Transformer技术全景解析:从理论到实现的全栈指南
本文将带你全面了解Transformer技术,从基础原理到计算细节,并提供了相应的实现代码,帮助你快速掌握这一强大的技术栈。
目录
引言
本文将带你全面了解Transformer技术,从基础原理到计算细节,并提供了相应的实现代码,帮助你快速掌握这一强大的技术栈。
一、发展现状
在深度学习中,RNN和LSTM曾是处理序列数据的主流方法,但随着序列长度增加,它们面临梯度消失和并行性差的问题。2017年,Google团队提出Transformer架构,采用自注意力机制,解决了这些问题,并在自然语言处理(NLP)领域带来突破。如今,Transformer及其变体在NLP、计算机视觉(CV)和语音处理等领域占据主导地位。例如,GPT系列在文本生成和多模态任务中表现出色,Vision Transformer(ViT)在图像分类等任务中也取得显著成果。目前约85%的NLP生产系统基于Transformer变体,体现了其强大的适应性和核心地位。
二、模型结构
1、基本编码器-解码器结构
在神经序列转换模型中,编码器-解码器(Encoder-Decoder)结构是核心组成部分,广泛应用于处理序列格式的数据(Seq2Seq)。编码器将符号表示的输入序列(x1,…,xn)映射到连续表示序列z,而解码器则负责生成符号输出序列(Y1,…,Ym)。在生成下一个符号时,解码器会将之前生成的符号作为额外输入,这体现了模型的自回归特性。这种结构在处理可变长度的序列时表现出色,因为它能够适应输入和输出序列长度的不同。编码器通过编码过程将输入序列压缩为一个固定维度的上下文向量,该向量作为输入序列的抽象表示,解码器基于此上下文向量进行解码操作以生成目标输出序列。
下面是一个标准的编码器-解码器结构的实现代码:
import torch
import torch.nn as nn
from torch.nn.functional import log_softmax
class EncoderDecoder(nn.Module):
"""
一个标准的编码器-解码器架构。这是这个模型和许多其他模型的基础。
该类整合了编码器、解码器、源语言嵌入、目标语言嵌入和生成器,用于处理Seq2Seq任务。
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
"""
初始化编码器-解码器模型。
参数:
encoder (nn.Module): 编码器模块,负责将源序列编码为连续表示。
decoder (nn.Module): 解码器模块,负责将编码后的表示解码为目标序列。
src_embed (nn.Module): 源语言嵌入层,将源序列的索引转换为向量表示。
tgt_embed (nn.Module): 目标语言嵌入层,将目标序列的索引转换为向量表示。
generator (nn.Module): 生成器模块,将解码器的输出转换为最终的预测结果。
"""
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"""
前向传播函数,处理掩码的源序列和目标序列。
参数:
src (Tensor): 源序列的索引。
tgt (Tensor): 目标序列的索引。
src_mask (Tensor): 源序列的掩码,用于忽略填充位置。
tgt_mask (Tensor): 目标序列的掩码,用于忽略填充位置。
返回:
Tensor: 解码器的输出,经过生成器处理后的最终预测结果。
"""
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
"""
编码函数,将源序列编码为连续表示。
参数:
src (Tensor): 源序列的索引。
src_mask (Tensor): 源序列的掩码,用于忽略填充位置。
返回:
Tensor: 编码后的表示,即编码器的输出。
"""
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
"""
解码函数,将编码后的表示解码为目标序列。
参数:
memory (Tensor): 编码后的表示,即编码器的输出。
src_mask (Tensor): 源序列的掩码,用于忽略填充位置。
tgt (Tensor): 目标序列的索引。
tgt_mask (Tensor): 目标序列的掩码,用于忽略填充位置。
返回:
Tensor: 解码器的输出,经过生成器处理后的最终预测结果。
"""
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"""
定义标准线性+softmax生成步骤。
该类用于将解码器的输出转换为最终的预测结果,通常用于生成模型的最后一步。
"""
def __init__(self, d_model, vocab):
"""
初始化生成器。
参数:
d_model (int): 模型的维度,即解码器输出的维度。
vocab (int): 词汇表的大小,即可能的输出类别的数量。
"""
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
"""
定义一个线性层,将解码器的输出(维度为d_model)映射到词汇表大小(vocab)的维度。
"""
def forward(self, x):
"""
前向传播函数,将解码器的输出转换为最终的预测结果。
参数:
x (Tensor): 解码器的输出,维度为[batch_size, seq_len, d_model]。
返回:
Tensor: 经过log_softmax处理的预测结果,维度为[batch_size, seq_len, vocab]。
"""
return log_softmax(self.proj(x), dim=-1)
"""
使用线性层将解码器的输出映射到词汇表大小的维度,然后应用log_softmax函数。
log_softmax函数计算每个位置的log概率,用于后续的损失计算和预测。
dim=-1表示在最后一个维度(即词汇表维度)上应用softmax。
"""2、Transformer中编码器的实现
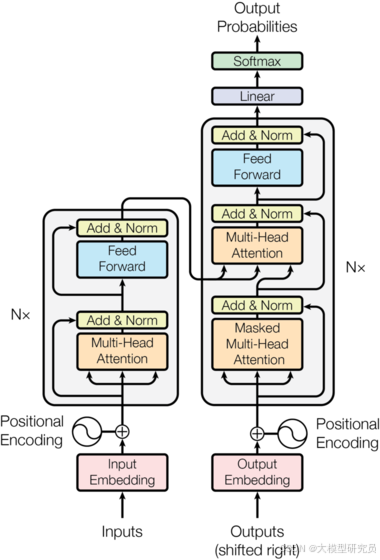
Transformer遵循编码器和解码器的整体架构:编码器和解码器都使用堆叠式自注意力层和逐点全连接层,分别如上图所示的左右两部分。
编码器由6个相同的层组成,每个层包含两个子层:
1、多头自注意力机制:允许模型在序列的不同位置之间动态地分配不同的注意力权重,从而捕捉序列内部的长距离依赖关系。
2、位置全连接前馈网络:对自注意力层的输出进行进一步的非线性变换。
每个子层的输出通过残差连接和层归一化处理,即 LayerNorm(x + Sublayer(x)),其中 Sublayer(x) 是子层本身实现的函数。这种结构有助于缓解深层网络中的梯度消失问题,并促进信息的流动。
下面是Transformer中编码器结构的实现代码:
def clones(module, N):
"""
生成N个相同的模块层。
参数:
module (nn.Module): 要复制的模块。
N (int): 需要复制的模块数量。
返回:
nn.ModuleList: 包含N个相同模块副本的列表。
"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class EncoderLayer(nn.Module):
"""
编码器层由自注意力机制和前馈网络组成。
"""
def __init__(self, size, self_attn, feed_forward, dropout):
"""
初始化编码器层。
参数:
size (int): 输入特征的维度。
self_attn (nn.Module): 自注意力机制模块。
feed_forward (nn.Module): 前馈网络模块。
dropout (float): dropout的概率。
"""
super(EncoderLayer, self).__init__()
self.self_attn = self_attn # 自注意力机制模块
self.feed_forward = feed_forward # 前馈网络模块
self.sublayer = clones(SublayerConnection(size, dropout), 2) # 创建两个子层连接模块
self.size = size # 保存输入特征的维度
def forward(self, x, mask):
"""
前向传播函数,按照图中的连接方式处理输入。
参数:
x (Tensor): 输入张量。
mask (Tensor): 输入序列的掩码,用于忽略填充位置。
返回:
Tensor: 经过编码器层处理后的输出。
"""
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 通过第一个子层连接模块和自注意力机制
return self.sublayer[1](x, self.feed_forward) # 通过第二个子层连接模块和前馈网络
class LayerNorm(nn.Module):
"""
构建一个层归一化模块。
层归一化在每个样本的特征维度上进行归一化,而不是在批次维度上。
"""
def __init__(self, features, eps=1e-6):
"""
初始化层归一化模块。
参数:
features (int): 特征的数量,即输入张量的最后一个维度的大小。
eps (float, optional): 用于数值稳定性的小常数。默认值为1e-6。
"""
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features)) # 可学习的缩放参数
self.b_2 = nn.Parameter(torch.zeros(features)) # 可学习的偏移参数
self.eps = eps # 数值稳定性常数
def forward(self, x):
"""
前向传播函数,对输入进行层归一化。
参数:
x (Tensor): 输入张量,维度为[batch_size, ..., features]。
返回:
Tensor: 归一化后的张量。
"""
mean = x.mean(-1, keepdim=True) # 计算特征维度上的均值
std = x.std(-1, keepdim=True) # 计算特征维度上的标准差
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2 # 应用层归一化公式
class SublayerConnection(nn.Module):
"""
一个残差连接后跟一个层归一化的模块。
为了代码的简洁性,这里的归一化是在子层之前进行的,而不是之后。
"""
def __init__(self, size, dropout):
"""
初始化子层连接模块。
参数:
size (int): 输入特征的维度。
dropout (float): dropout的概率。
"""
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size) # 初始化层归一化模块
self.dropout = nn.Dropout(dropout) # 初始化dropout模块
def forward(self, x, sublayer):
"""
前向传播函数,应用残差连接到任何具有相同大小的子层。
参数:
x (Tensor): 输入张量。
sublayer (nn.Module): 子层模块,其输出维度与输入维度相同。
返回:
Tensor: 经过残差连接和层归一化后的输出。
"""
return x + self.dropout(sublayer(self.norm(x)))
"""
首先对输入x进行层归一化,然后通过子层模块sublayer,接着应用dropout,
最后将结果与原始输入x相加,形成残差连接。
"""3、Transformer中解码器的实现
解码器也由6个相同的层组成,除了编码器中的两个子层外,解码器还包含一个额外的子层,该子层对编码器堆的输出执行多头注意力。这允许解码器层关注编码器的输出,从而将输入序列的信息整合到输出序列中。
与编码器类似,解码器中的每个子层也使用残差连接和层归一化。此外,解码器中的自注意力子层被修改以防止位置关注后续位置,这是通过掩码机制实现的。这种掩码,加上输出嵌入偏移一个位置的事实,确保位置i的预测仅依赖于小于i的已知输出。
class DecoderLayer(nn.Module):
"""
解码器层由自注意力机制、源注意力机制和前馈网络组成。
"""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
"""
初始化解码器层。
参数:
size (int): 输入特征的维度。
self_attn (nn.Module): 自注意力机制模块。
src_attn (nn.Module): 源注意力机制模块,用于关注编码器的输出。
feed_forward (nn.Module): 前馈网络模块。
dropout (float): dropout的概率。
"""
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
"""
创建三个子层连接模块,分别用于自注意力、源注意力和前馈网络。
每个子层连接模块包括层归一化和残差连接。
"""
def forward(self, x, memory, src_mask, tgt_mask):
"""
前向传播函数,按照图中的连接方式处理输入。
参数:
x (Tensor): 目标序列的嵌入表示。
memory (Tensor): 编码器的输出,作为解码器的内存。
src_mask (Tensor): 源序列的掩码,用于忽略填充位置或不相关信息。
tgt_mask (Tensor): 目标序列的掩码,用于防止位置关注后续位置。
返回:
Tensor: 经过解码器层处理后的输出。
"""
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
"""
1. 通过第一个子层连接模块和自注意力机制处理x。
2. 通过第二个子层连接模块和源注意力机制处理x。
3. 通过第三个子层连接模块和前馈网络处理x,并返回最终结果。
"""三、核心原理解析
1、自注意力机制
自注意力机制(Self-Attention)是一种强大的序列建模工具,它允许模型在处理序列数据时动态地调整对每个元素的关注程度,从而捕捉序列内部的复杂依赖关系。这种机制不依赖于外部信息,而是在序列内部元素之间进行信息的交互和整合,对于序列中的每个元素,自注意力机制会计算该元素与序列中所有其他元素的相关性,生成一个加权的表示,其中权重反映了元素间的相互关系。
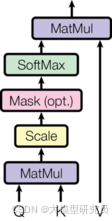
从数学视角来看,自注意力机制可以通过以下公式表示:
其中,Q、K 和 V 分别代表查询(Query)、键(Key)和值(Value)向量,dk 是键向量的维度。
从物理视角来看,自注意力机制可以类比于信息检索过程,其中Query-Key匹配度决定Value的权重,这有助于模型识别和比较序列中不同元素之间的关系。
在工程视角下,自注意力机制的一个重要优势是其能够实现多头注意力的并行计算,这极大地促进了模型的并行化训练,因为每个位置上的计算都可以独立进行。
def attention(query, key, value, mask=None, dropout=None):
"""
计算“缩放点积注意力”。
参数:
query (Tensor): 查询向量,维度为 [batch_size, seq_len, d_k]
key (Tensor): 键向量,维度为 [batch_size, seq_len, d_k]
value (Tensor): 值向量,维度为 [batch_size, seq_len, d_v]
mask (Tensor, optional): 掩码,用于掩盖不相关的键,维度为 [batch_size, seq_len, seq_len]
dropout (nn.Dropout, optional): dropout层,用于正则化
返回:
Tensor: 注意力加权的值向量,维度为 [batch_size, seq_len, d_v]
Tensor: 注意力分数,维度为 [batch_size, seq_len, seq_len]
"""
d_k = query.size(-1) # 获取键向量的维度
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
"""
计算query和key的点积,并除以sqrt(d_k)进行缩放,以防止点积值过大。
然后,将key转置,使得点积操作能够正确地计算query和key之间的相似度。
"""
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
"""
如果提供了掩码,将掩码位置的分数设置为一个非常小的数(如-1e9),这样在softmax操作中这些位置的注意力权重将接近于0。
"""
p_attn = scores.softmax(dim=-1) # 计算softmax以获得注意力权重
if dropout is not None:
p_attn = dropout(p_attn) # 应用dropout
return torch.matmul(p_attn, value), p_attn # 计算加权的value并返回注意力权重2、多头注意力机制
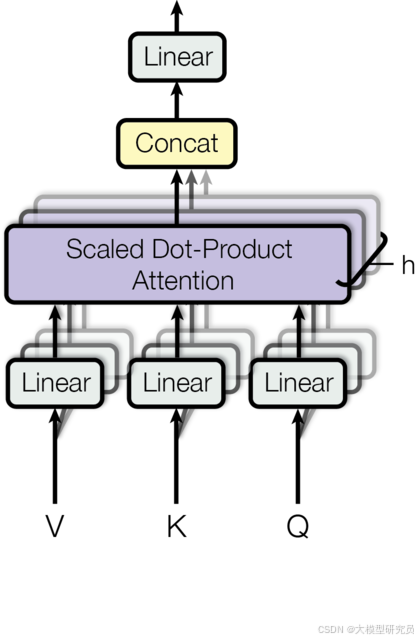
多头注意力机制允许模型同时关注不同表示子空间中的信息,这些信息可能位于输入的不同位置。通过使用单个注意力头,模型的平均行为会抑制这种并行关注的能力。
多头注意力的计算公式如下:
其中,每个头的计算如下:
这里的投影是参数矩阵:
:查询(Query)的投影矩阵
:键(Key)的投影矩阵
:值(Value)的投影矩阵
:输出的投影矩阵
每个头可以学习到不同的特征表示,最后通过拼接和线性变换将这些表示整合起来,形成最终的输出。
实现代码如下:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"""
初始化一个具有多个注意力头的模块。
参数:
h (int): 注意力头的数量。
d_model (int): 模型的维度,即每个头处理的特征数量。
dropout (float, optional): 在注意力权重上应用的dropout概率。默认为0.1。
"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0 # 确保模型维度可以被头数整除
self.d_k = d_model // h # 每个头的维度
self.h = h # 头的数量
# 创建4个线性层,分别用于查询(query)、键(key)、值(value)和最终的输出(output)
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None # 用于存储计算得到的注意力权重
self.dropout = nn.Dropout(p=dropout) # 创建dropout层
def forward(self, query, key, value, mask=None):
"""
前向传播函数,实现多头注意力机制。
参数:
query (Tensor): 查询向量,维度为 [batch_size, seq_len, d_model]
key (Tensor): 键向量,维度为 [batch_size, seq_len, d_model]
value (Tensor): 值向量,维度为 [batch_size, seq_len, d_model]
mask (Tensor, optional): 掩码,用于掩盖不相关的键。默认为None。
"""
if mask is not None:
# 如果提供了掩码,增加一个维度以用于所有头
mask = mask.unsqueeze(1)
nbatches = query.size(0) # 批次大小
# 1) 对查询、键和值进行线性变换,并将结果分成多个头
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) 对所有头的投影向量应用注意力机制
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) 将所有头的结果拼接起来,并应用最终的线性变换
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
# 删除不再需要的中间变量以节省内存
del query
del key
del value
return self.linears[-1](x) # 返回最终的输出3、三种不同的注意力应用方式
编码器-解码器注意力(Encoder-Decoder Attention):
-
在编码器-解码器注意力层中,查询(queries)来自于先前的解码器层,而记忆键(memory keys)和值(values)来自于编码器的输出。
-
这使得解码器中的每个位置都能够关注输入序列中的所有位置。
-
这种机制模仿了序列到序列模型中典型的编码器-解码器注意力机制
编码器中的自注意力层(Self-Attention in the Encoder):
-
编码器包含自注意力层。在自注意力层中,所有的键、值和查询都来自同一个地方,即编码器中前一层的输出。
-
编码器中的每个位置都能够关注编码器前一层中的所有位置。
解码器中的自注意力层(Self-Attention in the Decoder):
-
类似地,解码器中的自注意力层允许解码器中的每个位置关注解码器中直到并包括该位置的所有位置。
-
为了保持自回归特性,我们需要防止解码器中的信息向左流动。在自注意力层中,通过掩码(masking)实现这一点,将所有对应于非法连接的softmax输入值设置为一个非常大的负数(例如负无穷大),从而在计算注意力时忽略这些位置。
4、位置前馈的全连接前馈网络
在Transformer模型中,除了注意力子层之外,编码器和解码器的每一层都包含一个位置前馈的全连接前馈网络(Position-wise Feed-Forward Networks)。这种网络对每个位置分别且以相同的方式应用,意味着网络对序列中的每个元素独立进行操作,而不考虑元素之间的顺序关系。
位置前馈的全连接前馈网络的结构通常包括两个线性变换(即全连接层),中间夹着一个ReLU激活函数。其数学表达式如下:
代码实现如下:
class PositionwiseFeedForward(nn.Module):
"""
实现位置前馈的全连接前馈网络(FFN)。
这个网络对每个位置的输入序列独立地应用相同的全连接网络。
"""
def __init__(self, d_model, d_ff, dropout=0.1):
"""
初始化位置前馈的全连接前馈网络。
参数:
d_model (int): 输入和输出的维度。
d_ff (int): 中间层的维度。
dropout (float, optional): dropout的概率。默认为0.1。
"""
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff) # 第一个线性层,将输入维度转换为中间层维度
self.w_2 = nn.Linear(d_ff, d_model) # 第二个线性层,将中间层维度转换回输入维度
self.dropout = nn.Dropout(dropout) # dropout层,用于正则化
def forward(self, x):
"""
前向传播函数,实现FFN方程。
参数:
x (Tensor): 输入张量,维度为 [batch_size, seq_len, d_model]。
返回:
Tensor: 输出张量,维度为 [batch_size, seq_len, d_model]。
"""
return self.w_2(self.dropout(self.w_1(x).relu())) # 应用第一个线性层,ReLU激活函数,dropout,然后应用第二个线性层5、嵌入和softmax函数
在Transformer模型中,嵌入(Embeddings)和Softmax函数被用来将输入和输出的标记(tokens)转换为维度为的向量。嵌入层是将词汇表中的每个单词映射到一个固定维度的连续向量空间的矩阵。这些嵌入向量随后被输入到模型中进行进一步的处理。
此外,模型使用传统的线性变换和softmax函数将解码器的输出转换为下一个标记的预测概率分布。在Transformer模型中,嵌入层和预Softmax线性变换之间共享相同的权重矩阵,这与某些其他序列转换模型类似。
在嵌入层中,权重矩阵乘以 ,其中
是模型的维度。这样做的目的是为了在应用softmax函数之前对权重进行缩放,以保持数值稳定性,避免在计算过程中出现梯度太大或太小的值。
实现代码如下:
class Embeddings(nn.Module):
"""
词嵌入层,将输入的单词索引转换为维度为d_model的向量。
"""
def __init__(self, d_model, vocab):
"""
初始化词嵌入层。
参数:
d_model (int): 嵌入向量的维度。
vocab (int): 词汇表的大小,即单词的数量。
"""
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model) # 初始化PyTorch的嵌入层
self.d_model = d_model # 保存模型维度
def forward(self, x):
"""
前向传播函数,将输入的单词索引转换为嵌入向量。
参数:
x (Tensor): 输入的单词索引,维度为[batch_size, seq_len]。
返回:
Tensor: 嵌入向量,维度为[batch_size, seq_len, d_model]。
"""
return self.lut(x) * math.sqrt(self.d_model) # 乘以sqrt(d_model)进行缩放5、位置编码(Positional Encoding)
在Transformer模型中,由于没有使用递归(recurrence)和卷积(convolution)结构,为了使模型能够利用序列中元素的顺序信息,必须向模型注入一些关于序列中标记(tokens)的相对或绝对位置的信息。为此,在编码器(encoder)和解码器(decoder)堆栈的底部,我们向输入嵌入(embeddings)中添加了“位置编码”(positional encodings)。位置编码与嵌入具有相同的维度 ,因此可以将两者相加。
有许多选择位置编码的方式,包括学习得到的和固定模式的。在Transformer中使用了不同频率的正弦(sine)和余弦(cosine)函数来构建位置编码:
这些函数的频率呈几何级数增长,使得模型可以捕捉到不同尺度上的序列结构。此外,这种位置编码的设计使得对于任何固定的偏移 ,位置
可以表示为位置
的线性函数,这有助于模型学习关注相对位置。
实现代码如下:
class PositionalEncoding(nn.Module):
"""
实现位置编码函数。
"""
def __init__(self, d_model, dropout, max_len=5000):
"""
初始化位置编码模块。
参数:
d_model (int): 模型的维度。
dropout (float): dropout的概率。
max_len (int, optional): 最大序列长度。默认为5000。
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # 初始化dropout层
# 一次性在对数空间中计算位置编码。
pe = torch.zeros(max_len, d_model) # 初始化位置编码矩阵
position = torch.arange(0, max_len).unsqueeze(1) # 创建位置向量
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
) # 计算除数项,用于生成不同频率的正弦和余弦波形
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度使用正弦函数
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度使用余弦函数
pe = pe.unsqueeze(0) # 增加批次维度
self.register_buffer("pe", pe) # 注册缓冲区,以便在训练过程中保持不变
def forward(self, x):
"""
前向传播函数,将位置编码添加到输入序列中。
参数:
x (Tensor): 输入序列,维度为 [batch_size, seq_len, d_model]。
返回:
Tensor: 添加了位置编码的序列。
"""
x = x + self.pe[:, : x.size(1)].requires_grad_(False) # 将位置编码添加到输入序列
return self.dropout(x) # 应用dropout四、Transformer整体结构实现
class Encoder(nn.Module):
"""
Core encoder is a stack of N layers
主编码器由 N 层相同的编码器层堆叠而成
"""
def __init__(self, layer, N):
"""
初始化函数
:param layer: 单个编码器层的定义
:param N: 编码器层的数量
"""
super(Encoder, self).__init__()
self.layers = clones(layer, N) # 创建 N 个相同的编码器层
self.norm = LayerNorm(layer.size) # 添加一个层归一化(Layer Normalization)
def forward(self, x, mask):
"""
前向传播函数
:param x: 输入张量(通常是嵌入后的词向量)
:param mask: 掩码张量,用于屏蔽某些位置的信息
:return: 编码后的输出
"""
"Pass the input (and mask) through each layer in turn."
for layer in self.layers: # 遍历每一层编码器
x = layer(x, mask) # 将输入和掩码传递给当前层
return self.norm(x) # 最后对输出进行层归一化
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N) # 堆叠 N 层解码器层
self.norm = LayerNorm(layer.size) # 添加层归一化
def forward(self, x, memory, src_mask, tgt_mask):
"""
前向传播函数
:param x: 输入张量(通常是目标序列的嵌入表示)
:param memory: 编码器的输出,用于解码器的交互注意力层
:param src_mask: 源序列的掩码,用于屏蔽编码器输出中的某些位置
:param tgt_mask: 目标序列的掩码,用于屏蔽解码器输入中的某些位置
:return: 解码后的输出
"""
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask) # 逐层传递输入
return self.norm(x) # 最终输出经过层归一化
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
辅助函数:根据超参数构建模型。
参数:
src_vocab (int): 源语言的词汇表大小。
tgt_vocab (int): 目标语言的词汇表大小。
N (int, optional): 编码器和解码器层的数量。默认为6。
d_model (int): 模型的维度。默认为512。
d_ff (int): 前馈网络的维度。默认为2048。
h (int): 注意力头的数量。默认为8。
dropout (float): dropout的概率。默认为0.1。
"""
c = copy.deepcopy # 用于复制注意力和前馈网络层
attn = MultiHeadedAttention(h, d_model) # 创建多头注意力层
ff = PositionwiseFeedForward(d_model, d_ff, dropout) # 创建位置前馈网络
position = PositionalEncoding(d_model, dropout) # 创建位置编码层
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), # 创建编码器
Decoder(DecoderLayer(d_model, c(attn), c(ff), dropout), N), # 创建解码器
nn.Sequential(Embeddings(d_model, src_vocab), c(position)), # 创建源语言嵌入层
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)), # 创建目标语言嵌入层
Generator(d_model, tgt_vocab) # 创建生成器
)
# 使用Glorot / fan_avg初始化参数。
for p in model.parameters():
if p.dim() > 1:
init.xavier_uniform_(p) # 使用xavier_uniform_初始化权重
return model # 返回构建的模型
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)