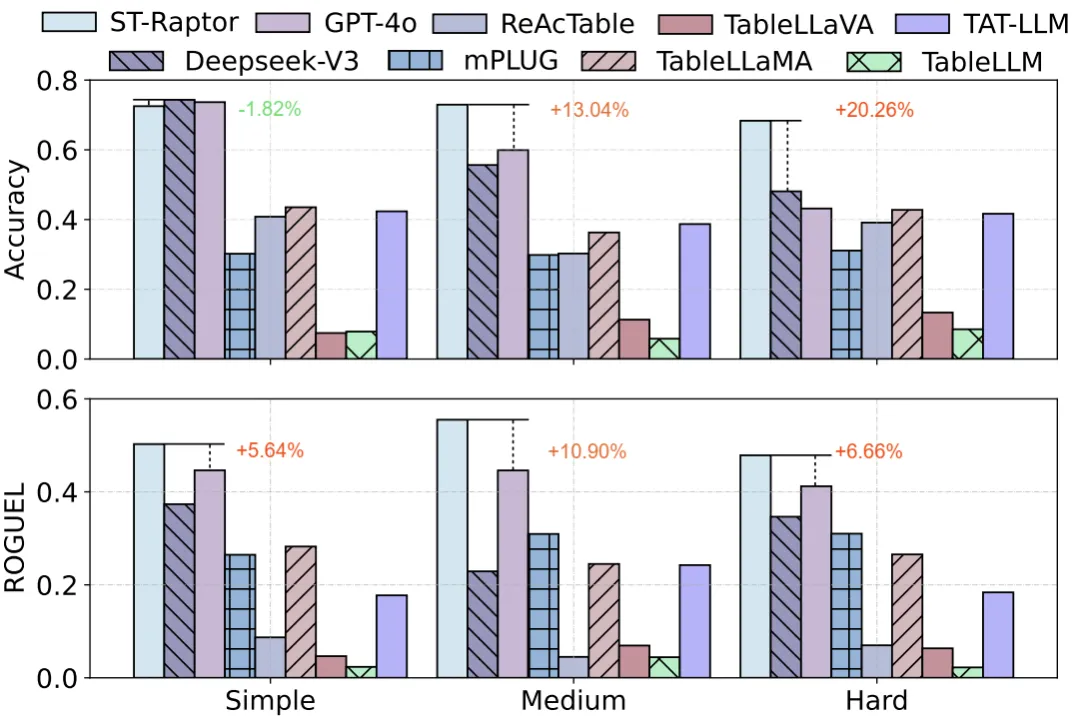
在其余两个半结构化表格问题数据集 WikiTQ 和 TempTabQA 上的测试结果如下表所示,ST-Raptor 准确率位于榜首,展现出了优秀的泛化能力。
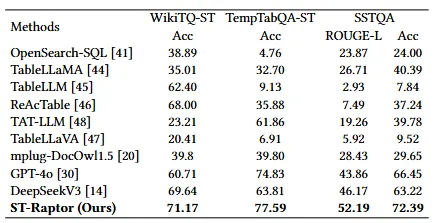
综上所述,ST-Raptor 提供了一套行之有效的半结构化表格问答解决方案,为现实生活中的半结构化表格自动化处理提供了新思路。通过挂载 ST-Raptor,LLM 可以增加对半结构化表格的理解能力和分析能力,提升表格问答的准确性。在未来,可以优化 HO-Tree 的表示和创建,使其囊括更多复杂表格;同时可以定制更多树上操作,使问题回答更流畅便捷。
ST-Raptor 立足于表格结构解析这一核心挑战,有效弥补了大语言模型在处理二维表格结构时的能力短板,能够直接支持包括 Excel 在内的多种复杂半结构化表格输入。尽管如此,现实场景中的半结构化表格仍普遍存在格式不规范、布局多样、语义歧义以及跨表关联等复杂问题,值得在模型架构、语义理解与泛化能力等方面展开长期而深入的探索。
.....
#0用户0产品估值850亿
ChatGPT之母&翁荔团队发布首个AI成果:真凶就是Batch
由前OpenAI CTO Mira Murati创立的Thinking Machines Lab首次发声,他们发布的DanceGRPO技术为LLM推理中的不确定性问题提供了解决方案。这项技术通过确保模型在面对相同输入时始终产生一致的输出,为强化学习等高级AI技术的发展铺平了道路。
家人们,你敢信吗?
一家成立仅半年,0 产品、0 用户的初创公司,估值已经飙到了 120 亿美元(约合人民币 850 亿)!
你没听错,数字是真的,事儿也是真的。这家公司,就是由前 OpenAI CTO、被誉为“ChatGPT 之母”的 Mira Murati 创办的——Thinking Machines Lab(TML)。
今天这个神秘的“天价”团队,终于打响了它的第一枪,Mira Murati 亲自在推特官宣,发布了公司的第一篇博客文章——
《Defeating Nondeterminism in LLM Inference》
中译:《克服 LLM 推理中的不确定性》

博客链接:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/

这篇博客是公司的新栏目 “Connectionism”(连接主义) 的首秀,TML 公司表示他们将频繁分享研究与代码:
要做真正的 Open 的 AI 呗,在阴阳谁我不说 ~
TML 联合创始人&著名技术博主 Lilian Weng 翁荔(也是 OpenAI 前研究与安全副总裁 VP) 随后转推,暗示了“Connection Machine”的存在。
(不知道这会不会是他们未来产品的名字!)
而这篇开山之作文章的核心作者,正是刚从 Meta 离职的 PyTorch 核心开发者 Horace He。

他要挑战的,正是那个让无数开发者头疼的难题:为什么与大模型的对话,总像在“开盲盒”?
问题定位
但是理论上,所有开发者都知道的另一个事实,就是将温度系数(temperature)设为零,彻底关掉随机性。而这时的输出,本应像“1+1=2”一样,是绝对稳定可预测的。
它还是会变。
这个“通病”让模型评测变得困难,让调试过程如同噩梦,更让那些需要绝对确定性的下游应用(如强化学习、代码生成)也很头疼。
在此之前,社区有一个广为流传的关于这个“通病”的主流假说—“并发 + 浮点”理论。
懂计算机 float 运算的小伙伴,这其实很好理解。
第一,是浮点计算的非结合性导致的,由于计算机存在舍入误差,数学上 (a+b)+c = a+(b+c) 的绝对相等,在浮点数世界里会变成约等,而计算顺序的改变,会带来结果上“位级别”的微小差异。

第二,是GPU并行计算决定的:为了追求极致速度,GPU 会同时派出成百上千个核心(kernel)去执行求和等归约操作。谁先算完、谁后算完,这个计算的顺序在每次运行时都是不可预测的。

当上面这两个随机不可控撞在一起,偏差就出现了。
这一点点偏差,就足以让模型在某个关键的“岔路口”做出不同选择,从而生成不同的输出结果。
不过,Thinking Machines Lab 发布的《克服 LLM 推理中的不确定性》论文博客提出了质疑。
他们认为,问题不在“有没有并行/浮点”。
看看他们是怎么论证的?
首先研究团队做了一个简单的实验:
在 GPU 上,反复对相同的数据做同一个 matmul (矩阵乘法),结果在位级别上是完全确定的。
如果之前主流假说成立,即并发计算必然导致随机性,那么这里也应该出现不一致。
研究团队另外提到,在典型的 LLM 前向传播中,为了性能与稳定性,所采用的底层计算内核(Kernels)已经主动避免了使用那些会引入 running-time 不确定性的技术,例如跨线程块的原子加法。
原子加法操作虽然能保证并发计算结果的完整性,但硬件并不保证这些计算的累加顺序。这种顺序的随机性是“原子操作”与生俱来的特性,一旦算法依赖它,几乎必然会导致非确定性。

但是,目前 LLM 前向传播的核心环节(如矩阵乘法、层归一化)并不涉及这类原子操作。
这意味着,LLM 的前向过程本质上是 running-time 确定的,即对于固定的输入,无论运行多少次,它都会产生完全相同的位级别输出。
所以 TML 的研究团队,认为不确定性来自什么时候归约顺序会被改写。
所以论文将矛头指向了一个更高阶的系统设计缺陷:批次不变性 (Batch Invariance) 的缺失。
“批次不变性”是指:
一个数据样本的计算结果,不应受到其所在处理批次(batch)的大小或批次中其他样本内容的影响。
那通俗地说:
你向 AI 提问,得到的结果,理论上不应该因为和你一同被处理的还有 3 个人还是 30 个人(即批次大小)而有所不同。
但在现实的推理服务器上,正是推理 inference 阶段的存在的问题,为了效率这个原则被打破了:
- 服务器负载是随机的,你永远不知道在你提问的那一刻,服务器上还有多少并发请求。
- 动态批处理,为了让 GPU 不“挨饿”,服务器会把短时间内收到的多个请求“打包”成一个批次(Batch)再处理。
- 批次大小(Batch Size)变得随机,你的请求这次可能被分入一个大小为 4 的批次,下次可能是大小为 16 的批次。
- 计算策略为性能而动态切换,底层的计算内核(Kernel)为了在任何批次大小下都跑出最快速度,被设计得极其“智能”:它会根据批次大小,动态选择最优的计算策略。
解决问题
定位到问题后,研究团队认为解决方案也就清晰了:
强制计算内核(Kernels)使用固定的策略,牺牲一部分针对特定情况的极致性能优化,以换取计算路径的绝对一致性。
论文展示了如何对 Transformer 模型的三个核心模组进行改造:
RMSNorm
RMSNorm 的改造相对直接,它的标准并行化策略是“数据并行”,即为批次中的每个序列(sequence)分配一个 GPU 的计算单元(线程块/SM)。这种策略在批次较大时(例如,批次大小超过 GPU 核心数)效率很高。但当批次很小时,大量计算单元会处于空闲状态,造成严重的性能浪费。
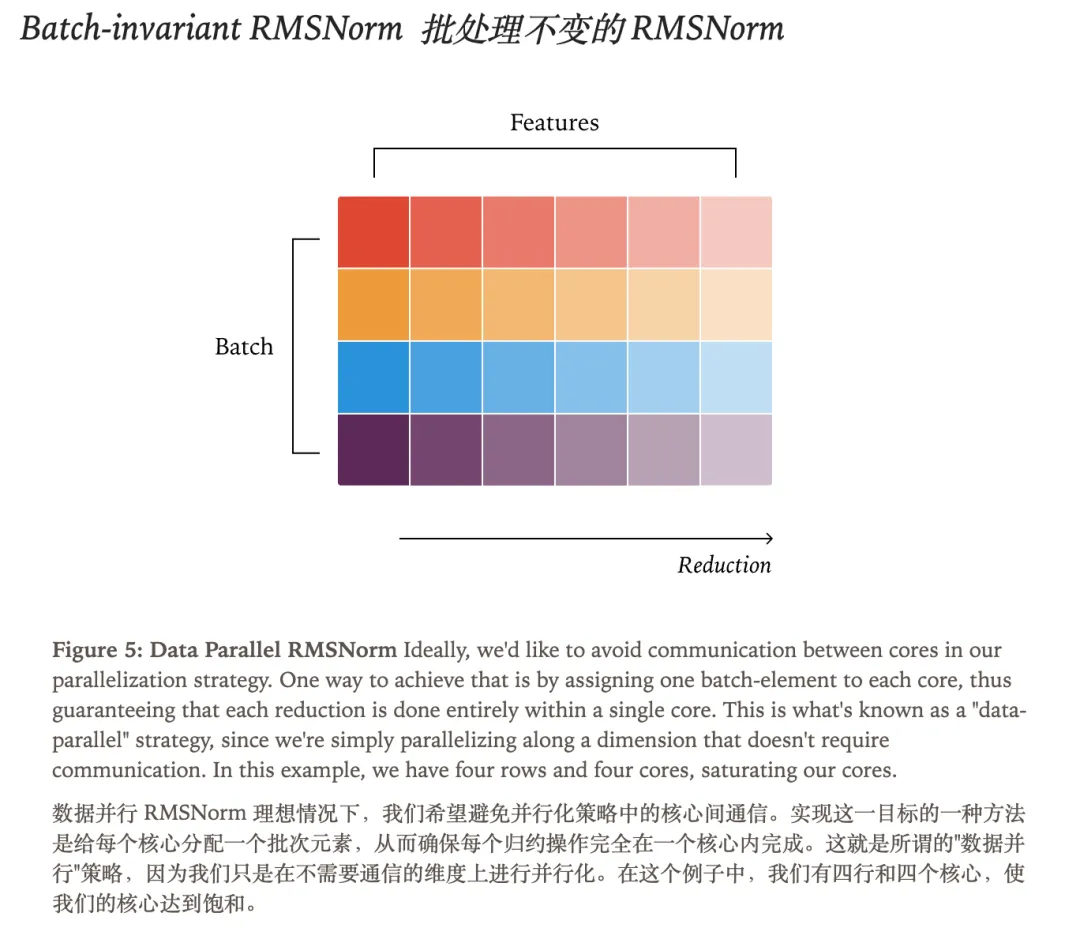
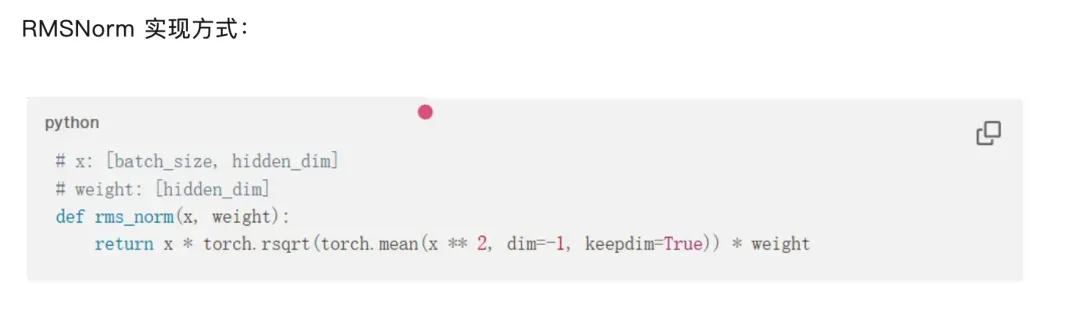
为了解决小批次下的效率问题,高性能计算内核会采取一种“自适应”策略:它会动态检测到核心空闲,并立刻改变并行模式,不再一个核心处理一个序列,而是用多个核心协同处理一个序列。
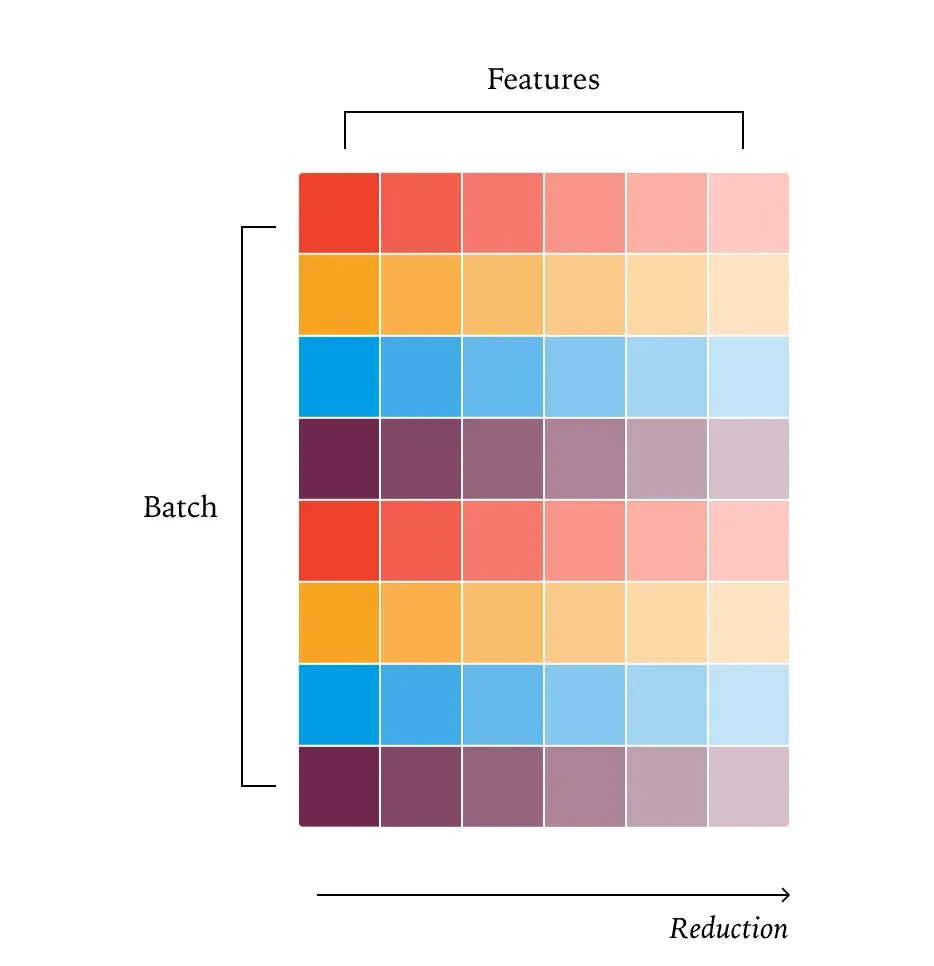
这种“分裂式规约”为了合并结果,引入了额外的跨核心通信和求和步骤,彻底改变了原始的计算顺序,从而破坏了批次不变性。
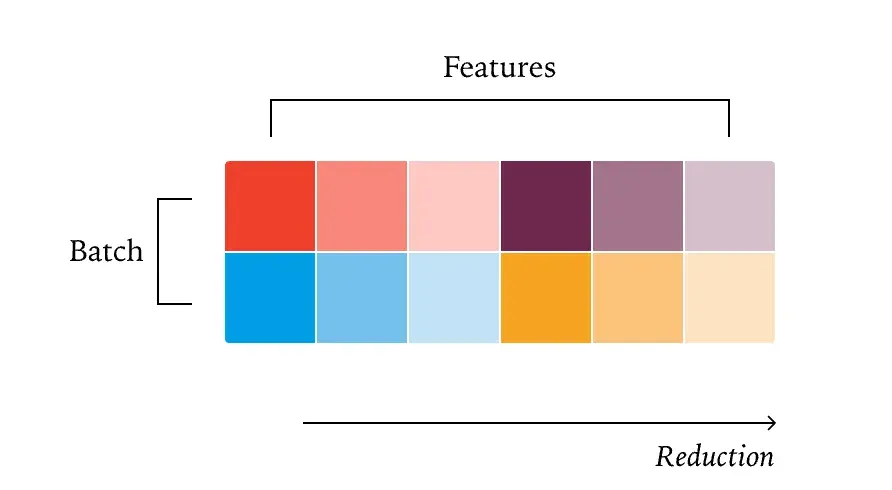
最直接的解决方案就是禁用这种自适应并行策略,开发者必须选择并固定一种对所有批次大小都适用的归约策略。
矩阵乘法
矩阵乘法(Matmul)的非不变性来源更为复杂:
- Split-K 策略: 与 RMSNorm 类似,对于某些矩阵形状(特别是当批次维度 M 和 N 较小,而需要累加的 K 维度较大时),为了创造更多并行任务让 GPU“忙起来”,一种常见的优化是“Split-K”。它将 K 维度切分成多块,分配给不同核心并行计算,最后再将各部分结果相加。这种“先分后总”的模式,从根本上改变了加法顺序。
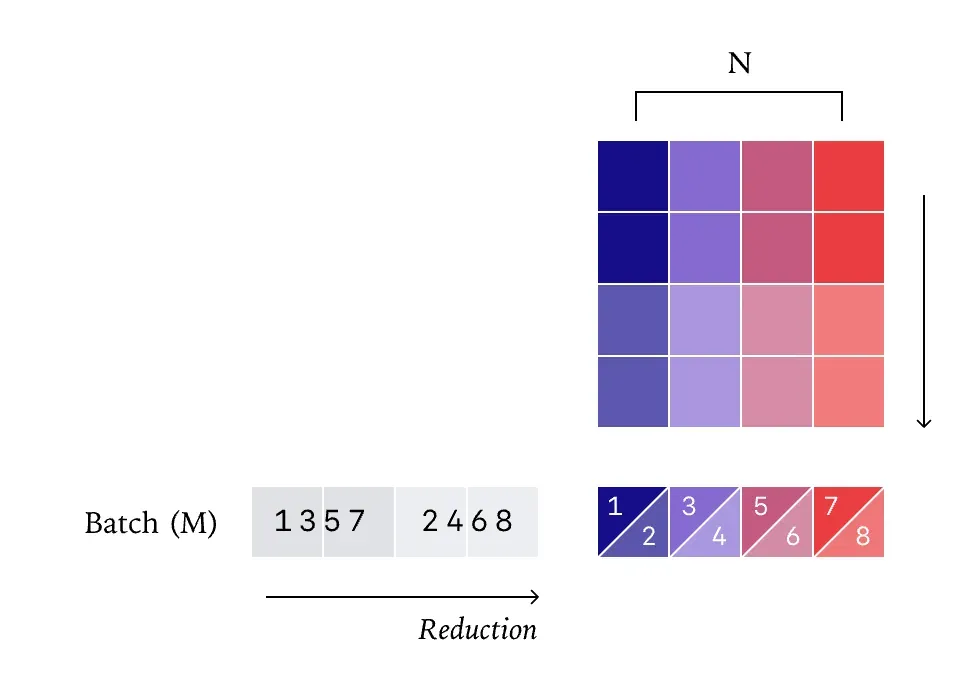
- 张量核心指令的动态选择: 现代 GPU 库中,包含一个庞大的、针对不同硬件和数据类型高度优化的计算函数库。在运行时,一个“启发式调度器”会根据输入张量的具体形状,动态地选择一个它认为最快的函数实现。批次大小的微小改变,就可能导致调度器选择一个完全不同的底层函数,而不同函数的内部计算顺序可能天差地别。
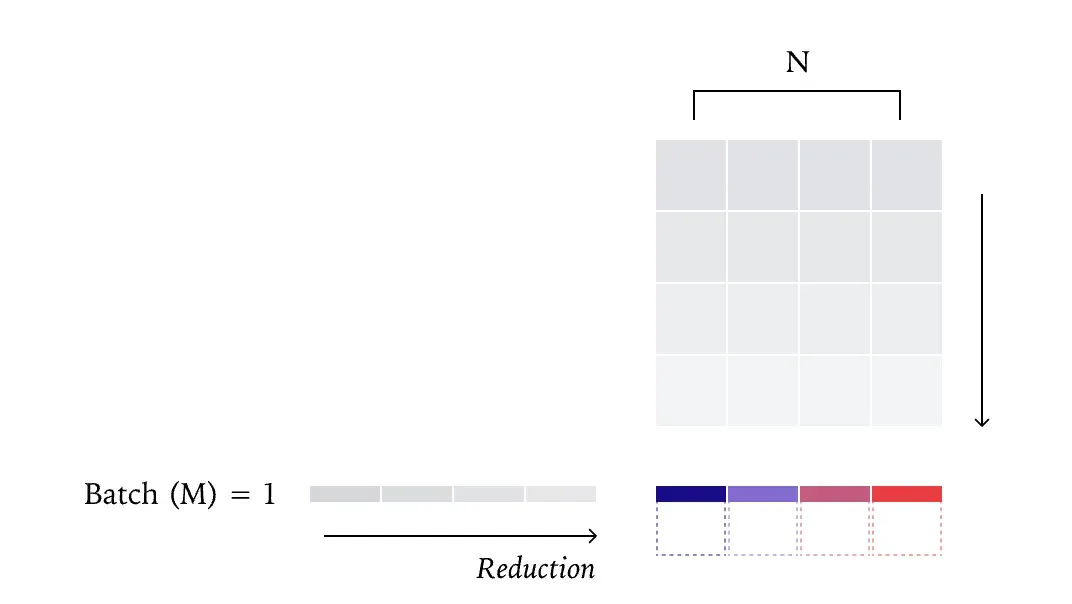
解决方案是放弃这种动态调度和优化。
开发者为模型中遇到的所有矩阵乘法形状,编译并指定一个固定的计算内核配置(固定的 tile 大小、固定的并行策略,并明确禁用 Split-K)。
这牺牲了针对特定形状的极致性能优化,以换取一条稳定不变的计算路径。但是幸运的是,在 LLM 推理场景下,模型维度通常很大,禁用 Split-K 等优化的性能损失通常在可接受范围内。
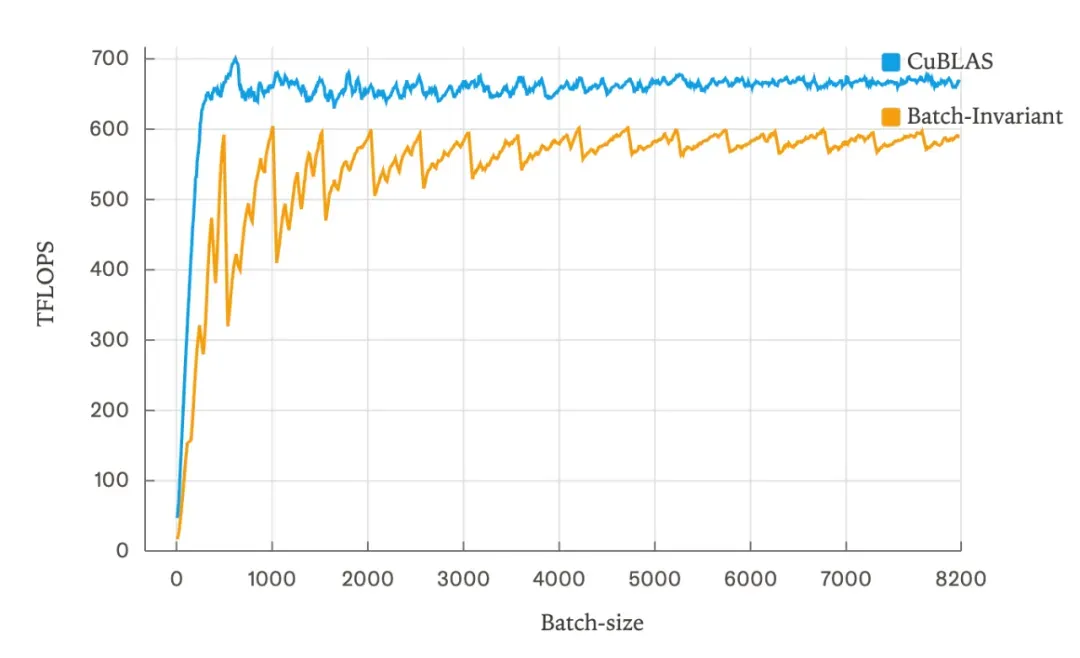
注意力机制
注意力机制的确定性改造更困难,因为它引入了全新的复杂维度:
- 跨序列维度归约: 注意力的核心是计算查询(Query)与键(Key)的点积,这涉及在序列长度维度上的归约,而序列长度本身是动态变化的。
- 与推理优化的深度耦合: 在 vLLM 等现代推理引擎中,为了高效管理内存,使用了分页 KV 缓存(Paged KV Cache)等复杂技术,注意力计算必须与这些动态变化的内存布局进行交互。
因此研究团队希望的是,对于任意一个给定的查询 token,无论它是在预填充阶段与数百个其他 token 一同处理,还是在解码阶段单独处理,其最终的注意力计算结果必须完全相同。
于是,研究团队提出了一个两阶段的确定性解决方案:
- 确保一致的内存布局: 在调用注意力计算函数之前,推理引擎必须先更新 KV 缓存和相应的页表,确保无论处理上下文如何(预填充或解码),键(Key)和值(Value)张量在内存中的布局都是一致的。这从源头上消除了因内存访问模式不同而引入的差异。
- 针对 Split-KV 的“固定拆分大小”策略: 在解码阶段,查询长度通常为 1,此时为了保持 GPU 繁忙,几乎必须沿 KV 序列长度维度进行并行化(即“Split-KV”)。
传统做法(非确定性):根据当前批次的总工作量,动态地将 KV 序列切分成最合适的块数,以期最大化并行度。这种做法使得切分方式依赖于批次大小,从而破坏了不变性。
而论文提出的是新做法是采用“固定拆分大小”(fixed split-size)策略,不再固定切分的数量,而是固定每个切分块的大小(例如,固定为 256 个 token)。
一个长度为 1000 的 KV 序列,将被确定性地切分为 3 个大小为 256 的块和 1 个大小为 232 的块,确保归约的结构完全独立于批次中的其他请求,从而完美地保持了批次不变性。
实验论证
论文设计了一系列实验,极其直观地展示了其解决方案的有效性,并量化了实现确定性所需付出的代价。
生成结果对比
为了让读者直观感受“非确定性”的严重程度,研究团队进行了一项生成实验。实验场景: 使用 Qwen 模型,将 temperature 设为 0,对提示词“Tell me about Richard Feynman”进行 1000 次采样。测试模型:
- 标准 vLLM(非确定性):1000 次运行,竟产生了 80 个不同的输出版本。大部分(992 次)结果在前 102 个词元后生成了“Queens, New York”,而少数(8 次)结果则生成了“New York City”。这清晰地表明,差异并非随机噪声,而是由系统非不变性触发的、微小但具有决定性的计算路径分叉。
- 确定性 vLLM(改造后): 全部 1000 次采样,生成了完全相同、逐位一致的唯一结果。
性能代价
那换取这种 100% 的可靠性,代价是什么?
研究团队设置了一个 API 服务器,其中一台 GPU 运行 Qwen-3-8B,并请求 1000 个序列,输出长度在 90 到 110 之间。
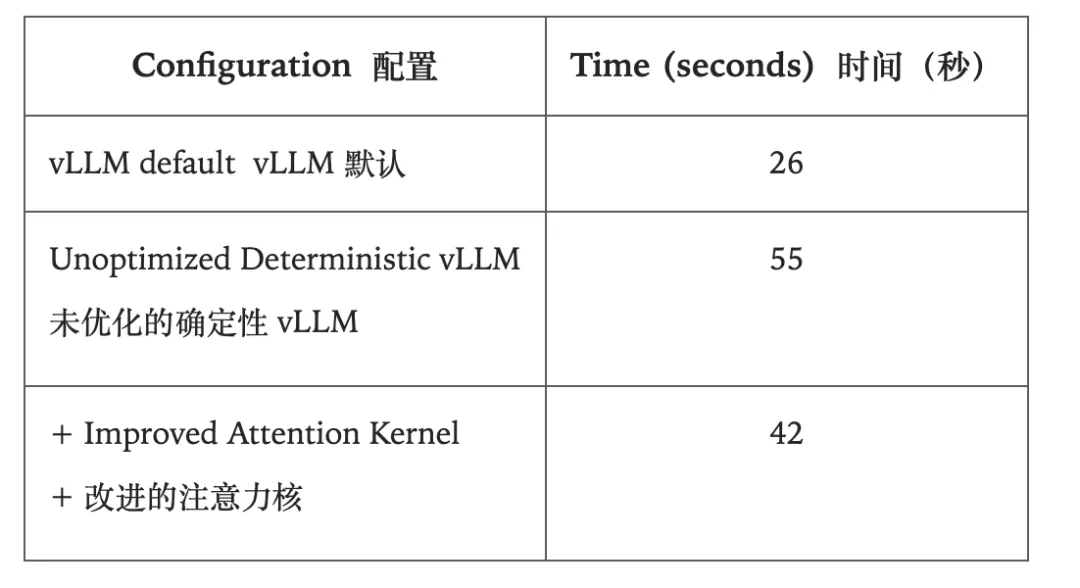
结果发现:通过牺牲约 13.5% 的峰值吞吐量,可以换来 100% 的生成结果可复现性。
结语
Thinking Machines Lab 的这篇文章,可以是一次系统工程探索。
一句话总结这篇技术博客的核心意思:在固定 kernel 配置下,许多算子/库是运行到运行可复现的;真正让线上端点“同样输入 → 不同输出”的主因是端点负载变化 → 批量大小变化 →(非批次不变的)内核改变归约顺序。
它的价值有两点的:
在应用层面,它为强化学习等高级 AI 技术的发展清除了一块危险的基石,换上了一块稳固的基石;
在理念层面,它在这个日益追求“大力出奇迹”的 AI 时代,高声呼唤着工程严谨性的回归。作为这支复仇者联盟首次公开的技术亮相,不仅充分证明了团队能力,更彰显了他们的雄心:他们不只想现在的棋盘上多落一子,他们想的是重新定义棋盘的规则!
系统的可预测性与绝对可靠性,必须优先于对峰值性能的极致追求。一个无法保证 100% 一致性的系统,其基础是不牢固的。
.....
#姚顺雨离职OpenAI
「亿元入职腾讯」传闻引爆AI圈,鹅厂辟谣了
姚顺雨加入腾讯了?已被辟谣。
昨天,有消息称,OpenAI 著名研究者、清华校友、著名博客《AI 下半场》的作者姚顺雨已经加入了腾讯混元大模型团队,并且还传言说他将在这里组建一支自己领导的研究团队。
这一消息瞬间点燃了 AI 社区,「年薪 1 亿」的传闻更是让话题迅速升温。
相关的内容也是越传越全面,根据小红书用户 @Top华人科创社区 的贴文,有网友透露,姚顺雨上周已经来腾讯开会了。
不过,今早鹅厂黑板报已正式辟谣,否认了相关说法。但也有网友追问:辟谣的是「没加入」,还是「没有上亿薪酬」?

不过谣言也并非空穴来风,据多个信息源表示,姚顺雨确已从 OpenAI 离职。
如今 AI 人才争夺战确实日趋激烈。海外,Meta 的扎克伯格高调抛出「上亿年薪」挖角各个公司的顶尖研究员;国内,各大厂同样全力加码,力求稳住核心团队。可以预见,类似的风声还会不断出现。
从清华学霸到 OpenAI
姚顺雨,毕业于清华姚班,普林斯顿大学计算机科学博士,2024 年 8 月加入 OpenAI。
在加入 OpenAI 之前,他就已经在语言智能体领域做出了一系列开创性的工作:
- 使 AI 通过多路径推理解决复杂问题的 ToT(思维树);
- 让 AI 在推理中动态行动的 ReAct;
- 为 AI 智能体提供模块化的认知架构的 CoALA。
此外,他还参与构建了著名软件工程基准 SWE-Bench 和模拟电子商务网站环境 WebShop,推动了 AI 智能体的发展。截至目前,姚顺雨的论文总引用量已经超过了 1.5 万。
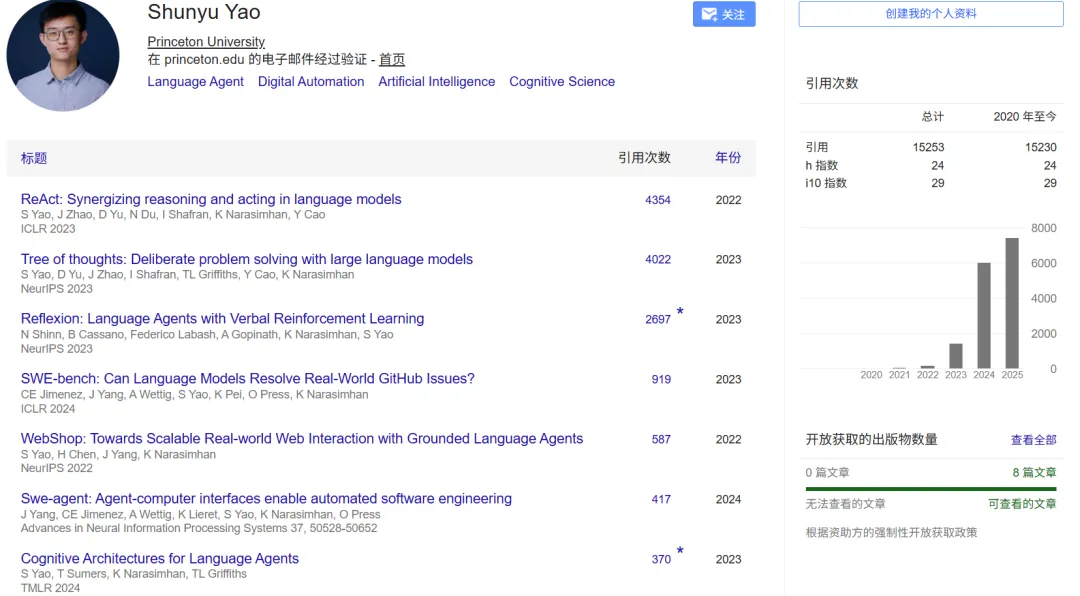
姚顺雨于 2024 年 8 月加入 OpenAI,至今已有 1 年 4 个月,目前他的领英主页尚未更新。
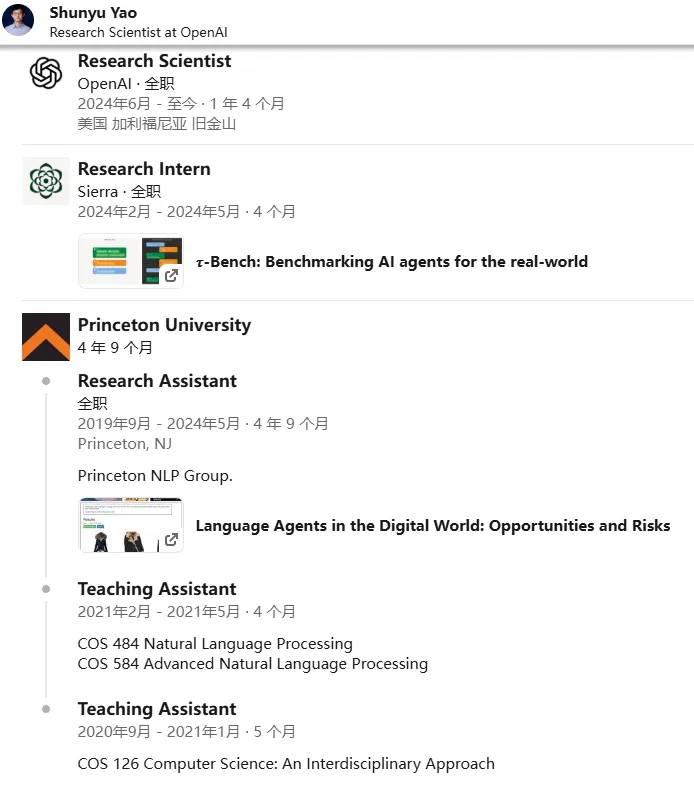
在 OpenAI 期间,他担任研究科学家,专注于将大型语言模型从理论研究推向实际应用,特别是 AI Agent 的开发。
他主导开发了 OpenAI 首个发布的智能体模型及产品,Computer-Using Agent (CUA),致力于创建与数字世界交互的通用 AI 智能体。同时,他参与了 Deep Research 项目。
事实上,早在 GPT-2 刚兴起时,他就预见了语言模型的潜力,率先研究如何将其转化为「会思考的 Agent」,展现了惊人的学术前瞻性。
作为内部研究负责人,他推动了 OpenAI 与 Jony Ive(前苹果首席设计师)及其公司 LoveFrom/IO 的战略合作。该合作旨在探索无屏幕、上下文感知的新型 AI 硬件设备,他已领导相关研究工作近一年。
整体而言,姚顺雨在 OpenAI 的工作继承并扩展了他在普林斯顿大学博士期间(如 ReAct、Tree of Thoughts)的研究,致力于推动 AI 在真实数字世界中的自动化与应用。
今年 4 月,姚顺雨发表的博客文章《The Second Half》,提出了「AI 下半场」的概念,被广泛认为是 AI 研究范式转折的标志性论述,其核心理论是 AI 领域正在从「训练更强的模型」转向「定义和评估真正有用的任务」。
他写道:「我认为我们应该从根本上重新思考评估。这不仅意味着创造新的和更难的基准测试,而是从根本上质疑现有的评估设置并创造新的,这样我们就会被迫发明超越现有方案的新方法。」
2024 年,27 岁的姚顺雨入选《麻省理工科技评论》「35 岁以下科技创新 35 人」中国区榜单,成为该届最年轻入选者。

图源:https://tr35.mittrchina.com/annual-winner?title=2024
除科研外,他还是清华大学学生说唱社联合创始人、姚班联席会主席。
这位年轻的研究科学家之后又将给我们带来怎样的新惊喜?值得期待。
....
#Qwen3-Next
全新MoE架构!阿里开源,训练成本直降9成
训练、推理性价比创新高。
大语言模型(LLM),正在进入 Next Level。
周五凌晨,阿里通义团队正式发布、开源了下一代基础模型架构 Qwen3-Next。总参数 80B 的模型仅激活 3B ,性能就可媲美千问 3 旗舰版 235B 模型,也超越了 Gemini-2.5-Flash-Thinking,实现了模型计算效率的重大突破。

新模型立即在 Qwen.ai 上线,并上传了 HuggingFace。
- 新模型网页版:https://chat.qwen.ai/
- HuggingFace:https://huggingface.co/collections/Qwen/qwen3-next-68c25fd6838e585db8eeea9d
- Kaggle:https://www.kaggle.com/models/qwen-lm/qwen3-next-80b
Qwen3-Next 针对大模型在上下文长度扩展(Context Length Scaling)和参数量扩展(Total Parameter Scaling)的未来趋势而设计。通义团队表示,其模型结构相较 4 月底推出的 Qwen3 的 MoE 模型新增了多种技术并进行了核心改进,包括混合注意力机制、高稀疏度 MoE 结构、一系列提升训练稳定性的优化,以及提升推理效率的多 token 预测(MTP)机制等。
模型结构示意图:
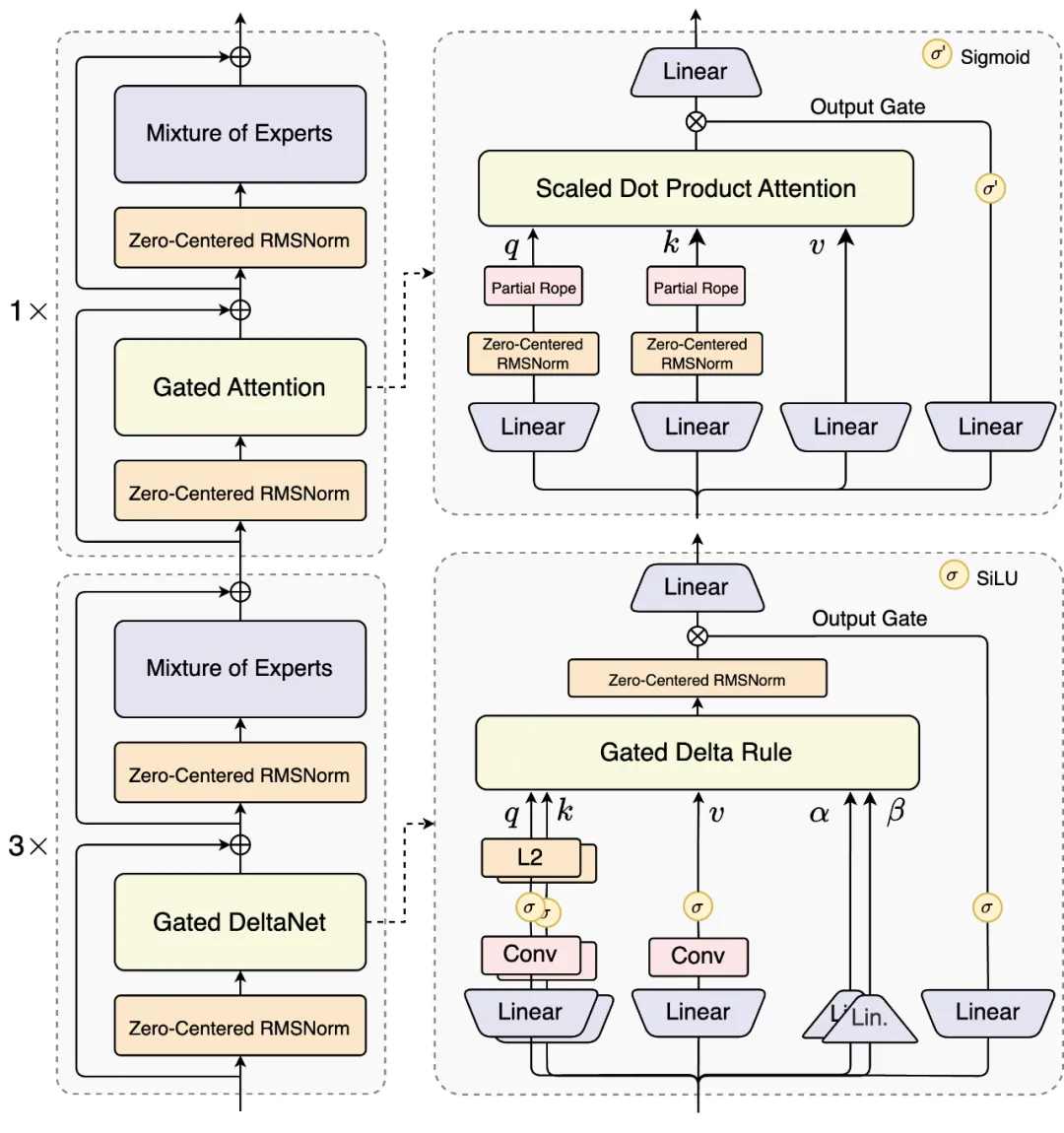
通义团队介绍了新架构使用的一些机制。
- 混合架构:Gated DeltaNet + Gated Attention
线性注意力打破了标准注意力的二次复杂度,在处理长上下文时有着更高的效率。通义团队发现,单纯使用线性注意力或标准注意力均存在局限:前者在长序列建模上效率高但召回能力弱,后者计算开销大、推理不友好。
通过系统实验,人们发现 Gated DeltaNet 相比常用的滑动窗口注意力(Sliding Window Attention)和 Mamba2 有更强的上下文学习(in-context learning)能力,并在 3:1 的混合比例(即 75% 层使用 Gated DeltaNet,25% 层保留标准注意力)下能一致超过超越单一架构,实现性能与效率的双重优化。
在保留的标准注意力中,通义进一步引入多项增强设计:
(1)沿用先前工作中的输出门控机制,缓解注意力中的低秩问题;
(2)将单个注意力头维度从 128 扩展至 256;
(3)仅对注意力头前 25% 的位置维度添加旋转位置编码,提高长度外推效果。
- 极致稀疏 MoE:仅激活 3.7% 参数
Qwen3-Next 采用了高稀疏度的 Mixture-of-Experts (MoE) 架构,总参数量达 80B,每次推理仅激活约 3B 参数。实验表明,在使用全局负载均衡后,当激活专家固定时,持续增加专家总参数可带来训练 loss 的稳定下降。
相比 Qwen3 MoE 的 128 个总专家和 8 个路由专家,Qwen3-Next 扩展到了 512 总专家,10 路由专家与 1 共享专家的组合,在不牺牲效果的前提下最大化资源利用率。
- 训练稳定性友好设计
通义团队发现, 注意力输出门控机制能消除注意力池与极大激活等现象,保证模型各部分的数值稳定。Qwen3 采用了 QK-Norm,部分层的 norm weight 值会出现异常高的情况。为缓解这一现象,进一步提高模型的稳定性,通义在 Qwen3-Next 中采用了 Zero-Centered RMSNorm,并在此基础上对 norm weight 施加 weight decay,以避免权重无界增长。
通义还在初始化时归一化了 MoE router 的参数,确保每个 expert 在训练早期都能被无偏地选中,减小初始化对实验结果的扰动。
- Multi-Token Prediction
Qwen3-Next 引入原生 Multi-Token Prediction (MTP) 机制,既得到了 Speculative Decoding 接受率较高的 MTP 模块,又提升了主干本身的综合性能。Qwen3-Next 还特别优化了 MTP 多步推理性能,通过训练推理一致的多步训练,进一步提高了实用场景下的 Speculative Decoding 接受率。
通义千问大模型负责人林俊旸在 X 上分享了新一代模型开发的细节。他表示团队已经在混合模型和线性注意力机制上进行了大约一年的实验。新的解决方案应该足够稳定可靠,能够应对超长上下文。
Gated DeltaNet 加混合是经过大量尝试和错误才实现的,而 Gated Attention 的实现就像是免费的午餐,可以获得额外好处。
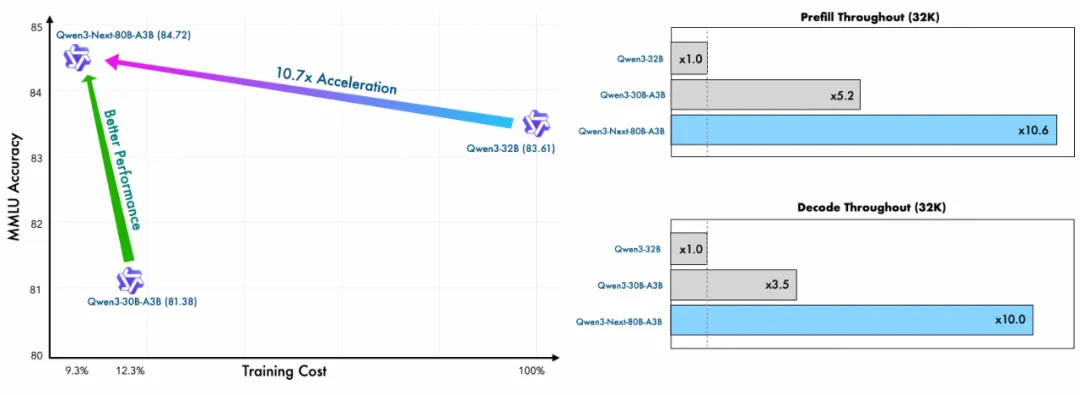
得益于创新的混合模型架构,Qwen3-Next 在推理效率方面表现出显著优势。与 Qwen3-32B 相比,Qwen3-Next-80B-A3B 在预填充(prefill)阶段展现出卓越的吞吐能力:在 4k tokens 的上下文长度下,吞吐量接近前者的七倍;当上下文长度超过 32k 时,吞吐提升更是达到十倍以上。
在解码(decode)阶段,该模型同样表现优异 —— 在 4k 上下文下实现近四倍的吞吐提升,而在超过 32k 的长上下文场景中,仍能保持十倍以上的吞吐优势。
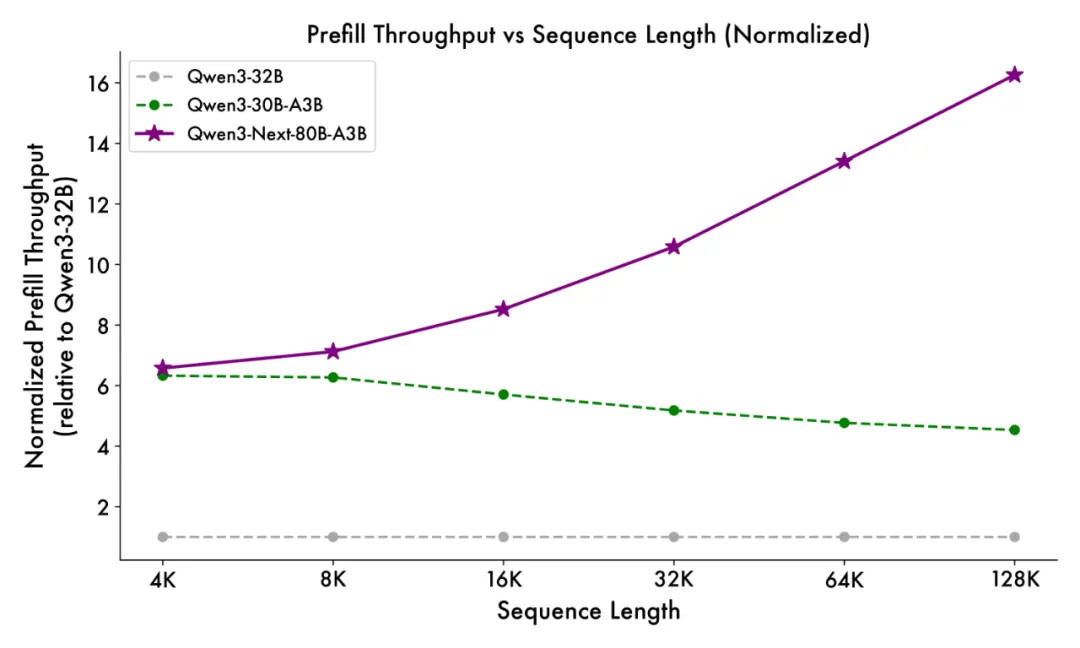
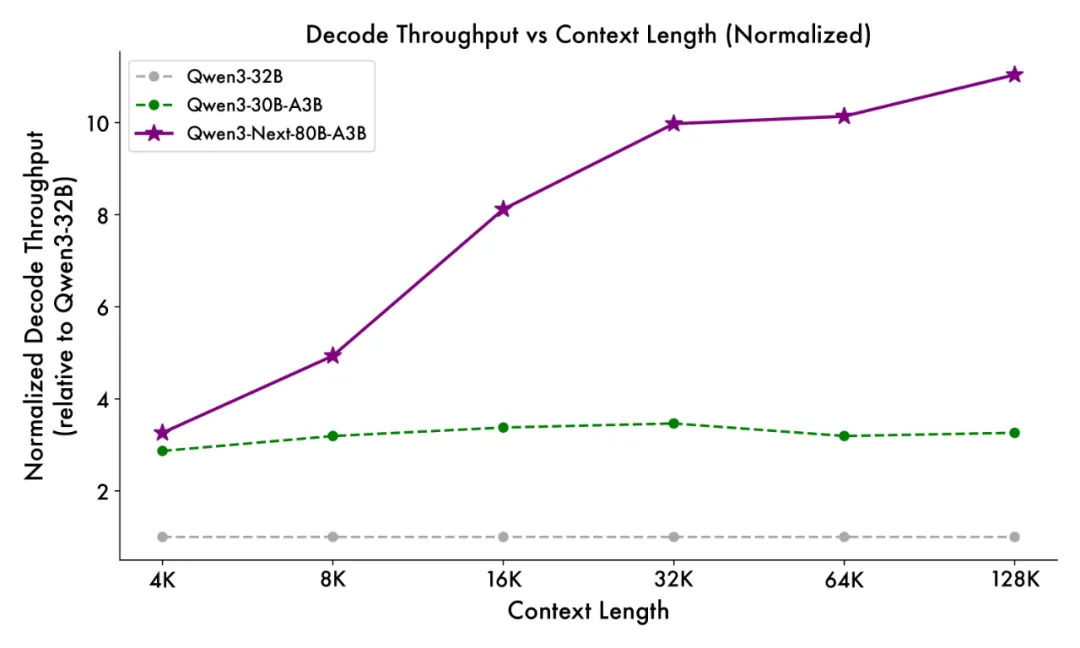
基于 Qwen3-Next 的模型结构,通义团队训练了 Qwen3-Next-80B-A3B-Base 模型,该模型拥有 800 亿参数(仅激活 30 亿参数),实现了与 Qwen3-32B dense 模型相近甚至略好的性能,同时训练成本(GPU hours) 仅为 Qwen3-32B 的十分之一不到,在 32k 以上的上下文下的推理吞吐则是 Qwen3-32B 的十倍以上,实现了极致的训练和推理性价比。
通义团队开源了 Qwen3-Next-80B-A3B 的指令(Insctruct)模型和推理(Thinking)两款模型。新模型解决了混合注意力机制 + 高稀疏度 MoE 架构在强化学习训练中长期存在的稳定性与效率难题,实现了 RL 训练效率与最终效果的双重提升。
在编程(LiveCodeBench v6)、人类偏好对齐 (Arena-Hard v2) 以及综合性能力 (LiveBench) 评测中,Qwen3-Next-Instruct 表现甚至超过了千问的开源旗舰模型,并在包含通用知识(SuperGPQA)、数学推理(AIME25)等核心测评中全面超越了 SOTA 密集模型 Qwen3-32B;Qwen3-Next-Thinking 则全面超越了 Gemini2.5-Flash-Thinking,在数学推理 AIME25 评测中获得了 87.8 分。而达到如此高水平的模型性能,仅需激活 Qwen3-Next 总参数 80B 中的 3B。

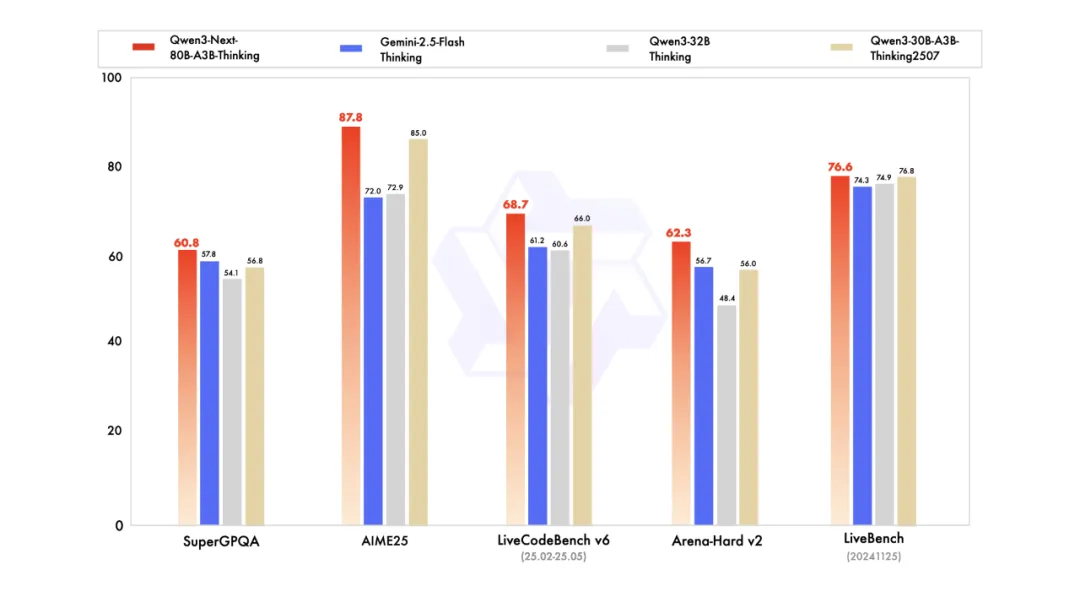
目前,Qwen3-Next 模型也已经在很多第三方平台中上线。
使用新模型在 anycoder 中的 vibe coding 示例:
....
#EviNote-RAG
告别错误累计与噪声干扰,EviNote-RAG 开启 RAG 新范式
本文第一作者戴语琴,清华大学博士生。该工作为戴语琴在蚂蚁大安全实习期间完成,该工作属于蚂蚁集团大安全 Venus 系列工作,致力于打造搜索智能体 / UI 智能体。本文通讯作者为该校副教授吕帅,研究方向包括大语言模型、多模态生成、AI4Design。共同通讯作者沈永亮,浙江大学百人计划研究员,博士生导师,研究方向包括大模型推理、RAG 检索增强生成、多模态生成模型等。
在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
低信噪比让关键信息淹没在冗余文档里,错误累计则让推理链像骨牌一样层层坍塌。这两大顽疾,使得现有 RAG 系统在复杂任务中难以真正可靠。
近期,一项由蚂蚁集团、清华大学、浙江大学、MIT、UC Berkeley、香港大学和新加坡国立大学等机构联合完成的研究提出了全新方案——EviNote-RAG。它不仅在多个权威基准上实现了显著性能提升,更在训练稳定性与推理可靠性上带来了质的飞跃。
核心秘诀在于两个创新:
- 支持性证据笔记(Supportive-Evidence Notes, SEN):像人类一样「先做笔记」,用结构化方式过滤噪声、标记不确定信息。
- 证据质量奖励(Evidence Quality Reward, EQR):通过逻辑蕴含监督,确保笔记真正支撑答案,避免浅层匹配和错误累积。
这一组合带来的改变是革命性的:训练曲线不再震荡,答案推理更加稳健。消融与补充实验进一步验证了这一点——SEN 是性能提升的基石,而 EQR 则是质量提升的关键。两者相辅相成,使 EviNote-RAG 成为当前最稳定、最可信赖的 RAG 框架之一。
换句话说,EviNote-RAG 不仅解决了性能问题,更为复杂推理场景下的检索增强开辟了一条全新的发展路径。
在多个开放域问答基准上,EviNote-RAG 取得了显著突破:
- 在 HotpotQA 上相对提升 20%(+0.093 F1 score),
- 在 Bamboogle 上相对提升 40%(+0.151 F1 score),
- 在 2Wiki 上相对提升 91%(+0.256 F1 score),不仅刷新了当前最优表现,还表现出更强的泛化能力与训练稳定性。
- 论文标题:EviNote-RAG: Enhancing RAG Models via Answer-Supportive Evidence Notes
- 论文地址:https://arxiv.org/abs/2509.00877v1
- Github 地址:https://github.com/Dalyuqin/EviNoteRAG
研究背景与动机
在如今这个信息爆炸的时代,检索增强生成(RAG)技术已经成为大型语言模型(LLM)在开放问答(QA)任务中的得力助手。通过引入外部知识,RAG 能够有效提升回答的准确性和时效性。
但一个现实问题是:LLM 的知识固定在训练时刻,容易输出过时甚至错误的信息。于是,检索增强生成(RAG)被提出:在问答时,从外部知识库中检索最新信息,辅助模型生成更准确的答案。然而,现有 RAG 系统依然存在两个核心痛点:
- 低信噪比。在开放域检索场景中,真正与答案相关的证据信息往往稀缺且难以识别,大量无关或冗余内容充斥在检索结果中,导致模型在有限的上下文窗口里难以高效聚焦关键信息。
- 错误累计。当推理跨越不完整或噪声证据时,错误会在多跳链路中层层放大,最终严重削弱答案的准确性和稳定性。这一问题在多跳问答场景中尤为突出。
过去的研究尝试通过改进检索质量、引入重排序或摘要压缩、以及对特定语料进行监督微调来缓解上述问题。虽然这些方法在一定程度上降低了噪声、减轻了推理负担,但它们普遍依赖标注的信息提取数据或外部启发式规则,缺乏一种端到端、稳健且可泛化的解决路径。如何从根本上突破低信噪比与错误累计这两大瓶颈,成为推动 RAG 演进的核心动因。
因此,研究者提出了新的框架——EviNote-RAG。

EviNote-RAG 与传统方法的对比:EviNote-RAG 通过证据注释提取关键信息,并在蕴意法官的指导下,确保保留的内容直接支持答案,从而减少噪音并提高性能。
传统的「检索-回答」范式不同,EviNote-RAG 将流程重构为「检索-笔记-回答」的三阶段结构。
在这一框架中,模型首先生成 Supportive-Evidence Notes(SENs)——类似人类笔记的精简摘要,仅保留与答案相关的关键信息,并对不确定或缺失的部分进行明确标注。这一过程有效过滤了无关内容,从源头上缓解了低信噪比问题。
进一步地,EviNote-RAG 通过引入 Evidence Quality Reward(EQR)——基于逻辑蕴含的奖励信号,对 SEN 是否真正支撑最终答案进行评估和反馈。这一机制促使模型避免依赖浅层匹配或片段化证据,从而大幅减轻了错误累计的风险。
得益于 SEN 与 EQR 的协同作用,EviNote-RAG 不仅在多个开放域问答基准上实现了显著性能提升,还在训练稳定性、泛化能力与推理可靠性方面表现突出,真正为解决 RAG 的两大顽疾提供了一条端到端的可行路径。
技术亮点
检索-笔记-回答新范式:不再直接依赖原始检索结果,而是通过结构化的笔记生成,主动过滤干扰信息,增强证据利用率。
类人笔记机制:SEN 模块模仿人类做笔记的习惯,用「*」标记关键信息,用「–」标记不确定信息,避免模型被误导。
逻辑蕴含驱动的奖励信号:引入轻量级自然语言推理模型作为「蕴含判别器」,确保笔记能够逻辑上支撑最终答案,从而在训练中提供更密集、更高质量的奖励信号。
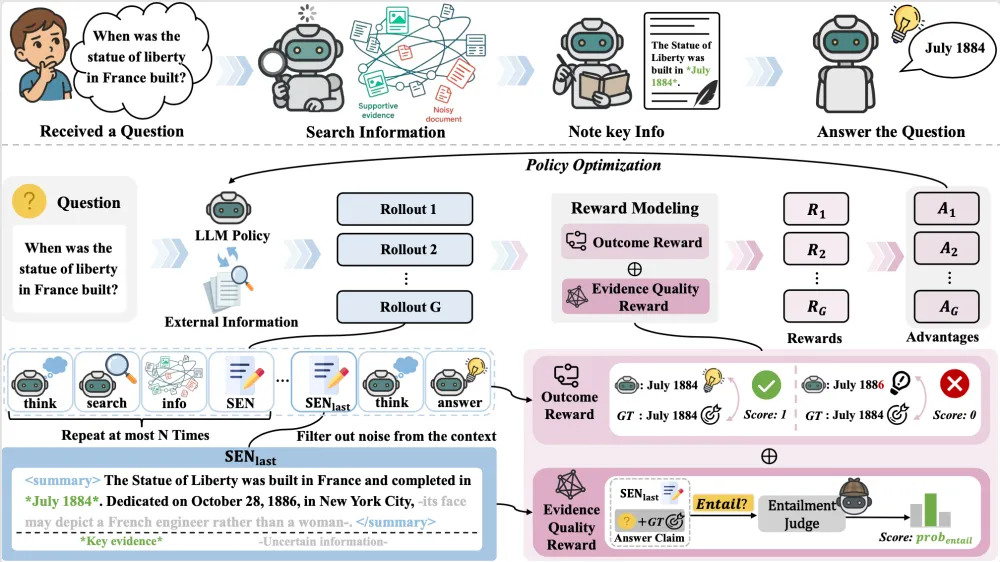
EviNote-RAG 概述:为了提高信息利用率,该方法引入了一个记录阶段,在这个阶段,模型生成支持性证据笔记(SENs),这些笔记只捕获回答所需的信息。基于蕴涵的证据质量奖励(EQR)进一步确保每个注释忠实地支持最终答案,引导模型走向更准确和基于证据的推理。
实验表现
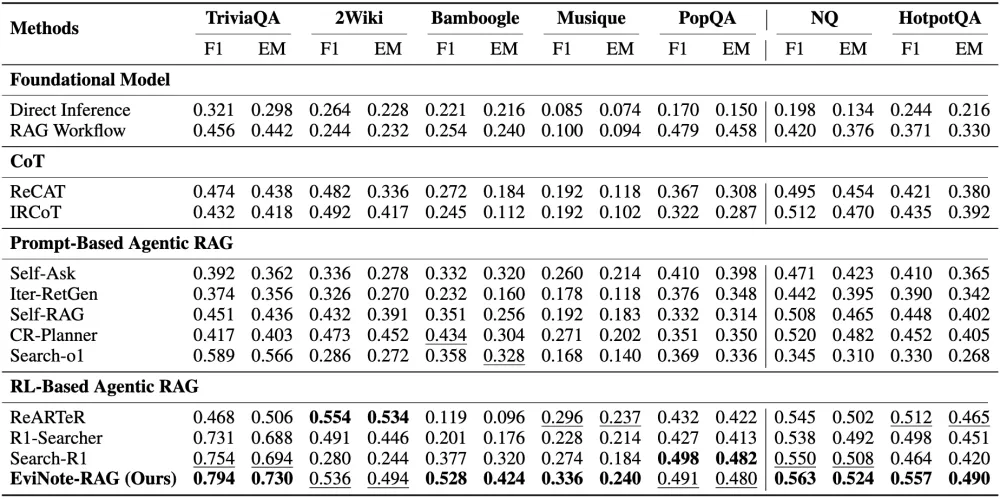
在 7 个主流 QA 基准数据集上测试了 EviNote-RAG,涵盖了 in-domain(同分布任务)和 out-of-domain(跨域任务)两大类。评价指标包括 F1 和 EM(Exact Match)。
结果非常亮眼:在 HotpotQA(多跳推理任务)上相比基础模型,F1 提升 +0.093(20%);在 Bamboogle(跨域复杂 QA)上 F1 提升 +0.151(40%);在 2Wiki(多跳跨域 QA)上 F1 提升 +0.256(91%)。
Training Dynamics:
从不稳定到稳健,RAG 训练的新范式
在传统 RAG 框架中,训练往往充满不确定性:奖励稀疏,KL 发散,甚至在训练中后期出现「坍塌」现象,模型陷入无效循环或生成退化答案。
EviNote-RAG 的引入,彻底改变了这一局面。通过在训练过程中加入 Supportive-Evidence Notes(SEN)与 Evidence Quality Reward(EQR),模型不仅学会了过滤无关信息,更获得了密集、稳定的奖励信号。这一结构化的「检索-笔记-回答」范式,使得训练曲线从动荡转向平滑,逐步提升性能的同时,极大增强了鲁棒性。
我们的分析揭示了三个关键发现:
Finding 1. 稳定性来自结构化指令,而非奖励本身。仅靠奖励设计无法避免模型漂移,唯有通过「先做笔记、再回答」的流程,把推理显式约束在证据之上,才能保证训练稳定增长。
Finding 2. 检索噪声过滤显著提升计算效率。SEN 在训练早期即丢弃无关证据,使输出更简洁聚焦,减少冗余推理,从而显著降低推理时延。
Finding 3. 行为监督不仅提升稳定性,更改善输出质量。EQR 的引入有效防止了「过短回答」与「循环生成」等退化模式,使模型在保持高效的同时,输出更忠实、更有逻辑支撑。
结果表明,EviNote-RAG 不只是性能提升,更是一种训练范式的革新:在噪声横行的检索环境中,训练终于能像一条清晰的轨道般稳定前行。
案例分析

一个直观的案例是回答「谁创作了《Knockin’ on Heaven’s Door》?」。
在传统 RAG 系统中,模型容易被检索文档中的噪声或误导性信息干扰。例如,某些文档强调 Guns N’ Roses 的翻唱版本,甚至用语暗示其「作者身份」。结果,模型很容易被这种表述带偏,最终输出错误答案「Guns N’ Roses」。
而在同样的场景下,EviNote-RAG 展现出了截然不同的表现。通过生成 Supportive-Evidence Notes(SEN),模型能够主动筛除无关或误导性的片段,仅保留和问题直接相关的核心证据。多份文档反复提及「Bob Dylan 为 1973 年电影《Pat Garrett and Billy the Kid》创作了这首歌」,这些被标注为关键信息,最终帮助模型稳定输出正确答案「Bob Dylan」。
这一案例生动展示了 EviNote-RAG 在低信噪比环境下的优势:即便存在大量混淆性信息,模型依然能够通过「先做笔记、再给答案」的流程,构建出基于真实证据的推理链,从而避免被误导。换句话说,EviNote-RAG 不仅是在「回答问题」,更是在「学会像人类一样做判断」。
消融实验与补充实验:
拆解模块贡献,验证方法稳健性
为了进一步理解 EviNote-RAG 的机制贡献,我们系统地进行了消融实验与补充实验。结果表明,我们的方法并非黑箱优化的「偶然胜利」,而是每一个设计环节都发挥了关键作用。
消融实验:SEN 与 EQR 缔造稳健推理在逐步剥离组件的实验中,基线模型(SEARCH-R1)在跨域和多跳任务中表现不稳定。引入 Supportive-Evidence Notes(SEN)后,模型性能显著提升:无关检索内容被过滤,答案相关性更强。在此基础上进一步加入 Evidence Quality Reward(EQR),模型在复杂推理链路中表现更加稳定,F1 和 EM 得到进一步提升。这一组合清晰地验证了我们的方法论逻辑:SEN 提供结构化约束,EQR 提供逻辑一致性监督,二者相辅相成,最终显著增强推理准确性。
补充实验:不同总结策略与奖励设计的比较我们进一步探索了不同的总结与监督方式:Naive Summary (NS)、Naive Evidence (NE)、Force Summary (FS) 等。结果显示,强行要求输出总结(FS)非但没有带来增益,反而由于奖励稀疏导致性能下降。
相比之下,SEN 在明确标注关键信息与不确定信息的同时,提供了更细粒度的监督信号,显著优于 NS/NE。实验还表明,单纯的奖励扰动(Stochastic Reward)难以带来稳定提升,而结合 EQR 的 SEN+EQR 则在稳定性与准确性上均达到最佳。这一系列对照实验凸显出一个核心结论:有效的监督不在于「要求总结」,而在于「如何组织与标记支持性证据」。
核心发现:
- SEN 是性能提升的基础:通过强制模型「做笔记」,显著降低噪声干扰。
- EQR 是质量提升的关键:通过逻辑蕴含约束,防止浅层匹配,强化因果一致性。
- 结构化监督胜于简单约束:相比强制总结或随机奖励,SEN+EQR 提供了稳定、密集且高质量的学习信号。
综上,消融与补充实验不仅验证了 EviNote-RAG 的有效性,更揭示了在 noisy RAG 环境中,结构化证据组织与逻辑监督是突破性能瓶颈的关键。
....

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献101条内容
已为社区贡献101条内容

所有评论(0)