手把手1B进行lora微调,然后量化模型案例(简单跑通代码,入门系列)
手把手1B进行lora微调,然后量化模型案例(简单跑通代码,入门系列)
流程
首先到huggingface下载小模型,我实际上下载的是1B的小模型
添加命令行参数
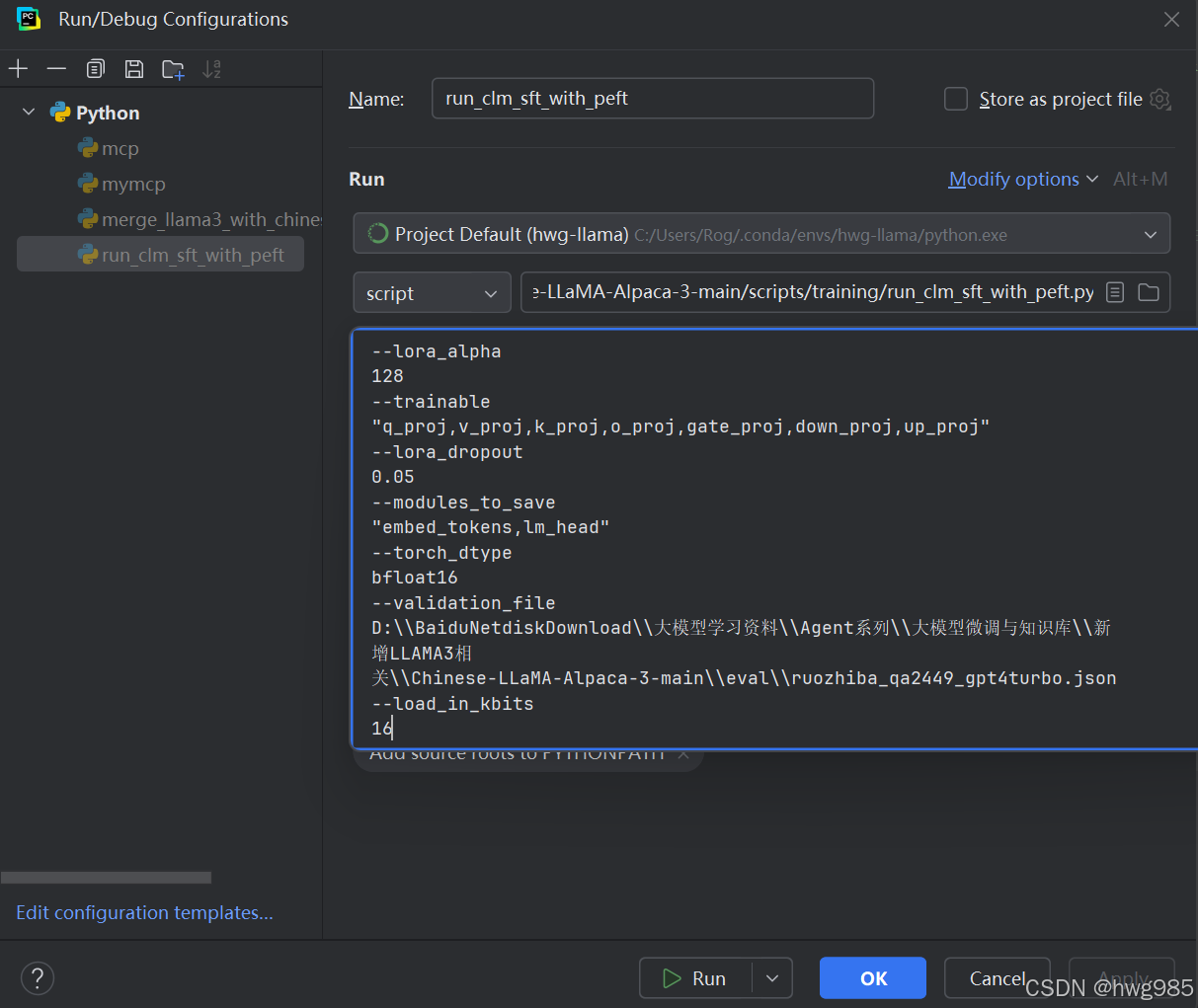
--model_name_or_path D:\\迅雷下载 --tokenizer_name_or_path D:\\迅雷下载 --dataset_dir D:\\BaiduNetdiskDownload\\大模型学习资料\\Agent系列\\大模型微调与知识库\\新增LLAMA3相关\\Chinese-LLaMA-Alpaca-3-main\\data --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --do_train 1 --do_eval 1 --seed 42 --bf16 1 --num_train_epochs 3 --lr_scheduler_type cosine --learning_rate 1e-4 --warmup_ratio 0.05 --weight_decay 0.1 --logging_strategy steps --logging_steps 10 --save_strategy steps --save_total_limit 3 --evaluation_strategy steps --eval_steps 100 --save_steps 200 --gradient_accumulation_steps 8 --preprocessing_num_workers 8 --max_seq_length 1024 --output_dir D:\\BaiduNetdiskDownload\\大模型学习资料\\Agent系列\\大模型微调与知识库\\新增LLAMA3相关\\Chinese-LLaMA-Alpaca-3-main\\output-data\\llama3-lora-res --overwrite_output_dir 1 --ddp_timeout 30000 --logging_first_step True --lora_rank 64 --lora_alpha 128 --trainable "q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj" --lora_dropout 0.05 --modules_to_save "embed_tokens,lm_head" --torch_dtype bfloat16 --validation_file D:\\BaiduNetdiskDownload\\大模型学习资料\\Agent系列\\大模型微调与知识库\\新增LLAMA3相关\\Chinese-LLaMA-Alpaca-3-main\\eval\\ruozhiba_qa2449_gpt4turbo.json --load_in_kbits 16
跑run_clm_sft_with_peft.py(作用是生成lora得到的微调之后的模型)
其中命令行参数里面--dataset_dir指定了你的微调里面的数据集
然后合并LORA,现在只训练和保存了一部分权重,需要和原始的合并在一起
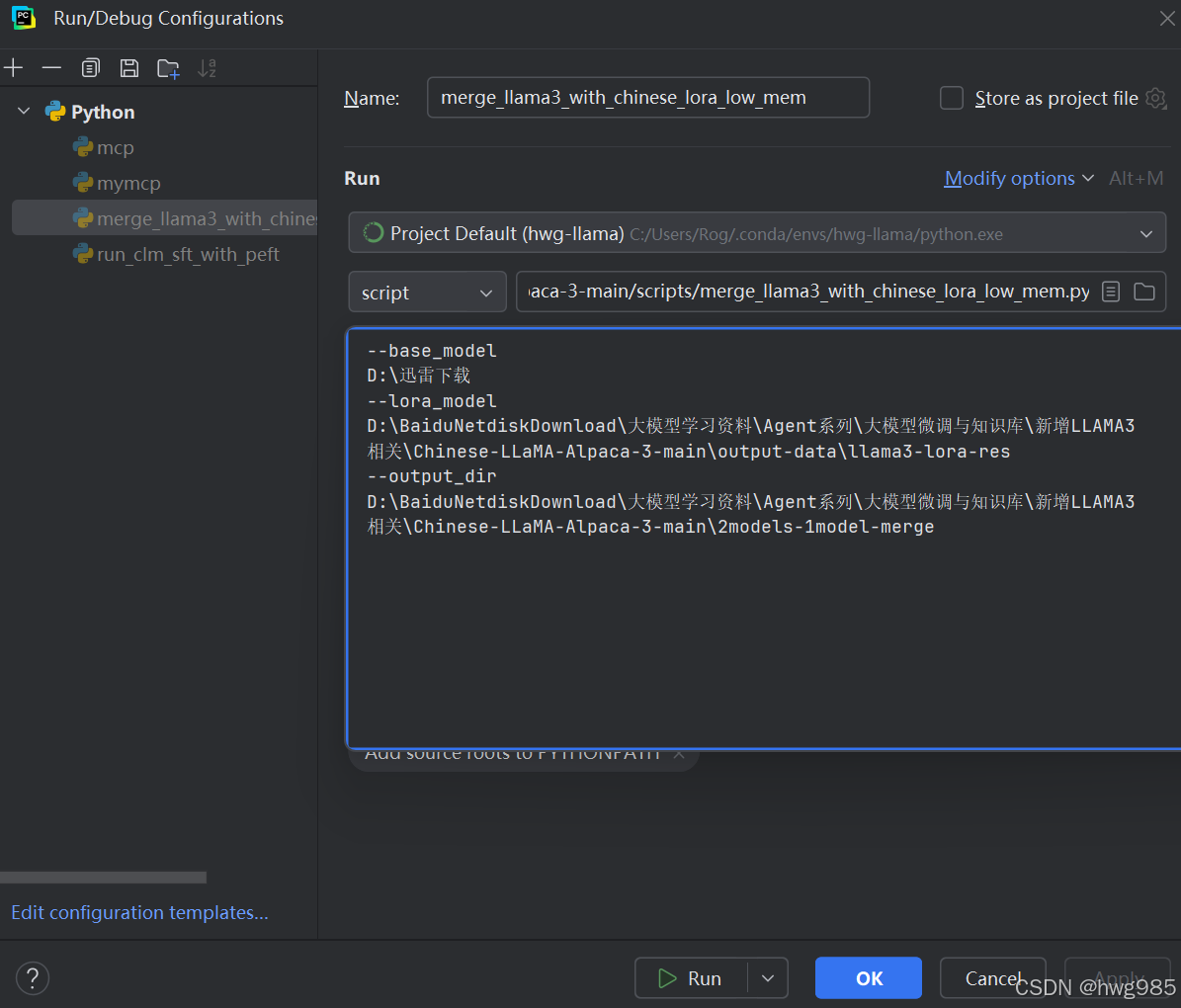
1.执行merge_llama3_with_chinese_lora_low_mem.py,需要传入的参数(改成自己的):
base-model和loar-model和output-dir全部指定目录即可,一个是需要微调的模型所在目录, 一个是lora出来的模型所在目录,一个是和并之后的目录
--base_model
D:\迅雷下载
--lora_model
D:\BaiduNetdiskDownload\大模型学习资料\Agent系列\大模型微调与知识库\新增LLAMA3相关\Chinese-LLaMA-Alpaca-3-main\output-data\llama3-lora-res
--output_dir
D:\BaiduNetdiskDownload\大模型学习资料\Agent系列\大模型微调与知识库\新增LLAMA3相关\Chinese-LLaMA-Alpaca-3-main\2models-1model-merge
然后如果有需要还可以进一步量化
量化之前需要从GitHub下载工具
https://github.com/ggerganov/llama.cpp
cd llama.cpp
pip install -r requirements/requirements-convert-hf-to-gguf.txt
cmake -B build
cmake --build build --config Release
中间如果出现安装错误,那就单独拎出来挨个包安装,我记得这里坑比较多,比较难搞,而且好像是要安装一个rust库,然后我还用了那个visual studio的生成工具安装了对应的c++库,错误是cursor帮我诊断的,有坑就找他吧
然后利用cmake的东西,编译安装一下子
然后配置环境变量
D:\Download\llama.cpp-master\llama.cpp-master\build\bin\Release
到Path里面,方便执行后续量化指令
执行权重的转换,把safetensors文件转化为gguf文件
python convert.py --outfile D:\BaiduNetdiskDownload\大模型学习资料\Agent系列\大模型微调与知识库\新增LLAMA3相关\Chinese-LLaMA-Alpaca-3-main\convert-file\my_llama3.gguf D:\BaiduNetdiskDownload\大模型学习资料\Agent系列\大模型微调与知识库\新增LLAMA3相关\Chinese-LLaMA-Alpaca-3-main\2models-1model-merge
然后中间出错了,量化的时候不能有中文,后面复制了转换后的gguf到另外一个盘
下面是量化命令,因为前面配置过了环境变量,因此这里llama-quantize.exe就方便了!!!
llama-quantize.exe E:\tuning\my_llama3.gguf E:\tuning\quantize\q.gguf q4_0
量化结果
ollama create hwg-model -f D:\BaiduNetdiskDownload\大模型学习资料\Agent系列\大模型微调与知识库\新增LLAMA3相关\Chinese-LLaMA-Alpaca-3-main\modelfile\Modelfile
Modefile内容如下
FROM E:\tuning\quantize\q.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
SYSTEM """You are a helpful assistant. 你是一个乐于助人的助手。"""
PARAMETER num_keep 24
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
PARAMETER stop assistant
run_clm_sft_with_peft.py内容
import logging
import math
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
from pathlib import Path
import datasets
import torch
from build_dataset import build_instruction_dataset
import transformers
from transformers import (
CONFIG_MAPPING,
AutoConfig,
BitsAndBytesConfig,
AutoModelForCausalLM,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
DataCollatorForSeq2Seq
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
from peft import LoraConfig, TaskType, get_peft_model, PeftModel, prepare_model_for_kbit_training
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.40.0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
'''
--model_name_or_path
D:\\PycharmProject\\2024\\llama-3-chinese-8b-instruct-v2
--tokenizer_name_or_path
D:\\PycharmProject\\2024\\llama-3-chinese-8b-instruct-v2
--dataset_dir
D:\\PycharmProject\\2024\\Chinese-LLaMA-Alpaca-3-main\\data
--per_device_train_batch_size
1
--per_device_eval_batch_size
1
--do_train
1
--do_eval
1
--seed
42
--bf16
1
--num_train_epochs
3
--lr_scheduler_type
cosine
--learning_rate
1e-4
--warmup_ratio
0.05
--weight_decay
0.1
--logging_strategy
steps
--logging_steps
10
--save_strategy
steps
--save_total_limit
3
--evaluation_strategy
steps
--eval_steps
100
--save_steps
200
--gradient_accumulation_steps
8
--preprocessing_num_workers
8
--max_seq_length
1024
--output_dir
D:\\PycharmProject\\2024\\llama3-lora
--overwrite_output_dir
1
--ddp_timeout
30000
--logging_first_step
True
--lora_rank
64
--lora_alpha
128
--trainable
"q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
--lora_dropout
0.05
--modules_to_save
"embed_tokens,lm_head"
--torch_dtype
bfloat16
--validation_file
D:\\PycharmProject\\2024\\Chinese-LLaMA-Alpaca-3-main\\eval\\ruozhiba_qa2449_gpt4turbo.json
--load_in_kbits
16
'''
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
)
},
)
tokenizer_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The tokenizer for weights initialization.Don't set if you want to train a model from scratch."
)
},
)
config_overrides: Optional[str] = field(
default=None,
metadata={
"help": (
"Override some existing default config settings when a model is trained from scratch. Example: "
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
)
},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=False,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
torch_dtype: Optional[str] = field(
default=None,
metadata={
"help": (
"Override the default `torch.dtype` and load the model under this dtype. If `auto` is passed, the "
"dtype will be automatically derived from the model's weights."
),
"choices": ["auto", "bfloat16", "float16", "float32"],
},
)
low_cpu_mem_usage: bool = field(
default=False,
metadata={
"help": (
"It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
"set True will benefit LLM loading time and RAM consumption."
)
},
)
def __post_init__(self):
if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
raise ValueError(
"--config_overrides can't be used in combination with --config_name or --model_name_or_path"
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_dir: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
validation_split_percentage: Optional[float] = field(
default=0.05,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
keep_linebreaks: bool = field(
default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
)
data_cache_dir: Optional[str] = field(default=None, metadata={"help": "The datasets processed stored"})
max_seq_length: Optional[int] = field(default=1024)
@dataclass
class MyTrainingArguments(TrainingArguments):
trainable : Optional[str] = field(default="q_proj,v_proj")
lora_rank : Optional[int] = field(default=8)
lora_dropout : Optional[float] = field(default=0.1)
lora_alpha : Optional[float] = field(default=32.)
modules_to_save : Optional[str] = field(default=None)
peft_path : Optional[str] = field(default=None)
use_flash_attention_2 : Optional[bool] = field(default=False)
double_quant: Optional[bool] = field(default=True)
quant_type: Optional[str] = field(default="nf4")
load_in_kbits: Optional[int] = field(default=16)
full_finetuning : Optional[bool] = field(default=False)
logger = logging.getLogger(__name__)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, MyTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
send_example_telemetry("run_clm", model_args, data_args)
# Setup logging
logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO, # if training_args.local_rank in [-1, 0] else logging.WARN,
handlers=[logging.StreamHandler(sys.stdout)],)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16 or training_args.bf16}"
)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
config_kwargs = {
"cache_dir": model_args.cache_dir,
"revision": model_args.model_revision,
"use_auth_token": True if model_args.use_auth_token else None,
}
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.config_overrides is not None:
logger.info(f"Overriding config: {model_args.config_overrides}")
config.update_from_string(model_args.config_overrides)
logger.info(f"New config: {config}")
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
"use_auth_token": True if model_args.use_auth_token else None,
}
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.tokenizer_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer)
eval_dataset=None
train_dataset = None
if training_args.do_train:
with training_args.main_process_first(desc="loading and tokenization"):
path = Path(data_args.dataset_dir)
files = [os.path.join(path,file.name) for file in path.glob("*.json")]
logger.info(f"Training files: {' '.join(files)}")
train_dataset = build_instruction_dataset(
data_path=files,
tokenizer=tokenizer,
max_seq_length=data_args.max_seq_length,
data_cache_dir=None,
preprocessing_num_workers = data_args.preprocessing_num_workers)
logger.info(f"Num train_samples {len(train_dataset)}")
logger.info("Training example:")
logger.info(tokenizer.decode(train_dataset[0]['input_ids']))
if training_args.do_eval:
with training_args.main_process_first(desc="loading and tokenization"):
files = [data_args.validation_file]
logger.info(f"Evaluation files: {' '.join(files)}")
eval_dataset = build_instruction_dataset(
data_path=files,
tokenizer=tokenizer,
max_seq_length=data_args.max_seq_length,
data_cache_dir = None,
preprocessing_num_workers = data_args.preprocessing_num_workers)
logger.info(f"Num eval_samples {len(eval_dataset)}")
logger.info("Evaluation example:")
logger.info(tokenizer.decode(eval_dataset[0]['input_ids']))
torch_dtype = (
model_args.torch_dtype
if model_args.torch_dtype in ["auto", None]
else getattr(torch, model_args.torch_dtype)
)
compute_dtype = (torch.float16 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32))
if training_args.load_in_kbits in [4, 8]:
if training_args.modules_to_save is not None:
load_in_8bit_skip_modules = training_args.modules_to_save.split(',')
else:
load_in_8bit_skip_modules = None
quantization_config = BitsAndBytesConfig(
load_in_4bit=training_args.load_in_kbits == 4,
load_in_8bit=training_args.load_in_kbits == 8,
llm_int8_threshold=6.0,
load_in_8bit_skip_modules=load_in_8bit_skip_modules,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=training_args.double_quant,
bnb_4bit_quant_type=training_args.quant_type # {'fp4', 'nf4'}
)
else:
quantization_config = None
if quantization_config is not None:
logger.info(f"quantization_config:{quantization_config.to_dict()}")
# device_map = {"":int(os.environ.get("LOCAL_RANK") or 0)}
device_map = "cuda" # 直接指定使用 GPU
model = AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
torch_dtype=torch_dtype,
#low_cpu_mem_usage=model_args.low_cpu_mem_usage,
low_cpu_mem_usage=True,
device_map=device_map,
#device_map='cpu',
quantization_config=quantization_config,
attn_implementation="flash_attention_2" if training_args.use_flash_attention_2 else "sdpa"
)
if training_args.load_in_kbits in [4, 8]:
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=training_args.gradient_checkpointing)
model.config.use_cache = False
model_vocab_size = model.get_input_embeddings().weight.shape[0]
logger.info(f"Model vocab size: {model_vocab_size}")
logger.info(f"len(tokenizer):{len(tokenizer)}")
if model_vocab_size != len(tokenizer):
logger.info(f"Resize model vocab size to {len(tokenizer)}")
model.resize_token_embeddings(len(tokenizer))
if not training_args.full_finetuning:
if training_args.peft_path is not None:
logger.info("Peft from pre-trained model")
model = PeftModel.from_pretrained(model, training_args.peft_path, device_map=device_map, is_trainable=True)
else:
logger.info("Init new peft model")
target_modules = training_args.trainable.split(',')
modules_to_save = training_args.modules_to_save
if modules_to_save is not None:
modules_to_save = modules_to_save.split(',')
lora_rank = training_args.lora_rank
lora_dropout = training_args.lora_dropout
lora_alpha = training_args.lora_alpha
logger.info(f"target_modules: {target_modules}")
logger.info(f"lora_rank: {lora_rank}")
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=target_modules,
inference_mode=False,
r=lora_rank, lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
modules_to_save=modules_to_save)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
metrics["train_samples"] = len(train_dataset)
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] =len(eval_dataset)
try:
perplexity = math.exp(metrics["eval_loss"])
except OverflowError:
perplexity = float("inf")
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if __name__ == "__main__":
main()
merge_llama3_with_chinese_lora_low_mem.py
"""
Usage:
python merge_llama3_with_chinese_lora_low_mem.py \
--base_model path/to/llama-3-hf-model \
--lora_model path/to/llama-3-chinese-lora \
--output_type [huggingface|pth|] \
--output_dir path/to/output-dir
"""
import argparse
import json
import os
import gc
import torch
import peft
from transformers import AutoTokenizer
from huggingface_hub import snapshot_download
import re
import shutil
import safetensors
from safetensors.torch import load_file as safe_load_file
'''
--base_model D:\\PycharmProject\\2024\\llama-3-chinese-8b-instruct-v2
--lora_model D:\\PycharmProject\\2024\\llama3-lora
--output_dir D:\\PycharmProject\\2024\\llama3-lora-merge
'''
# 添加 dtype_byte_size 的替代实现
def dtype_byte_size(dtype):
"""
Returns the size (in bytes) of a given torch dtype
"""
if dtype == torch.bool:
return 1
elif dtype == torch.int8 or dtype == torch.uint8:
return 1
elif dtype == torch.int16 or dtype == torch.float16:
return 2
elif dtype == torch.int32 or dtype == torch.float32:
return 4
elif dtype == torch.int64 or dtype == torch.float64:
return 8
elif dtype == torch.bfloat16:
return 2
else:
raise ValueError(f"Unsupported dtype: {dtype}")
parser = argparse.ArgumentParser(description='Script to merge Llama-3-hf with Llama-3-Chinese or Llama-3-Chinese-Instruct LoRA weights')
parser.add_argument('--base_model', default=None, required=True,
type=str, help="Base model path (basically Llama-3-hf)")
parser.add_argument('--lora_model', default=None, required=True,
type=str, help="LoRA model path (Llama-3-Chinese-LoRA, Llama-3-Chinese-Instruct-LoRA)")
parser.add_argument('--output_type', default='huggingface',choices=['huggingface', 'pth'],
type=str, help="Output model type can be 'huggingface' (default) or 'pth' format")
parser.add_argument('--output_dir', default='./merged_model',
type=str, help="Output path for the merged model")
parser.add_argument('--verbose', default=False, action='store_true',
help="Show detailed debugging messages")
WEIGHTS_NAME = "adapter_model.bin"
SAFETENSORS_WEIGHTS_NAME = "adapter_model.safetensors"
layers_to_model_size = {
16 : '1B',
32 : '8B',
80 : '70B',
}
num_shards_of_models = {
'1B': 1,
'8B': 1,
'70B': 8
}
params_of_models = {
'1B':
{
"dim": 2048,
"n_heads": 16,
"n_layers": 16,
"norm_eps": 1e-05,
"vocab_size": -1,
},
'8B':
{
"dim": 4096,
"n_heads": 32,
"n_layers": 32,
"norm_eps": 1e-05,
"vocab_size": -1,
},
'70B':
{
"dim": 8192,
"n_heads": 64,
"n_layers": 80,
"norm_eps": 1e-05,
"vocab_size": -1,
},
}
def transpose(weight, fan_in_fan_out):
return weight.T if fan_in_fan_out else weight
def jsonload(filename):
with open(filename, "r") as file:
d = json.load(file)
return d
# Borrowed and modified from https://github.com/tloen/alpaca-lora
def translate_state_dict_key(k):
k = k.replace("base_model.model.", "")
if k == "model.embed_tokens.weight":
return "tok_embeddings.weight"
elif k == "model.norm.weight":
return "norm.weight"
elif k == "lm_head.weight":
return "output.weight"
elif k.startswith("model.layers."):
layer = k.split(".")[2]
if k.endswith(".self_attn.q_proj.weight"):
return f"layers.{layer}.attention.wq.weight"
elif k.endswith(".self_attn.k_proj.weight"):
return f"layers.{layer}.attention.wk.weight"
elif k.endswith(".self_attn.v_proj.weight"):
return f"layers.{layer}.attention.wv.weight"
elif k.endswith(".self_attn.o_proj.weight"):
return f"layers.{layer}.attention.wo.weight"
elif k.endswith(".mlp.gate_proj.weight"):
return f"layers.{layer}.feed_forward.w1.weight"
elif k.endswith(".mlp.down_proj.weight"):
return f"layers.{layer}.feed_forward.w2.weight"
elif k.endswith(".mlp.up_proj.weight"):
return f"layers.{layer}.feed_forward.w3.weight"
elif k.endswith(".input_layernorm.weight"):
return f"layers.{layer}.attention_norm.weight"
elif k.endswith(".post_attention_layernorm.weight"):
return f"layers.{layer}.ffn_norm.weight"
elif k.endswith("rotary_emb.inv_freq") or "lora" in k:
return None
else:
print(layer, k)
raise NotImplementedError
else:
print(k)
raise NotImplementedError
def unpermute(w):
return (
w.view(n_heads, 2, dim // n_heads // 2, dim).transpose(1, 2).reshape(dim, dim)
)
def save_shards(model_sd, num_shards: int, prefix="", verbose=False):
"""
Convert and save the HF format weights to PTH format weights
"""
with torch.no_grad():
if num_shards == 1:
new_state_dict = {}
for k, v in model_sd.items():
new_k = translate_state_dict_key(k)
if new_k is not None:
if "wq" in new_k or "wk" in new_k:
new_state_dict[new_k] = unpermute(v)
else:
new_state_dict[new_k] = v
os.makedirs(output_dir, exist_ok=True)
print(f"Saving shard 1 of {num_shards} into {output_dir}/{prefix}consolidated.00.pth")
torch.save(new_state_dict, output_dir + f"/{prefix}consolidated.00.pth")
else:
new_state_dicts = [dict() for _ in range(num_shards)]
for k in list(model_sd.keys()):
v = model_sd[k]
new_k = translate_state_dict_key(k)
if new_k is not None:
if new_k=='tok_embeddings.weight':
assert v.size(1)%num_shards==0
splits = v.split(v.size(1)//num_shards,dim=1)
elif new_k=='output.weight':
if v.size(0)%num_shards==0:
splits = v.split(v.size(0)//num_shards,dim=0)
else:
size_list = [v.size(0)//num_shards] * num_shards
size_list[-1] += v.size(0)%num_shards
splits = v.split(size_list, dim=0)
elif new_k=='norm.weight':
splits = [v] * num_shards
elif 'ffn_norm.weight' in new_k:
splits = [v] * num_shards
elif 'attention_norm.weight' in new_k:
splits = [v] * num_shards
elif 'w1.weight' in new_k:
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'w2.weight' in new_k:
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'w3.weight' in new_k:
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'wo.weight' in new_k:
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'wv.weight' in new_k:
splits = v.split(v.size(0)//num_shards,dim=0)
elif "wq.weight" in new_k or "wk.weight" in new_k:
v = unpermute(v)
splits = v.split(v.size(0)//num_shards,dim=0)
else:
print(f"Unexpected key {new_k}")
raise ValueError
if verbose:
print(f"Processing {new_k}")
for sd,split in zip(new_state_dicts,splits):
sd[new_k] = split.clone()
del split
del splits
del model_sd[k],v
gc.collect() # Effectively enforce garbage collection
os.makedirs(output_dir, exist_ok=True)
for i,new_state_dict in enumerate(new_state_dicts):
print(f"Saving shard {i+1} of {num_shards} into {output_dir}/{prefix}consolidated.0{i}.pth")
torch.save(new_state_dict, output_dir + f"/{prefix}consolidated.0{i}.pth")
def merge_shards(output_dir, num_shards: int):
ckpt_filenames = sorted([f for f in os.listdir(output_dir) if re.match('L(\d+)-consolidated.(\d+).pth',f)])
for i in range(num_shards):
shards_filenames = sorted([f for f in ckpt_filenames if re.match(f'L(\d+)-consolidated.0{i}.pth',f)])
print(f"Loading {shards_filenames} ...")
shards_dicts = [torch.load(os.path.join(output_dir,fn)) for fn in shards_filenames]
shards_merged = {}
for d in shards_dicts:
shards_merged |= d
print(f"Saving the merged shard to " + os.path.join(output_dir, f"consolidated.0{i}.pth"))
torch.save(shards_merged, os.path.join(output_dir, f"consolidated.0{i}.pth"))
print("Cleaning up...")
del shards_merged
for d in shards_dicts:
del d
del shards_dicts
gc.collect() # Effectively enforce garbage collection
for fn in shards_filenames:
os.remove(os.path.join(output_dir,fn))
if __name__=='__main__':
args = parser.parse_args()
base_model_path = args.base_model
lora_model_path = args.lora_model
output_dir = args.output_dir
output_type = args.output_type
os.makedirs(output_dir, exist_ok=True)
print(f"="*80)
print(f"Base model: {base_model_path}")
print(f"LoRA model: {lora_model_path}")
tokenizers_and_loras = []
print(f"Loading {lora_model_path}")
if not os.path.exists(lora_model_path):
print("Cannot find lora model on the disk. Downloading lora model from hub...")
lora_model_path = snapshot_download(repo_id=lora_model_path)
tokenizer = AutoTokenizer.from_pretrained(lora_model_path)
lora_config = peft.LoraConfig.from_pretrained(lora_model_path)
if os.path.exists(os.path.join(lora_model_path, SAFETENSORS_WEIGHTS_NAME)):
lora_filename = os.path.join(lora_model_path, SAFETENSORS_WEIGHTS_NAME)
use_safetensors = True
elif os.path.exists(os.path.join(lora_model_path, WEIGHTS_NAME)):
lora_filename = os.path.join(lora_model_path, WEIGHTS_NAME)
use_safetensors = False
else:
raise ValueError(
f"Please check that the file {WEIGHTS_NAME} or {SAFETENSORS_WEIGHTS_NAME} is present at {lora_model_path}."
)
if use_safetensors:
lora_state_dict = safe_load_file(lora_filename, device="cpu")
else:
lora_state_dict = torch.load(lora_filename, map_location='cpu')
# lora_state_dict = torch.load(os.path.join(lora_model_path,'adapter_model.bin'), map_location='cpu')
if 'base_model.model.model.embed_tokens.weight' in lora_state_dict:
lora_vocab_size = lora_state_dict['base_model.model.model.embed_tokens.weight'].shape[0]
assert lora_vocab_size == len(tokenizer), \
(f"The vocab size of the tokenizer {len(tokenizer)} does not match the vocab size of the LoRA weight {lora_vocab_size}!\n")
tokenizers_and_loras.append(
{
"tokenizer" :tokenizer,
"state_dict" :lora_state_dict,
"config": lora_config,
"scaling": lora_config.lora_alpha / lora_config.r,
"fan_in_fan_out" : lora_config.fan_in_fan_out,
})
if not os.path.exists(base_model_path):
print("Cannot find lora model on the disk. Downloading lora model from hub...")
base_model_path = snapshot_download(repo_id=base_model_path)
if os.path.exists(os.path.join(base_model_path, "pytorch_model.bin")):
ckpt_filenames = ["pytorch_model.bin"]
elif os.path.exists(os.path.join(base_model_path, "model.safetensors.index.json")):
ckpt_filenames = sorted([f for f in os.listdir(base_model_path) if re.match('model-(\d+)-of-(\d+).safetensors',f)])
elif os.path.exists(os.path.join(base_model_path, "pytorch_model.index.json")):
ckpt_filenames = sorted([f for f in os.listdir(base_model_path) if re.match('pytorch_model-(\d+)-of-(\d+).bin',f)])
# 修改为使用os.path.join来处理路径
model_path = os.path.join(base_model_path, "model.safetensors")
config_path = os.path.join(base_model_path, "config.json")
print(f"Checking model path: {model_path}")
print(f"Checking config path: {config_path}")
if os.path.exists(model_path):
print(f"Found model file at: {model_path}")
ckpt_filenames = [model_path]
else:
print(f"Warning: Could not find model file at: {model_path}")
ckpt_filenames = []
if not os.path.exists(config_path):
raise FileNotFoundError(f"Cannot find config.json at {config_path}")
if len(ckpt_filenames) == 0:
raise FileNotFoundError(f"Cannot find base model checkpoints in {base_model_path}. Please make sure the checkpoints are saved in the HF format.")
print(f"Loading config from: {config_path}")
layers = jsonload(config_path)["num_hidden_layers"]
print(f"Detected {layers} layers in model")
model_size = None
total_size = 0
for index, filename in enumerate(ckpt_filenames):
print(f"Loading ckpt {filename}")
if re.match('(.*).safetensors', filename):
print(f"Loading safetensors file: {filename}")
try:
state_dict = safe_load_file(filename, device="cpu")
print(f"Successfully loaded state dict with {len(state_dict)} keys")
except Exception as e:
print(f"Error loading safetensors file: {e}")
raise
else:
state_dict = torch.load(os.path.join(base_model_path,filename), map_location='cpu')
# state_dict = torch.load(os.path.join(base_model_path,filename), map_location='cpu')
if index == 0:
model_size = layers_to_model_size[layers]
if output_type == 'pth':
params = params_of_models[model_size]
num_shards = num_shards_of_models[model_size]
n_layers = params["n_layers"]
n_heads = params["n_heads"]
dim = params["dim"]
dims_per_head = dim // n_heads
base = 500000.0 # llama-3
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
print("Merging...")
for k in state_dict:
for tl_idx, t_and_l in enumerate(tokenizers_and_loras):
saved_key = 'base_model.model.'+k
lora_key_A = saved_key.replace('.weight','.lora_A.weight')
if saved_key in t_and_l['state_dict']:
if args.verbose:
print(f"copying {saved_key} from {tl_idx}-th LoRA weight to {k}")
state_dict[k] = t_and_l['state_dict'][saved_key].half().clone() # do we need half()?
if lora_key_A in t_and_l['state_dict']:
lora_key_B = lora_key_A.replace('lora_A.weight','lora_B.weight')
if args.verbose:
print(f"merging {lora_key_A} and lora_B.weight form {tl_idx}-th LoRA weight to {k}")
state_dict[k] += (
transpose(
t_and_l['state_dict'][lora_key_B].float()
@ t_and_l['state_dict'][lora_key_A].float(), t_and_l['fan_in_fan_out']) * t_and_l['scaling']
)
# weight_size = state_dict[k].numel() * dtype_byte_size(state_dict[k].dtype)
weight_size = state_dict[k].numel() * dtype_byte_size(state_dict[k].dtype)
total_size += weight_size
if output_type == 'huggingface':
print(f"Saving ckpt {filename} to {output_dir} in HF format...")
output_path = os.path.join(output_dir, os.path.basename(filename))
print(f"Output path: {output_path}")
# 确保目标文件不存在或可以被覆盖
if os.path.exists(output_path):
try:
print(f"Removing existing file: {output_path}")
os.unlink(output_path)
except OSError as e:
print(f"Warning: Could not remove existing file {output_path}: {e}")
# 强制进行一次垃圾回收
gc.collect()
if use_safetensors:
try:
print(f"Saving state dict with {len(state_dict)} keys to {output_path}")
safetensors.torch.save_file(
state_dict, output_path, metadata={"format": "pt"}
)
print(f"Successfully saved to {output_path}")
except Exception as e:
print(f"Error saving safetensors file: {e}")
print("Trying alternative save method...")
# 如果safetensors保存失败,尝试先保存为临时文件然后重命名
temp_path = output_path + ".tmp"
print(f"Saving to temporary file: {temp_path}")
safetensors.torch.save_file(
state_dict, temp_path, metadata={"format": "pt"}
)
if os.path.exists(temp_path):
if os.path.exists(output_path):
os.unlink(output_path)
os.rename(temp_path, output_path)
print(f"Successfully saved using temporary file method")
else:
print(f"Saving using torch.save to {output_path}")
torch.save(state_dict, os.path.join(output_dir, filename))
print(f"Successfully saved using torch.save")
elif output_type == 'pth':
print(f"Converting to pth format...")
save_shards(model_sd=state_dict, num_shards=num_shards,prefix=f"L{index+1}-", verbose=args.verbose)
del state_dict
gc.collect() # Effectively enforce garbage collection
print(f"Saving tokenizer")
tokenizers_and_loras[-1]['tokenizer'].save_pretrained(output_dir)
if output_type == 'pth':
with open(output_dir + "/params.json", "w") as f:
print(f"Saving params.json into {output_dir}/params.json")
json.dump(params, f)
merge_shards(output_dir, num_shards=num_shards)
if output_type=='huggingface':
configs = ('config.json', 'generation_config.json', 'pytorch_model.bin.index.json', "model.safetensors.index.json")
if model_size == "1B" or model_size == "1.3B":
configs = ('config.json', 'generation_config.json')
for config in configs:
if os.path.exists(os.path.join(lora_model_path, config)):
print(f"Saving {config} from {lora_model_path}")
with open(os.path.join(lora_model_path, config),'r') as f:
obj = json.load(f)
else:
if os.path.exists(os.path.join(base_model_path, config)):
print(f"Saving {config} from {base_model_path}")
with open(os.path.join(base_model_path, config),'r') as f:
obj = json.load(f)
if config == 'config.json':
obj['vocab_size'] = len(tokenizers_and_loras[-1]['tokenizer'])
if config == 'pytorch_model.bin.index.json' or config == "model.safetensors.index.json":
obj['metadata']['total_size'] = total_size
if os.path.exists(os.path.join(base_model_path, config)):
with open(os.path.join(output_dir, config), 'w') as f:
json.dump(obj, f, indent=2)
# for f in os.listdir(lora_model_path):
# if re.match('(.*).py', f):
# shutil.copy2(os.path.join(lora_model_path, f), output_dir)
print("Done.")
print(f"Check output dir: {output_dir}")

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)