Python----大模型(基于LLaMA Factory角色扮演模型微调)
LLaMAFactory是一个无需编码即可微调大模型的开源平台,支持LLaMA、Qwen等上百种预训练模型,提供多种训练算法(PPO、DPO等)和优化技术(LoRA、QLoRA等)。项目提供WebUI界面,简化了模型微调流程。使用步骤包括:1)安装依赖环境;2)从魔搭社区下载基础模型;3)准备并配置训练数据集;4)通过WebUI进行模型微调、评估和导出。该项目支持从7B到70B参数的模型,并提供多
一、LLaMA Factory
项目地址:https://github.com/hiyouga/LLaMA-Factory/tree/main
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调 平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模 型的微调,框架特性包括:
模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、 ChatGLM、Phi 等等。
训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、 LoRA+、LoftQ 和 PiSSA。
加速算子:FlashAttention-2 和 Unsloth。
推理引擎:Transformers 和 vLLM。
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
| Method | Bits | 7B | 14B | 30B | 70B | xB |
|---|---|---|---|---|---|---|
Full (bf16 or fp16) |
32 | 120GB | 240GB | 600GB | 1200GB | 18xGB |
Full (pure_bf16) |
16 | 60GB | 120GB | 300GB | 600GB | 8xGB |
| Freeze/LoRA/GaLore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 2xGB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | xGB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4GB |
安装依赖
| Mandatory | Minimum | Recommend |
|---|---|---|
| python | 3.9 | 3.10 |
| torch | 2.0.0 | 2.6.0 |
| torchvision | 0.15.0 | 0.21.0 |
| transformers | 4.49.0 | 4.50.0 |
| datasets | 2.16.0 | 3.2.0 |
| accelerate | 0.34.0 | 1.2.1 |
| peft | 0.14.0 | 0.15.1 |
| trl | 0.8.6 | 0.9.6 |
| Optional | Minimum | Recommend |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed | 0.10.0 | 0.16.4 |
| bitsandbytes | 0.39.0 | 0.43.1 |
| vllm | 0.4.3 | 0.8.2 |
| flash-attn | 2.5.6 | 2.7.2 |
安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e ".[torch,metrics]"
LLaMA-Factory 校验
llamafactory-cli version

二、魔搭社区下载大模型
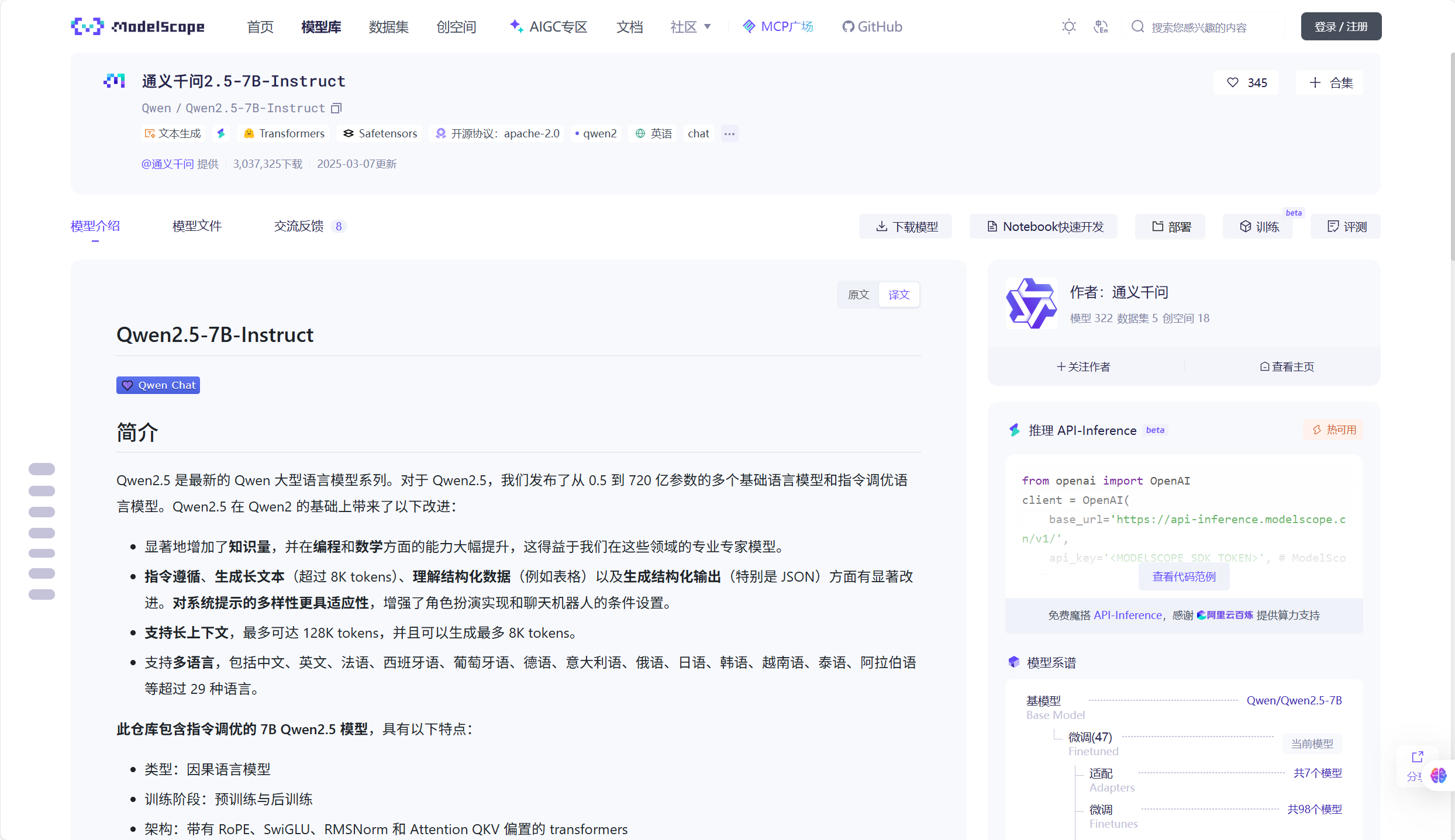
from modelscope.hub.snapshot_download import snapshot_download
llm_model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct',cache_dir='models')三、开启WebUI服务器端口
LLaMA-Factory 支持通过 WebUI 零代码微调大语言模型。 在完成安装后,可以通过以下指 令进入 WebUI:
llamafactory-cli webui如果多卡分布式训练,可以使用以下命令启动:
CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli webui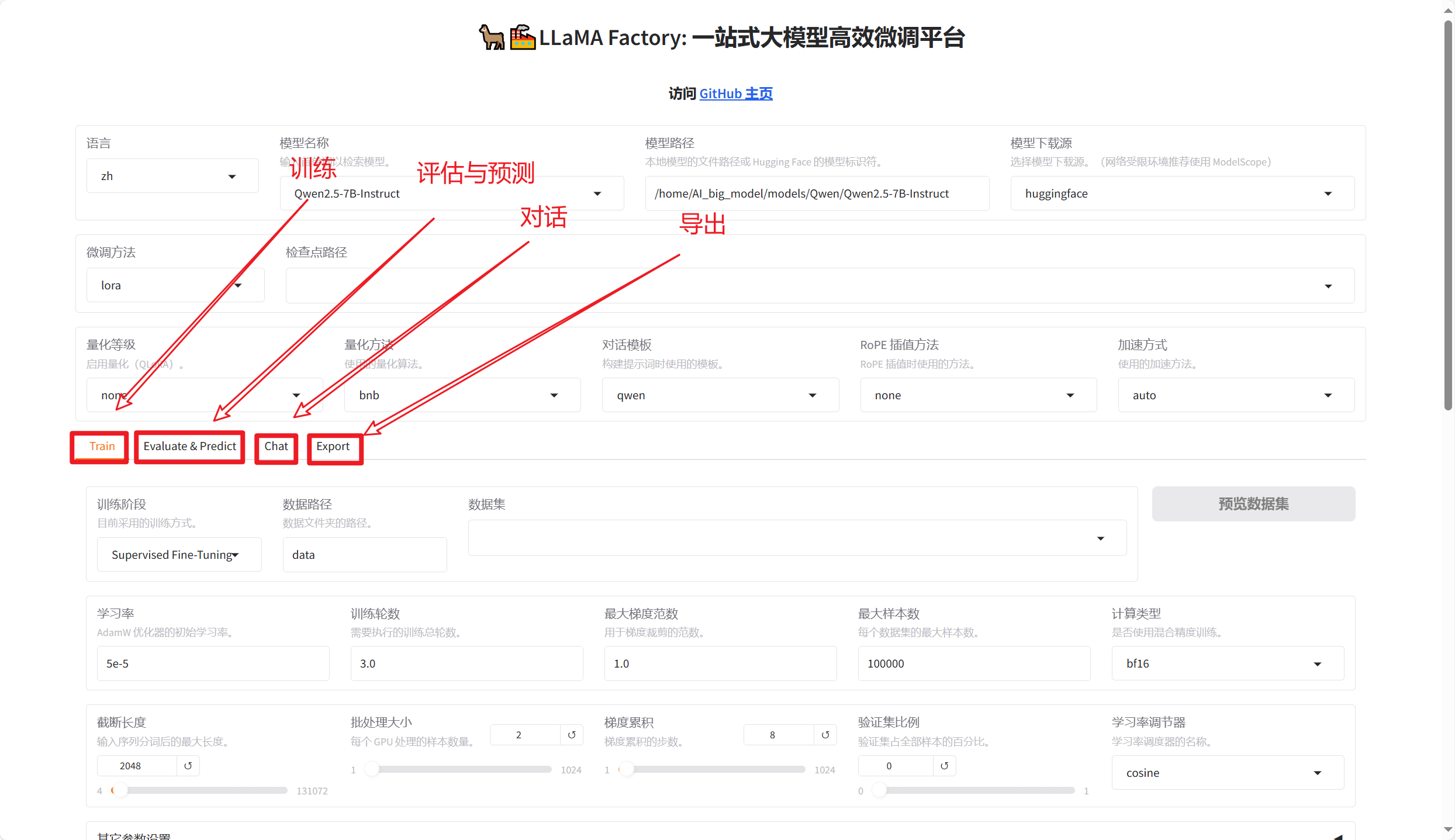
四、操作步骤
4.1、构建数据集
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
将下载下来的压缩包 data.zip 放在服务器中的LLaMA-Factory路径下。
cd LLaMA-Factory/mkdir -p data/role_play && unzip data.zip -d data/role_play在LLaMA-Factory-main/data/dataset_info.json 下添加如下配置
"role_play_train": {
"file_name": "role_play/train.json",
"formatting": "sharegpt"
},
"role_play_eval": {
"file_name": "role_play/eval.json",
"formatting": "sharegpt"
}4.2、模型微调
配置信息
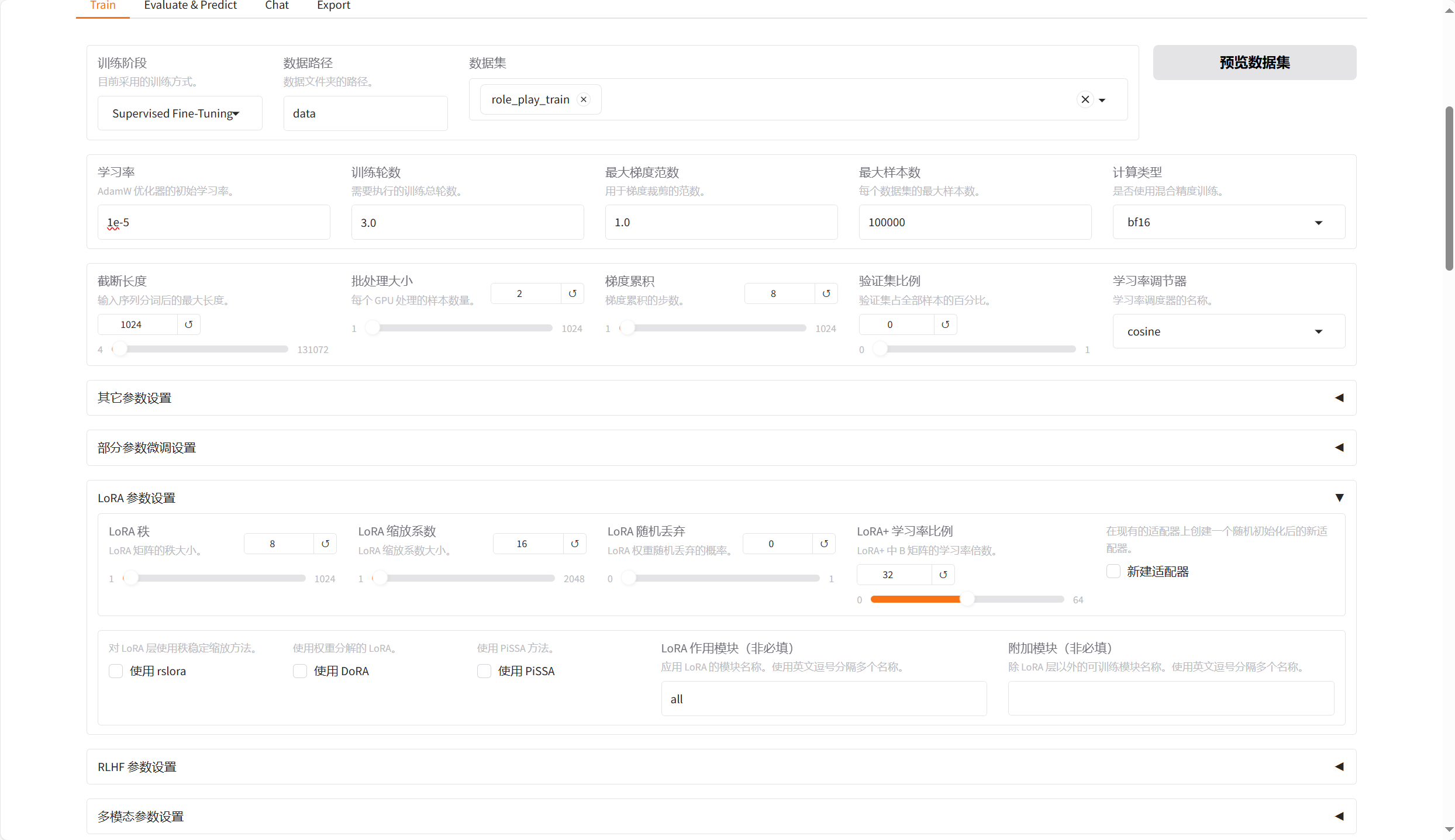
微调结果
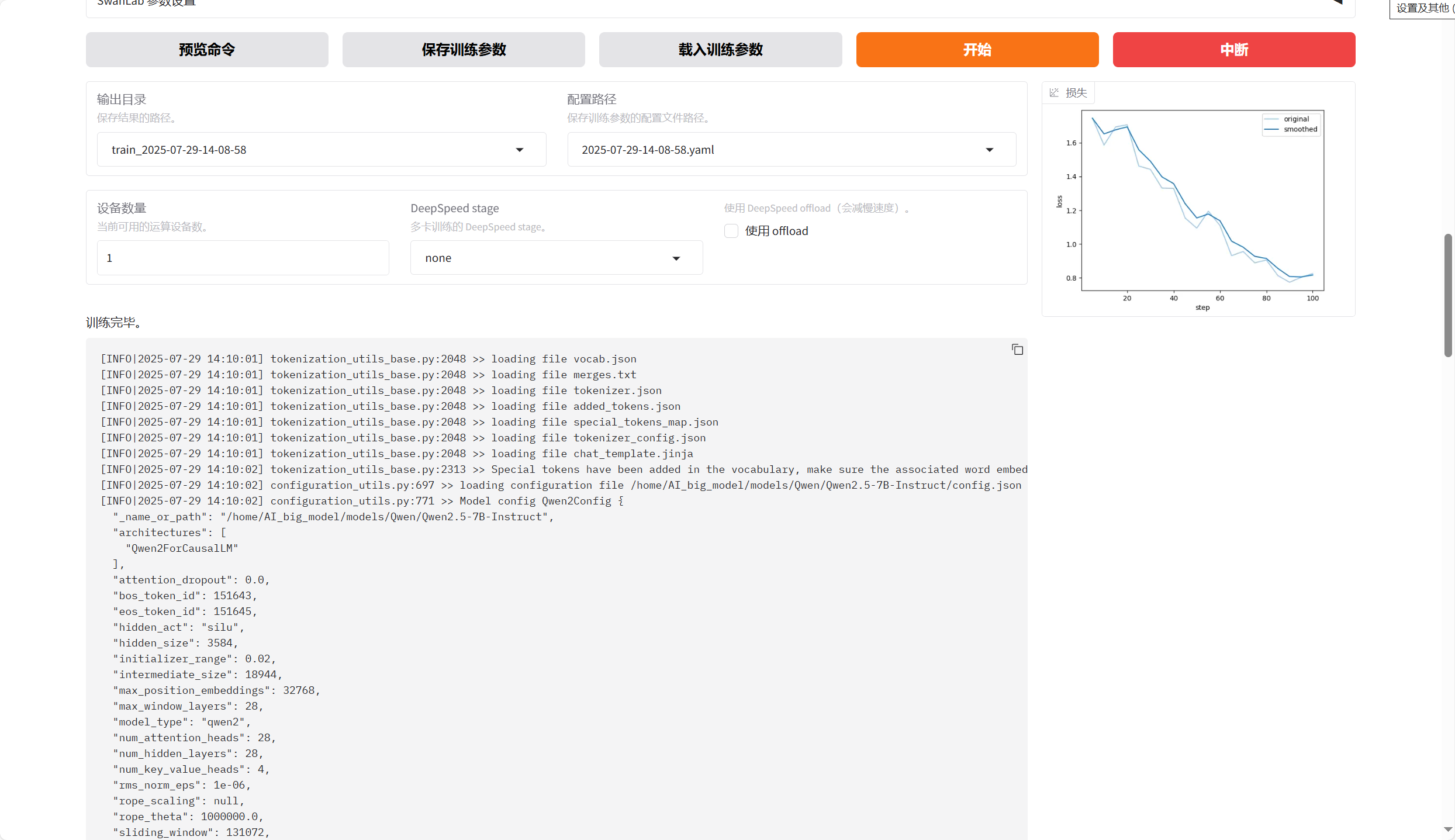
4.3、模型评估
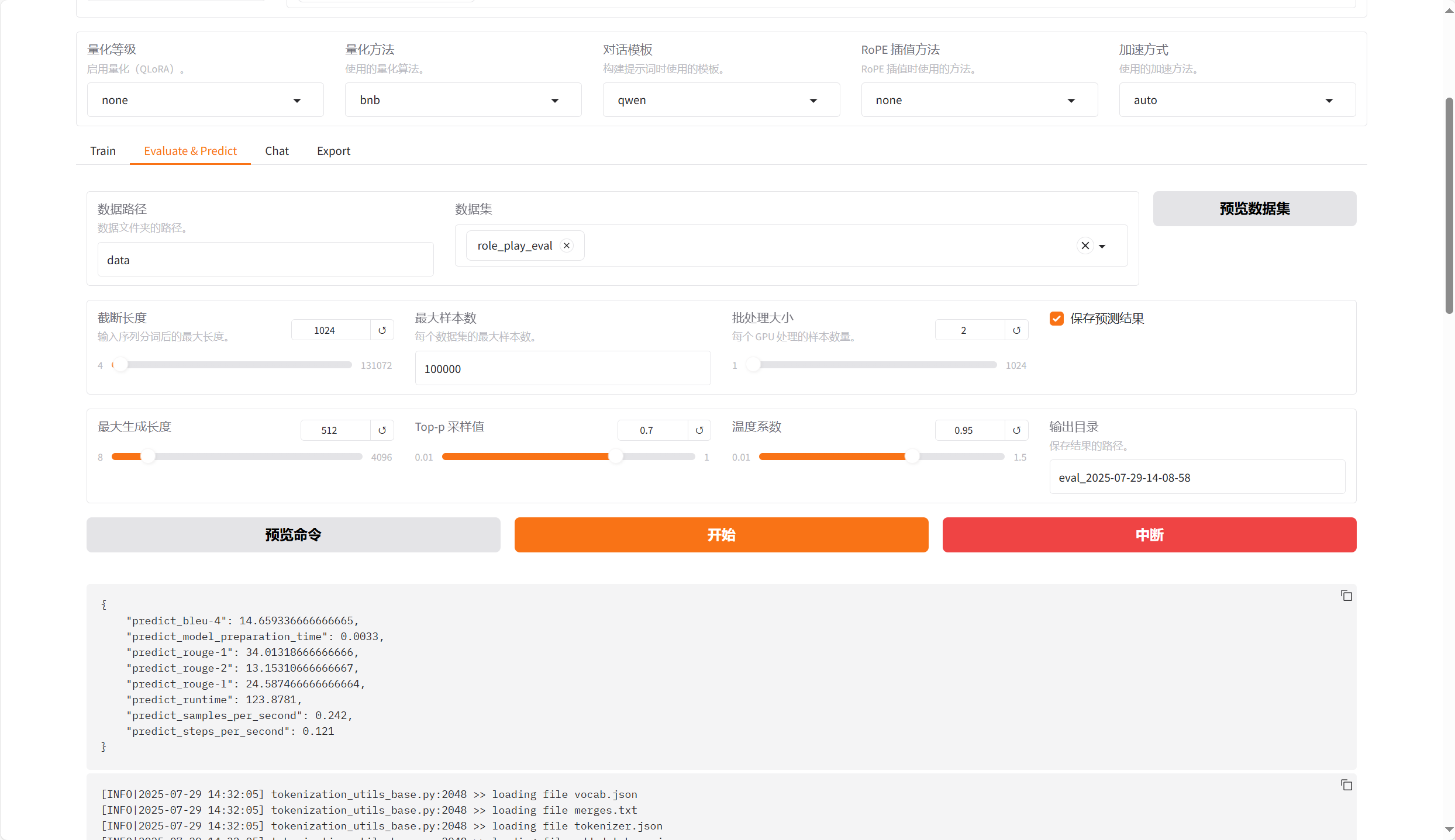
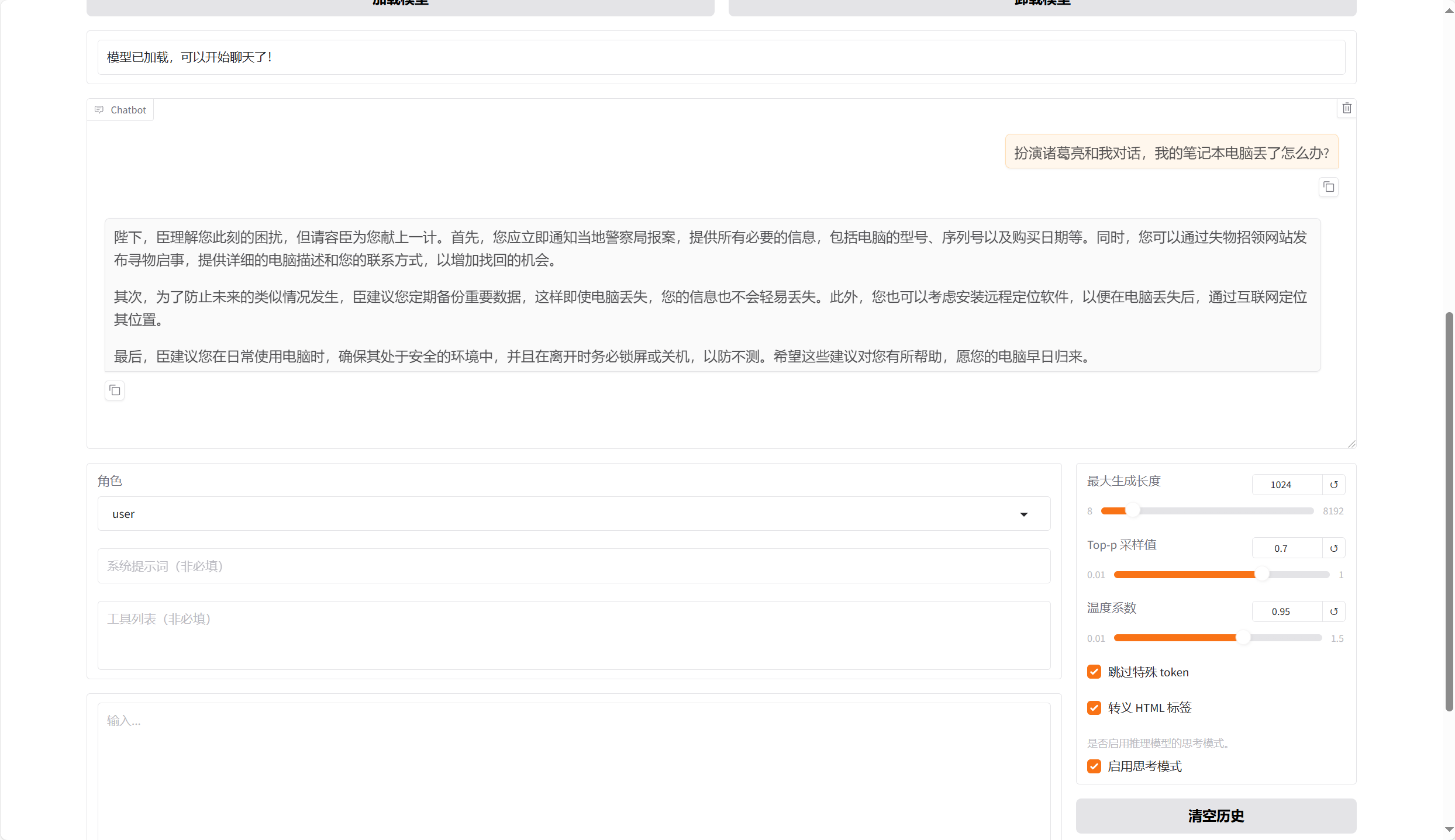
4.4、模型对话
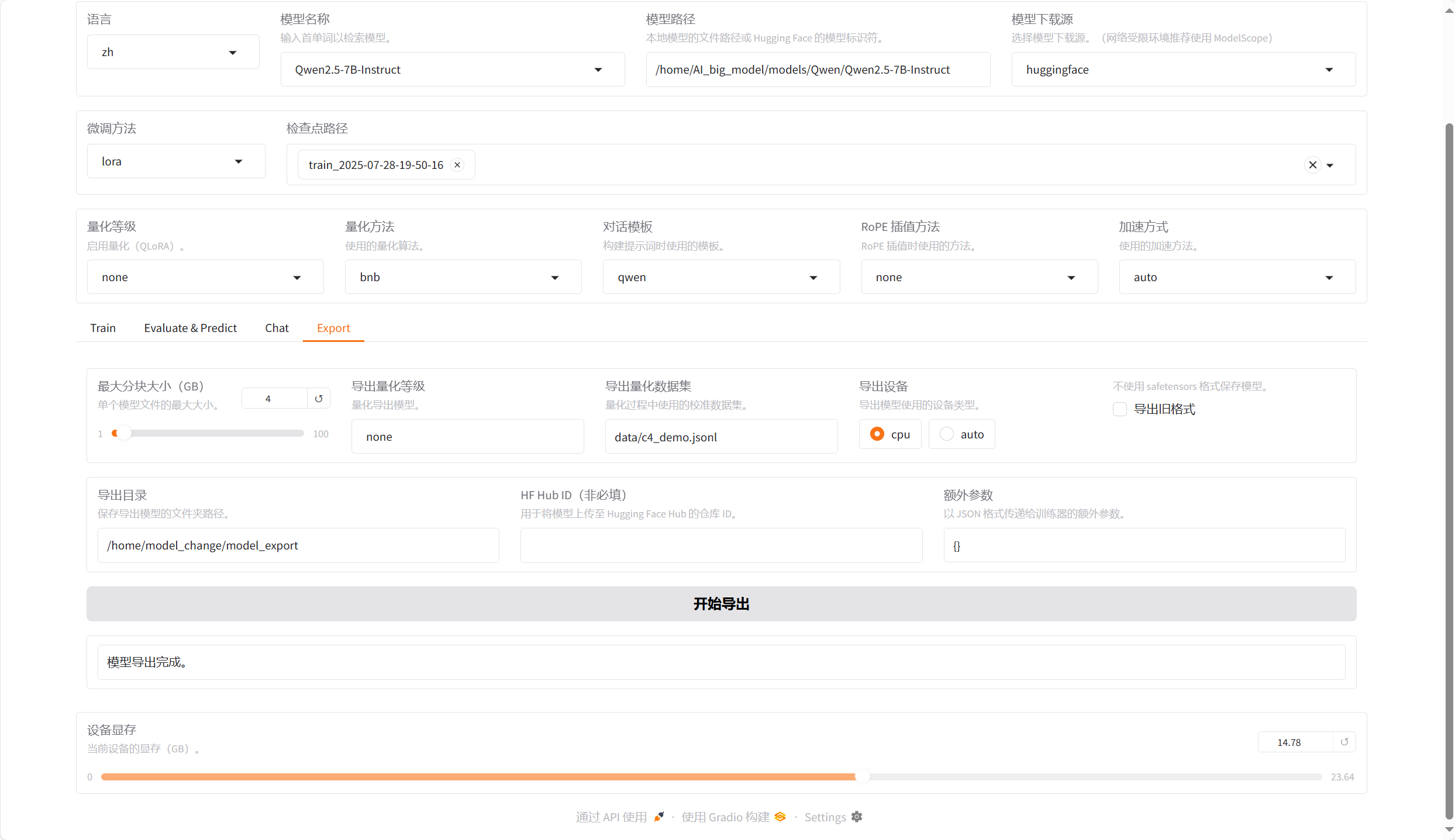
4.5、模型导出

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)