大模型LoRA微调笔记
本文简要介绍了微调过程的关键环节。研究使用魔搭社区提供的免费GPU资源进行模型训练,充分利用了该平台的计算资源。同时,详细说明了训练数据的来源和应用方式,展现了完整的数据使用流程。这些技术要素共同构成了模型微调的基础条件,为后续优化工作提供了必要支持。通过合理配置这些资源,确保了微调过程的顺利进行。
·
一、 什么是LoRA? (What is LoRA?)
- 全称: Low-Rank Adaptation (低秩适应)。
- 定义: LoRA是一种高效、低成本的大语言模型(LLM)微调技术。
- 核心思想: 在不改变预训练大模型原始参数的前提下,通过引入额外的、可训练的“旁路”模块来学习模型权重的增量(ΔW),从而实现模型的微调。
- 比喻理解: 想象一个已经造好的、结构复杂的大型机器(预训练大模型)。传统微调是直接拆开机器,修改内部所有零件,成本高且易出错。LoRA则像是给机器加装一个小型的、可编程的“外挂控制器”(低秩矩阵),通过这个外挂来调整机器的行为,而机器本身保持不变。
二、 为什么需要LoRA? (Why LoRA?)
- 传统微调的痛点:
- 计算成本高昂: 微调整个大模型需要巨大的GPU内存和算力。
- 存储成本高: 每次微调都会产生一个完整的、与原始模型一样大的新模型文件。
- 部署复杂: 部署多个任务的微调模型需要存储和管理多个庞大的模型。
- LoRA的优势:
- 参数高效: 只训练新增的少量低秩矩阵参数,通常只占原模型参数量的0.1%~1%。
- 节省显存: 训练时无需加载和更新全部模型参数,大幅降低显存占用。
- 快速切换: 不同任务的LoRA权重文件很小,可以快速加载和切换,实现“一个大模型,多个小专家”。
- 避免灾难性遗忘: 原始模型权重被冻结,不会因微调新任务而丢失原有知识。
三、 LoRA的工作原理是什么? (How does LoRA work?)
- 核心公式:
W' = W + ΔW = W + B * AW: 预训练模型的原始权重矩阵。W': 微调后的有效权重。ΔW: 需要学习的权重增量。B * A: LoRA模块,用两个低秩矩阵A和B的乘积来近似ΔW。
- 低秩分解:
- 假设原始权重
W的维度是d x k。 - LoRA引入一个低秩
r(r << d, r << k),将ΔW分解为一个d x r的矩阵B和一个r x k的矩阵A的乘积。 - 这样,需要训练的参数从
d * k个减少到d * r + r * k个,参数量急剧下降。
- 假设原始权重
- 实现方式:
- 将LoRA模块“注入”到Transformer模型的注意力层中,通常是作用于Query (Q) 和 Value (V) 的权重矩阵。
- 在前向传播时,计算路径变为:
h = Wx + BAx,其中Wx是原始路径,BAx是LoRA的旁路。
四、 LoRA微调的关键超参数有哪些? (Key Hyperparameters)
- 秩 (Rank -
r):- 定义: 低秩矩阵
A和B的秩,即分解的维度。 - 影响:
r值越大,LoRA的表达能力越强,但参数量和计算量也越大。通常r在4到64之间选择,需要根据任务复杂度和数据量进行调整。
- 定义: 低秩矩阵
- 缩放因子 (Alpha -
α):- 定义: 一个缩放系数,用于调节LoRA更新的幅度。
- 公式:
W' = W + (α/r) * B * A - 影响: 控制LoRA模块对最终输出的影响程度。较大的
α意味着更强的微调效果。实践中,常将α设置为2r或通过实验调整。
- Dropout: 可选地在LoRA模块中加入Dropout层,以防止过拟合。
- 目标模块 (Target Modules):
- 定义: 指定将LoRA注入到模型的哪些层。
- 常见选择:
q_proj,v_proj(注意力层的Query和Value投影)。有时也会加入k_proj和o_proj。
五、 如何进行LoRA微调? (How to Fine-tune with LoRA?)
- 步骤概述:
- 准备: 加载预训练大模型,并冻结其所有参数。
- 注入: 使用库(如Hugging Face PEFT)将LoRA模块按配置注入到指定的目标层。
- 训练: 在特定任务的数据集上训练,只更新LoRA模块的参数(
A和B矩阵)。 - 保存: 训练完成后,只保存LoRA的权重文件(通常只有几MB到几十MB)。
- 推理/部署: 加载原始大模型,并“加载”对应的LoRA权重,两者结合进行推理。
- 工具推荐: Hugging Face的
PEFT(Parameter-Efficient Fine-Tuning) 库是实现LoRA微调最常用和便捷的工具。
六、 LoRA的局限性是什么? (Limitations)
- 表达能力受限: 由于是低秩近似,对于需要大规模、复杂权重更新的任务,LoRA可能不如全参数微调效果好。
- 超参数敏感:
秩(r)和缩放因子(α)的选择对最终效果影响较大,需要一定的调参经验。 - 适用层有限: 主要应用于注意力机制,对于模型的其他部分(如MLP层)效果可能不显著。
七、 LoRA的应用场景与总结
- 应用场景:
- 个性化模型: 快速微调模型以适应特定用户或风格。
- 多任务学习: 为不同任务训练不同的LoRA权重,共享同一个基础模型。
- 资源受限环境: 在显存和算力有限的情况下进行模型微调。
- 快速原型开发: 快速验证新任务的可行性。
- 总结:
- LoRA是当前大模型微调领域最重要、最实用的参数高效微调(PEFT)技术之一。
- 它通过“冻结主干,训练旁路”的创新思想,完美平衡了微调效果与计算成本。
- 掌握LoRA原理和调参方法,是进入大模型应用开发的必备技能。

2. 微调的过程

2.1 数据集
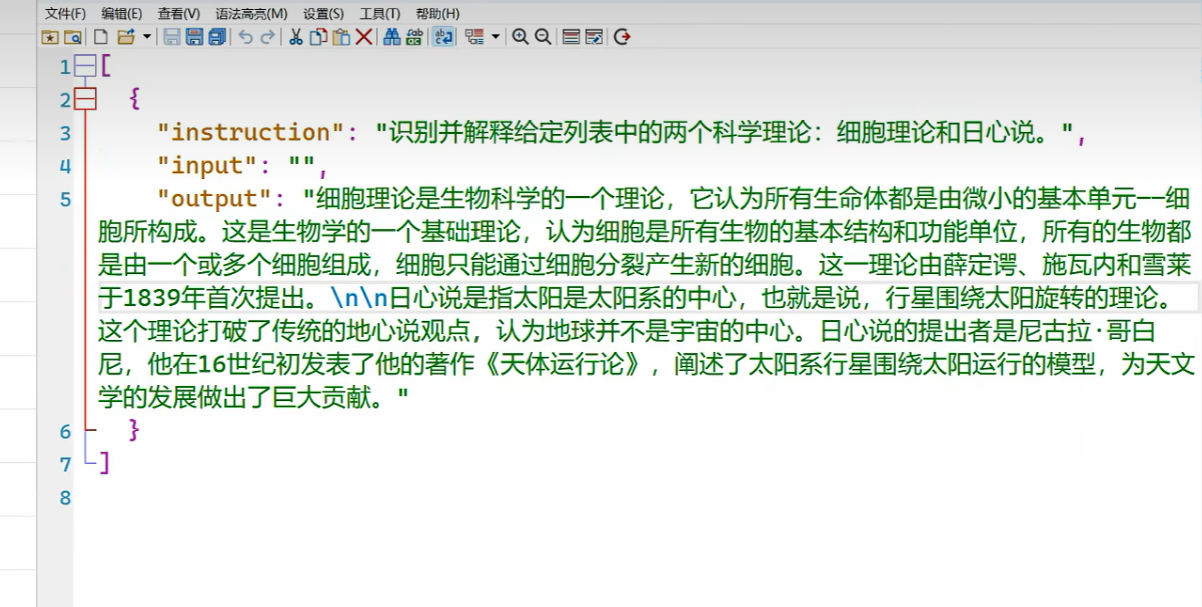


魔搭社区,免费GPU资源 ,训练微调。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)